
3.5 Firm's Performance (LTV, CLV, and CE)
Making customer acquisition selection decisions on the basis of the response probability, initial order quantity, and duration is not enough. Companies should select prospects to acquire based on their lifetime contribution, which can be termed as LTV, CLV, or CE. Hansotia and Wang [5] in the last scenario of their studies considered that prospects' LTV varied due to their profiles and the promotion packages they received. These authors modeled the present value of revenue (PVR) and estimated LTV by subtracting the present value of cost of goods and the estimated marketing and operation costs for that customer. A common issue that occurs in the estimation of CLV is that observations may be right-censored. Some of the customers may have already lapsed in the observation period while others may still use the product or service beyond the observation period. Estimating the lifetime value of the customers who are still active over the observation period by OLS regression may underestimate their lifetime contribution to the companies. Hansotia and Wang [5] used the Tobit model to estimate the PVR for customers. The Tobit model assumes that there is a latent variable ![]() which linearly depends on
which linearly depends on ![]() via a vector of parameters
via a vector of parameters ![]() . And there is a normally distributed error
. And there is a normally distributed error ![]() to capture the random fluctuation of the relationship. For the right-censored situation in which censoring occurs above a value
to capture the random fluctuation of the relationship. For the right-censored situation in which censoring occurs above a value ![]() , the Tobit model is
, the Tobit model is
(3.26) 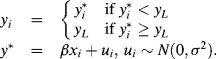
The authors did not restrict the latent variables having a normal distribution but chose from a set of distributions including the gamma, log-normal, logistic, and Weibull distributions. In their studies, the authors presented the likelihood function, which is the probability of observing the sample values, as
(3.27) ![]()
where ![]() if observation
if observation ![]() is uncensored, 0 otherwise. The authors estimated the Tobit model using the method of maximum likelihood by the Lifereg procedure in SAS. We provide the introduction and estimation of the type 1 Tobit model in Appendix appE. For the other types of Tobit models, readers should refer to Amemiya (1985).
is uncensored, 0 otherwise. The authors estimated the Tobit model using the method of maximum likelihood by the Lifereg procedure in SAS. We provide the introduction and estimation of the type 1 Tobit model in Appendix appE. For the other types of Tobit models, readers should refer to Amemiya (1985).
In non-contractual settings, customers can terminate the relationship with companies without any notice. Thus, it is not easy to identify whether the customers have lapsed or not and whether the observation is censored or not. Reinartz et al. [7] considered that the account is still active and the duration is right-censored if the expected time until the next purchase exceeds the recency since last purchase. Using the data from a B2B high-tech manufacturer, Reinartz et al. [7] adopted a standard right-censored Tobit model to estimate the duration with independent variables including the estimated response probability. These authors further estimated customer profitability with a standard right-censored Tobit model using a set of exogenous variables and including the predicted duration and response probability. Similar to Reinartz et al. [7], Thomas et al. [8] developed an ARPRO (Acquisition, Retention, and PROfitability) model which uses a standard right-censored Tobit model to estimate and predict the total long-term customer profitability as a function of both the customer's predicted relationship duration and acquisition probability. The authors found that decreasing marketing spending for a B2B firm and catalog retailer and increasing spending to customers for a pharmaceutical firm would lead to increases in total customer profitability.
In an online grocery retailing industry, Lewis [4] separated customers' purchase activities in the observation period into three quarters, each quarter's activities expressed as RFM measures. The author used a Tobit model to estimate the three-quarter activity as a function of second-quarter RFM scores. The estimated model was then used to predict the fourth-quarter activity and the customer asset value was then calculated as a total of observed expenditures and the predicted fourth-quarter activity.
Blattberg and Deighton [9] proposed to find the optimal level of acquisition spending based on the maximization of first-year value. These authors solved this issue using a tool called decision calculus, an approach to decision making in which managers break down a complex problem into smaller and simpler problems which are then incorporated into a model to solve the original complex problem. To calculate the optimal level of acquisition spending that maximizes first-year value, the authors asked managers four questions to determine the acquisition expenditure per prospect $A, the acquisition rate obtained as a result of that expenditure a, the ceiling rate (the highest possible number of customers the company could reasonably acquire in a given time period), and the margin generated by a customer in a year $m. The authors then drew a curve of the actual acquisition probability from the equation
(3.28) ![]()
where ![]() is a constant that controls the steepness of the curve. Next, the authors calculated the net contribution from acquiring a prospect in the first year
is a constant that controls the steepness of the curve. Next, the authors calculated the net contribution from acquiring a prospect in the first year ![]() and drew the second curve showing how the average value of acquired customers in the first year varies with spending on acquisition. Combing the two curves, the authors found the optimal level of acquisition spending at the peak of the second curve where acquisition should stop.
and drew the second curve showing how the average value of acquired customers in the first year varies with spending on acquisition. Combing the two curves, the authors found the optimal level of acquisition spending at the peak of the second curve where acquisition should stop.
The fundamental question encountered in managing customer acquisition is to model the probability of being acquired for customers. The logit or probit model is the most common method used since they are by nature used to model binary outcomes, such as being acquired or not. In addition, logit or probit models are used to examine the effect of different customer characteristics and purchase behavior on the probability. In some circumstances, researchers may want to model several acquisition metrics together, such as the number of newly acquired customers and the initial order quantity, and systems of linear regression are able to complete the task. In addition, it is possible that the acquisition metrics, such as the number of customers acquired through promotion and through networking, and company profitability, are correlated and variant across time, and VAR is a suitable modeling method to account for the correlation and time effects. Furthermore, researchers may want to model the duration of newly acquired customers and determine the effects that various explanatory variables have on the time to defect. Since most of the duration data contain censored observations, OLS regression would provide biased estimates. A classic parametric method for survival data is the accelerated failure time model, which can be estimated by the method of maximum likelihood. The variation of the accelerated failure time model, depending on the assumption of its disturbance distribution, such as the Weibull, exponential, gamma, log-logistic and log-normal distribution, is often used in duration modeling. Customer acquisition leads to firm profitability, which is the metric researchers have a strong interest to model. CLV is often used to represent firm profitability achievement and capability, and researchers often have to encounter censored observations while modeling CLV. Tobit models are essentially suitable methods in the modeling and have gained extensive popularity. Besides stochastic methods, researchers have used deterministic methods, such as decision calculus, to determine the optimal level of acquisition spending for profit maximization.
3.5.1 Empirical Example: Firm's Performance
The final step of the analysis is to determine whether the customers that were acquired are profitable. We also want to know whether we can determine the drivers of the customer profitability to see if future acquisition efforts can help lead to acquire a larger number of profitable customers. At the end of this example we should be able to:
The information we will need for this model includes the following list of variables for the 292 prospects that became customers (Acquisition = 1):
| Dependent variables | |
| Censor | 1 if the customer was still a customer at the end of the observation window, 0 otherwise |
| CLV | The predicted customer lifetime value score. It is 0 if the prospect was not acquired or has already churned from the firm (000s) |
| Independent variables | |
| Acq_Expense | Dollars spent on marketing efforts to try and acquire that prospect |
| Lambda(λ) | The computed inverse Mills ratio from the acquisition model |
| Acq_Expense_SQ | Square of dollars spent on marketing efforts to try and acquire that prospect |
| Ret_Expense | Dollars spent on marketing efforts to try and retain that customer |
| Ret_Expense_SQ | Square of dollars spent on marketing efforts to try and retain that customer |
| First_Purchase | Dollar value of the first purchase (0 if the customer was not acquired) |
| Crossbuy | The number of categories the customer has purchased |
| Frequency | The number of times the customer purchased during the observation window |
| Frequency_SQ | The square of the number of times the customer purchased during the observation window |
| Industry | 1 if the prospect is in the B2B industry, 0 otherwise |
| Revenue | Annual sales revenue of the prospect's firm (in millions of dollars) |
| Employees | Number of employees in the prospect's firm |
In this case we have two dependent variables. One dependent variable, called Censor, helps us to delineate between those customers who are still customers and those customers who have already left the firm. Our second dependent variable is called CLV, or customer lifetime value. For the sake of this example the CLV score (in thousands) for each of the acquired customers has been predicted for you. Since CLV is a forward-looking measure (i.e., it measures the expected future profitability of a customer), the only customers with a CLV score are those who are still customers with the firm. These are the customers who meet the following two criteria – they have a value of 1 for Acquisition and a value of 1 for Censor.
Similar to the example for initial purchase quantity, we need to take into account both the probability that the customer is still a customer (Censor) and the expected future profitability of the customer (CLV). To do this we get the following equation:
![]()
In this case we also recognize that we will have to account for potential sample selection bias and estimate the model in a two-stage framework. Again, similar to the modeling framework for initial order quantity, we first model Censor as a probit using all of the independent variables. Then, we compute the inverse Mills ratio for those customers who have Censor = 1. Finally, we run an OLS regression with CLV as the dependent variable only for the 135 customers who are still customers. We use all the independent variables listed and the inverse Mills ratio (λ). See the initial order quantity example for a more detailed description of the steps. We get the following results:


We gain the following insights from the results. We see that λ is positive, but not significant. Thus we cannot interpret this to mean that there is not a selection problem, only that it is unlikely given that the error term of our selection equation is not correlated with the error term of our regression equation. We also see that with the exception of Employees, the remaining variables in the CLV model are all significant at p < 0.05. This means that we have uncovered many of the key drivers of CLV for this set of customers. We find that Acq_Expense and Ret_Expense are positive with a diminishing return, as noted by the positive coefficient on the level term and the negative coefficient on the squared term. This suggests that the more you spend on both acquisition and retention efforts, up to a threshold, the higher the customer's expected lifetime value. For First_ Purchase we see that there is a positive coefficient suggesting that the higher the initial purchase amount, the higher the expected customer lifetime value. For Crossbuy we see that there is a positive coefficient suggesting that the more products a customer purchases, the higher the expected lifetime value. We find that Frequency is positive with a diminishing return, as noted by the positive coefficient on the level term and the negative coefficient on the squared term. This suggests that customers who purchase consistently at a moderate rate over their tenure are most likely to have the highest lifetime value. Then in terms of firmographic variables we find that customers who are B2B (Industry) and customers who have higher Revenue are more likely to have a higher lifetime value than customers who are not in the B2B Industry and have a lower Revenue.
Our next step is to predict CLV for each of the customers and see if our predictions are accurate. We do this by starting with the equation for expected future profitability at the beginning of this example:
![]()
In this case Φ is the normal CDF, X is the matrix of independent variable values from the Censor equation, β is the vector of parameter estimates from the Censor equation, γ is the matrix of independent variables from the CLV equation, α is the vector of parameter estimates from the CLV equation, μ is the parameter estimate for the inverse Mills ratio, and λ is the inverse Mills ratio. Once we have predicted the CLV value for each of the prospects we want to compare this to the actual value from the database.
We do the comparison for the CLV values of the 135 customers where Censor = 1, that is, the customers that are still active with the firm. We find for these data that the MAD is 0.29 (or $290) and the MAPE is 4.5%. For our benchmark model we use the mean of 6.58 as our predicted value for each customer. In this case we get a MAD of 0.71 (or $710) and a MAPE of 11.05%. We see that our CLV model provides a significant better prediction of CLV than the benchmark model. This shows that identifying the drivers of CLV can significantly help a firm understand which customers are most likely to be profitable in the future.
3.5.2 How Do You Implement it?
Similar to the example for initial order quantity, we use a two-stage modeling framework. We first use a binary probit model using PROC Logistic and a probit link function to model the probability that a customer has already quit. Next, we use a SAS Data step to compute the inverse Mills ratio. Finally, we use PROC Reg in SAS to determine the drivers of CLV. Other statistical programs such as SPSS can be used to run these two-stage least squares models.