
Chapter 9
How Joins work internally
“A Join Index walked up to two tables in a bar and said, mind if I Join you?”
Table of Contents Chapter 9 – How Joins work Internally
– If the Join Condition is the Primary Index no Movement
– How the Parsing Engine Decides on a Join Plan
– Quiz – Redistribute the Employees by their Dept_No
– Quiz – Employees Dept_No landed on AMP with Matches
– When Rows are on the same AMP they can be Joined
– Redistribution and then a Row Hash Match Scan
– Quiz – Redistribute the Orders to the Proper AMP
– Answer to Redistribute the Employees by their Dept_No Quiz
– A Visual of the Join in Action
– Nexus Query Chameleon Example
– The Big Table Small Table Join causes Duplication
– Visual of Duplication of the Smaller Table across All-AMPs
– Duplication of the Smaller Table across All-AMPs
– A Visual of Duplication of the Smaller Table on a Single AMP
– A Visual of Redistribution on a Single AMP
Teradata Join Quiz
Which Statement is NOT true!
1. Each Table in Teradata has a Primary Index, unless it is a NoPI table.
2. The Primary Index is the mechanism that allows Teradata to physically distribute the rows of a table across the AMPs.
3. Each AMP Sorts their rows by the Row-ID, unless it is a Partitioned table, and then the sort is first by the Partition and then by Row-ID.
4. For two rows to be Joined together Teradata insists that both rows are physically on the same AMP.
5. Teradata will either Redistribute one or both of the tables or Duplicate the smaller table across all AMPs to ensure matching rows are on the same AMP, even if it is only for the life of the Join.
Do you know which statement above is False?
Teradata Join Quiz Answer
Which Statement is NOT true!
1. Each Table in Teradata has a Primary Index, unless it is a NoPI table.
2. The Primary Index is the mechanism that allows Teradata to physically distribute the rows of a table across the AMPs.
3. Each AMP Sorts their rows by the Row-ID, unless it is a Partitioned table, and then the sort is first by the Partition and then by Row-ID.
4. For two rows to be Joined together Teradata insists that both rows are physically on the same AMP.
![]()
5. Teradata will either Redistribute one or both of the tables or Duplicate the smaller table across all AMPs to ensure matching rows are on the same AMP, even if it is only for the life of the Join.
Do you know which statement above is False? All statements above are TRUE!
If the Join Condition is the Primary Index no Movement

CREATE Table Employee_Table
( Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
) UNIQUE PRIMARY INDEX(Employee_No);
CREATE Table Department_Table
(Dept_No INTEGER
,Department_Name CHAR(20)
,Mgr_No INTEGER
,Budget DECIMAL(10,2)
)
UNIQUE PRIMARY INDEX(Dept_No);
Teradata knows that it can only JOIN two rows together if they are physically on the same AMP. This can occur naturally if the join condition columns are the Primary Indexes of their respective tables, but most likely Teradata will have to move data to get the matching rows on the same AMP. What will the Parsing Engine decide to do next?
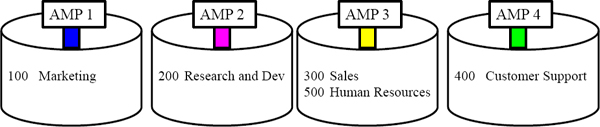
How the Parsing Engine Decides on a Join Plan

The Parsing Engine (PE) knows that the Dept_No column is the Primary Index for the Department_Table. It also know that the Dept_No column is NOT the Primary Index for the Employee_Table, so the PE commands the AMPs to Redistribute the entire Employee_Table by Dept_No into spool. This is equivalent to loading the Employee_Table with a Primary Index of Dept_No. Now all matching rows can join.
Quiz – Redistribute the Employees by their Dept_No
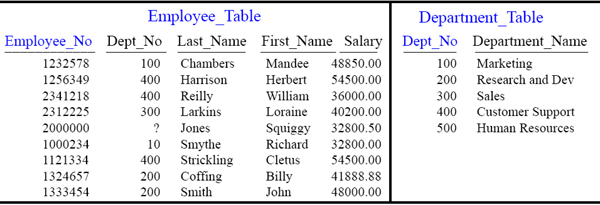
If Teradata decides to Redistribute the Employee_Table by Dept_No which AMPs will hold which Employees? Place their Dept_No and Last_Name on the AMP after Redistribution.
Fill in the quiz above. This is a great opportunity to understand the Teradata engine.
Quiz – Employees Dept_No landed on AMP with Matches
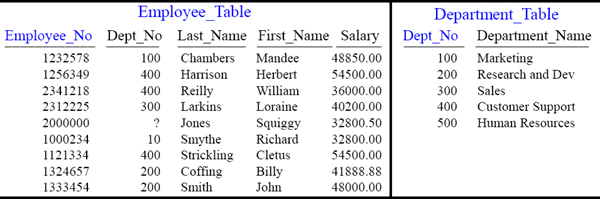

Each redistributed row landed on the same AMP as its matching row. Turn the page.
When Rows are on the same AMP they can be Joined


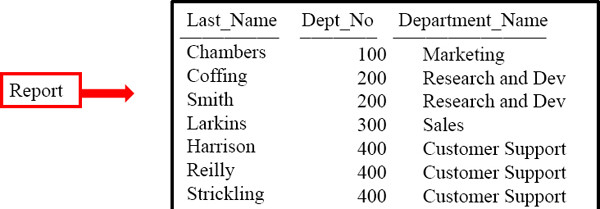
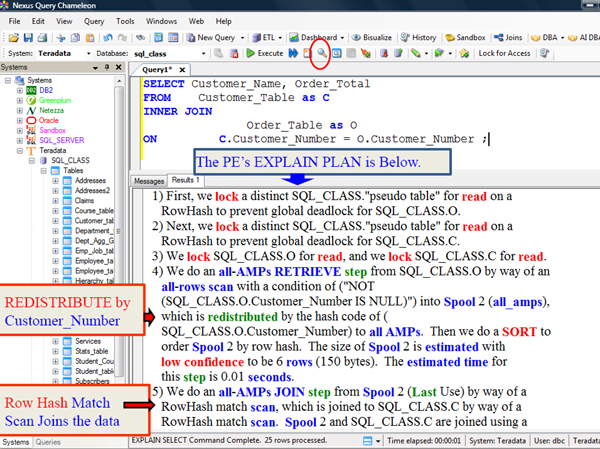
Redistribution and then a Row Hash Match Scan


Above resides the Query, the Parsing Engine's (PE) Analysis and a summary (in laymen's terms) of the PE's PLAN. First we need to get all matching rows to the corresponding AMP so the join can be performed between the two tables.
Quiz – Redistribute the Orders to the Proper AMP

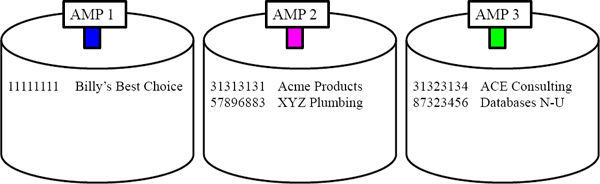
If Teradata decides to Redistribute the Order_Table by Customer_No which AMPs will hold which Orders? Place their Customer_Number and Order_Total on the AMP after Redistribution.
Fill in the quiz above. This is a great opportunity to understand the Teradata engine.
Answer to Redistribute the Employees by their Dept_No Quiz

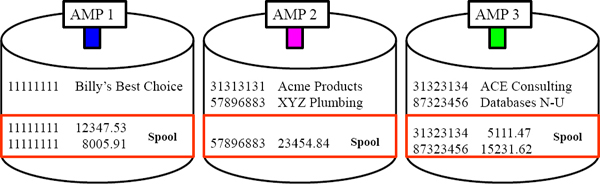
The Teradata Hashing Formula is consistent. It is used to load a Table's rows via the Primary Index of the table. Teradata follows the same Hash Formula to Redistribute for Joins.
Each redistributed row landed on the same AMP as its matching row. Turn the page.
A Visual of the Join in Action



The Big Table Small Table Join causes Duplication


Visual of Duplication of the Smaller Table across All-AMPs
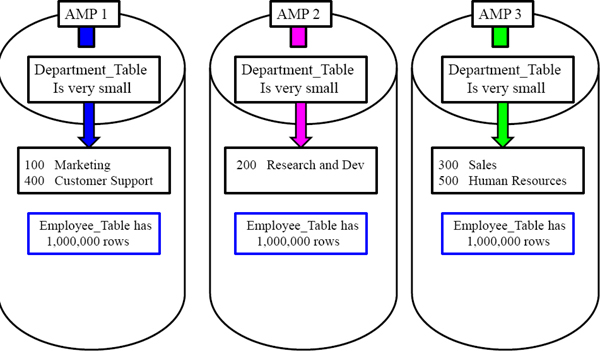
The next slide will demonstrate how Teradata Duplicates the smaller table (Department_Table) across All-AMPs.
Duplication of the Smaller Table across All-AMPs
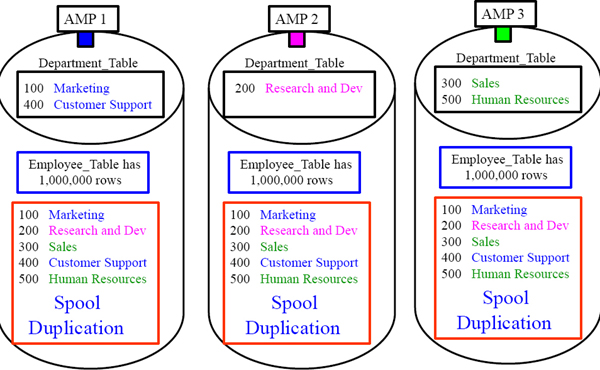
Teradata took the Department_Table and gathered up all 5-rows and then in Spool Duplicated the entire 5-row Table across All-AMPs. Now the join can happen!
A Visual of Duplication of the Smaller Table on a Single AMP

The picture above shows the smaller table Duplicated in its entirety on this AMP in spool. This same spool table resides on every AMP for only the life of this join. Notice that both Dept_No's in the Table and Spool have corresponding Row Hashes.
A Visual of Redistribution on a Single AMP
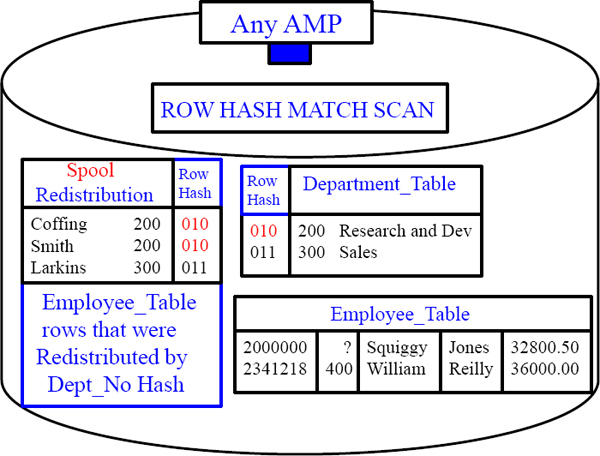
The picture above shows the Department_Table on the top right that holds two rows on this particular AMP. The Employee_Table has been redistributed by Hash Code on Dept_No and the rows in spool have matches on the same AMP.