
15
Other Patterns in Java EE
WHAT’S IN THIS CHAPTER?
- WebSockets
- Message-oriented middleware
- Microservices versus monoliths
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
The wrox.com code download for this chapter is found at www.wrox.com/go/
projavaeedesignpatterns on the Download Code tab. The code is in the Chapter 15 download and individually named according to the names throughout the chapter.
This chapter discusses some of the things that are benefits of Java EE and development. You might think of this chapter as containing all the topics that are important to know but don’t fit in any of the other chapters.
This chapter introduces web sockets, which is an exciting new feature of Java EE. Then it introduces message-orientated middleware before moving on to the related topic of microservice architecture.
Enjoy this eclectic bag of tech goodies!
WHAT ARE WEBSOCKETS?
WebSockets might be the most interesting improvement on the web since the introduction of Asynchronous JavaScript And XML (AJAX). It has been popular since the emergence of HTML5 and is supported by many web frameworks. However, it took quite a long time to have a stable and compatible specification for WebSockets.
The Hypertext Transfer Protocol (HTTP) model was designed long before the Internet was popular, and it relied on simple specification and design. In the traditional HTTP model, a client opens a connection to the back-end server, sends an HTTP request of type1 GET, POST, PUT, or DELETE, and the HTTP server returns an appropriate response. There have been several attempts to hack and communicate over standard HTTP, such as AJAX, as well as design a new model such as SPDY.
The traditional HTTP model has been cumbersome for almost any application that goes beyond the simple get-and-submit-content data model. Think about a chat client, in which the participants can send messages in any order, and hundreds can be chatting at the same time. The standard request-response approach would be too limiting for such purposes. Some early approaches to get past this limitation were AJAX and Comet. Both relied on long polling: opening an HTTP connection and keeping it alive (maintaining the connection open) by not finalizing the response.
With WebSockets, the client can initiate a raw socket to the server and execute full-duplex communication. WebSockets support was introduced with JSR-356. The package javax.websocket and its server subpackage contain all classes, interfaces, and annotations related to WebSockets.
To implement WebSockets in Java EE, you need to create an endpoint class with the WebSocket life-cycle methods shown in Listing 15-1.
The Endpoint class introduces three life-cycle methods: onOpen, onClose, and onError. At least the extending class needs to implement the onOpen method.
You can deploy this endpoint in two different ways: either by configuration or programmatically.
To programmatically deploy the code in Listing 15-1, your application needs to invoke the following:
ServerEndpointConfig.Builder.create(HelloEndpoint.class, "/hello").build();The deployed WebSocket is available from ws://<host>:<port>/<application>/hello. However, a better way is to use annotation configuration. Therefore, the same endpoint becomes Listing 15-2.
This approach lets you use annotations and keep up with the Plain Old Java Object (POJO) approach because you are not extending a base class. The annotated endpoint has the same life-cycle methods as the one in Listing 15-2, but it introduces an additional onMessage life-cycle method. Rather than implementing onOpen and adding the onMessage handler, it’s enough to implement an annotated onMessage method in the annotation-based approach. You can annotate several methods with @OnMessage to receive different types of data, such as String or ByteBuffer for binary.
The client-side implementation of WebSockets depends on the web frameworks in use. However, a simple JavaScript version is shown in the following snippet.
var webSocket = new WebSocket('ws://127.0.0.1:8080/websockets/hello'),
webSocket.send("world");A better example is to send a complex object in JavaScript Object Notation (JSON) format, which can be marshaled to an object, as in the following code snippet.
var msg = {
type: "message",
text: "World",
date: Date.now()
};
webSocket.send(JSON.stringify(msg));
webSocket.onmessage = function(evt) { /* Expect to receive hello world */ };WebSockets are great for building web applications that need persistent and asynchronous messaging between the client and the server. Java EE offers an easy implementation of WebSockets. They have far more configurations and implementation options than discussed here. If we have sparked your interest in WebSockets we suggest you visit Oracle’s Java EE Tutorial,2 which explains in more details how to program WebSockets using the Java API.
WHAT IS MESSAGE-ORIENTATED MIDDLEWARE
The communication between components in a Java EE system is synchronous. A call chain is started from the calling Enterprise JavaBean (EJB) to a data access object (DAO) to the entity, and so on to the final target. All components of the call chain must be available and ready to receive the call, and the calling component must wait for a response before proceeding. The success of the invocation depends on the availability of all components. As you saw in Chapter 9, “Asynchronous,” an invocation of an asynchronous method does not require the calling object to wait for a response. It can continue with the normal flow of execution, while the asynchronous method sets up its own call chain.
Message-oriented middleware (MOM) provides a type of buffer between systems that allows the communication to be delayed if a component is not up and running. Messages are delivered as soon as all components are available. Invocations are translated into messages and sent via a messaging system to a target component that processes the message and may respond. If the target component is not available, the messages are queued waiting for the system to become available. When the component is available, the messages are processed.
At one end of the chain is a producer that translates the call into a form that can be transmitted as a message, and at the other end is a consumer who receives the message. The consumers and producers are highly decoupled, because they don’t know anything about each other. They don’t even have to be written in the same language or be hosted on the same network; they may even be distributed over several external servers.
A MOM system is composed of four players: messages, consumers, producers, and brokers. Producers generate the messages and send them to brokers, who distribute the messages to destinations where they’re stored until a consumer connects and processes them.
There are two architectural implementations of MOM: point-to-point and publish/subscribe.
In the point-to-point implementation, the producer sends a message to the destination, which is called a queue. In the queue, the message waits for a consumer to pick it up and confirm that it has been processed successfully. If it has, the message is then removed from the queue. Figure 15.1 shows the producer putting the message M1 onto the queue and then the consumer picking up the message from the queue and processing it. In this implementation the message is only processed by one consumer.

Figure 15.1 Point-to-point implementation
In the publish/subscribe implementation, the destination is called a topic. A producer publishes a message to a topic, and all consumers who subscribe to the topic receive a copy of the message. This is shown in Figure 15.2, where messages M1 and M2 are published to the topic T1 and consumed by consumer C1 and C2, and message M3 is published on topic T2 and consumed by consumers C2 and C3.
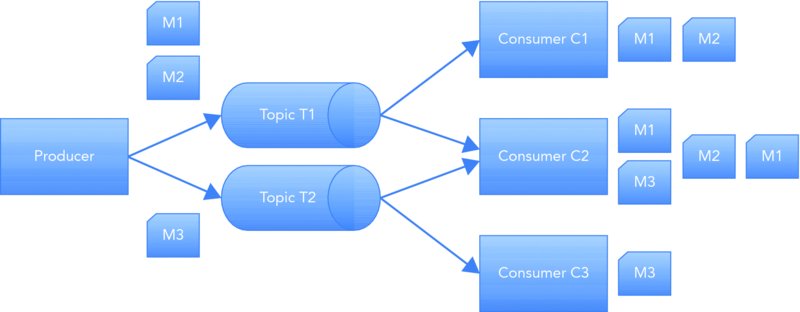
Figure 15.2 Publish/subscribe implementation
Java EE provides a convenient application programming interface (API) that deals with these implementations and is called the Java Message Service (JMS). It is a set of interfaces that describe the creation of messages, providers, and consumers. When implemented in an EJB container, message-driven beans (MDBs) act as listeners for JMS messages being invoked asynchronously.
WHAT IS THE MICROSERVICE ARCHITECTURE?
Over the past few years, the microservice architecture pattern has become a hotly discussed and popular pattern. The idea behind it is to design a large distributed scalable application that consists of small cohesive services that are able to evolve or even be completely rewritten over the life of the application.
This is not a new idea, and it is similar to the Service Orientated Architecture (SOA) pattern that has been in use for a long time. The essence of the microservice is the idea that each service should be small—perhaps as small as only a few hundred lines of code. The objective is to decompose a large, monolithic application into much smaller applications to solve development and evolutionary problems.
This chapter discusses the reasons for following the microservice path, its disadvantages and benefits, and how it compares to the more established and familiar monolithic architecture.
Monolithic Architecture
The most common way to develop and package a web application has always been to collect all the resources, components, and class files into a single Web application ARchive (WAR) or Enterprise ARchive (EAR) file and deploy it to a web server. A typical application for a bookstore might include components that manage the user’s accounts, process payment, control stock, administer customer services, and generate front-end views. All this is developed in one monolithic application and then packaged and deployed to a web server. Figure 15.3 shows a simplified representation of a monolithic application.
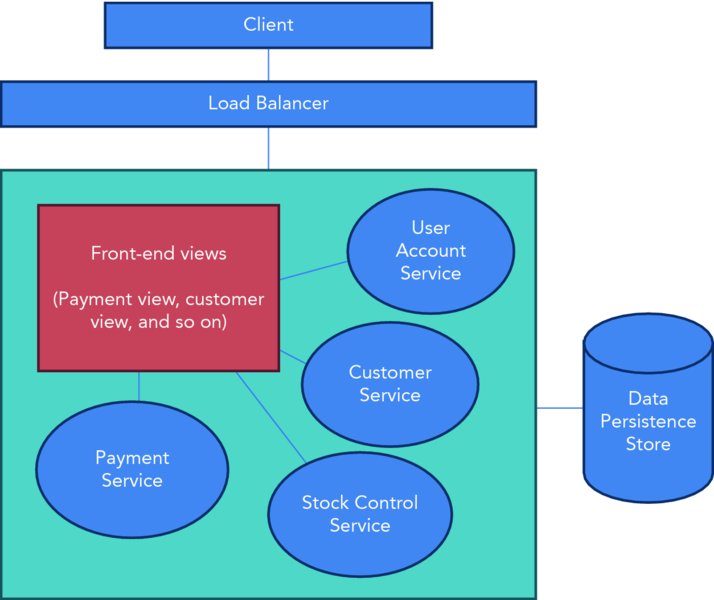
Figure 15.3 Monolithic architecture
The components are packaged together in a logical modular form and deployed as one single monolithic application. It’s a simple way to develop and deploy an application because there’s only one application to test. Integrated Development Environments (IDEs) and other development tools are designed with the monolithic architecture in mind. Despite these benefits of monolithic architecture, applications built to this design are often very large.
A small application is easy for developers to come to grips with, to understand, and maintain, but a large monolithic application can be difficult, especially for those developers who have recently joined the team. They may take many weeks or months to thoroughly understand the application.
Frequent deployments are not practical because they require the coordination of many developers (and perhaps other departments). It may take hours or days to arrange a deployment, hindering the testing of new features and bug fixes. A significant drawback to the monolithic design is that it’s difficult to change the technology or framework. The application was developed based on technology decisions made at the beginning of the project. You are stuck with these decisions; if a technology is found that solves the problem in a more elegant or performant way, it is difficult to start using it. Rewriting an entire application is almost never an affordable option. The monolithic architecture pattern does not lend itself well to scalability.
Scalability
Scalability refers to an application’s ability to grow (and shrink) as demand for its services changes without noticeably affecting the user experience. A badly performing e-commerce website loses customers quickly, making scalability very important. The first go-to solution is to scale horizontally and duplicate the application over many servers and load balance the traffic in a High Availability (HA) manner, with a passive peer that becomes active if the active peer goes down. X-axis scaling improves the capacity and availability of the application. This option does not have development cost implications but does result in higher hosting and maintenance expense.3
You can scale an application along the Z-axis. The application code is duplicated onto several servers, similar to an X-axis split, but in this case each server is responsible for only a fraction of the data. A mechanism is put in place to route data to the appropriate server, perhaps based on a user type or primary key. Z-axis scaling benefits from much the same performance improvements as X-axis scaling; however, it implies new development expense to rearchitect the application.
None of these solutions resolves the worsening application and development complexity. For this, you need vertical scaling.
The application can be scaled along the Y-axis. It is decomposed into functionality, service, or resource. The way you do this is entirely your choice and will depend on the situation, although division by use case is common. The idea is that each decomposed part should encapsulate a small set of related activities.
To visualize the X-, Y-, and Z-axis scaling, you draw an AKF scale cube,4 as in Figure 15.4.
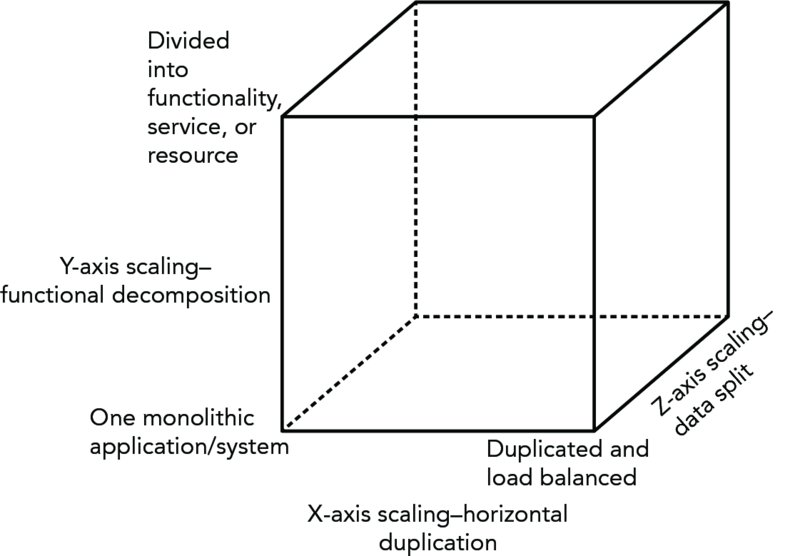
Figure 15.4 The AKF cube should have X-, Y-, and Z-axis scaling.
Decomposing into Services
The microservice approach decomposes a monolithic application along the Y-axis into services that satisfy a single use case or a set of related functionality. These services are then duplicated on several servers and placed behind a load balancer, X-axis split. The data persistence may be scaled along the Z-axis by sharding the data based on a primary key.
If you decompose the applications in Figure 15.3 along the Y-axis, you end up with the architecture in Figure 15.5.
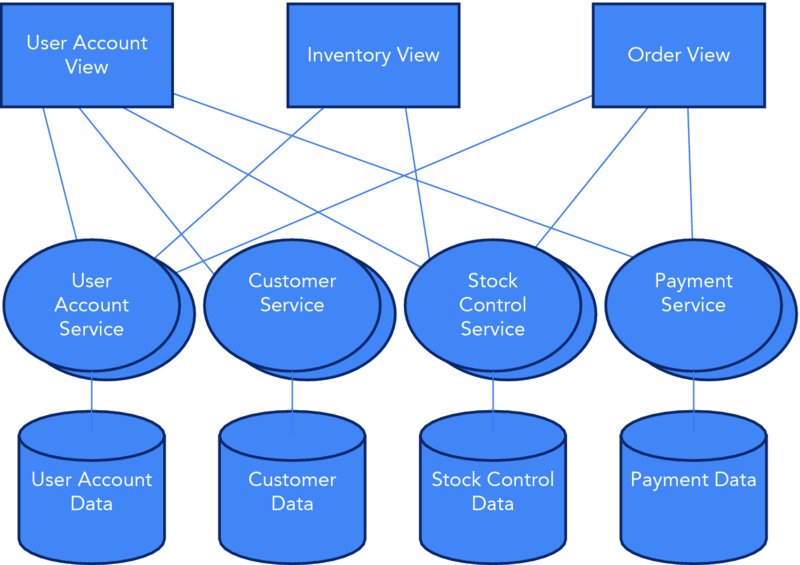
Figure 15.5 Y-axis decomposition
The front-end views have been split into separate applications that access the functionality of several back-end services. The services have been split from the monolithic application into standalone applications that manage their own data. You can achieve splits along the Z-axis by sharding the data and scaling along the X-axis by clustering and load balancing.
You have seen how to decompose a monolithic application into microservices and learned the importance of scalability for the continuance of an application.
Now you’ll look more closely at the specific benefits and cost of the microservice architecture.
Microservice Benefits
From the development perspective, the benefits of a microservice architecture result from the size and agility of the small applications of which it consists. They are easy for developers to understand and for the IDE to manage. A large application that consists of many hundreds of modules can take considerable time to load, which negatively affects the developers’ productivity. Each microservice application can be deployed quicker and often without the cooperation of other teams. Because each service stands alone, local changes to code do not affect other microservices; therefore, continuous development is possible. Each microservice can be developed by a dedicated team of developers who manage the deployment and resource requirements of their service independently of other teams.
The user interface (UI) is normally divorced from back-end development; your development team may never see a line of UI code. If you are programming to a REpresentational State Transfer (REST) API (see Chapter 13, “RESTful Web Services”), you are only required to honor the resource representation contract, not to think about the way the front end will be implemented. This allows true separation of concerns.
From the perspective of application performance, the main benefit comes from being able to deploy each microservice onto its own tailored environment. The resource requirements of your microservice may differ from another, thereby allowing resource allocation to be fine grained. A monolithic application is deployed on one environment with shared resources.
Fault tolerance and isolation are increased. A fault in one microservice does not affect the operations of the others, allowing the application to continue to perform. In a system that uses MOM to communicate between services, messages destined for a failed microservice wait in the queue until the fault is resolved and the microservice (consumer) begins to consume the messages. If the application is scaled horizontally, there’s no break in service because one of the duplicate microservices consumes the messages. In a monolithic application, such a fault could bring down the entire application.
Among all the benefits attributed to the microservice architecture, the most talked about is the ease with which you can change the technology stack. Because each microservice is small, rewriting it is not expensive. In fact, new microservices can be written in any language, allowing you to choose the most suitable language for solving the problem. Technology decisions made at the beginning of the project do not dictate the technology that you must use throughout the application’s life.
Nothing in Life Is Free
The benefits of the microservice architecture do not come free. There are costs involved.
The ease with which you can develop a microservice makes it easy for the number of microservices to grow, and to grow very quickly. Fifteen microservices can easily become thirty or more, especially when different versions of the same microservice are counted. This poses several difficulties.
The responsibility for operations may move to the development team. With only a handful of services to maintain, it’s not a difficult task, but as the number of microservices grows, the task of maintaining them increases. A significant investment needs to be made to ensure that the microservices are deployed and maintained. Processes need to be automated to reduce the burden of deploying and maintaining a large number of services. There may be a knowledge gap you need to fill, adding to the overall running costs.
Cross-cutting changes to semantics means that all microservices must update their code to keep in sync. This can be time consuming to perform and has significant retesting costs. Alterations to interface contracts and message formats can be the cause of such changes and require that all teams work in a coordinated way. Equally, failing to change an interface or message format early on in the project results in significantly greater costs as the number of microservices grows.
Duplicated code is something that you have been taught is bad, and it is. In a microservice environment, the risk of code duplication is high. To avoid coupling and dependencies, code must sometimes be duplicated, meaning every instance of that code must be tested and maintained. You may be able to abstract code to a share library, but this does not work in a polyglot environment.
The inherent unreliability and complexity of distributed systems are duplicated in a microservice environment. Every service may be hosted in a distributed way, communicating via networks that suffer from latency issues, incompatible versions, unreliable providers, hardware problems, and more. Constant monitoring of network performance is vital.
Conclusions
The monolithic architecture has been used for many years to develop applications and serves small applications and development teams well. It’s easy to develop and test because IDEs are designed to manage these types of application structures. But as you have seen, it does not scale well and hinders development. It is difficult to introduce new technology, and refactoring is expensive.
Microservices decompose into logical services of related functionality. Their small size makes them easy for developers to understand. Development and deployment are continuous. Scalability is built into the architecture, and you are not stuck with initial technology decisions.
FINALLY, SOME ANTI-PATTERNS
The purpose of this book is to fill the gap between “classical” patterns and Java EE. You will find many books discussing anti-patterns, but there is no harm in discussing a few here.
Anti-patterns usually occur because of misuse of one or several patterns. A Java EE developer who has enough experience can easily list more anti-patterns than patterns. Here are a few that are common or that you may already have come across.
Uber Class
There is probably no single project without a huge class that serves many purposes and responsibilities. Not only does this violate Java EE principles, but such classes override basic object-oriented programming (OOP) principles and must be avoided.
Services that are overloaded with many responsibilities fall into the same category. If you are not a big fan of OOP, that’s fine, but if you do want to continue to write code in an OOP language, it is best to keep your classes small and highly cohesive.
Although many others had expressed this anti-pattern, Reza Rahman may have first introduced the name.
Lasagna Architecture
Java EE promoted layers starting from the early days, which may have resulted in many unnecessary interfaces and packages. Although this pattern may look like an answer to uber class and monolithic applications, usually it complicates things unnecessarily.
Lasagna architecture in the OOP world is not much different from spaghetti programming in structural programming. Too much abstraction is unnecessary and provides no help. Interfaces and loose coupling are great tools only when you use them in the right amount, in the right context, and only when they are needed.
This anti-pattern has been expressed by many developers with many different names, such as Baklava Code. However, the name lasagna may have been first given by Adam Bien,5 who is heavily against unnecessary use of interfaces.
Mr. Colombus
Almost all experienced Java EE developers want to invent or implement their own perfect solution. Most of the time these are only attempts to abstract and provide a better interface to a common library, such as logging or testing, where it may even go to extremes and rewrite an important functionality that has been supported by the open source community for years, such as an Object Relational Mapping (ORM) layer.
Although inventing something new may look appealing, reinventing something is just a waste of time. If you are going to write a new logging or an ORM framework, you should really have a good reason to do it. If you don’t, you are rewriting a well-supported mature product, and most likely you’ll end up maintaining it and providing all the support, tests, and future development alone.
Always make sure you have done enough literature searches on open source projects before starting to write a framework from scratch.
Friends with Benefits
One huge problem of J2EE was vendor locking. By the time J2EE 1.4 was released, most vendor servers only worked with the same vendor’s tools and IDEs. This looked like a mutually beneficial relationship at first because the vendor provided professional support for its own tools, and open source tools and servers were left to the community to support. However, in the long term, many J2EE developers observed how open source tools and servers provided standard behavior and compatibility to Java specifications when vendors failed to do so.
There is nothing wrong with buying professional support and services and using tools, servers, and IDEs from vendors as long as the project is not locked to that vendor. Vendor locking may introduce problems that are impossible to solve without new releases and patches from the vendor, whereas building applications always make it possible to change to other vendors.
Bleeding Edge
Passionate developers love to use bleeding-edge technologies. For example, WebSockets were introduced many years ago, but they still suffer compatibility issues with old versions of browsers. No one can argue against the joy of learning something new and implementing a bleeding-edge technology in a project. However, it may become cumbersome to support such projects if you are targeting the mainstream.
A good approach to deciding which framework or technology to use is to see how it fits with your target user base. If you are building a banking application for clients who may still be using Internet Explorer 6, using WebSockets is the best choice (although most WebSockets frameworks provide fallback scenarios).
You always need to make sure an outsource library or framework is well supported, mature, and fits your project before moving on.
Utilityman
Utility classes and packages are common in projects. No one can argue that you need a class to perform some math operations, such as rounding or converting different number types. If you do have such utility or helper classes, you probably need to organize them with a package name of util or helper, right? No, in reality, they just help you collect junk. Because util and helper sound too generic, many classes are moved into these packages. Any class that may not be categorized easily will end up in your package. The generic name does not provide real information, so even though those classes are not used anymore, no one would dare to remove them.
If you have a great utility that everybody needs to use, just place it where it belongs with the current usage and provide proper documentation. You can move it to some more generic package in the future if needed.
Just like lasagna, Adam Bien first described and named this pattern.