
Chapter 30
Table Create and Data Types
“Create a definite plan for carrying out your desire and begin at once, whether you are ready or not, to put this plan into action. “
Table of Contents Chapter 30 – Table Create and Data Types
– Major Data Types and the number of Bytes they take up
– Making an exact copy a Table
– Making a NOT-So-Exact Copy a Table
– Troubleshooting Copying and Changing the Primary Index
– Copying only specific columns of a table
– Copying a Table and Keeping the Statistics
– Copying a Table with Statistics
– Copying a table Structure with NO Data but Statistics
– Fallback
– Fallback
– Table Customization of the Data Block Size
– Table Customization with FREESPACE Percent
– Example of how a Queue Table Works
– Example of how a Queue Table Works
Creating a Table
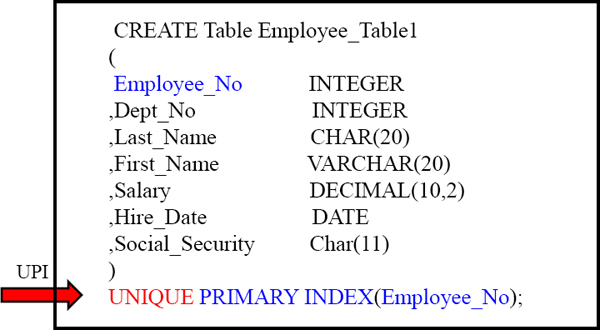
This is a basic TABLE CREATE STATEMENT. You have Columns and the data types in them. As you see, the Primary Index is defined for a Table at TABLE CREATE time.
Creating a Table

A Non-Unique Primary Index (NUPI) is on the above table. Notice how you only need to put ‘Primary Index’.
Creating a Table
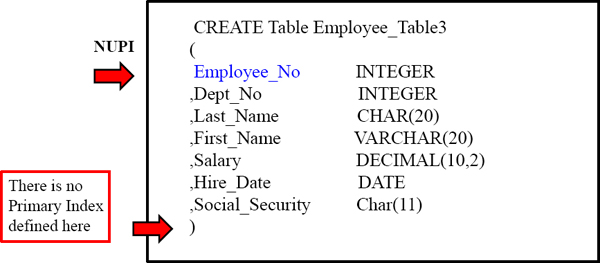
Here we have created a table without defining the Primary Index. This will default to the first column in the table here and make it a Non-Unique Primary Index (NUPI).
Creating a Table
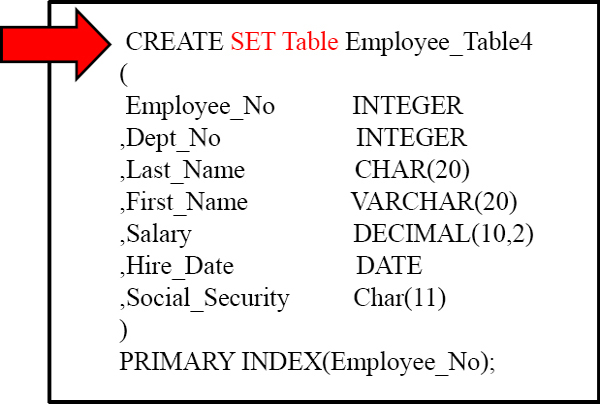
SET TABLE means that Duplicate ROWS are rejected. If your system is in Teradata mode then SET tables will be the default.
Creating a Table

A MULTISET Table means the table will ALLOW duplicate rows. If your system is in ANSI mode then MULTISET tables will be the default. In either Teradata mode or ANSI mode you can specifically state (SET or MULTISET) for the table type desired.
Creating a Table
CREATE SET Table Employee_Table6
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
)
UNIQUE PRIMARY INDEX(Employee_No);
It is very important when dealing with a SET table to have either a Unique Primary Index or a Unique Secondary Index. They eliminate the Duplicate Row Check. Because SET tables won't allow duplicate rows a “Duplicate Row Check” is done on all new INSERTS or UPDATES, but if any column has a UNIQUE constraint then the system knows that no row can be duplicate because the specific column is UNIQUE. This saves a lot of time. Do your best to stay away from the Duplicate Row Check.
Creating a Table
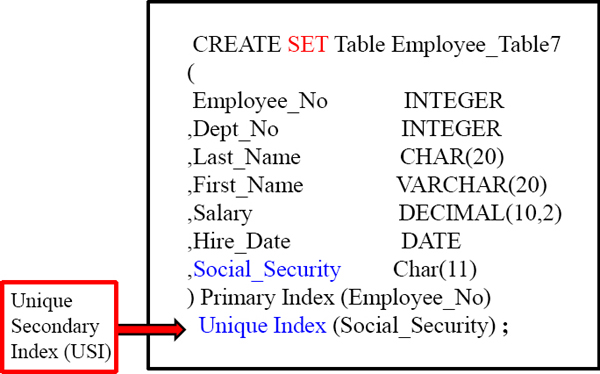
It is very important when dealing with a SET table to have either a Unique Primary Index or a Unique Secondary Index. They eliminate the Duplicate Row Check. Here we have created a UNIQUE Secondary Index (USI), and this will ensure no duplicate Social_Security values exist, so the system won't do the duplicate row check.
Creating a Table

The Unique Secondary Index (USI) is an alternate path to the data. It allows for faster searches on a column, however it isn't as quick as the UPI or NUPI. When you utilize the USI column in the WHERE Clause it is always a 2-AMP operation. Fast!
Creating a Table
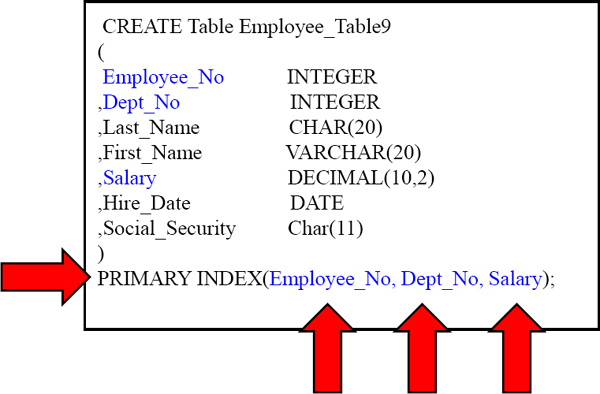
This is a Multi-Column Primary Index in this table. In this example, we have 3 Columns that make up our Primary Index.
| Data Types | ||
| Data Type | Description | Data Value Range |
| INTEGER | Signed whole number | -2,147,483,648 to 2,147,483,647 |
| SMALLINT | Signed smaller whole number | 32,768 to 32,767 |
| DECIMAL(X,Y)Where: X=1 thru 18, total number of digits in the number And Y=0 thru 18 digits to the right of the decimal | Signed decimal number 18 digits on either side of the decimal point | Largest value DEC(18,0) Smallest value DEC(18,18) |
| NUMERIC(X,Y) Same as DECIMAL | Synonym for DECIMAL | Same as DECIMAL |
| FLOAT | REAL | PRECISION | DOUBLE PRECISION | Floating Point Format (IEEE) | <value>x10307 to <value>x10-308 |
| CHARACTER(X) CHAR(X) Where: X=1 thru 64000 | Fixed length character string, 1 byte of storage per character, | 1 to 64,000 characters long, pads to length with space |
| VARCHAR(X) CHARACTER VARYING(X) CHAR VARYING(X) Where: X=1 thru 64000 | Variable length character string, 1 byte of storage per character, plus 2 bytes to record length of actual data | 1 to 64,000 characters as a maximum. The system only stores the characters presented to it. |
| CLOB (X { K | M | G }) CHARACTER LARGE OBJECT (X { K | M | G }) | Large character object, for manipulating chunks. Can also specify character set and attribute. | Max for LATIN in K, M or G: 2097088000 bytes Max for UNICODE in K or M: 1048544000 bytes. |
| BLOB (X { K | M | G }) BINARY LARGE OBJECT (X { K | M | G }) | Large binary object, for manipulating chunks. | Specified in Kilobytes, Megabytes or Gigabytes. Max is 2097088000 bytes. |
| DATE | Signed internal representation of YYYYMMDD | See Date Chapter |
| TIME | Identifies a field as a TIME value with Hour, Minutes and Seconds | See Date Chapter |
| TIMESTAMP | Identifies a field as a TIMESTAMP value with Year, Month, Day, Hour, Minute, and Seconds | See Date Chapter |
| BYTEINT | Signed whole number | -128 to 127 |
| BYTE (X) Where: X=1 thru 64000 | Binary | 1 to 64,000 bytes |
| VARBYTE (X) Where: X=1 thru 64000 | Variable length binary | 1 to 64,000 bytes |
| LONG VARCHAR | Variable length string | 64,000 characters (maximum data length) The system only stores the characters provided, not trailing spaces.) |
| GRAPHIC (X) Where: X=1 thru 32000 | Fixed length string of 16-bit bytes (2 bytes per character) | 1 to 32,000 KANJI characters |
| VARGRAPHIC (X) Where: X=1 thru 32000 | Variable length string of 16-bit bytes | 1 to 32,000 characters as a maximum. The system only stores characters provided. |
| BIGINT | Represents a signed, binary integer value | from –9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
| PERIOD(DATE) | Two Dates that make up a Date Period | Beginning Date and Ending Date |
| PERIOD(TIME(n) [WITH TIME ZONE]) | Two Times that make up a Time Period | Beginning Time and Ending Time |
| PERIOD(TIMESTAMP(n) [WITH TIME ZONE]) | Two Timestamps that make up a Timestamp Period | Beginning Timestamp and Ending Timestamp |
Major Data Types and the number of Bytes they take up
| Bytes | Data Type | Comments |
| 1 | BYTEINT | |
| 2 | SMALLINT | |
| 4 | INTEGER | |
| 8 | BIGINT | |
| 1 | DECIMAL 1-2 | |
| 2 | DECIMAL 3-4 | |
| 4 | DECIMAL 5-9 | |
| 8 | DECIMAL 10-18 | |
| 16 | DECIMAL 19-38 | |
| 8 | FLOAT | |
| 4 | DATE | |
| 6/8 | TIME | 6 for 32-bit systems; 8 for 64-bit |
| 8 | TIME WITH TIME ZONE | |
| 10/12 | TIMESTAMP | 10 for 32-bit systems; 12 for 64-bit |
| 12 | TIMESTAMP WITH TIME ZONE |
Making an exact copy a Table
-- This table already exists
CREATE SET Table Employee_Table8
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No)
Unique Index (Social_Security) ;
Make a Copy of the Table with the Data.
CREATE Table Employee_Table10 AS Employee_Table8 WITH DATA
Make a Copy of the Table without the Data.
CREATE Table Employee_Table11 AS Employee_Table8 WITH NO DATA
When you want to make an exact copy of a table, by using the syntax at the top, it will make an exact copy including the INDEXES! You must include the WITH DATA or WITH NO DATA keywords, or it will error.
Making a NOT-So-Exact Copy a Table
This table already exists
CREATE SET Table Employee_Table8
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No)
Unique Index (Social_Security) ;
Make a copy with some changes and keep the Data.
CREATE Table Employee_Table12 AS
(SELECT * FROM Employee_Table8)
WITH DATA
PRIMARY INDEX (Dept_No)
Make a copy with some changes with NO Data.
CREATE Table Employee_Table13 AS
(SELECT * FROM Employee_Table8)
WITH NO DATA
PRIMARY INDEX (Dept_No)
We made a copy of the table, but changed the Primary Index. The syntax above must be used to do this. You must include the WITH DATA or WITH NO DATA keywords, or it will error.
Copying a Table
-- This table already exists
CREATE SET Table Employee_Table8
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No
Unique Index (Social_Security) ;
-- Make a Copy of a Table
CREATE Table Employee_Table13
AS
(SELECT * FROM Employee_Table8)
WITH DATA ;

By using this way of getting the data, you can supply the table with a new Primary Index. In the example, they didn't take that opportunity so the Primary Index will be the first column of the table and it will be a NUPI. You must include the WITH DATA or WITH NO DATA keywords, or it will error.
Troubleshooting Copying and Changing the Primary Index
This table already exists
CREATE SET Table Employee_Table8
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No)
Unique Index (Social_Security) ;
Make a Copy of a Table
CREATE Table Employee_Table14
AS Employee_Table8
WITH DATA
PRIMARY INDEX (Dept_No) ;

Want a new Primary Index for your table? Well, this is NOT the copy syntax that will copy a table with a different Primary Index. See the previous slides.
Copying only specific columns of a table
--This table already exists
CREATE SET Table Employee_Table8
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No)
Unique Index (Social_Security) ;

This copy statement will not error and actually copy only the first four columns and their data. It will also change the Primary Index to a NUPI on Dept_No.
Copying a Table and Keeping the Statistics
--This table already exists
CREATE SET Table Employee_Table8
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No)
Unique Index (Social_Security) ;
--Make a Copy of a Table
CREATE TABLE Employee_Table16
AS Employee_Table8 with DATA
AND Statistics;

This copy statement will not error and will actually copy the table structure, the data, and have the exact same statistics.
Copying a Table with Statistics
--This Table already exists
CREATE SET Table Employee_Table
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No)
Unique Index (Social_Security) ;

This copy statement will not error . It will actually copy the table structure with no data, but the Statistics will all be ZEROED.
Copying a table Structure with NO Data but Statistics
-- This table already exists
CREATE SET Table Employee_Table2
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No)
Unique Index (Social_Security) ;

Once the Employee_Table7 is loaded with data, the user can Recollect Statistics. What is clever here is that originally the statistics on the new table are zeroed, which means they have the columns and indexes listed that were previously collected by the old table, but now actual statistic data. Once the new table is loaded and the COLLECT STATISTICS command is run again it will automatically update the true statistics of the new table, but only collect on the columns or indexes the old table had done in the past.
Fallback
CREATE SET Table Employee_Table, FALLBACK
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No)
Unique Index (Social_Security) ;
Fallback means a Duplicate copy of each row is stored on a different AMP. This effectively doubles the size of the table, but all is good if an AMP goes down. Fallback rows are stored on the AMPs, but Teradata never accesses the Fallback rows for a query unless the Primary data is inaccessible due to a hardware or software failure.
Fallback
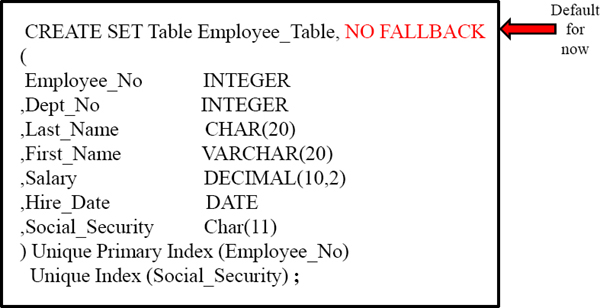
NO Fallback is the default. However, you should specify because FALLBACK can be the default at the database level.
Before Journal
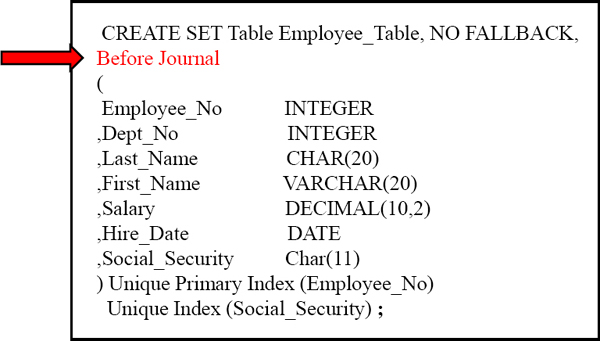
Journaling helps with roll backing data if there is an error. A BEFORE Journal is a BEFORE Image of a row that will be stored for any new/changing row.
Dual Before Journal
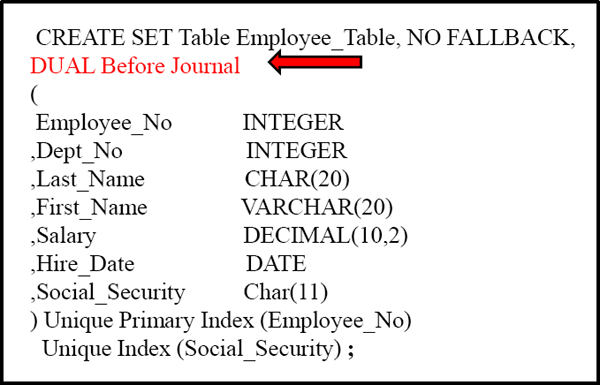
A DUAL BEFORE Journal takes Two BEFORE IMAGES of a row and these two copies are stored on two separate AMPS whenever any new/changing row occurs.
After Journal
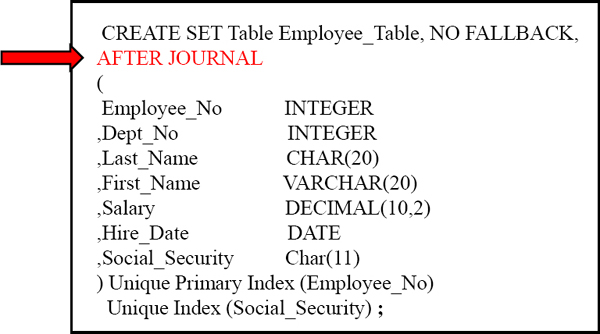
An AFTER Journal is an AFTER Image of a row that will be stored for any new/changing row.
Dual After Journal

A DUAL AFTER Journal is two AFTER IMAGES of a row that are stored for any new/changing row
Journal Keyword Alone
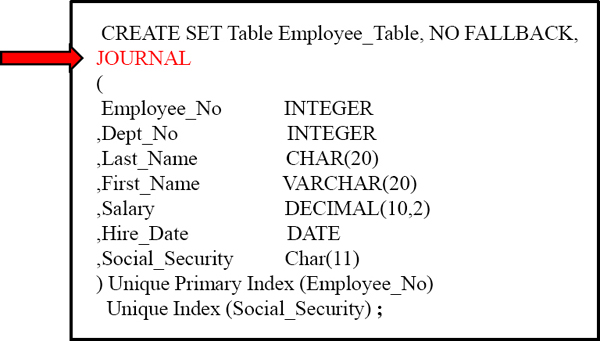
A JOURNAL is a BEFORE and AFTER image that will be stored for any new/changing row
Why Use Journaling?
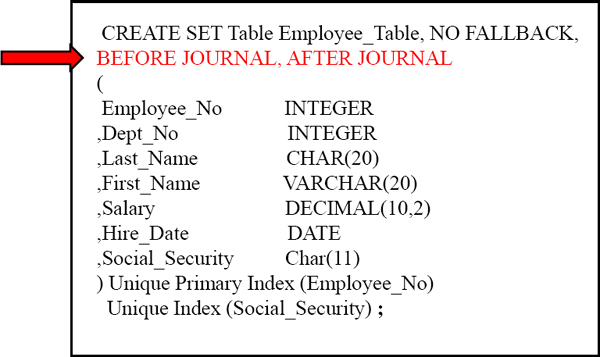
A BEFORE Journal would be utilized to Rollback a programming error to the way things looked BEFORE (at a specific Point-In-Time) .
Why Use Journaling?

An AFTER Journal would be part of the Full System Backup strategy to recover how things looked AFTER (to a specific Point-In-Time). The above example uses both a BEFORE and AFTER Journal.
Table Customization of the Data Block Size
CREATE SET Table Employee_Table, FALLBACK,
DATABLOCKSIZE=16384 BYTES,
FREESPACE = 20 PERCENT
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No) ;
A user sometimes does not want to use the DEFAULT DATABLOCKSIZE. With this command, it allows them to alter the DATABLOCKSIZE. An OLTP Table is better tuned for smaller BLOCK SIZES.
Table Customization with FREESPACE Percent
CREATE SET Table Employee_Table, FALLBACK,
DATABLOCKSIZE=16384 BYTES,
FREESPACE = 20 PERCENT
(
Employee_No INTEGER
,Dept_No INTEGER
,Last_Name CHAR(20)
,First_Name VARCHAR(20)
,Salary DECIMAL(10,2)
,Hire_Date DATE
,Social_Security Char(11)
) Unique Primary Index (Employee_No) ;
FREESPACE of 20 PERCENT means when using MULTILOAD or FASTLOAD, the table will only take up 80% of the Cylinder leaving 20% as free space.
Creating a QUEUE Table
CREATE SET Table Retail_Sales, QUEUE
(
Ret_Qits TIMESTAMP (6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6)
,Product_ID INTEGER
,Quantity INTEGER
)
PRIMARY INDEX(Product_ID);
The first column of a QUEUE Table is ALWAYS a Queue Insertion Timestamp Column (QITS) defined as above. The first column CANNOT be defined as UNIQUE, an IDENTITY Column, or a UNIQUE SECONDARY INDEX OR PRIMARY KEY. The FIFO (First In First Out) is the principle is a Queue table built around. As rows come into the table they will be processes with the CONSUME statement on a first in first out basis. The major significance of having a Queue Table is Rows retrieved are processed only once and then deleted.
Example of how a Queue Table Works
CREATE SET Table Retail_Sales, QUEUE

(
Ret_Qits TIMESTAMP (6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6)
,Product_ID INTEGER
,Quantity INTEGER
) PRIMARY INDEX(Product_ID);

INSERT INTO Retail_Sales
(Current_Timestamp, 1000, 100);

SELECT * FROM Retail_Sales;
| Ret_Qits | Product_ID | Quantity |
| 04/10/2011 10:22:23:19 | 1000 | 100 |
This row will NOT automatically be DELETED because of our SELECT.
Example of how a Queue Table Works
CREATE SET Table Retail_Sales, QUEUE
(
Ret_Qits TIMESTAMP (6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6)
,Product_ID INTEGER
,Quantity INTEGER
) PRIMARY INDEX(Product_ID);
INSERT INTO Retail_Sales
(Current_Timestamp, 1000, 100);
SELECT and CONSUME TOP 1 * from Retail_Sales;
| Ret_Qits | Product_ID | Quantity |
| 04/10/2011 10:22:23:19 | 1000 | 100 |
This row will automatically be DELETED because of our SELECT and CONSUME TOP 1 Statement.