
19
Fog Computing to Enable Geospatial Video Analytics for Disaster-incident Situational Awareness
Dmitrii Chemodanov, Prasad Calyam, and Kannappan Palaniappan
Department of Electrical Engineering and Computer Science, University of Missouri Columbia, MO, USA
19.1 Introduction
Computer Science is no more about computers than astronomy is about telescopes.
–E.W. Dijkstra
Computer science advances go far beyond creating a new piece of hardware or software. The latest advances are increasingly fostering the development of new algorithms and protocols for a more effective/efficient use of cutting-edge technologies within new computing paradigms. What follows is an introduction to a novel function-centric computing (FCC) paradigm that allows traditional computer vision applications to scale faster over geo-distributed hierarchical cloud-fog infrastructures. We discuss salient challenges in realizing this paradigm and show its benefits through a prism of disaster-incident response scenarios. Based on innovative data collection and processing solutions, we illustrate how geospatial video analytics enabled by FCC can help coordinate disaster relief resources to save lives.
19.1.1 How Can Geospatial Video Analytics Help with Disaster-Incident Situational Awareness?
In the event of natural or man-made disasters, timely and accurate situational awareness is crucial for assisting first responders in disaster relief coordination. To this end, imagery data, such as videos and photographs, can be collected from numerous disaster-incident scenes using surveillance cameras, civilian mobile devices, and aerial platforms. This imagery data processing can be essential for first responders to (1) provide situational awareness for law enforcement officials (e.g. by using online face recognition to reunite lost citizens [1]), and (2) inform critical decisions for allocating scarce relief resources (e.g. medical staff/ambulances or search-and-rescue teams [2]). Building dynamic three-dimensional reconstructions of incident scenes can increase situational awareness in a theater-scale setting (as large as two city blocks) of the incident scene. This can be achieved by fusing crowd-sources and data-intensive surveillance imagery [3]. Furthermore, tracking objects of interest in wide-area motion imagery (WAMI) can provide analytics for planning wide-area relief and law enforcement activities at the regional-scale of incident scenes (tens of city blocks) [4]. We use the term geospatial video analytics to refer to such an integration of computer vision algorithms implemented for different scales and types of imagery/video data collected from Internet of Things (IoT) devices, and processed through geo-distributed hierarchical cloud-fog platforms.
19.1.2 Fog Computing for Geospatial Video Analytics
To be effective for users (i.e. incident commanders, first responders), geospatial video analytics needs to involve high-throughput data collection as well as seamless data processing of imagery/video [5]. For instance, the user's quality of experience (QoE) expectations demand that the geospatial video analytics is resilient to any edge network connectivity issues for data collection, while also delivering low-latency access (e.g. in real time) to process large amounts of visual data using cloud-fog resources that run complex computer vision algorithms. The fog resources are augmented by cloud resources, as well as services closer to end-user's IoT devices, to allow computing anywhere within the IoT-to-cloud continuum. Thus, providing applications with options for fog computing reduces cloud service latencies enables computing closer to the IoT data sources at the network edges.
Figure 19.1 shows how cloud/fog resources are used for imagery data processing to realize a collection, computation, and consumption (3C) pipeline that is common for any geospatial video analytics use case. In this stage of data collection, it is possible that the network edge could have lost infrastructure, e.g. loss of cellular base stations in a disaster scene and/or intermittently accessible IoT devices (e.g. sensors, wearable heads-up display devices, Bluetooth beacons). Similarly, in the stage of data processing, it is quite likely that infrastructure edges are rarely equipped with high-performance computation capabilities to run computer vision algorithms. Moreover, cloud-processed data needs to be moved closer to users through content caching at fog resources for thin-client consumption and interactive visual data exploration. Thus, adoption of fog computing in conjunction with cloud computing platforms for relevant compute, storage, and network resource provisioning and management requires a new computing paradigm. Moreover, the cloud-fog resource provisioning becomes an NP-hard problem to solve in large-scale visual data processing across distributed disaster incident scenes [6].

Figure 19.1 Illustrative example of a visual data computing at network edges (i.e. at fog) that needs to span geographically dispersed sites of data collection, computation, and consumption: fog computing resources here are linked with cloud computing platforms.
19.1.3 Function-Centric Cloud/Fog Computing Paradigm
To address both the data collection and data processing problems in geospatial video analytics, we prescribe a novel FCC paradigm that integrates computer vision, edge routing, and computer/network virtualization areas. Figure 19.2 illustrates the FCC paradigm that extends the basic 3C pipeline for data collection at the edge with preprocessing and human-computer interaction (HCI) analysis functions (i.e. “small instance functions”) that can be placed for low-latency access on edge servers by using fog computing. For example, in this context, to cope with the potential loss of infrastructure at the collection site near a disaster scene, we can use mobile ad hoc wireless networks (MANETs) which need to be operational for collecting media-rich visual information from this scene as quickly as possible at the edge cloud gateway. In another example, for processing large-scale visual data sets using object tracking computer vision algorithms, the FCC involves the placement of computer-intensive tracking functions (i.e. “large instance functions”) on a cloud server. Thus, applying the FCC paradigm can accomplish geospatial video analytics by suitable computer location selection that is based on decoupling of visual data processing functions for theater-scale or regional-scale applications. The decoupling can allow for cloud-fog resource orchestration that results in speed-up of traditional computer vision algorithms by several orders of magnitude [5]. In essence, FCC can be extended to existing computation offloading techniques found in mobile cloud computing literature, where virtualization principles are used for decoupling computers, storage, and network functions in resource allocation and management of cloud-fog resources [7, 8].

Figure 19.2 Illustrative example of the function-centric fog/cloud computing paradigm used for the real-time object tracking pipeline [5].
19.1.4 Function-Centric Fog/Cloud Computing Challenges
First, FCC assumes that data collection involves the ability to collect data even in lost infrastructure regions, e.g. loss of cellular base stations in a disaster scene, as well as in the presence of intermittently available and mobile IoT devices. For FCC to be operational in such edge network scenarios, we need to steer user traffic dynamically within MANETs to satisfy its throughput and latency requirements. To this aim, we cannot adopt full-fledged routing solutions from core networks due to mobility as well as power constraints of IoT devices. Instead, lightweight routing approaches, such as those based on geographic routing, are more suited. However, there is a lack of traffic steering techniques in MANETs that can provide sustainable high-speed delivery of data to a geo-distributed cloud infrastructure gateway component [9]. Specifically, this can be achieved by designing a more high-performing greedy-forwarding approach that is not subject to the local minimum problem due to (severe) IoT failures and mobility. This problem is caused by the lack of global network knowledge of greedy forwarding algorithms (see e.g. [10–13]), which can deliver packets to nodes with no neighbors closer to the destination than themselves. Second, FCC implementation requires refactoring computer vision applications that are typically developed with codes that are tightly coupled for ad hoc theater/regional task-specific solutions, and are not designed for function portability. For this, principles from the recent advances in serverless computing used in Amazon Web Services Lambda [14], Google Cloud Functions [15], Microsoft Azure Functions [16], and IBM OpenWhisk [17] can be used. More specifically, FCC can mitigate application scalability limitations via use of microservices, where application code decoupling is performed via RESTful Application Programming Interfaces (APIs) [5] to manage load balancing, elasticity, and server instance types independently for each application function.
Third, FCC implementation that can satisfy geo-location and latency demands of geospatial video analytics needs to cope with node failures and congested network paths that frequent impact (QoS) requirements [18]. Especially in specific cases of natural or man-made disaster incidents, FCC will be subject to severe infrastructure outages and austere edge-network environments [19]. Moreover, computation and network QoS demands of computer vision functions can fluctuate, depending on the progress of the disaster incident response activities [20]. Thus, the FCC needs to use reliability-ensuring mechanisms to cope proactively with both potential computer vision function demand fluctuations [20] as well as possible infrastructure outages [18, 19].
Lastly, optimal placement of computer vision functions as shown in Figure 19.2 is a known “Service Function Chaining (SFC)” problem in the network function virtualization (NFV) area. The SFC has known approximation guarantees only in some special cases where chaining of service functions [21] and/or their ordering [22, 23] are omitted. In the general case, however, it requires solving of the NP-hard integer multi-commodity-chain flow (MCCF) problem to align flow splits with supported hardware granularity [24]. It is also necessary to support cases when service functions or their associated flows are nonsplittable. This subproblem has no known approximation guarantees and has been previously reported as the integer NFV service distribution problem [25]. Furthermore, its complexity can be exacerbated by incorporated reliability and geo-location/latency-aware mechanisms. The former aims to cope proactively with both possible infrastructure outages as well as function demand fluctuations, whereas the latter is needed to satisfy QoS demands of geo-distributed latency-sensitive function chains.
19.1.5 Chapter Organization
This chapter seeks to introduce concepts of fog computing related to enabling geospatial video analytics at theater and regional scales for disaster-incident situational awareness. The chapter will first discuss the natural decomposability of common computer vision applications (i.e. for face recognition, object tracking, and 3-D scene reconstruction) to a set of functions that motivates the need of FCC paradigm. Following this, we outline innovative state-of-the-art solutions to the “data collection” and “data processing” problems in geospatial video analytics that are based on theoretical and experimental research conducted by the authors in the Virtualization, Multimedia and Networking (VIMAN) Lab, and Computational Imaging and VisAnalysis (CIVA) Lab at University of Missouri-Columbia (supported in part by the Coulter Foundation Translational Partnership Program, and the National Science Foundation CNS-1647084 award). More specifically, we present a novel “artificial intelligence (AI)–augmented geographic routing approach” that can address the data collection challenges of geospatial video analytics at the wireless network edge within lost infrastructure regions. In addition, we present a novel “metapath composite variable approach” that can be used for a near-optimal and practical geo/latency-constrained SFC over fog/cloud platforms to enable data processing in geospatial video analytics. Last, we discuss the main findings of this chapter with the list of open challenges for adopting fog computing architectures in geospatial video analytics to effectively and efficiently deliver disaster-incident situational awareness.
19.2 Computer Vision Application Case Studies and FCC Motivation
In this section, we consider three common computer vision applications that operate on different data scales (e.g. theater-scale vs. regional-scale) and have different latency and geo-location requirements. In particular, we describe benefits of FCC for the following application case studies: (1) real-time patient triage status tracking with Panacea's Cloud incident command dashboard [26] featuring face recognition, (2) reconstruction of dynamic visualizations from 3-D light detection and ranging (LIDAR) scans [27], and (3) tracking objects of interest in WAMI [2]. Recall that we distinguish between theater-scale and regional-scale applications based on the geographical coverage of the incident and the nature of the distributed visual data – with theater-scale being small area (two city blocks) around a disaster incident site, and regional-scale being large areas (dozens of city blocks) distributed across multiple disaster incident sites. The salient contribution of our work is to transform exemplar computer vision applications (e.g. face recognition, 3-D scene reconstruction, and object tracking), with state-of-the-art solutions for increasing speed of “data collection” and scale of “data processing” using edge routing and SFC, as detailed in the following Sections 19.3 and 19.4, respectively.
19.2.1 Patient Tracking with Face Recognition Case Study
19.2.1.1 Application's 3C Pipeline Needs
Following medical triage protocols of hospitals during response coordination at natural or man-made disaster incident scenes is challenging. Especially when dealing with several patients with trauma, it is stressful for paramedics to verbally communicate and track patients.

Figure 19.3 Illustrative example of the Panacea's Cloud setup: IoT device data sets generated on-site (e.g. near disaster scenes) need to be collected through a MANET at the edge cloud for further processing in conjunction with the core cloud.
In our first case study application, “Panacea's Cloud” [26], the FCC needs to support a incident command dashboard, as shown in Figure 19.3, that can handle patient tracking using real-time IoT device data streams (e.g. video streams from wearable heads-up display or smartphones, geolocation information from virtual beacons) from multiple incident scenes. Proper aggregation of the IoT data sets and intuitive user interfaces in the dashboard can be critical for efficient coordination between first responder agencies, e.g. fire, police, hospitals, and so on [28]. The dashboard supports real-time videoconferencing of paramedics with the incident commander for telemedical consultation, medical supplies replenishment communication, or coordination of ambulance routing at a theater-scale incident site. It can also facilitate patient triage status tracking through secure mapping of the geolocation information with a face recognition application, where the latter is used to recognize the person and, if possible, pull his/her relevant medical information [29]. Such a mapping is essential to ensure that the relevant patients at the incident sites are provided the necessary care, and follow-ups on the care can be scheduled with new responders or at a new location of the patient. The face recognition capability can also be used in the dashboard for “lost person” use cases, where first responders can detect children when attempting to reunite them with their guardians [30], or identify bad actors in crowds, who might raise public safety resource allocation decisions.
19.2.1.2 Face Recognition Pipeline Details
The visual data processing pipeline steps for face recognition are shown in Figure 19.4 and can be divided into two main classes according to the nature of the inherent functions, such as:
- Small function processing. Compression, preprocessing, and results verification
- Large function processing. Segmentation and face detection, features extraction and matching
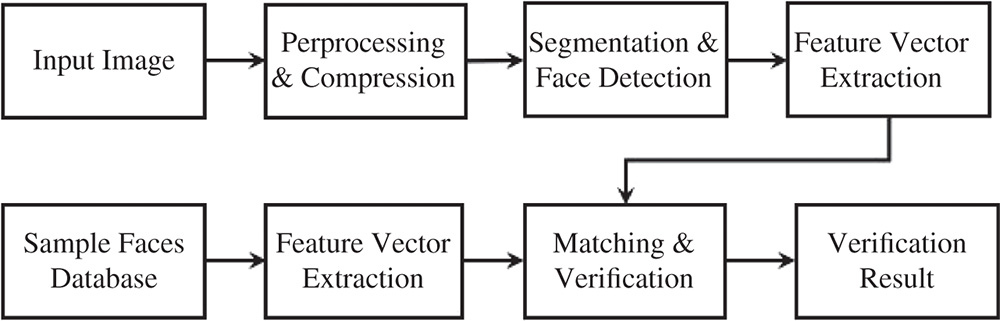
Figure 19.4 Overview of visual data processing stages in a facial recognition application used in patient triage status tracking.
Small function processing is mainly focused on pure pixel-level information. In contrast, large function processing is focused on both pixel and object level information. To work effectively, large functions typically require data preprocessing stages. Figure 19.4 shows facial recognition steps that are used for “Panacea's Cloud” patient tracking and involve the digital image at the client side and a larger image sample dataset at the server side. A preprocessing step is performed to first detect a human face within a small amount of time (i.e. with low latency). During this step, all input images are compressed to one quarter of their original size. Subsequently, the image is fed into a pretrained face classifier. This classifier is provided by Dlib [31] (an open-source library) and is based on [32] for facial recognition tasks. Training is done using a “very deep” convolutional neural network, which comprises a long sequence of convolutional layers that have recently shown state-of-the-art performance in related tasks.
19.2.2 3-D Scene Reconstruction from LIDAR Scans
19.2.2.1 Application's 3C Pipeline Needs
3-D scene reconstructions have been proven to be useful for a quick damage assessment by public safety organizations. Such an assessment is possible through highly accurate LIDAR scans at incident scenes that provide evidence at relevant locations from multiple viewpoints [33]. As Figure 19.5 shows, 3-D models of a scene can be created, e.g. by fusing a set of 2-D videos and LIDAR scans. This visual data can be obtained from civilian mobile devices as well as from surveillance cameras near (or at) incident scenes. In our second case study application, FCC registers 2-D videos with 3-D LIDAR scans collected at the theater scale. As a result, first responders can view sets of videos in an intuitive (3-D) virtual environment [27]. This simplifies the cumbersome task of analyzing several disparate 2-D videos on a grid display. However, commonly used data from LIDAR scans can be large in size – a typical resolution of about 1 cm for data collected at a range of up to 300 m with 6 mm accuracy. Thus, when collected from large-area incident scenes, this data can be computationally expensive to process. To help with this processing, FCC can help take advantage of this rich source of information and quickly provide the situational awareness.

Figure 19.5 Illustrative example of a 3-D scene reconstruction with use of LIDAR scans: a 2-D video frame (top left) is first projected onto LIDAR scan (bottom left) to then reconstruct a 3-D scene (right).
19.2.2.2 3-D Scene Reconstruction Pipeline Details
Fusing a video with a LIDAR scan requires calculation of camera poses for 2-D video with respect to the 3-D point space. Figure 19.6 illustrates steps of matching a 2-D video frame to LIDAR scans with known 3-D correspondences, calculation of projection matrix for the camera, and segmentation of moving objects in the 3-D space. The steps of the visual data processing pipeline in this case study application can be classified as follows:
- Small function processing. Metadata data preprocessing, 2-D video frame background registration, rendering of 3-D
- Large function processing. Projection matrix calculation, segmentation of motion, positioning of dynamic objects
To better understand what each function computes, we describe one possible pipeline of the 3-D scene reconstruction using LIDAR scan and 2-D videos. We start by estimation of the 2-D-3-D relationship between the LIDAR scan and its photographs. To this end, we map 2-D pixels to 3-D points during a preprocessing step using standard computer vision techniques described in [34]. The entire point space is projected onto each image exactly once. Subsequently, the 2-D-3-D mappings can be stored at a remote cloud server location. Identification of moving objects in the 2-D video is performed using the mixture of Gaussians (MOG) approach [35] that yields a binary image featuring the motion segmented from the background.

Figure 19.6 Overview of 3-D scene reconstruction stages with 2-D videos and LIDAR scans.
19.2.3 Tracking Objects of Interest in WAMI
19.2.3.1 Application's 3C Pipeline Needs
Tracking objects of interest is crucial for (intelligent) search-and-rescue activities after a large-area disaster incident. Object tracking has long shown potential for city-wide crowd surveillance by providing a hawk-eye's view for public safety organizations. Our third case study application that relates to search-and-rescue type of activities operates on the regional scale by identifying and tracking objects of interest in WAMI. This in turn can assist incident managers in studying the behaviors of particular vehicles [2]. The tracker's input is in the form of bounding boxes that indicate targets, as shown in Figure 19.7. Novel sensor technologies allow responders to capture high-resolution imagery data (ranging between 10 cm and 1 m) for wide-area surveillance. The processing is performed by our likelihood of features tracking (LoFT) framework, which utilizes WAMI frames with a high resolution of 25 cm ground sampling distance (GSD) coming at about one to four frames per second [36]. Utilizing FCC for tracking such imagery data can be challenging, for several reasons. First of all, the objects of interest are usually small with a (relatively) large motion displacement due to the inherent low frame rate. Secondly, WAMI imagery itself is challenging for automated analytics due to multiple reasons including (but not limited to) variations in illumination, oblique camera viewing angles, tracking through shadows, occlusions from tall structures, blurring, and stabilization artifacts (e.g. due to atmospheric conditions). LOFT uses a set of imagery features, including gradient magnitude, histogram of oriented gradients, median binary patterns [37], eigenvalues of the Hessian matrix for shape indices, and intensity maps.

Figure 19.7 Illustrative example of WAMI imagery ecosystem: tiled (TIFF) aerial images of 80 MB size and with a resolution of 7800 × 10 600 pixels.
19.2.3.2 Object Tracking Pipeline Details
Typical object tracking in wide-area motion imagery comprises several visual data processing stages tested on (large-area) aerial data [38, 39]. Figure 19.8 outlines these stages, which can be classified according to the tracker functionality as follows:
- Small function processing. Raw data compression, data storage, metadata preprocessing, geo-projection, tiling, and stabilization
- Large function processing. Initialization of objects of interest, their detection, tracking, and analysis. A small function processing mainly operates on pure pixel level information, whereas a large function processing deals with information on both pixel as well as object levels. We remark that for most of large functions to work effectively, we need the preprocessing stages while applying our FCC approach. For example, common object trackers benefit from imagery stabilization, and hence registration becomes crucial during data preprocessing. Our LOFT case study utilizes a track-before-detect approach to significantly reduce the search space, which is especially helpful in large wide-area motion imagery, as most of the objects in WAMI look similar [2, 40]. However, a proper synchronization between large tracking and small preprocessing functions is needed for this approach. To this aim, latency constraints have to be imposed to avoid bottlenecks in the tracking pipeline. When the tracker is fully consolidated on a single server, it has a processing rate of three to four frames per second. Thus, it is also important to take into account bandwidth demands because even a single WAMI frame can be 80 MB in size; and at four frames per second, the maximum throughput required is up to 2.5 Gbps.

Figure 19.8 Overview of object tracking stages in a typical WAMI analysis pipeline.
19.3 Geospatial Video Analytics Data Collection Using Edge Routing
Fog computing relies on the use of wireless edge networks to facilitate data marshaling with IoT devices that are intermittently available and mobile. It is possible for IoT devices to experience scarce energy, high mobility, and frequent failures [41, 42], which consequently makes fog computing difficult. In extreme conditions (i.e. after a disaster or in remote areas), fog computing needs to be set up even within lost infrastructure regions without, e.g., cellular connectivity and operational in specialized wireless sensor network environments. In this section, we consider a special case of data marshaling at the network edge to collect data for geospatial video analytics at a gateway dashboard from disaster incident scenes over MANETs. However, MANETs are commonly subject to the high node-mobility as well as severe node failures (e.g. caused by intermittent energy supply). Consequently, there is a need for packet delivery solutions that utilize either network topology knowledge [42–45] or rely on a logically centralized network control [5, 8]. In this section, we detail our novel edge routing protocol based on our work in [28], in order to overcome throughput sustainability challenges of data collection when using existing solutions within lost infrastructure regions.
19.3.1 Network Edge Geographic Routing Challenges
Software-defined networking (SDN) and NFV have been recently adopted to overcome some of the challenges in data marshaling between IoT devices and the edge network gateway (e.g. to access cloud-fog resources) [5, 8]. For instance, a control plane can be used to dynamically find paths that satisfy IoT-based application low-latency and bandwidth demands [5, 46]. Existing edge routing solutions commonly rely on the network topology knowledge, such as spanning trees [44, 47], or on the network clusters knowledge [45]. These solutions may not be suitable in highly dynamic conditions, such as the one caused by severe node failures and/or high node mobility. To this aim, a geographic routing approach can be utilized to cope with existing MANET solution limitations in disaster incident scenarios. However, routing protocols that use this approach are not typically capable of providing sustained and high-throughput data rates for a satisfactory visual data delivery to the edge gateway [9]. This is mainly due to the local minimum problem that frequently occurs in the presence of nonarbitrary node mobility and failures. This problem manifests mainly owing to the lack of global network knowledge of the greedy forwarding algorithm [10–13]. As a result, packets may be delivered to nodes with no neighbors closer to the destination than themselves. This, in turn, makes it impossible to find the next hop during packet-forwarding actions.
Existing solutions only partially address the local minimum problem and can be divided into stateless and stateful solutions. Existing stateless greedy forwarding algorithms may not deliver packets even if a path exists [11, 12]. In addition, they can also stretch such paths significantly to desperately find a way to the destination [10]. On the other hand, existing stateful greedy forwarding solutions that rely on some network topology knowledge (e.g. partial paths [42] or spanning trees [44, 47]) are sensitive to high IoT device mobility and their frequent failures [42, 43, 48]. Given that such conditions are common in disaster incident scenarios, implementations that use these algorithms can have poor/unacceptable performance to deliver high-speed visual data to the network edge gateway in order to provide situational awareness.
Examples of routing protocols that guarantee packet delivery are the greedy perimeter stateless routing (GPSR) [11] and GFG [49]. Although both protocols can recover packets from a local minimum by using face routing, they are based on strong assumptions, such as planar and unit disk graphs. Their strong assumptions rarely hold in practice especially when: nodes are mobile, graphs have arbitrary shapes and physical obstacles manifest [50]. To overcome such limitations, the authors in [50] propose a solution that avoids use of planar graphs by proposing a cross-link detection protocol (CLDP) complication. However, it has been shown that CLDP requires an expensive signaling mechanism to first detect and then remove crossed edges [43]. As an alternative, authors in [44, 51] have proposed a greedy distributed spanning tree routing (GDSTR) protocol. This protocol uses (less expensive) distributed spanning trees to guarantee packet delivery and recover them from local minima. Another solution to the local minimum problem is to use a greedy embedding method that assigns “local minima-free” virtual coordinates based on spanning trees [47]. More recent works [42, 43, 48] have shown that spanning trees are also highly sensitive to network dynamics, such as node mobility and failures.
Owing to the above limitations, newer routing protocols have been proposed to cope with topology dynamics to some extent [42, 43]. For example, MTD routing protocol requires construction of Delaunay triangulation (DT) graphs for local minimum recovery [43]. When topology changes, nodes may lose their Delaunay neighbors, which are needed for recovery from a local minimum degrading MTD performance under node mobility and/or failures. The authors in [10] build their approach upon the work in [47]. In particular, they show how packet delivery can subject to a local minimum due to greedy embedding inaccuracies caused by network dynamics. As a solution, they propose a novel routing protocol, viz., gravity pressure greedy forwarding (GPGF) [10]. GPGF is shown to have guaranteed packet delivery on graphs of an arbitrary shape at the expense of packet header space [48] and can stretch paths significantly violating packets' time-to-leave (TTL) constraints. In contrast, our work titled “Artificial Intelligence–Augmented Geographic Routing Approach (AGRA)” in [28] overcomes aforementioned challenges and delivers packets with sustained and high-speed throughput to the network edge gateway. In the remainder of this section, we detail our AGRA solution, which proactively avoids local minima by utilizing obstacles knowledge mined from satellite imagery.
19.3.2 Artificial Intelligence Relevance in Geographic Routing
Under severe node failures and mobility caused by disaster-incident scenarios, routing protocols cannot rely on the network topology knowledge, such as spanning trees, routing tables, etc. As a result, most of the geographic routing-based protocols (especially those designed for static sensor networks) today are poorly applicable for MANETs during the disaster-incident response application use cases described earlier in Section 19.2. At the same time, we can observe how local minimum of the greedy forwarding often happens near large physical obstacles (especially those of concave shapes). Examples of such obstacles include (but are not limited to) natural obstacles (e.g. lakes or ponds) or man-made obstacles (e.g. buildings). Figure 19.9a,b illustrate these obstacles over an example satellite imagery dataset.
As part of the geospatial video analytics pipeline, the information about physical obstacles can be mined directly from the satellite maps of the disaster-incident area. Figure 19.10 shows maps of Joplin, Missouri, before and right after tornado damages that occurred on May 22, 2011. We can see how information (such as location, size, etc.) of the Joplin Hospital (see Figure 19.10a,b) and the Joplin High School (see Figure 19.10c,d) buildings is mainly preserved after tornado damages. As a result, we can mine information about potential physical obstacles even from maps of the disaster-incident area that do not contain information about any marked damages. To this aim, we need to address the following problems: (1) how can information about potential obstacles be extracted from the satellite imagery of the disaster scene, and (2) how can we utilize this knowledge within a geographic routing-based protocol to improve the latter's application layer data-throughput. Thus, a well-designed cloud-fog computing integration with this extended geographical routing approach that uses satellite imagery knowledge can ensure that user QoE demands are met in terms of obtaining real-time situational awareness in disaster response coordination.

Figure 19.9 Various physical obstacles including both man-made e.g. buildings (a) and natural e.g. lakes or ponds (b) over an example satellite imagery dataset that can be used for training purposes.

Figure 19.10 Joplin, MO satellite maps of Joplin Hospital (a, b) and Joplin High School (c, d) buildings before (a, c) and right after (b, d) tornado damages that occurred on May 22, 2011. This satellite imagery is taken from openly available source at [52].
19.3.3 AI-Augmented Geographic Routing Implementation
To mine information about physical obstacles that can be utilized by the network edge geographic routing algorithm, one can manually label all such obstacles on the map that can cause potential local minima. However, due to the fact that time is critical for first responders, manually labeling physical obstacles on maps in a timely manner is not feasible for large-area incident scenes, and thus we aim to automate this labeling process. The AI techniques, particularly in the pattern recognition literature, can be ideal candidates to automate this process, as they include many approaches to detect objects (i.e. determine their size and location) in any given (satellite) imagery. These approaches can include nearest neighbor, support vector machines, deep learning and other techniques. However, present-day state-of-the-art detectors are based on deep learning approaches [53, 54]. For example, the “You Only Look Once” deep-learning-based technique can detect objects in images using only a single (26 layers) neural network – an easier task for the fog resources [53]. On the other hand, its performance can be worse than the one shown by more sophisticated deep learning-based detectors [54].1
The deep-learning-based detectors may misclassify obstacles or not find them at all, and thus, they still need some human assistance in sample labeling. To further address deep learning complexity limitations, we move its functions to the cloud resources, as shown in Figure 19.11 for our Panacea's Cloud application, and overcome resource limitations of fog storage and computation. Assuming that training samples can be collected and partly labeled at the fog (e.g. during prior incident responses), we can use them for (semi-) supervised deep learning [56] to improve object detection in the future. The available detector can be always (pre-)uploaded to the fog resources and used in an off-line manner to support edge routing within lost infrastructure regions of a disaster-incident. After detection, the information about physical obstacles is propagated by AGRA through services supported at the network edge gateway to the MANET.
To benefit from an obstacles information, AGRA features a conceptually different greedy forwarding mode that repels packets away from these obstacles [28]. This mode utilizes the electrostatic potential field calculated via Green's function, and to the best of our knowledge it is the first greedy forwarding approach that provides theoretical guarantees on a shortest path approximation as well as on a local minima avoidance. In [28], we also show how this mode can be augmented with the GPGF protocol gravity pressure mode to provide practical guarantees on local minima avoidance and recovery. To this end, we have proposed two algorithms, viz., attractive repulsive greedy forwarding (ARGF) and attractive repulsive pressure greedy forwarding (ARPGF). Both algorithms alternate attractive and repulsive packet greedy forwarding modes in 2-D or 3-D Euclidean spaces [28]. Our numerical simulations also indicate their superior performance in terms of a path stretch reduction as well as a delivery ratio increase with respect to GPGF. Thus, ARPGF can be suitable for routing in MANETs under challenging disaster-incident conditions. We remark that such improvements are due to the knowledge of obstacles that allow our improved routing protocols better cope with severe node failures and high mobility. As a result, both these routing protocols demonstrate overall greater application level throughput under challenging conditions of disaster-incident response scenarios, making them crucial for real-time (visual) situational awareness. Note that the performance of these routing protocols degrades with respect to their predecessor performances, i.e. ARGF to GF [12] and ARPGF to GPGF [10], with the object information quality degradation, e.g. due to miscalculations by deep learning-based detectors. Due to space constraints, we omit details of our edge routing protocols that utilize the AI-AGRA, and refer curious readers to [28] for more details.

Figure 19.11 To cope with deep learning functions complexity of the obstacle detector, we move them to the core cloud. The up-to-date detector can be then pre-uploaded to the fog and used in an off-line manner to enhance edge routing.
19.4 Fog/Cloud Data Processing for Geospatial Video Analytics Consumption
Once data collection hurdles are overcome using AGRA, data processing within cloud-fog platforms needs to be orchestrated for the consequent geospatial video analytics. To ensure satisfactory user QoE in the consumption stages of the pipeline, fog computing needs to cope with geographical resource accessibility and latency demands of geospatial video analytics [57]. To this end, the fog computing APIs augment the core/public cloud APIs closer to the end user locations at the expense of computation/storage capabilities available locally (on-site). Correspondingly, emerging paradigms, such as the microservices introduced in Section 19.1, can help seamless data-intensive fog computing in conjunction with cloud computing to compensate the insufficient local processing capabilities within a geographical area of interest. An essential system aspect in the design to use microservices is to perform application code decoupling (as atomic services) to manage fog/cloud leased resources independently for each application function. Resulting geo-distributed latency-sensitive “service chains” have to be orchestrated as follows: they first have to be composed from the leased fog/cloud platform resources and then maintained throughout their lifetime. Composing an instance of a virtual function chain (or a virtual network in general) requires the QoS-constrained service chain to be mapped on top of a physical network hosted by a single infrastructure provider, or by a federation of providers. This problem is similar to NFV SFC, where traffic is redirected on-demand trough a “chain” of middleboxes that host specific network functions,, as firewalls, load balancers, and others to satisfy resource providers' policies [58]. In the rest of this section, we first describe SFC challenges related to data processing of geospatial video analytics. We then propose a novel constrained shortest path–based SFC composition and maintenance approach, the “Matapath-based composite variable approach” [6].
19.4.1 Geo-Distributed Latency-Sensitive SFC Challenges
SFC is traditionally used in NFV to place a set of middleboxes and chain relevant functions to steer traffic through them [59]. Existing SFC solutions either separate the service placement from the service chaining phase [21–23], or jointly optimize both of the two phases [20, 25].
19.4.1.1 SFC Optimality
In some special cases the optimal SFC is shown to have approximation guarantees [21–23]. For instance, authors in [22, 23] provide near-optimal approximation algorithms for the SFC problem without chaining and ordering constraints. Also, the authors in [21] propose the first SFC solution with the approximation guarantees, which admits ordering constraints, but still omits chaining constraints. The work in [60] shows approximation guarantees for SFCs with both ordering and chaining constraints, but only under assumptions that available service chaining options are of polynomial size. In the general case, however, when service functions need to be jointly placed and chained in a geo-distributed cloud-fog infrastructure with a corresponding compute/network resource allocation, possible SFC compositions are of exponential size. Thus, it becomes a linear topology virtual network embedding (VNE) [61, 62] and can be formulated as the (NP-hard) MCCF problem with integrality constraints with no known approximation guarantees [25]. To this aim, the authors in [25] propose a heuristic algorithm that relies on a number of active resources that can be used to consolidate flows. The preliminary evaluation results of this algorithm in a small-scale network settings (of 10 nodes) show promise for providing efficient solutions to the integer MCCF problem in practical settings.
19.4.1.2 SFC Reliability
With the advent of edge networking and a growing number of latency sensitive services, recent works also consider problems of geodistributed [63] and edge SFC [64]. Although these works mainly focus on the new load balancing and latency optimization techniques, they omit an important reliability aspect of geo-distributed latency-sensitive SFCs. The closest works related to ours are [20, 65]. Authors in [20] propose a prediction-based approach that proactively handles SFC demand fluctuations. However, their approach does not account for network/infrastructure outages that mainly cause service function failures [18]. At the same time, work in [65] proposes a SFC solution that ensures a sufficient infrastructure reliability, but neither proactively nor reactively handles SFC demand fluctuations.
19.4.1.3 Our Approach
We present the first (to our knowledge) practical and near-optimal SFC composition approach in the general case of joint service function placement and chaining in a geo-distributed cloud-fog infrastructure. Our approach also is the first to admit end-to-end network QoS constraints, such as latency, packet loss, etc. In particular, we describe a novel metapath composite variable approach that reduces a combinatorial complexity of the (master) integer MCCF problem. As a result, our approach achieves 99% optimality on average and takes seconds to compose SFCs for practically sized problems of US Tier-1 (300 nodes) and regional (600 nodes) infrastructure providers' topologies. In contrast, master MCCF problem solution takes hours using a high-performance computing cloud server [6]. Moreover, in contrast to [20, 65], the proposed metapath composite variable approach allows us to uniquely ensure reliability of geo-distributed latency-sensitive SFCs via use of chance-constraints and backup policies. Details of our metapath composite variable approach design and implementation to cope with both SFC demand fluctuations and infrastructure outages as described in [6] are summarized in the remainder of this section.
19.4.2 Metapath-Based Composite Variable Approach
To simplify the combinatorial complexity of the integer MCCF-based SFC composition problem, we present an abridged description of our novel metapath-based composite variable approach detailed in [6]. Similar to existing composite variable schemes [66], our goal is to create a binary variable that composes multiple (preferably close to optimal) decisions. To this end, we build upon a known result in optimization theory: all network flow problems can be decomposed into paths and cycles [67]. We first introduce our notion of metapath and its relevance to the constrained shortest-path problem [68–70]. We then use the constrained shortest metapaths to create variables with composite decisions for the SFC composition problem and discuss scalability improvements of this approach.
19.4.2.1 Metalinks and Metapaths
Before defining the metapath, it is useful to introduce the idea of “metalinks.” Metalinks have been widely adopted in prior NFV/VNE literature to solve optimally graph matching problems [25, 71]. A metalink is an augmentation link in a network graph. In our case, it represents the (potential) feasible placement of some service a on some physical node A, as shown in Figure 19.12. Formally, we have:
Building on the definition of a metalink, we can define a metapath as the path that connects any two services through the physical network augmented with metalinks. For example, consider following metapaths a–A–Y–b and a–A–B–b, as shown in Figure 19.12. Formally, we have:

Figure 19.12 Illustrative example of the augmented with metalinks physical network which represent feasible service a, b, and c placements; numbers indicate fitness function values – red and black values annotate service placement and service chaining via some physical link, respectively.
Intuitively, metapath Pijst is formed by exactly two metalinks that connect s and t to the physical network and an arbitrary number of physical links kl 2 ES.
19.4.2.2 Constrained Shortest Metapaths
Having defined metapaths, let us consider a simple case of the SFC composition problem – composition of a single-link chain (i.e. two services connected via a single virtual link): the optimal composition of a single-link chain can be seen as the constrained shortest (meta)path problem. This connects two services via the augmented physical network, where (1) all physical links have arbitrary fitness values of a service chaining (virtual link mapping), and (2) all metalinks have arbitrary fitness values of a service placement divided by the number of neighboring services (i.e. by 1 for a single-link chain). In our example, shown in Figure 19.3, the optimal single-link SFC a–b composition can be represented by the constrained shortest metapath a–A–Y–b, which satisfies all SFC composition constraints with the overall fitness function of 3.
19.4.2.3 Multiple-link Chain Composition via Metapath
While observing Figure 19.12, we can notice how using only a single constrained shortest metapath per a single-link segment of a multiple-link SFC a–b–c can lead to an unfeasible composition: as the optimal a–b composition is a–A–Y–b metapath. Also, the optimal b–c composition is b–B–X–c metapath, and the service b has to be simultaneously placed on Y and B physical nodes. Thus, we cannot stitch these metapaths, and we need to find more than one constrained shortest metapath per a single-link chain. In our composite variable approach, we find k-constrained shortest metapaths (to create k binary variables) per each single-link segment of a multilink service chain. To find metapaths, any constrained shortest path algorithm can be used [68–70]. However, we build our metapath composite variable approach upon the path finder proposed in our prior work that is an order of magnitude faster than recent solutions [72].

Figure 19.13 System architecture of our Incident-Supporting Service Chain Orchestration prototype includes four main logical components: (1) control application is responsible for service chain composition in a centralized control plane and its maintenance in a distributed control plane; (2) simple coordination layer (SCL) and root controllers are responsible for guaranteeing consistency in the distributed control plane; (3) SDN is responsible for traffic steering in the data plane; and (4) hypervisor is responsible for virtual machines (VMs) provisioning.
To further benefit from constrained shortest metapaths and simplify the chain composition problem, we offload its constraints (either fully or partially) to either metalinks or the path finder. Specifically, geo-location and an arbitrary number of end-to-end network (e.g. latency) QoS constraints can be fully offloaded to metalinks and to the path finder, respectively. At the same time, capacity constraints of the SFC composition problem are global and can be only partially offloaded. Once k-constrained shortest paths have been found for each single-link service chain segment, we can solve the GAP problem [73] to assign each single-link chain segment to exactly one constrained shortest metapath and stitch these metapaths as described below. Aside from solving the NP-hard GAP problem directly, we can also solve the GAP using its polynomial Lagrangian relaxation by compromising both its optimality and feasibility guarantees [73]. Finally, found metapaths can be used subsequently to migrate failed SFC segments during their maintenance. The details of the metapath-based composite variable approach as well as the main MCCF problem integer programming formulation are omitted due to space constraints, and can be found in our detailed related work in [6].
19.4.2.4 Allowable Fitness Functions for Metapath-Based Variables
In general, fitness functions qualify for our metapath composite variable approach if they comprise either additive or multiplicative terms. The above requirement fits for most SFC objectives [59], and other objectives can also qualify if well-behaved (e.g. if their single-link chain fitness values can be minimized by a path finder).
19.4.2.5 Metapath Composite Variable Approach Results
We found that our approach achieves 99% optimality on average and takes seconds to compose SFCs for practically sized problems of US Tier−1 (300 nodes) and regional (600 nodes) infrastructure providers' topologies. For the same setup, we found that the master problem solution takes hours using a cloud server tailored for high-performance computing. As a result, our metapath approach can secure up to 2 times more SFCs in comparison to the state-of-the-art NFV/VNE approaches under challenging disaster incident conditions. Moreover, supported policies allow efficient trade-off between a SFC reliability and its composition optimality [6].
19.4.3 Metapath-Based SFC Orchestration Implementation
In this subsection, we describe the architecture of our incident-supporting metapath-based SFC orchestration implementation prototype shown in Figure 19.13. Our prototype architecture includes four main logical components: (1) a controller application, used to compose and maintain service chains; (2) our implementation of the Simple Coordination Layer (SCL), used to guarantee consistency of the distributed control plane and root controllers; (3) an SDN-based system with (4) a hypervisor to allocate mapped physical resources. The prototype source code for this incident-supporting metapath-based SFC orchestration implementation is publicly available under a GNU license at [74]. In the remainder of this section, we describe additional details for each of the four prototype components.
19.4.3.1 Control Applications
We have two main types of control applications that use our metapath-based composite variable approach. The first type is responsible for the resilient service-chain composition in the centralized control plane. The second type is responsible for maintenance of composed service chains. Note that we move the service-chain maintenance to the distributed control plane to avoid both a single point of failure as well as congestion in the centralized control plane.
19.4.3.2 SCL
To guarantee consistency in the distributed control plane and avoid various related violations (e.g. looping paths, SLO violations, etc.), one can use a SCL [75], or alternatively any other existing comparable consensus protocols. SCL includes three main components: SCL agent running on physical resources, SCL proxy controller running on controllers in the distributed control plane, and SCL policy coordinator running in the centralized control plane. The agent periodically exchanges messages with corresponding proxy controllers and triggers any changes in the physical resources. Proxy controllers send information to the service chain maintenance control application and periodically interact with other SCL proxy controllers. Finally, all policy changes (e.g. in control applications, in SCL, etc.) are committed via a two-phase commit [75] that is directed by the policy coordinator.
19.4.3.3 SDN and Hypervisor
The last two logical components of our prototype implementation are commonly used SDN and hypervisor systems being used in cloud-fog deployments. Guided by control applications, both SDN and hypervisor are responsible for traffic steering and virtual machines (VMs) provisioning in the data plane, respectively. In our prototype implementation, we use OpenFlow as our main SDN system [76] and Docker containers [77] as our hypervisor system to place services on the physical server.
19.5 Concluding Remarks
19.5.1 What Have We Learned?
In this chapter, we have learned how geospatial video analytics using fog/cloud resources can benefit from the FCC paradigm. We described how FCC advances current knowledge of the parameterization of application resource requirements in the form of small and large instance visual-data processing functions. The decoupling into small and large instance functions enables new optimizations of cloud/fog computation location selection utilizing network virtualization to connect the network edges (wired and wireless) in the fog with the core/public cloud platforms. To demonstrate the potential of FCC in cloud-fog infrastructures, we have considered three computer vision application case studies for disaster incident response and showed how these applications can be decoupled into a set of processing functions. We have also learnt how FCC is subject to challenges of: (1) “data collection” at the wireless edge within lost/austere infrastructure regions, and (2) the consequent “data processing” within geo-distributed fog/cloud platforms that satisfies geo/latency QoS constraints of a geospatial video analytics consumption with satisfactory user QoE.
To cope with challenges of data collection, we have seen how we can utilize geographic edge routing protocols and mobile ad hoc networks (MANETs). To provide sustainable high-speed data delivery to the edge cloud gateway, we have to overcome limitations of geographic routing approaches, such as the local minimum problem. We discussed one potential solution to this problem that considered an AI-AGRA that uses satellite imagery datasets corresponding to the disaster incident area(s). In this approach, we saw how recent deep-learning solutions can be used to augment geographic routing algorithms with the potential local minimum knowledge retrieved from satellite imagery.
To cope with challenges of data processing, we discussed how one can apply the microservices paradigm using natural decomposability of computer vision applications. Using microservices, we can utilize the NFV SFC mechanisms to satisfy geo/latency requirements of geospatial video analytics as well as overcome insufficient local processing capabilities within data collection regions. As the optimal SFC in a general case is basically the NP-hard MCCF problem, we presented a near-optimal and practical metapath composite variable approach. This approach achieves 99% optimality on average and allows us to significantly reduce combinatorial complexity of the master MCCF problem, i.e. it takes just a few seconds for SFC over US Tier-1 and regional infrastructure topologies, whereas the MCCF solution in the same case takes several hours to compute.
19.5.2 The Road Ahead and Open Problems
We conclude this chapter with a list of open challenges for adopting fog computing architectures in geospatial video analytics. Addressing these challenges is essential for a variety of computer vision applications, such as face recognition in crowds, object tracking in aerial wide-area motion imagery, reconnaissance, and video surveillance that are relevant for delivering disaster-incident situational awareness.
- Consideration of energy-awareness. To improve overall data collection performance from IoT devices at the wireless edge within lost infrastructure regions, edge routing protocols should not only account for a routing accuracy, but also take into account residual energy levels on routers/IoT devices [29], as well as optimize traffic based on user behavior (e.g. mobility pattern of first responders) to improve the overall edge network utilization as well as satisfy user QoE demands.
- Consideration of virtual topologies of functions. In some cases when handling diverse spatio-temporal data sets, computer vision applications may not be easily decomposable to a chain of functions; hence other (more complex) virtual topologies of functions should be addressed in potential cases where benefits of the proposed metapath composite variable approach may no longer hold.
- Consideration of processing states. When computer vision applications for video analytics are not stateless, e.g. tracking objects of interest may require maintenance of an object model, and state information needs to be preserved across functions. This in turn adds an additional layer of complexity that needs to be handled when considering how we can better handle noisy data for processing and compose chains of such functions.
- Consideration of hierarchical control architectures. To fully benefit from the FCC paradigm and deliver disaster-incident situational awareness, existing fog/cloud platforms may need to be extended with a support of hierarchical software-defined control planes to avoid single point of failure/congestion and enable efficient utilization of fog/cloud resources.
- Consideration of distributed intelligence for IoT. There will undoubtedly be impressive advances in wearables and other smart IoT devices (with higher data resolutions/sizes), 5G wireless networks, and flexible integration, as well as management of fog/cloud platforms occur; better modeling, suitable architectures, pertinent optimizations, and new machine-learning algorithms (particularly deep learning and/or reinforcement learning, real-time recommenders) for geospatial video analytics will need to be considered to adapt these advances for disaster incident–supporting computer vision applications.
Solving the above open issues in future explorations is significantly important to advance the knowledge to further the area of geospatial video analytics. Investigations to find solutions to these open issues can lead to a more helpful and accurate disaster-incident situational awareness that can foster effective and efficient disaster relief coordination to save lives.
References
- 1 Thoma, G., Antani, S., Gill, M. et al. (2012). People locator: a system for family reunification. IT Professional 14 (3): 13–21.
- 2 Pelapur, R., Candemir, S., Bunyak, F. et al. (2012). Persistent target tracking using likelihood fusion in wide-area and full motion video sequences. In: IEEE International Conference on Information Fusion, 2420, 2427.
- 3 Schurr, N., Marecki, J., Tambe, M. et al. (2005). The future of disaster response: humans working with multiagent teams using DEFACTO. In: AAAI Spring Symposium: AI Technologies for Homeland Security, 9–16.
- 4 Klontz, J.C. and Jain, A.K. (2013). A case study on unconstrained facial recognition using the Boston marathon bombings suspects, Michigan State University. Technical Report 119 (120): 1.
- 5 Gargees, R., Morago, B., Pelapur, R. et al. (2017). Incident-supporting visual cloud computing utilizing software-defined networking. IEEE Transactions on Circuits and Systems for Video Technology 27 (1): 182–197.
- 6 Chemodanov, D., Calyam, P., and Esposito, F. (2019). A near-optimal reliable composition approach for geo-distributed latency-sensitive service chains. In: IEEE International Conference on Computer Communications (INFOCOM).
- 7 Dinh, H.T., Lee, C., Niyato, D., and Wang, P. (2013). A survey of mobile cloud computing: architecture, applications, and approaches. Wireless Communications and Mobile Computing 13 (18): 1587–1611.
- 8 Fernando, N., Loke, S.W., and Rahayu, W. (2013). Mobile cloud computing: a survey. Future Generation Computer Systems 29 (1): 84–106.
- 9 Burchard, J., Chemodanov, D., Gillis, J., and Calyam, P. (2017). Wireless mesh networking protocol for sustained throughput in edge computing. In: IEEE International Conference on Computing, Networking and Communications (ICNC), 958–962. IEEE.
- 10 Cvetkovski, A. and Crovella, M. (2009). Hyperbolic embedding and routing for dynamic graphs. In: IEEE International Conference on Computer Communications (INFOCOM), 1647–1655.
- 11 Karp, B. and Kung, H.-T. (2000). GPSR: Greedy perimeter stateless routing for wireless networks. In: ACM International Conference on Mobile Computing and Networking, 243–254. ACM.
- 12 Kranakis, E., Singh, H., and Urrutia, J. (1999). Compass routing on geometric networks. In: IEEE Conference on Computational Geometry.
- 13 Sukhov, A.M. and Chemodanov, D.Y. (2013). The neighborhoods method and routing in sensor networks. In: IEEE Conference on Wireless Sensor (ICWISE), 7–12. IEEE.
- 14 AWS lambda. https://aws.amazon.com/lambda. Accessed February 2018.
- 15 Google Cloud Functions. https://cloud.google.com/functions. Accessed February 2018.
- 16 Microsoft azure functions. https://azure.microsoft.com/en-us/services/functions. Accessed February 2018.
- 17 IBM OpenWhisk. https://www.ibm.com/cloud/functions. Accessed February 2018.
- 18 Potharaju, R. and Jain, N. (2013). Demystifying the dark side of the middle: a field study of middlebox failures in datacenters. In: Proceedings of Internet Measurement Conference, 9–22. ACM.
- 19 Eriksson, B., Durairajan, R., and Barford, P. (2013). Riskroute: a framework for mitigating network outage threats. In: ACM Conference on Emerging Networking Experiments and Technologies, 405–416.
- 20 Fei, X., Liu, F., Xu, H., and Jin, H. (2018). Adaptive VNF scaling and flow routing with proactive demand prediction. In: IEEE International Conference on Computer Communications (INFOCOM), 486–494.
- 21 Tomassilli, A., Giroire, F., Huin, N., and Prennes, S. (2018). Provably efficient algorithms for placement of SFCs with ordering constraints. In: IEEE International Conference on Computer Communications (INFOCOM).
- 22 Cohen, R., Lewin-Eytan, L., Naor, J.S., and Raz, D. (2015). Near optimal placement of virtual network functions. In: IEEE International Conference on Computer Communications (INFOCOM), 1346–1354.
- 23 Sang, Y., Bo, J., Gupta, G.R. et al. (2017). Provably efficient algorithms for joint placement and allocation of virtual network functions. In: IEEE International Conference on Computer Communications (INFOCOM), 1–9.
- 24 Jain, S., Kumar, A., Mandal, S. et al. (2013). B4: experience with a globally-deployed software defined WAN. ACM SIGCOMM Computer Communication Review 43: 3–14.
- 25 Feng, H., Llorca, J., Tulino, A.M. et al. (2017). Approximation algorithms for the NFV service distribution problem. In: IEEE International Conference on Computer Communications (INFOCOM), 1–9.
- 26 Gillis, J., Calyam, P., Bartels, A. et al. (2015). Panacea's glass: mobile cloud framework for communication in mass casualty disaster triage. In: IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (MobileCloud), 128–134. IEEE.
- 27 Morago, B., Bui, G., and Duan, Y. (2014). Integrating LiDAR range scans and photographs with temporal changes. In: IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 732–737.
- 28 Chemodanov, D., Esposito, F., Sukhov, A. et al. (2019). Agra: AI-augmented geographic routing approach for IoT-based incident-supporting applications. Future Generation Computer Systems 92: 1051–1065.
- 29 Trinh, H., Chemodanov, D., Yao, S. et al. (2017). Energy-aware mobile edge computing for low-latency visual data processing. In: IEEE International Conference on Future Internet of Things and Cloud (FiCloud).
- 30 Chung, S., Christoudias, C.M., Darrell, T. et al. (2012). A novel image-based tool to reunite children with their families after disasters. Academic Emergency Medicine 19 (11): 1227–1234.
- 31 King, D.E. (2009). Dlib-ml: a machine learning toolkit. Journal of Machine Learning Research 10: 1755–1758.
- 32 Parkhi, O.M., Vedaldi, A., Zisserman, A. et al. (2015). Deep face recognition. In: British Machine Vision Conference, vol. 1, 6.
- 33 Kwan, M.-P. and Ransberger, D. (2010). LiDAR assisted emergency response: detection of transport network obstructions caused by major disasters. Computers, Environment and Urban Systems 34 (3): 179–188.
- 34 Hartley, R. and Zisserman, A. (2010). Multiple View Geometry. Cambridge University Press.
- 35 Stauffer, C. and Stauffer, E.G. (1999). Adaptive background mixture models for real-time tracking. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 246–253.
- 36 Palaniappan, K., Rao, R., and Seetharaman, G. (2011). Wide-area persistent airborne video: architecture and challenges. In: Distributed Video Sensor Networks, 349–371.
- 37 Hafiane, A., Seetharaman, G., Palaniappan, K., and Zavidovique, B. (2008). Rotationally invariant hashing of median patterns for texture classification. In: Lecture Notes in Computer Science (LNCS), 619–629.
- 38 Aliakbarpour, H., Palaniappan, K., and Seetharaman, G. (2015). Robust camera pose refinement and rapid SfM for multiview aerial imagery without RANSAC. In: IEEE Geoscience and Remote Sensing Letters (GRSL), 2203–2207.
- 39 Hafiane, A., Palaniappan, K., and Seetharaman, G. (2008). UAV-video registration using block-based features. In: IEEE International Symposium on Geoscience and Remote Sensing (IGARSS), 1104–1107.
- 40 Palaniappan, K., Bunyak, F., Kumar, P. et al. (2010). Efficient feature extraction and likelihood fusion for vehicle tracking in low frame rate airborne video. In: IEEE Conference on Information Fusion (FUSION), 1–8.
- 41 Akhtar, F., Rehmani, M.H., and Reisslein, M. (2016). White space: definitional perspectives and their role in exploiting spectrum opportunities. Telecommunications Policy 40 (4): 319–331.
- 42 Król, M., Schiller, E., Rousseau, F., and Duda, A. (2016). Weave: efficient geographical routing in large-scale networks. In: EWSN, 89–100.
- 43 Lam, S.S. and Qian, C. (2013). Geographic routing in d-dimensional spaces with guaranteed delivery and low stretch. IEEE/ACM Transactions on Networking (TON) 21 (2): 663–677.
- 44 Leong, B., Liskov, B., and Morris, R. (2006). Geographic routing without planarization. In: NSDI, vol. 6, 25.
- 45 Umer, T., Amjad, M., Afzal, M.K., and Aslam, M. (2016). Hybrid rapid response routing approach for delay-sensitive data in hospital body area sensor network. In: ACM International Conference on Computing Communication and Networking Technologies.
- 46 Esposito, F. (2017). Catena: a distributed architecture for robust service function chain instantiation with guarantees. In: IEEE Conference of Network Softwarization, 1–9.
- 47 Kleinberg, R. (2007). Geographic routing using hyperbolic space. In: IEEE International Conference on Computer Communications (INFOCOM), 1902–1909.
- 48 Sahhaf, S., Tavernier, W., Colle, D. et al. (2015). Experimental validation of resilient tree-based greedy geometric routing. Computer Networks 82: 156–171.
- 49 Bose, P., Morin, P., Stojmenović, I., and Urrutia, J. (2001). Routing with guaranteed delivery in ad hoc wireless networks. Wireless Networks 7 (6): 609–616.
- 50 Kim, Y.-J., Govindan, R., Karp, B., and Shenker, S. (2005). Geographic routing made practical. In: Proceedings of the 2nd Conference on Symposium on Networked Systems Design & Implementation, vol. 2, 217–230. USENIX Association.
- 51 Zhou, J., Chen, Y., Leong, B., and Sundaramoorthy, P.S. (2010). Practical 3-D geographic routing for wireless sensor networks. In: ACM Conference on Embedded Networked Sensor Systems, 337–350.
- 52 National Oceanic and Atmospheric Organization. https://geodesy.noaa.gov/stormarchive/storms/joplin/index.html. Accessed March 2018.
- 53 Redmon, J., Divvala, S., Girshick, R., and Farhadi, A. (2016). You only look once: unified, real-time object detection. In: IEEE Conference on Computer Vision and Pattern Recognition, 779–788.
- 54 Gidaris, S. and Komodakis, N. (2015). Object detection via a multi-region and semantic segmentation-aware CNN model. In: IEEE International Conference on Computer Vision, 1134–1142.
- 55 Blaschke, T. (2010). Object based image analysis for remote sensing. ISPRS Journal of Photogrammetry and Remote Sensing 65 (1): 2–16.
- 56 Weston, J., Ratle, F., Mobahi, H., and Collobert, R. (2012). Deep learning via semi-supervised embedding. In: Neural Networks: Tricks of the Trade, 639–655. Springer.
- 57 Bonomi, F., Milito, R., Zhu, J., and Addepalli, S. (2012). Fog computing and its role in the internet of things. In: ACM Workshop on Mobile Cloud Computing, 13–16.
- 58 Gil Herrera, J. and Botero, J.F. (2016). Resource allocation in NFV: a comprehensive survey. IEEE Transactions on Network and Service Management 13 (3): 518–532.
- 59 Bhamare, D., Jain, R., Samaka, M., and Erbad, A. (2016). A survey on service function chaining. Journal of Network and Computer Applications 75: 138–155.
- 60 Guo, L., Pang, J., and Walid, A. (2018). Joint placement and routing of network function chains in data centers. In: IEEE International Conference on Computer Communications (INFOCOM), 612–620.
- 61 Yu, R., Xue, G., and Zhang, X. (2018). Application provisioning in fog computing-enabled Internet-of-Things: a network perspective. In: IEEE International Conference on Computer Communications (INFOCOM), 783–791.
- 62 Chowdhury, M., Rahman, M.R., and Boutaba, R. (2012). Vineyard: virtual network embedding algorithms with coordinated node and link mapping. IEEE/ACM Transactions on Networking 20 (1): 206–219.
- 63 Fei, X., Liu, F., Hong, X., and Jin, H. (2017). Towards load-balanced VNF assignment in geo-distributed NFV infrastructure. IEEE International Symposium on Quality of Service (IWQoS): 1–10.
- 64 Cziva, R., Anagnostopoulos, C., and Pezaros, D.P. (2018). Dynamic, latency-optimal VNF placement at the network edge. In: IEEE International Conference on Computer Communications (INFOCOM), 693–701.
- 65 Spinnewyn, B., Mennes, R., Botero, J.F., and Latré, S. (2017). Resilient application placement for geo-distributed cloud networks. Journal of Network and Computer Applications 85: 14–31.
- 66 Barnhart, C., Farahat, A., and Lohatepanont, M. (2009). Airline fleet assignment with enhanced revenue modeling. Operations Research 57 (1): 231–244.
- 67 Ahuja, R.K., Magnanti, T.L., and Orlin, J.B. (2014). Network Flows. Elsevier.
- 68 Lozano, L. and Medaglia, A.L. (2013). On an exact method for the constrained shortest path problem. Computers & Operations Research 40 (1): 378–384.
- 69 Chen, X., Cai, H., and Wolf, T. (2015). Multi-criteria routing in networks with path choices. In: IEEE International Conference on Network Protocols, 334–344.
- 70 Van Mieghem, P. and Kuipers, F.A. (2004). Concepts of exact QoS routing algorithms. IEEE/ACM Transactions on Networking 12 (5): 851–864.
- 71 Mijumbi, R., Serrat, J., Gorricho, J.-L., and Boutaba, R. (2015). A path generation approach to embedding of virtual networks. IEEE Transactions on Network and Service Management 12 (3): 334–348.
- 72 Chemodanov, D., Esposito, F., Calyam, P., and Sukhov, A. (2018). A constrained shortest path scheme for virtual network service management. IEEE Transactions on Network and Service Management 16 (1): 127–142.
- 73 Fisher, M.L. (1981). The lagrangian relaxation method for solving integer programming problems. Management Science 27 (1): 1–18.
- 74 Metapath-based service chain orchestration repository. https://goo.gl/TMKZxj. Accessed February 2018.
- 75 Panda, A., Zheng, W., Hu, X. et al. (2017). SCL: simplifying distributed SDN control planes. In: NSDI, 329–345.
- 76 McKeown, N., Anderson, T., Balakrishnan, H. et al. (2008). Openflow: enabling innovation in campus networks. ACM SIGCOMM Computer Communication Review 38 (2): 69–74.
- 77 Docker containers. https://www.docker.com. Accessed February 2018.