
Chapter 7
Columnar Tables
“Go for the gold: better one great column and some undistinguished ones than constant mediocrity.”
Table of Contents Chapter 7 – Columnar Tables
– Columnar Tables have NO Primary Index
– NoPI Tables Spread rows across all-AMPs Evenly
– NoPI Tables used as Staging Tables for Data Loads
– What does a Columnar Table look like?
– Comparing Normal Table Vs Columnar Tables
– Example of Columnar CREATE Statement
– Columnar can move just One Container to Memory
– Containers on AMPs match up Perfectly to rebuild a Row
– Indexes can be used on Columns (Containers)
– Indexes can be used on Columns (Containers)
– Single-Column Vs Multi-Column Containers
– Comparing Normal Table Vs Columnar Tables
– Columnar Row Hybrid CREATE Statement
– AMP 1
– Review of Row Based Partition Primary Index (PPI)
– Visual of Row Partitioning (PPI Tables) by Month
– CREATE Statement for both Row and Column Partition
– Visual of Row Partitioning (PPI Tables)and Columnar
– How to Load into a Columnar Table
– Auto Compress in Columnar Tables
– Auto Compress Techniques in Columnar Tables
– When and When NOT to use Columnar Tables
– Watch the Video on the contest for the Teradata Search-off
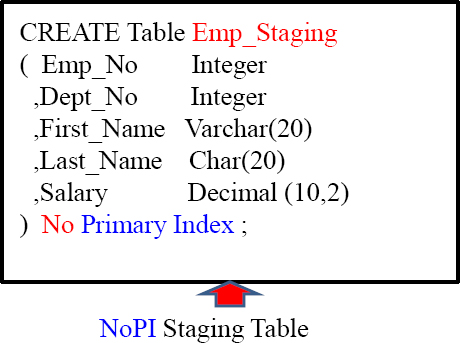
Columnar Tables have NO Primary Index
CREATE Table Employee_NoPI
(
Emp_No Integer
,Dept_No Integer
,First_Name Varchar(20)
,Last_Name Char(20)
,Salary Decimal (10,2)
)
No Primary Index ;
This table is called a No Primary Index (NoPI) Table!
Before discussing how to CREATE a Columnar table it is important that you understand that Teradata allows for NOPI tables, which distinctly state NO Primary Index.
This is NOT a NoPI Table
CREATE Table Employee_NoPI
(
Emp_No Integer
,Dept_No Integer
,First_Name Varchar(20)
,Last_Name Char(20)
,Salary Decimal (10,2)
) ;
This table is NOT a No Primary Index (NoPI) Table!
This will make the first column the Primary Index
and automatically make it Non-Unique (NUPI)
If you forget to put in a Primary Index Teradata thinks you made a mistake and it will make the first column a Non-Unique Primary Index. If you want a NoPI table you must state NO PRIMARY INDEX.
NoPI Tables Spread rows across all-AMPs Evenly


The purpose of a NoPI table is to spread the rows evenly across the AMPs. This is why a NoPI table is often used as a staging table. The concept is to get data into Teradata with the rows spread evenly and then to use INSERT/SELECTs into the production tables. NoPI tables are also used in Columnar Tables for V14!
NoPI Tables used as Staging Tables for Data Loads
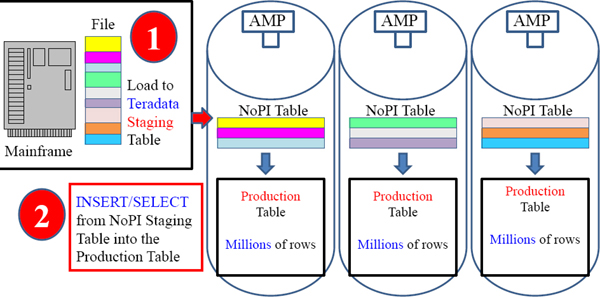
NoPI tables were first designed to be staging tables. Data from a Mainframe can be loaded onto Teradata perfectly evenly and quickly. Then an INSERT/SELECT can be done to move the data from the staging table (on Teradata) to the production table (also on Teradata). The data can be transformed in staging and there are no Load Restrictions with an INSERT/SELECT.
NoPI Table Capabilities
NoPI tables:
Are always Multi-Set Tables
Have Secondary Indexes (USI or NUSI)
Have Join Indexes
Be Volatile or Global Temporary Tables
Can COLLECT STATISTICS
Be FALLBACK Protected
Have Triggers
Be Large Objects (LOBs)
Have Primary Key Foreign Key Constraints
A (NoPI) Table always spreads the data perfectly evenly!
Above are some of the capabilities of NoPI tables. Next we will show the restrictions.
NoPI Table Restrictions
NoPI tables are limited and below are some restrictions:
No Primary Indexes allowed
No SET Tables
No Partition Primary Index (PPI) tables
No Queue Tables
No Hash Indexes
No Identity Columns
No Permanent Journaling
Can't be the Target Table for any UPDATE, UPSERT or
MERGE-INTO Statements
A (NoPI) Table is used as a staging table or in a Columnar Table!
Above are restrictions for NoPI Tables.
What does a Columnar Table look like?
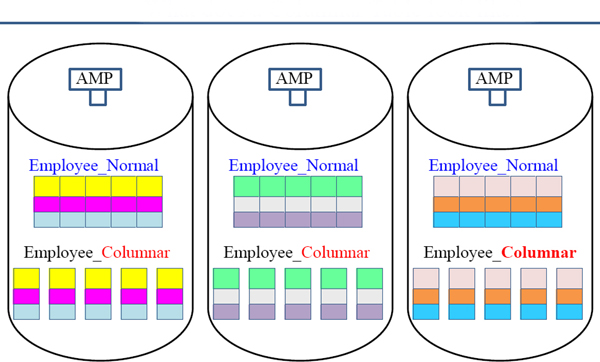
The two tables above contain the same Employee data, but one is a Columnar table. Employee_Normal has placed 3 rows on each AMP with 5 columns. The other table Employee_Columnar has 5 Containers each with one column.
Comparing Normal Table Vs Columnar Tables
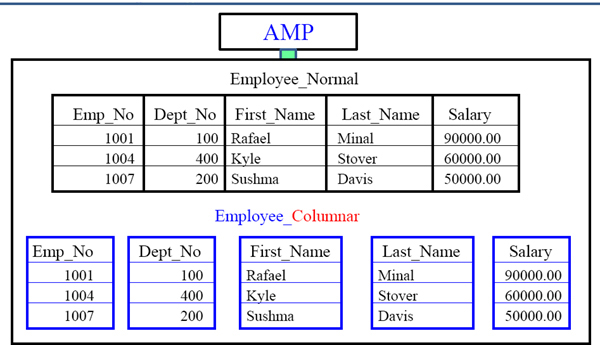
Both tables in the example contain the same data. The first is a normal table and the second is a columnar table. Both have the same three rows, but the columnar table almost appears to be 5 different tables (each with 1-column), referred to as containers.
Columnar Table Fundamentals
Columnar Tables must be a NoPI Table so No Primary Index (NoPI)
The NoPI brings even distribution to the table
Columnar Tables allow Columns to be Partitioned
An AMP still holds the entire row, but partitions vertically
Columns are placed inside their own individual Container
All Containers have the same amount of rows in the exact order
Single Columns or Multi-Columns can be placed inside containers
Each container looks like a small table for I/O purposes
Add up all the containers and you rebuild the row
Columnar Tables make sense when users query only certain columns
When a row is deleted it is NOT Physically Deleted but marked deleted

Understand the fundamentals above and you already have a good handle on Columnar.
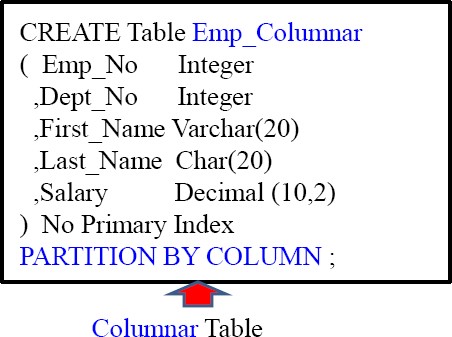
Example of Columnar CREATE Statement

When a table is created (Teradata V14 and beyond) the creator can specify that they want the table to be a Columnar table. The table has to be a NoPI table (No Primary Index) and you must define the PARTITION BY COLUMN.
Columnar can move just One Container to Memory

The query above only asks for the column Emp_No to satisfy the query. How many columns will be placed inside this AMP's FSG Cache? ONE! This is because the Container for Emp_No is all that is needed. Less movement is the value of Columnar.
Containers on AMPs match up Perfectly to rebuild a Row
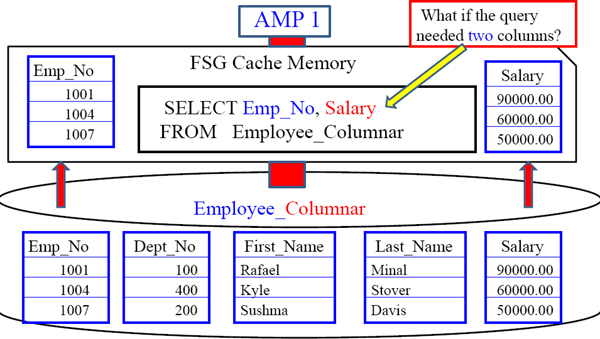
How many columns will be placed inside this AMP's FSG Cache? Two! This is because the Containers for Emp_No and Salary are inside their own block. Columnar tables allow for smaller blocks to move to and from memory to disk. 1007 makes 50000.00!
Indexes can be used on Columns (Containers)

The query above only asks for the column Last_Name in the SELECT list, but has a WHERE clause to filter for Emp_No 1001. How many columns will be placed inside this AMP's FSG Cache? Two interesting points are about to happen! See next slide!
Indexes can be used on Columns (Containers)

Two interesting points to note for your understanding. 1) The Emp_No containers is moved into memory using an INDEX. 2) The Last_Name containers is also placed into memory and Minal has the same relative row number (1) as 1001 so its found easily.
Visualize a Columnar Table

This AMP is assigned 3 Employee Rows
All AMPs hold 3 different Employee Rows also
Each Row has 5 Columns
This Columnar Table partitions in 5 separate containers
Each container has a relative row number (1, 2, 3)
Each container has the exact same number of rows
Above are some fundamentals to visualize when thinking about Columnar Tables.
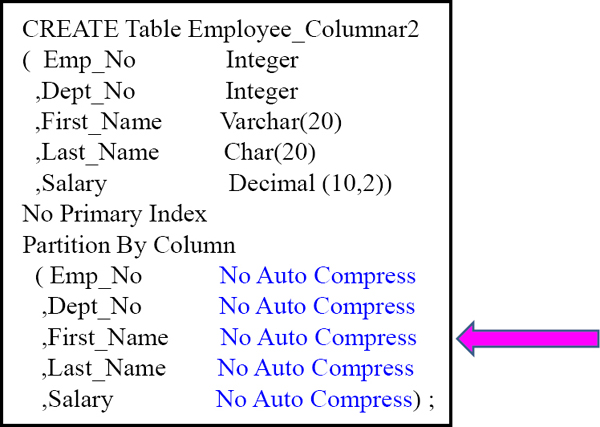
Single-Column Vs Multi-Column Containers

The syntax here is special because we have placed Emp_No into a single-column container, Dept_No into a single-column container, but we have First_Name, Last_Name and Salary all sharing a third container.
Comparing Normal Table Vs Columnar Tables
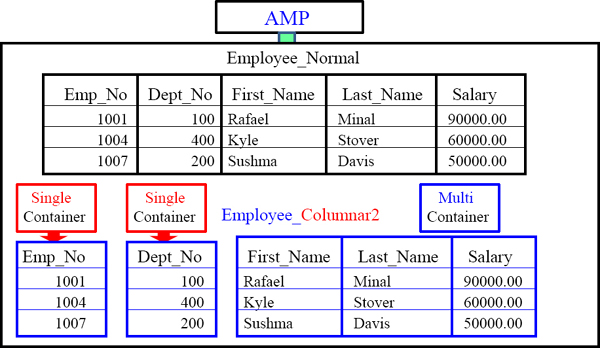
Notice that Employee_Columnar2 has two single-column containers and one multi.
Columnar Row Hybrid CREATE Statement

The syntax here is special because we have combined the words Column with Row.
Columnar Row Hybrid Example

The small arrows point out the Partition Number and starting Row Number.

A reason to use a Row Hybrid is mostly for compression opportunities. In this case we used it for 3 columns we expect to be used together in the SELECT List of user's SQL.
Review of Row Based Partition Primary Index (PPI)
/* Creating a PPI Table */
CREATE TABLE Order_Table_PPI
(Order_Number INTEGER Not Null
,Customer_Number INTEGER
,Order_Date DATE
,Order_Total Decimal (10,2)
) PRIMARY INDEX(Order_Number)
PARTITION BY RANGE_N (Order_Date
BETWEEN date ‘2012-01-01’
AND date ‘2012-12-31’
EACH INTERVAL ‘1’ Month);
There are three different types of Row Partitioning:
The above example is NOT Columnar, but a review of PPI tables, which partition the rows. The above is an example of a Range_N Partition. What this does is organizes the AMPs rows by a date. As you can see, at the end of the CREATE Statement, we put our Interval. We've set it for ‘1’ Month. What this means is that by the end of the year, the table will have 12 Partitions on each AMP! The next page shows a visual.
Visual of Row Partitioning (PPI Tables) by Month
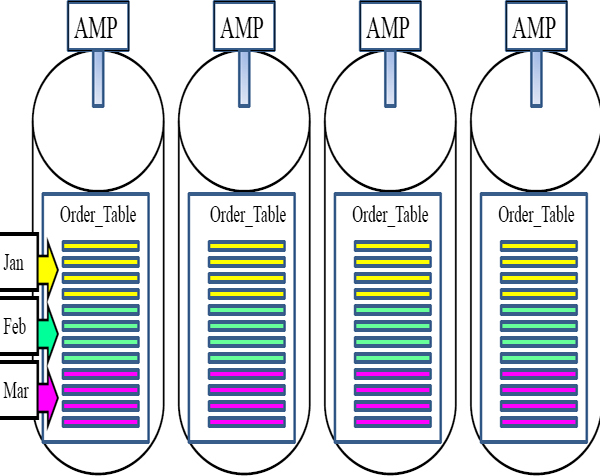
The purpose of a Row Partitioned Table is to eliminate rows not needed to satisfy Range Queries. Notice that all January Orders are in the top partition (yellow) so if a user wants all orders in January each AMP reads 1 partition (top partition).
CREATE Statement for both Row and Column Partition

This type of table will be one that has four column partitions for Order_Number, Customer_Number, Order_Date and Order_Total. Each column partition or “Container” will Row Partition by Month of Order_Date.
Visual of Row Partitioning (PPI Tables)and Columnar

This combines Row Partitioning with Column Partitioning. This is perfect for queries (see above query) that don't want to select all columns in the table or all rows.
How to Load into a Columnar Table
INSERT INTO Emp_Columnar
Select * from Emp_Staging ;
You first load to the NoPI Staging Table on Teradata and then you do an INSERT/SELECT from the Staging Table directly into the Columnar Table. FastLoad and MultiLoad won't work on a Columnar Table.
Columnar NO AUTO COMPRESS
Teradata compresses Columnar columns unless NO AUTO COMPRESS is stated.
Auto Compress in Columnar Tables
Compressed unless NO AUTO COMPRESS stated.
Teradata uses many different Compression techniques.
Teradata will decide NOT to Compress some Partitions.
Decompression automatic on column retrieval.
Compression at its best for single-column partitions.
Overhead in deciding best compression techniques.
No Overhead with NO AUTO COMPRESS in CREATE.
Teradata will automatically Compress each container if applicable!
Auto Compress Techniques in Columnar Tables
Trim Compression will compress leading zeros and trailing spaces to reduce space.
NULL Compression will compress NULL Values if the column is defined as NULLABLE.
Local Dictionary Compression is similar to Multi-Value Compression where a list of values are compressed.
Run Length Encoding Compression will have values only once and then maintain an associated count.
Unicode to UTF8 Compression for all Unicode (2-byte) characters that are ASCII so only (1-Byte) is needed.
Delta on Mean Compression will get the MEAN or AVERAGE and store –1, -2, + 3 to show the difference.
When and When NOT to use Columnar Tables
USE:
Queries access varying columns or column subsets.
The WHERE Clause is “Selective”.
Ad Hoc Queries are an excellent candidate.
Data Analytics are an excellent workload candidate.
Do NOT Use If:
Queries will run on data that is being updated/deleted.
Queries need to be tactical sub-second/OLTP queries.
A workload is CPU bound.
There are some do's and don'ts you will want to know about.
Watch the Video on the contest for the Teradata Search-off

Tera-Tom Trivia
Tom Coffing is a professional golf coach and caddy. Tom has caddied in over 100 professional events for his daughter Carling Coffing. Carling won the Golf Channel reality TV show “The Big Break” and she has made the cut in all three LPGA events. Carling and Tom continue to work together today. Carling continues to have enormous success as a TV personality.
Click on the link below or place it in your browser and watch the video on the famous contest the Teradata Search-off.