
THE WEB APPLICATION SECURITY CONSORTIUM (WASC) is a nonprofit organization dedicated to promoting the best practices of application security. The participants are both experts and beginning students of application security—individuals, academic institutions, and corporations from all over the world. It is important to realize that anyone can participate and cooperate with the WASC. As a reader of this book, you are one of the more qualified people to contribute.
In this chapter, you will be introduced to several weaknesses of applications and how they can be exploited. You will learn several reasons why the WASC exists and is necessary. Finally, you will understand many best practices for mitigating the threats.
Security is a top priority for today's Web sites and Web applications. The computing world struggles to ensure that security keeps pace with expanding e-commerce and online business opportunities. Old vulnerabilities are commonly exploited while new ones are discovered. News of exploits, identify theft, and other security breaches shakes consumer and end-user confidence.
Despite the risks, people continue to shop, bank, and post personal data online. With each transaction, they send credit card information, names, addresses, passwords, and more over the Web. This information is constantly at risk. In the past, perimeter security measures were deployed to help address the risks as were security protocols such as Secure Sockets Layer (SSL) and Transport Layer Security (TLS); however, these measures are not enough to secure all data.
The Web Application Security Consortium (WASC) identifies 34 classes of Web attacks and 15 different Web site weaknesses. Web sites and Web applications face these attacks every day. Some attacks seek to capture data, others to overwhelm the system and applications. Further, many of these attacks cannot be addressed with traditional perimeter security measures. New security and policy measures need to be incorporated into an organization's security strategy.
Note
More information about WASC can be found in Chapter 15.
Phishing schemes, denial of services, stolen credit card numbers, identify theft—the threats to Web sites and Web applications seem overwhelming. The first step in protecting Web applications and Web services is having a clear understanding of the current threats that can affect an organization's network and Web services. Attacks result in loss of data, identity theft, loss of brand integrity, and loss of money.
Web site and Web applications are a target for today's hackers and cyber criminals. As people become more integrated into the Web—with online banking, online healthcare information, online purchasing, and the posting of confidential data—securing Web applications and services becomes increasingly critical. Unfortunately, every online transaction is a potential security risk with cyber criminals patiently waiting to exploit Web site and Web application vulnerabilities. Organizations today must design and implement strategies to address Web site vulnerabilities. The WASC outlines 34 threats to Web applications and processes. These risks are discussed next.
Today's Web sites offer many interactive features and provide a range of services and functionality. In normal operation, the functions that a site provides are a harmless addition to the Web site, but in the hands of the hacker, these functions become a security threat.
The abuse of functionality attack takes advantage of the features of a Web site or a Web application to launch an attack. Among the dangers of an abuse of functionality attack are that it can access an application or Web site with the intention to defraud, launch a denial of service attack to consume resources, modify the site, or damage the Web application.
The abuse of functionality problem occurs with interactive Web sites. When Internet visitors are given access and interactive privileges, such as using the search feature or uploading files, some people find ways to turn these features into attacks. There are several forms of interactive content that may be abused:
Password/username recovery forms
Spamming e-mail forms
Using a Web site's search feature to navigate through unprotected areas of the Web site directory
Using a Web site's file upload system to upload malicious content
Using a file upload system to replace key configuration files
Flooding a Web site using DoS attacks in username/passwords form
A brute-force attack attempts to crack a cryptographic key or password simply by guessing. It involves programs designed to guess every possible combination until the password or key is guessed correctly. Of course, the more complex a password is, the harder it is to crack and the less likely brute force will be successful. This is why choosing passwords that are difficult to guess is so critical.
For Web applications, the most common forms of brute-force attacks are launched against user logon credentials. Many users choose passwords that are easy to remember and they change them infrequently. A brute-force dictionary attack uses an exhaustive list of words attempting to guess at a password or username. This includes trying common misspellings of words, uppercase and lowercase words and guessing at common strategies such as replacing the capital letter "O" with a zero (0) and the number 1 with a lowercase letter "l". Although it may sound very time-consuming, a brute-force attacker can process millions of name and password combinations per second.
A successful brute-force attack may allow the intruder to assume the identity of the broken account and:
Access confidential and sensitive data intended to be protected behind user credentials.
Provide access to administrative areas of applications, Web servers, or operating systems. Once there, the intruder may have unobstructed access to change, modify, copy, or delete data and sensitive information.
Place malicious code, Trojan horses, worms, and other malicious code into Web servers or applications. Among the brute-force attack types that can be launched are:
Logon credentials—Today's users have username/password combinations for everything from social networking sites to online banking and system logons. Brute-force attacks can be launched at each of these areas.
Credit card information—Some hackers brute force credit card information. This includes getting the security CVV number on the back of a card.
Files and folders—Many files on a system are protected using a "security by obscurity" principle, meaning the directory location is secret. Brute-force attacks that keep guessing at directory locations can eventually find them. The directories may hold sensitive data such as usernames and passwords or company information.
Note
One way to verify if a system is attacked by a brute-force attack is to check the log files periodically. A log file registering numerous logon failures may be an indication of a brute-force attack.
These are a sample of the types of brute-force attacks that can be launched. Essentially, anywhere credentials or user input is required, an attacker may use a brute-force attack.
Account lockout policies are used to configure how a system will respond to invalid logon attempts. All operating systems use some sort of authentication lockout procedures. In this section, you will review those available in Microsoft Windows Vista and Windows 7 for editions intended for organizational or enterprise use.
The danger of not having an account lockout policy in place is that it is possible for intruders to keep guessing usernames and passwords in an attempt to gain access to the system. An example is programs that run through a dictionary of words and characters trying to access an account. To prevent these brute-force attacks, you can use account lockout policies that shut the account down after a preset failed number of logon attempts.
There are many options for configuring account lockout options. Table 7-1 summarizes account lockout options in Windows operating systems.
Establishing a lockout policy is designed to secure the authentication process. Without such a strategy in place, the authentication process is easily compromised.
Table 7-1. Account lockout options in Windows.
ACCOUNT LOCKOUT POLICY | DESCRIPTION |
|---|---|
Account lockout duration | The lockout duration defines the number of minutes that an account remains locked out. Once the time has been exceeded, the account will automatically be enabled. The available range is 0 to 99,999 minutes. You can also specify that a locked-out account will remain locked out until an administrator explicitly unlocks it by setting the value to 0. The default is 30 minutes when the account lockout threshold is set to 1 or higher. |
Account lockout threshold | The threshold policy sets the number of failed logon attempts that must be exceeded before a user's account is locked out. The value can be between 1 and 999 failed logon attempts. The default is 0. |
Reset account lockout counter after | This policy specifies how long the counter will remember unsuccessful logon attempts. The available range is 1 minute to 99,999 minutes. The default setting is None; this policy is enabled only if the account lockout threshold policy is set to something other than 0. |
Passwords represent one of the biggest security concerns for both networks and Web site access. Once a password is compromised, access to the system is an easy logon process. To help make system passwords more secure, password policies are developed and enforced. Table 7-2 shows some of the password policies that may be used.
For many environments, the default password policy settings are sufficient. For those systems that require additional security, configuring the password policy is one of the first steps you should take in securing the system.
A buffer overflow occurs in an application when more information is stored in the buffer than the space reserved for it. A "buffer" refers to a temporary data storage area. When a buffer's storage area is exceeded, it can cause data in other areas to be overwritten, which can corrupt stored information. Buffer overflows have been a form of attack since the 1980s and are a result of application programming that fails to test and consider the potential problems with buffer flow attacks.
An attacker can launch a buffer overflow attack to:
Crash an application or process.
Modify the application or process.
Take ownership of an application or process.
In a common form of buffer overflow attacks, an interactive session or shell is initiated on the victim's machine. If the program being exploited runs with a high privilege level (such as root for UNIX/Linux or Administrator for Windows), the attacker gets elevated privileges to that machine.
Buffer overflows are not easy to protect against. In fact, most of us must rely on well-written code to prevent buffer attacks. Unfortunately, many programs that are tested thoroughly still have potential buffer flow security flaws. For many, to prevent buffer overflow security risks, traditional security mechanisms are employed, including maintaining up-to-date service packs and patches for all software applications.
Content spoofing involves creating a fake Web site or Web application and fooling victims into thinking it is a legitimate one. One of the goals of content spoofing is to lure victims to an authentic-looking but illegitimate Web site. The next step is to steal logon credentials, credit card information, or other forms of personal data.
Note
Content spoofing attacks combine with phishing attacks to lure victims to a site. Mitigation strategies employ the same strategies as those used with phishing.
Content spoofing tactics often include spam e-mail links, forum links, and chat room links. These links have the same goal, which is to lure victims to the fake Web site. At a content-spoofing site, if someone enters personal data, the attacker can read and use it.
Table 7-2. Password policies.
DESCRIPTION | |
|---|---|
Enforce password history | The password history policy sets the number of unique new passwords that must be associated with a user account before an old password can be reused. This prevents the same password from being used over and over, increasing the difficulty in obtaining the password. The value must be between 0 and 24 passwords. |
The maximum password age sets the number of days that a password can be used before the system requires the user to change it. You can set passwords to expire after a number of days between 1 and 999, or you can specify that passwords never expire by setting the number of days to 0. The default setting is 42 days. | |
The minimum password age sets the number of days that a password must be used before the user can change it. You can set a value between 1 and 998 days, or you can allow changes immediately by setting the number of days to 0. The default setting is 0. | |
Minimum password length | Passwords using more characters are typically more secure than those using fewer characters. The minimum password length allows you to set the least number of characters that a password for a user account may contain. You can set a value between 1 and 14 characters, or you can establish that no password is required by setting the number of characters to 0. |
Passwords must meet complexity requirements | Many users choose a password based on the ease of remembering the password. This policy ensures that the passwords chosen meet a certain complexity requirement making them harder to guess. |
Store passwords using reversible encryption for all users in the domain | This password policy supports applications that use protocols requiring knowledge of the user's password for authentication purposes. Storing passwords using reversible encryption is essentially the same as storing plaintext versions of the passwords. Don't enable this policy unless application requirements outweigh the need to protect password information. |
Many content spoofing attacks today use phishing as a mechanism to lure victims to an illegitimate site. For example, a recent e-mail campaign alerted e-mail recipients that a Christmas package was due to arrive and needed verification for delivery. The e-mail provided a link that, when clicked, took users to a legitimate-looking delivery site. Users were asked for an address, credit card information, and other personal data. These forms of attack are very effective, particularly when the original phishing e-mail appears to come from a trusted source.
In computing terms, a "session" refers to an information exchange between two or more computing devices. The session ID identifies previous users to a Web site and stores user-specific information about a session. Credential/session prediction is an attack that involves impersonating the Web site user and then using the rights and privileges of that user on the site. Specifically, the session prediction attack tries to obtain the session ID of an authorized user. For example, if a Web site creates sessions using easily guessable methods, such as adding the date plus the first five characters of the last name, an attacker could easily generate valid session IDs while posing as a real user.
Note
One issue with session IDs is insufficient expiration time. If a session stays active too long without timing out and requiring renewed authentication, an attacker can reuse an old session and session ID. To mitigate, always log off Web sites when you're finished.
Session IDs allow for user tracking on a Web site, including automatic authentication for future visits. This means users do not have to reenter data and authentication credentials each time they log onto a Web site. If the session ID is compromised, the attacker can hijack a session or replay a session. In either case, your credentials are being used. It is impossible for the Web site to tell if a trusted source or an attacker is using the credentials.
The term "session hijacking" refers to an attacker obtaining a valid session ID and then using it to access the victim's sessions. With the session ID, the attacker can access the session and Web communication and pose as the owner of the session ID. Session IDs are usually kept in cookies or form fields on the client system.
The main purpose of the cross-site scripting (XSS) attack is to obtain client browser cookies, security tokens, or any other personal information that can identify the client with the Web site and the Web server. With client credentials in hand, the attacker can assume the identity of the client and impersonate the user's interaction with the site. Now the attacker has access to all client interaction information including credit card information, addresses and passwords.
The XSS attack takes advantage of the vulnerabilities of a Web site, but the Web site itself is not harmed. The Web site is not the target of the attack. The intent is to attack the client browser, gather personal information by exploiting the Web server, and impersonate the user. The target is the client browser's cookies and personal information. The goal is to steal the identity of the cookie's owner.
Note
XSS is covered in greater detail in Chapter 6 in a discussion of the Open Web Application Security Project (OWASP).
Similar to a form of XSS attack, a cross-site request forgery (CSRF) attack creates links that take the visitor to a malicious destination uniform resource locator (URL). While XSS attacks exploit the trust that a user has for a site, CSRF attacks exploit the trust a Web site has for the user's browser. This can occur because once a visitor is authenticated and logged onto a particular Web site, that site trusts all requests from the browser. This trust is exploited with a CSRF attack.
After a visitor logs onto a Web site, the site issues authentication tokens within a cookie to the browser. Each subsequent request to send the cookie back to the site lets the site know you are authorized to take whatever action is taken. The site has absolute trust in the browser's credentials. If the visitor were to leave that site and go to the malicious site, the previous session may still be valid and authenticated. Here is where the attack happens. The attacker can now use the open session to access the previous site with already-approved authentication.
Note
Cross-site forgery is covered in greater detail in Chapter 6 along with XSS attacks.
Denials of service (DoS) attacks are designed to prevent legitimate use of a network service. Attackers achieve this by flooding a network or Web application with more traffic or data than it can handle. This type of attack is not designed to gain network access but rather to overwhelm a system and tie up its resources to the point that it becomes unusable. A DoS attack can prevent a service from being available to users by completely overwhelming the application or system. For example, some attackers flood a Web server with so many requests that it cannot continue to function as a Web server. DoS attacks are often difficult to trace. Because attackers have no need to receive information back, it is common to spoof or fake the source of the attack. This makes it more difficult to trace the origin.
The impact of DoS attacks include:
Saturating network resources, which then render that service unusable
Flooding the network media, which prevents communication between computers on the network
Causing significant downtime because users are unable to access required services
Creating huge financial losses for an organization due to network and service downtime
Note
More information on DoS and distributed DoS (DDoS) attacks can be found in Chapter 5.
A fingerprinting attack is used to gather as much information as possible about a target system, including the operating system used, Web application and version in use, database information, and network architecture. Gathering this type of information is critical for attackers because many of the attacks they use, whether XSS, buffer overflows or others, are dependent upon certain versions of Web applications or software. This makes it important for administrators to ensure that fingerprinting attacks cannot pinpoint potentially revealing information to an attacker.
With fingerprinting, the attacker may be looking for the following information:
From a security standpoint, any information that an attacker can get is too much information. If your company has a Web presence, it is likely that the firewalls permit Hypertext Transfer Protocol (HTTP) traffic over port 80. However, the firewalls don't need to permit, for example, a request to resolve a Domain Name System (DNS) request for a resource for internal use only, especially if the request originates from outside. Web servers can leak information through this port in HTTP that an attacker can use.
Format strings and buffer overflow attacks share a similarity in that both attacks exploit user input. With a format string attack, user input is interpreted as a command by the application. Although both the buffer overflow and the format string attack take advantage of available user input, format string attacks are successful because user input is not validated. Buffer overflow attacks are successful because the buffer boundaries are exploited.
Unfiltered user input employs format string parameters found in programming languages such as C and C+. The attack occurs when a malicious user uses string input for specific C or C+ functions. Common string function commands include:
Fprint—Prints to a file
Sprintf—Prints to a string
Printf—Output of a formatted string
There are many different command string functions. The following is a list of parameters that can be used with these commands to complete the attack:
%s—Reads character strings from the process' memory%n—Writes an integer to locations in the process' memory%x—Reads data from the stack

If the input string is entered with a valid parameter, the attacker may be able to:
Run commands on the server.
Read information within the stack.
Cause segmentation faults and/or software crashes.
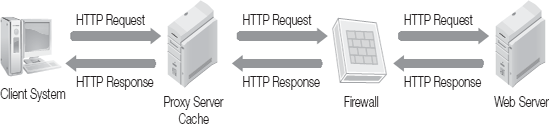
HTTP is the protocol used for transferring documents over the World Wide Web. HTTP works on a client/server model with the client system requesting information and resources from a Web server. This process is shown in Figure 7-1.
Figure 7-1 shows the request and response nature of the HTTP communication. However in real-world application, the client usually does not communicate directly with the Web server. Rather, the communication goes through intermediary points such as firewalls and proxy servers. Figure 7-2 shows the HTTP request traveling through intermediary points.
There are a number of intermediary points through which the HTTP request may travel, including:
Local browser cache
Proxy server (onsite)
Intrusion detection system (IDS)
Filtering firewall
Web application firewall
DMZ
This is a specialized attack. The attacker needs familiarity with the target Web application and the end-user agent or browser. As the name implies, the idea of the attack is in splitting something. The split object is the HTTP header or an error message sent back as a response. This relies on two criteria to be successful. First, a Web application must be vulnerable to the attack. Second, the attacker sends a specially formed HTTP request that makes the application return what is interpreted as two responses.
The attack is very similar to the HTTP request splitting attack. The attacker achieves the split by sending the carriage return (CR) and linefeed (LF) characters. Neither character actually shows up onscreen. However, when encoded within a string of information, the result can cause unintended consequences.
Note
Sending a carriage return (CR) or linefeed (LF) character is essentially the same as pressing the Enter key on a keyboard.
The threat created by this attack is the use of unexpected carriage returns. If successful, the attacker can interact directly with the Web server, instead of the application layer. The way to mitigate the risk is to screen for CR and LF characters at the application layer.
This attack is effective whenever Web proxies or Web application firewalls are in use between a Web server and the end user. In other words, this attack is used when one server handles an HTTP request and then passes it on to another Web server. Requests by proxies are often parsed in different ways than the intended destination Web server. The proxy may parse only part of the request, if not just enough to know where it's intended to go. The request may include malicious commands or special characters to obtain new, sensitive information. When this attack proves successful, an attacker will leverage it to launch more malicious attacks.
The attack is very similar to the HTTP request smuggling attack. The effect is similar to an HTTP response splitting attack. In an HTTP request splitting attack, the object being split is the initial HTTP request. The attacker forms a malicious request. This request is interpreted by most browsers as a single request. However, the Web server receiving the special request interprets it as two requests. The request is split by inserting special characters within the body of the primary request. The effectiveness of the attack depends on whether the Web application parses requests for CR or LF characters. If successful, the attacker can take advantage of the vulnerability to send longer lasting attacks.
An "integer" is a whole number, one that is not a fraction. Integers may be 0, 1, 2, 3, and so on, and their negative equivalents -0,-1, -2, -3, and so on. Integer-related vulnerabilities typically arise when an application performs some arithmetic on an integer and exceeds the integer's intended size. For example, in computing, an 8-bit integer is often used. The 8-bit integer has a value of -128 to 127. The integer overflow attack pushes the integer beyond this boundary. If 1 is added to 127, an integer overflow occurs.
The result of exceeding the integer boundary can lead to undefined and unpredictable outcomes such as crashes. Additionally, integer overflows can result in buffer overflows and can be used to execute malicious code.
The Lightweight Directory Access Protocol (LDAP) is a protocol that provides a mechanism to access and query directory services systems. Directory services include systems such as Novell Directory Services (NDS) and Microsoft Active Directory, database servers, Web servers, and Web application servers. Although LDAP supports command-line queries executed directly against the directory database, most LDAP interactions are via utilities such as an authentication program (network logon) or locating a resource in the directory through a search utility.
LDAP injection is an attack technique that exploits Web sites that allow LDAP statements from supplied input. If an attacker modifies an LDAP input statement, the attacker may be able to gain database access with full privileged permissions. LDAP injection vulnerability occurs due to weak input validation prior to processing LDAP statements.
Preventing LDAP injection requires monitoring and allowing only valid input for LDAP queries. This means utilizing both client-side and server-side validation to ensure the authenticity of the input. This validation should ensure that only authentic input is accepted.
Another form of input validation attack is the mail command injection attack. The mail command injection is designed to attack mail servers and applications that use the IMAP and SMTP protocols. The Simple Mail Transfer Protocol (SMTP) protocol defines how mail messages are sent between hosts. SMTP uses Transmission Control Protocol (TCP) connections to guarantee error-free delivery of messages. SMTP is not overly sophisticated, and it requires that the destination host always be available. For this reason, mail systems spool incoming mail so that users can read it later. Internet Message Access Protocol (IMAP) is a Transmission Control Protocol/Internet Protocol (TCP/IP) protocol designed for downloading, or pulling, e-mail from a mail server. IMAP is used because although the mail is transported around the network via SMTP, users cannot always read mail immediately, so it must be stored in a central location. From this location, it needs to be downloaded, which is what IMAP allows you to do.
Note
SMTP and IMAP injection vulnerabilities are often exploited by e-mail spammers who obtain e-mail addresses and generate large numbers of nuisance e-mail messages.
Many Web sites and Web applications allow users to submit forms, feedback, or other content using e-mail and the SMTP protocol. If attackers are able to place malicious input into the SMTP or IMAP conversations, they may be able to take control of the messages being used by an application.
SMTP injection vulnerabilities are mitigated by implementing strict validation of any user-supplied data that is passed to an e-mail server and in SMTP and IMAP conversations.
This attack is successful in part because of the diverse languages used for creating Web sites. For many Web sites, a Web page is created using a high-level language such as PHP, ASP, or Java. Sometimes the Web page processes information at a lower level language such as C or C++. A subtle difference between the former and latter languages is how they handle null byte characters. Examples of null byte characters are %00 or 0×00 in hexadecimal.
In the case of high-level languages, a null-byte character does not affect processing of information. In fact, with input validation, the null byte character is likely ignored. However, the lower, system-level languages act differently. They interpret a null byte character as the end of a string of information. This abruptly ends processing. How this affects the system can be unique per Web page. This abrupt end causes unknown behavior to the Web site and perhaps even the system. Even worse, whatever happens will be run with system-level privileges.
Operating system commanding is an attack aimed directly at a system's operating system. In this attack, user input launches unauthorized commands on the operating system, including those on a Web or database server. In a successful OS commanding attack, the attacker can execute commands on the server through a browser or other input mechanisms. With OS commanding, executed commands by an attacker will run with the same privileges of the component that executed the command, (e.g., database server, Web application server, Web server, wrapper, application). Because the commands are often executed with elevated privileges, an attacker can gain access or damage parts that otherwise are unreachable (e.g., the operating system directories and files).
As with other forms of input attacks, the attack can be minimized by restricting character input, restricting forms of input, using permissions to lock down access and disabling unused commands. To help protect operating systems and network servers, security systems must be in place that maintain tight controls over acceptable user input.
Path traversal attacks can occur on any server or system where files are stored. In a path traversal attack, the attacker attempts to circumvent acceptable file and directory areas to access files, directories, and data located elsewhere on the server. This can be done by changing the URL address to point to other areas on the server.
Note
A common path traversal attack uses the ../ syntax sequence to attempt to locate restricted areas on a server.
Many attackers know the names and default locations of key files and directories in various applications and Web servers. Knowing the locations allows attackers to try a traversal attack directly to where they want to go. In a common path traversal attack, the attacker uses ../ to navigate the directory tree to access files in other directories.
Similar to the path traversal is the predictable resource location attack. Every system has numerous default system files and directories that are often forgotten but may hold sensitive data. Using a brute-force attack or even an educated guess based on default file locations, the attacker can potentially gain access to unauthorized areas.
Every operating system has default resource and system directories and files, which may include backup files and folders, log files, temporary files, download files, and update files. Any and all of these file and folder locations may contain information about network resources, Web applications, network topology, passwords, and sensitive data. Much of this information can be used to launch another attack and enable unauthorized access to sensitive locations. There are several predictable resource location attacks. The syntax to access them looks similar to the following:
/backup//logs//system//admin//temp//logs/
Preventing path traversal and predictable resource location attacks may involve removing old files and folders that contain sensitive data, securing files and folders that contain sensitive data, controlling user input, and establishing security filtering software that monitors access to files and folders.
With injection attacks, attackers want to place their code and input on a target system. This is the intent of the remote file inclusion (RFI) attack. RFI attacks commonly attempt to take advantage of weaknesses in the PHP programming language. The PHP language is a scripting language commonly used to create dynamic Web pages. If attackers are successful in injecting files and code into a PHP-created Web site, they can access anything on that site, such as the database, passwords, and credit card information.
Once the attackers inject code, they can run malicious code on the target system. The results of an RFI attack range from errors to system crashes to complete system compromise.

Routing detour attacks are a form of man-in-the-middle attack in which an intermediary attacker re-routes data to an alternate location. Routing is an important concept for networks and the Internet. All online transactions are routed to a destination based on information within the HTTP header. A message traverses the Internet from one router to the next until it finally reaches its destination.
The routing system used on the Internet can be a security threat in that an attacker may be able to re-route data away from its intended destination to one the attacker chooses. In some cases, the data can be routed and then re-routed back to the original destination and the theft goes completely unnoticed. This can be particularly damaging if the detoured data is sensitive, such as banking information or passwords. Figure 7-3 shows how a routing detour may occur.
There are many types of session-based attacks; most are a form of impersonation. Impersonation refers to an attacker's attempt to use the session credentials of a valid user. A session fixation attack allows an attacker to steal and use a valid user session. A "session" is a communication between systems on a network. This attack can be successful when an authenticated user's session ID does not immediately expire, allowing an attacker to capture and use an existent session ID. During the attack, the attacker entices a user to authenticate to a Web server then hijacks the valid and trusted session ID.
There are at least three ways in which an attacker can obtain a valid session identifier:
Prediction—With prediction attacks, the attacker simply guesses at the session identifier often using a brute-force attack.
Capture —Capturing a valid session identifier may involve obtaining a cookie that is used to store the session identifier or exploiting a browser's vulnerability.
Fixation—Session fixation is an attack in which the victim is tricked into using a session identifier chosen by the attacker.
Figure 7-4 shows how this attack may occur.
Simple Object Access Protocol (SOAP) is a general method for communicating Extensible Markup Language (XML) over networks. XML is a set of rules for encoding documents electronically. XML was chosen as the standard message format because of its widespread use and open source development. Additionally, a wide variety of freely available tools significantly eases the transition to a SOAP-based implementation. SOAP is commonly used for browser-accessed Web applications and in communications occurring between back-end application components.
Note
Simple Object Access Protocol (SOAP) is an XML-based protocol that lets applications exchange information commonly over HTTP.
SOAP communications may be exploited using user-injected code similar to other injection attacks. XML syntax using characters such as <> and / can be inserted into SOAP communications, allowing the attacker to interfere with the data message.

Server-side include (SSI) injection is an injection attack that occurs on the server and not on the client system. In an SSI attack, malicious code is placed in a Web application, which is then stored on the server. When the Web application is executed locally on the Web server, the malicious code carries out its function. The SSI injection attack is successful when the Web application is ineffective in filtering user-supplied input.
To defend against SSI injection attacks, an application must be configured to assume that all input is potentially harmful and take steps necessary to secure and filter all user input. This includes filtering the types and numbers of characters that are accepted by Web servers from users.
Most Web applications use a database to store sensitive client or other information. This may include:
User accounts and personal data
User passwords
Client financial information
Credit card information
The Structured Query Language (SQL) is used to communicate with these databases and can be used to add content, modify content, update, and delete information from the database. Sometimes, if SQL is not properly deployed, conFIGUREd or updated, attackers may be able to exploit SQL.
Web applications use SQL statements that incorporate user-supplied data. If this user-supplied data is unsafe and unfiltered, the Web application may be vulnerable to an SQL injection attack. A successful attack will allow the attacker to access, read, delete, and modify the information within the database and even take control of the server on which the database is operating.
URL redirecting points a Web page to another URL of your choice. That is, a visitor clicks on one URL and is then taken to another. URL redirecting is commonly done for a variety of reasons. For example, if a company changes its URL, a redirector takes customers and clients to the new site automatically. URL redirecting may be used for Web server load balancing, to link updates, make navigation easier and more. In itself, URL redirecting is not a security risk.
URL redirectors can be misused to redirect visitors to a malicious site. For example, a normal redirection link such as:
http://www.homepagexyz.com/login.php?redirect=
http://www.homepagexyz.com/home.php
This is a simple URL redirection. However, consider a slight variation. In the following sample:
http://www.homepagexyz.com/login.php?redirect=
may take you to:
http://www.h0mepagexyz.com/home.php
In the second example, the letter "o" has been replaced with the number "0", and the URL redirection may point to a malicious site. The malicious site may look authentic but will in fact be an imposter site. This very simple example shows how redirecting may catch users off guard.
As previously mentioned, Web applications use databases to store and access information. Some of these databases store and organize data using the XML language. The XML Path (XPath) language is used for navigating XML documents and for retrieving data from within them. User input and queries are used with XPath to access the XML information. With XPath injection attacks, attackers are able to inject data into an application so that it executes user-controlled XPath queries. When successfully exploited, this vulnerability may allow an attacker to bypass authentication mechanisms and access XML information without proper authorization.
As with other injection attacks, input validation is an important part of the defense strategy. Input validation helps to ensure that malicious input is filtered out and does not execute and enable access to the XML database. Detailed input validation strategies include sanitization, accepting known good input only, and filtering.
Note
Strategies to ensure proper input validation are covered later in this chapter.
DoS attacks are commonly used to overwhelm network resources, hardware, Web applications, and more. DoS attacks are some of the oldest forms of attack, dating to the mid-1990s. The XML attribute blowup is a form of DoS attack aimed at exhausting the system's resources.
XML DoS attacks are extremely asymmetric: To deliver the attack payload, an attacker needs to spend only a fraction of the processing power or bandwidth that the victim must spend to handle the payload. Worse, DoS vulnerabilities in code that processes XML are also extremely widespread. Even if you're using thoroughly tested parsers like those found in the Microsoft .NET Framework System.Xml classes, your code can still be vulnerable unless you take steps to protect it.
This attack relies on a Web application that employs an XML parser to parse untrusted data from the end user. The application's parser runs at system level privileges and does not filter what was provided to it before running. For example, an application expects XML structured data, but an attacker instead provides a command and path to a desired file on the local Web server. The application, instead of returning XML output, returns the password file on the local Web server.
The paths to many system files are known because a well-known structure is created upon installation. Some of those files could provide sensitive knowledge of that system, even revealing vulnerabilities. Further, some files specific to a certain user may also be revealed.
This attack is essentially a DoS attack. The attacker takes advantage of the ability to create XML-related macros, also called "entities." Normally, a created entity is resolved by an XML parser. These entities are created with care that they do not loop endlessly. An attacker, however, may create sets of entities that recursively try to resolve themselves. This exercise would quickly exhaust a system's resources. The result would be a denial of normal operation and availability.
The XML injection attack takes advantage of the trusting nature of an XML application. Success of this attack follows the "garbage in, garbage out" rule of data processing. If unintended or malicious XML content is fed into a XML message, the result will likely also be malicious. The challenge for the attacker is gaining the intended effect. For example, imagine that an organization's XML application expects specific content to produce a letter to customers. The attacker instead sends content that the application successfully utilizes to create the customer letter. The letter's meaning is changed for the worst. You can imagine the customer's response when the organization claims the letters are all created automatically.
An SQL injection attack hijacks an SQL query, and an XQuery injection attack does the same for XQuery commands. In both cases, an attacker attempts to send data which may be acceptable to start, but is malformed to interrupt a query. The ending portion of the sent data will be malicious, sending a command or trying to elicit information or queries. All these are unauthorized to the attacker, but would be executed by the system with its own privileges, on behalf of the attacker.
Note
An XQuery injection attack is the same as the SQL injection attack in concept and method. The only difference is the setting, similar to a car hijacking versus a plane hijacking.
As shown in this section, there are numerous attacks that can be launched against Web server and Web applications.
Many organizations are unaware of the types and large number of attacks that can be launched against their corporate sites. Administrators must be prepared to identify and protect against the variety of attacks that cyber criminals use. WASC highlights 15 well-known Web site attacks and identifies what they are designed to do. This section looks at the various Web attacks and how you can mitigate them.
Applications can be one of the more difficult elements to secure on a network due to their complexity and their ability to accept user input. Application misconfiguration attacks focus on identifying and exploiting weaknesses found within Web applications. Unfortunately, many Web applications have vulnerabilities out of the box and additional features enabled by default. This may mean hidden accounts, open security features, and more. The default configuration of most applications is typically not sufficient in terms of security. Application misconfigurations are common, and so too are the attacks aimed at exploiting them.
Key to managing application misconfigurations is application hardening. Application hardening is the process of securing applications in use on a network. This involves clearly understanding how applications operate to ensure no unused or unsecured features are being used. For example, in the case of operating systems, it may be necessary to block or disable any unused services or ports. Additionally, it is necessary to ensure that all applications are updated with the latest service pack or patch.
Note
Many administrators assume that all applications are flawed and have inherent security risks. This assumption is a good way to approach network application security.
Web sites have a directory structure. A URL takes you to a specific page within the directory index of the Web site. In normal operation, a user enters a URL address such as http://www.xyz.com/pagel/ and the page is retrieved and presented to the user. However, many sites use a feature known as automatic directory listing. Automatic directory listing identifies all of the files within a given directory if the base file is not found. The base files refer to such files as index.html, default.htm, index.php, and so on.
When these files are not found, a directory listing is sent to the client system. When a list is presented to the client, it may contain directories or files that were never intended to be seen or accessed. Directory indexing is often harmless, but revealing these files provides attackers with information.
Table 7-3. NTFS permissions.
Some of the files that may be included in the directory listing include:
Backup files
Temporary files
Hidden files
User accounts
Configuration files
Administrator documents
Personal client folders
Effectively managing files and folders on an operating system will certainly involve assigning and managing the permissions required to access them. Permissions allow administrators to decide who can and cannot access particular files and folders and what they can do with them when they are accessed. If your system is conFIGUREd with NTFS partitions, you have the option of controlling file and folder access on a per-user or per-group basis. If you are using a system with FAT partitions, you are out of luck. FAT partitions do not offer any local security functionality.
In a Windows environment, there are six basic NTFS permissions available: Full Control, Modify, Read & Execute, Read, Write, and List Folder Contents. Table 7-3 describes each of these.
Table 7-4. Advanced NTFS file permissions.
PERMISSION | DESCRIPTION |
|---|---|
Traverse Folder/Execute File | Allows or denies permission to move through folders. Traverse Folder takes effect only when the group or user is not granted the Bypass Traverse Checking user right in the Group Policy snap-in. Execute File allows or denies running program files. |
List Folder/Read Data | List Folder allows or denies viewing file names and subfolder names within the folder. Read Data applies to the files only and allows or denies viewing the data in the files. |
Read Attributes | Allows or denies the ability to view the attributes of files or folders. |
Read Extended Attributes | Allows or denies the ability to view the extended attributes of files or folders. |
Create Files/Write Data | Create Files allows or denies creating files within a folder. Write Data allows or denies making changes to a file and overwriting existing content. |
Create Folders/Append Data | Create Folders allows or denies permission to create folders within folders. Append Data allows or denies the ability to make changes to the end of files. |
Write Attributes | Allows or denies the ability to change the attributes of files or folders. |
Write Extended Attributes | Allows or denies the ability to change the extended attributes of files or folders. |
Delete | Allows or denies permission to delete file or folders. |
Read Permissions | Allows or denies permission to read files or folders. |
Change Permissions | Allows or denies the ability to change permissions of the file or folder, such as Full Control, Read, and Write. |
Take Ownership | Allows or denies the ability to take ownership of files or folders. |
Delete Subfolders and Files | Allows or denies the ability to delete subfolders and files. |
The six basic NTFS permissions discussed above are comprised of several more specific NTFS permissions. Knowing the individual NTFS permissions allows an administrator to fine-tune permission settings and give more control over what users can and cannot access. Table 7-4 shows the advanced NTFS file permission.
As mentioned earlier in this chapter, many applications rely on external input from sources such as end users and browsers. External input provides a potential security risk as attackers aim to exploit input as part of an attack. In security terms, input handling refers to the validation, sanitization, storage, and filtering of user input. Most security experts suggest that it is a best practice to treat all user input as potentially harmful. Applications that accept user input are potentially vulnerable to injection attacks, overflow attacks, DoS attacks, and others.
When handling user input, there are a few security approaches to consider:
Sanitization—When user input is sanitized, it is inspected for potentially harmful code and modified according to predetermined guidelines. Sanitization often involves identifying and disallowing specific characters and syntax sequences.
Reject known bad input—Certain syntax and characters are banned from input. If they show up in a query, the entire input stream is rejected. A catalog of known, banned input is referenced and updated as needed. Rejecting known bad input can be effective; however, attackers are quick to find new and improved ways to exploit Web sites. This means that a blacklist strategy may always be one step behind.
Accept only known good input—An opposite approach to the blacklist is a whitelist strategy for managing user input. A whitelist approach allows only code that matches a set of acceptable inputs. All other input is blocked. This can be a highly effective way to manage user input as the administrator dictates what input is and is not allowed.
Output handling refers to the way applications control their output data. Output data from the application may take the form of logging, printing, coding, error messages, or raw data to be passed on to another application. The risks of improper output handling occur when the application produces unintended or sensitive information, such as overly informative error messages. Another example would be if a malicious user purposefully provoked the application to reveal sensitive information.
Information leakage occurs when a Web site or Web application discloses sensitive information unknowingly. For example, error messages can reveal information about the server, the application, and network topology that an attacker can use to exploit the system. Information leakage can come from a variety of sources, such as stolen laptops, unsecured backups, log files, error messages, employee e-mails, HTTP headers, and unencrypted data transfers. Any data leakage can assist an attacker in isolating and planning an attack.
Note
Information leakage is covered in detail in Chapter 6.
There are many strategies to help reduce the risk of data leakage. These include:
End-user education—Inform network users of the threats and impact of data leakage and how they can help prevent the problem.
Filtering systems—Use filtering systems to help identify information heading into and out of the network and network servers.
Authorization—Use permission to help secure local files, folders, and directories. Apply the principle of least privilege to help reduce who has access to key areas of the server.
Monitoring error messages—Check whether error massages, which seem cryptic and unreadable, actually give out potentially sensitive information about the network.
Policies and procedures—Develop strong network-wide policies and procedures to govern how data is to be handled and stored. This includes error messages and log files.
Note
When it comes to authorization, the concept of least privilege is often applied. The principle of least privilege refers to providing users with as few privileges as possible, just enough to fulfill their network needs. It is a security measure that ensures users are not granted more permissions than needed.
Note
How well is your site being indexed? There are many reasons why a site may not be indexed properly. To test indexing in Google, type the following in the Google search bar: Site:yourdomainname.com
The results from this query will display the index results from your domain. This site search works equally well for all top-level domains, such as .edu, .net, and .org.
All Web pages must be indexed by search engines to be listed in search results. Indexing is an automatic process in which software programs known as spiders or bots examine Web sites, collecting data and analyzing the Web sites' keywords. The results are stored and indexed in the search engine's database. When a user performs a search, the search engine looks through the database and returns the results.
In the process of indexing, the spiders and bots may collect sensitive or unwanted information. This indexed information may be retrieved from the index database by an attacker who uses a series of queries to the search engine.
Many Web applications require manual user input, such as filling out various Web-based user forms. Anti-automation attacks occur when processes that should be done manually are automated by the attacker. Automated attacks fill out forms and overload the system or take advantage of vulnerabilities. An example is an automated application that fills out forms for new accounts or continually posts to message boards.

Anti-automation strategies are used to prevent these forms of attack. CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) refers to mechanisms used to protect against automated attacks. The function of CAPTCHA is to provide a challenge/response mechanism to help ensure that a form is being filled out by a human and not an automated process. A common type of CAPTCHA requires users to input letters or number combinations from a distorted image on the screen. Others strategies may be a simple math question, a logical question, or a required response to an audio message. Figure 7-5 shows a distorted text CAPTCHA.
For a client to gain access to a network, network resources, or many Web sites, both authentication and authorization are required. "Authentication" is any process that verifies identity. This usually involves a username and password but can include any other method of demonstrating identity, such as a smart card, biometrics, voice recognition, fingerprints, and codes. Authentication is a significant consideration for network and system security and one that administrators battle with regularly.
'Authorization" is finding out if the person, once identified and authenticated, is allowed access to a particular resource. This is usually determined by finding out if the person is a part of a group that provides the correct permissions or has a particular level of security clearance.
Insufficient authentication occurs when a Web site permits an attacker to access sensitive content or functionality without having to properly authenticate. Web-based administration tools are a good example of Web sites providing access to sensitive functionality. Depending on the specific online resource, these Web applications should not be directly accessible without requiring users to properly verify their identity.
In Web application terms, insufficient authorization happens when the application does not adequately ensure that authorization polices are being used and enforced. This means that after users are authenticated, they are limited to access based on their authorized privileges.
Many applications grant different application functionality to different users. The security trick is to balance the user permissions, granting enough access to use the application but not enough to allow access to protected areas.
Many Web applications and Web sites require password authentication. Unfortunately, passwords and usernames are often forgotten, and password recovery mechanisms are required. Typical password recovery requires users to provide secret information that only they should know, often in the form of a hint or response to a secret question that jogs the memory. The recovered username and password is sent to the user's registered e-mail address.
In many instances, the password recovery procedures are sufficient, but sometimes an attacker may pose as the one who forgot the password and recover it. With the username and password combination, the attacker then can lock out the legitimate user and use the account at will. In some cases, a legitimate user may not notice the attack for months, and the attacker has all that time to access the resources as the legitimate user.
Note
When creating password and username combinations, do so with the assumption that an attacker may test password recovery mechanisms. If banking online or maintaining sensitive data on a Web site, verify that password recovery procedures are strong.
Each process used for a Web application follows certain logic and structure. For instance, a user purchasing an item from a Web site follows orderly steps. These include selecting the item, adding it to the shopping cart, entering credit card information, and so on. Web sites and Web applications often use similar logical flows to complete various transactions. Process validation refers to the correct sequence of steps in a transaction or online process. Insufficient process validation occurs when the attacker skips steps in the process and generates errors or unforeseen results.
Note
Insufficient process validation attacks are closely aligned with abuse of functionality attacks in which the function of the Web site is exploited.
Preventing insufficient process validation may involve carefully testing all Web processes in and out of their logical flow. Additionally, in development it is important to outline and create a logical process flow.
When devices on a network want to communicate, they do so by creating a session between them. This session is established using protocols and security mechanisms, and these security mechanisms set up trust in the session. Insufficient session expiration can occur when this trust is exploited by an attacker who captures the session ID and impersonates the valid user.
Many Web sites commonly use cookies to store session IDs, and once a cookie is captured, it may be used for an active session. One of the strategies used to prevent an attacker using a session ID is to end the session or logout. Once the session has expired, this attack cannot occur. Some applications do not have an expiration time set on a session and some have session expirations that are too long. Decreasing the session expiration time will help prevent an attacker from using an unexpired session.
Note
Any potential Web application with sensitive data should use a default timeout system that identifies when a site is inactive and automatically logs out. This helps prevent inadvertently leaving a session open to attack.
Insufficient transport layer protection refers to not encrypting or securing communications at the transport level of the Open Systems Interconnection reference model. In the communication between a Web server and a client, if the link is not secured, all information is sent back and forth in cleartext. This makes the communication susceptible to a man-in-the-middle attack in which the integrity and confidentiality of the data in transit is threatened.
Today, administrators use the Transport Layer Security (TLS) protocol and the Secure Sockets Layer (SSL) protocol. TLS is used to secure communications between client/server applications. When a server and client communicate, TLS ensures that no one can eavesdrop and intercept or otherwise tamper with the data message.
The SSL protocol is similar to the TLS protocol in that it is used to secure connection between a client and a server, over which any amount of data can be sent securely.
The servers used by an organization are critical for daily operations, providing key services to both internal and external users. This includes authentication services, proxy services, firewall, data repository Web, e-mail, file server management, and much more. Given their importance, it is little wonder that they are often the target of attack.
Perimeter defenses are an important part of server security, but firewalls, IDS, and IPS are only part of the solution. The proper administration of servers is critical to overall security. There are many forms of attacks that may be launched at servers including:
Exploiting bugs or security flaws in the operating system itself
DoS attacks aimed at overwhelming server resources
Injection attacks designed to corrupt the system or access sensitive data
Launching a man-in-the-middle attack aimed at intercepting unencrypted data
Malware attacks, including Trojan horses and viruses designed to disrupt server functioning
These are only some of the types of attacks that can be launched against network servers. Each attack has its own strategy to get to the server and, therefore, security strategies aim to reduce the threat.
Many of the attacks launched against a server can be mitigated using perimeter defense mechanisms while others need to be done directly on the server. One mitigation strategy that cannot be overlooked is addressing server misconfiguration errors.
All operating systems ship with a default configuration. That is, they are preconFIGUREd for use. Each organization has different security needs, however, making the default configuration ineffective for many organizations. Out-of-the-box server operating system software needs to be hardened and customized.
Strategies to properly configure the server include:
Keeping the server current with the latest service packs and patches
Hardening and configuring the operating system to address security adequately, potentially shutting down unused services and address ports. Installing and configuring additional security systems, such as filtering software and malware scanners
Using third-party companies to help test the server, looking for vulnerabilities
Researching common server threats and how to configure a server to address them
Regularly monitoring logs to search for potential breaches
Note
As previously mentioned, one common configuration problem is the handing of error messages. A server that is not configured to properly manage and store error messages can leak information.
It is important to remember that improperly configured server operating systems are a threat to an organization. Predictable accounts and passwords, limited local encryption, and known directory structures can lead to a breach in data confidentiality and potential server downtime.
This chapter provides descriptions of 34 potential attacks on a Web site. This is not an exhaustive list, but after reading through the 34 attacks, you should have a greater appreciation of the vast range of possible attacks. The attacks range in many factors, including technique, skill involved, and dependencies for success. Some attacks are the attacker's end goal, while others merely open a door for other purposes. Lastly, the attacks range in the damage that results if an attacker succeeds.
How do you mitigate all these attacks? With each attack comes certain ways to detect, prevent, or even reverse its effects. Further, new attacks are born continuously. Fortunately, you don't need to enact an exhaustive list of "just in case" controls for every new possible attack. The proper way to mitigate attack risks is to implement a best practices approach. This starts with being security conscious as early as possible. Your ability to protect against attacks is far more effective when security is considered from the earliest stages of design. The second step is knowing your infrastructure from each front-end Web application to each back-end database. You are more capable of understanding risks and how to mitigate them when you fully understand what is at risk. Lastly, being proactive is necessary to gaining support at all levels for seeing mitigation steps through to the end. You need senior management to appreciate the need for security. This comes primarily from exercising a proactive attitude. Let senior management witness how proactive you must be in order to sufficiently protect the Web sites. If security is not seen as important to you, how can it be perceived as important to those who may not understand it?
In addition to the 34 possible attacks, you read through 15 distinct weaknesses for a Web site. The 15 are mostly deficiencies in authorization, data handling, or configuration settings. Similar to using best practices for mitigating attacks, you must practice due diligence for mitigating weaknesses. Awareness of these vulnerabilities is key. If an administrator is not concerned about sufficient privileges, then weaknesses get introduced. If a developer is not attentive to secure coding practices, weaknesses get introduced. In all cases where weaknesses are introduced, the attacker potentially benefits. It's only a matter of time until a weakness is discovered.
Web applications and Web sites are the new security battleground. In this chapter, you learned that the WASC identifies 34 specific threats to Web application security. Administrators need to be aware of and prepare for each of these types of attacks. Many types of attacks employ user input to inject code or other malicious input into a server or application. User input validation is the best weapon for ensuring that only acceptable input is received.
You also learned that the WASC outlines 15 Web site weaknesses that may be exploited. Each of these threats has mitigation strategies to help reduce the vulnerability risk.
Application hardening
Automatic directory listing
Blacklist
Brute-force attack
Buffer overflow
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart)
Content spoofing
Cryptographic key
Extensible Markup Language (XML)
Impersonation
Indexing
Internet Message Access Protocol (IMAP)
Lightweight Directory Access Protocol (LDAP)
Malicious code
Man-in-the-middle attack
Output handling
Path traversal attack
Principle of least privilege
Process validation
Routing detour attack
Sanitization
Server-side include (SSI) injection
Session ID
Transport Layer Security (TLS)
Web Application Security Consortium (WASC)
Whitelist
XML Path (XPath) language
XPath injection attack
One way to verify if a system is attacked by a brute-force attack is to periodically check the log files.
True
False
Content spoofing tactics often include which of the following?
Spam e-mail links
Forum links
Chat room links
A and C only
All of the above
How do XSS attacks differ from CSRF attacks?
Which of the following attacks involve the use of CR and LF characters? (Select two.)
HTTP request smuggling
HTTP response smuggling
HTTP request splitting
HTTP response splitting
A common path traversal attack uses which syntax sequence to attempt to locate restricted areas on a server?
../
*.*/
CR
LF
During a session fixation attack, in which ways can an attacker obtain a valid session identifier? (Select three.)
Prediction
Capture
Fixation
Spoofing
Which attack allows the attacker to access, read, delete, and modify information held within a database and even take control of the server on which the database is operating?
Which of the following are actual XML-related attacks? (Select two.)
XML attribute blowup
XML internal entities
XML entity expression
XML injection
Which of the following are Web site weaknesses discussed in this chapter? (Select three.)
OS commanding
Improper file system permissions
Insufficient authentication
Fingerprinting
Server misconfiguration
Applications hardening is the process of securing applications in use on a network.
True
False
To avoid improper input handling, which approaches can you use when handling user input? (Select three.)
Stripping
Sanitization
Rejecting known bad input
Accepting only known good input
Which of the following is a strategy for reducing the risk of data leakage?
Sanitization
Strong firewall controls
Authorization
Encryption