
Chapter 6. Metapatterns
This chapter is different from the others in that it doesn’t contain patterns for solving a particular problem, but patterns that deal with patterns. The term metapatterns is directly translated to “patterns about patterns.” The first method that will be discussed is job chaining, which is piecing together several patterns to solve complex, multistage problems. The second method is job merging, which is an optimization for performing several analytics in the same MapReduce job, effectively killing multiple birds with one stone.
Job Chaining
Job chaining is extremely important to understand and have an operational plan for in your environment. Many people find that they can’t solve a problem with a single MapReduce job. Some jobs in a chain will run in parallel, some will have their output fed into other jobs, and so on. Once you start to understand how to start solving problems as a series of MapReduce jobs, you’ll be able to tackle a whole new class of challenges.
Job chaining is one of the more complicated processes to handle because it’s not a feature out of the box in most MapReduce frameworks. Systems like Hadoop are designed for handling one MapReduce job very well, but handling a multistage job takes a lot of manual coding. There are operational considerations for handling failures in the stages of the job and cleaning up intermediate output. In this section, a few different approaches to job chaining will be discussed. Some will seem more appealing than others for your particular environment, as each has its own pros and cons.
A couple of frameworks and tools have emerged to fill this niche. If you do a lot of job flows and your chaining is pretty complex, you should consider using one of these. The approaches described in this section are more lightweight and need to be implemented on a job-by-job basis. Oozie, an open source Apache project, has functionality for building workflows and coordinating job running. Building job chains is only one of the many features that are useful for operationally running Hadoop MapReduce.
One particular common pitfall is to use MapReduce for something that is small enough that distributing the job is not necessary. If you think chaining two jobs together is the right choice, think about how much output there is from the first. If there are tons of output data, then by all means use a second MapReduce job. Many times, however, the output of the job is small and can be processed quite effectively on a single node. The two ways of doing this is to either load the data through the file system API in the driver after the job has completed, or incorporate it in some sort of bash script wrapper.
Caution
A major problem with MapReduce chains is the size of the temporary files. In some cases, they may be tiny, which will cause a significant amount of overhead in firing up way too many map tasks to load them.
In a nonchained job, the number of reducers typically depends more on the amount of data they are receiving than the amount of data you’d like to output. When chaining, the size of the output files is likely more important, even if the reducers will take a bit longer. Try to shoot for output files about the size of one block on the distributed filesystem. Just play around with the number of reducers and see what the impact is on performance (which is good advice in general).
The other option is to consistently use CombineFileInputFormat for jobs that load
intermittent output. CombineFileInputFormat takes smaller blocks
and lumps them together to make a larger input split before being
processed by the mapper.
With the Driver
Probably the simplest method for performing job chaining is to have a master driver that simply fires off multiple job-specific drivers. There’s nothing special about a MapReduce driver in Hadoop; it’s pretty generic Java. It doesn’t derive from some sort of special class or anything.
Take the driver for each MapReduce job and call them in the sequence they should run. You’ll have to specifically be sure that the output path of the first job is the input path of the second. You can be sure of this by storing the temporary path string as a variable and sharing it.
In a production scenario, the temporary directories should be cleaned up so they don’t linger past the completion of the job. Lack of discipline here can surprisingly fill up your cluster rather quickly. Also, be careful of how much temporary data you are actually creating because you’ll need storage in your file system to store that data.
You can pretty easily extrapolate this approach to create chains that are much longer than just two jobs. Just be sure to keep track of all of the temporary paths and optionally clean up the data not being used anymore as the job runs.
You can also fire off multiple jobs in parallel by using Job.submit()
instead of Job.waitForCompletion(). The submit method
returns immediately to the current thread and runs the job in the
background. This allows you to run several jobs at once. Use Job.isComplete(), a
nonblocking job completion check, to constantly poll to see whether all
of the jobs are complete.
The other thing to pay attention to is job success. It’s not good enough to just know that the job completed. You also need to check whether it succeeded or not. If a dependency job failed, you should break out of the entire chain instead of trying to let it continue.
It’s pretty obvious that this process is going to be rather
difficult to manage and maintain from a software engineering prospective
as the job chains get more complicated. This is where something
like JobControl or
Oozie comes in.
Job Chaining Examples
Basic job chaining
The goal of this example is to output a list of users along with a couple pieces of information: their reputations and how many posts each has issued. This could be done in a single MapReduce job, but we also want to separate users into those with an above-average number of posts and those with a below-average number. We need one job to perform the counts and another to separate the users into two bins based on the number of posts. Four different patterns are used in this example: numerical summarization, counting, binning, and a replicated join. The final output consists of a user ID, the number of times they posted, and their reputation.
The average number of posts per user is calculated between the
two jobs using the framework’s counters. The users data set is put in
the DistributedCache in the
second job to enrich the output data with the users’
reputations. This enrichment occurs in order to feed in to the next
example in this section, which calculates the average reputation of
the users in the two bins.
The following descriptions of each code section explain the solution to the problem.
Problem: Given a data set of StackOverflow posts, bin users based on if they are below or above the number of average posts per user. Also to enrich each user with his or her reputation from a separate data set when generating the output.
Job one mapper
Before we look at the driver, let’s get an understanding of
the mapper and reducer for both jobs. The mapper records the user ID
from each record by assigning the value of the OwnerUserId attribute as the output key
for the job, with a count of one as the value. It also increments a
record counter by one. This value is later used in the driver to
calculate the average number of posts per user. The AVERAGE_CALC_GROUP is a public static string at the driver
level.
publicstaticclassUserIdCountMapperextendsMapper<Object,Text,Text,LongWritable>{publicstaticfinalStringRECORDS_COUNTER_NAME="Records";privatestaticfinalLongWritableONE=newLongWritable(1);privateTextoutkey=newText();publicvoidmap(Objectkey,Textvalue,Contextcontext)throwsIOException,InterruptedException{Map<String,String>parsed=MRDPUtils.transformXmlToMap(value.toString());StringuserId=parsed.get("OwnerUserId");if(userId!=null){outkey.set(userId);context.write(outkey,ONE);context.getCounter(AVERAGE_CALC_GROUP,RECORDS_COUNTER_NAME).increment(1);}}}
Job one reducer
The reducer is also fairly trivial. It simply iterates through the input values (all of which we set to 1) and keeps a running sum, which is output along with the input key. A different counter is also incremented by one for each reduce group, in order to calculate the average.
publicstaticclassUserIdSumReducerextendsReducer<Text,LongWritable,Text,LongWritable>{publicstaticfinalStringUSERS_COUNTER_NAME="Users";privateLongWritableoutvalue=newLongWritable();publicvoidreduce(Textkey,Iterable<LongWritable>values,Contextcontext)throwsIOException,InterruptedException{// Increment user counter, as each reduce group represents one usercontext.getCounter(AVERAGE_CALC_GROUP,USERS_COUNTER_NAME).increment(1);intsum=0;for(LongWritablevalue:values){sum+=value.get();}outvalue.set(sum);context.write(key,outvalue);}}
Job two mapper
This mapper is more complicated than the previous jobs. It is
doing a few different things to get the desired output. The setup
phase accomplishes three different things. The average number of
posts per user is pulled from the Context object that was set during job
configuration. The MultipleOutputs
utility is initialized as well. This is used to write the output to
different bins. Finally, the user data set is parsed from the
DistributedCache to build a map
of user ID to reputation. This map is used for the desired data
enrichment during output.
Compared to the setup, the map method is much easier. The input value is parsed to get the user ID and number of times posted. This is done by simply splitting on tabs and getting the first two fields of data. Then the mapper sets the output key to the user ID and the output value to the number of posts along with the user’s reputation, delimited by a tab. The user’s number of posts is then compared to the average, and the user is binned appropriately.
An optional fourth parameter of MultipleOutputs.write is used in this
example to name each part file. A constant is used to specify the
directory for users based on whether they are below or above average
in their number of posts. The filename in the folder is named
through an extra /part string.
This becomes the beginning of the filename, to which the framework
will append -m-nnnnn, where
nnnnn is the task ID number. With this
name, a folder will be created for both bins and the folders will
contain a number of part files.
This is done for easier input/output management for the next example
on parallel jobs.
Finally, MultipleOutputs is
closed in the cleanup stage.
publicstaticclassUserIdBinningMapperextendsMapper<Object,Text,Text,Text>{publicstaticfinalStringAVERAGE_POSTS_PER_USER="avg.posts.per.user";publicstaticvoidsetAveragePostsPerUser(Jobjob,doubleavg){job.getConfiguration().set(AVERAGE_POSTS_PER_USER,Double.toString(avg));}publicstaticdoublegetAveragePostsPerUser(Configurationconf){returnDouble.parseDouble(conf.get(AVERAGE_POSTS_PER_USER));}privatedoubleaverage=0.0;privateMultipleOutputs<Text,Text>mos=null;privateTextoutkey=newText(),outvalue=newText();privateHashMap<String,String>userIdToReputation=newHashMap<String,String>();protectedvoidsetup(Contextcontext)throwsIOException,InterruptedException{average=getAveragePostsPerUser(context.getConfiguration());mos=newMultipleOutputs<Text,Text>(context);Path[]files=DistributedCache.getLocalCacheFiles(context.getConfiguration());// Read all files in the DistributedCachefor(Pathp:files){BufferedReaderrdr=newBufferedReader(newInputStreamReader(newGZIPInputStream(newFileInputStream(newFile(p.toString())))));Stringline;// For each record in the user filewhile((line=rdr.readLine())!=null){// Get the user ID and reputationMap<String,String>parsed=MRDPUtils.transformXmlToMap(line);// Map the user ID to the reputationuserIdToReputation.put(parsed.get("Id"),parsed.get("Reputation"));}}}publicvoidmap(Objectkey,Textvalue,Contextcontext)throwsIOException,InterruptedException{String[]tokens=value.toString().split(" ");StringuserId=tokens[0];intposts=Integer.parseInt(tokens[1]);outkey.set(userId);outvalue.set((long)posts+" "+userIdToReputation.get(userId));if((double)posts<average){mos.write(MULTIPLE_OUTPUTS_BELOW_NAME,outkey,outvalue,MULTIPLE_OUTPUTS_BELOW_NAME+"/part");}else{mos.write(MULTIPLE_OUTPUTS_ABOVE_NAME,outkey,outvalue,MULTIPLE_OUTPUTS_ABOVE_NAME+"/part");}}protectedvoidcleanup(Contextcontext)throwsIOException,InterruptedException{mos.close();}}
Driver code
Now let’s take a look at this more complicated driver. It is broken down into two sections for discussion: the first job and the second job. The first job starts by parsing command-line arguments to create proper input and output directories. It creates an intermediate directory that will be deleted by the driver at the end of the job chain.
Caution
A string is tacked on to the name of the output directory here to make our intermediate output directory. This is fine for the most part, but it may be a good idea to come up with a naming convention for any intermediate directories to avoid conflicts. If an output directory already exists during job submission, the job will never start.
publicstaticvoidmain(String[]args)throwsException{Configurationconf=newConfiguration();PathpostInput=newPath(args[0]);PathuserInput=newPath(args[1]);PathoutputDirIntermediate=newPath(args[2]+"_int");PathoutputDir=newPath(args[2]);// Setup first job to counter user postsJobcountingJob=newJob(,"JobChaining-Counting");countingJob.setJarByClass(JobChainingDriver.class);// Set our mapper and reducer, we can use the API's long sum reducer for// a combiner!countingJob.setMapperClass(UserIdCountMapper.class);countingJob.setCombinerClass(LongSumReducer.class);countingJob.setReducerClass(UserIdSumReducer.class);countingJob.setOutputKeyClass(Text.class);countingJob.setOutputValueClass(LongWritable.class);countingJob.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(countingJob,postInput);countingJob.setOutputFormatClass(TextOutputFormat.class);TextOutputFormat.setOutputPath(countingJob,outputDirIntermediate);// Execute job and grab exit codeintcode=countingJob.waitForCompletion(true)?0:1;...
The first job is checked for success before executing the
second job. This seems simple enough, but with more complex job
chains it can get a little annoying. Before the second job is
configured, we grab the counter values from the first job to get the
average posts per user. This value is then added to the job
configuration. We set our mapper code and disable the reduce phase,
as this is a map-only job. The other key parts to pay attention to
are the configuration of MultipleOutputs
and the DistributedCache.
The job is then executed and the framework takes over
from there.
Lastly and most importantly, success or failure, the intermediate output directory is cleaned up. This is an important and often overlooked step. Leaving any intermediate output will fill up a cluster quickly and require you to delete the output by hand. If you won’t be needing the intermediate output for any other analytics, by all means delete it in the code.
if(code==0){// Calculate the average posts per user by getting counter valuesdoublenumRecords=(double)countingJob.getCounters().findCounter(AVERAGE_CALC_GROUP,UserIdCountMapper.RECORDS_COUNTER_NAME).getValue();doublenumUsers=(double)countingJob.getCounters().findCounter(AVERAGE_CALC_GROUP,UserIdSumReducer.USERS_COUNTER_NAME).getValue();doubleaveragePostsPerUser=numRecords/numUsers;// Setup binning jobJobbinningJob=newJob(newConfiguration(),"JobChaining-Binning");binningJob.setJarByClass(JobChainingDriver.class);// Set mapper and the average posts per userbinningJob.setMapperClass(UserIdBinningMapper.class);UserIdBinningMapper.setAveragePostsPerUser(binningJob,averagePostsPerUser);binningJob.setNumReduceTasks(0);binningJob.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(binningJob,outputDirIntermediate);// Add two named outputs for below/above averageMultipleOutputs.addNamedOutput(binningJob,MULTIPLE_OUTPUTS_BELOW_NAME,TextOutputFormat.class,Text.class,Text.class);MultipleOutputs.addNamedOutput(binningJob,MULTIPLE_OUTPUTS_ABOVE_NAME,TextOutputFormat.class,Text.class,Text.class);MultipleOutputs.setCountersEnabled(binningJob,true);TextOutputFormat.setOutputPath(binningJob,outputDir);// Add the user files to the DistributedCacheFileStatus[]userFiles=FileSystem.get(conf).listStatus(userInput);for(FileStatusstatus:userFiles){DistributedCache.addCacheFile(status.getPath().toUri(),binningJob.getConfiguration());}// Execute job and grab exit codecode=binningJob.waitForCompletion(true)?0:1;}// Clean up the intermediate outputFileSystem.get(conf).delete(outputDirIntermediate,true);System.exit(code);}
Parallel job chaining
The driver in parallel job chaining is similar to the previous example. The only big enhancement is that jobs are submitted in parallel and then monitored until completion. The two jobs run in this example are independent. (However, they require the previous example to have completed successfully.) This has the added benefit of utilizing cluster resources better to have them execute simultaneously.
The following descriptions of each code section explain the solution to the problem.
Problem: Given the previous example’s output of binned users, run parallel jobs over both bins to calculate the average reputation of each user.
Mapper code
The mapper splits the input value into a string array. The
third column of this index is the reputation of the particular user.
This reputation is output with a unique key. This key is shared
across all map tasks in order to group all the reputations together
for the average calculation. NullWritable can be used to group all the records together, but we want
the key to have a meaningful value.
Caution
This can be expensive for very large data sets, as one reducer is responsible for streaming all the intermediate key/value pairs over the network. The added benefit here over serially reading the data set on one node is that the input splits are read in parallel and the reducers use a configurable number of threads to read each mapper’s output.
publicstaticclassAverageReputationMapperextendsMapper<LongWritable,Text,Text,DoubleWritable>{privatestaticfinalTextGROUP_ALL_KEY=newText("Average Reputation:");privateDoubleWritableoutvalue=newDoubleWritable();protectedvoidmap(LongWritablekey,Textvalue,Contextcontext)throwsIOException,InterruptedException{// Split the line into tokensString[]tokens=value.toString().split(" ");// Get the reputation from the third columndoublereputation=Double.parseDouble(tokens[2]);// Set the output value and write to contextoutvalue.set(reputation);context.write(GROUP_ALL_KEY,outvalue);}}
Reducer code
The reducer simply iterates through the reputation values, summing the numbers and keeping a count. The average is then calculated and output with the input key.
publicstaticclassAverageReputationReducerextendsReducer<Text,DoubleWritable,Text,DoubleWritable>{privateDoubleWritableoutvalue=newDoubleWritable();protectedvoidreduce(Textkey,Iterable<DoubleWritable>values,Contextcontext)throwsIOException,InterruptedException{doublesum=0.0;doublecount=0;for(DoubleWritabledw:values){sum+=dw.get();++count;}outvalue.set(sum/count);context.write(key,outvalue);}}
Driver code
The driver code parses command-line arguments to get the input
and output directories for both jobs. A helper function is then
called to submit the job configuration, which we will look at next.
The Job objects for both are then
returned and monitored for job completion. So long as either job is
still running, the driver goes back to sleep for five seconds. Once
both jobs are complete, they are checked for success or failure and
an appropriate log message is printed. An exit code is then returned
based on job success.
publicstaticvoidmain(String[]args)throwsException{Configurationconf=newConfiguration();PathbelowAvgInputDir=newPath(args[0]);PathaboveAvgInputDir=newPath(args[1]);PathbelowAvgOutputDir=newPath(args[2]);PathaboveAvgOutputDir=newPath(args[3]);JobbelowAvgJob=submitJob(conf,belowAvgInputDir,belowAvgOutputDir);JobaboveAvgJob=submitJob(conf,aboveAvgInputDir,aboveAvgOutputDir);// While both jobs are not finished, sleepwhile(!belowAvgJob.isComplete()||!aboveAvgJob.isComplete()){Thread.sleep(5000);}if(belowAvgJob.isSuccessful()){System.out.println("Below average job completed successfully!");}else{System.out.println("Below average job failed!");}if(aboveAvgJob.isSuccessful()){System.out.println("Above average job completed successfully!");}else{System.out.println("Above average job failed!");}System.exit(belowAvgJob.isSuccessful()&&aboveAvgJob.isSuccessful()?0:1);}
This helper function is configured for each job. It looks very
standard to any other configuration, except Job.submit
is used rather than Job.waitForCompletion. This will submit
the job and then immediately return, allowing the application to
continue. As we saw, the returned Job is monitored in the main method until completion.
privatestaticJobsubmitJob(Configurationconf,PathinputDir,PathoutputDir)throwsException{Jobjob=newJob(conf,"ParallelJobs");job.setJarByClass(ParallelJobs.class);job.setMapperClass(AverageReputationMapper.class);job.setReducerClass(AverageReputationReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(DoubleWritable.class);job.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(job,inputDir);job.setOutputFormatClass(TextOutputFormat.class);TextOutputFormat.setOutputPath(job,outputDir);// Submit job and immediately return, rather than waiting for completionjob.submit();returnjob;}
With Shell Scripting
This method of job chaining is very similar to the previous approach of implementing a complex job flow in a master driver that fires off individual job drivers, except that we do it in a shell script. Each job in the chain is fired off separately in the way you would run it from the command line from inside of a shell script.
This has a few major benefits and a couple minor downsides. One
benefit is that changes to the job flow can be made without having to
recompile the code because the master driver is a scripting language
instead of Java. This is important if the job is prone to failure and
you need to easily be able to manually rerun or repair failed jobs.
Also, you’ll be able to use jobs that have already been productionalized
to work through a command-line interface, but not a script. Yet another
benefit is that the shell script can interact with services, systems,
and tools that are not Java centric. For example, later in this chapter
we’ll discuss post-processing of output, which may be very natural to do
with sed or awk, but less natural to do in Java.
One of the downsides of this approach is it may be harder to implement more complicated job flows in which jobs are running in parallel. You can run jobs in the background and then test for success, but it may not be as clean as in Java.
Tip
Wrapping any Hadoop MapReduce job in a script, whether it be a single Java MapReduce job, a Pig job, or whatever, has a number of benefits. This includes post-processing, data flows, data preparation, additional logging, and more.
In general, using shell scripting is useful to chain new jobs with existing jobs quickly. For more robust applications, it may make more sense to build a driver-based chaining mechanism that can better interface with Hadoop.
Bash example
In this example, we use the Bash shell to tie together the basic job chaining and parallel jobs examples. The script is broken into two pieces: setting variables to actually execute the jobs, and then executing them.
Bash script
Input and outputs are stored in variables to create the a
number of executable commands. There are two commands to run both
jobs, cat the output to the
screen, and cleanup all the analytic output.
#!/bin/bashJAR_FILE="mrdp.jar"JOB_CHAIN_CLASS="mrdp.ch6.JobChainingDriver"PARALLEL_JOB_CLASS="mrdp.ch6.ParallelJobs"HADOOP="$(which hadoop)"POST_INPUT="posts"USER_INPUT="users"JOBCHAIN_OUTDIR="jobchainout"BELOW_AVG_INPUT="${JOBCHAIN_OUTDIR}/belowavg"ABOVE_AVG_INPUT="${JOBCHAIN_OUTDIR}/aboveavg"BELOW_AVG_REP_OUTPUT="belowavgrep"ABOVE_AVG_REP_OUTPUT="aboveavgrep"JOB_1_CMD="${HADOOP}jar${JAR_FILE}${JOB_CHAIN_CLASS}${POST_INPUT}${USER_INPUT}${JOBCHAIN_OUTDIR}"JOB_2_CMD="${HADOOP}jar${JAR_FILE}${PARALLEL_JOB_CLASS}${BELOW_AVG_INPUT}${ABOVE_AVG_INPUT}${BELOW_AVG_REP_OUTPUT}${ABOVE_AVG_REP_OUTPUT}"CAT_BELOW_OUTPUT_CMD="${HADOOP}fs -cat${BELOW_AVG_REP_OUTPUT}/part-*"CAT_ABOVE_OUTPUT_CMD="${HADOOP}fs -cat${ABOVE_AVG_REP_OUTPUT}/part-*"RMR_CMD="${HADOOP}fs -rmr${JOBCHAIN_OUTDIR}${BELOW_AVG_REP_OUTPUT}${ABOVE_AVG_REP_OUTPUT}"LOG_FILE="avgrep_`date +%s`.txt"
The next part of the script echos each command prior to running it. It
executes the first job, and then checks the return code to see
whether it failed. If it did, output is deleted and the script
exits. Upon success, the second job is executed and the same error
condition is checked. If the
second job completes successfully, the output of each job is written
to the log file and all the output is deleted. All the extra output
is not required, and since the final output of each file consists
only one line, storing it in the log file is worthwhile, instead of
keeping it in HDFS.
{echo${JOB_1_CMD}${JOB_1_CMD}if[$?-ne0]thenecho"First job failed!"echo${RMR_CMD}${RMR_CMD}exit$?fiecho${JOB_2_CMD}${JOB_2_CMD}if[$?-ne0]thenecho"Second job failed!"echo${RMR_CMD}${RMR_CMD}exit$?fiecho${CAT_BELOW_OUTPUT_CMD}${CAT_BELOW_OUTPUT_CMD}echo${CAT_ABOVE_OUTPUT_CMD}${CAT_ABOVE_OUTPUT_CMD}echo${RMR_CMD}${RMR_CMD}exit0}&>${LOG_FILE}
Sample run
A sample run of the script follows. The MapReduce analytic output is omitted for brevity.
/home/mrdp/hadoop/bin/hadoop jar mrdp.jar mrdp.ch6.JobChainingDriver posts
users jobchainout
12/06/10 15:57:43 INFO input.FileInputFormat: Total input paths to process : 5
12/06/10 15:57:43 INFO util.NativeCodeLoader: Loaded the native-hadoop library
12/06/10 15:57:43 WARN snappy.LoadSnappy: Snappy native library not loaded
12/06/10 15:57:44 INFO mapred.JobClient: Running job: job_201206031928_0065
...
12/06/10 15:59:14 INFO mapred.JobClient: Job complete: job_201206031928_0065
...
12/06/10 15:59:15 INFO mapred.JobClient: Running job: job_201206031928_0066
...
12/06/10 16:02:02 INFO mapred.JobClient: Job complete: job_201206031928_0066
/home/mrdp/hadoop/bin/hadoop jar mrdp.jar mrdp.ch6.ParallelJobs
jobchainout/belowavg jobchainout/aboveavg belowavgrep aboveavgrep
12/06/10 16:02:08 INFO input.FileInputFormat: Total input paths to process : 1
12/06/10 16:02:08 INFO util.NativeCodeLoader: Loaded the native-hadoop library
12/06/10 16:02:08 WARN snappy.LoadSnappy: Snappy native library not loaded
12/06/10 16:02:12 INFO input.FileInputFormat: Total input paths to process : 1
Below average job completed successfully!
Above average job completed successfully!
/home/mrdp/hadoop/bin/hadoop fs -cat belowavgrep/part-*
Average Reputation: 275.36385831014724
/home/mrdp/hadoop/bin/hadoop fs -cat aboveavgrep/part-*
Average Reputation: 2375.301960784314
/home/mrdp/hadoop/bin/hadoop fs -rmr jobchainout belowavgrep aboveavgrep
Deleted hdfs://localhost:9000/user/mrdp/jobchainout
Deleted hdfs://localhost:9000/user/mrdp/belowavgrep
Deleted hdfs://localhost:9000/user/mrdp/aboveavgrepWith JobControl
The JobControl and ControlledJob classes make up a system for chaining MapReduce jobs and has some
nice features like being able to track the state of the chain and fire
off jobs automatically when they’re ready by declaring their
dependencies. Using JobControl is the
right way of doing job chaining, but can sometimes be too heavyweight
for simpler applications.
To use JobControl, start by
wrapping your jobs with ControlledJob. Doing this is relatively
simple: you create your job like you usually would, except you also
create a ControlledJob that takes in
your Job or Configuration as a parameter, along with a
list of its dependencies (other ControlledJobs). Then, you add them one-by-one
to the JobControl object, which
handles the rest.
You still have to keep track of temporary data and clean it up afterwards or in the event of a failure.
Note
You can use any of the methods we’ve discussed so far to create iterative jobs that run the same job over and over. Typically, each iteration takes the previous iteration’s data as input. This is common practice for algorithms that have some sort of optimization component, such as k-means clustering in MapReduce. This is also common practice in many graph algorithms in MapReduce.
Job control example
For an example of a driver using JobControl, let’s combine the previous two
examples of basic job chaining and parallel jobs. We are already
familiar with the mapper and reducer code, so there is no need to go
over them again. The driver is the main showpiece here for job
configuration. It uses basic job chaining to launch the first job, and
then uses JobControl to execute the
remaining job in the chain and the two parallel jobs. The initial job
is not added via JobControl because
you need to interrupt the control for the in-between step of using the
counters of the first job to help assist in configuration of the
second job. All jobs must be completely configured before executing
the entire job chain, which can be limiting.
Main method
Let’s take a look at the main method. Here, we parse the
command line arguments and create all the paths we will need for all
four jobs to execute. We take special care when naming the variables
to know our data flows. The first job is then configured via a
helper function and executed. Upon completion of the first job, we
invoke Configuration methods in helper functions
to create three ControlledJob
objects. Each Configuration
method determines what mapper, reducer, etc. goes into each
job.
The binningControlledJob
has no dependencies, other than verifying that previous job executed
and completed successfully. The next two jobs are dependent on the
binning ControlledJob. These two
jobs will not be executed by JobControl until the binning job completes
successfully. If it doesn’t complete successfully, the other jobs
won’t be executed at all.
All three ControlledJobs
are added to the JobControl
object, and then it is run. The call to JobControl.run will block until the group
of jobs completes. We then check the failed job list to see if any
jobs failed and set our exit code accordingly. Intermediate output
is cleaned up prior to exiting.
publicstaticfinalStringAVERAGE_CALC_GROUP="AverageCalculation";publicstaticfinalStringMULTIPLE_OUTPUTS_ABOVE_NAME="aboveavg";publicstaticfinalStringMULTIPLE_OUTPUTS_BELOW_NAME="belowavg";publicstaticvoidmain(String[]args)throwsException{Configurationconf=newConfiguration();PathpostInput=newPath(args[0]);PathuserInput=newPath(args[1]);PathcountingOutput=newPath(args[3]+"_count");PathbinningOutputRoot=newPath(args[3]+"_bins");PathbinningOutputBelow=newPath(binningOutputRoot+"/"+JobChainingDriver.MULTIPLE_OUTPUTS_BELOW_NAME);PathbinningOutputAbove=newPath(binningOutputRoot+"/"+JobChainingDriver.MULTIPLE_OUTPUTS_ABOVE_NAME);PathbelowAverageRepOutput=newPath(args[2]);PathaboveAverageRepOutput=newPath(args[3]);JobcountingJob=getCountingJob(conf,postInput,countingOutput);intcode=1;if(countingJob.waitForCompletion(true)){ControlledJobbinningControlledJob=newControlledJob(getBinningJobConf(countingJob,conf,countingOutput,userInput,binningOutputRoot));ControlledJobbelowAvgControlledJob=newControlledJob(getAverageJobConf(conf,binningOutputBelow,belowAverageRepOutput));belowAvgControlledJob.addDependingJob(binningControlledJob);ControlledJobaboveAvgControlledJob=newControlledJob(getAverageJobConf(conf,binningOutputAbove,aboveAverageRepOutput));aboveAvgControlledJob.addDependingJob(binningControlledJob);JobControljc=newJobControl("AverageReputation");jc.addJob(binningControlledJob);jc.addJob(belowAvgControlledJob);jc.addJob(aboveAvgControlledJob);jc.run();code=jc.getFailedJobList().size()==0?0:1;}FileSystemfs=FileSystem.get(conf);fs.delete(countingOutput,true);fs.delete(binningOutputRoot,true);System.exit(code);}
Helper methods
Following are all the helper methods used to create the
actual Job or
Configuration objects. A ControlledJob can be created from either
class. There are three separate methods, the final method being used
twice to create the identical parallel jobs. The inputs and outputs
are all that differentiate them.
publicstaticJobgetCountingJob(Configurationconf,PathpostInput,PathoutputDirIntermediate)throwsIOException{// Setup first job to counter user postsJobcountingJob=newJob(conf,"JobChaining-Counting");countingJob.setJarByClass(JobChainingDriver.class);// Set our mapper and reducer, we can use the API's long sum reducer for// a combiner!countingJob.setMapperClass(UserIdCountMapper.class);countingJob.setCombinerClass(LongSumReducer.class);countingJob.setReducerClass(UserIdSumReducer.class);countingJob.setOutputKeyClass(Text.class);countingJob.setOutputValueClass(LongWritable.class);countingJob.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(countingJob,postInput);countingJob.setOutputFormatClass(TextOutputFormat.class);TextOutputFormat.setOutputPath(countingJob,outputDirIntermediate);returncountingJob;}publicstaticConfigurationgetBinningJobConf(JobcountingJob,Configurationconf,PathjobchainOutdir,PathuserInput,PathbinningOutput)throwsIOException{// Calculate the average posts per user by getting counter valuesdoublenumRecords=(double)countingJob.getCounters().findCounter(JobChainingDriver.AVERAGE_CALC_GROUP,UserIdCountMapper.RECORDS_COUNTER_NAME).getValue();doublenumUsers=(double)countingJob.getCounters().findCounter(JobChainingDriver.AVERAGE_CALC_GROUP,UserIdSumReducer.USERS_COUNTER_NAME).getValue();doubleaveragePostsPerUser=numRecords/numUsers;// Setup binning jobJobbinningJob=newJob(conf,"JobChaining-Binning");binningJob.setJarByClass(JobChainingDriver.class);// Set mapper and the average posts per userbinningJob.setMapperClass(UserIdBinningMapper.class);UserIdBinningMapper.setAveragePostsPerUser(binningJob,averagePostsPerUser);binningJob.setNumReduceTasks(0);binningJob.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(binningJob,jobchainOutdir);// Add two named outputs for below/above averageMultipleOutputs.addNamedOutput(binningJob,JobChainingDriver.MULTIPLE_OUTPUTS_BELOW_NAME,TextOutputFormat.class,Text.class,Text.class);MultipleOutputs.addNamedOutput(binningJob,JobChainingDriver.MULTIPLE_OUTPUTS_ABOVE_NAME,TextOutputFormat.class,Text.class,Text.class);MultipleOutputs.setCountersEnabled(binningJob,true);// Configure multiple outputsconf.setOutputFormat(NullOutputFormat.class);FileOutputFormat.setOutputPath(conf,outputDir);MultipleOutputs.addNamedOutput(conf,MULTIPLE_OUTPUTS_ABOVE_5000,TextOutputFormat.class,Text.class,LongWritable.class);MultipleOutputs.addNamedOutput(conf,MULTIPLE_OUTPUTS_BELOW_5000,TextOutputFormat.class,Text.class,LongWritable.class);// Add the user files to the DistributedCacheFileStatus[]userFiles=FileSystem.get(conf).listStatus(userInput);for(FileStatusstatus:userFiles){DistributedCache.addCacheFile(status.getPath().toUri(),binningJob.getConfiguration());}// Execute job and grab exit codereturnbinningJob.getConfiguration();}publicstaticConfigurationgetAverageJobConf(Configurationconf,PathaverageOutputDir,PathoutputDir)throwsIOException{JobaverageJob=newJob(conf,"ParallelJobs");averageJob.setJarByClass(ParallelJobs.class);averageJob.setMapperClass(AverageReputationMapper.class);averageJob.setReducerClass(AverageReputationReducer.class);averageJob.setOutputKeyClass(Text.class);averageJob.setOutputValueClass(DoubleWritable.class);averageJob.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(averageJob,averageOutputDir);averageJob.setOutputFormatClass(TextOutputFormat.class);TextOutputFormat.setOutputPath(averageJob,outputDir);// Execute job and grab exit codereturnaverageJob.getConfiguration();}
Chain Folding
Chain folding is an optimization that is applied to MapReduce job chains. Basically, it is a rule of thumb that says each record can be submitted to multiple mappers, or to a reducer and then a mapper. Such combined processing would save a lot of time reading files and transmitting data. The structure of the jobs often make these feasible because a map phase is completely shared-nothing: it looks at each record alone, so it doesn’t really matter what the organization of the data is or if it is grouped or not. When building large MapReduce chains, folding the chain to combine map phases will have some drastic performance benefits.
The main benefit of chain folding is reducing the amount of data movement in the MapReduce pipeline, whether it be the I/O of loading and storing to disk, or shuffling data over the network. In chained MapReduce jobs, temporary data is stored in HDFS, so if we can reduce the number of times we hit the disks, we’re reducing the total I/O in the chain.
There are a number of patterns in chains to look for to determine what to fold.
Take a look at the map phases in the chain. If multiple map phases are adjacent, merge them into one phase. This would be the case if you had a map-only job (such as a replicated join), followed by a numerical aggregation. In this step, we are reducing the amount of times we’re hitting the disks. Consider a two-job chain in which the first job is a map-only job, which is then followed by a traditional MapReduce job with a map phase and a reduce phase. Without this optimization, the first map-only job will write its output out to the distributed file system, and then that data will be loaded by the second job.
Instead, if we merge the map phase of the map-only job and the traditional job, that temporary data never gets written, reducing the I/O significantly. Also, fewer tasks are started, reducing overhead of task management. Chaining many map tasks together is an even more drastic optimization. In this case, there really isn’t any downside to do this other than having to possibly alter already existing code.
If the job ends with a map phase (combined or otherwise), push that phase into the reducer right before it. This is a special case with the same performance benefits as the previous step. It removes the I/O of writing temporary data out and then running a map-only job on it. It also reduces the task start-up overhead.
Note that the the first map phase of the chain cannot benefit from this next optimization. As much as possible, split up each map phase (combined or otherwise) between operations that decrease the amount of data (e.g., filtering) and operations that increase the amount of data (e.g., enrichment). In some cases, this is not possible because you may need some enrichment data in order to do the filtering. In these cases, look at dependent phases as one larger phase that cumulatively increases or decreases the amount of data. Push the processes that decrease the amount of data into the previous reducer, while keeping the processes that increase the amount of data where they are.
This step is a bit more complex and the difference is more subtle. The gain here is that if you push minimizing map-phase processing into the previous reducer, you will reduce the amount of data written to temporary storage, as well as the amount of data loaded off disk into the next part of the chain. This can be pretty significant if a drastic amount of filtering is done.
Caution
Be careful when merging phases that require lots of memory. For example, merging five replicated joins together might not be a good idea because it will exceed the total memory available to the task. In these cases, it might be better to just leave them separate.
Note
Regardless of whether a job is a chain or not, try to filter as much data as early as possible. The most expensive parts of a MapReduce job are typically pushing data through the pipeline: loading the data, the shuffle/sort, and storing the data. For example, if you care only about data from item 2012, filter that out in the map phase, not after the reducer has grouped the data together.
Let’s run through a couple of examples to help explain the idea and why it is so useful.
To exemplify step one, consider the chain in Figure 6-1. The original chain (on top) is optimized so that the replicated join is folded into the mapper of the second MapReduce job (bottom).

This job performs a word count on comments from teenagers. We do this to find out what topics are interesting to our youngest users. The age of the user isn’t with the comment, which is why we need to do a join. In this case, the map-only replicated join can be merged into the preprocessing of the second job.
To exemplify step two, consider the following chain in Figure 6-2. The original chain (top) is optimized so that the replicated join is folded into the reducer of the second MapReduce job (bottom).

This job enriches each user’s information with the number of comments that user has posted. It uses a generic counting MapReduce job, then uses a replicated join to add in the user information to the count. In this case, the map-only replicated join can be merged into the reducer.
To exemplify step three, consider the following chain in Figure 6-3. The original chain (top) is optimized so that the replicated join is folded into the reducer of the second MapReduce job (bottom).

This job is a bit more complicated than the others, as is evident from the long chain used to solve it. The intent is to find the most popular tags per age group, which is is done by finding a count of each user, enriching their user information onto it, filtering out counts less than 5, then finally grouping by the age group and summing up the original counts. When we look at the map tasks (enrichment and filtering), the replicated join is adding data, while the filter is removing data. Following step three, we are going to move the filtering to the first MapReduce job, and then move the replicated join into the map phase of the second MapReduce job. This gives us the new chain that can be seen at the bottom of Figure 6-3. Now the first MapReduce job will write out significantly less data than before and then it follows that the second MapReduce job is loading less data.
There are two primary methods for implementing chain folding:
manually cutting and pasting code together, and a more elegant approach
that uses special classes called ChainMapper and ChainReducer. If this is a one-time job and
logically has multiple map phases, just implement it in one shot with the
manual approach. If several of the map phases are reused (in a software
reuse sense), then you should use the ChainMapper and ChainReducer approach to follow good software
engineering practice.
The ChainMapper and ChainReducer Approach
ChainMapper and ChainReducer are special mapper and reducer classes that allow you to run multiple
map phases in the mapper and multiple map phases after the reducer. You
are effectively expanding the traditional map and reduce paradigm into
several map phases, followed by a reduce phase, followed by several map
phases. However, only one map phase and one reduce phase is ever
invoked.
Each chained map phase feeds into the next in the pipeline. The output of the first is then processed by the second, which is then processed by the third, and so on. The map phases on the backend of the reducer take the output of the reducer and do additional computation. This is useful for post-processing operations or additional filtering.
Caution
Be sure that the input types and output types between each chain
match up. If the first phase outputs a <LongWritable, Text>, be sure the
second phase takes its input as <LongWritable, Text>.
Chain Folding Example
Bin users by reputation
This example is a slight modification of the job chaining example. Here,
we use two mapper implementations for the initial map phase. The first
formats each input XML record and writes out the user ID with a count
of one. The second mapper then enriches the user ID with his or her
reputation, which is read during the setup phase via the DistributedCache.
These two individual mapper classes are then chained together to
feed a single reducer. This reducer is a basic LongSumReducer that simply iterates through all the values and sums the
numbers. This sum is then output along with the input key.
Finally, a third mapper is called that will bin the records
based on whether their reputation is below or above 5,000. This entire
flow is executed in one MapReduce job using ChainMapper and ChainReducer.
Caution
This example uses the deprecated mapred API, because ChainMapper and ChainReducer were not available in the
mapreduce package when this
example was written.
The following descriptions of each code section explain the solution to the problem.
Problem: Given a set of user posts and user information, bin users based on whether their reputation is below or above 5,000.
Parsing mapper code
This mapper implementation gets the user ID from the input post record and outputs it with a count of 1.
publicstaticclassUserIdCountMapperextendsMapReduceBaseimplementsMapper<Object,Text,Text,LongWritable>{publicstaticfinalStringRECORDS_COUNTER_NAME="Records";privatestaticfinalLongWritableONE=newLongWritable(1);privateTextoutkey=newText();publicvoidmap(Objectkey,Textvalue,OutputCollector<Text,LongWritable>output,Reporterreporter)throwsIOException{Map<String,String>parsed=MRDPUtils.transformXmlToMap(value.toString());// Get the value for the OwnerUserId attributeoutkey.set(parsed.get("OwnerUserId"));output.collect(outkey,ONE);}}
Replicated join mapper code
This mapper implementation is fed the output from the previous
mapper. It reads the users data set during the setup phase to create
a map of user ID to reputation. This map is used in the calls to
map to enrich the output key with
the user’s reputation. This new key is then output along with the
input value.
publicstaticclassUserIdReputationEnrichmentMapperextendsMapReduceBaseimplementsMapper<Text,LongWritable,Text,LongWritable>{privateTextoutkey=newText();privateHashMap<String,String>userIdToReputation=newHashMap<String,String>();publicvoidconfigure(JobConfjob){Path[]files=DistributedCache.getLocalCacheFiles(job);// Read all files in the DistributedCachefor(Pathp:files){BufferedReaderrdr=newBufferedReader(newInputStreamReader(newGZIPInputStream(newFileInputStream(newFile(p.toString())))));Stringline;// For each record in the user filewhile((line=rdr.readLine())!=null){// Get the user ID and reputationMap<String,String>parsed=MRDPUtils.transformXmlToMap(line);// Map the user ID to the reputationuserIdToReputation.put(parsed.get("Id",parsed.get("Reputation"));}}}publicvoidmap(Textkey,LongWritablevalue,OutputCollector<Text,LongWritable>output,Reporterreporter)throwsIOException{Stringreputation=userIdToReputation.get(key.toString());if(reputation!=null){outkey.set(key.toString()+" "+reputation);output.collect(outkey,value);}}}
Reducer code
This reducer implementation sums the values together and outputs this summation with the input key: user ID and reputation.
publicstaticclassLongSumReducerextendsMapReduceBaseimplementsReducer<Text,LongWritable,Text,LongWritable>{privateLongWritableoutvalue=newLongWritable();publicvoidreduce(Textkey,Iterator<LongWritable>values,OutputCollector<Text,LongWritable>output,Reporterreporter)throwsIOException{intsum=0;while(values.hasNext()){sum+=values.next().get();}outvalue.set(sum);output.collect(key,outvalue);}}
Binning mapper code
This mapper uses MultipleOutputs to bin users into two data
sets. The input key is parsed to pull out the reputation. This
reputation value is then compared to the value 5,000 and the record
is binned appropriately.
publicstaticclassUserIdBinningMapperextendsMapReduceBaseimplementsMapper<Text,LongWritable,Text,LongWritable>{privateMultipleOutputsmos=null;publicvoidconfigure(JobConfconf){mos=newMultipleOutputs(conf);}publicvoidmap(Textkey,LongWritablevalue,OutputCollector<Text,LongWritable>output,Reporterreporter)throwsIOException{if(Integer.parseInt(key.toString().split(" ")[1])<5000){mos.getCollector(MULTIPLE_OUTPUTS_BELOW_5000,reporter).collect(key,value);}else{mos.getCollector(MULTIPLE_OUTPUTS_ABOVE_5000,reporter).collect(key,value);}}publicvoidclose(){mos.close();}}
Driver code
The driver handles configuration of the ChainMapper
and ChainReducer. The most
interesting piece here is adding mappers and setting the reducer.
The order in which they are added affects the execution of the
different mapper implementations. ChainMapper is first used to add the two
map implementations that will be called back to back before any
sorting and shuffling occurs. Then, the ChainReducer static methods are used to
set the reducer implementation, and then finally a mapper on the
end. Note that you don’t use ChainMapper to add a mapper after a
reducer: use ChainReducer.
The signature of each method takes in the JobConf of a
mapper/reducer class, the input and output key value pair types, and
another JobConf for the
mapper/reducer class. This can be used in case the mapper or reducer
has overlapping configuration parameters. No special configuration
is required, so we simply pass in empty JobConf objects. The seventh parameter in
the signature is a flag as to pass values in the chain by reference
or by value. This is an added optimization you can use if the
collector does not modify the keys or values in either the mapper or
the reducer. Here, we make these assumptions, so we pass objects by
reference (byValue =
false).
In addition to configuring the chain mappers and reducers, we
also add the user data set to the DistributedCache so our second mapper can
perform the enrichment. We also set configure the MultipleOutputs and use a NullOutputFormat rather than the typical TextOutputFormat. Use of this output
format will prevent the framework from creating the default empty
part files.
publicstaticvoidmain(String[]args)throwsException{JobConfconf=newJobConf("ChainMapperReducer");conf.setJarByClass(ChainMapperDriver.class);PathpostInput=newPath(args[0]);PathuserInput=newPath(args[1]);PathoutputDir=newPath(args[2]);ChainMapper.addMapper(conf,UserIdCountMapper.class,LongWritable.class,Text.class,Text.class,LongWritable.class,false,newJobConf(false));ChainMapper.addMapper(conf,UserIdReputationEnrichmentMapper.class,Text.class,LongWritable.class,Text.class,LongWritable.class,false,newJobConf(false));ChainReducer.setReducer(conf,LongSumReducer.class,Text.class,LongWritable.class,Text.class,LongWritable.class,false,newJobConf(false));ChainReducer.addMapper(conf,UserIdBinningMapper.class,Text.class,LongWritable.class,Text.class,LongWritable.class,false,newJobConf(false));conf.setCombinerClass(LongSumReducer.class);conf.setInputFormat(TextInputFormat.class);TextInputFormat.setInputPaths(conf,postInput);// Configure multiple outputsconf.setOutputFormat(NullOutputFormat.class);FileOutputFormat.setOutputPath(conf,outputDir);MultipleOutputs.addNamedOutput(conf,MULTIPLE_OUTPUTS_ABOVE_5000,TextOutputFormat.class,Text.class,LongWritable.class);MultipleOutputs.addNamedOutput(conf,MULTIPLE_OUTPUTS_BELOW_5000,conf.setOutputKeyClass(Text.class);conf.setOutputValueClass(LongWritable.class);// Add the user files to the DistributedCacheFileStatus[]userFiles=FileSystem.get(conf).listStatus(userInput);for(FileStatusstatus:userFiles){DistributedCache.addCacheFile(status.getPath().toUri(),conf);}RunningJobjob=JobClient.runJob(conf);while(!job.isComplete()){Thread.sleep(5000);}System.exit(job.isSuccessful()?0:1);}
Job Merging
Like job folding, job merging is another optimization aimed to reduce the amount of I/O through the MapReduce pipeline. Job merging is a process that allows two unrelated jobs that are loading the same data to share the MapReduce pipeline. The main benefit of merging is that the data needs to be loaded and parsed only once. For some large-scale jobs, that task might be the most expensive part of the whole operation. One of the downsides of “schema-on-load” and storing the data in its original form is having to parse it over and over again, which can really impact performance if parsing is complicated (e.g., XML).
Assume we have two jobs that need to run over the exact same massive amount of data. These two jobs both load and parse the data, then perform their computations. With job merging, we’ll have one MapReduce job that logically performs the two jobs at once without mixing the two applications as seen in Figure 6-4. The original chain (top) is optimized so that the two mappers run on the same data, and the two reducers run on the same data (bottom).
Nothing is stopping you from applying job merging to more than two jobs at once. The more the merrier! The more you consolidate a shared burden across jobs, the more compute resources you’ll have available in your cluster.
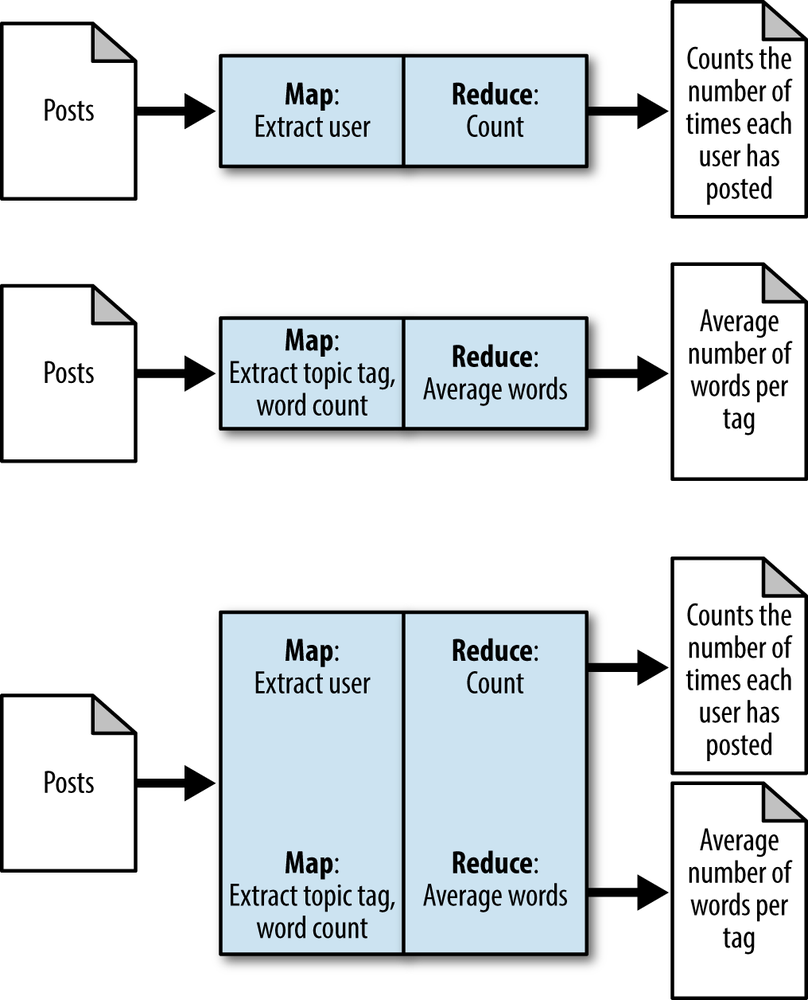
Likely, this process will be relevant only for important and already existing jobs in a production cluster. Development groups that take the time to consolidate their core analytics will see significant reductions in cluster utilization. When the jobs are merged, they’ll have to run together and the source code will have to be kept together. This is likely not worth it for jobs that are run in an ad hoc manner or are relatively new to the environment.
Unfortunately, you must satisfy a number of prerequisites before applying this pattern. The most obvious one is that both jobs need to have the same intermediate keys and output formats, because they’ll be sharing the pipeline and thus need to use the same data types. Serialization or polymorphism can be used if this is truly a problem, but adds a bit of complexity.
Job merging is a dirty procedure. Some hacks will have to be done to get it to work, but definitely more work can be put into a merging solution to make it a bit cleaner. From a software engineering perspective, this complicates the code organization, because unrelated jobs now share the same code. At a high level, the same map function will now be performing the original duties of the old map functions, while the reduce function will perform one action or another based on a tag on the key that tells which data set it came from. The steps for merging two jobs are as follows:
Bring the code for the two mappers together.
There are a couple of ways to do this. Copying and pasting the code works, but may complicate which piece of code is doing what. Good in-code comments can help you compensate for this. The other method is to separate the code into two helper map functions that process the input for each algorithm.
In the mapper, change the writing of the key and value to “tag” the key with the map source.
Tagging the key to indicate which map it came from is critical so that the data from the different maps don’t get mixed up. There are a few ways to do this depending on the original data type. If it is a string, you can simply make the first character the tag, so for instance you could change “parks” to “Aparks” when it comes from the first map, and “Bparks” when it comes from the second map.
The general way to tag is to make a custom composite tuple-like key that stores the tag separately from the original data. This is definitely the cleaner way of doing things, but takes a bit more work.
In the reducer, parse out the tag and use an if-statement to switch what reducer code actually gets executed.
As in the mapper, you can either just copy and paste the code into an if-statement or have the if-statement call out to helper functions. The if-statement controls the path of execution based on the tag.
Use
MultipleOutputsto separate the output for the jobs.MultipleOutputsis a special output format helper class that allows you to write to different folders of output for the same reducer, instead of just a single folder. Make it so the one reducer path always writes to one folder of theMultipleOutputs, while the other reducer path writes to the other folder.
Job Merging Examples
Anonymous comments and distinct users
This example combines Anonymizing StackOverflow comments and Distinct user IDs. Both examples used the comments data set as input. However, their outputs were very different. One created a distinct set of users, while the other created an anonymized version of each record. The comment portion of the StackOverflow data set is the largest we have, so merging these jobs together will definitely cut our processing time down. This way, the data set needs to be read only once.
The following descriptions of each code section explain the solution to the problem.
Problem: Given a set of comments, generate an anonymized version of the data and a distinct set of user IDs.
TaggedText WritableComparable
A custom WritableComparable
object is created to tag a Text with a string. This is a cleaner way of splitting the logic
between the two jobs, and saves us some string parsing in the
reducer.
This object has two private member variables and getters and
setters for each variable. It holds a String that the mapper uses to tag each Text value
that is also held by this object. The reducer then examines the tag
to find out which reduce logic to execute. The compareTo method is what makes this object
also comparable and allowed for use as a key in the MapReduce
framework. This method first examines the tag for equality. If they
are equal, the text inside the object is then compared and the value
immediately returned. If they are not equal, the value of the
comparison is then returned. Items are sorted by tag first, and then
by the text value. This type of comparison will produce output such
as:
A:100004122 A:120019879 D:10 D:22 D:23
publicstaticclassTaggedTextimplementsWritableComparable<TaggedText>{privateStringtag="";privateTexttext=newText();publicTaggedText(){}publicvoidsetTag(Stringtag){this.tag=tag;}publicStringgetTag(){returntag;}publicvoidsetText(Texttext){this.text.set(text);}publicvoidsetText(Stringtext){this.text.set(text);}publicTextgetText(){returntext;}publicvoidreadFields(DataInputin)throwsIOException{tag=in.readUTF();text.readFields(in);}publicvoidwrite(DataOutputout)throwsIOException{out.writeUTF(tag);text.write(out);}publicintcompareTo(TaggedTextobj){intcompare=tag.compareTo(obj.getTag());if(compare==0){returntext.compareTo(obj.getText());}else{returncompare;}}publicStringtoString(){returntag.toString()+":"+text.toString();}}
Merged mapper code
The map method simply passes the parameters to two helper
functions, each of which processes the map logic individual to write
output to context. The map
methods were slightly changed from their original respective
examples in order to both output Text objects as the key and value. This is
a necessary change so we can have the same type of intermediate
key/value pairs we had in the separate map logic. The anonymizeMap method generates an anonymous
record from the input value, whereas the distinctMap method grabs the user ID from
the record and outputs it. Each intermediate key/value pair written
out from each helper map method is tagged with either “A” for
anonymize or “D” for distinct.
Tip
Each helper math method parses the input record, but this
parsing should instead be done inside the actual map method, The resulting Map<String,String> can then be
passed to both helper methods. Any little optimizations like this
can be very beneficial in the long run and should be
implemented!
publicstaticclassAnonymizeDistinctMergedMapperextendsMapper<Object,Text,TaggedText,Text>{privatestaticfinalTextDISTINCT_OUT_VALUE=newText();privateRandomrndm=newRandom();privateTaggedTextanonymizeOutkey=newTaggedText(),distinctOutkey=newTaggedText();privateTextanonymizeOutvalue=newText();publicvoidmap(Objectkey,Textvalue,Contextcontext)throwsIOException,InterruptedException{anonymizeMap(key,value,context);distinctMap(key,value,context);}privatevoidanonymizeMap(Objectkey,Textvalue,Contextcontext)throwsIOException,InterruptedException{Map<String,String>parsed=MRDPUtils.transformXmlToMap(value.toString());if(parsed.size()>0){StringBuilderbldr=newStringBuilder();bldr.append("<row ");for(Entry<String,String>entry:parsed.entrySet()){if(entry.getKey().equals("UserId")||entry.getKey().equals("Id")){// ignore these fields}elseif(entry.getKey().equals("CreationDate")){// Strip out the time, anything after the 'T'// in the valuebldr.append(entry.getKey()+"=""+entry.getValue().substring(0,entry.getValue().indexOf('T'))+"" ");}else{// Otherwise, output this.bldr.append(entry.getKey()+"=""+entry.getValue()+"" ");}}bldr.append(">");anonymizeOutkey.setTag("A");anonymizeOutkey.setText(Integer.toString(rndm.nextInt()));anonymizeOutvalue.set(bldr.toString());context.write(anonymizeOutkey,anonymizeOutvalue);}}privatevoiddistinctMap(Objectkey,Textvalue,Contextcontext)throwsIOException,InterruptedException{Map<String,String>parsed=MRDPUtils.transformXmlToMap(value.toString());// Otherwise, set our output key to the user's id,// tagged with a "D"distinctOutkey.setTag("D");distinctOutkey.setText(parsed.get("UserId"));// Write the user's id with a null valuecontext.write(distinctOutkey,DISTINCT_OUT_VALUE);}}
Merged reducer code
The reducer’s calls to setup and cleanup handle the creation and closing of
the MultipleOutputs
utility. The reduce method checks
the tag of each input key and calls a helper reducer method based on
the tag. The reduce methods are passed the Text object inside the TaggedText.
For the anonymous call, all the input values are iterated over
and written to a named output of anonymize/part. Adding the slash and the
“part” creates a folder under the configured output directory that
contains a number of part files equivalent to the number of reduce
tasks.
For the distinct reduce call, the input key is written to
MultipleOutputs with a NullWritable to a named output of distinct/part. Again, this will create a
folder called distinct underneath
the job’s configured output directory.
Caution
In this example, we are outputting the same essential
format—a Text object and a
NullWritable object— from each
of the reduce calls. This won’t always be the case! If your jobs
have conflicting output key/value types, you can utilize the
Text object to normalize the
outputs.
publicstaticclassAnonymizeDistinctMergedReducerextendsReducer<TaggedText,Text,Text,NullWritable>{privateMultipleOutputs<Text,NullWritable>mos=null;protectedvoidsetup(Contextcontext)throwsIOException,InterruptedException{mos=newMultipleOutputs<Text,NullWritable>(context);}protectedvoidreduce(TaggedTextkey,Iterable<Text>values,Contextcontext)throwsIOException,InterruptedException{if(key.getTag().equals("A")){anonymizeReduce(key.getText(),values,context);}else{distinctReduce(key.getText(),values,context);}}privatevoidanonymizeReduce(Textkey,Iterable<Text>values,Contextcontext)throwsIOException,InterruptedException{for(Textvalue:values){mos.write(MULTIPLE_OUTPUTS_ANONYMIZE,value,NullWritable.get(),MULTIPLE_OUTPUTS_ANONYMIZE+"/part");}}privatevoiddistinctReduce(Textkey,Iterable<Text>values,Contextcontext)throwsIOException,InterruptedException{mos.write(MULTIPLE_OUTPUTS_DISTINCT,key,NullWritable.get(),MULTIPLE_OUTPUTS_DISTINCT+"/part");}protectedvoidcleanup(Contextcontext)throwsIOException,InterruptedException{mos.close();}}
Driver code
The driver code looks just like any other driver that uses
MultipleOutputs. All the logic of
merging jobs is done inside the mapper and reducer implementation.
publicstaticvoidmain(String[]args)throwsException{// Configure the merged jobJobjob=newJob(newConfiguration(),"MergedJob");job.setJarByClass(MergedJobDriver.class);job.setMapperClass(AnonymizeDistinctMergedMapper.class);job.setReducerClass(AnonymizeDistinctMergedReducer.class);job.setNumReduceTasks(10);TextInputFormat.setInputPaths(job,newPath(args[0]));TextOutputFormat.setOutputPath(job,newPath(args[1]));MultipleOutputs.addNamedOutput(job,MULTIPLE_OUTPUTS_ANONYMIZE,TextOutputFormat.class,Text.class,NullWritable.class);MultipleOutputs.addNamedOutput(job,MULTIPLE_OUTPUTS_DISTINCT,TextOutputFormat.class,Text.class,NullWritable.class);job.setOutputKeyClass(TaggedText.class);job.setOutputValueClass(Text.class);System.exit(job.waitForCompletion(true)?0:1);}