
Chapter 7. The Scala Object System
The Predef Object
For your convenience,
whenever you compile code, the Scala compiler automatically imports the
definitions in the java.lang package
(javac does this, too). On the .NET platform, it
imports the system package. The compiler also imports
the definitions in the analogous Scala package, scala.
Hence, common Java or .NET types can be used without explicitly importing
them or fully qualifying them with the java.lang.
prefix, in the Java case. Similarly, a number of common, Scala-specific
types are made available without qualification, such as
List. Where there are Java and Scala type names that
overlap, like String, the Scala version is imported
last, so it “wins.”
The compiler also
automatically imports the Predef object, which defines
or imports several useful types, objects, and functions.
Tip
You can learn a lot of Scala by viewing the source for
Predef. It is available by clicking the “source” link
in the Predef Scaladoc page, or you can download the
full source code for Scala at http://www.scala-lang.org/.
Table 7-1 shows a partial list of the items imported or
defined by Predef on the Java platform.
Types |
|
Exceptions |
|
Values |
|
Objects |
|
Classes |
|
Methods | Factory methods to create
tuples; overloaded versions of
|
Predef
declares the types and exceptions listed in the table using the
type keyword. They are definitions that equal the
corresponding scala.<Type> or
java.lang.<Type> classes, so they behave like
“aliases” or imports for the corresponding classes. For example,
String is declared as follows:
typeString= java.lang.String
In this case, the
declaration has the same net effect as an import
java.lang.String statement would have.
But didn’t we just say that
definitions in java.lang are imported automatically,
like String? The reason there is a type definition is
to enable support for a uniform string type across all runtime
environments. The definition is only redundant on the JVM.
The type
Pair is an “alias” for
Tuple2:
typePair[+A, +B]=Tuple2[A, B]
There are two type
parameters, A and B, one for each
item in the pair. Recall from Abstract Types And Parameterized Types that we explained the
meaning of the + in front of each type
parameter.
Briefly, a
Pair[A2,B2], for some A2 and
B2, is a subclass of
Pair[A1,B1], for some A1 and
B1, if A2 is a subtype of
A1 and B2 is a subtype of
B1. In Understanding Parameterized Types, we’ll
discuss + and other type qualifiers in more
detail.
The Pair
class also has a companion object
Pair with an apply factory method,
as discussed in Companion Objects. Hence, we can create
Pair instances as in this example:
val p = Pair(1, "one")
Pair.apply is
called with the two arguments. The types A and
B, shown in the definition of Pair,
are inferred. A new Tuple2 instance is returned.
Map and
Set appear in both the types and values lists. In the
values list, they are assigned the
companion objects
scala.collection.immutable.Map and
scala.collection.immutable.Set, respectively. Hence,
Map and Set in
Predef are values, not object
definitions, because they refer to objects defined elsewhere, whereas
Pair and Triple are defined in
Predef itself. The types Map and
Set are assigned the corresponding immutable classes.
The
ArrowAssoc class defines two methods:
->, and the Unicode equivalent →.
The utility of these methods was demonstrated previously in Option, Some, and None: Avoiding nulls, where we created a map of U.S. state
capitals:
valstateCapitals =Map("Alabama"->"Montgomery","Alaska"->"Juneau",// ..."Wyoming"->"Cheyenne")// ...
The definition of the
ArrowAssoc class and the Map and
Set values in Predef make the
convenient Map initialization syntax possible. First,
when Scala sees Map(...) it calls the
apply method on the Map companion
object, just as we discussed for Pair.
Map.apply
expects zero or more Pairs (e.g., (a1, b2),
(a2, b2), ...), where each tuple holds a name and value. In the
example, the tuple types are all inferred to be of type
Pair[String,String]. The declaration of
Map.apply is as follows:
objectMap{ ...defapply[A, B](elems : (A,B)*) :Map[A, B]= ... }
Recall that there can be no
type parameters on the Map companion object because
there can be only one instance. However, apply can have
type parameters.
The apply method takes a
variable-length argument list. Internally,
x will be a subtype of Array[X]. So,
for Map.apply, elems is of type
Array[(A,B)] or Array[Tuple2[A,B]],
if you prefer.
So, now that we know what
Map.apply expects, how do we get from a ->
b to (a, b)?
Predef
also defines an implicit type conversion method
called any2ArrowAssoc. The compiler knows that
String does not define a ->
method, so it looks for an implicit conversion
in scope to a type that defines such a method, such
as ArrowAssoc. The any2ArrowAssoc
method performs that conversion. It has the following
implementation:
implicitdefany2ArrowAssoc[A](x:A):ArrowAssoc[A]=newArrowAssoc(x)
It is applied to each item
to the left of an arrow ->, e.g., the
"Alabama" string. These strings are wrapped in
ArrowAssoc instances, upon which the
-> method is then invoked. This method has the
following implementation:
classArrowAssoc[A](x:A) { ...def->[B](y:B):Tuple2[A, B]=Tuple2(x, y) }
When it is invoked, it is
passed the string on the righthand side of the ->.
The method returns a tuple with the value, ("Alabama",
"Montgomery"), for example. In this way, each key ->
value is converted into a tuple and the resulting
comma-separated list of tuples is passed to the
Map.apply factory method.
The description may sound
complicated at first, but the beauty of Scala is that this map
initialization syntax is not an ad hoc language feature, such as a
special-purpose operator -> defined in the language
grammar. Instead, this syntax is defined with normal definitions of types
and methods, combined with a few general-purpose parsing conventions, such
as support for implicits. Furthermore, it is all
type-safe. You can use the same techniques to write
your own convenient “operators” for mini Domain-Specific
Languages (see Chapter 11).
Implicit type conversions are discussed in more detail in Implicit Conversions.
Next, recall from Chapter 1 that we were able to replace calls to
Console.println(...) with
println(...). This “bare” println
method is defined in Predef, then
imported automatically by the
compiler. The definition calls the corresponding method in Console. Similarly, all the other I/O
methods defined by Predef, e.g.,
readLine and format, call the corresponding
Console methods.
Finally, the
assert, assume, and
require methods are each overloaded with various
argument list options. They are used for runtime testing of boolean
conditions. If a condition is false, an exception is thrown. The
Ensuring class serves a similar purpose. You can use
these features for Design by Contract programming, as
discussed in Better Design with Design By Contract.
For the full list of
features defined by Predef, see the corresponding
Scaladoc entry in [ScalaAPI2008].
Classes and Objects: Where Are the Statics?
Many object-oriented languages allow classes to have class-level constants, fields, and methods, called “static” members in Java, C#, and C++. These constants, fields, and methods are not associated with any instances of the class.
An example of a class-level field is a shared logging instance used by all instances of a class for logging messages. An example of a class-level constant is the default logging “threshold” level.
An example of a class-level method is a “finder” method that locates all instances of the class in some repository that match some user-specified criteria. Another example is a factory method, as used in one of the factory-related design patterns (see [GOF1995]).
To remain consistent with
the goal that “everything is an object” in Scala, class-level fields and
methods are not supported. Instead, Scala supports declarations of classes
that are singletons, using the
object keyword instead of the class
keyword. The objects provide an object-oriented
approach to “static” data and methods. Hence, Scala does not even have a
static keyword.
Objects
are instantiated automatically and lazily by the runtime system (see
Section 5.4 of [ScalaSpec2009]). Just as for classes and
traits, the body of the object is the constructor, but
since the system instantiates the object, there is no way for the user to
specify a parameter list for the constructor, so they aren’t supported.
Any data defined in the object has to be initialized with default values.
For the same reasons, auxiliary constructors can’t be used and are not
supported.
We’ve already seen some
examples of objects, such as the specs objects used
previously for tests, and the Pair type and its
companion object, which we explored in The Predef Object:
typePair[+A, +B]=Tuple2[A, B]objectPair{defapply[A, B](x:A, y:B) =Tuple2(x, y)defunapply[A, B](x:Tuple2[A, B]):Option[Tuple2[A, B]]=Some(x) }
To reference an object field
or method, you use the syntax object_name.field or
object_name.method(...), respectively. For example,
Pair.apply(...). Note that this is the same syntax that
is commonly used in languages with static fields and methods.
Tip
When an object named MyObject is compiled to a
class file, the class file name will be
MyObject$.class.
In Java and C#, the
convention for defining constants is to use final
static fields. (C# also has a constant
keyword for simple fields, like ints and
strings.) In Scala, the convention is to use
val fields in objects.
Finally, recall from Nested Classes that class definitions can be nested within other class definitions. This property generalizes for objects. You can define nested objects, traits, and classes inside other objects, traits, and classes.
Package Objects
Scala version 2.8
introduces a new scoping construct called package
objects. They are used to define types, variables, and
methods that are visible at the level of the corresponding package. To
understand their usefulness, let’s see an example from Scala version 2.8
itself. The collection library is being reorganized to refine the
package structure and to use it more consistently (among other changes).
The Scala team faced a dilemma. They wanted to move types to new
packages, but avoid breaking backward compatibility. The
package object construct provided a solution, along
with other benefits.
For example, the immutable
List is defined in the scala
package in version 2.7, but it is moved to the
scala.collection.immutable package in version 2.8.
Despite the change, List is made visible in the
scala package using package object
scala, found in the
src/library/scala/package.scala file in the version
2.8 source code distribution. Note the file name. It’s not required, but
it’s a useful convention for package objects. Here is the full package
object definition (at the time of this writing; it could change before
the 2.8.0 final version is released):
packageobject scala {typeIterable[+A]= scala.collection.Iterable[A]valIterable = scala.collection.Iterable@deprecated("use Iterable instead")typeCollection[+A]=Iterable[A]@deprecated("use Iterable instead")valCollection =IterabletypeSeq[+A]= scala.collection.Sequence[A]valSeq = scala.collection.SequencetypeRandomAccessSeq[+A]= scala.collection.Vector[A]valRandomAccessSeq = scala.collection.VectortypeIterator[+A]= scala.collection.Iterator[A]valIterator = scala.collection.IteratortypeBufferedIterator[+A]= scala.collection.BufferedIterator[A]typeList[+A]= scala.collection.immutable.List[A]valList = scala.collection.immutable.ListvalNil = scala.collection.immutable.Niltype::[A] = scala.collection.immutable.::[A]val:: = scala.collection.immutable.::typeStream[+A]= scala.collection.immutable.Stream[A]valStream = scala.collection.immutable.StreamtypeStringBuilder= scala.collection.mutable.StringBuildervalStringBuilder = scala.collection.mutable.StringBuilder}
Note that pairs of
declarations like type List[+] = ... and val
List = ... are effectively “aliases” for the companion class
and object, respectively. Because the contents of the
scala package are automatically imported by the
compiler, you can still reference all the definitions in this object in
any scope without an explicit import statement for fully qualified
names.
Other than the way the
members in package objects are scoped, they behave just like other
object declarations. While this example contains only
vals and types, you can also
define methods, and you can subclass another class or trait and mix in
other traits.
Another benefit of
package objects is that it provides a more succinct implementation of
what was an awkward idiom before. Without package objects, you would
have to put definitions in an ad hoc object inside the desired package,
then import from the object. For example, here is how
List would have to be handled without a package
object:
packagescala {objecttoplevel{ ...typeList[+A]= scala.collection.immutable.List[A]valList = scala.collection.immutable.List... } } ...importscala.toplevel._ ...
Finally, another benefit of package objects is the way they provide a clear separation between the abstractions exposed by a package and the implementations that should be hidden inside it. In a larger application, a package object could be used to expose all the public types, values, and operations (methods) for a “component,” while everything else in the package and nested packages could be treated as internal implementation details.
Sealed Class Hierarchies
Recall from Case Classes that we demonstrated pattern matching with our
Shapes hierarchy, which use case classes. We had a
default case _ => ...
expression. It’s usually wise to have one. Otherwise, if someone defines a
new subtype of Shape and passes it to this
match statement, a runtime
scala.MatchError will be thrown, because the new shape
won’t match the shapes covered in the match statement. However, it’s not
always possible to define reasonable behavior for the default
case.
There is an alternative
solution if you know that the case class hierarchy is unlikely to change
and you can define the whole hierarchy in one file.
In this situation, you can add the sealed keyword to
the declaration of the common base class. When sealed, the compiler knows
all the possible classes that could appear in the match
expression, because all of them must be defined in the same source file.
So, if you cover all those classes in the case
expressions (either explicitly or through shared parent classes), then you
can safely eliminate the default case
expression.
Here is an example using the HTTP 1.1 methods (see [HTTP1.1]), which are not likely to change very often, so we declare a “sealed” set of case classes for them:
// code-examples/ObjectSystem/sealed/http-script.scalasealedabstractclassHttpMethod()caseclassConnect(body:String)extendsHttpMethodcaseclassDelete(body:String)extendsHttpMethodcaseclassGet(body:String)extendsHttpMethodcaseclassHead(body:String)extendsHttpMethodcaseclassOptions(body:String)extendsHttpMethodcaseclassPost(body:String)extendsHttpMethodcaseclassPut(body:String)extendsHttpMethodcaseclassTrace(body:String)extendsHttpMethoddefhandle(method:HttpMethod) = methodmatch{caseConnect(body)=>println("connect: "+ body)caseDelete(body)=>println("delete: "+ body)caseGet(body)=>println("get: "+ body)caseHead(body)=>println("head: "+ body)caseOptions(body)=>println("options: "+ body)casePost(body)=>println("post: "+ body)casePut(body)=>println("put: "+ body)caseTrace(body)=>println("trace: "+ body) }valmethods =List(Connect("connect body..."),Delete("delete body..."),Get("get body..."),Head("head body..."),Options("options body..."),Post("post body..."),Put("put body..."),Trace("trace body...")) methods.foreach { method=>handle(method) }
This script outputs the following:
connect: connect body... delete: delete body... get: get body... head: head body... options: options body... post: post body... put: put body... trace: trace body...
No default case is
necessary, since we cover all the possibilities. Conversely, if you omit
one of the classes and you don’t provide a default case or a case for a
shared parent class, the compiler warns you that the “match is not
exhaustive.” For example, if you comment out the case for
Put, you get this warning:
warning: match is not exhaustive!
missing combination Put
def handle (method: HttpMethod) = method match {
...You also get a
MatchError exception if a Put
instance is passed to the match.
Using
sealed has one drawback. Every time you add or remove a
class from the hierarchy, you have to modify the file, since the entire
hierarchy has to be declared in the same file. This breaks the
Open-Closed Principle (see [Meyer1997] and [Martin2003]), which
is a solution to the practical problem that it can be costly to modify
existing code, retest it (and other code that uses it), and redeploy it.
It’s much less “costly” if you can extend the system by adding new derived
types in separate source files. This is why we picked
the HTTP method hierarchy for the example. The list of methods is very
stable.
Tip
Avoid sealed case class hierarchies if the
hierarchy changes frequently (for an appropriate definition of
“frequently”).
Finally, you may have
noticed some duplication in the example. All the concrete classes have a
body field. Why didn’t we put that field in the parent
HttpMethod class? Because we decided to use case
classes for the concrete classes, we’ll run into the same problem with
case class inheritance that we discussed in Case Class Inheritance, where we added a shared
id field in the Shape hierarchy. We
need the body argument for each HTTP method’s
constructor, yet it will be made a field of each method type
automatically. So, we would have to use the override
val technique we demonstrated previously.
We could remove the case keywords and implement the methods and companion objects that we need. However, in this case, the duplication is minimal and tolerable.
What if we want to use case
classes, yet also reference the body field in
HttpMethod? Fortunately, we know that Scala will
generate a body reader method in every concrete
subclass (as long as we use the name body
consistently!). So, we can declare that method abstract in
HttpMethod, then use it as we see fit. The following
example demonstrates this technique:
// code-examples/ObjectSystem/sealed/http-body-script.scalasealedabstractclassHttpMethod() {defbody:StringdefbodyLength= body.length }caseclassConnect(body:String)extendsHttpMethodcaseclassDelete(body:String)extendsHttpMethodcaseclassGet(body:String)extendsHttpMethodcaseclassHead(body:String)extendsHttpMethodcaseclassOptions(body:String)extendsHttpMethodcaseclassPost(body:String)extendsHttpMethodcaseclassPut(body:String)extendsHttpMethodcaseclassTrace(body:String)extendsHttpMethoddefhandle(method:HttpMethod) = methodmatch{caseConnect(body)=>println("connect: "+ body)caseDelete(body)=>println("delete: "+ body)caseGet(body)=>println("get: "+ body)caseHead(body)=>println("head: "+ body)caseOptions(body)=>println("options: "+ body)casePost(body)=>println("post: "+ body)casePut(body)=>println("put: "+ body)caseTrace(body)=>println("trace: "+ body) }valmethods =List(Connect("connect body..."),Delete("delete body..."),Get("get body..."),Head("head body..."),Options("options body..."),Post("post body..."),Put("put body..."),Trace("trace body...")) methods.foreach { method=>handle(method) println("body length? "+ method.bodyLength) }
We declared
body abstract in HttpMethod. We
added a simple bodyLength method that calls
body. The loop at the end of the script calls
bodyLength. Running this script produces the following
output:
connect: connect body... body length? 15 delete: delete body... body length? 14 get: get body... body length? 11 head: head body... body length? 12 options: options body... body length? 15 post: post body... body length? 12 put: put body... body length? 11 trace: trace body... body length? 13
As always, every feature has pluses and minuses. Case classes and sealed class hierarchies have very useful properties, but they aren’t suitable for all situations.
The Scala Type Hierarchy
We have mentioned a number of types in Scala’s type hierarchy already. Let’s look at the general structure of the hierarchy, as illustrated in Figure 7-1.
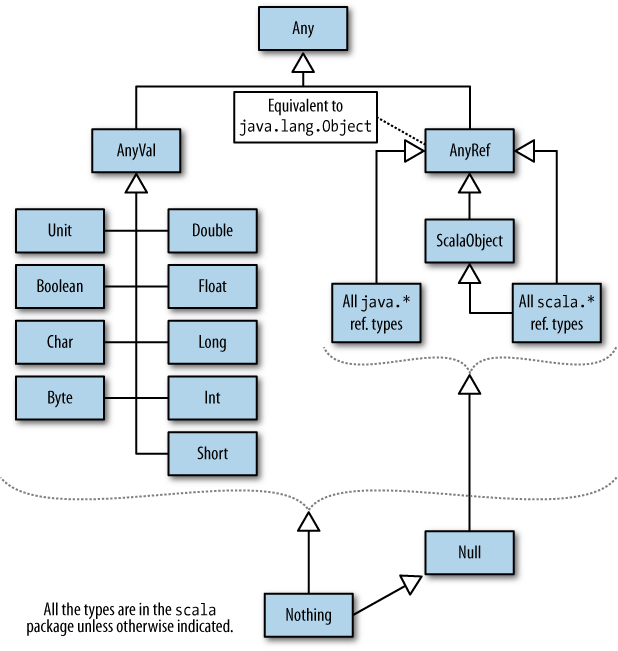
Tables 7-2 and 7-3 discuss the types shown in Figure 7-1, as well as some other important types that aren’t shown. Some details are omitted for clarity. When the underlying “runtime” is discussed, the points made apply equally to the JVM and the .NET CLR, except where noted.
| Name | Parent | Description |
| none | The root of the hierarchy. Defines a few
final methods like |
|
| The parent of all value types,
which correspond to the primitive types on
the runtime platform, plus |
|
| The parent of all reference
types, including all |
The value
types are children of AnyVal.
| Name | Runtime primitive type |
| Boolean ( |
| Byte. |
| Char. |
| Short. |
| Int. |
| Long. |
| Float. |
| Double. |
| Serves the same role as |
All other types, the
reference types, are children of
AnyRef. Table 7-4 lists
some of the more commonly used reference types. Note that there are some
significant differences between the version 2.7.X and 2.8
collections.
| Name | Parent | Description |
|
| Trait for collections of known size. |
|
| Used most often as a return type when a method could
return an instance of one of two unrelated types. For example, an
exception or a “successful” result. The |
|
| Trait representing a function that takes
|
|
| Trait with methods for operating on collections of
instances. Users implement
the abstract |
|
|
|
| All other types |
|
| All reference types |
|
|
| Wraps an optional item. It is a |
|
| An |
|
| Trait with methods for determining arity and getting
the nth item in a “Cartesian product.”
Subtraits are defined for |
| Mixin trait added to all Scala reference type instances. | |
|
| Trait for ordered collections. |
|
| Separate case classes for arity |
Besides
List, some of the other library collections include
Map, Set, Queue,
and Stack. These other collections come in two
varieties: mutable and immutable. The immutable collections are in the
package scala.collection.immutable, while the mutable
collections are in scala.collection.mutable. Only an
immutable version of List is provided; for a mutable
list, use a ListBuffer, which can return a
List via the toList method. For Scala version 2.8, the collections
implementations reuse code from
scala.collection.generic. Users of the collections
would normally not use any types defined in this package. We’ll explore
some of these collections in greater detail in Functional Data Structures.
Consistent with its
emphasis on functional programming (see Chapter 8), Scala encourages you to use the
immutable collections, since List is automatically
imported and Predef defines types
Map and Set that refer to the
immutable versions of these collections. All other collections have to be
imported explicitly.
Predef
defines a number of implicit conversion methods for the value types
(excluding Unit). There are implicit conversions to the
corresponding scala.runtime.RichX types. For example,
the byteWrapper method converts a
Byte to a scala.runtime.RichByte.
There are implicit conversions between the “numeric”
types—Byte, Short,
Int, Long, and
Float—to the other types that are “wider” than the
original. For example, Byte to Int,
Int to Long, Int
to Double, etc. Finally, there are conversions to the
corresponding Java wrapper types, e.g., Int to
java.lang.Integer. We discuss implicit conversions in
more detail in Implicit Conversions.
There are several examples of
Option elsewhere, e.g., Option, Some, and None: Avoiding nulls. Here is a script that illustrates using an
Either return value to handle a thrown exception or
successful result (adapted from http://dcsobral.blogspot.com/2009/06/catching-exceptions.html):
// code-examples/ObjectSystem/typehierarchy/either-script.scaladefexceptionToLeft[T](f:=> T):Either[java.lang.Throwable, T]=try{Right(f) }catch{caseex=>Left(ex) }defthrowsOnOddInt(i:Int) = i %2match{case0=>icase1=>thrownewRuntimeException(i +" is odd!") }for(i<-0to3) exceptionToLeft(throwsOnOddInt(i))match{caseLeft(ex)=>println("Oops, got exception "+ ex.toString)caseRight(x)=>println(x) }
The
exceptionToLeft method evaluates f.
It catches a Throwable and returns it as the
Left value or returns the normal result as the
Right value. The for loop uses this
method to invoke throwsOnOddInt. It pattern matches on
the result and prints an appropriate message. The output of the script is
the following:
0 Oops, got exception java.lang.RuntimeException: 1 is odd! 2 Oops, got exception java.lang.RuntimeException: 3 is odd!
A
FunctionN trait, where N is 0 to 22,
is instantiated for an anonymous function with N
arguments. So, consider the following anonymous function:
(t1:T1, ..., tN:TN)=>newR(...)
It is syntactic sugar for the following creation of an anonymous class:
newFunctionN{defapply(t1:T1, ..., tN:TN):R=newR(...)// other methods}
We’ll revisit
FunctionN in Variance Under Inheritance and Function Types.
Linearization of an Object’s Hierarchy
Because of single
inheritance, the inheritance hierarchy would be linear, if we ignored
mixed-in traits. When traits are considered, each of which may be derived
from other traits and classes, the inheritance hierarchy forms a directed,
acyclic graph (see [ScalaSpec2009]). The term
linearization refers to the algorithm used to
“flatten” this graph for the purposes of resolving method lookup
priorities, constructor invocation order, binding of
super, etc.
Informally, we saw in Stackable Traits that when an instance has more than one trait, they bind right to left, as declared. Consider the following example of linearization:
// code-examples/ObjectSystem/linearization/linearization1-script.scalaclassC1{defm=List("C1") }traitT1extendsC1{overridedefm= {"T1"::super.m } }traitT2extendsC1{overridedefm= {"T2"::super.m } }traitT3extendsC1{overridedefm= {"T3"::super.m } }classC2extendsT1withT2withT3{overridedefm= {"C2"::super.m } }valc2 =newC2println(c2.m)
Running this script yields the following output:
List(C2, T3, T2, T1, C1)
This list of strings built
up by the m methods reflects the
linearization of the inheritance hierarchy, with a
few missing pieces we’ll discuss shortly. We’ll also see why C1 is at the
end of the list. First, let’s see what the invocation sequence of the
constructors looks like:
// code-examples/ObjectSystem/linearization/linearization2-script.scalavarclist =List[String]()classC1{ clist ::="C1"}traitT1extendsC1{ clist ::="T1"}traitT2extendsC1{ clist ::="T2"}traitT3extendsC1{ clist ::="T3"}classC2extendsT1withT2withT3{ clist ::="C2"}valc2 =newC2println(clist.reverse)
Running this script yields the following output:
List(C1, T1, T2, T3, C2)
So, the construction sequence is the reverse. (We had to reverse the list on the last line, because the way it was constructed put the elements in the reverse order.) This invocation order makes sense. For proper construction to occur, the parent types need to be constructed before the derived types, since a derived type often uses fields and methods in the parent types during its construction process.
The output of the first
linearization script is actually missing three types at the end. The full
linearization for reference types actually ends with
ScalaObject, AnyRef, and
Any. So the linearization for C2 is
actually:
List(C2, T3, T2, T1, C1, ScalaObject, AnyRef, Any)
Scala inserts the
ScalaObject trait as the last mixin, just before
AnyRef and Any that are the
penultimate and ultimate parent classes of any reference type. Of course,
these three types do not show up in the output of the scripts, because we
used an ad hoc m method to figure out the behavior by
building up an output string.
The “value types,” subclasses of
AnyVal, are all declared abstract
final. The compiler manages instantiation of them. Since we
can’t subclass them, their linearizations are simple and
straightforward.
The linearization defines the order in which method lookup occurs. Let’s examine it more closely.
All our classes and traits
define the method m. The one in C2
is called first, since the instance is of that type.
C2.m calls super.m, which resolves
to T3.m. The search appears to be
breadth-first, rather than
depth-first. If it were depth-first, it would invoke
C1.m after T3.m. Afterward,
T3.m, T2.m, then
T1.m, and finally C1.m are invoked.
C1 is the parent of the three traits. From which of the
traits did we traverse to C1? Actually, it is
breadth-first, with “delayed” evaluation, as we will see. Let’s modify our
first example and see how we got to C1:
// code-examples/ObjectSystem/linearization/linearization3-script.scalaclassC1{defm(previous:String) =List("C1("+previous+")") }traitT1extendsC1{overridedefm(p:String) = {"T1"::super.m("T1") } }traitT2extendsC1{overridedefm(p:String) = {"T2"::super.m("T2") } }traitT3extendsC1{overridedefm(p:String) = {"T3"::super.m("T3") } }classC2extendsT1withT2withT3{overridedefm(p:String) = {"C2"::super.m("C2") } }valc2 =newC2println(c2.m(""))
Now we pass the name of the
caller of super.m as a parameter, then
C1 prints out who called it. Running this script yields
the following output:
List(C2, T3, T2, T1, C1(T1))
It’s the last one,
T1. We might have expected T3 from a
“naïve” application of breadth-first traversal.
Here is the actual algorithm for calculating the linearization. A more formal definition is given in [ScalaSpec2009].
This explains how we got to
C1 from T1 in the previous example.
T3 and T2 also have it in their
linearizations, but they come before T1, so the
C1 terms they contributed were deleted.
Let’s work through the algorithm using a slightly more involved example:
// code-examples/ObjectSystem/linearization/linearization4-script.scalaclassC1{defm=List("C1") }traitT1extendsC1{overridedefm= {"T1"::super.m } }traitT2extendsC1{overridedefm= {"T2"::super.m } }traitT3extendsC1{overridedefm= {"T3"::super.m } }classC2AextendsT2{overridedefm= {"C2A"::super.m } }classC2extendsC2AwithT1withT2withT3{overridedefm= {"C2"::super.m } }defcalcLinearization(obj:C1, name:String) = {vallin = obj.m :::List("ScalaObject","AnyRef","Any") println(name +": "+ lin) } calcLinearization(newC2,"C2 ") println("") calcLinearization(newT3{},"T3 ") calcLinearization(newT2{},"T2 ") calcLinearization(newT1{},"T1 ") calcLinearization(newC2A,"C2A") calcLinearization(newC1,"C1 ")
C2 : List(C2, T3, T1, C2A, T2, C1, ScalaObject, AnyRef, Any) T3 : List(T3, C1, ScalaObject, AnyRef, Any) T2 : List(T2, C1, ScalaObject, AnyRef, Any) T1 : List(T1, C1, ScalaObject, AnyRef, Any) C2A: List(C2A, T2, C1, ScalaObject, AnyRef, Any) C1 : List(C1, ScalaObject, AnyRef, Any)
To help us along, we
calculated the linearizations for the other types, and we also appended
ScalaObject, AnyRef, and
Any to remind ourselves that they should also be there.
We also removed the logic to pass the caller’s name to
m. That caller of C1 will
always be the element to its immediate
left.
So, let’s work through the
algorithm for C2 and confirm our results. We’ll
suppress the ScalaObject, AnyRef,
and Any for clarity, until the end. See Table 7-5.
| # | Linearization | Description |
1 |
| Add the type of the instance. |
2 |
| Add the linearization for |
3 |
| Add the linearization for
|
4 |
| Add the linearization for
|
5 |
| Add the linearization for
|
6 |
| Remove duplicates of |
7 |
| Remove duplicate |
8 |
| Finish! |
What the algorithm does is push any shared types to the right until they come after all the types that derive from them.
Try modifying the last script with different hierarchies and see if you can reproduce the results using the algorithm.
Recap and What’s Next
We have finished our survey of Scala’s object model. If you come from an object-oriented language background, you now know enough about Scala to replace your existing object-oriented language with object-oriented Scala.
However, there is much more to come. Scala supports functional programming, which offers powerful mechanisms for addressing a number of design problems, such as concurrency. We’ll see that functional programming appears to contradict object-oriented programming, at least on the surface. That said, a guiding principle behind Scala is that these two paradigms complement each other more than they conflict. Combined, they give you more options for building robust, scalable software. Scala lets you choose the techniques that work best for your needs.