
Chapter 4
Defining the Functional Difference
IN THIS CHAPTER
![]() Examining declarations
Examining declarations
![]() Working with functional data
Working with functional data
![]() Creating and using functions
Creating and using functions
As described in Chapter 1 and explored in Chapters 2 and 3, using the functional programming paradigm entails an approach to problems that differs from the paradigms that languages have relied on in the past. For one thing, the functional programming paradigm doesn’t tie you to thinking about a problem as a machine would; instead, you use a mathematical approach that doesn’t really care about how the machine solves the problem. As a result, you focus on the problem description rather than the solution. The difference means that you use declarations —formal or explicit statements describing the problem — instead of procedures — step-by-step problem solutions.
 To make the functional paradigm work, the code must manage data differently than when using other paradigms. The fact that functions can occur in any order and at any time (allowing for parallel execution, among other things) means that functional languages can’t allow mutable variables that maintain any sort of state or provide side effects. These limitations force developers to use better coding practices. After all, the use of side effects in coding is really a type of shortcut that can make the code harder to understand and manage, besides being far more prone to bugs and other reliability issues.
To make the functional paradigm work, the code must manage data differently than when using other paradigms. The fact that functions can occur in any order and at any time (allowing for parallel execution, among other things) means that functional languages can’t allow mutable variables that maintain any sort of state or provide side effects. These limitations force developers to use better coding practices. After all, the use of side effects in coding is really a type of shortcut that can make the code harder to understand and manage, besides being far more prone to bugs and other reliability issues.
This chapter provides examples in both Haskell and Python to demonstrate the use of functions. You see extremely simple uses of functions in Chapters 2 and 3, but this chapter helps move you to the next level.
Comparing Declarations to Procedures
The term declaration has a number of meanings in computer science, and different people use the term in different ways at different times. For example, in the context of a language such as C, a declaration is a language construct that defines the properties associated with an identifier. You see declarations used for defining all sorts of language constructs, such as types and enumerations. However, that’s not how this book uses the term declaration. When making a declaration in this book, you’re telling the underlying language to do something. For example, consider the following statement:
- Make me a cup of tea!
The statement tells simply what to do, not how to do it. The declaration leaves the execution of the task to the party receiving it and infers that the party knows how to complete the task without additional aid. Most important, a declaration enables someone to perform the required task in multiple ways without ever changing the declaration. However, when using a procedure named MakeMeTea (the identifier associated with the procedure), you might use the following sequence instead:
- Go to the kitchen.
- Get out the teapot.
- Add water to the teapot.
- Bring the pot to a boil.
- Get out a teacup.
- Place a teabag in the teacup.
- Pour hot water over the teabag and let steep for five minutes.
- Remove the teabag from the cup.
- Bring me the tea.
A procedure details what to do, when to do it, and how to do it. Nothing is left to chance and no knowledge is assumed on the part of the recipient. The steps appear in a specific order, and performing a step out of order will cause problems. For example, imagine pouring the hot water over the teabag before placing the teabag in the cup. Procedures are often error prone and inflexible, but they do allow for precise control over the execution of a task. Even though making a declaration might seem to be superior to a procedure, using procedures does have advantages that you must consider when designing an application.
Declarations do suffer from another sort of inflexibility, however, in that they don't allow for interpretation. When making a declarative statement (“Make me a cup of tea!”), you can be sure that the recipient will bring a cup of tea and not a cup of coffee instead. However, when creating a procedure, you can add conditions that rely on state to affect output. For example, you might add a step to the procedure that checks the time of day. If it’s evening, the recipient might return coffee instead of tea, knowing that the requestor always drinks coffee in the evening based on the steps in the procedure. A procedure therefore offers flexibility in its capability to interpret conditions based on state and provide an alternative output.
Declarations are quite strict with regard to input. The example declaration says that a cup of tea is needed, not a pot or a mug of tea. The MakeMeTea procedure, however, can adapt to allow variable inputs, which further changes its behavior. You can allow two inputs, one called size and the other beverage. The size input can default to cup and the beverage input can default to tea, but you can still change the procedure's behavior by providing either or both inputs. The identifier, MakeMeTea, doesn’t indicate anything other than the procedure’s name. You can just as easily call it MyBeverageMaker.
 One of the hardest issues in moving from imperative languages to functional languages is the concept of declaration. For a given input, a functional language will produce the same output and won't modify or use application state in any way. A declaration always serves a specific purpose and only that purpose.
One of the hardest issues in moving from imperative languages to functional languages is the concept of declaration. For a given input, a functional language will produce the same output and won't modify or use application state in any way. A declaration always serves a specific purpose and only that purpose.
The second hardest issue is the loss of control. The language decides how to perform tasks, not the developer. Yet, you sometimes see functional code where the developer tries to write it as a procedure, usually producing a less-than-desirable result (when the code runs at all).
Understanding How Data Works
Data is a representation of something — perhaps a value. However, it can just as easily represent a real-world object. The data itself is always abstract, and existing computer technology represents it as a number. Even a character is a number: The letter A is actually represented as the number 65. The letter is a value, and the number is the representation of that value: the data. The following sections discuss data with regard to how it functions within the functional programming paradigm.
Working with immutable data
Being able to change the content of a variable is problematic in many languages. The memory location used by the variable is important. If the data in a particular memory location changes, the value of the variable pointing to that memory location changes as well. The concept of immutable data requires that specific memory locations remain untainted. All Haskell data is immutable.
Python data, on the other hand, isn’t immutable in all cases. The “Passing by reference versus by value” section that appears later in the chapter gives you an example of this issue. When working with Python code, you can rely on the id function to help you determine when changes have occurred to variables. For example, in the following code, the output of the comparison between id(x) and oldID will be false.
x = 1
oldID = id(x)
x = x + 1
id(x) == oldID
 Every scenario has some caveats, and doing this with Python does as well. The
Every scenario has some caveats, and doing this with Python does as well. The id of a variable is always guaranteed unique except in certain circumstances:
- One variable goes out of scope and another is created in the same location.
- The application is using multiprocessing and the two variables exist on different processors.
- The interpreter in use doesn't follow the CPython approach to handling variables.
When working with other languages, you need to consider whether the data supported by that language is actually immutable and what set of events occurs when code tries to modify that data. In Haskell, modifications aren’t possible, and in Python, you can detect changes, but not all languages support the functionality required to ensure that immutability is maintained.
Considering the role of state
Application state is a condition that occurs when the application performs tasks that modify global data. An application doesn’t have state when using functional programming. The lack of state has the positive effect of ensuring that any call to a function will produce the same results for a given input every time, regardless of when the application calls the function. However, the lack of state has a negative effect as well: The application now has no memory. When you think about state, think about the capability to remember what occurred in the past, which, in the case of an application, is stored as global data.
Eliminating side effects
Previous discussions of procedures and declarations (as represented by functions) have left out an important fact. Procedures can’t return a value. The first section of the chapter, “Comparing Declarations to Procedures,” presents a procedure that seems to provide the same result as the associated declaration, but the two aren’t the same. The declaration “Make me a cup of tea!” has only one output: the cup of tea. The procedure has a side effect instead of a value. After making a cup of tea, the procedure indicates that the recipient of the request should take the cup of tea to the requestor. However, the procedure must successfully conclude for this event to occur. The procedure isn’t returning the tea; the recipient of the request is performing that task. Consequently, the procedure isn’t returning a value.
Side effects also occur in data. When you pass a variable to a function, the expectation in functional programming is that the variable’s data will remain untouched — immutable. A side effect occurs when the function modifies the variable data so that upon return from the function call, the variable changes in some manner.
Seeing a Function in Haskell
Haskell is all about functions, so, unsurprisingly, it supports a lot of function types. This chapter doesn't overwhelm you with a complete listing of all the function types (see Chapter 5, for example, to discover lambda functions), but it does demonstrate two of the more important function types (non-curried and curried) in the following sections.
Using non-curried functions
You can look at non-curried functions as Haskell’s form of the standard function found in other languages. The next section explains the issue of currying, but for now, think of standard functions as a stepping-stone to them. To create a standard function, you provide a function description like this one:
add (x, y) = x + y
This function likely looks similar to functions you create in other languages. To use this function, you simply type something like add (1, 2) and press Enter. Figure 4-1 shows the result.
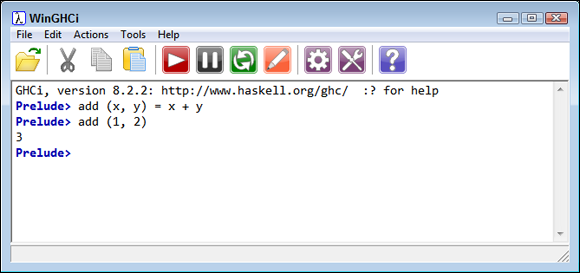
FIGURE 4-1: Create and use a new function named add.
Functions can act as the basis for other functions. Incrementing a number is really just a special form of addition. Consequently, you can create the inc function shown here:
inc (x) = add (x, 1)
As you can see, add is the basis for inc. Using inc is as simple as typing something like inc 5 and pressing Enter. Note that the parentheses are optional, but you could also type inc (5) and press Enter. Figure 4-2 shows the result.
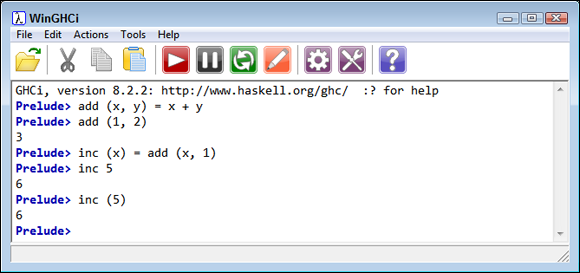
FIGURE 4-2: Use add as the basis for inc.
Using curried functions
Currying in Haskell is the process of transforming a function that takes multiple arguments into a function that takes just one argument and returns another function when additional arguments are required. The examples in the previous section act as a good basis for seeing how currying works in contrast to non-curried functions. Begin by opening a new window and creating a new version of add, as shown here:
add x y = x + y
The difference is subtle, but important. Notice that the arguments don't appear in parentheses and have no comma between them. The function content still appears the same, however. To use this function, you simply type something like add 1 2 and press Enter. Figure 4-3 shows the result.
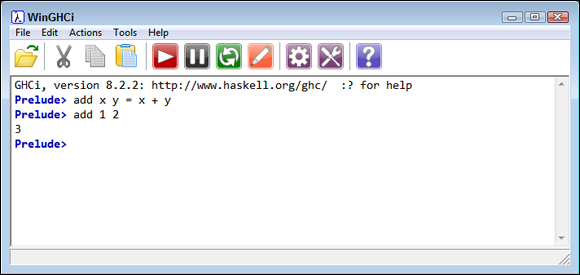
FIGURE 4-3: The curried form of add uses no parentheses.
You don’t actually see the true effect of currying, though, until you create the inc function. The inc function really does look different, and the effects are even more significant when function complexity increases:
inc = add 1
This form of the inc function is shorter and actually a bit easier to read. It works the same way as the non-curried version. Simply type something like inc 5 and press Enter to see the result shown in Figure 4-4.
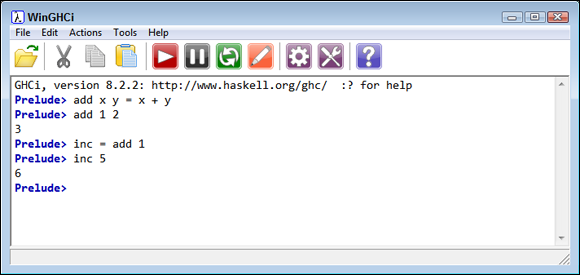
FIGURE 4-4: Currying makes creating new functions easier.
Interestingly enough, you can convert between curried and non-curried versions of a function as needed using the built-in curry and uncurry functions. Try it with add by typing uadd = uncurry add and pressing Enter. To prove to yourself that uadd is indeed the non-curried form of add, type uadd 1 2 and press Enter. You see the error shown in Figure 4-5.
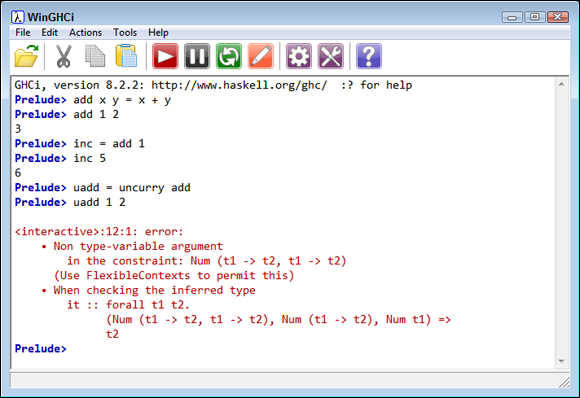
FIGURE 4-5: The uadd function really is the non-curried form of add.
 You can use curried functions in some places where non-curried functions won't work. The
You can use curried functions in some places where non-curried functions won't work. The map function is one of these situations. (Don’t worry about the precise usage of the map function for now; you see it demonstrated in Chapter 6.) The following code adds a value of 1 to each of the members of the list.
map (add 1) [1, 2, 3]
The output is [2,3,4] as expected. Trying to perform the same task using uadd results in an error, as shown in Figure 4-6.
![Screen capture of WinGHCi window with the code map (add 1) [1, 2, 3] and output [2,3,4] followed by map (uadd 1) [1, 2, 3] and the error report.](http://imgdetail.ebookreading.net/202009/02/9781119527503/9781119527503__functional-programming-for__9781119527503__images__9781119527503-fg0406.png)
FIGURE 4-6: Curried functions add essential flexibility to Haskell.
Seeing a Function in Python
Functions in Python look much like functions in other languages. The following sections show how to create and use Python functions, as well as provide a warning about using them in the wrong way. You can compare this section with the previous section to see the differences between pure and impure function use. (The “Defining Functional Programming” section of Chapter 1 describes the difference between pure and impure approaches to functional programming.)
Creating and using a Python function
Python relies on the def keyword to define a function. For example, to create a function that adds two numbers together, you can use the following code:
def add(x, y):
return x + y
To use this function, you can type something like add(1, 2). Figure 4-7 shows the output of this code when you run it in Notebook.
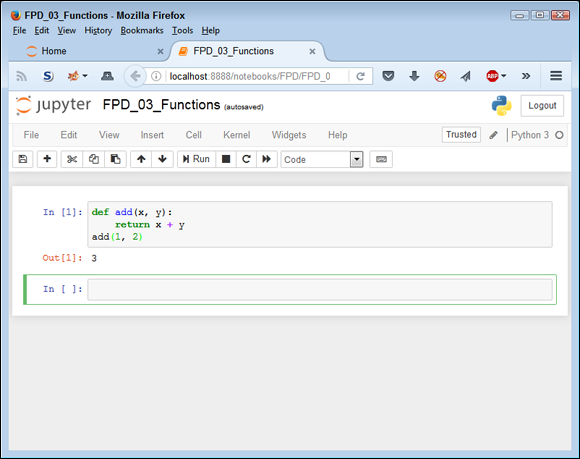
FIGURE 4-7: The add function adds two numbers together.
As with Haskell, you can use Python functions as the basis for defining other functions. For example, here is the Python version of inc:
def inc(x):
return add(x, 1)
The inc function simply adds 1 to the value of any number. To use it, you might type something like inc(5) and then run the code, as shown in Figure 4-8, using Notebook.
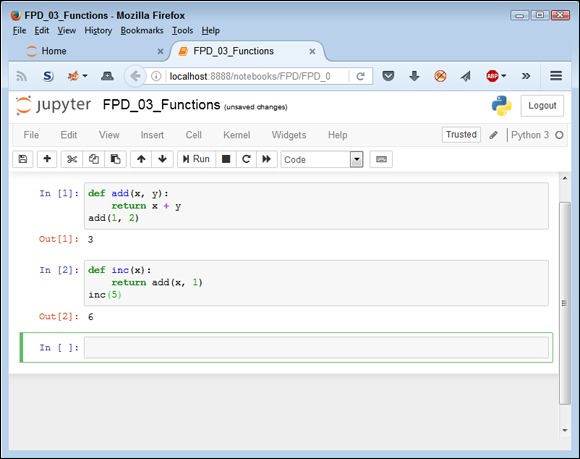
FIGURE 4-8: You can build functions using other functions as needed.
Passing by reference versus by value
The point at which Python shows itself to be an impure language is the use of passing by reference. When you pass a variable by reference, it means that any change to the variable within the function results in a global change to the variable's value. In short, using pass by reference produces a side effect, which isn’t allowed when using the functional programming paradigm.
Normally, you can write functions in Python that don’t cause the passing by reference problem. For example, the following code doesn’t modify x, even though you might expect it to:
def DoChange(x, y):
x = x.__add__(y)
return x
x = 1
print(x)
print(DoChange(x, 2))
print(x)
The value of x outside the function remains unchanged. However, you need to exercise care when creating functions using some objects and built-in methods. For example, the following code will modify the output:
def DoChange(aList):
aList.append(4)
return aList
aList = [1, 2, 3]
print(aList)
print(DoChange(aList))
print(aList)
The appended version will become permanent in this case because the built-in function, append, performs the modification. To avoid this problem, you must create a new variable within the function, change its value, and then return the new variable, as shown in the following code:
def DoChange(aList):
newList = aList.copy()
newList.append(4)
return newList
aList = [1, 2, 3]
print(aList)
print(DoChange(aList))
print(aList)
Figure 4-9 shows the results. In the first case, you see the changed list, but the second case keeps the list intact.
![Screen capture of WinGHCi window with two functions and their results. In [4]: [1, 2, 3]; [1, 2, 3, 4]; [1, 2, 3, 4] and In [5]: [1, 2, 3]; [1, 2, 3, 4]; [1, 2, 3].](http://imgdetail.ebookreading.net/202009/02/9781119527503/9781119527503__functional-programming-for__9781119527503__images__9781119527503-fg0409.png)
FIGURE 4-9: Use objects and built-in functions with care to avoid side effects.
Whether you encounter a problem with particular Python objects or not depends on their mutability. An int isn't mutable, so you don’t need to worry about having problems with functions changing its value. On the other hand, a list is mutable, which is the source of the problems with the examples that use a list in this section. The article at https://medium.com/@meghamohan/mutable-and-immutable-side-of-python-c2145cf72747 offers insights into the mutability of various Python objects.