
Chapter 9. Regular expressions
Regular expressions are used in XML Schema to restrict the values of simple types to certain patterns of characters. For example, a pattern could specify that an SKU must be three digits, followed by a hyphen, followed by two uppercase letters. This chapter explains the XML Schema syntax for regular expressions.
9.1. The structure of a regular expression
XML Schema’s regular expression language is very similar to that of the Perl programming language. Regular expressions, also known as “regexes,” are made up of branches, which are in turn made up of pieces. Each piece consists of one atom and an optional quantifier.
For example, suppose the product number in your organization can either be an SKU or a 7-digit number. The SKU format is three digits, followed by a hyphen, followed by two uppercase letters—for example, 123-AB. We could represent this pattern by defining the simple type shown in Example 9–1.
Example 9–1. A simple type with a pattern
<xs:simpleType name="ProductNumberType">
<xs:restriction base="xs:string">
<xs:pattern value="d{3}-[A-Z]{2}|d{7}"/>
</xs:restriction>
</xs:simpleType>
One difference between XML Schema regular expressions and other regular expression languages is that XML Schema assumes anchors to be present at the beginning and end of the expression. This means that the whole value, not just a substring, must match the expression. In the previous example, the whole product number must be a 6-digit SKU or a 7-digit number, with no characters before or after it.
Figure 9–1 shows the structure of the regular expression from the previous example.

Figure 9–1. Structure of a regular expression
It has two branches separated by a vertical bar (|): the first to represent an SKU, and the second to represent a seven-digit number. If there is more than one branch in a regular expression, a matching string must match at least one of the branches; it is not required to match all of the branches. In this case, the first branch consists of three pieces:
• d{3} represents the initial three digits. The atom, d, is a character class escape that represents any digit. The quantifier, {3}, indicates how many times this atom (a digit) may appear.
• - represents the hyphen. The atom in this case is the hyphen, which represents itself as a normal character. This piece does not contain a quantifier, so the hyphen must appear once and only once.
• [A-Z]{2} represents the two letters. The atom, [A-Z], is a character class expression which represents any one of the letters A through Z. The quantifier, {2}, indicates how many times this atom (a letter) may appear.
The second branch, d{7}, consists of only one piece which represents the seven digits.
The rest of this chapter explains these concepts in detail.
9.2. Atoms
An atom describes one or more characters. It may be any one of the following:
• A normal character, such as a.
• Another regular expression, enclosed in parentheses, such as (a|b).
• An escape, indicated by a backslash, such as d or p{IsBasicLatin}.
• A character class expression, indicated by square brackets, such as [A-Z].
Each of these types of atoms is described in the sections that follow.
9.2.1. Normal characters
An atom can be a single character, as shown in Table 9–1. Each of the characters a, b, and c is an atom.
Table 9–1. Using normal characters

Most characters that can be entered from a keyboard can be represented directly in a regular expression. Some characters, known as metacharacters, have special meaning and must be escaped1 in order to be treated like normal characters. They are: ., , ?, *, +, |, {, }, (, ), [, and ]. This is explained in Section 9.2.3.1 on p. 165.
The space character can be used to represent itself in a regular expression. This means that you may not put any extra whitespace in the regular expression that will not appear in the matching strings. For example, the regular expression “a | b” will only match “a followed by a space” or “a space followed by b”.
Characters that are not easily entered on a keyboard may also be represented as they are in any XML document—by character references that specify the character’s Unicode code point. XML character references take two forms:
• “&#” plus a sequence of decimal digits representing the character’s code point, followed by “;”
• “&#x” plus a sequence of hexadecimal digits representing the character’s code point, followed by “;”
For example, a space can be represented as  . You can also include the predefined XML entities for the “less than,” “greater than,” ampersand, apostrophe, and quote characters. Table 9–2 lists some common XML character references and entities.
Table 9–2. Common XML character references and entities

Table 9–3 illustrates the inclusion of character entities and references in regular expressions.
Table 9–3. Using character references

9.2.2. The wildcard escape character
The period (.) has special significance in regular expressions; it matches any one character except a carriage return or line feed. The period character, known as wildcard, represents only one matching character, but a quantifier (such as *) may be applied to it to represent multiple characters. Table 9–4 shows some examples of the wildcard escape character in use.
Table 9–4. Using the wildcard escape character

The period character is also useful at the beginning or end of a regular expression to signify a pattern that starts with, ends with, or contains a matching string, as shown in the last three examples of the table. This gets around the implicit anchors in XML Schema regular expressions.
It is important to note that the period loses its wildcard power when placed in a character class expression (within square brackets).
9.2.3. Character class escapes
A character class escape uses the backslash () as an escape character to indicate any one of several characters. There are four categories of character class escapes:
• Single character escapes, which represent one specific character
• Multicharacter escapes, which represent any one of several characters
• Category escapes, which represent any one of a group of characters with similar characteristics (such as “Punctuation”), as defined in the Unicode standard
• Block escapes, which represent any one character within a range of code points, as defined in the Unicode standard
Note that each escape may be matched by only one character. You must apply a quantifier such as * to an escape to make it represent multiple characters.
This section describes each of the four types of character class escapes.
9.2.3.1. Single-character escapes
Single-character escapes are used for characters that are either difficult to read and write in their natural form, or have special meaning in regular expressions. Each escape represents only one possible matching character. Table 9–5 provides a complete list of single-character escapes.
Table 9–5. Single-character escapes

Table 9–6 illustrates single-character escapes in regular expressions. The first example has an unescaped plus sign (+). However, the plus sign has another meaning in regular expressions—it is treated as a quantifier on the atom consisting of the character 1. The second example escapes the plus sign, which results in it being treated as an atom itself that can appear in the matching string. The third example escapes the first plus sign, but not the second, resulting in the first one being interpreted as an atom and the second one being interpreted as a quantifier.
Table 9–6. Using single-character escapes

9.2.3.2. Multicharacter escapes
A multicharacter escape may represent any one of several characters. Table 9–7 provides a complete list of multicharacter escapes.
Table 9–7. Multicharacter escapes

Table 9–8 illustrates multicharacter escapes in regular expressions.
Table 9–8. Using multicharacter escapes

9.2.3.3. Category escapes
Category escapes provide convenient groupings of characters, based on their characteristics. These categories are defined by the Unicode standard. More information about the Unicode standard can be found at www.unicode.org. Table 9–9 provides a complete list of category escapes.


The syntax to use one of these escapes is p{xx} where xx is the one- or two-character property. For example, p{Nd} represents any decimal digit. It is also possible to represent the complement—that is, any character that is not part of the category, using a capital P. For example, P{Nd} represents any character that is not a decimal digit. Table 9–10 illustrates category escapes in regular expressions.
Table 9–10. Using category escapes

Note that the category escapes include all character sets. If you only intend for an expression to match the capital letters A through Z, it is better to use [A-Z] than p{Lu}, because p{Lu} will allow uppercase letters of all alphabets, not just Latin. Likewise, if your intention is to allow only the decimal digits 0 through 9, use [0-9] rather than p{Nd} or d, because there are digits other than 0 through 9 in some languages’ scripts.
9.2.3.4. Block escapes
Block escapes represent a range of characters based on their Unicode code points. The Unicode standard provides names for these ranges, such as Basic Latin, Greek, Thai, Mongolian, etc. The block names used in regular expressions are these same names, with the spaces removed. Table 9–11 lists the first five block escape ranges as an example. A complete list of the most recent Unicode blocks can be downloaded from www.unicode.org/Public/UNIDATA/Blocks.txt.
Table 9–11. Partial list of block escapes
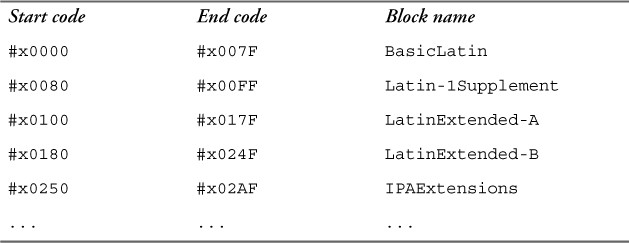
The syntax to use one of the block escapes is p{IsXX} where XX is the block name. For example, p{IsBasicLatin} represents any character in the range #x0000 to #x007F. It is also possible to represent the complement—that is, any character that is not part of the block—using a capital P. For example, P{IsBasicLatin} represents any character that is not in that range. Table 9–12 illustrates block escapes in regular expressions.
Table 9–12. Using block escapes

9.2.4. Character class expressions
A character class expression allows you to specify a choice from a set of characters. The expression, which appears in square brackets, may include a list of individual characters or character escapes, or a character range, or both. It is also possible to negate the specified set of characters, or subtract values from it. Like an escape, a character class expression may only represent one character in the matching string. To allow a matching character to appear multiple times, a quantifier may be applied to the expression.
9.2.4.1. Listing individual characters
The simplest case of a character class expression is a list of the matching characters or escapes. The expression represents one and only one of the characters listed. Table 9–13 illustrates a list of characters inside an expression. The first example can be read as “a or b or c, followed by z.” The character class expression in the second example uses escapes to represent one character that is either an uppercase letter or a decimal digit.
Table 9–13. Specifying a list of characters

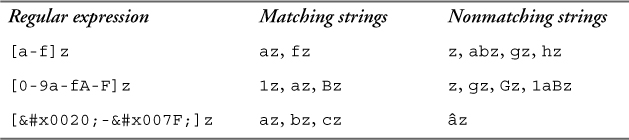
9.2.4.2. Specifying a range
A range of characters may be specified in a character class expression. The lower and upper bounds are inclusive, and they are separated by a hyphen. For example, to allow the letters a through f, you can specify [a-f]. The bounds must be single characters or single character escapes. It is not valid to specify a range using multicharacter strings, such as [(aa)-(fe)], or multicharacter escapes, such as [p{Lu}-p{Ll}]. The lower bound must have a code point that is less than or equal to that of the upper bound.
Multiple ranges may be specified in the same expression. If multiple ranges are specified, the character must match one of the ranges.
Table 9–14 illustrates ranges in expressions. The first example can be read as “a letter between a and f (inclusive), followed by z.” The second example provides three ranges, namely the digits 0 to 9, lowercase a to f, and uppercase A to F. The first character of a matching string must conform to at least one of these ranges. The third example uses character entities to represent the bounds.
Table 9–14. Specifying a range
9.2.4.3. Combining individual characters and ranges
It is also possible to combine ranges, individual characters, and escapes in an expression, in any order. Table 9–15 illustrates this. The first example allows the first character of the matching string to be either a digit 0 through 9, or one of the letters p, q, or r. The second example represents nearly the same thing, with a range on the letters instead of the numbers, and the escape d to represent the digits. It is not exactly the same thing because d also includes decimal digits from other character sets, not just the digits 0 through 9.
Table 9–15. Combining characters and ranges

9.2.4.4. Negating a character class expression
A character class expression can be negated to represent any character that is not in the specified set of characters. You can negate any expression, regardless of whether it is a range, a list of characters, or both. The negation character, ^, must appear directly after the opening bracket.
Table 9–16 illustrates this negation. The character class expression in the first example represents “any character except a or b.” In the second example it is “any character that is not a digit.” In the third, it is “any character that does not fall in the range 1 through 3 or a through c.” Note that the negation in the third example applies to both ranges. It is not possible to negate one range but not another in the same expression. To represent this, use subtraction, which is described in the next section.
Table 9–16. Negating a character class expression

9.2.4.5. Subtracting from a character class expression
It is possible to subtract individual values or ranges of values from a specified set of characters. A minus sign (-) precedes the values to be subtracted, which are themselves enclosed in square brackets. Table 9–17 illustrates subtractions from character class expressions. The first example represents “any character between a and z, except for c, followed by z.” The second is “any character between a and z, except for c and d, followed by z.” The third example subtracts a range, namely c through e, from the range a through z. The net result is that the allowed values are a through b and f through z. The fourth example is a subtraction from a negation of a subtraction. The negation character applies only to the a-z range, and the 123 digits are subtracted from that. Essentially, the example allows the first character to be anything except the letters a to z or the digits 1, 2, or 3.
Table 9–17. Subtracting from a character class expression

9.2.4.6. Escaping rules for character class expressions
Special escaping rules apply to character class expressions. They are as follows:
• The characters [, ], , and - should be escaped when included as individual characters or bounds in a range.1
• The character ^ should be escaped if it appears first in the character class expression, directly after the opening bracket ([).
The other metacharacters do not need to be escaped when used in a character class expression, because they have no special meaning in that context. This includes the period character, which does not serve as a wildcard escape character when inside a character class expression. However, it is never an error to escape any of the metacharacters, and getting into the habit of always escaping them eliminates the need to remember these rules.
9.2.5. Parenthesized regular expressions
A parenthesized regular expression may be used as an atom in a larger regular expression. Any regular expression may be included in the parentheses, including those containing normal characters, characters entities, escapes, and character class expressions.
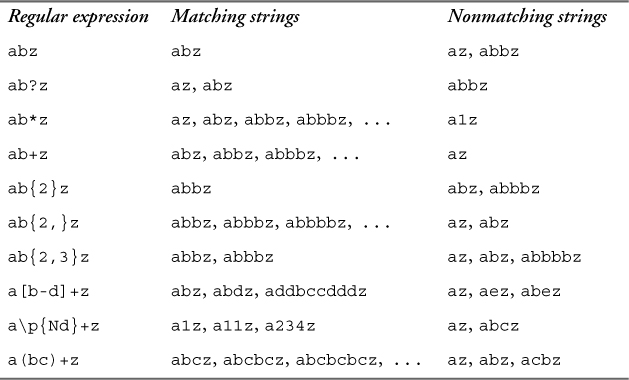
Parenthesized expressions are useful for repeating certain sequences of characters. For example, suppose you want to indicate a repetition of the string ab. The expression ab* will match abbb, but not abab because the quantifier applies to the final atom, not the entire string. To allow abab, you need to parenthesize the two characters: (ab)*.
Parenthesized expressions are also useful when you want to allow a choice between several different patterns. For example, to allow either the string ab or the string cd to come before z, you can use the expression (ab|cd)z. This example makes use of branches, which are described further in Section 9.4 on p. 177. Table 9–18 shows some examples of parenthesizing within regular expressions.
Table 9–18. Using parenthesized regular expressions

9.3. Quantifiers
A quantifier indicates how many times the atom may appear in a matching string. Table 9–19 lists the quantifiers.

Table 9–20 illustrates quantifiers in regular expressions. The first seven examples illustrate the seven types of quantifiers. They each have three atoms: a, b, and z, with the quantifier applying only to b. The remaining three examples show how quantifiers can apply not just to normal character atoms, but also to character class expressions, character class escapes, and parenthesized regular expressions, respectively.
9.4. Branches
As mentioned early in this chapter, a regular expression can consist of an unlimited number of branches. Branches, separated by the vertical bar (|) character, represent a choice between several expressions. The | character does not act on the atom immediately preceding it, but on the entire expression that precedes it (back to the previous | or an opening parenthesis). For example, the regular expression true|false indicates a choice between true and false, not “tru, followed by e or f, followed by alse”. It is not necessary to put true and false in parentheses. Table 9–21 shows some examples that exhibit the interaction between branches, expressions, and parentheses.
Table 9–21. Branches, expressions, and parentheses
