

Chapter 6
Watson and the Jeopardy! Challenge
How does Watson—IBM's Jeopardy!-playing computer—work? Why does it need predictive modeling in order to answer questions, and what secret sauce empowers its high performance? How does the iPhone's Siri compare? Why is human language such a challenge for computers? Is artificial intelligence possible?
January 14, 2011. The big day had come. David Gondek struggled to sit still, battling the butterflies of performance anxiety, even though he was not the one onstage. Instead, the spotlights shone down upon a machine he had helped build at IBM Research for the past four years. Before his eyes, it was launched into a battle of intellect, competing against humans in this country's most popular televised celebration of human knowledge and cultural literacy, the quiz show Jeopardy!
Celebrity host Alex Trebek read off a clue, under the category “Dialing for Dialects:”*

Watson,1 the electronic progeny of David and his colleagues, was competing against the two all-time champions across the game show's entire 26-year televised history. These two formidable opponents were of a different ilk, holding certain advantages over the machine, but also certain disadvantages. They were human.

Watson competes against two humans on Jeopardy!
Watson buzzed in ahead of its opponents. Deaf and unable to hear Trebek's professional, confident voice, it had received the Jeopardy! clue as a transmission of typed text. The audience heard Watson's synthesized voice respond, phrasing it according to the show's stylistic convention of posing each answer in the form of a question. “What is Sanskrit?”2
For a computer, questions like this might as well be written in Sanskrit. Human languages like English are far more complex than the casual speaker realizes, with extremely subtle nuance and a pervasive vagueness we nonmachines seem completely comfortable with. Programming a computer to work adeptly with human language is often considered the ultimate challenge of artificial intelligence (AI).
Text Analytics
It was Greek to me.
—William Shakespeare
I'm completely operational, and all my circuits are functioning perfectly.
—HAL, the intelligent computer from 2001: A Space Odyssey (1968)
Science fiction almost always endows AI with the capacity to understand human tongues. Hollywood glamorizes a future in which we chat freely with the computer like a well-informed friend. In Star Trek IV: The Voyage Home (1986), our heroes travel back in time to a contemporary Earth and are confounded by its primitive technology. Our brilliant space engineer Scotty, attempting to make use of a Macintosh computer, is so accustomed to computers understanding the spoken word that he assumes its mouse must be a microphone. Patiently picking up the mouse as if it were a quaint artifact, he jovially beckons, “Hello, computer!”
2001: A Space Odyssey's smart and talkative computer, HAL, bears a legendary, disputed connection in nomenclature to IBM (just take each letter back one position in the alphabet); however, author Arthur C. Clarke has strenuously denied that this was intentional. Ask IBM researchers whether their question-answering Watson system is anything like HAL, which goes famously rogue in the film, and they'll quickly reroute your comparison toward the obedient computers of Star Trek.
The field of research that develops technology to work with human language is natural language processing (NLP, aka computational linguistics). In commercial application, it's known as text analytics. These fields develop analytical methods especially designed to operate across the written word.
If data is all Earth's water, textual data is the part known as “the ocean.” Often said to compose 80 percent of all data, it's everything we the human race know that we've bothered to write down. It's potent stuff—content-rich because it was generated with the intent to convey not just facts and figures, but human knowledge.
But text, data's biggest opportunity, presents the greatest challenge.
Our Mother Tongue's Trials and Tribulations
It is difficult to answer, when one does not understand the question.
—Sarek, Spock's father, in Star Trek IV: The Voyage Home
Let's begin with the relatively modest goal of grammatically deconstructing the Sanskrit question, repeated here:

For example, consider how “of India” fits in. It's a prepositional phrase that modifies “this classical language.” That may seem obvious to you, human reader, but if the final two words had been “of course,” that phrase would instead modify the main verb, “is” (or the entire phrase, depending on how you look at it).
Determining how each component such as “of India” fits in relies on a real understanding of words and the things in the world that they represent. Take the classic linguistic conundrum, “Time flies like an arrow.” Which is the main verb of the sentence? It is flies if you interpret the sentence as: “Time moves quickly, just as an arrow does.” But it could be time if you read it as the imperative, ordering you to “Measure the speed of flies as you would measure that of an arrow.”
The preferred retort to this aphorism, often attributed to Groucho Marx, is: “Fruit flies like a banana.” It's funny and grammatically revealing. Suddenly like is now the verb, instead of a preposition.
“I had a car.” If the duration of time for which this held true was one year, I would say, “I had a car for a year.” But change one word and everything changes. “I had a baby.” If the duration of labor was five hours, you would say, “I had a baby in five hours,” not “for five hours.” The word choice depends on whether you're describing a situation or an event, and the very meaning of the object—car or baby—makes the difference.
“I ate spaghetti with meatballs.” Meatballs were part of the spaghetti dish.
“I ate spaghetti with a fork.” The fork was instrumental to eating, not part of the spaghetti.
“I ate spaghetti with my friend Bill.” Bill wasn't part of the spaghetti, nor was he instrumental to eating, although he was party to the eating event.
“I had a ball.” Great, you had fun.
“I had a ball but I lost it.” Not so much fun! But in a certain context, the same phrase goes back to being about having a blast:
- Q: “How was your vacation and where is my video camera?”
- A: “I had a ball but I lost it.”
In language, even the most basic grammatical structure that determines which words directly connect depends on our particularly human view of and extensive knowledge about the world. The rules are fluid, and the categorical shades of meaning are informal.3
Once You Understand the Question, Answer It
How can a slim chance and a fat chance be the same, while a wise man and wise guy are opposites?
—Anonymous
Why does your nose run, and your feet smell?
—George Carlin
Beyond processing a question in the English language, a whole other universe of challenge lurks: answering it. Assume for a moment the language challenges have been miraculously met and the computer has gained the ability to “understand” a Jeopardy! question, to grammatically break it down, and to assess the “meaning” of its main verb and how this meaning fuses with the “meanings” of the other words such as the subject, object, and prepositional phrases to form the question's overall meaning. Consider the following question, under the category “Movie Phone:”

A perfect language-understanding machine could invoke a routine to search a database of movies for one starring Keanu Reeves in which a plot element involves using a land-line telephone to “get out of” something—that something also being the title of the movie (The Matrix). Even if the reliable transformation of question to database lookup were possible, how could any database be sure to include coverage of these kinds of abstract movie plot elements, which are subjective and open ended?
As another example that would challenge any database, consider this Jeopardy! question under the category “The Art of the Steal:”

First, to succeed, the system must include the right information about each art piece, just as movie plot elements were needed for the Matrix question. IBM would have needed the foresight to include in a database of artworks whether, when, and where each item was stolen (for this item, the answer is Baghdad). Second, the system would also need to equate “went missing” with being stolen. That may be a reasonable interpretation regarding artwork, but if I said that my car keys went missing, we wouldn't reach the same conclusion. How endlessly involved would a mechanical incarnation of human reason need to be in order to automatically make such distinctions? Written sources such as newspaper articles did in fact use a diverse collection of words to report this art carving's disappearance, looting, theft, or being stolen.
Movies and artworks represent only the tip-top of a vast iceberg. Jeopardy! questions could fall within any domain, from the history of wine to philosophy to literature to biochemistry, and the answer required could be a person, place, animal, thing, year, or abstract concept. This unbounded challenge is called open question answering. Anything goes.
The old-school AI researcher succumbs to temptation and fantasizes about building a Complete Database of Human Knowledge. That researcher is fun to chat with. He holds a grandiose view regarding our ability to reach for the stars by digging deep, examining our own inner cognitions, and expressing them with computer programs that mimic human reason and encode human knowledge. But someone has to break it to the poor fellow: This just isn't possible. As more pragmatic researchers concluded in the 1980s and 1990s, it's too large and too ill defined.
In reality, given these challenges, IBM concluded only 2 percent of Jeopardy! questions could be answered with a database lookup. The demands of open question answering reach far beyond the computer's traditional arena of storing and accessing data for flight reservations and bank records. We're going to need a smarter robot.
The Ultimate Knowledge Source
We are not scanning all those books to be read by people. We are scanning them to be read by an AI.
—A Google employee regarding Google's book scanning, as quoted by George Dyson in Turing's Cathedral: The Origins of the Digital Universe
A bit of good news: IBM didn't need to create comprehensive databases for the Jeopardy! challenge because the ultimate knowledge source already exists: the written word. I am pleased to report that people like to report; we write down what we know in books, Web pages, Wikipedia entries, blogs, and newspaper articles. All this textual data composes an unparalleled gold mine of human knowledge.
The problem is that these things are all encoded in human language, just like those confounding Jeopardy! questions. So the question-answering machine must overcome not only the intricacies and impossibilities of the question itself, but the same aspects of all the millions of written documents that may hold the question's answer.
Googling the question won't work. Although it's a human's primary means of seeking information from the Internet's sea of documents, Google doesn't hone down to an answer. It returns a long list of Web pages, each with hundreds or thousands of possible answers within. It is not designed for the task at hand: identifying the singular answer to a question. Trying to use Google or other Internet search solutions to play Jeopardy!—for example, by doing a search on words from a question and answering with the document topic of the top search result—does not cut it. If only question answering were that easy to solve! This kind of solution answers only 30 percent of the questions correctly.
Artificial Impossibility
I'm wondering how to automate my wonderful self— a wond'rous thought that presupposes my own mental health. Maybe it's crazy to think thought's so tangible, or that I can sing. Either way, if I succeed, my machine will attempt the very same thing.
—What artificial intelligence researchers sing in the shower
It is irresistible to pursue this because, as we pursue understanding natural language, we pursue the heart of what we think of when we think of human intelligence.
—David Ferrucci, Watson Principal Investigator, IBM Research
There's a fine line between genius and insanity.
—Oscar Levant
Were these IBM researchers certifiably nuts to take on this grand challenge, attempting to programmatically answer any Jeopardy! question? They were tackling the breadth of human language that stretches beyond the phrasing of each question to include a sea of textual sources, from which the answer to each question must be extracted. With this ambition, IBM had truly doubled down.
I would have thought success impossible. After witnessing the world's best researchers attempting to tackle the task through the 1990s (during which I spent six years in natural language processing research, as well as a summer at the same IBM Research center that bore Watson), I was ready to throw up my hands. Language is so tough that it seemed virtually impossible even to program a computer to answer questions within a limited domain of knowledge such as movies or wines. Yet IBM had taken on the unconstrained, open field of questions across any domain.
Meeting this challenge would demonstrate such a great leap toward humanlike capabilities that it invokes the “I” word: intelligence. A computer pulling it off would appear as magical and mysterious as the human mind. Despite my own 20-odd years studying, teaching, and researching all things artificial intelligence (AI), I was a firm skeptic. But this task required a leap so great that seeing it succeed might leave me, for the first time, agreeing that the term AI is justified.
AI is a loaded term. It blithely presumes a machine could ever possibly qualify for this title. Only with great audacity does the machine-builder bestow the honor of “intelligence” upon her own creations. Invoking the term comes across as a bit self-aggrandizing, since the inventor would have to be pretty clever herself to pull this off.
The A isn't the problem—it's the I. Intelligence is an entirely subjective construct, so AI is not a well-defined field. Most of its various definitions boil down to “making computers intelligent,” whatever that means! AI ordains no one particular capability as the objective to be pursued. In practice, AI is the pursuit of philosophical ideals and research grants.
What do God, Groucho Marx, and AI have in common? They'd never be a member of a club that would have them as a member. AI destroys itself with a logical paradox in much the same way God does in Douglas Adams's Hitchhiker's Guide to the Galaxy:4
“I refuse to prove that I exist,” says God, “for proof denies faith, and without faith I am nothing.”
“But,” says Man, “The Babel fish [which translates between the languages of interplanetary species] is a dead giveaway isn't it? It could not have evolved by chance. It proves that you exist, and so therefore, by your own arguments, you don't. QED.”
“Oh dear,” says God, “I hadn't thought of that,” and promptly disappears in a puff of logic.
AI faces analogous self-destruction because, once you get a computer to do something, you've necessarily trivialized it. We conceive of as yet unmet “intelligent” objectives that appear big, impressive, and unwieldy, such as transcribing the spoken word (speech recognition) or defeating the world chess champion. They aren't easy to achieve, but once we do pass such benchmarks, they suddenly lose their charm. After all, computers can manage only mechanical tasks that are well understood and well specified. You might be impressed by its lightning-fast speed, but its electronic execution couldn't hold any transcendental or truly humanlike qualities. If it's possible, it's not intelligent. Conversely, as famed computer scientist Larry Tesler succinctly put it, “Intelligence is whatever machines haven't done yet.”
Suffering from an intrinsic, overly grandiose objective, AI inadvertently equates to “getting computers to do things too difficult for computers to do”—artificial impossibility.
Learning to Answer Questions
But in fact, IBM did face a specific, well-defined task: answering Jeopardy! questions. And if the researchers succeeded and Watson happened to appear intelligent to some, IBM would earn extra credit on this homework assignment.
As a rule, anticipating all possible variations in language is not possible. NLP researchers derive elegant, sophisticated systems to deconstruct phrases in English and other natural languages, based on deep linguistic concepts and specially designed dictionaries. But, implemented as computer programs, the methods just don't scale. It's always possible to find phrases that seem simple and common to us as humans, but trip up an NLP system. The researcher, in turn, broadens the theory and knowledge base, tweaking the system to accommodate more phrases. After years of tweaking, these hand-engineered methods still have light-years to go before we'll be chatting with our laptops just the same as with people.
There's one remaining hope: Automate the researchers' iterative tweaking so it explodes with scale as a learning process. After all, that is the very topic of this book:
- Predictive analytics (PA)—Technology that learns from experience (data) to predict the future behavior of individuals in order to drive better decisions.
Applying PA to question answering is a bit different from most of the examples we've discussed in this book. In those cases, the predictive model foretells whether a human will take a certain action, such as click, buy, lie, or die, based on things known about that individual:

IBM's Watson computer includes models that predict whether human experts would consider a Jeopardy! question/answer pair correct:

If the model is working well, it should give a low score, since event horizon, not radiation, is the correct answer (Star Trek fans will appreciate this question's category, “Final Frontiers”). Watson did prudently put a 97 percent score on event horizon and scored its second and third candidates, mass and radiation, at 11 percent and 10 percent, respectively. This approach frames question answering as a PA application:
- What's predicted: Given a question and one candidate answer, whether the answer is correct.
- What's done about it: The candidate answer with the highest predictive score is provided by the system as its final answer.
Answering questions is not prediction in the conventional sense—Watson does not predict the future. Rather, its models “predict” the correctness of an answer. The same core modeling methods apply—but unlike other applications of predictive modeling, the unknown thing being “predicted” is already known by some, rather than becoming known only when witnessed in the future. Through the remainder of this chapter, I employ this alternative use of the word predict, meaning, “to imperfectly infer an unknown.” You could even think of Watson's predictive models as answering the predictive question: “Would human experts agree with this candidate answer to the question?” This semantic issue also arises for predicting clinical diagnosis (Central Table 4), fraud (Central Table 5), human thought (Central Table 8) and other areas—all marked with (for “detect”) in the Central Tables.
Walk Like a Man, Talk Like a Man
IBM needed data—specifically, example Jeopardy! questions—from which to learn. Ask and ye shall receive: Decades of televised Jeopardy! provide hundreds of thousands of questions, each alongside its correct answer (IBM downloaded these from fan websites, which post all the questions). This wealth of learning data delivers a huge, unprecedented boon for pushing the envelope in human language understanding. While most PA projects enjoy as data a good number of example individuals who either did or did not take the action being predicted (such as all those behaviors listed in the left columns of this book's Central Tables of PA applications), most NLP projects simply do not have many previously solved examples from which to learn.
With this abundance of Jeopardy! history, the computer could learn to become humanlike. The questions, along with their answer key, contribute examples of human behavior: how people answer these types of questions. Therefore, this form of data fuels machine learning to produce a model that mimics how a human would answer, “Is this the right answer to this question?”—the learning machine models the human expert's response. We may be too darn complex to program computers to mimic ourselves, but the model need not derive answers in the same manner as a person; with predictive modeling, perhaps the computer can find some innovative way to program itself for this human task, even if it's done differently than by humans.
As Alan Turing famously asked, would a computer program that exhibits humanlike behavior qualify as AI? It's anthropocentric to think so, although I've been called worse.
But having extensive Jeopardy! learning data did not in itself guarantee successful predictive models, for two reasons:
- Open question answering presents tremendous unconquered challenges in the realms of language analysis and human reasoning.
- Unlike many applications of PA, success on Jeopardy! requires high predictive accuracy; The Prediction Effect from Chapter 1—a little prediction goes a long way—does not apply here.
When IBM embarked upon the Jeopardy! challenge in 2006, the state of the art fell severely short. The most notable source of open question answering data was a government-run competition called TREC QA (Text REtrieval Conference—Question Answering). To serve as training data, the contest provided questions that were much more straightforward and simply phrased than those on Jeopardy!, such as, “When did James Dean die?” Competing systems would pore over news articles to find each answer. IBM had a top-five competitor that answered 33 percent of those questions correctly, and no competing system broke the 50 percent mark. Even worse, after IBM worked for about one month to extend the system to the more challenging arena of Jeopardy! questions, it could answer only 13 percent correctly, substantially less than the 30 percent achieved by just using Internet search.
Putting on the Pressure
Scientists often set their own research goals. A grand challenge takes this control out of the hands of the scientist to force them to work on a problem that is harder than one they would pick to work on themselves.
—Edward Nazarko, Client Technical Advisor, IBM
Jumping on the Jeopardy! challenge, IBM put its name on the line. Following the 1997 chess match in which IBM's Deep Blue computer defeated then world champion Garry Kasparov, the 2011 Jeopardy! broadcast pitted man against machine just as publicly, and with a renewed, healthy dose of bravado. A national audience of Jeopardy! viewers waited on the horizon.
As with all grand challenges, success was not a certainty. No precedent or principle had ensured it would be possible to fly across the Atlantic (Charles Lindbergh did so to win $25,000 in 1927); walk on the moon (NASA's Apollo 11 brought people there in 1969, achieving the goal John F. Kennedy set for that decade); beat a chess grandmaster with a computer (IBM's Deep Blue in 1997); or even improve Netflix's movie recommendation system by 10 percent (2009, as detailed in the previous chapter).

Reproduced with permission.
In great need of a breakthrough, IBM tackled the technical challenge with the force only a megamultinational enterprise can muster. With over $92 billion in annual revenue and more than 412,000 employees worldwide, IBM is the third-largest U.S. company by number of employees. All told, its investment to develop Watson is estimated in the tens of millions of dollars, including the dedication of a team that grew to 25 PhD's over four years at its T. J. Watson Research Center in New York (which, like the Jeopardy!-playing computer, was named after IBM's first president, Thomas J. Watson).
The power to push really hard does not necessarily mean you're pushing in the right direction. From where will scientific epiphany emerge? Recall the key innovation that the crowdsourcing approach to grand challenges helped bring to light, ensemble models, introduced in the prior chapter. It's just what the doctor ordered for IBM's Jeopardy! challenge.
The Answering Machine
David Gondek and his colleagues at IBM Research could overcome the daunting Jeopardy! challenge only with synthesis. When it came to processing human language, the state of the art was fragmented and partial—a potpourri of techniques, each innovative in conception but severely limited in application. None of them alone made the grade.
How does IBM's Watson work? It's built with ensemble models. Watson merges a massive amalgam of methodologies. It succeeds by fusing technologies. There's no secret ingredient; it's the overall recipe that does the trick. Inside Watson, ensemble models select the final answer to each question.
Before we more closely examine how Watson works, let's look at the discoveries made by a PA expert who analyzed Jeopardy! data in order to “program himself” to become a celebrated (human) champion of the game show.
Moneyballing Jeopardy!
On September 21, 2010, a few months before Watson faced off on Jeopardy!, televisions across the land displayed host Alex Trebek speaking a clue tailored to the science fiction fan.

Contestant Roger Craig avidly buzzed in. Like any technology PhD, he knew the answer was Spock.
As Spock would, Roger had taken studying to its logical extreme. Jeopardy! requires inordinate cultural literacy, the almost unattainable status of a Renaissance man, one who holds at least basic knowledge about pretty much every topic. To prepare for his appearance on the show, which he'd craved since age 12, Roger did for Jeopardy! what had never been done before. He Moneyballed it.
Roger optimized his study time with prediction. As a mere mortal, he faced a limited number of hours per day to study. He rigged his computer with Jeopardy! data. An expert in predictive modeling, he developed a system to learn from his performance practicing on Jeopardy! questions so that it could serve up questions he was likely to miss in order to efficiently focus his practice time on the topics where he needed it most. He used PA to predict himself.
- What's predicted: Which questions a student will get right or wrong.
- What's done about it: Spend more study time on the questions the student will get wrong.
This bolstered the brainiac for a breakout. On Jeopardy!, Roger set the all-time record for a single-game win of $77,000 and continued on, winning more than $230,000 during a seven-day run that placed him as the third-highest winning contestant (regular season) to date. He was invited back a year later for a “Tournament of Champions” and took its $250,000 first place award. He estimates his own ability to correctly answer 90 percent of Jeopardy! questions, placing him among a small handful of all-time best players.
Analyzing roughly 211,000 Jeopardy! questions (downloaded as IBM did from online archives maintained by fans of the game show), Roger gained perspective on its knowledge domain. If you learn about 10,000 to 12,000 answers, he told me, you've got most of it covered. This includes countries, states, presidents, and planets. But among many categories, you only need to go so far. Designed to entertain its audience, Jeopardy! doesn't get too arcane. So you only need to learn about the top cities, elements, movies, and flowers. In classical music, knowing a couple of dozen composers and the top few works of each will do the trick.
These bounds are no great relief to those pursuing the holy grail of open question answering. Predictive models often choose between only two options: Will the person click, buy, lie, or die—yes or no? As if that's not hard enough, for each question, Watson must choose between more than 10,000 possible answers.
The analytical improvement of human competitors was more bad news for Watson. Allowed by Roger to access his system, Watson's soon-to-be opponent Ken Jennings borrowed the study-guiding software while preparing for the big match, crediting it as “a huge help getting me back in game mode.”
Amassing Evidence for an Answer
Here's how Watson works. Given a question, it takes three main steps:
- Collect thousands of candidate answers.
- For each answer, amass evidence.
- Apply predictive models to funnel down.

Predictive modeling has the final say. After gathering thousands of candidate answers to a question, Watson funnels them down to spit out the single answer scored most highly by a predictive model.
Watson gathers the answers and their evidence from sources that IBM selectively downloaded, a snapshot of a smart part of the Internet that forms Watson's base of knowledge. This includes 8.6 million written documents, consisting of 3.5 million Wikipedia articles (i.e., a 2010 copy of the entire English portion thereof), the Bible, other miscellaneous popular books, a history's worth of newswire articles, entire encyclopedias, and more. This is complemented by more structured knowledge sources such as dictionaries, thesauri, and databases such as the Internet Movie Database.
Watson isn't picky when collecting the candidate answers. The system follows the strategy of casting a wide, ad hoc net in order to ensure that the correct answer is in there somewhere. It rummages through its knowledge sources in various ways, including performing search in much the same way as Internet search engines like Google do (although Watson searches only within its own internal store). When it finds a relevant document, for some document types such as Wikipedia articles, it will grab the document's title as a candidate answer. In other cases, it will nab “answer-sized snippets” of text, as Watson developers call them. It also performs certain lookups and reverse lookups into databases and dictionaries to collect more candidate answers.
Like its fictional human namesake, the partner of Sherlock Holmes, Watson now faces a classic whodunit: Which of the many suspected answers is “guilty” of being the right one?5 The mystery can only be solved with diligent detective work in order to gather as much evidence as possible for or against each candidate. Watson pounds the pavement by once again surveying its sources.
With so many possible answers, uncertainty looms. It's a serious challenge for the machine to even be confident what kind of thing is being asked for. An actor? A movie? State capital, entertainer, fruit, planet, company, novel, president, philosophical concept? IBM determined that Jeopardy! calls for 2,500 different types of answers. The researchers considered tackling a more manageable task by covering only the most popular of these answer types, but it turned out that even if they specialized Watson for the top 200, it could then answer only half the questions. The range of possibilities is too wide and evenly spread for a shortcut to work.
Elementary, My Dear Watson
Evidence counterattacks the enemy: uncertainty. To this end, Watson employs a diverse range of language technologies. This is where the state of the art in NLP comes into play, incorporating the research results from leading researchers at Carnegie Mellon University, the University of Massachusetts, the University of Southern California, the University of Texas, Massachusetts Institute of Technology, other universities, and, of course, IBM Research itself.
Sometimes, deep linguistics matters. Consider this question:

When David Gondek addressed Predictive Analytics World with a keynote, he provided an example phrase that could threaten to confuse Watson:
In May, Gary arrived in India after he celebrated his anniversary in Portugal.
So many words match, the system is likely to include Gary as a candidate answer. Search methods would love a document that includes this phrase. Likewise, Watson's evidence-seeking methods built on the comparison of words would give this phrase a high score—most of its words appear in the question at hand.
Watson needs linguistic methods that more adeptly recognize how words relate to one another so that it pays heed to, for example:
On the 27th of May 1498, Vasco da Gama landed in Kappad Beach.
Other than in, of, and the, only the word May overlaps with the question. However, Watson recognizes meaningful correspondences. Kappad Beach is in India. Landed in is a way to paraphrase arrived in. A 400th anniversary in 1898 must correspond to a prior event in 1498.
These matches establish support for the correct answer, Vasco da Gama. Like all candidate answers, it is evaluated for compatibility with the answer type—in this case, explorer, as determined from this explorer in the question. Vasco da Gama is indeed famed as an explorer, so support would likely be strong.
These relationships pertain to the very meaning of words, their semantics. Watson works with databases of established semantic relationships and seeks evidence to establish new ones. Consider this Jeopardy! question:

Watson's candidate answers include organelle, vacuole, cytoplasm, plasma, and mitochondria. The type of answer sought being a liquid, Watson finds evidence that the correct answer, cytoplasm, makes the cut. It looks up a record listing cytoplasm as a fluid, and has sufficient evidence that fluids are often liquids to boost cytoplasm's score on that basis.
Here, Watson performs a daredevil stunt of logic. Reasoning as humans do in the wide-open domain of Jeopardy! questions is an extreme sport. Fuzziness pervades—for example, most reputable sources Watson may access would state all liquids are fluids, but some are ambiguous as to whether glass is definitely solid or liquid. Similarly, all people are mortal, yet infamous people have attained immortality. Therefore, a strict hierarchy of concepts just can't apply. Because of this, as well as the vagueness of our languages' words and the difference context makes, databases of abstract semantic relationships disagree madly with one another. Like political parties, they often fail to see eye to eye, and a universal authority—an absolute, singular truth—to reconcile their differences simply does not exist.
Rather than making a vain attempt to resolve these disagreements, Watson keeps all pieces of evidence in play, even as they disagree. The resolution comes only at the end, when weighing the complete set of evidence to select its final answer to a question. In this way, Watson's solution is analogous to yours. Rather than absolutes, it adjusts according to context. Some songs are both a little bit country and a little bit rock and roll. With a James Taylor song, you could go either way.
On the other hand, keeping an “open mind” by way of this sort of flexible thinking can lead to embarrassment. Avoiding absolutes means playing fast and loose with semantics, leaving an ever-present risk of gaffes—that is, mistaken answers that seem all too obvious to us humans. For example, in Watson's televised Jeopardy! match, it faced a question under the category “U.S. Cities”:

Struggling, Watson managed to accumulate only scant evidence for its candidate answers, so it would never have buzzed in to attempt the question. However, this was the show's “Final Jeopardy!” round, so a response from each player was mandatory. Instead of the correct answer, Chicago, Watson answered with a city that's not in the United States at all, Toronto. Canadian game show host Alex Trebek poked a bit of fun, saying that he had learned something new.
English grammar matters. To answer some questions, phrases must be properly deconstructed. Consider this question:skiptop

In seeking evidence, Watson pulls up this phrase, which appeared in a Los Angeles Times article:
Ford pardoned Nixon on Sept. 8, 1974.
Unlike you, a computer won't easily see the answer must be Nixon rather than Ford. Based on word matching alone, this phrase provides equal support for Ford as it does for Nixon. Only by detecting that the question takes the passive voice, which means the answer sought is the receiver rather than the issuer of a pardon, and by detecting that the evidence phrase is in the active voice, is this phrase correctly interpreted as stronger support for Nixon than Ford.6
NLP's attempts to grammatically deconstruct don't always work. Complementary sources of evidence must be accumulated, since computers won't always grok the grammar. Language is tricky. Consider this question:

A phrase like this could be stumbled upon as evidence:
Sam was upset before witnessing the near win by Milorad Cavic.
If upset is misinterpreted as a passively voiced verb rather than an adjective, the phrase could be interpreted as evidence for Sam as the question's answer. However, it was swimmer Michael Phelps who held on to his perfect 2008 Olympics performance. Even detecting the simplest grammatical structure of a sentence depends on the deep, often intangible meaning of words.
Mounting Evidence
There's no silver bullet. Whether interpreting semantic relationships between words or grammatically deconstructing phrases, language processing is brittle. Even the best methods are going to get it wrong a lot of the time. This predicament is exacerbated by the clever, intricate manner in which questions are phrased on Jeopardy! The show's question writers have adopted a playful, informative style in order to entertain the TV viewers at home.
The only hope is to accumulate as much evidence as possible, searching far and wide for support of, or evidence against, each candidate answer. Every little bit of evidence helps. In this quest, diversity is the name of the game. An aggregate mass of varied evidence stands the best chance, since neither the cleverest nor the simplest method may be trusted if used solo. Fortunately, diversity comes with the territory: As with scientific research in general, the NLP researchers who developed the methods at hand each worked to distinguish their own unique contribution, intentionally differentiating the methods they designed from those of others.
Watson employs an assorted number of evidence routines that assess a candidate answer, including:
- Passage search. After inserting the candidate answer into the question to try it on for size (e.g., “Nixon was presidentially pardoned on Sept. 8, 1974”) and searching, do many matches come up? How many match word for word, semantically, and after grammatical deconstruction? What's the longest similar sequence of words that each found phrase has in common with the question?
- Popularity. How common is the candidate answer?
- Type match. Does the candidate match the answer type called for by the question (e.g., entertainer, fruit, planet, company, or novel)? If it's a person, does the gender match?
- Temporal. Was the candidate in existence within the question's time frame?
- Source reliability. Does the evidence come from a source considered reliable?
For each question, you never know which of these factors (and the hundreds of variations thereof that Watson measures) may be critical to arriving at the right answer. Consider this question:

Although the correct answer is Argentina, measures of evidence based on simple search show overwhelming support for Bolivia due to a certain border dispute well covered in news articles. Fortunately, enough other supporting evidence such as from logically matched phrases and geographical knowledge sources compensates and wins out, and Watson answers correctly.
Some may view this ad hoc smorgasbord of techniques as a hack, but I do not see it that way. It is true that the most semantically and linguistically intricate approaches are brittle and often just don't work. It can also be said that the remaining methods are harebrained in their oversimplicity. But a collective capacity emerges from this mix of components, which blends hundreds of evidence measurements, even if each alone is crude.7
The Ensemble Effect comes into full play: The sheer count and diversity of approaches make up for their individual weaknesses. As a whole, the system achieves operational proficiency on a previously unachievable, far-off goal: open human language question answering.
Weighing Evidence with Ensemble Models
There are two ways of building intelligence. You either know how to write down the recipe, or you let it grow itself. And it's pretty clear that we don't know how to write down the recipe. Machine learning is all about giving it the capability to grow itself.
—Tom Mitchell, founding chair of the world's first Machine Learning Department (at Carnegie Mellon University)
The key to optimally joining disparate evidence is machine learning. Guided by the answer key for roughly 25,000 Jeopardy! questions, the learning process discovers how to weigh the various sources of evidence for each candidate answer. To this end, David Gondek led the application of machine learning in developing Watson. He had his hands on the very process that brings it all together.
Synthesizing sources of evidence to select a single, final answer propels Watson past the limits of Internet search and into the formerly unconquered domain of question answering. Here's a more detailed overview:

An overview of key steps Watson takes for each question, with an example question and its candidate answers along the bottom. An ensemble model selects the final answer from thousands of candidates.
As shown, Watson gathers candidate answers and then evidence for each candidate. Its ensemble model then scores each candidate answer with a confidence level so that it may be ranked relative to the other candidates. Watson then goes with the answer for which it holds the highest confidence, speaking it out loud when prompted to do so on Jeopardy!
- What's predicted: Given a question and one candidate answer, whether the answer is correct.
- What's done about it: The candidate answer with the highest predictive score is provided by the system as its final answer.
An Ensemble of Ensembles
David led the design of Watson's innovative, intricate machine learning components, of which the ensembling of models is part and parcel. Moving from document search to open question answering demands a great leap, so the design is a bit involved. Watson incorporates ensembling in three ways:
- Combining evidence. Hundreds of methods provide evidence scores for each candidate answer. Instead of tallying a simple vote across contributing evidence scores, as in some work with ensembles described in the prior chapter, the method takes it a step further by training a model to decide how best to fuse them together.8
- Specialized models by question type. Watson has separate specialized ensemble models for specific question types, such as puzzle, multiple choice, date, number, translation, and etymology (about the history and origin of words) questions. In this way, Watson consists of an ensemble of ensembles.
- Iterative phases of predictive models. For each question, Watson iteratively applies several phases of predictive models, each of which can compensate for mistakes made by prior phases. Each phase filters candidates and refines the evidence. The first phase filters down the number of candidate answers from thousands to about one hundred, and subsequent phases filter out more. After each phase's filtering, the evidence scores are reassessed and refined relative to the now-smaller list of candidate answers. A separate predictive model is developed for each phase so that the ranking of the shrinking list of candidates is further honed and refined. With these phases, Watson consists of an ensemble of ensembles of ensembles.
Machine Learning Achieves the Potential of Natural Language Processing
Despite this complexity, Watson's individual component models are fairly straightforward: they perform a weighted vote of the evidence measures. In this way, some forms of evidence count more, and others count less. Although David tested various modeling methods, such as decision trees (covered in Chapter 4), he discovered that the best results for Watson came from another modeling technique called logistic regression, which weighs each input variable (i.e., measure of evidence), adds them up, and then formulaically shifts the resulting sum a bit for good measure.9
Since the model is made up of weights, the modeling process learns to literally weigh the evidence for each candidate answer. The predictive model filters out weak candidate answers by assigning them a lower score. It doesn't help Watson derive better candidate answers—rather, it cleans up the bulky mass of candidates, narrowing down to one final answer.
To this end, the predictive models are trained over 5.7 million examples of a Jeopardy! question paired with a candidate answer. Each example includes 550 predictor variables that summarize the various measures of evidence aggregated for that answer (therefore, the model is made of 550 weights, one per variable). This large amount of training data was formed out of 25,000 Jeopardy! questions. Each question contributes to many training examples, since there are many incorrect candidate answers. Both the correct and incorrect answers provide experience from which the system learns how to best weigh the evidence.
Watson leverages The Ensemble Effect, propelling the state of the art in language processing to achieve its full potential and conquer open question answering. Only by learning from the guidance provided by the archive of Jeopardy! questions was it possible to successfully merge Watson's hundreds of language-processing methods. Predictive modeling has the effect of measuring the methods' relative strengths and weaknesses. In this way, the system quantifies how much more important evidence from linguistically and semantically deep methods can be, and just how moderately simpler word-matching methods should be weighed so that they, too, may contribute to question answering.
With this framework, the IBM team empowered itself to incrementally refine and bolster Watson in anticipation of the televised Jeopardy! match—and moved the field of question answering forward. The system allows researchers to experiment with a continually growing range of language-processing methods: Just throw in a new language-processing technique that retrieves and reports on evidence for candidate answers, retrain the system's ensemble models, and check for its improved performance.
As David and his team expanded and refined the hundreds of evidence-gathering methods, returns diminished relative to efforts. Performance kept improving, but at a slower and slower pace. However, they kept at it, squeezing every drop of potential out of their brainshare and data, right up until the final weeks before the big match.
Confidence without Overconfidence
Both experts and laypeople mistake more confident predictions for more accurate ones. But overconfidence is often the reason for failure. If our appreciation of uncertainty improves, our predictions can get better too.
—Nate Silver, The Signal and the Noise: Why So Many Predictions Fail—but Some Don't
You got to know when to hold 'em, know when to fold 'em.
—Don Schlitz, “The Gambler” (sung by Kenny Rogers)
Jeopardy! wasn't built for players with no self-doubt.
—Chris Jones, Esquire magazine
Besides answering questions, there's a second skill each Jeopardy! player must hone: assessing self-confidence. Why? Because you get penalized by answering incorrectly. When a question is presented, you must decide whether to attempt to buzz in and provide an answer. If you do, you'll either gain the dollar amount assigned to the question or lose as much.
In this way, Jeopardy! reflects a general principle of life and business: You need not do everything well; select the tasks at which you excel. It's the very practice of putting your best foot forward. In fact, many commercial uses of PA optimize on this very notion. Just as Watson must predict which questions it can successfully answer, businesses predict which customers will be successfully sold to—and therefore are worth the expenditure of marketing and sales resources.
Calculating a measure of self-confidence in each answer could be a whole new can of worms for the system. Is it a tall order to require the machine to “know thyself” in this respect?
David Gondek showed that this problem could be solved “for free.” The very same predictive score output by the models that serves to select the best answer also serves to estimate confidence in that answer. The scores are probabilities. For example, if a candidate answer with a score of 0.85 has a higher score than every other candidate, it will be Watson's final answer, and Watson will consider its chance of being correct at 85 percent. As the IBM team put it, “Watson knows what it knows, and it knows what it doesn't know.”
Watching Watson's televised Jeopardy! matches, you can see these self-confidence scores in action. For each question, Watson's top three candidate answers are displayed at the bottom of your TV screen along with their confidence scores (for example, see the second figure in this chapter). Watson bases its decision to buzz in on its top candidate's score, plus its position in the game relative to its opponents. If it is behind, it will play more aggressively, buzzing in even if the confidence is lower. If ahead in the game, it will be more conservative, buzzing in to answer only when highly confident.
A player's success depends not only on how many answers are known, but on his, her, or its ability to assess self-confidence. With that in mind, here's a view that compares Jeopardy! players:
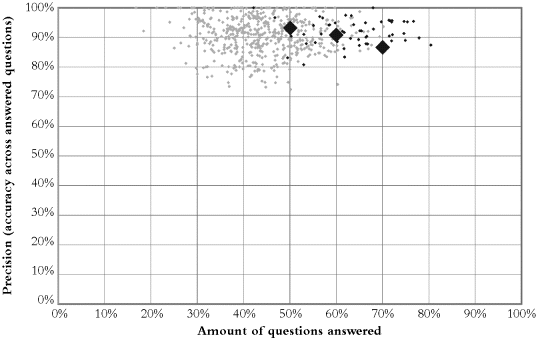
Jeopardy! player performances. Each dot signifies a winner's game (the dark dots represent Ken Jennings's games). The three large diamonds represent the per-game performance Watson can achieve.10
Players strive for the top right of this graph. Most points on the graph depict the performance of an individual human player. The horizontal axis indicates what proportion of questions they successfully buzzed in for, and the vertical axis tells us, for those questions they answered, how often they were correct. Buzzing in more would put you further to the right, but would challenge you with the need to know more answers.
Human Jeopardy! winners tend toward the top, since they usually answer correctly, and some also reach pretty far to the right. Each light gray dot represents the performance of the winner of one game. The impressively positioned dark gray dots that stretch further to the right represent the outstanding performance of champion player Ken Jennings, whose breathtaking streak of 74 consecutive wins in 2004 demonstrated his prowess. He is one of the two champions against whom Watson was preparing to compete.
Watson performs at the level of human experts. Three example points (large diamonds) are shown to illustrate Watson's potential performance. When needed, Watson sets itself to buzz in more often, assuming an aggressive willingness to answer even when confidence is lower. This moves its performance to the right and, as a result, also a bit down. Alternatively, when playing more conservatively, fewer questions are attempted, but Watson's answer is more often correct—precision is higher (unlike politics, on this graph left is more conservative).
Human sweat empowered Watson's human level of performance. The machine's proficiency is the product of four painstaking years of perseverance by the team of researchers.11
The Need for Speed
There was one more requirement. Watson had to be fast.
A Jeopardy! player has only a few seconds to answer a question, but on a single computer (e.g., 2.6 gigahertz), determining an answer can take a couple of hours. It's a lengthy process because Watson employs hundreds of methods to search a huge number of sources, both to accrue candidate answers and to collect evidence measurements for each one. It then predictively scores and ranks the candidates by applying the series of predictive models (I refer here only to the deployed use of Watson to play Jeopardy!, after the machine learning process is completed and the models are being employed without further learning).
To make it thousands of times faster, Watson employs thousands of CPUs. This supercomputer clobbers bottlenecks and zips along, thanks to a cluster of 90 servers consisting of 2,800 core processors. It handles 80 trillion operations per second. It favors 15 terabytes of RAM over slower hard-drive storage. The cost of this hardware brawn is estimated to come to $3 million, a small fraction of the cost to develop its analytical software brains.
Having thousands of CPUs means that thousands of tasks can be done simultaneously, in parallel. Watson's process lends itself so amenably to taking advantage of this hardware by way of distribution into contemporaneous subtasks that the research team considers it embarrassingly parallel. For example, each evidence-seeking, language-processing routine can be assigned to its own processor.
Better is bigger. To assemble Watson, IBM crated in a mammoth configuration of hardware, about 10 refrigerators' worth. Watson didn't go to Jeopardy!; Jeopardy! came to Watson, setting up a temporary game show studio within IBM's T. J. Watson Research Center.
Double Jeopardy!—Would Watson Win?
Watson was not sure to win. During sparring games against human champions, Watson had tweaked its way up to a 71 percent win record. It didn't always win, and these trial runs didn't pit it against the lethal competition it was preparing to face on the televised match: all-time leading Jeopardy! champions Ken Jennings and Brad Rutter.skiptop

Reproduced with permission.
The Jeopardy! match was to gain full-scale media publicity, exposing IBM's analytical prowess or failure. The top-rated quiz show in syndication, Jeopardy! attracts nearly 9 million viewers every day and would draw an audience of 34.5 million for this special man-versus-machine match. If the massive popularity of Jeopardy! put on the pressure, so too was it the only reason this grand challenge might be doable. As the United States' greatest pop culture institution of human knowledge, Jeopardy!'s legacy provided the treasure trove of historical question/answer pairs from which Watson learns.
Beyond impressing or disappointing your average home viewer, Watson's impending performance held enormous professional ramifications. Within both the practical realm of information technology and the research world of artificial intelligence, IBM had loudly proclaimed that it was prepared to run a three-and-a-half-minute mile. After the immense investment, one can only imagine the seething pressure the research team must have felt from the powers at IBM to defend the corporate image and ensure against public humiliation. At this juncture, the researchers saw clear implications for their scientific careers as well as for science itself.
During its formative stages, Watson's most humorous mistakes entertained, but threatened to embarrass IBM on national TV. Under the category “The Queen's English”:

Watson said: urinate (correct answer: call on the phone).
Under the category “New York Times Headlines”:

Watson said: a sentence (correct answer: World War I).
Under the category “Boxing Terms”:

Watson said: wang bang (correct answer: low blow).
The team rallied for the home stretch. Watson principal investigator David Ferrucci, who managed the entire initiative, moved everyone from their offices into a common area he considered akin to a war room, cultivating a productive but crisislike level of eustress. Their lives were flipped on their heads. David Gondek moved temporarily into a nearby apartment to eliminate his commuting time. The team lived and breathed open question answering. “I think I dream about Jeopardy! questions now,” Gondek said. “I have nightmares about Jeopardy! questions. I talk to people in the form of a question.”
Jeopardy! Jitters: Deploying a Prototype
There's no such thing as human error. Only system error.
—Alexander Day Chaffee, software architect
Core Watson development team member Jennifer Chu-Carroll tried to stay calm. “We knew we probably were gonna win, but…what if we did the math wrong for some reason and lost by a dollar instead of won by a dollar?” There were provisions in their agreement with the Jeopardy! producers for do-overs in the case of a hardware crash (the show was taped, not broadcast live, and like any computer, sometimes you need to turn off Watson and then start it back up again). However, if Watson spat out an embarrassing answer due to a software bug without crashing, nothing could be done to take it back. This was going to national television.
Groundbreaking deployments of new technology—whether destined to be in orbit or intelligent—risk life and limb, not only because they boldly go where no one has gone before, but because they launch a prototype. Moon-bound Apollo 11 didn't roll off the assembly line. It was the first of its kind. The Watson system deployed on Jeopardy! was beta. Rather than conducting the established, sound process of “productizing” a piece of software for mass distribution, this high-speed, real-time behemoth was constructed not by software engineers who build things, but by the same scientific researchers who designed and developed its analytical capabilities. On the software side, the deployed system and the experimental system were largely one and the same. There was no clear delineation between some of the code they used for iterative, experimental improvement with machine learning and code within the deployed system. Of course, these were world-class researchers, many with software design training, but the pressure mounted as these scientists applied virtual hammer to nail to fashion a vessel that would propel their laboratory success into an environment of high-paced, unforeseen questions.
Shedding their lab coats for engineering caps, the team members dug in as best they could. As David Gondek told me, changes in Watson's code continued even until and including the very day before the big match, which many would consider a wildly unorthodox practice in preparing for a mission-critical launch of software. Nobody on the team wanted to be the programmer who confused metric and English imperial units in their code, thus crashing NASA's Mars Climate Orbiter, as took place in 1998 after a $327.6 million, nine-month trip to Mars. Recall the story of the Netflix Prize (see Chapter 5), which was won in part by two nonanalysts who found that their expertise as professional software engineers was key to their success.
The brave team nervously saw Watson off to meet its destiny. The training wheels were off. Watson operates on its own, self-contained and disconnected from the Internet or any other knowledge source. Unlike a human Jeopardy! player, the one connection it does need is an electrical outlet. It's scary to watch your child fly from the nest. Life has no safety net.
As a machine, Watson was artificial. The world would now witness whether it was also intelligent.
For the Win
You are about to witness what may prove to be an historic competition.
—Alex Trebek
If functional discourse in human language qualifies, then the world was publicly introduced to the greatest singular leap in artificial intelligence on February 14, 2011.
As the entertainment industry would often have it, this unparalleled moment in scientific achievement was heralded first with Hollywood cheese, and only secondarily with pomp and circumstance. After all, this was a populist play. It was, in a sense, the very first conversant machine ever, and thus potentially easier for everyone to relate to than any other computer. Whether perceived as Star Trek-ian electronic buddy or HAL-esque force to be reckoned with, 34.5 million turned on the TV to watch it do its thing.
The Jeopardy! theme song begins to play,12 and a slick, professional voice manically declares, “From the T. J. Watson Research Center in Yorktown Heights, New York, this is Jeopardy!, the IBM Challenge!”
When colleagues and I watch the footage, there's a bit of culture shock: We're looking for signs of AI, and instead see glitzy show business. But this came as no surprise to the members of Team Watson seated in the studio audience, who had been preparing for Jeopardy! for years.
Once the formalities and introductions to Watson pass, the show moves along jauntily as if it's just any other episode, as if there is nothing extraordinary about the fact that one of the players spitting out answer after answer is not an articulate scholar with his shirt buttoned up to the top, but instead a robot with a synthetic voice straight out of a science fiction movie.
But for David Gondek and his colleagues it was anything but ordinary. The team endured a nail-biting day during the show's recording, one month before its broadcast. Watching the two-game match, which was televised over a three-day period, you see dozens of questions fly by. When the camera turns for audience reactions, it centers on the scientists, David Ferrucci, David Gondek, Jennifer Chu-Carroll, and others, who enjoy moments of elation and endure the occasional heartache.
On this day, Machine triumphed over Man. Watson answered 66 questions correctly and eight incorrectly. Of those eight, only the answer that categorized Toronto as a U.S. city was considered a gaffe by human standards. The example questions covered in this chapter marked with an asterisk (“*”) were fielded by Watson during the match (all correctly except the one answered with Toronto). The final scores, measured in Jeopardy! as dollars, were Watson: $77,147, Jennings: $24,000, and Rutter: $21,600.13
Prompted to write down his answer to the match's final question, Ken Jennings, invoking a Simpsons meme originating from an H. G. Wells movie, appended an editorial: “I, for one, welcome our new computer overlords.” He later ruminated, “Watson has lots in common with a top-ranked human Jeopardy! player: It's very smart, very fast, speaks in an uneven monotone, and has never known the touch of a woman.”
After Match: Honor, Accolades, and Awe
I would have thought that technology like this was years away, but it's here now. I have the bruised ego to prove it.
—Brad Rutter
This was to be an away game for humanity, I realized.
—Ken Jennings
Maybe we should have toned it down a notch.
—Sam Palmisano, then CEO, IBM
One million-dollar first place award for the Jeopardy! match? Check (donated to charities). American Technology Awards' “Breakthrough Technology of the Year Award”? Check. R&D magazine “Innovator of the Year” award? Check.
Webby “Person of the Year” award? Unexpected, but check.
Riding a wave of accolades, IBM is working to reposition components of Watson and its underlying question-answering architecture, which the company calls DeepQA, to serve industries such as healthcare and finance. Consider medical diagnosis. The wealth of written knowledge is so great, no doctor could read it all; providing a ranked list of candidate diagnoses for each patient could mean doctors miss the right one less often. Guiding the analysis of knowledge sources by learning from training data—answers in the case of Jeopardy! and diagnoses in the case of healthcare—is a means to “capture and institutionalize decision-making knowledge,” as Robert Jewell of IBM Watson Solutions put it to me.
Iambic IBM AI
Is Watson intelligent? The question presupposes that such a concept is scientific in the first place. The mistake has been made, as proselytizers have often “over-souled” AI (credit for this poignant pun goes to Eric King, president of the consultancy he dubbed with the double entendre The Modeling Agency). It's easy to read a lot into the thing. Case in point: I once designed a palindrome-generation system (a palindrome reads the same forward and backward) when teaching the AI course at Columbia University that spontaneously derived “Iambic IBM AI.” This one is particularly self-referential in that its meter is iambic.
Some credit Watson with far too much smarts. A guard working at IBM's research facility got David Gondek's attention as he was leaving for the day. Since this was a machine that could answer questions about any topic, he suggested, why not ask it who shot JFK?
Strangely, even technology experts tend to answer this philosophical question with a strong opinion in one direction or the other. It's not about right and wrong. Waxing philosophical is a dance, a wonderful, playful pastime. I like to join in the fun as much as the next guy. Here are my thoughts:
Watching Watson rattle off one answer after another to diverse questions laced with abstractions, metaphors, and extraneous puns, I am dumbfounded. It is the first time I've felt compelled to anthropomorphize a machine in a meaningful way, well beyond the experience of suspending disbelief in order to feel fooled by a magic trick. To me, Watson looks and feels adept, not just with information but with knowledge. My perceptions endow it with a certain capacity to cogitate. It's a sensation I never thought I'd have cause to experience in my lifetime. To me, Watson is the first artificial intelligence.
If you haven't done so, I encourage you to watch the Jeopardy! match (see the Notes at www.PredictiveNotes.com for a YouTube link).
Predict the Right Thing
Predictive models are improving and achieving their potential, but sometimes predicting what's going to happen misses the point entirely. Often, an organization needs to decide what next action to take. One doesn't just want to predict what individuals will do—one wants to know what to do about it. To this end, we've got to predict something other than what's going to happen—something else entirely. Turn to the next chapter to find out what.