
CHAPTER 9
DATA MANAGEMENT LAYER DESIGN
A project team designs the data management layer of a system using a four-step process: selecting the format of the storage, mapping the problem domain classes to the selected format, optimizing the storage to perform efficiently, and then designing the necessary data access and manipulation classes. This chapter describes the different ways objects can be stored and several important characteristics that should be considered when choosing among object persistence formats. It describes a problem domain class to object persistence format mapping process for the most important object persistence formats. Because the most popular storage format today is the relational database, the chapter focuses on the optimization of relational databases from both storage and access perspectives. We describe the effect that nonfunctional requirements have on the data-management layer. Last, the chapter describes how to design data access and manipulation classes.
OBJECTIVES
- Become familiar with several object persistence formats
- Be able to map problem domain objects to different object persistence formats
- Be able to apply the steps of normalization to a relational database
- Be able to optimize a relational database for object storage and access
- Become familiar with indexes for relational databases
- Be able to estimate the size of a relational database
- Understand the affect of nonfunctional requirements on the data management layer
- Be able to design the data access and manipulation classes
CHAPTER OUTLINE
- Introduction
- Object Persistence Formats
- Mapping Problem Domain Objects to Object persistence Formats
- Optimizing RDBMS-Based Object Storage
- Designing Data Access and Manipulation Classes
- Nonfunctional Requirements and Data Management Layer Design
- Applying the Concepts at CD Selections
- Summary
INTRODUCTION
As explained in Chapter 7, the work done by any application can be divided into a set of layers. This chapter focuses on the data management layer, which includes both data access and manipulation logic, along with the actual design of the storage. The data storage component of the data management layer manages how data are stored and handled by the programs that run the system. This chapter describes how a project team designs the storage for objects (object persistence) using a four-step approach: selecting the format of the storage, mapping the problem domain objects to the object persistence format, optimizing the object persistence format, and designing the data access and manipulation classes necessary to handle the communication between the system and the database.
Applications are of little use without the data that they support. How useful is a multimedia application that can't support images or sound? Why would someone log into a system to find information if it took him or her less time to locate the information manually? Design includes four steps to object persistence design that decrease the chances of ending up with inefficient systems, long system response times, and users who cannot get to the information that they need in the way that they need it—all of which can affect the success of the project.
The first part of this chapter describes a variety of storage formats and explains how to select the appropriate one for your application. From a practical perspective, there are five basic types of formats that can be used to store objects for application systems: files (sequential and random), object-oriented databases, object-relational databases, relational databases, or NoSQL datastores.1 Each type has certain characteristics that make it more appropriate for some types of systems over others.
Once the object persistence format is selected to support the system, the problem domain objects need to drive the design of the actual object storage. Then the object storage needs to be designed to optimize its processing efficiency, which is the focus of the next part of the chapter. One of the leading complaints by end users is that the final system is too slow, so to avoid such complaints project team members must allow time during design to carefully make sure that the file or database performs as fast as possible. At the same time, the team must keep hardware costs down by minimizing the storage space that the application will require. The goals of maximizing access to the objects and minimizing the amount of space taken to store objects can conflict, and designing object persistence efficiency usually requires trade-offs.
Finally, it is necessary to design a set of data access and manipulation classes to ensure the independence of the problem domain classes from the storage format. The data access and manipulation classes handle all communication with the database. In this manner, the problem domain is decoupled from the object storage, allowing the object storage to be changed without affecting the problem domain classes.
OBJECT PERSISTENCE FORMATS
There are five main types of object persistence formats: files (sequential and random access), object-oriented databases, object-relational databases, relational databases, and NoSQL data-stores. Files are electronic lists of data that have been optimized to perform a particular transaction. For example, Figure 9-1 shows a customer order file with information about customers’ orders, in the form in which it is used, so that the information can be accessed and processed quickly by the system.
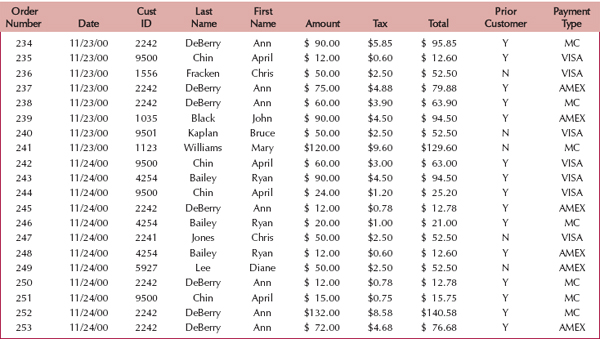
FIGURE 9-1 Customer Order File
A database is a collection of groupings of information, each of which is related to each other in some way (e.g., through common fields). Logical groupings of information could include such categories as customer data, information about an order, product information, and so on. A database management system (DBMS) is software that creates and manipulates these databases (see Figure 9-2 for a relational database example). Such end user DBMSs as Microsoft Access support small-scale databases that are used to enhance personal productivity, whereas enterprise DBMSs, such as DB2, Versant, and Oracle, can manage huge volumes of data and support applications that run an entire company. An end-user DBMS is significantly less expensive and easier for novice users to use than its enterprise counterpart, but it does not have the features or capabilities that are necessary to support mission-critical or large-scale systems.
In the next sections we describe sequential and random-access files, relational databases, object-relational databases, and object-oriented databases that can be used to handle a system's object persistence requirements. We also describe a new exciting technology that shows much promise for object persistence: NoSQL datastores. Finally, we describe a set of characteristics on which the different formats can be compared.
Sequential and Random Access Files
From a practical perspective, most object-oriented programming languages support sequential and random access files as part of the language.2 In this section, we describe what sequential access and random access files are.3 We also describe how sequential access and random access files are used to support an application. For example, they can be used to support master files, look-up files, transaction files, audit files, and history files.

FIGURE 9-2 Customer Order Database
Sequential access files allow only sequential file operations to be performed (e.g., read, write, and search). Sequential access files are very efficient for sequential operations, such as report writing. However, for random operations, such as finding or updating a specific object, they are very inefficient. On the average, 50 percent of the contents of a sequential access file will have to be searched through before finding the specific object of interest in the file. They come in two flavors: ordered and unordered.
An unordered sequential access file is basically an electronic list of information stored on disk. Unordered files are organized serially (i.e., the order of the file is the order in which the objects are written to the file). Typically, new objects simply are added to the file's end.
Ordered sequential access files are placed into a specific sorted order (e.g., in ascending order by customer number). However, there is overhead associated with keeping files in a particular sorted order. The file designer can keep the file in sorted order by always creating a new file each time a delete or addition occurs, or he or she can keep track of the sorted order via the use of a pointer, which is information about the location of the related record. A pointer is placed at the end of each record, and it “points” to the next record in a series or set. The underlying data/file structure in this case is the linked list4 data structure demonstrated in the previous chapter.
Random access files allow only random or direct file operations to be performed. This type of file is optimized for random operations, such as finding and updating a specific object. Random access files typically give a faster response time to find and update operations than any other type of file. However, because they do not support sequential processing, applications such as report writing are very inefficient. The various methods to implement random access files are beyond the scope of this book.5
There are times when it is necessary to be able to process files in both a sequential and random manner. One simple way to do this is to use a sequential file that contains a list of the keys (the field in which the file is to be kept in sorted order) and a random access file for the actual objects. This minimizes the cost of additions and deletions to a sequential file while allowing the random file to be processed sequentially by simply passing the key to the random file to retrieve each object in sequential order. It also allows fast random processing to occur by using only the random access file, thus optimizing the overall cost of file processing. However, if a file of objects needs to be processed in both a random and sequential manner, the developer should consider using a database (relational, object-relational, or object-oriented) instead.
There are many different application types of files—for example, master files, lookup files, transaction files, audit files, and history files. Master files store core information that is important to the business and, more specifically, to the application, such as order information or customer mailing information. They usually are kept for long periods of time, and new records are appended to the end of the file as new orders or new customers are captured by the system. If changes need to be made to existing records, programs must be written to update the old information.
Lookup files contain static values, such as a list of valid ZIP codes or the names of the U.S. states. Typically, the list is used for validation. For example, if a customer's mailing address is entered into a master file, the state name is validated against a lookup file that contains U.S. states to make sure that the operator entered the value correctly.
A transaction file holds information that can be used to update a master file. The transaction file can be destroyed after changes are added, or the file may be saved in case the transactions need to be accessed again in the future. Customer address changes, for one, would be stored in a transaction file until a program is run that updates the customer address master file with the new information.
For control purposes, a company might need to store information about how data change over time. For example, as human resources clerks change employee salaries in a human resources system, the system should record the person who made the changes to the salary amount, the date, and the actual change that was made. An audit file records before and after images of data as they are altered so that an audit can be performed if the integrity of the data is questioned.
Sometimes files become so large that they are unwieldy, and much of the information in the file is no longer used. The history file (or archive file) stores past transactions (e.g., old customers, past orders) that are no longer needed by system users. Typically the file is stored off-line, yet it can be accessed on an as-needed basis. Other files, such as master files, can then be streamlined to include only active or very recent information.
YOUR TURN: 9-1 Student Admissions System
Suppose you are building a Web-based system for the admissions office at your university that will be used to accept electronic applications from students. All the data for the system will be stored in a variety of files.
Question
Give an example using this system for each of the following file types: master, lookup, transaction, audit, and history. What kind of information would each file contain, and how would the file be used?
Relational Databases
A relational database is the most popular kind of database for application development today. A relational database is based on collections of tables with each table having a primary key—a field or fields whose values are unique for every row of the table. The tables are related to one another by placing the primary key from one table into the related table as a foreign key (see Figure 9-3). Most relational database management systems (RDBMS) support referential integrity, or the idea of ensuring that values linking the tables together through the primary and foreign keys are valid and correctly synchronized. For example, if an order-entry clerk using the tables in Figure 9-3 attempted to add order 254 for customer number 1111, he or she would have made a mistake because no customer exists in the Customer table with that number. If the RDBMS supported referential integrity, it would check the customer numbers in the Customer table; discover that the number 1111 is invalid; and return an error to the entry clerk. The clerk would then go back to the original order form and recheck the customer information. Can you imagine the problems that would occur if the RDBMS let the entry clerk add the order with the wrong information? There would be no way to track down the name of the customer for order 254.
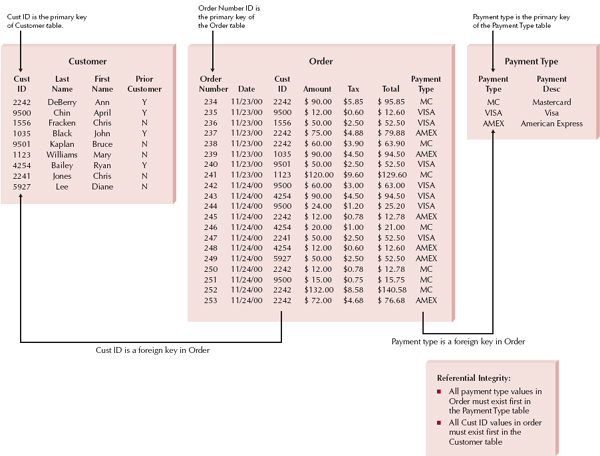
FIGURE 9-3 Relational Database
Tables have a set number of columns and a variable number of rows that contain occurrences of data. Structured query language (SQL) is the standard language for accessing the data in the tables, and it operates on complete tables, as opposed to the individual rows in the tables. Thus, a query written in SQL is applied to all the rows in a table all at once, which is different from a lot of programming languages, which manipulate data row by row. When queries must include information from more than one table, the tables first are joined based on their primary key and foreign key relationships and treated as if they were one large table. Examples of RDBMS software are Microsoft Access, Oracle, DB2, and MySQL.
To use a RDBMS to store objects, objects must be converted so that they can be stored in a table. From a design perspective, this entails mapping a UML class diagram to a relational database schema. We describe the mapping necessary later in this chapter.
Object-Relational Databases
Object-relational database management systems (ORDBMSs) are relational database management systems with extensions to handle the storage of objects in the relational table structure. This is typically done through the use of user-defined types. For example, an attribute in a table could have a data type of map, which would support storing a map. This is an example of a complex data type. In pure RDBMSs, attributes are limited to simple or atomic data types, such as integers, floats, or chars.
ORDBMSs, because they are simply extensions to their RDBMS counterparts, also have very good support for the typical data management operations that business has come to expect from RDBMSs, including an easy-to-use query language (SQL), authorization, concurrency-control, and recovery facilities. However, because SQL was designed to handle only simple data types, it too has been extended to handle complex object data. Currently, vendors deal with this issue in different manners. For example, DB2, Informix, and Oracle all have extensions that provide some level of support for objects.
Many of the ORDBMSs on the market still do not support many of the object-oriented features that can appear in an object-oriented design (e.g., inheritance). One of the problems in supporting inheritance is that inheritance support is language dependent. For example, the way Smalltalk supports inheritance is different from C++’s approach, which is different from Java's approach. Thus vendors currently must support many different versions of inheritance, one for each object-oriented language, or decide on a specific version and force developers to map their object-oriented design (and implementation) to their approach. Like RDBMSs, a mapping from a UML class diagram to an object-relational database schema is required. We describe the mapping necessary later in this chapter.
Object-Oriented Databases
The next type of database management system that we describe is the object-oriented database management systems (OODBMS). There have been two primary approaches to supporting object persistence within the OODBMS community: adding persistence extensions to an object-oriented programming language and creating an entirely separate database management system. In the case of OODBMS, the Object Data Management Group (ODMG) has completed the standardization process for defining (Object Definition Language, ODL), manipulating (Object Manipulating Language, OML), and querying (Object Query Language, OQL) objects in an OODBMS.6
With an OODBMS, collections of objects are associated with an extent. An extent is simply the set of instances associated with a particular class (i.e., it is the equivalent of a table in a RDBMS). Technically speaking, each instance of a class has a unique identifier assigned to it by the OODBMS: the Object ID. However, from a practical point of view, it is still a good idea to have a semantically meaningful primary key (even though from an OODBMS perspective this is unnecessary). Referential integrity is still very important. In an OODBMS, from the user's perspective, it looks as if the object is contained within the other object. However, the OODBMS actually keeps track of these relationships through the use of the Object ID, and therefore foreign keys are not necessary.7
OODBMSs provide support for some form of inheritance. However, as already discussed, inheritance tends to be language dependent. Currently, most OODBMSs are tied closely to either a particular object-oriented programming language (OOPL) or a set of OOPLs. Most OODBMSs originally supported either Smalltalk or C++. Today, many of the commercially available OODBMSs provide support for C++, Java, and Smalltalk.
OODBMSs also support the idea of repeating groups (fields) or multivalued attributes. These are supported through the use of attribute sets and relationships sets. RDBMSs do not explicitly allow multivalued attributes or repeating groups. This is considered to be a violation of the first normal form (discussed later in this chapter) for relational databases. Some ORDBMSs do support repeating groups and multivalued attributes.
Up until recently, OODBMSs have mainly been used to support multimedia applications or systems that involve complex data (e.g., graphics, video, sound). Application areas, such as computer-aided design and manufacturing (CAD/CAM), financial services, geographic information systems, health care, telecommunications, and transportation, have been the most receptive to OODBMSs. They are also becoming popular technologies for supporting electronic commerce, online catalogs, and large Web multimedia applications. Examples of pure OODBMSs include Gemstone, Objectivity, db4o, and Versant.
Although pure OODBMS exist, most organizations currently invest in ORDBMS technology. The market for OODBMS is expected to grow, but its ORDBMS and RDBMS counterparts dwarf it. One reason for this situation is that there are many more experienced developers and tools in the RDBMS arena. Furthermore, relational users find that using an OODBMS comes with a fairly steep learning curve.
NoSQL Data Stores
NoSQL data stores are the newest type of object persistence available. Depending on whom you talk to, NoSQL either stands for No SQL or Not Only SQL. Regardless, the data stores that are described as NoSQL typically do not support SQL. Currently, there is no standard for NoSQL data stores. Most NoSQL data stores were created to address problems associated with storing large amounts of distributed data in RDBMSs. They tend to support very fast queries. However, when it comes to updating, they normally do not support a locking mechanism, and consequently, all copies of a piece of data are not required to be consistent at all times. Instead they tend to support an eventually consistent based model. So it is technically possible to have different values for different copies of the same object stored in different locations in a distributed system. Depending on the application, this could cause problems for decision makers. Therefore, their applicability is limited and they are not applicable to traditional business transaction processing systems. Some of the better known NoSQL data stores include Google's Big Table, Amazon's Dynamo, Apache's HBase, Apache's CouchDB, and Apache/Facebook's Cassandra. There are many different types of NoSQL data stores including key-value stores, document stores, column-oriented stores, and object databases. Besides object databases, which are either ORDBMSs or OODBMSs, we describe each below.
Key-value data stores essentially provide a distributed index (primary key) to where a BLOB (binary large object) is stored. A BLOB treats a set of attributes as one large object. A good example of this type of NoSQL data store is Amazon's Dynamo. Dynamo provides support for many of the core services for Amazon. Obviously, being one of the largest e-commerce sites in the world, Amazon had to have a solution for object persistence that was scalable, distributable, and reliable. Typical RDBMS-based solutions would not work for some of these applications. Typical applications that use key-value data stores are Web-based shopping carts, product catalogs, and bestseller lists. These types of applications do not require updating the underlying data. For example, you do not update the title of a book in your shopping cart when you are making a purchase at Amazon. Given the scale and distributed nature of this type of system, there are bound to be many failures across the system. Being fault tolerant and temporarily sacrificing some consistency across all copies of an object is a reasonable trade-off.
Document data stores, as the name suggests, are built around the idea of documents. The idea of document databases has been around for a long time. One of the early systems that used this approach was Lotus Notes. These types of stores are considered to be schema free. By that we mean there is no detailed design of the database. A good example of an application that would benefit from this type of approach is a business card database. In a relational database, multiple tables would need to be designed. In a document data store, the design is done more in a “just in time” manner. As new business cards are input into the system, attributes not previously included are simply added to the evolving design. Previously entered business cards would simply not have those attributes associated with them. One major difference between key-value data stores and document data stores is that the “document” has structure and can be easily searched based on the non-key attributes contained in the document, whereas the key-value data store simply treats the “value” as one big monolithic object. Apache's CouchDB is a good example of this type of data store.
Columnar data stores organize the data into columns instead of rows. However, there seems to be some confusion as to what this actually implies. In the first approach to columnar data stores, the rows represent the attributes and the columns represent the objects. This is in comparison to a relational database, where columns represent the attributes and the objects are represented by rows. These types of data stores are very effective in business intelligence, data mining, and data warehousing applications where the data are fairly static and many computations are performed over a single or a small subset of the available attributes. In comparison to a relational database where you would have to select a set of attributes from all rows; with this type of data store, you would simply have to select a set of rows. This should be a lot faster than with a relational database. A few good examples of this type of columnar data store include Oracle's Retail Predictive Application Server, HP's Vertica, and SAP's Sybase IQ. The second approach to columnar data stores, which includes Apache's HBase, Apache/Facebook's Cassandra, and Google's BigTable, is designed to handle very large data sets (petabytes of data) that can be accessed as if the data are stored in columns. However, in this case, the data are actually stored in a three-dimensional map composed of object ID, attribute name, timestamp, and value instead of using columns and rows. This approach is highly scalable and distributable. These types of data stores support social applications such as Twitter and Facebook and support search applications such as Google Maps, Earth, and Analytics.
Given the popularity of social computing, business intelligence, data mining, data warehousing, e-commerce, and their need for highly scalable, distributable, and reliable data storage, NoSQL data stores is an area that should be considered as part of an object persistence solution. However, at this time, NoSQL data stores lack the maturity to be considered for most business applications. Given the overall diversity and complexity of NoSQL data stores and their limited applicability to traditional business applications, we do not consider them any further in this text.
Selecting an Object Persistence Format
Each of the file and database storage formats that have been presented has its strengths and weaknesses, and no one format is inherently better than the others. In fact, sometimes a project team chooses multiple formats (e.g., a relational database for one, a file for another, and an object-oriented database for a third). Thus, it is important to understand the strengths and weaknesses of each format and when to use each one. Figure 9-4 presents a summary of the characteristics of each and the characteristics that can help identify when each type of format is more appropriate.
Major Strengths and Weaknesses The major strengths of files include that some support for sequential and random access files is normally part of an OOPL, files can be designed to be very efficient, and they are a good alternative for temporary or short-term storage. However, all file manipulation must be done through the OOPL. Files do not have any form of access control beyond that of the underlying operating system. Finally, in most cases, if files are used for permanent storage, redundant data most likely will result. This can cause many update anomalies.
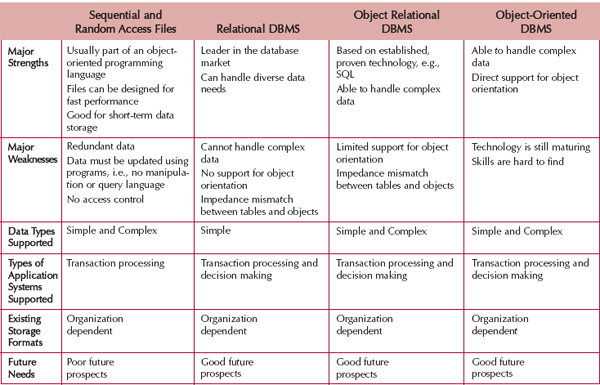
FIGURE 9-4 Comparison of Object Persistence Formats
RDBMSs bring with them proven commercial technology. They are the leaders in the DBMS market. Furthermore, they can handle very diverse data needs. However, they cannot handle complex data types, such as images. Therefore, all objects must be converted to a form that can be stored in tables composed of atomic or simple data. They provide no support for object orientation. This lack of support causes an impedance mismatch between the objects contained in the OOPL and the data stored in the tables. An impedance mismatch refers to the amount of work done by both the developer and DBMS and the potential information loss that can occur when converting objects to a form that can be stored in tables.
Because ORDBMSs are typically object-oriented extensions to RDBMSs, they inherit the strengths of RDBMSs. They are based on established technologies, such as SQL, and unlike their predecessors, they can handle complex data types. However, they provide only limited support for object orientation. The level of support varies among the vendors; therefore, ORDBMSs also suffer from the impedance mismatch problem.
OODBMSs support complex data types and have the advantage of directly supporting object orientation. Therefore, they do not suffer from the impedance mismatch that the previous DBMSs do. Even though the ODMG has released version 3.0 of its set of standards, the OODBMS community is still maturing. Therefore, this technology might still be too risky for some firms. The other major problems with OODBMS are the lack of skilled labor and the perceived steep learning curve of the RDBMS community.
Data Types Supported The first issue is the type of data that will need to be stored in the system. Most applications need to store simple data types, such as text, dates, and numbers, and all files and DBMSs are equipped to handle this kind of data. The best choice for simple data storage, however, is usually the RDBMS because the technology has matured over time and has continuously improved to handle simple data very effectively.
Increasingly, applications are incorporating complex data, such as video, images, or audio. ORDBMSs or OODBMSs are best able to handle data of this type. Complex data stored as objects can be manipulated much faster than with other storage formats.
Type of Application System There are many different kinds of application systems that can be developed. Transaction-processing systems are designed to accept and process many simultaneous requests (e.g., order entry, distribution, payroll). In transaction-processing systems, the data are continuously updated by a large number of users, and the queries that are asked of the systems typically are predefined or targeted at a small subset of records (e.g., List the orders that were backordered today or What products did customer #1234 order on May 12, 2001?).
Another set of application systems is the set designed to support decision making, such as decision support systems (DSS), management information systems (MIS), executive information systems (EIS), and expert systems (ES). These decision-making support systems are built to support users who need to examine large amounts of read-only historical data. The questions that they ask are often ad hoc, and they include hundreds or thousands of records at a time (e.g., List all customers in the West region who purchased a product costing more than $500 at least three times, or What products had increased sales in the summer months that have not been classified as summer merchandise?).
Transaction-processing systems and DSSs thus have very different data storage needs. Transaction-processing systems need data storage formats that are tuned for a lot of data updates and fast retrieval of predefined, specific questions. Files, relational databases, object-relational databases, and object-oriented databases can all support these kinds of requirements. By contrast, systems to support decision making are usually only reading data (not updating it), often in ad hoc ways. The best choices for these systems usually are RDBMSs because these formats can be configured specially for needs that may be unclear and less apt to change the data.
Existing Storage Formats The storage format should be selected primarily on the basis of the kind of data and application system being developed. However, project teams should consider the existing storage formats in the organization when making design decisions. In this way, they can better understand the technical skills that already exist and how steep the learning curve will be when the storage format is adopted. For example, a company that is familiar with RDBMS will have little problem adopting a relational database for the project, whereas an OODBMS might require substantial developer training. In the latter situation, the project team might have to plan for more time to integrate the object-oriented database with the company's relational systems or possibly consider moving toward an ORDBMS solution.
Future Needs Not only should a project team consider the storage technology within the company, but it should also be aware of current trends and technologies that are being used by other organizations. A large number of installations of a specific type of storage format suggest that skills and products are available to support the format. Therefore, the selection of that format is safe. For example, it would probably be easier and less expensive to find RDBMS expertise when implementing a system than to find help with an OODBMS.
Other Miscellaneous Criteria Other criteria that should be considered include cost, licensing issues, concurrency control, ease of use, security and access controls, version management, storage management, lock management, query management, language bindings, and APIs. We also should consider performance issues, such as cache management, insertion, deletion, retrieval, and updating of complex objects. Finally, the level of support for object orientation (such as objects, single inheritance, multiple inheritance, polymorphism, encapsulation and information hiding, methods, multivalued attributes, repeating groups) is critical.
YOUR TURN: 9-2 Donation Tracking System
A major public university graduates approximately 10,000 students per year, and the development office has decided to build a Web-based system that solicits and tracks donations from the university's large alumni body. Ultimately, the development officers hope to use the information in the system to better understand the alumni giving patterns so that they can improve giving rates.
Question
- What kind of system is this? Does it have characteristics of more than one?
- What different kinds of data will this system use?
- On the basis of your answers, what kind of data storage format(s) do you recommend for this system?
MAPPING PROBLEM DOMAIN OBJECTS TO OBJECT PERSISTENCE FORMATS8
As described in the previous section, there are many different formats from which to choose to support object persistence. Each of the different formats can have some conversion requirements. Regardless of the object persistence format chosen, we suggest supporting primary keys and foreign keys by adding them to the problem domain classes at this point. However, this does imply some additional processing required. The developer has to set the value for the foreign key when adding the relationship to an object. In some cases, this overhead may be too costly. In those cases, this suggestion should be ignored. In the remainder of this section, we describe how to map the problem domain classes to the different object persistence formats. From a practical perspective, file formats are used mostly for temporary storage. Thus we do not consider them further.
We also recommend that the data management functionality specifics, such as retrieval and updating of data from the object storage, be included only in classes contained in the data management layer. This will ensure that the data management classes are dependent on the problem domain classes and not the other way around. Furthermore, this allows the design of problem domain classes to be independent of any specific object persistence environment, thus increasing their portability and their potential for reuse. Like our previous recommendation, this one also implies additional processing. However, the increased portability and potential for reuse realized should more than compensate for the additional processing required.
Mapping Problem Domain Objects to an OODBMS Format
If we support object persistence with an OODBMS, the mappings between the problem domain objects and the OODBMS tend to be fairly straightforward. As a starting point, we suggest that each concrete problem domain class should have a corresponding object persistence class in the OODBMS. There will also be a data access and manipulation (DAM) class that contains the functionality required to manage the interaction between the object persistence class and the problem domain layer. For example, using the appointment system example from the previous chapters, the Patient class is associated with an OODBMS class (see Figure 9-5). The Patient class essentially will be unchanged from analysis. The Patient-OODBMS class will be a new class that is dependent on the Patient class, whereas the Patient-DAM class will be a new class that depends on both the Patient class and the Patient-OODBMS class. The Patient-DAM class must be able to read from and write to the OODBMS. Otherwise, it will not be able to store and retrieve instances of the Patient class. Even though this does add overhead to the installation of the system, it allows the problem domain class to be independent of the OODBMS being used. If at a later time another OODBMS or object persistence format is adopted, only the DAM classes will have to be modified. This approach increases both the portability and the potential for reuse of the problem domain classes.
Even though we are implementing the DAM layer using an OODBMS, a mapping from the problem domain layer to the OODBMS classes in the data access and management layer may be required, depending on the level of support of inheritance in the OODBMS and the level of inheritance used in the problem domain classes. If multiple inheritance is used in the problem domain but not supported by the OODBMS, then the multiple inheritance must be factored out of the OODBMS classes. For each case of multiple inheritance (i.e., more than one superclass), the following rules can be used to factor out the multiple inheritance effects in the design of the OODBMS classes.8

FIGURE 9-5 Appointment System Problem-Domain and DM Layers
Rule 1a: Add a column(s) to the OODBMS class(es) that represents the subclass(es) that will contain an Object ID of the instance stored in the OODBMS class that represents the “additional” superclass(es). This is similar in concept to a foreign key in an RDBMS. The multiplicity of this new association from the subclass to the “superclass” should be 1..1. Add a column(s) to the OODBMS class(es) that represents the superclass(es) that will contain an Object ID of the instance stored in the OODBMS class that represents the subclass(es). If the superclasses are concrete, that is, they can be instantiated themselves, then the multiplicity from the superclass to the subclass is 0..1, otherwise, it is 1..1. An exclusive-or (XOR) constraint must be added between the associations. Do this for each “additional” superclass.
or
Rule 1b: Flatten the inheritance hierarchy of the OODBMS classes by copying the attributes and methods of the additional OODBMS superclass(es) down to all of the OODBMS subclasses and remove the additional superclass from the design.9
These multiple inheritance rules are very similar to those described in Chapter 8. Figure 9-6 demonstrates the application of these rules. The right side of the figure portrays the same problem domain classes that were in Chapter 8: Airplane, Car, Boat, FlyingCar, and AmphibiousCar. FlyingCar inherits from both Airplane and Car, and AmphibiousCar inherits from both Car and Boat. Figure 9-6a portrays the mapping of multiple inheritance relationships into a single inheritance-based OODBMS using Rule 1a. Assuming that Car is concrete, we apply Rule 1a to the Problem Domain classes, and we end up with the OODBMS classes on the left side of Part a, where we have:
- Added a column (attribute) to FlyingCar-OODBMS that represents an association with Car-OODBMS;
- Added a column (attribute) to AmphibiousCar-OODBMS that represents an association with Car-OODBMS;
- Added a pair of columns (attributes) to Car-OODBMS that represents an association with FlyingCar-OODBMS and AmphibiousCar-OODBMS and for completeness sake;
- Added associations between AmphibiousCar-OODBMS and Car-OODBMS and FlyingCar-OODBMS and Car-OODBMS that have the correct multiplicities and the XOR constraint explicitly shown.
We also display the dependency relationships from the OODBMS classes to the problem domain classes. Furthermore, we illustrate the fact that the association between Flying-Car-OODBMS and Car-OODBMS and the association between AmphibiousCar-OODBMS and Car-OODBMS are based on the original factored-out inheritance relationships in the problem domain classes by showing dependency relationships from the associations to the inheritance relationships.
On the other hand, if we apply Rule 1b to map the Problem Domain classes to a single-inheritance-based OODBMS, we end up with the mapping in Figure 9-6b, where all the attributes of Car have been copied into the FlyingCar-OODBMS and AmphibiousCarOODBMS classes. In this latter case, you may have to deal with the effects of inheritance conflicts (see Chapter 8).
The advantage of Rule 1a is that all problem domain classes identified during analysis are preserved in the database. This allows maximum flexibility of maintenance of the design of the data management layer. However, Rule 1a increases the amount of message passing required in the system, and it has added processing requirements involving the XOR constraint, thus reducing the overall efficiency of the design. Our recommendation is to limit Rule 1a to be applied only when dealing with “extra” superclasses that are concrete because they have an independent existence in the problem domain. Use Rule 1b when they are abstract because they do not have an independent existence from the subclass.
YOUR TURN: 9-3 Doctor's Office Appointment System
In the previous chapters, we have been using a doctor's office appointment system as an example. Assume that you now know that the OODBMS that will be used to support the system will support only single inheritance. Using a class diagram, draw the design for the database.

FIGURE 9-6 Mapping Problem Domain Objects to a Single Inheritance–Based OODBMS
In either case, additional processing will be required. In the first case, cascading of deletes will work, not only from the individual object to all its elements but also from the superclass instances to all the subclass instances. Most OODBMSs do not support this type of deletion. However, to enforce the referential integrity of the system, it must be done. In the second case, there will be a lot of copying and pasting of the structure of the superclass to the subclasses. In the case that a modification of the structure of the superclass is required, the modification must be cascaded to all of the subclasses. Again, most OODBMSs do not support this type of modification cascading; therefore, the developer must address it. However, multiple inheritance is rare in most business problems. In most situations the preceding rules will never be necessary.
When instantiating problem domain objects from OODBMS objects, additional processing will also be required. The additional processing will be in the retrieval of the OODBMS objects and taking their elements to create a problem domain object. Also, when storing the problem domain object, the conversion to a set of OODBMS objects is required. Basically speaking, any time that an interaction takes place between the OODBMS and the system, if multiple inheritance is involved and the OODBMS supports only single inheritance, a conversion between the two formats will be required. This conversion is the purpose of the data access and manipulation classes described later in this chapter.
Mapping Problem Domain Objects to an ORDBMS Format
If we support object persistence with an ORDBMS, then the mapping from the problem domain objects to the data management objects is much more involved. Depending on the level of support for object orientation, different mapping rules are necessary. For our purposes, we assume that the ORDBMS supports Object IDs, multivalued attributes, and stored procedures. However, we assume that the ORDBMS does not provide any support for inheritance. Based on these assumptions, Figure 9-7 lists a set of rules that can be used to design the mapping from the Problem Domain objects to the tables of the ORDBMS-based data management layer.
First, all concrete Problem Domain classes must be mapped to the tables in the ORDBMS. For example in Figure 9-8, the Patient class has been mapped to Patient-ORDBMS table. Notice that the Participant class has also been mapped to an ORDBMS table. Even though the Participant class is abstract, this mapping was done because in the complete class diagram (see Figure 7-15), the Participant class had multiple direct subclasses (Employee and Patient).
Second, single-valued attributes should be mapped to columns in the ORDBMS tables. Again, referring to Figure 9-8, we see that the amount attribute of the Patient class has been included in the Patient Table class.
Third, depending on the level of support of stored procedures, the methods and derived attributes should be mapped either to stored procedures or program modules.
Fourth, single-valued (one-to-one) aggregation and association relationships should be mapped to a column that can store an Object ID. This should be done for both sides of the relationship.
Fifth, multivalued attributes should be mapped to columns that can contain a set of values. For example in Figure 9-8, the insurance carrier attribute in the Patient class may contain multiple values because a patient may have more than one insurance carrier. Thus in the Patient table, a multiplicity has been added to the insurance carrier attribute to portray this fact.
The sixth mapping rule addresses repeating groups of attributes in a problem domain object. In this case, the repeating group of attributes should be used to create a new table in the ORDBMS. It can imply a missing class in the problem domain layer. Normally, when a set of attributes repeats together as a group, it implies a new class. Finally, we must create a one-to-many association from the original table to the new one.

FIGURE 9-7 Schema for Mapping Problem Domain Objects to ORDBMS
The seventh rule supports mapping multivalued (many-to-many) aggregation and association relationships to columns that can store a set of Object IDs. Basically, this is a combination of the fourth and fifth rules. Like the fourth rule, this should be done for both sides of the relationships. For example in Figure 9-8, the Symptom table has a multivalued attribute (Patients) that can contain multiple Object IDs to Patient Table objects, and Patient table has a multivalued attribute (Symptoms) that can contain multiple Object IDs to Symptom Table objects.
The eighth rule combines the intentions of Rules 4 and 7. In this case, the rule maps one-to-many and many-to-one relationships. On the single-valued side (1..1 or 0..1) of the relationship, a column that can store a set of Object IDs from the table on the multivalued side (1..* or 0..*) of the relationship should be added. On the multivalued side, a column should be added to the table that can store an Object ID from an instance stored in the table on the single-valued side of the relationship. For example, in Figure 9-8, the Patient table has a multivalued attribute (Appts) that can contain multiple Object IDs to Appointment Table objects, whereas the Appointment table has a single-valued attribute (Patient) that can contain an Object ID to a Patient Table object.
The ninth, and final, rule deals with the lack of support for generalization and inheritance. In this case, there are two different approaches. These approaches are virtually identical to the rules described with the preceding OODBMS object persistence formats. For example in Figure 9-8, the Patient table contains an attribute (Participant) that can contain an Object ID for a Participant Table object, and the Participant table contains an attribute (SubClassObjects) that contain an Object ID for an object, in this case, stored in the Patient table. In the other case, the inheritance hierarchy is flattened.

FIGURE 9-8 Example of Mapping Problem Domain Objects to ORDBMS Schema
Of course, additional processing is required any time an interaction takes place between the database and the system. Every time an object must be created or retrieved from the database, updated, or deleted, the ORDBMS object(s) must be converted to the problem domain object, or vice versa. Again, this is the purpose of the data access and manipulation classes. The only other choice is to modify the problem domain objects. However, such a modification can cause problems between the problem domain layer and the physical architecture and human–computer interface layers. Generally speaking, the cost of conversion between the ORDBMS and the problem domain layer will be more than offset by the savings in development time associated with the interaction between the problem domain and physical architecture and human–computer interaction layers and the ease of maintenance of a semantically clean problem domain layer. In the long run, owing to the conversions necessary, the development and production cost of using an OODBMS may be less than the development and production cost implementing the object persistence in an ORDBMS.
YOUR TURN: 9-4 Doctor's Office Appointment System
In Your Turn 9-3, you created a design for the database assuming that the database would be implemented using an OODBMS that supported only single inheritance. In this case, assume that you now know that an ORDBMS will be used and that it does not support any inheritance. However, it does support Object IDs, multivalued attributes, and stored procedures. Using a class diagram, draw the design for the database.
Mapping Problem Domain Objects to a RDBMS Format
If we support object persistence with an RDBMS, then the mapping from the problem domain objects to the RDBMS tables is similar to the mapping to an ORDBMS. However, the assumptions made for an ORDBMS are no longer valid. Figure 9-9 lists a set of rules that can be used to design the mapping from the problem domain objects to the RDBMS-based data management layer tables.

FIGURE 9-9 Schema for Mapping Problem Domain Objects to RDBMS
The first four rules are basically the same set of rules used to map problem domain objects to ORDBMS-based data management objects. First, all concrete problem domain classes must be mapped to tables in the RDBMS. Second, single-valued attributes should be mapped to columns in the RDBMS table. Third, methods should be mapped to either stored procedures or program modules, depending on the complexity of the method. Fourth, single-valued (one-to-one) aggregation and association relationships are mapped to columns that can store the foreign keys of the related tables. This should be done for both sides of the relationship. For example in Figure 9-10, we needed to include tables in the RDBMS for the Participant, Patient, Symptom, and Appointment classes.
The fifth rule addresses multivalued attributes and repeating groups of attributes in a problem domain object. In these cases, the attributes should be used to create new tables in the RDBMS. As in the ORDBMS mappings, repeating groups of attributes can imply missing classes in the Problem Domain layer. In that case, a new problem domain class may be required. Finally, we should create a one-to-many or zero-to-many association from the original table to the new one. For example, in Figure 9-10, we needed to create a new table for insurance carrier because it was possible for a patient to have more than one insurance carrier.
The sixth rule supports mapping multivalued (many-to-many) aggregation and association relationships to a new table that relates the two original tables. In this case, the new table should contain foreign keys back to the original tables. For example, in Figure 9-10, we needed to create a new table that represents the suffer association between the Patient and Symptom problem domain classes.
The seventh rule addresses one-to-many and many-to-one relationships. With these types of relationships, the multivalued side (0..* or 1..*) should be mapped to a column in its table that can store a foreign key back to the single-valued side (0..1 or 1..1). It is possible that we have already taken care of this situation because we earlier recommended inclusion of both primary and foreign key attributes in the problem domain classes. In the case of Figure 9-10, we had already added the primary key from the Patient class to the Appointment class as a foreign key (see participantNumber). However, in the case of the reflexive relationship, primary insurance carrier, associated with the Patient class, we need to add a new attribute (primaryInsuranceCarrier) to be able to store the relationship.
The eighth, and final, rule deals with the lack of support for generalization and inheritance. As in the case of an ORDBMS, there are two different approaches. These approaches are virtually identical to the rules described with OODBMS and ORDBMS object persistence formats given earlier. The first approach is to add a column to each table that represents a subclass for each of the concrete superclasses of the subclass. Essentially, this ensures that the primary key of the subclass is the same as the primary key for the superclass. If we had previously added the primary and foreign keys to the problem domain objects, as we recommended, then we do not have to do anything else. The primary keys of the tables will be used to rejoin the instances stored in the tables that represent each of the pieces of the problem domain object. Conversely, the inheritance hierarchy can be flattened and the rules (Rules 1 through 7) can be reapplied.
As in the case of the ORDBMS approach, additional processing will be required any time that an interaction takes place between the database and the system. Every time an object must be created, retrieved from the database, updated, or deleted, the mapping between the problem domain and the RDBMS must be used to convert between the two different formats. In this case, a great deal of additional processing will be required. However, from a practical point of view, it is more likely that you will use a RDBMS for storage of objects than the other approaches because RDBMSs are by far the most popular format in the marketplace. We will focus on how to optimize the RDBMS format for object persistence in the next section of this chapter.
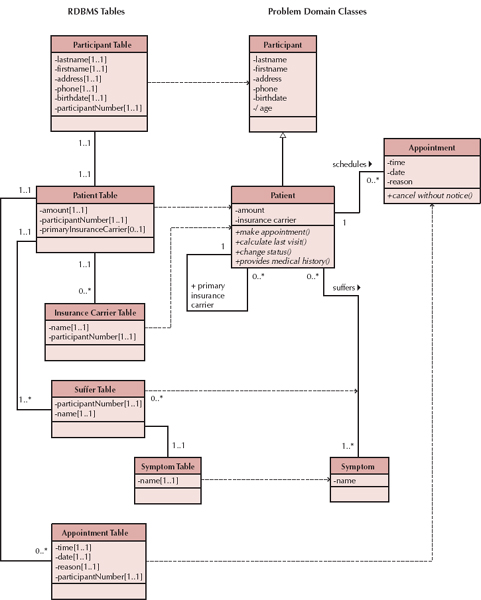
FIGURE 9-10 Example of Mapping Problem Domain Objects to RDBMS Schema
YOUR TURN: 9-5 Doctor's Office Appointment System
In Your Turn 9-3, you created a design for the database assuming that the database would be implemented using an OODBMS that supported only single inheritance. And, in Your Turn 9-4, you created a design for the database assuming that the database would be implemented using an ORDBMS that did not support any inheritance but did support Object IDs, multivalued attributes, and stored procedures. In this case, you should assume that the system will be supported by an RDBMS. Using a class diagram, draw the design for the database.
OPTIMIZING RDBMS-BASED OBJECT STORAGE
Once the object persistence format is selected, the second step is to optimize the object persistence for processing efficiency. The methods of optimization vary based on the format that you select; however, the basic concepts remain the same. Once you understand how to optimize a particular type of object persistence, you will have some idea as to how to approach the optimization of other formats. This section focuses on the optimization of the most popular storage format: relational databases.
There are two primary dimensions in which to optimize a relational database: for storage efficiency and for speed of access. Unfortunately, these two goals often conflict because the best design for access speed may take up a great deal of storage space as compared to other, less-speedy designs. The first section describes how to optimize the object persistence for storage efficiency using a process called normalization. The next section presents design techniques, such as denormalization and indexing, which can speed up the performance of the system. Ultimately, the project team will go through a series of trade-offs until the ideal balance of the two optimization dimensions is reached. Finally, the project team must estimate the size of the data storage needed to ensure there is enough capacity on the server(s).
Optimizing Storage Efficiency
The most efficient tables in a relational database in terms of storage space have no redundant data and very few null values. The presence of null values suggests that space is being wasted (and more data to store means higher data storage hardware costs). For example, the table in Figure 9-11 repeats customer information, such as name and state, each time a customer places an order, and it contains many null values in the product-related columns. These nulls occur whenever a customer places an order for fewer than three items (the maximum number on an order).
In addition to wasting space, redundancy and null values also allow more room for error and increase the likelihood that problems will arise with the integrity of the data. What if customer 1035 moved from Maryland to Georgia? In the case of Figure 9-11, a program must be written to ensure that all instances of that customer are updated to show Georgia as the new state of residence. If some of the instances are overlooked, then the table will contain an update anomaly, whereby some of the records contain the correctly updated value for state and other records contain the old information.
Nulls threaten data integrity because they are difficult to interpret. A blank value in the Order table's product fields could mean the customer did not want more than one or two products on his or her order, the operator forgot to enter in all three products on the order, or the customer canceled part of the order and the products were deleted by the operator. It is impossible to be sure of the actual meaning of the nulls.
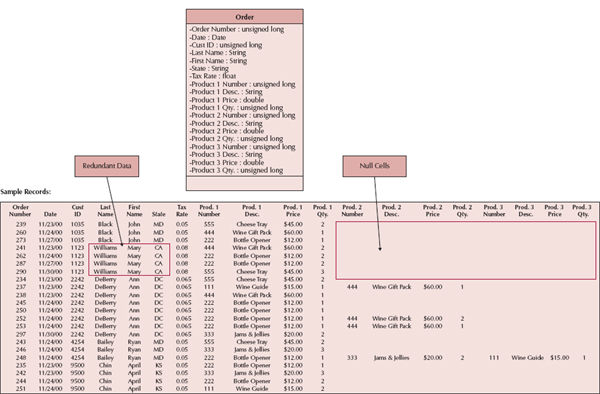
FIGURE 9-11 Optimizing Storage

FIGURE 9-12 The Steps of Normalization
For both these reasons—wasted storage space and data integrity threats—project teams should remove redundancy and nulls from the table. During design, the class diagram is used to examine the design of the RDBMS tables (e.g., see Figure 9-10) and optimize it for storage efficiency. If you follow the modeling instructions and guidelines that were presented in Chapter 5, you will have little trouble creating a design that is highly optimized in this way because a well-formed logical data model does not contain redundancy or many null values.
Sometimes, however, a project team needs to start with a model that was poorly constructed or with one that was created for files or a nonrelational type of format. In these cases, the project team should follow a series of steps that serve to check the model for storage efficiency. These steps make up a process called normalization.10 Normalization is a process whereby a series of rules are applied to the RDBMS tables to determine how well they are formed (see Figure 9-12). These rules help analysts identify tables that are not represented correctly. Here, we describe three normalization rules that are applied regularly in practice. Figure 9-11 shows a model in 0 Normal Form, which is an unnormalized model before the normalization rules have been applied.
A model is in first normal form (1NF) if it does not lead to multivalued fields, fields that allow a set of values to be stored, or repeating fields, which are fields that repeat within a table to capture multiple values. The rule for 1NF says that all tables must contain the same number of columns (i.e., fields) and that all the columns must contain a single value. Notice that the model in Figure 9-11 violates 1NF because it causes product number, description, price, and quantity to repeat three times for each order in the table. The resulting table has many records that contain nulls in the product-related columns, and orders are limited to three products because there is no room to store information for more.
A much more efficient design (and one that conforms to 1NF) leads to a separate table to hold the repeating information; to do this, we create a separate table on the model to capture product order information. A zero-to-many relationship would then exist between the two tables. As shown in Figure 9-13, the new design eliminates nulls from the Order table and supports an unlimited number of products that can be associated with an order.
Second normal form (2NF) requires first that the data model is in 1NF and second that the data model leads to tables containing fields that depend on a whole primary key. This means that the primary key value for each record can determine the value for all the other fields in the record. Sometimes fields depend on only part of the primary key (i.e., partial dependency), and these fields belong in another table.
For example, in the new Product Order table that was created in Figure 9-13, the primary key is a combination of the order number and product number, but the product description and price attributes are dependent only upon product number. In other words, by knowing product number, we can identify the product description and price. However, knowledge of the order number and product number is required to identify the quantity. To rectify this violation of 2NF, a table is created to store product information, and the description and price attributes are moved into the new table. Now, product description is stored only once for each instance of a product number as opposed to many times (every time a product is placed on an order).
A second violation of 2NF occurs in the Order table: customer first name and last name depend only upon the customer ID, not the whole key (Cust ID and Order number). As a result, every time the customer ID appears in the Order table, the names also appear. A much more economical way of storing the data is to create a Customer table with the Customer ID as the primary key and the other customer-related fields (i.e., last name and first name) listed only once within the appropriate record. Figure 9-14 illustrates how the model would look when placed in 2NF.
Third normal form (3NF) occurs when a model is in both 1NF and 2NF and, in the resulting tables, none of the fields depend on nonprimary key fields (i.e., transitive dependency). Figure 9-14 contains a violation of 3NF: the tax rate on the order depends upon the state to which the order is being sent. The solution involves creating another table that contains state abbreviations serving as the primary key and the tax rate as a regular field. Figure 9-15 presents the end results of applying the steps of normalization to the original model from Figure 9-11.
YOUR TURN: 9-6 Normalizing a Student Activity File
Suppose that you have been asked to build a system that tracks student involvement in activities around campus. You have been given a file with information that needs to be imported into the system, and the file contains the following fields:
| student social security number | activity 1 start date |
| student last name | activity 2 code |
| student first name | activity 2 description |
| student advisor name | activity 2 start date |
| student advisor phone | activity 3 code |
| activity 1 code | activity 3 description |
| activity 1 description | activity 3 start date |
Normalize the file. Show how the logical data model would change at each step.
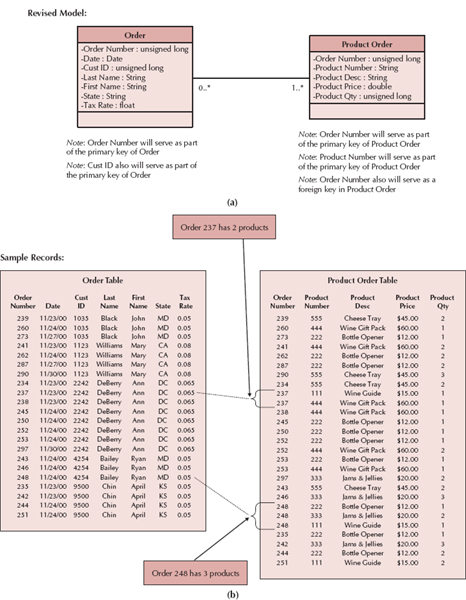
FIGURE 9-13 1NF: Remove Repeating Fields
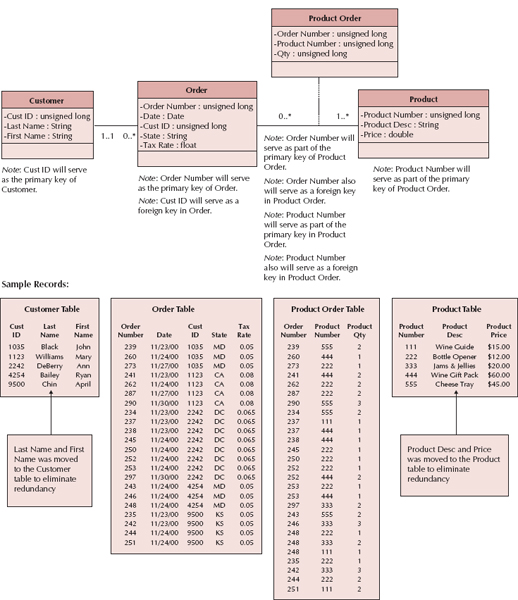
FIGURE 9-14 2NF Partial Dependencies Removed
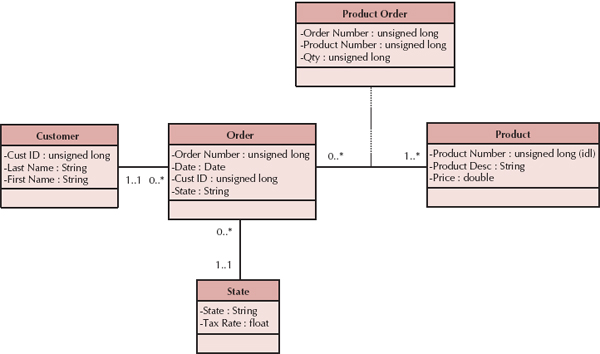
FIGURE 9-15 3NF Normalized Field
Optimizing Data Access Speed
After you have optimized the design of the object storage for efficiency, the end result is that data are spread out across a number of tables. When data from multiple tables need to be accessed or queried, the tables must be first joined. For example, before a user can print out a list of the customer names associated with orders, first the Customer and Order tables need to be joined, based on the customer number field (see Figure 9-15). Only then can both the order and customer information be included in the query's output. Joins can take a lot of time, especially if the tables are large or if many tables are involved.
Consider a system that stores information about 10,000 different products, 25,000 customers, and 100,000 orders, each averaging three products per order. If an analyst wanted to investigate whether there were regional differences in music preferences, he or she would need to combine all the tables to be able to look at products that have been ordered while knowing the state of the customers placing the orders. A query of this information would result in a huge table with 300,000 rows (i.e., the number of products that have been ordered) and 11 columns (the total number of columns from all of the tables combined).
The project team can use several techniques to try to speed up access to the data, including denormalization, clustering, and indexing.
Denormalization After the object storage is optimized, the project team may decide to denormalize, or add redundancy back into the design. Denormalization reduces the number of joins that need to be performed in a query, thus speeding up access. Figure 9-16 shows a denormalized model for customer orders. The customer last name was added back into the Order table because the project team learned during analysis that queries about orders usually require the customer last name field. Instead of joining the Order table repeatedly to the Customer table, the system now needs to access only the Order table because it contains all of the relevant information.

FIGURE 9-16 Denormalized Physical Data Model
Denormalization should be applied sparingly for the reasons described in the previous section, but it is ideal in situations in which information is queried frequently but updated rarely. There are three cases in which you may rely upon denormalization to reduce joins and improve performance. First, denormalization can be applied in the case of look-up tables, which are tables that contain descriptions of values (e.g., a table of product descriptions or a table of payment types). Because descriptions of codes rarely change, it may be more efficient to include the description along with its respective code in the main table to eliminate the need to join the look-up table each time a query is performed (see Figure 9-17a).
Second, one-to-one relationships are good candidates for denormalization. Although logically two tables should be separated, from a practical standpoint the information from both tables may regularly be accessed together. Think about an order and its shipping information. Logically, it might make sense to separate the attributes related to shipping into a separate table, but as a result the queries regarding shipping will probably always need a join to the Order table. If the project team finds that certain shipping information, such as state and shipping method, are needed when orders are accessed, they may decide to combine the tables or include some shipping attributes in the Order table (see Figure 9-17b).
Third, at times it is more efficient to include a parent entity's attributes in its child entity on the physical data model. For example, consider the Customer and Order tables in Figure 9-16, which share a one-to-many relationship, with Customer as the parent and Order as the child. If queries regarding orders continuously require customer information, the most popular customer fields can be placed in Order to reduce the required joins to the Customer table, as was done with Customer Last Name.
YOUR TURN: 9-7 Denormalizing a Student Activity File
Consider the logical data model that you created for Your Turn 9-3. Examine the model and describe possible opportunities for denormalization. How would you change the physical data model for this file, and what are the benefits of your changes?
Clustering Speed of access also is influenced by the way that the data are retrieved. Think about shopping in a grocery store. If you have a list of items to buy but you are unfamiliar with the store's layout, you need to walk down every aisle to make sure that you don't miss anything from your list. Likewise, if records are arranged on a hard disk in no particular order (or in an order that is irrelevant to your data needs), then any query of the records results in a table scan in which the DBMS has to access every row in the table before retrieving the result set. Table scans are the most inefficient of data retrieval methods.
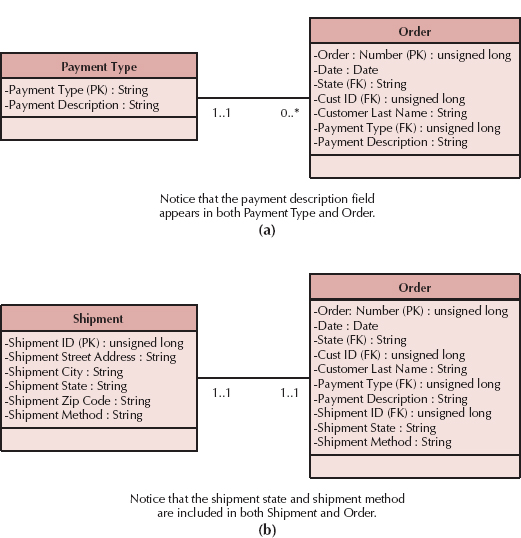
FIGURE 9-17 Denormalization Situations (FK, foreign key; PK, primary key)
One way to improve access speed is to reduce the number of times that the storage medium needs to be accessed during a transaction. One method is to cluster records together physically so that similar records are stored close together. With intrafile clustering, like records in the table are stored together in some way, such as in order by primary key or, in the case of a grocery store, by item type. Thus, whenever a query looks for records, it can go directly to the right spot on the hard disk (or other storage medium) because it knows in what order the records are stored, just as we can walk directly to the bread aisle to pick up a loaf of bread. Interfile clustering combines records from more than one table that typically are retrieved together. For example, if customer information is usually accessed with the related order information, then the records from the two tables may be physically stored in a way that preserves the customer-order relationship. Returning to the grocery store scenario, an interfile cluster would be similar to storing peanut butter, jelly, and bread next to each other in the same aisle because they are usually purchased together, not because they are similar types of items. Of course, each table can have only one clustering strategy because the records can be arranged physically in only one way.
Indexing A familiar time saver is an index located in the back of a textbook, which points directly to the page or pages that contain a topic of interest. Think of how long it would take to find all the times that relational database appears in this textbook without the index to rely on! An index in data storage is like an index in the back of a textbook; it is a minitable that contains values from one or more columns in a table and the location of the values within the table. Instead of paging through the entire textbook, we can move directly to the right pages and get the information we need. Indexes are one of the most important ways to improve database performance. Whenever there are performance problems, the first place to look is an index.
A query can use an index to find the locations of only those records that are included in the query answer, and a table can have an unlimited number of indexes. Figure 9-18 shows an index that orders records by payment type. A query that searches for all the customers who used American Express can use this index to find the locations of the records that contain American Express as the payment type without having to scan the entire Order table.
Project teams can make indexes perform even faster by placing them into the main memory of the data storage hardware. Retrieving information from memory is much faster than from another storage medium, such as a hard disk—think about how much faster it is to retrieve a memorized phone number versus one that must be looked up in a phone book. Similarly, when a database has an index in memory, it can locate records very, very quickly.

FIGURE 9-18 Payment Type Index
Of course, indexes require overhead in that they take up space on the storage medium. Also, they need to be updated as records in tables are inserted, deleted, or changed. Thus, although queries lead to faster access to the data, they slow down the update process. In general, we should create indexes sparingly for transaction systems or systems that require a lot of updates, but we should apply indexes generously when designing systems for decision support (see Figure 9-19).
CONCEPTS IN ACTION: 9-A Mail-Order Index
A Virginia-based mail-order company sends out approximately 25 million catalogs each year using a Customer table with 10 million names. Although the primary key of the Customer table is customer identification number, the table also contains an index of Customer Last Name. Most people who call to place orders remember their last name, not their customer identification number, so this index is used frequently.
An employee of the company explained that indexes are critical to reasonable response times. A fairly complicated query was written to locate customers by the state in which they lived, and it took more than three weeks to return an answer. A customer state index was created, and that same query provided a response in twenty minutes: that's 1,512 times faster!
Question
As an analyst, how can you make sure that the proper indexes have been put in place so that users are not waiting for weeks to receive the answers to their questions?
Estimating Data Storage Size
Even if we have denormalized our physical data model, clustered records, and created indexes appropriately, the system will perform poorly if the database server cannot handle its volume of data. Therefore, one last way to plan for good performance is to apply volumetrics, which means estimating the amount of data that the hardware will need to support. You can incorporate your estimates into the database server hardware specification to make sure that the database hardware is sufficient for the project's needs. The size of the database is based on the amount of raw data in the tables and the overhead requirements of the DBMS. To estimate size you will need to have a good understanding of the initial size of your database as well as its expected growth rate over time.
Raw data refers to all the data that are stored within the tables of the database, and it is calculated based on a bottom-up approach. First, write down the estimated average width for each column (field) in the table and sum the values for a total record size (see Figure 9-20). For example, if a variable-width Last Name column is assigned a width of 20 characters, you can enter 13 as the average character width of the column. In Figure 9-20, the estimated record size is 49.
Next, calculate the overhead for the table as a percentage of each record. Overhead includes the room needed by the DBMS to support such functions as administrative actions and indexes, and it should be assigned based on past experience, recommendations from technology vendors, or parameters that are built into software that was written to calculate volumetrics. For example, your DBMS vendor might recommend that you allocate 30 percent of the records’ raw data size for overhead storage space, creating a total record size of 63.7 in the Figure 9-20 example.

FIGURE 9-19 Guidelines for Creating Indexes

FIGURE 9-20 Calculating Volumetrics
Finally, record the number of initial records that will be loaded into the table, as well as the expected growth per month. This information should have been collected during analysis. According to Figure 9-20, the initial space required by the first table is 3,185,000, and future sizes can be project based on the growth figure. These steps are repeated for each table to get a total size for the entire database.
Many CASE tools provide you with database-size information based on how you set up the object persistence, and they calculate volumetrics estimates automatically. Ultimately, the size of the database needs to be shared with the design team so that the proper technology can be put in place to support the system's data and potential performance problems can be addressed long before they affect the success of the system.
CONCEPTS IN ACTION: 9-B Return on Investment from Virtualization—A Hard Factor to Determine
Many companies are undergoing server virtualization. This is the concept of putting multiple virtual servers onto one physical device. The payoffs can be significant: fewer servers, less electricity, less generated heat, less air conditioning, less infrastructure and administration costs; increased flexibility; less physical presence (i.e., smaller server rooms), faster maintenance of servers, and more. There are (of course) costs—such as licensing the virtualization software, labor costs in establishing the virtual servers onto a physical device, and labor costs in updating tables and access. But, determining the Return on Investment can be a challenge. Some companies have lost money on server virtualization, but most would say they have gained a positive return on investment with virtualization but have not really quantified the results.
Questions
- How might a company really determine the return on investment for server virtualization?
- Would server virtualization impact the amount of data storage required? Why or why not?
- Is this a project that a systems analyst might be involved in? Why or why not?
DESIGNING DATA ACCESS AND MANIPULATION CLASSES
The final step in developing the data management layer is to design the data access and manipulation classes that act as a translator between the object persistence and the problem domain objects. Thus they should always be capable of at least reading and writing both the object persistence and problem domain objects. As described earlier and in Chapter 8, the object persistence classes are derived from the concrete problem domain classes, whereas the data access and manipulation classes depend on both the object persistence and problem domain classes.
Depending on the application, a simple rule to follow is that there should be one data access and manipulation class for each concrete problem domain class. In some cases, it might make sense to create data access and manipulation classes associated with the human–computer interaction classes (see Chapter 10). However, this creates a dependency from the data management layer to the human–computer interaction layer. Adding this additional complexity to the design of the system normally is not recommended.
Returning to the ORDBMS solution for the Appointment system example (see Figure 9-8), we see that we have four problem domain classes and four ORDBMS tables. Following the previous rule, the DAM classes are rather simple. They have to support only a one-to-one translation between the concrete problem domain classes and the ORDBMS tables (see Figure 9-21). Because the Participant problem domain class is an abstract class, only three data access and manipulation classes are required: Patient-DAM, Symptom-DAM, and Appointment-DAM. However, the process to create an instance of the Patient problem domain class can be fairly complicated. The Patient-DAM class might have to be able to retrieve information from all four ORDBMS tables. To accomplish this, the Patient-DAM class retrieves the information from the Patient table. Using the Object-IDs stored in the attribute values associated with the Participant, Appts, and Symptoms attributes, the remaining information required to create an instance of Patient is easily retrieved by the Patient-DAM class.
In the case of using an RDBMS to provide persistence, the data access and manipulation classes tend to become more complex. For example, in the Appointment system, there are still four problem domain classes, but, owing to the limitations of RDBMSs, we have to support six RDBMS tables (see Figure 9-10). The data access and manipulation class for the Appointment problem domain class and the Appointment RDBMS table is no different from those supported for the ORDBMS solution (see Figures 9-21 and 9-22). However, owing to the multivalued attributes and relationships associated with the Patient and Symptom problem domain classes, the mappings to the RDBMS tables were more complicated. Consequently, the number of dependencies from the data access and manipulation classes (Patient-DAM and Symptom-DAM) to the RDBMS tables (Patient table, Insurance Carrier table, Suffer table, and the Symptom table) has increased. Furthermore, because the Patient problem domain class is associated with the other three problem domain classes, the actual retrieval of all information necessary to create an instance of the Patient class could involve joining information from all six RDBMS tables. To accomplish this, the Patient-DAM class must first retrieve information from the Patient table, Insurance Carrier table, Suffer table, and the Appointment table. Because the primary key of the Patient table and the Participant table are identical, the Patient-DAM class can either directly retrieve the information from the Participant table, or the information can be joined using the participantNumber attributes of the two tables, which act as both primary and foreign keys. Finally, using the information contained in the Suffer table, the information in the Symptom table can also be retrieved. Obviously, the farther we get from the object-oriented problem domain class representation, the more work must be performed. However, as in the case of the ORDBMS example, notice that absolutely no modifications were made to the problem domain classes. Therefore, the data access and manipulation classes again have prevented data management functionality from creeping into the problem domain classes.
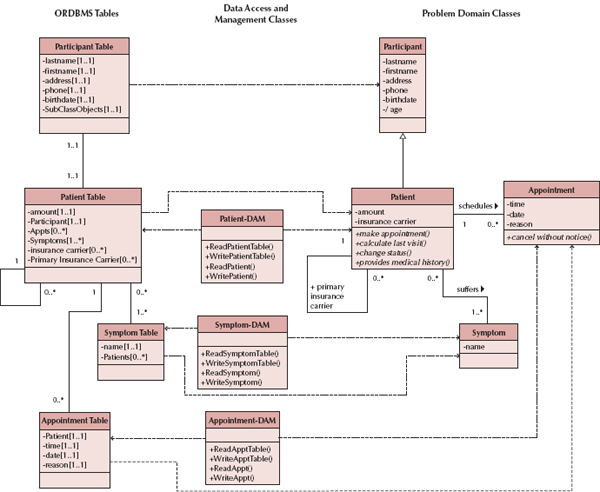
FIGURE 9-21 Managing Problem Domain Objects to ORDBMS using DAM Classes
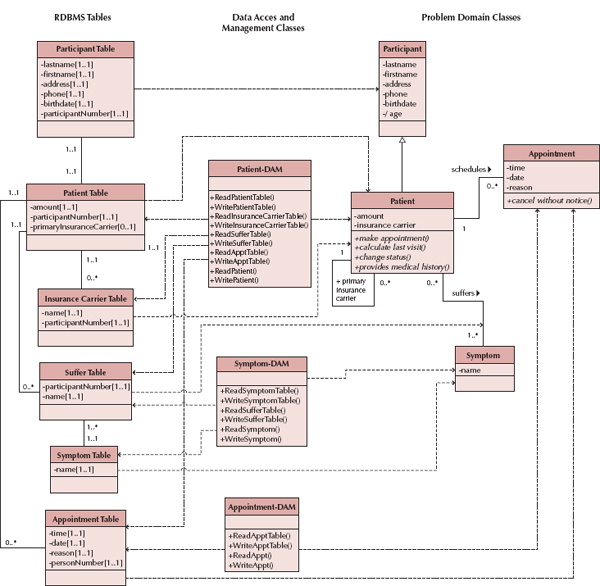
FIGURE 9-22 Mapping Problem Domain Objects to RDBMS using DAM Classes
One specific approach that has been suggested to support the implementation of data access and manipulation classes is to use an object-relational mapping library such as Hibernate.11 Hibernate developed within the JBoss community, allows the mapping of objects written in Java that are to be stored in an RDBMS. Instead of using an object-oriented programming language to implement the data access and manipulation classes, with Hibernate, they are implemented in XML files that contain the mapping. As in the above approach, modeling the mapping in an XML file prevents the details on data access and manipulation from sneaking into the problem domain representation.
NONFUNCTIONAL REQUIREMENTS AND DATA MANAGEMENT LAYER DESIGN12
Recall that nonfunctional requirements refer to behavioral properties that the system must have. These properties include issues related to performance, security, ease of use, operational environment, and reliability. In this text, we have grouped nonfunctional requirements into four categories: operational, performance, security, and cultural and political requirements. We describe each of these in relation to the data management layer.
The operational requirements for the data management layer include issues that deal with the technology being used to support object persistence. However, the choice of the hardware and operating system limits the choice of the technology and format of the object persistence available. This is especially true when you consider mobile computing. Given the limited memory and storage available on these devices, the choices to support object persistence are limited. One possible choice to support object persistence that works both on Google's Android and Apple's iOS-based platforms is SQLite. SQLite is a lightweight version of SQL that supports RDBMS. However, there are many different approaches to support object persistence that are more platform dependent; for example, Android supports storing objects with shared preferences (a key-value pair-based NoSQL approach), internal storage, on an SD card, in a local cache, or on a remote system. This, in turn, determines which set of the mapping rules described earlier will have to be used. Another operational requirement could be the ability to import and export data using XML. Again, this could limit the object stores under consideration.
The primary performance requirements that affect the data management layer are speed and capacity. As described before, depending on the anticipated—and, afterwards, actual—usage patterns of the objects being stored, different indexing and caching approaches may be necessary. When considering distributing objects over a network, speed considerations can cause objects to be replicated on different nodes in the network. Thus multiple copies of the same object may be stored in different locations on the network. This raises the issue of update anomalies described before in conjunction with normalization. Depending on the application being built, NoSQL data stores that support an eventually consistent update model may be appropriate. Also, depending on the estimated size and growth of the system, different DBMSs may need to be considered. An additional requirement that can affect the design of the data management layer deals with the availability of the objects being stored. It might make sense to limit the availability to different objects based on the time of day. For example, one class of users may be allowed to access a set of objects only from 8 to 12 in the morning and a second set of users may be able to access them only from 1 to 5 in the afternoon. Through the DBMS, these types of restrictions could be set.
The security requirements deal primarily with access controls, encryption, and backup. Through a modern DBMS, different types of access can be set (e.g., Read, Update, or Delete) granting access only to users (or class of users) who have been authorized. Furthermore, access control can be set to guarantee that only users with “administrator” privileges are allowed to modify the object storage schema or access controls. Encryption requirements on this layer deal with whether the object should be stored in an encrypted format or not. Even though encrypted objects are more secure than unencrypted objects, the process of encrypting and decrypting the objects will slow down the system. Depending on the physical architecture being used, the cost of encryption may be negligible. For example, if we plan on encrypting the objects before transmitting them over a network, there may be no additional cost of storing them in the encrypted format. Backup requirements deal with ensuring that the objects are routinely copied and stored in case the object store becomes corrupted or unusable. Having a backup copy made on a periodic basis and storing the updates that have occurred since the last backup copy was made ensures that the updates are not lost and the object store can be reconstituted by running the copies of the updates against the backup copy to create a new current copy.
The only political and cultural requirements that can affect the data management layer deal with how the detailed format of the data is to be stored. For example, in what format should a date be stored? Or how many characters should be allocated for a last name field that is part of an Employee object? There could be a corporate IT bias toward different hardware and software platforms. If so, this could limit the type of object store available.
APPLYING THE CONCEPTS AT CD SELECTIONS
In the previous installments of the CD Selections case, we saw how Alec, Margaret, and the development team had worked through developing models and designs of the problem domain classes. Now that the design of the problem domain layer is somewhat stable, the team has moved into developing the models and designs of the solution domain (data management, human–computer interaction, and physical architecture) classes. In this installment, we follow the team members that have been assigned to the development of the data management layer classes for the Web-based system being developed for CD Selections.
SUMMARY
Object Persistence Formats
There are five basic types of object persistence formats: files (sequential and random access), object-oriented databases, object-relational databases, relational databases, and NoSQL data stores. Files are electronic lists of data that have been optimized to perform a particular transaction. There are two different access methods (sequential and random), and there are five different application types: master, look-up, transaction, audit, and history. Master files typically are kept for long periods of time because they store important business information, such as order information or customer mailing information. Look-up files contain static values that are used to validate fields in the master files, and transaction files temporarily hold information that will be used for a master file update. An audit file records before and after images of data as they are altered so that an audit can be performed if the integrity of the data is questioned. Finally, the history file stores past transactions (e.g., old customers, past orders) that are no longer needed by the system.
A database is a collection of information groupings related to one another in some way, and a DBMS (database management system) is software that creates and manipulates databases. There are three types of databases that are likely to be encountered during a project: relational, object-relational, and object-oriented. The relational database is the most popular kind of database for application development today. It is based on collections of tables that are related to each other through common fields, known as foreign keys. Object-relational databases are relational databases that have extensions that provide limited support for object orientation. The extensions typically include some support for the storage of objects in the relational table structure. Object-oriented databases come in two flavors: full-blown DBMS products and extensions to an object-oriented programming language. Both approaches typically fully support object orientation. Finally, NoSQL data stores represent a new class of approaches to support object persistence. These include key-value stores, document stores, column-oriented stores, and object databases.
The application's data should drive the storage format decision. Relational databases support simple data types very effectively, whereas object databases are best for complex data. The type of system also should be considered when choosing among data storage formats (e.g., relational databases have matured to support transactional systems). Although less critical to the format selection decision, the project team needs to consider what technology exists within the organization and the kind of technology likely to be used in the future.
Mapping Problem Domain Objects to Object Persistence Formats
There are many different approaches to support object persistence. Each of the different formats for object persistence has some conversion requirements. The complexity of the conversion requirements increases the farther the format is from an object-oriented format. An OODBMS has the fewest conversion requirements, whereas an RDBMS tends to have the most. No matter what format is chosen, all data management functionality should be kept out of the problem domain classes to minimize the maintenance requirements of the system and to maximize the portability and reusability of the problem domain classes.
Optimizing RDBMS-Based Object Storage
There are two primary dimensions by which to optimize a relational database: storage efficiency and speed of access. The most efficient relational database tables in terms of data storage are those that have no redundant data and very few null values. Normalization is the process whereby a series of rules are applied to the data management layer to determine how well it is formed. A model is in first normal form (1NF) if it does not lead to repeating fields, which are fields that repeat within a table to capture multiple values. Second normal form (2NF) requires that all tables be in 1NF and lead to fields whose values are dependent on the whole primary key. Third normal form (3NF) occurs when a model is in both 1NF and 2NF and none of the resulting fields in the tables depend on nonprimary key fields (i.e., transitive dependency). With each violation, additional tables should be created to remove the repeating fields or improper dependencies from the existing tables.
Once we have optimized the design of the object persistence for storage efficiency, the data may be spread out across a number of tables. To improve speed, the project team may decide to denormalize—add redundancy back into—the design. Denormalization reduces the number of joins that need to be performed in a query, thus speeding up data access. Denormalization is best in situations where data are accessed frequently and updated rarely. Three modeling situations are good candidates for denormalization: lookup tables, entities that share one-to-one relationships, and entities that share one-to-many relationships. In all three cases, attributes from one entity are moved or repeated in another entity to reduce the joins that must occur while accessing the database.
Clustering occurs when similar records are stored close together on the storage medium to speed up retrieval. In intrafile clustering, similar records in the table are stored together in some way, such as in sequence. Interfile clustering combines records from more than one table that typically are retrieved together. Indexes also can be created to improve the access speed of a system. An index is a minitable that contains values from one or more columns in a table and tells where the values can be found. Instead of performing a table scan, which is the most inefficient way to retrieve data from a table, an index points directly to the records that match the requirements of a query.
Finally, the speed of the system can be improved if the right hardware is purchased to support it. Analysts can use volumetrics to estimate the current and future size of the database and then share these numbers with the people who are responsible for buying and configuring the database hardware.
Designing Data Access and Manipulation Classes
Once the object persistence has been designed, a translation layer between the problem domain classes and the object persistence should be created. The translation layer is implemented through data access and manipulation classes. In this manner, any changes to the object persistence format chosen will require changes only to the data access and manipulation classes. The problem domain classes will be completely isolated from the changes. One popular approach to supporting data access and manipulation classes is through the use of a mapping library such as Hibernate.
Nonfunctional Requirements and Data Management Layer Design
Nonfunctional requirements can affect the design of the data management layer. Operational requirements can limit the viability of different object persistence formats. Performance requirements can cause various indexing and caching approaches to be considered. Furthermore, performance requirements can create situations where denormalization must be considered. Performance considerations are especially important in the area of mobile computing. The security requirements can cause the design to include varying types of access to be controlled and the possibility of using different encryption algorithms to make the data more difficult to use by unauthorized users. Finally, political and cultural concerns can influence the design of certain attributes and objects.
KEY TERMS
- Access control, 405
- Attribute sets, 375
- Audit file, 372
- Cluster, 398
- Column-oriented data stores, 376
- Data access and manipulation classes, 401
- Data management layer, 368
- Database, 369
- Database management system (DBMS), 369
- Decision support systems (DSS), 378
- Denormalization, 396
- Document data stores, 376
- End user DBMS, 369
- Enterprise DBMS, 369
- Executive information systems (EIS), 378
- Expert system (ES), 378
- Extent, 375
- File, 368
- First normal form (1NF), 392
- Foreign key, 372
- Hardware and operating system, 405
- History file, 372
- Impedance mismatch, 378
- Index, 399
- Interfile clustering, 398
- Intrafile clustering, 398
- Join, 374
- Key-value data stores, 376
- Linked list, 371
- Lookup file, 372
- Management information system (MIS), 378
- Master file, 371
- Multivalued attributes (fields), 375
- Normalization, 390
- NoSQL data stores, 375
- Object ID, 375
- Object-oriented database management system (OODBMS), 374
- Object-oriented programming language (OOPL), 375
- Object persistence, 368
- Object-relational database management system (ORDBMS), 374
- Operational requirements, 405
- Ordered sequential access file, 371
- Overhead, 400
- Partial dependency, 393
- Performance requirements, 405
- Pointer, 371
- Political and cultural requirements, 406
- Primary key, 372
- Problem domain classes, 402
- Random access files, 371
- Raw data, 400
- Referential integrity, 372
- Relational database management system (RDBMS), 372
- Repeating groups (fields), 375
- Second normal form (2NF), 393
- Security requirements, 405
- Sequential access files, 371
- Structured query language (SQL), 374
- Table scan, 398
- Third normal form (3NF), 393
- Transaction file, 372
- Transaction-processing system, 378
- Transitive dependency, 393
- Unordered sequential access file, 371
- Update anomaly, 390
- Volumetrics, 400
QUESTIONS
- Describe the four steps in object persistence design.
- How are a file and a database different from each other?
- What is the difference between an end-user database and an enterprise database? Provide an example of each one.
- What are the differences between sequential and random access files?
- Name five types of files and describe the primary purpose of each type.
- What is the most popular kind of database today? Provide three examples of products that are based on this database technology.
- What is referential integrity and how is it implemented in an RDBMS?
- List some of the differences between an ORDBMS and an RDBMS.
- What are the advantages of using an ORDBMS over an RDBMS?
- List some of the differences between an ORDBMS and an OODBMS.
- What are the advantages of using an ORDBMS over an OODBMS?
- What are the advantages of using an OODBMS over an RDBMS?
- What are the advantages of using an OODBMS over an ORDBMS?
- What are the factors in determining the type of object persistence format that should be adopted for a system? Why are these factors so important?
- Why should you consider the storage formats that already exist in an organization when deciding upon a storage format for a new system?
- When implementing the object persistence in an ORDBMS, what types of issues must you address?
- When implementing the object persistence in an RDBMS, what types of issues must you address?
- Name three ways null values can be interpreted in a relational database. Why is this problematic?
- What are the two dimensions in which to optimize a relational database?
- What is the purpose of normalization?
- How does a model meet the requirements of third normal form?
- Describe three situations that can be good candidates for denormalization.
- Describe several techniques that can improve performance of a database.
- What is the difference between interfile and intrafile clustering? Why are they used?
- What is an index and how can it improve the performance of a system?
- Describe what should be considered when estimating the size of a database.
- Why is it important to understand the initial and projected size of a database during design?
- What are some of the nonfunctional requirements that can influence the design of the data management layer?
- What are the key issues in deciding between using perfectly normalized databases and denormalized databases?
- What is the primary purpose of the data access and manipulation classes?
- Why should the data access and manipulation classes be dependent on the problem domain classes instead of the other way around?
- Why should the object persistence classes be dependent on the problem domain classes instead of the other way around?
EXERCISES
- A. Using the Web or other resources, identify a product that can be classified as an end-user database and a product that can be classified as an enterprise database. How are the products described and marketed? What kinds of applications and users do they support? In what kinds of situations would an organization choose to implement an end-user database over an enterprise database?
- B. Visit a commercial website (e.g., Amazon.com). If files were being used to store the data supporting the application, what types of files would be needed? What access type would be required? What data would they contain?
- C. Using the Web, review one of the following products. What are the main features and functions of the software? In what companies has the DBMS been implemented, and for what purposes? According to the information that you found, what are three strengths and weaknesses of the product?
- Relational DBMS
- Object-relational DBMS
- Object-oriented DBMS
- D. You have been given a file that contains the following fields relating to CD information. Using the steps of normalization, create a model that represents this file in third normal form. The fields include:
Musical group name CD title 2 Musicians in group CD title 3 Date group was formed CD 1 length Group's agent CD 2 length CD title 1 CD 3 length Assumptions:
- Musicians in group contains a list of the members of the people in the musical group.
- Musical groups can have more than one CD, so both group name and CD title are needed to uniquely identify a particular CD.
- E. Jim Smith's dealership sells Fords, Hondas, and Toyotas. The dealership keeps information about each car manufacturer with whom they deal so that they can get in touch with them easily. The dealership also keeps information about the models of cars that they carry from each manufacturer. They keep information like list price, the price the dealership paid to obtain the model, and the model name and series (e.g., Honda Civic LX). They also keep information about all sales that they have made (instance.g., they record a buyer's name, the car bought, and the amount paid for the car). To contact the buyers in the future, contact information is also kept (e.g., address, phone number). Create a class diagram for this situation. Apply the rules of normalization to the class diagram to check the diagram for processing efficiency.
- F. Describe how you would denormalize the model that you created in exercise E. Draw the new class diagram based on your suggested changes. How would performance be affected by your suggestions?
- G. Examine the model that you created in exercise F. Develop a clustering and indexing strategy for this model. Describe how your strategy will improve the performance of the database.
- H. Calculate the size of the database that you created in exercise F. Provide size estimates for the initial size of the database as well as for the database in one year's time. Assume that the dealership sells ten models of cars from each manufacturer to approximately 20,000 customers a year. The system will be set up initially with one year's worth of data.
- L. For the A Real Estate Inc. problem in Chapter 4 (exercises I, J, and K), Chapter 5 (exercises P and Q), Chapter 6 (exercise D), Chapter 7 (exercise A), and Chapter 8 (exercise A):
- Apply the rules of normalization to the class diagram to check the diagram for processing efficiency.
- Develop a clustering and indexing strategy for this model. Describe how your strategy will improve the performance of the database.
- M. For the A Video Store problem in Chapter 4 (exercises L, M, and N), Chapter 5 (exercises R and S), Chapter 6 (exercise E), Chapter 7 (exercise B), and Chapter 8 (exercise B):
- Apply the rules of normalization to the class diagram to check the diagram for processing efficiency.
- Develop a clustering and indexing strategy for this model. Describe how your strategy will improve the performance of the database.
- N. For the gym membership problem in Chapter 4 (exercises O, P, and Q), Chapter 5 (exercises T and U), Chapter 6 (exercise F), Chapter 7 (exercise C), and Chapter 8 (exercise C):
- Apply the rules of normalization to the class diagram to check the diagram for processing efficiency.
- Develop a clustering and indexing strategy for this model. Describe how your strategy will improve the performance of the database.
- O. For the Picnics R Us problem in Chapter 4 (exercises R, S, and T), Chapter 5 (exercises V and W), Chapter 6 (exercise G), Chapter 7 (exercise D), and Chapter 8 (exercise D):
- Apply the rules of normalization to the class diagram to check the diagram for processing efficiency.
- Develop a clustering and indexing strategy for this model. Describe how your strategy will improve the performance of the database.
- N. For the Of-the-Month-Club problem in Chapter 4 (exercises U, V, and W), Chapter 5 (exercises X and Y), Chapter 6 (exercise H), Chapter 7 (exercise E), and Chapter 8 (exercise E):
- Apply the rules of normalization to the class diagram to check the diagram for processing efficiency.
- Develop a clustering and indexing strategy for this model. Describe how your strategy will improve the performance of the database.
MINICASES
- The system development team at the Wilcon Company is working on developing a new customer order entry system. In the process of designing the new system, the team has identified the following class and its attributes:
Inventory Order
Order Number (PK)
Order Date
Customer Name
Street Address
City
State
Zip
Customer Type
Initials
District Number
Region Number
1 to 22 occurrences of:
Item Name
Quantity Ordered
Item Unit
Quantity Shipped
Item Out
Quantity Received
- State the rule that is applied to place a class in first normal form. Based on the above class, create a class diagram that will be in 1NF.
- State the rule that is applied to place a class into second normal form. Revise the class diagram for the Wilcon Company using the class and attributes described (if necessary) to place it in 2NF.
- State the rule that is applied to place a class into third normal form. Revise the class diagram to place it in 3NF.
- When planning for the physical design of this database, can you identify any likely situations where the project team might choose to denormalize the class diagram? After going through the work of normalizing, why would this be considered?
- In the new system under development for Holiday Travel Vehicles, seven tables will be implemented in the new relational database. These tables are: New Vehicle, Trade-in Vehicle, Sales Invoice, Customer, Salesperson, Installed Option, and Option. The expected average record size for these tables and the initial record count per table are given here.

Perform a volumetrics analysis for the Holiday Travel Vehicle system. Assume that the DBMS that will be used to implement the system requires 35 percent overhead to be factored into the estimates. Also, assume a growth rate for the company of 10 percent per year. The systems development team wants to ensure that adequate hardware is obtained for the next three years.
- Refer to the Professional and Scientific Staff Management (PSSM) minicase in Chapters 4, 6, 7, and 8.
- Apply the rules of normalization to the class diagram to check the diagram for processing efficiency.
- Develop a clustering and indexing strategy for this model. Describe how your strategy will improve the performance of the database.
1 There are other types of files, such as relative, indexed sequential, and multi-indexed sequential, and databases, such as hierarchical, network, and multidimensional. However, these formats typically are not used for object persistence.
2 For example, see the FileInputStream, FileOutputStream, and RandomAccessFile classes in the java.io package.
3 For a more complete coverage of issues related to the design of files, see Owen Hanson, Design of Computer Data Files (Rockville, MD: Computer Science Press, 1982).
4 For more information on various data structures see Ellis Horowitz and Sartaj Sahni, Fundamentals of Data Structures (Rockville, MD: Computer Science Press, 1982); and Michael T. Goodrich and Roberto Tamassia, Data Structures and Algorithms in Java (New York: Wiley, 1998).
5 For a more-detailed look at the underlying data and file structures of the different types of files, see Mary E. S. Loomis, Data Management and File Structures, 2nd ed. (Englewood Cliffs, NJ: Prentice Hall, 1989); and Michael J. Folk and Bill Zoeellick, File Structures: A Conceptual Toolkit (Reading, MA: Addison-Wesley, 1987).
6 See www.odbms.org for more information.
7 Depending on the storage and updating requirements, it usually is a good idea to use a foreign key in addition to the Object ID. The Object ID has no semantic meaning. Therefore, in the case of needing to rebuild relationships between objects, Object IDs are difficult to validate. Foreign keys, by contrast, should have some meaning outside of the DBMS.
8 The rules presented in this section are based on material in Ali Bahrami, Object-Oriented Systems Development using the Unified Modeling Language (New York: McGraw-Hill, 1999); Michael Blaha and William Premerlani, Object-Oriented Modeling and Design for Database Applications (Upper Saddle River, NJ: Prentice Hall, 1998); Akmal B. Chaudri and Roberto Zicari, Succeeding with Object Databases: A Practical Look at Today's Implementations with Java and XML (New York: Wiley, 2001); Peter Coad and Edward Yourdon, Object-Oriented Design (Upper Saddle River, NJ: Yourdon Press, 1991); and Paul R. Read, Jr., Developing Applications with Java and UML (Boston: Addison-Wesley, 2002).
9 It is also a good idea to document this modification in the design so that in the future, modifications to the design can be easily maintained.
10 Normalization also can be performed on the problem domain layer. However, the normalization process should be used on the problem domain layer only to uncover missing classes. Otherwise, optimizations that have nothing to do with the semantics of the problem domain can creep into the problem domain layer.
11 For more information on Hibernate, see www.hibernate.org/.
12 Because the vast majority of nonfunctional requirements affect the physical architecture layer, we provide additional details in Chapter 11.