
5.2 Acquisition and Retention
Customer acquisition and customer retention are two processes that are essentially correlated. Researchers have modeled these two issues both separately and together. Lewis [5] investigated whether shipping fees differentially influence customer acquisition and retention. In a system of simultaneous equations, the author examined the effects shipping fees and other marketing variables on the number of new customers acquired the average order size for new customers, and the number of daily orders and the average order size for established customer. The models were estimated in a system because the dependent variables were possibly correlated. Furthermore, to account for the possible correlation between various equations and the possibility of endogenously determined explanatory variables, the author estimated the equations using three-stage least squares. Lagged measures of the endogenous variables, such as prices and average order size, were used as instruments in the estimation.
In another study, Lewis [6] investigated the influence of customer acquisition promotion depth on customer retention, including repeat purchasing and the time being a customer. In an online retailing setting, the author adopted a logistic regression to model whether the customer makes subsequent purchases within the next three quarters using acquisition discount as an explanatory variable. In a newspaper subscription setting, the author adopted accelerated failure time models to model the time as a subscriber using acquisition discount and its quadratic form as an explanatory variable. The author further examined the effects of acquisition discount on customer asset value.
Extending the proposed model by Blattberg and Deighton [4], Berger and Nasr-Bechwati [2] optimized the allocation of the promotion budget between acquisition spending and retention spending. The latter authors considered several different market situations, while here we only report the simplest situation. When companies are considering one market segment and using one promotion method, such as direct mailing, managers decide the allocation of existing budget between acquisition and retention to maximize customer equity. Following Blattberg and Deighton [4],
while
where ![]() is the average budget per prospect. These authors multiplied
is the average budget per prospect. These authors multiplied ![]() by the acquisition rate because a firm can only retain customers that have been acquired. The problem is to maximize the objective function which can also be expressed as a function of
by the acquisition rate because a firm can only retain customers that have been acquired. The problem is to maximize the objective function which can also be expressed as a function of ![]() because
because
(5.1) ![]()
Thus, managers just need to decide the acquisition spending to obtain the maximized customer equity by nonlinear programming.
Researchers have also considered methods to link customer acquisition and retention together instead of treating them as independent variables. Thomas [1] proposed a method known as a Tobit model with selection to account for the impact that the customer acquisition process has on the retention process. The standard right-censored Tobit model was specified as
(5.2) 
where ![]() is the index variable,
is the index variable, ![]() the length of customer i's lifetime,
the length of customer i's lifetime, ![]() the censoring point for customer i (the customer's maximum observable lifetime),
the censoring point for customer i (the customer's maximum observable lifetime), ![]() the vector of covariates affecting the length of the customer's lifetime,
the vector of covariates affecting the length of the customer's lifetime, ![]() , and
, and ![]() is the segment (
is the segment (![]() ). The corresponding conditional likelihood for any individual in segment s is as follows:
). The corresponding conditional likelihood for any individual in segment s is as follows:
(5.3) ![]()
where ![]() is the likelihood function for individual i given that he/she is in segment s,
is the likelihood function for individual i given that he/she is in segment s, ![]() the right-censoring indicator (1 = observation i is right-censored, 0 = not right-censored),
the right-censoring indicator (1 = observation i is right-censored, 0 = not right-censored), ![]() the standard normal cumulative distribution function,
the standard normal cumulative distribution function, ![]() the standard normal density function,
the standard normal density function, ![]() the value of the censoring variable for observation i,
the value of the censoring variable for observation i, ![]() the standard deviation of the Tobit error term, and
the standard deviation of the Tobit error term, and ![]() .
.
The author added truncation to the specification and obtained what is known as a Tobit model with selection as
(5.4) 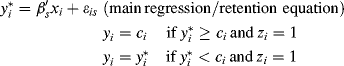
and
(5.5) 
where ![]() is the length of customer i's lifetime,
is the length of customer i's lifetime, ![]() the index variable,
the index variable, ![]() customer i's unobserved utility,
customer i's unobserved utility, ![]() the acquisition of customer i (1 = acquired, 0 = not acquired),
the acquisition of customer i (1 = acquired, 0 = not acquired), ![]() a vector of covariates affecting the retention of customer i,
a vector of covariates affecting the retention of customer i, ![]() a vector of covariates affecting the acquisition of customer i, and s the segment (1, 2,..., S). The proposed model successfully links customer acquisition to retention because the length of the customer's lifetime is observed conditional on the customer being acquired, and because the error term in the acquisition equation is possibly correlated with that in the retention equation. The author asserted that the proposed model is similar to the two-step procedure which combines a binary probit model with a standard Tobit model. But the two-step procedure is not applicable here since the information of non-acquired customers is not available. The author asserted that the proposed model could be consistently estimated with maximum likelihood estimation [7]. The estimation details are recorded in Appendix A.
a vector of covariates affecting the acquisition of customer i, and s the segment (1, 2,..., S). The proposed model successfully links customer acquisition to retention because the length of the customer's lifetime is observed conditional on the customer being acquired, and because the error term in the acquisition equation is possibly correlated with that in the retention equation. The author asserted that the proposed model is similar to the two-step procedure which combines a binary probit model with a standard Tobit model. But the two-step procedure is not applicable here since the information of non-acquired customers is not available. The author asserted that the proposed model could be consistently estimated with maximum likelihood estimation [7]. The estimation details are recorded in Appendix A.
Furthermore, Reinartz, Thomas, and Kumar [3] modeled customer acquisition, retention, and profitability all together in a system of equations, a probit two-stage least squares model. The probit model estimates the acquisition process and two standard right-censored Tobit models estimate the customer relationship duration and customer profitability. The mathematical specifications of the models are expressed as
(5.6) ![]()
(5.7) ![]()
(5.8) 
where ![]() is a latent variable indicating customer i's utility to engage in a relationship with a firm,
is a latent variable indicating customer i's utility to engage in a relationship with a firm, ![]() an indicator variable showing whether customer i is acquired (
an indicator variable showing whether customer i is acquired (![]() ) or not (
) or not (![]() ),
), ![]() a vector of covariates affecting the acquisition of customer i,
a vector of covariates affecting the acquisition of customer i, ![]() the duration of customer i's relationship with the firm,
the duration of customer i's relationship with the firm, ![]() a vector of covariates affecting the duration of customer i's relationship with the firm,
a vector of covariates affecting the duration of customer i's relationship with the firm, ![]() the cumulative profitability of customer i,
the cumulative profitability of customer i, ![]() a vector of covariates affecting customer i's lifetime value,
a vector of covariates affecting customer i's lifetime value, ![]() segment-specific parameters, and
segment-specific parameters, and ![]() and
and ![]() error terms.
error terms.
The three models are linked because the error terms in three equations are correlated. And these authors assume that the error terms (![]() and
and ![]() ) are multivariate normal with a mean vector zero and a covariance matrix specified as
) are multivariate normal with a mean vector zero and a covariance matrix specified as
(5.9) 
To estimate the system of equations, three-step procedures were adopted. In the first step, a probit model was applied to all prospects, acquired and non-acquired. The estimated probit model gave a selectivity variable, lambda (![]() ), for the acquired customers. The variable lambda (
), for the acquired customers. The variable lambda (![]() ) was later included as an independent variable in the duration and profitability equations to correct for selection bias due to non-acquired customers. In the second step, a standard right-censored Tobit model was used to estimate duration with the estimated lambda (
) was later included as an independent variable in the duration and profitability equations to correct for selection bias due to non-acquired customers. In the second step, a standard right-censored Tobit model was used to estimate duration with the estimated lambda (![]() ) and covariates affecting duration. In the third step, a standard right-censored Tobit model was used to estimate profitability with the estimated lambda (
) and covariates affecting duration. In the third step, a standard right-censored Tobit model was used to estimate profitability with the estimated lambda (![]() ), the estimated duration, and covariates affecting the long-term profitability of customers.
), the estimated duration, and covariates affecting the long-term profitability of customers.
Schweidel, Fader, and Bradlow [8] argued that previous research on customer acquisition and retention considered acquisition only as a binary variable but did not consider the time when customers were acquired. These authors considered that the two constructs, the time that elapses before a prospective customer acquires a particular service and the subsequent duration for which a customer retains service before dropping it, may be related. The authors adopted the Sarmanov family of multivariate distributions with the inclusion of survival functions to address the correlation between the two constructs and the censoring issues in acquisition and retention. According to these authors, the Sarmanov family works by defining
(5.10) ![]()
where ![]() and
and ![]() are univariate probability density functions, and
are univariate probability density functions, and ![]() and
and ![]() are bounded mixing functions such that
are bounded mixing functions such that

for ![]() . In order for
. In order for ![]() to be a bivariate density function,
to be a bivariate density function, ![]() ,
, ![]() and
and ![]() must satisfy the condition
must satisfy the condition ![]() for all values of
for all values of ![]() and
and ![]() . Lee [9] showed that the mixing distribution for any univariate function
. Lee [9] showed that the mixing distribution for any univariate function ![]() is given by
is given by

Then replacing ![]() in Equation 5.11 with the probability mass functions given in Equations 11 and 24 yields the mixing functions for acquisition and retention processes, denoted
in Equation 5.11 with the probability mass functions given in Equations 11 and 24 yields the mixing functions for acquisition and retention processes, denoted ![]() and
and ![]() , respectively
, respectively
(5.12) 
and
(5.13) 
The joint distribution of acquisition time and duration of service at the customer level is then given by
(5.14) ![]()
In summary, the customer acquisition modeling is actually a probability prediction and the customer retention modeling essentially concerns the duration of customer lifetime. Acquisition probability can be estimated by a probit or logit model and hazard models can also be used if the timing of the incidence is concerned. Duration data are usually right-censored, so Tobit or hazard models are by nature suitable estimation techniques. Researchers link acquisition and retention modeling together either by specifying the correlation of the error terms in probability and duration models or by specifying the joint distribution of acquisition and retention for estimation.
5.2.1 Empirical Example: Balancing Acquisition and Retention
In order to understand how to allocate resources across customer acquisition and customer retention, we first need to develop a set of models which describe the acquisition and retention process. This will involve three different models: the acquisition model, duration model, and profit model. Once we have the results from the three models, then we can determine how to optimally shift resources between acquisition and retention efforts to maximize profitability. Thus, the modeling framework will take the following format (similar to the modeling framework as described earlier in the chapter):
(5.15) ![]()
(5.16) ![]()
(5.17) 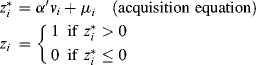
where ![]() is a latent variable indicating customer i's utility to engage in a relationship with a firm,
is a latent variable indicating customer i's utility to engage in a relationship with a firm, ![]() an indicator variable showing whether customer i is acquired (
an indicator variable showing whether customer i is acquired (![]() ) or not (
) or not (![]() ),
), ![]() a vector of covariates affecting the acquisition of customer i,
a vector of covariates affecting the acquisition of customer i, ![]() the duration of customer i's relationship with the firm,
the duration of customer i's relationship with the firm, ![]() a vector of covariates affecting the duration of customer i's relationship with the firm,
a vector of covariates affecting the duration of customer i's relationship with the firm, ![]() the cumulative profitability of customer i,
the cumulative profitability of customer i, ![]() a vector of covariates affecting customer i's lifetime value,
a vector of covariates affecting customer i's lifetime value, ![]() a vector of parameters, and
a vector of parameters, and ![]() and
and ![]() error terms. Given that the modeling framework is recursive in nature, we can estimate it in a stepwise fashion. Thus, we will proceed in the following manner. There will be four subsections in this empirical example. The first subsection will describe and estimate the acquisition model, the second will describe and estimate the duration model, the third will describe and estimate the profit model, and the fourth will describe and show how to optimally allocate resources between acquisition and retention.
error terms. Given that the modeling framework is recursive in nature, we can estimate it in a stepwise fashion. Thus, we will proceed in the following manner. There will be four subsections in this empirical example. The first subsection will describe and estimate the acquisition model, the second will describe and estimate the duration model, the third will describe and estimate the profit model, and the fourth will describe and show how to optimally allocate resources between acquisition and retention.
5.2.1.1 Acquisition Model
The key question we want to answer with regard to customer acquisition here is whether we can determine which future prospects have the highest likelihood of adoption. To do this we first need to know which past prospects were acquired and which were not. In the dataset provided for this chapter we have a binary variable which identifies whether or not a prospect was acquired by the firm (and hence became a customer) and a set of drivers which are likely to help explain a customer's decision to adopt. A random sample of 500 prospects (some of whom became customers) was taken from a B2B firm. The information we need for our acquisition model includes the following list of variables:
| Dependent variable | |
| Acquisition | 1 if the prospect was acquired, 0 otherwise |
| Independent variables | |
| Acq_Exp | The total dollars spent on trying to acquire this prospect |
| Acq_Exp_SQ | The square of the total dollars spent on trying to acquire this prospect |
| Industry | 1 if the prospect is in the B2B industry, 0 otherwise |
| Revenue | Annual sales revenue of the prospect's firm (in millions of dollars) |
| Employees | Number of employees in the prospect's firm |
In this case, we have a binary dependent variable (Acquisition) which tells us whether the prospect did adopt (= 1) or did not adopt (= 0). We also have five independent variables that we believe will be drivers of adoption. First, we have how many dollars the firm spent on each prospect (Acq_Expense) and the squared value of that variable (Acq_Expense_SQ). We want to use both the linear and squared terms since we expect that for each additional dollar spent on the acquisition effort for a given prospect, there will be a diminishing return to the value of that dollar. Second, since the focal firm of this example is a B2B firm, the other three variables are firmographic variables of the prospects. These include whether the prospect sells to B2B (= 1) or B2C (= 0) customers (Industry), how much (in millions) that the prospect firm makes in annual revenue (Revenue), and how many employees the prospect firm has (Employees).
First, we need to model the probability that a prospect will adopt. Since our dependent variable (Acquisition) is binary and we need an error structure that is similar to the duration and profit models (both normally distributed), we select a probit regression for this model. Choosing a logistic regression would require transforming the model output before integrating the results with the other two equations. In this case the y variable is Acquisition and the x variables represent the five independent variables in our database. When we run the probit regression we get the following result:
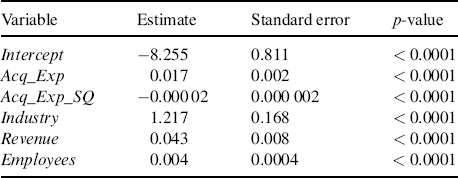
As we can see from the results, all five independent variables are significant at a p-value of 5% or better. First, this means that acquisition expense has a positive, but diminishing, effect (Acq_Exp > 0 and Acq_Exp_SQ < 0) on acquisition likelihood. Second, prospects who are B2B (vs. B2C), have a higher Revenue, and have more Employees are more likely to be acquired.
Now that we have determined the drivers of customer acquisition we need to use the output of the model to determine our model's predictive accuracy. To do this we need to use the estimates we obtained from the acquisition model to help us determine the predicted probability that each customer will repurchase. We use the parameter estimates from the repurchase model and values for the x variables for each customer in each time period to predict whether a customer is likely to purchase in that time period. For a probit regression we must apply the proper probability function
![]()
where X is the matrix of variables, β is the vector of coefficients, μ is the mean of the error distribution (in this case 0), σ is the standard deviation of the error distribution (in this case 1 since it is a standard normal distribution), and erf is the error function which is equal to
![]()
Once we compute the probability of repurchase, we need to create a cutoff value to determine at which point we are going to divide the customers into the two groups – predicted to adopt and predicted not to adopt. There is no rule that explicitly tells us what that cutoff number should be. Often by default we select 0.5 since it is equidistant from 0 and 1. However, it is also reasonable to check multiple cutoff values and choose the one that provides the best predictive accuracy for the dataset. By using 0.5 as the cutoff for our example, any customer whose predicted probability of acquisition is greater than or equal to 0.5 is classified as predicted to adopt and the rest are predicted not to adopt. To determine the predictive accuracy we compare the predicted to the actual acquisition values in a 2 × 2 table. For our sample of 500 customers we get the following table:
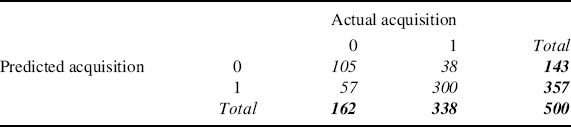
As we can see from the table, our in-sample model accurately predicts 64.8% of the prospects who chose not to adopt (105/162) and 88.7% of the prospects who chose to adopt (300/338). For the prediction of prospects who did adopt this is a significant increase in the predictive capability of a random guess model1 which would be only 67.6% accurate for this dataset. However, we see that our model slightly underperforms the random guess model with regard to the prospects that chose not to adopt. To determine overall model prediction performance we look at the diagonal and see that overall our prediction accuracy is 81.0% (405/500). Given that the model in general predicts better than the random guess model, we would determine that the model prediction is good.
As a result we now know how changes in acquisition expense and prospect characteristics are likely to either increase or decrease the likelihood of adoption. And we also know that these drivers do a good job in helping us predict whether a prospect is going to adopt or not.
5.2.1.2 Duration Model
The second step of this process is to estimate the duration model. The purpose of this model is to understand the drivers that describe the length of time a customer is likely to be a customer conditional on the fact that adoption occurred. Thus the equation takes the following format:
![]()
This equation shows us that the expected duration is a function of the probability that the prospect is acquired multiplied by the expected value of duration given that the prospect was acquired. If we were to merely run a regression with Duration as the dependent variable and ignore the probability that the customer will make a purchase, we would get biased estimates due to a potential sample selection bias.
Sample selection bias is a problem that is common in many marketing problems and has to be statistically accounted for in many modeling frameworks. In this case the customer has a choice as to whether or not to be adopted before deciding how long the relationship will last. If we were to ignore this choice we would bias the estimates from the model and we would have less precise predictions for the value of Duration. To account for this issue we need to be able to predict the value for both the probability of Acquisition (what we did in the first step of this example) and the expected value of Duration given that the prospect is expected to adopt. To account for this issue we use a two-stage modeling framework similar to that described earlier in this chapter and found in Reinartz et al. [3].
We will use the output and predictions of the probit model from the first step of this example to create a new variable, λ, which will represent the correlation in the error structure across the two equations. This variable, also known as the sample selection correction variable, will then be used as an independent variable in the Duration model to remove the sample selection bias in the estimates. To compute λ we use the following equation, also known as the inverse Mills ratio:
![]()
In this equation ϕ represents the normal probability density function, Φ represents the normal cumulative density function, X represents the value of the variables in the acquisition model, and β represents the coefficients derived from the estimation of the acquisition model.
Finally, we want to estimate a regression model for Duration and include the variable λ as an additional independent variable. This is done in a straightforward manner using the following equation:
![]()
In this case Duration is the value of the duration, γ is the matrix of variables used to help explain the value of Duration, α are the coefficients for the independent variables, μ is the coefficient on the inverse Mills ratio, λ is the inverse Mills ratio, and ε is the error term. Thus, for this example we will use the following list of variables:
| Dependent variable | |
| Duration | The number of days the customer was a customer of the firm, 0 if Acquisition = 0 |
| Independent variables | |
| Ret_Exp | The total dollars spent on trying to retain this customer |
| Ret_Exp_SQ | The square of the total dollars spent on trying to retain this customer |
| Freq | The number of purchases the customer made during that customer's lifetime with the firm, 0 if Acquisition = 0 |
| Freq_SQ | The square of the number of purchases the customer made during that customer's lifetime with the firm |
| Crossbuy | The number of product categories the customer purchased from during that customer's lifetime with the firm, 0 if Acquisition = 0 |
| SOW | The percentage of purchases the customer makes from the given firm given the total amount of purchases across all firms in that category |
| Lambda(λ) | The computed inverse Mills ratio from the acquisition model |
When we estimate the second-stage of the model, we get the following parameter estimates from the second of the two equations (the parameter estimates for the acquisition model are detailed in the first part of this example):

We gain the following insights from the results. We see that λ is positive and significant. We can interpret this to mean that there is a potential selection bias problem since the error term of our selection equation is correlated positively with the error term of our regression equation. We also see that all other variables of the duration model are significant, meaning that we have likely uncovered many of the drivers of duration.
We find that Ret_Exp is positive with a diminishing return, as noted by the positive coefficient on Ret_Exp and the negative coefficient on Ret_Exp_SQ. This means that marketing efforts to retain and build relationships with the customer do cause the customer to stay longer in the relationship, to a point. Then, after the threshold is reached, marketing efforts actually decrease the length of duration of the relationship on average. This is likely due to the fact that overly contacting customers can often strain the relationship between the customer and firm. We find that Freq is also positive with a diminishing return, as noted by the positive coefficient on Freq and a negative coefficient on Freq_SQ. This means that customers who purchase a moderate number of times are likely to have the longest relationships with the firm. And customers who purchase less frequently (or very frequently) are more likely to leave the relationship earlier. We find the coefficient on Crossbuy is positive, suggesting that customers who purchase across more categories are more likely to stay in the relationship longer. Finally, we find the coefficient on SOW to be positive, suggesting that customers who purchase a larger percentage of their budget for a given set of items at the focal store are more likely to have a longer relationship.
Our next step is to predict the value of Duration to see how well our model compares to the actual values. We do this by starting with the equation for expected duration at the beginning of this example:
![]()
In this case Φ is the normal CDF distribution, X is the matrix of independent variable values from the Acquisition equation, β is the vector of parameter estimates from the Acquisition equation, γ is the matrix of independent variables from the Duration equation, α is the vector of parameter estimates from the Duration equation, μ is the parameter estimate for the inverse Mills ratio, and λ is the inverse Mills ratio. Once we have predicted the Duration value for each of the customers we want to compare this to the actual value from the database. We do this by computing the MAD. The equation is as follows:
![]()
We find for all customers that MAD = 144.02. This means that on average each of our predictions of Duration deviates from the actual value by about 144 days. If we were to instead use the mean value of Duration (742.45) across all customers as our prediction for all prospects (this would be the benchmark model case), we would find that MAD = 484.09, or about 484 days. As we can see, our model does a significantly better job of predicting the length of the customer relationship than the benchmark case.
5.2.1.3 Profit Model
The third step of this process is to estimate the profit model. The purpose of this model is to understand the drivers that describe the expected value of the CLV. Thus the equation takes the following format:
![]()
This equation shows us that the expected duration is a function of the probability that the prospect is acquired multiplied by the expected value of profit given that the prospect was acquired and the estimated duration of the customer's relationship with the firm. Again, if we were to merely run a regression with Profit as the dependent variable and ignore the probability that the customer will make a purchase and the estimated duration, we would get biased estimates due to a potential sample selection bias.
Thus, we will use the λ variable as an additional variable in the model which is computed using the following equation:
![]()
In this equation ϕ represents the normal probability density function, Φ represents the normal cumulative density function, X represents the value of the variables in the acquisition model, and β represents the coefficients derived from the estimation of the acquisition model.
We will also use the expected value of Duration from the second step of this example in our profit model. The expected value of Duration is merely computed as
![]()
Finally, we want to estimate a regression model for Profit and include the variables λ and E(Duration) as additional independent variables. This is done in a straightforward manner using the following equation:
![]()
In this case Profit is the value of the profit, γ is the matrix of variables used to help explain the value of Profit, α are the coefficients for the independent variables, μ is the coefficient on the inverse Mills ratio, λ is the inverse Mills ratio, ρ is the coefficient on the expected duration, Durâtion is the expected duration, and ε is the error term. Thus, for this example we will use the following list of variables:
| Dependent variable | |
| Profit | The CLV of a given customer, –(Acq_Exp) if the customer is not acquired |
| Independent variables | |
| Acq_Exp | The total dollars spent on trying to acquire this prospect |
| Acq_Exp_SQ | The square of the total dollars spent on trying to acquire this prospect |
| Ret_Exp | The total dollars spent on trying to retain this customer |
| Ret_Exp_SQ | The square of the total dollars spent on trying to retain this customer |
| Freq | The number of purchases the customer made during that customer's lifetime with the firm, 0 if Acquisition = 0 |
| Freq_SQ | The square of the number of purchases the customer made during that customer's lifetime with the firm |
| Crossbuy | The number of product categories the customer purchased from during that customer's lifetime with the firm, 0 if Acquisition = 0 |
| SOW | The percentage of purchases the customer makes from the given firm, given the total amount of purchases across all firms in that category |
| Lambda(λ) | The computed inverse Mills ratio from the acquisition model |
| Durâtion | The number of days the customer was a customer of the firm, 0 if Acquisition = 0 |
When we estimate the third stage of the model, we get the following parameter estimates (the parameter estimates for the acquisition model are detailed in the first part of this example and the parameter estimates of the duration model are detailed in the second part):

We gain the following insights from the results. We see that λ is positive and significant. We can interpret this to mean that there is a potential selection bias problem since the error term of our selection equation is correlated positively with the error term of our regression equation. We also see that all other variables of the profit model are significant, meaning that we have likely uncovered many of the drivers of customer lifetime value.
We find that Acq_Exp is positive with a diminishing return, as noted by the positive coefficient on Acq_Exp and the negative coefficient on Acq_Exp_SQ. This means that marketing efforts to acquire prospects do cause the customer to be more profitable, to a threshold. Then, after the threshold is reached, marketing efforts on acquisition actually decrease the profitability of the customer on average. This is because, after a certain amount of spending on acquisition, there is no additional benefit (i.e., it costs more for no benefit in spending). We find that Ret_Exp is positive with a diminishing return, as noted by the positive coefficient on Ret_Exp and the negative coefficient on Ret_Exp_SQ. This means that marketing efforts to retain and build relationships with the customer do cause the customer to be more profitable, to a point. Then, after the threshold is reached, marketing efforts on retention actually decrease the profitability on average. This is likely due to the fact that overly contacting customers can often strain the relationship between the customer and firm and drive the customer not to purchase. We find that Freq is also positive with a diminishing return, as noted by the positive coefficient on Freq and negative coefficient on Freq_SQ. This means that customers who purchase a moderate number of times are likely to have the highest profitability with the firm. And customers who purchase less frequently (or very frequently) are more likely to less profitable. We find the coefficient on Crossbuy is positive, suggesting that customers who purchase across more categories are more likely to be profitable. We find the coefficient on SOW to be positive, suggesting that customers who purchase a larger percentage of their budget for a given set of items at the focal store are more likely to be profitable. Finally, we find the coefficient on expected duration to be positive, suggesting that customers who are in the relationship longer are more likely to profitable.
Our next step is to predict the value of Profit to see how well our model compares to the actual values. We do this by starting with the equation for expected profit at the beginning of this example:
![]()
In this case Φ is the normal CDF distribution, X is the matrix of independent variable values from the Acquisition equation, β is the vector of parameter estimates from the Acquisition equation, γ is the matrix of independent variables form the Profit equation, α is the vector of parameter estimates from the Profit equation, μ is the parameter estimate for the inverse Mills ratio, λ is the inverse Mills ratio, ρ is the coefficient on the expected duration, and Durâtion is the expected duration. Once we have predicted the Profit value for each of the customers we want to compare this to the actual value from the database. We do this by computing the MAD. The equation is as follows:
![]()
We find for all the customers that MAD = 752.26. This means that on average each of our predictions of Profit deviates from the actual value by about $752.26. If we were to instead use the mean value of Profit ($2403.84) across all customers as our prediction (this would be the benchmark model case), we would find that MAD = 1881.40, or $1881.40. As we can see, our model does a significantly better job of predicting the expected profit of customers than the benchmark case.