
Chapter 7. Input and Output Patterns
In this chapter, we’ll be focusing on what is probably the most often overlooked way to
improve the value of MapReduce: customizing input and output. You will not
always want to load or store data the way Hadoop MapReduce does out of the
box. Sometimes you can skip the time-consuming step of storing data in HDFS
and just accept data from some original source, or feed it directly to some
process that uses it after MapReduce is finished. Sometimes the basic Hadoop
paradigm of file blocks and input splits doesn’t do what you need, so this
is where a custom InputFormat or OutputFormat comes into play.
Three patterns in this chapter deal with input: generating data, external source input, and partition pruning. All three input patterns share an interesting property: the map phase is completely unaware that tricky things are going on before it gets its input pairs. Customizing an input format is a great way to abstract away details of the method you use to load data.
On the flip side, Hadoop will not always store data in the way you need it to. There is one pattern in this chapter, external source output, that writes data to a system outside of Hadoop and HDFS. Just like the custom input formats, custom output formats keep the map or reduce phase from realizing that tricky things are going on as the data is going out.
Customizing Input and Output in Hadoop
Hadoop allows you to modify the way data is loaded on disk in two major
ways: configuring how contiguous chunks of input are generated from blocks
in HDFS (or maybe more exotic sources), and configuring how records appear
in the map phase. The two classes you’ll be playing with to do this are
RecordReader and InputFormat. These work with the Hadoop MapReduce framework in a very similar
way to how mappers and reducers are plugged in.
Hadoop also allows you to modify the way data is stored in an
analogous way: with an OutputFormat
and a RecordWriter.
InputFormat
Hadoop relies on the input format of the job to do three things:
Validate the input configuration for the job (i.e., checking that the data is there).
Split the input blocks and files into logical chunks of type
InputSplit, each of which is assigned to a map task for processing.Create the
RecordReaderimplementation to be used to create key/value pairs from the rawInputSplit. These pairs are sent one by one to their mapper.
The most common input formats are subclasses of FileInputFormat,
with the Hadoop default being TextInputFormat. The input format first validates the input into the job by
ensuring that all of the input paths exist. Then it logically splits
each input file based on the total size of the file in bytes, using the
block size as an upper bound. For example, a 160 megabyte file in HDFS
will generate three input splits along the byte ranges 0MB-64MB, 64MB-128MB and 128MB-160MB. Each map task will be assigned
exactly one of these input splits, and then the RecordReader implementation is responsible for
generate key/value pairs out of all the bytes it has been
assigned.
Typically, the RecordReader has
the additional responsibility of fixing boundaries, because the input
split boundary is arbitrary and probably will not fall on a record
boundary. For example, the TextInputFormat reads text files using a
LineRecordReader to create key/value pairs for each map task for each line of
text (i.e., separated by a newline character). The key is the number of
bytes read in the file so far and the value is a string of characters up
to a newline character. Because it is very unlikely that the chunk of
bytes for each input split will be lined up with a newline character,
the LineRecordReader will read past
its given “end” in order to make sure a complete line is read. This bit
of data comes from a different data block and is therefore not stored on
the same node, so it is streamed from a DataNode hosting the block. This
streaming is all handled by an instance of the FSDataInputStream
class, and we (thankfully) don’t have to deal with any knowledge of
where these blocks are.
Don’t be afraid to go past split boundaries in your own formats, just be sure to test thoroughly so you aren’t duplicating or missing any data!
Tip
Custom input formats are not limited to file-based input. As
long as you can express the input as InputSplit objects and key/value pairs,
custom or otherwise, you can read anything into the map phase of a
MapReduce job in parallel. Just be sure to keep in mind what an input
split represents and try to take advantage of data locality.
The InputFormat abstract class
contains two abstract methods:
- getSplits
The implementation of
getSplitstypically uses the givenJobContextobject to retrieve the configured input and return aListofInputSplitobjects. The input splits have a method to return an array of machines associated with the locations of the data in the cluster, which gives clues to the framework as to which TaskTracker should process the map task. This method is also a good place to verify the configuration and throw any necessary exceptions, because the method is used on the front-end (i.e. before the job is submitted to the JobTracker).- createRecordReader
This method is used on the back-end to generate an implementation of
RecordReader, which we’ll discuss in more detail shortly. Typically, a new instance is created and immediately returned, because the record reader has aninitializemethod that is called by the framework.
RecordReader
The RecordReader abstract class
creates key/value pairs from a given InputSplit. While the InputSplit represents the byte-oriented view
of the split, the RecordReader makes
sense out of it for processing by a mapper. This is why Hadoop and
MapReduce is considered schema on read. It is in
the RecordReader that the schema is
defined, based solely on the record reader implementation, which changes
based on what the expected input is for the job. Bytes are read from the
input source and turned into a WritableComparable
key and a Writable value. Custom data
types are very common when creating custom input formats, as they are a
nice object-oriented way to present information to a mapper.
A RecordReader uses the data
within the boundaries created by the input split to generate key/value
pairs. In the context of file-based input, the “start” is the byte
position in the file where the RecordReader should start generating key/value
pairs. The “end” is where it should stop reading records. These are not
hard boundaries as far as the API is concerned—there is nothing stopping
a developer from reading the entire file for each map task. While
reading the entire file is not advised, reading outside of the
boundaries it often necessary to ensure that a complete record is
generated.
Consider the case of XML. While using a TextInputFormat
to grab each line works, XML elements are typically not on the same line
and will be split by a typical MapReduce input. By reading past the
“end” input split boundary, you can complete an entire record. After
finding the bottom of the record, you just need to ensure that each
record reader starts at the beginning of an XML element. After seeking
to the start of the input split, continue reading until the beginning of
the configured XML tag is read. This will allow the MapReduce framework
to cover the entire contents of an XML file, while not duplicating any
XML records. Any XML that is skipped by seeking forward to the start of
an XML element will be read by the preceding map task.
The RecordReader abstract class
has a number of methods that must be overridden.
- initialize
This method takes as arguments the map task’s assigned
InputSplitandTaskAttemptContext, and prepares the record reader. For file-based input formats, this is a good place to seek to the byte position in the file to begin reading.- getCurrentKey and getCurrentValue
These methods are used by the framework to give generated key/value pairs to an implementation of
Mapper. Be sure to reuse the objects returned by these methods if at all possible!- nextKeyValue
Like the corresponding method of the
InputFormatclass, this reads a single key/value pair and returnstrueuntil the data is consumed.- getProgress
Like the corresponding method of the
InputFormatclass, this is an optional method used by the framework for metrics gathering.- close
This method is used by the framework for cleanup after there are no more key/value pairs to process.
OutputFormat
Similarly to an input format, Hadoop relies on the output format of the job for two main tasks:
Validate the output configuration for the job.
Create the
RecordWriterimplementation that will write the output of the job.
On the flip side of the FileInputFormat,
there is a FileOutputFormat to
work with file-based output. Because most output from a
MapReduce job is written to HDFS, the many file-based output formats
that come with the API will solve most of yours needs. The default used
by Hadoop is the TextOutputFormat,
which stores key/value pairs to HDFS at a configured output directory
with a tab delimiter. Each reduce task writes an individual part file to
the configured output directory. The TextOutputFormat also validates that the output directory does not exist prior
to starting the MapReduce job.
The TextOutputFormat uses a
LineRecordWriter to write key/value pairs for each map task or reduce task,
depending on whether there is a reduce phase or not. This class uses the
toString method to serialize each
each key/value pair to a part file in HDFS, delimited by a tab. This tab
delimiter is the default and can be changed via job
configuration.
Again, much like an InputFormat, you are not restricted to storing
data to HDFS. As long as you can write key/value pairs to some other
source with Java (e.g., a JDBC database connection), you can use
MapReduce to do a parallel bulk write. Just make sure whatever you are
writing to can handle the large number of connections from the many
tasks.
The OutputFormat abstract class
contains three abstract methods for implementation:
- checkOutputSpecs
This method is used to validate the output specification for the job, such as making sure the directory does not already exist prior to it being submitted. Otherwise, the output would be overwritten.
- getRecordWriter
This method returns a
RecordWriterimplementation that serializes key/value pairs to an output, typically aFileSystemobject.- getOutputCommiter
The output committer of a job sets up each task during initialization, commits the task upon successful completion, and cleans up each task when it finishes — successful or otherwise. For file-based output, a
FileOutputCommittercan be used to handle all the heavy lifting. It will create temporary output directories for each map task and move the successful output to the configured output directory when necessary.
RecordWriter
The RecordWriter abstract
class writes key/value pairs to a file system, or another
output. Unlike its RecordReader
counterpart, it does not contain an initialize phase. However, the
constructor can always be used to set up the record writer for whatever
is needed. Any parameters can be passed in during construction, because
the record writer instance is created via OutputFormat.getRecordWriter.
The RecordWriter abstract class
is a much simpler interface, containing only two methods:
- write
This method is called by the framework for each key/value pair that needs to be written. The implementation of this method depends very much on your use case. The examples we’ll show will write each key/value pair to an external in-memory key/value store rather than a file system.
- close
This method is used by the framework after there are no more key/value pairs to write out. This can be used to release any file handles, shut down any connections to other services, or any other cleanup tasks needed.
Generating Data
Pattern Description
The generating data pattern is interesting because instead of loading data that comes from somewhere outside, it generates that data on the fly and in parallel.
Intent
You want to generate a lot of data from scratch.
Motivation
This pattern is different from all of the others in the book in that it doesn’t load data. With this pattern, you generate the data and store it back in the distributed file system.
Generating data isn’t common. Typically you’ll generate a bunch of the data at once then use it over and over again. However, when you do need to generate data, MapReduce is an excellent system for doing it.
The most common use case for this pattern is generating random data. Building some sort of representative data set could be useful for large scale testing for when the real data set is still too small. It can also be useful for building “toy domains” for researching a proof of concept for an analytic at scale.
Generating random data is also used often used as part of a benchmark, such as the commonly used TeraGen/TeraSort and DFSIO.
Unfortunately, the implementation of this pattern isn’t straightforward in Hadoop because one of the foundational pieces of the framework is assigning one map task to an input split and assigning one map function call to one record. In this case, there are no input splits and there are no records, so we have to fool the framework to think there are.
Structure
To implement this pattern in Hadoop, implement a
custom InputFormat and let
a RecordReader
generate the random data. The map function is completely oblivious to
the origin of the data, so it can be built on the fly instead of being
loaded out of some file in HDFS. For the most part, using the identity
mapper is fine here, but you might want to do some post-processing in
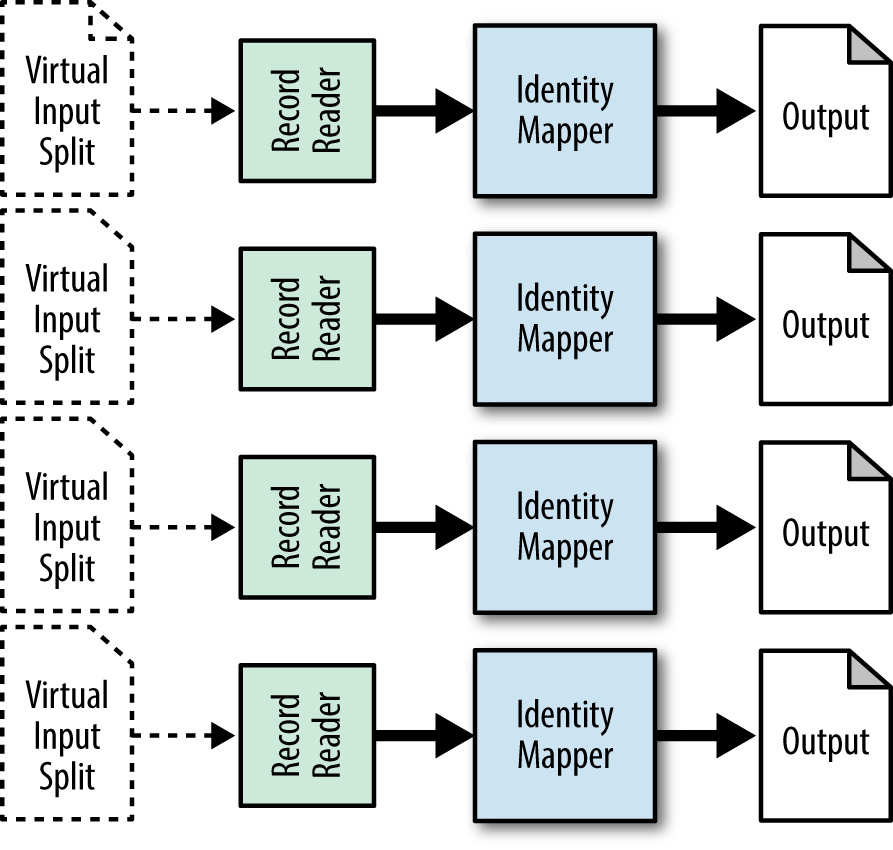
the map task, or even analyze it right away. See Figure 7-1.
This pattern is map-only.
The
InputFormatcreates the fake splits from nothing. The number of splits it creates should be configurable.The
RecordReadertakes its fake split and generates random records from it.In some cases, you can assign some information in the input split to tell the record reader what to generate. For example, to generate random date/time data, have each input split account for an hour.
In most cases, the
IdentityMapperis used to just write the data out as it comes in.
Tip
The lazy way of doing implementing this pattern is to seed the
job with many fake input files containing a single bogus record.
Then, you can just use a generic InputFormat and RecordReader and generate the data in the
map function. The empty input files are then deleted on application
exit.
Consequences
Each mapper outputs a file containing random data.
Resemblances
There are a number of ways to create random data with SQL and Pig, but nothing that is eloquent or terse.
Performance analysis
The major consideration here in terms of performance is how many worker map tasks are needed to generate the data. In general, the more map tasks you have, the faster you can generate data since you are better utilizing the parallelism of the cluster. However, it makes little sense to fire up more map tasks than you have map slots since they are all doing the same thing.
Generating Data Examples
Generating random StackOverflow comments
To generate random StackOverflow data, we’ll take a list of 1,000 words and just make random blurbs. We also have to generate a random score, a random row ID (we can ignore that it likely won’t be unique), a random user ID, and a random creation date.
The following descriptions of each code section explain the solution to the problem.
Driver code
The driver parses the four command line arguments to configure this job. It sets our custom input format and calls the static methods to configure it further. All the output is written to the given output directory. The identity mapper is used for this job, and the reduce phase is disabled by setting the number of reduce tasks to zero.
publicstaticvoidmain(String[]args)throwsException{Configurationconf=newConfiguration();intnumMapTasks=Integer.parseInt(args[0]);intnumRecordsPerTask=Integer.parseInt(args[1]);PathwordList=newPath(args[2]);PathoutputDir=newPath(args[3]);Jobjob=newJob(conf,"RandomDataGenerationDriver");job.setJarByClass(RandomDataGenerationDriver.class);job.setNumReduceTasks(0);job.setInputFormatClass(RandomStackOverflowInputFormat.class);RandomStackOverflowInputFormat.setNumMapTasks(job,numMapTasks);RandomStackOverflowInputFormat.setNumRecordPerTask(job,numRecordsPerTask);RandomStackOverflowInputFormat.setRandomWordList(job,wordList);TextOutputFormat.setOutputPath(job,outputDir);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);System.exit(job.waitForCompletion(true)?0:2);}
InputSplit code
The FakeInputSplit class
simply extends InputSplit and
implements Writable. There is no
implementation for any of the overridden methods, or for methods
requiring return values return basic values. This input split is
used to trick the framework into assigning a task to generate the
random data.
publicstaticclassFakeInputSplitextendsInputSplitimplementsWritable{publicvoidreadFields(DataInputarg0)throwsIOException{}publicvoidwrite(DataOutputarg0)throwsIOException{}publiclonggetLength()throwsIOException,InterruptedException{return0;}publicString[]getLocations()throwsIOException,InterruptedException{returnnewString[0];}}
InputFormat code
The input format has two main purposes: returning the list of
input splits for the framework to generate map tasks from, and then
creating the RandomStackOverflowRecordReader for the
map task. We override the getSplits method to return a configured
number of FakeInputSplit splits.
This number is pulled from the
configuration. When the framework calls createRecordReader, a RandomStackOverflowRecordReader
is instantiated, initialized, and returned.
publicstaticclassRandomStackOverflowInputFormatextendsInputFormat<Text,NullWritable>{publicstaticfinalStringNUM_MAP_TASKS="random.generator.map.tasks";publicstaticfinalStringNUM_RECORDS_PER_TASK="random.generator.num.records.per.map.task";publicstaticfinalStringRANDOM_WORD_LIST="random.generator.random.word.file";publicList<InputSplit>getSplits(JobContextjob)throwsIOException{// Get the number of map tasks configured forintnumSplits=job.getConfiguration().getInt(NUM_MAP_TASKS,-1);// Create a number of input splits equivalent to the number of tasksArrayList<InputSplit>splits=newArrayList<InputSplit>();for(inti=0;i<numSplits;++i){splits.add(newFakeInputSplit());}returnsplits;}publicRecordReader<Text,NullWritable>createRecordReader(InputSplitsplit,TaskAttemptContextcontext)throwsIOException,InterruptedException{// Create a new RandomStackOverflowRecordReader and initialize itRandomStackOverflowRecordReaderrr=newRandomStackOverflowRecordReader();rr.initialize(split,context);returnrr;}publicstaticvoidsetNumMapTasks(Jobjob,inti){job.getConfiguration().setInt(NUM_MAP_TASKS,i);}publicstaticvoidsetNumRecordPerTask(Jobjob,inti){job.getConfiguration().setInt(NUM_RECORDS_PER_TASK,i);}publicstaticvoidsetRandomWordList(Jobjob,Pathfile){DistributedCache.addCacheFile(file.toUri(),job.getConfiguration());}}
RecordReader code
This record reader is where the data is actually generated. It is given
during our FakeInputSplit during
initialization, but simply ignores it. The number of records to
create is pulled from the job configuration, and the list of random
words is read from the DistributedCache. For each call to
nextKeyValue, a random record is
created using a simple random number generator. The body of the
comment is generated by a helper function that randomly selects
words from the list, between one and thirty words (also random). The
counter is incremented to keep track of how many records have been
generated. Once all the records are generated, the record reader
returns false, signaling the
framework that there is no more input for the mapper.
publicstaticclassRandomStackOverflowRecordReaderextendsRecordReader<Text,NullWritable>{privateintnumRecordsToCreate=0;privateintcreatedRecords=0;privateTextkey=newText();privateNullWritablevalue=NullWritable.get();privateRandomrndm=newRandom();privateArrayList<String>randomWords=newArrayList<String>();// This object will format the creation date string into a Date// objectprivateSimpleDateFormatfrmt=newSimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS");publicvoidinitialize(InputSplitsplit,TaskAttemptContextcontext)throwsIOException,InterruptedException{// Get the number of records to create from the configurationthis.numRecordsToCreate=context.getConfiguration().getInt(NUM_RECORDS_PER_TASK,-1);// Get the list of random words from the DistributedCacheURI[]files=DistributedCache.getCacheFiles(context.getConfiguration());// Read the list of random words into a listBufferedReaderrdr=newBufferedReader(newFileReader(files[0].toString()));Stringline;while((line=rdr.readLine())!=null){randomWords.add(line);}rdr.close();}publicbooleannextKeyValue()throwsIOException,InterruptedException{// If we still have records to createif(createdRecords<numRecordsToCreate){// Generate random dataintscore=Math.abs(rndm.nextInt())%15000;introwId=Math.abs(rndm.nextInt())%1000000000;intpostId=Math.abs(rndm.nextInt())%100000000;intuserId=Math.abs(rndm.nextInt())%1000000;StringcreationDate=frmt.format(Math.abs(rndm.nextLong()));// Create a string of text from the random wordsStringtext=getRandomText();StringrandomRecord="<row Id=""+rowId+"" PostId=""+postId+"" Score=""+score+"" Text=""+text+"" CreationDate=""+creationDate+"" UserId"="+userId+"" />";key.set(randomRecord);++createdRecords;returntrue;}else{// We are done creating recordsreturnfalse;}}privateStringgetRandomText(){StringBuilderbldr=newStringBuilder();intnumWords=Math.abs(rndm.nextInt())%30+1;for(inti=0;i<numWords;++i){bldr.append(randomWords.get(Math.abs(rndm.nextInt())%randomWords.size())+" ");}returnbldr.toString();}publicTextgetCurrentKey()throwsIOException,InterruptedException{returnkey;}publicNullWritablegetCurrentValue()throwsIOException,InterruptedException{returnvalue;}publicfloatgetProgress()throwsIOException,InterruptedException{return(float)createdRecords/(float)numRecordsToCreate;}publicvoidclose()throwsIOException{// nothing to do here...}}
External Source Output
Pattern Description
As stated earlier in this chapter, the external source output pattern writes data to a system outside of Hadoop and HDFS.
Intent
You want to write MapReduce output to a nonnative location.
Motivation
With this pattern, we are able to output data from the MapReduce framework directly to an external source. This is extremely useful for direct loading into a system instead of staging the data to be delivered to the external source. The pattern skips storing data in a file system entirely and sends output key/value pairs directly where they belong. MapReduce is rarely ever hosting an applications as-is, so using MapReduce to bulk load into an external source in parallel has its uses.
In a MapReduce approach, the data is written out in parallel. As with using an external source for input, you need to be sure the destination system can handle the parallel ingest it is bound to endure with all the open connections.
Structure
Figure 7-2 shows the external source output structure, explained below.
The
OutputFormatverifies the output specification of the job configuration prior to job submission. This is a great place to ensure that the external source is fully functional, as it won’t be good to process all the data only to find out the external source was unable when it was time to commit the data. This method also is responsible for creating and initializing aRecordWriterimplementation.The
RecordWriterwrites all key/value pairs to the external source. Much like aRecordReader, the implementation varies depending on the external data source being written to. During construction of the object, establish any needed connections using the external source’s API. These connections are then used to write out all the data from each map or reduce task.

Consequences
The output data has been sent to the external source and that external source has loaded it successfully.
Caution
Note that task failures are bound to happen, and when they do,
any key/value pairs written in the write method can’t be reverted. In a
typical MapReduce job, temporary output is written to the file
system. In the event of a failure, this output is simply discarded.
When writing to an external source directly, it will receive the
data in a stream. If a task fails, the external source won’t
automatically know about it and discard all the data it received
from a task. If this is unacceptable, consider using a custom
OutputCommitter to write
temporary output to the file system. This temporary output can then
be read, delivered to the external source, and deleted upon success,
or deleted from the file system outright in the event of a
failure.
Performance analysis
From a MapReduce perspective, there isn’t much to worry about since the map and reduce are generic. However, you do have to be very careful that the receiver of the data can handle the parallel connections. Having a thousand tasks writing to a single SQL database is not going to work well. To avoid this, you may have to have each reducer handle a bit more data than you typically would to reduce the number of parallel writes to the data sink. This is not necessarily a problem if the destination of the data is parallel in nature and supports parallel ingestation. For example, for writing to a sharded SQL database, you could have each reducer write to a specific database instance.
External Source Output Example
Writing to Redis instances
This example is a basic means for writing to a number of Redis instances in parallel from MapReduce. Redis is an open-source, in-memory, key-value store. It is often referred to as a data structure server, since keys can contain strings, hashes, lists, sets, and sorted sets. Redis is written in ANSI C and works in most POSIX systems, such as Linux, without any external dependencies.
In order to work with the Hadoop framework, Jedis is used to communicate with Redis. Jedis is an open-source “blazingly small and sane Redis java client.” A list of clients written for other languages is available on their website.
Unlike other examples in this book, there is no actual analysis
in this example (along with the rest of the examples in this chapter).
It focuses on how to take a data set stored in HDFS and store it in an
external data source using a custom FileOutputFormat. In this example, the Stack
Overflow users data set is written to a configurable number of Redis
instances, specifically the user-to-reputation mappings. These
mappings are randomly distributed evenly among a single Redis
hash.
A Redis hash is a map between string fields and string values,
similar to a Java HashMap. Each
hash is given a key to identify the hash. Every hash can store more
than four billion field-value pairs.
The sections below with its corresponding code explain the following problem.
Problem: Given a set of user information, randomly distributed user-to-reputation mappings to a configurable number of Redis instances in parallel.
OutputFormat code
The RedisHashOutputFormat
is responsible for establishing and verifying the job
configuration prior to being submitted to the JobTracker. Once the
job has been submitted, it also creates the RecordWriter to serialize all the output
key/value pairs. Typically, this is a file in HDFS. However, we are
not bound to using HDFS, as we will see in the RecordWriter later on.
The output format contains configuration variables that must
be set by the driver to ensure it has all the information required
to do its job. Here, we have a couple public static methods to take some of the
guess work out of what a developer needs to set. This output format
takes in a list of Redis instance hosts as a CSV structure and a
Redis hash key to write all the output to. In the checkOutputSpecs method, we ensure that
both of these parameters are set before we even both launching the
job, as it will surely fail without them. This is where you’ll want
to verify your configuration!
The getRecordWriter method
is used on the back end to create an instance of a RecordWriter for the map or reduce task.
Here, we get the configuration variables required by the RedisHashRecordWriter and return a new
instance of it. This record writer is a nested class of the RedisHashOutputFormat, which is not
required but is more of a convention. The details of this class are
in the following section.
The final method of this output format is getOutputCommitter. The output committer
is used by the framework to manage any temporary output before
committing in case the task fails and needs to be reexecuted. For
this implementation, we don’t typically care whether the task fails
and needs to be re-executed. As long as the job finishes we are
okay. An output committer is required by the framework, but the
NullOutputFormat contains an
output committer implementation that doesn’t do anything.
publicstaticclassRedisHashOutputFormatextendsOutputFormat<Text,Text>{publicstaticfinalStringREDIS_HOSTS_CONF="mapred.redishashoutputformat.hosts";publicstaticfinalStringREDIS_HASH_KEY_CONF="mapred.redishashinputformat.key";publicstaticvoidsetRedisHosts(Jobjob,Stringhosts){job.getConfiguration().set(REDIS_HOSTS_CONF,hosts);}publicstaticvoidsetRedisHashKey(Jobjob,StringhashKey){job.getConfiguration().set(REDIS_HASH_KEY_CONF,hashKey);}publicRecordWriter<Text,Text>getRecordWriter(TaskAttemptContextjob)throwsIOException,InterruptedException{returnnewRedisHashRecordWriter(job.getConfiguration().get(REDIS_HASH_KEY_CONF),job.getConfiguration().get(REDIS_HOSTS_CONF));}publicvoidcheckOutputSpecs(JobContextjob)throwsIOException{Stringhosts=job.getConfiguration().get(REDIS_HOSTS_CONF);if(hosts==null||hosts.isEmpty()){thrownewIOException(REDIS_HOSTS_CONF+" is not set in configuration.");}StringhashKey=job.getConfiguration().get(REDIS_HASH_KEY_CONF);if(hashKey==null||hashKey.isEmpty()){thrownewIOException(REDIS_HASH_KEY_CONF+" is not set in configuration.");}}publicOutputCommittergetOutputCommitter(TaskAttemptContextcontext)throwsIOException,InterruptedException{return(newNullOutputFormat<Text,Text>()).getOutputCommitter(context);}publicstaticclassRedisHashRecordWriterextendsRecordWriter<Text,Text>{// code in next section}}
RecordWriter code
The RedisHashRecordWriter
handles connecting to Redis via the Jedis client and writing
out the data. Each key/value pair is randomly written to a Redis
instance, providing an even distribution of all data across all
Redis instances. The constructor stores the hash key to write to and
creates a new Jedis instance.
The code then connects to the Jedis instance and maps it to an
integer. This map is used in the write method to get the assigned Jedis
instance. The hash code is the key is taken modulo the number of
configured Redis instances. The key/value pair is then written to
the returned Jedis instance to the configured hash. Finally, all
Jedis instances are disconnected in the close method.
publicstaticclassRedisHashRecordWriterextendsRecordWriter<Text,Text>{privateHashMap<Integer,Jedis>jedisMap=newHashMap<Integer,Jedis>();privateStringhashKey=null;publicRedisHashRecordWriter(StringhashKey,Stringhosts){this.hashKey=hashKey;// Create a connection to Redis for each host// Map an integer 0-(numRedisInstances - 1) to the instanceinti=0;for(Stringhost:hosts.split(",")){Jedisjedis=newJedis(host);jedis.connect();jedisMap.put(i,jedis);++i;}}publicvoidwrite(Textkey,Textvalue)throwsIOException,InterruptedException{// Get the Jedis instance that this key/value pair will be// written toJedisj=jedisMap.get(Math.abs(key.hashCode())%jedisMap.size());// Write the key/value pairj.hset(hashKey,key.toString(),value.toString());}publicvoidclose(TaskAttemptContextcontext)throwsIOException,InterruptedException{// For each jedis instance, disconnect itfor(Jedisjedis:jedisMap.values()){jedis.disconnect();}}}
Mapper Code
The Mapper instance is very straightforward and looks like any other mapper. The user ID and reputation are retrieved from the record and then output. The output format does all the heavy lifting for us, allowing it to be reused multiple times to write whatever we want to a Redis hash.
publicstaticclassRedisOutputMapperextendsMapper<Object,Text,Text,Text>{privateTextoutkey=newText();privateTextoutvalue=newText();publicvoidmap(Objectkey,Textvalue,Contextcontext)throwsIOException,InterruptedException{Map<String,String>parsed=MRDPUtils.transformXmlToMap(value.toString());StringuserId=parsed.get("Id");Stringreputation=parsed.get("Reputation");// Set our output key and valuesoutkey.set(userId);outvalue.set(reputation);context.write(outkey,outvalue);}}
Driver Code
The driver code parses the command lines and calls our
public static methods to set up
writing data to Redis. The job is then submitted just like any
other.
publicstaticvoidmain(String[]args)throwsException{Configurationconf=newConfiguration();PathinputPath=newPath(args[0]);Stringhosts=args[1];StringhashName=args[2];Jobjob=newJob(conf,"Redis Output");job.setJarByClass(RedisOutputDriver.class);job.setMapperClass(RedisOutputMapper.class);job.setNumReduceTasks(0);job.setInputFormatClass(TextInputFormat.class);TextInputFormat.setInputPaths(job,inputPath);job.setOutputFormatClass(RedisHashOutputFormat.class);RedisHashOutputFormat.setRedisHosts(job,hosts);RedisHashOutputFormat.setRedisHashKey(job,hashName);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);intcode=job.waitForCompletion(true)?0:2;System.exit(code);}
External Source Input
Pattern Description
The external source input pattern doesn’t load data from HDFS, but instead from some system outside of Hadoop, such as an SQL database or a web service.
Intent
You want to load data in parallel from a source that is not part of your MapReduce framework.
Motivation
The typical model for using MapReduce to analyze your data is to store it into your storage platform first (i.e., HDFS), then analyze it. With this pattern, you can hook up the MapReduce framework into an external source, such as a database or a web service, and pull the data directly into the mappers.
There are a few reasons why you might want to analyze the data directly from the source instead of staging it first. It may be faster to load the data from outside of Hadoop without having to stage it into files first. For example, dumping a database to the file system is likely to be an expensive operation, and taking it from the database directly ensures that the MapReduce job has the most up-to-date data available. A lot can happen on a busy cluster, and dumping a database prior to running an analytics can also fail, causing a stall in the entire pipeline.
In a MapReduce approach, the data is loaded in parallel rather than in a serial fashion. The caveat to this is that the source needs to have well-defined boundaries on which data is read in parallel in order to scale. For example, in the case of a sharded databases, each map task can be assigned a shard to load from the a table, thus allowing for very quick parallel loads of data without requiring a database scan.
Structure
Figure 7-3 shows the external source input structure.
The
InputFormatcreates all theInputSplitobjects, which may be based on a custom object. An input split is a chunk of logical input, and that largely depends on the format in which it will be reading data. In this pattern, the input is not from a file-based input but an external source. The input could be from a series of SQL tables or a number of distributed services spread through the cluster. As long as the input can be read in parallel, this is a good fit for MapReduce.The
InputSplitcontains all the knowledge of where the sources are and how much of each source is going to be read. The framework uses the location information to help determine where to assign the map task. A customInputSplitmust also implement theWritableinterface, because the framework uses the methods of this interface to transmit the input split information to a TaskTracker. The number of map tasks distributed among TaskTrackers is equivalent to the number of input splits generated by the input format. TheInputSplitis then used to initialize aRecordReaderfor processing.The
RecordReaderuses the job configuration provided andInputSplitinformation to read key/value pairs. The implementation of this class depends on the data source being read. It sets up any connections required to read data from the external source, such as using JDBC to load from a database or creating a REST call to access a RESTful service.

Consequences
Data is loaded from the external source into the MapReduce job and the map phase doesn’t know or care where that data came from.
Performance analysis
The bottleneck for a MapReduce job implementing this pattern is going to be the source or the network. The source may not scale well with multiple connections (e.g., a single-threaded SQL database isn’t going to like 1,000 mappers all grabbing data at once). Another problem may be the network infrastructure. Given that the source is probably not in the MapReduce cluster’s network backplane, the connections may be reaching out on a single connection on a slower public network. This should not be a problem if the source is inside the cluster.
External Source Input Example
Reading from Redis Instances
This example demonstrates how to read data we just wrote to Redis. Again, we take in a CSV list of Redis instance hosts in order to connect to and read all the data from the hash. Since we distributed the data across a number of Redis instances, this data can be read in parallel. All we need to do is create a map task for each Redis instance, connect to Redis, and then create key/value pairs out of all the data we retrieve. This example uses the identity mapper to simply output each key/value pair received from Redis.
The sections below with its corresponding code explain the following problem.
Problem: Given a list of Redis instances in CSV format, read all the data stored in a configured hash in parallel.
InputSplit code
The RedisInputSplit
represents the data to be processed by an individual Mapper. In
this example, we store the Redis instance hostname as the location
of the input split, as well as the hash key. The input split
implements the Writable
interface, so that it is serializable by the framework, and includes
a default constructor in order for the framework to create a new
instance via reflection. We return the location via the getLocations method, in the hopes that the
JobTracker will assign each map task to a TaskTracker that is
hosting the data.
publicstaticclassRedisHashInputSplitextendsInputSplitimplementsWritable{privateStringlocation=null;privateStringhashKey=null;publicRedisHashInputSplit(){// Default constructor for reflection}publicRedisHashInputSplit(StringredisHost,Stringhash){this.location=redisHost;this.hashKey=hash;}publicStringgetHashKey(){returnthis.hashKey;}publicvoidreadFields(DataInputin)throwsIOException{this.location=in.readUTF();this.hashKey=in.readUTF();}publicvoidwrite(DataOutputout)throwsIOException{out.writeUTF(location);out.writeUTF(hashKey);}publiclonggetLength()throwsIOException,InterruptedException{return0;}publicString[]getLocations()throwsIOException,InterruptedException{returnnewString[]{location};}}
InputFormat code
The RedisHashInputFormat
mirrors that of the RedisHashOutputFormat in many ways. It
contains configuration variables to know which Redis instances to
connect to and which hash to read from. In the getSplits method, the configuration is
verified and a number of RedisHashInputSplits is created based on
the number of Redis hosts. This will create one map task for each
configured Redis instance. The Redis hostname and hash key are
stored in the input split in order to be retrieved later by the
RedisHashRecordReader. The
createRecordReader method is
called by the framework to get a new instance of a record reader.
The record reader’s initialize
method is called by the framework, so we can just create a new
instance and return it. Again by convention, this class contains two
nested classes for the record reader and input split
implementations.
publicstaticclassRedisHashInputFormatextendsInputFormat<Text,Text>{publicstaticfinalStringREDIS_HOSTS_CONF="mapred.redishashinputformat.hosts";publicstaticfinalStringREDIS_HASH_KEY_CONF="mapred.redishashinputformat.key";privatestaticfinalLoggerLOG=Logger.getLogger(RedisHashInputFormat.class);publicstaticvoidsetRedisHosts(Jobjob,Stringhosts){job.getConfiguration().set(REDIS_HOSTS_CONF,hosts);}publicstaticvoidsetRedisHashKey(Jobjob,StringhashKey){job.getConfiguration().set(REDIS_HASH_KEY_CONF,hashKey);}publicList<InputSplit>getSplits(JobContextjob)throwsIOException{Stringhosts=job.getConfiguration().get(REDIS_HOSTS_CONF);if(hosts==null||hosts.isEmpty()){thrownewIOException(REDIS_HOSTS_CONF+" is not set in configuration.");}StringhashKey=job.getConfiguration().get(REDIS_HASH_KEY_CONF);if(hashKey==null||hashKey.isEmpty()){thrownewIOException(REDIS_HASH_KEY_CONF+" is not set in configuration.");}// Create an input split for each hostList<InputSplit>splits=newArrayList<InputSplit>();for(Stringhost:hosts.split(",")){splits.add(newRedisHashInputSplit(host,hashKey));}LOG.info("Input splits to process: "+splits.size());returnsplits;}publicRecordReader<Text,Text>createRecordReader(InputSplitsplit,TaskAttemptContextcontext)throwsIOException,InterruptedException{returnnewRedisHashRecordReader();}publicstaticclassRedisHashRecordReaderextendsRecordReader<Text,Text>{// code in next section}publicstaticclassRedisHashInputSplitextendsInputSplitimplementsWritable{// code in next section}}
RecordReader code
The RedisHashRecordReader
is where most of the work is done. The initialize method is called by the
framework and provided with an input split we created in the input
format. Here, we get the Redis instance to connect to and the hash
key. We then connect to Redis and get the number of key/value pairs
we will be reading from Redis. The hash doesn’t have a means to
iterate or stream the data one at a time or in bulk, so we simply
pull everything over and disconnect from Redis. We store an iterator
over the entries and log some helpful statements along the
way.
In nextKeyValue, we iterate
through the map of entries one at a time and set the record reader’s
writable objects for the key and value. A return value of true informs the framework that there is a
key/value pair to process. Once we have exhausted all the key/value
pairs, false is returned so the
map task can complete.
The other methods of the record reader are used by the
framework to get the current key and value for the mapper to
process. It is worthwhile to reuse this object whenever possible.
The getProgress method is useful
for reporting gradual status to the JobTracker and should also be
reused if possible. Finally, the close method is for finalizing the
process. Since we pulled all the information and disconnected from
Redis in the initialize method,
there is nothing to do here.
publicstaticclassRedisHashRecordReaderextendsRecordReader<Text,Text>{privatestaticfinalLoggerLOG=Logger.getLogger(RedisHashRecordReader.class);privateIterator<Entry<String,String>>keyValueMapIter=null;privateTextkey=newText(),value=newText();privatefloatprocessedKVs=0,totalKVs=0;privateEntry<String,String>currentEntry=null;publicvoidinitialize(InputSplitsplit,TaskAttemptContextcontext)throwsIOException,InterruptedException{// Get the host location from the InputSplitStringhost=split.getLocations()[0];StringhashKey=((RedisHashInputSplit)split).getHashKey();LOG.info("Connecting to "+host+" and reading from "+hashKey);Jedisjedis=newJedis(host);jedis.connect();jedis.getClient().setTimeoutInfinite();// Get all the key/value pairs from the Redis instance and store// them in memorytotalKVs=jedis.hlen(hashKey);keyValueMapIter=jedis.hgetAll(hashKey).entrySet().iterator();LOG.info("Got "+totalKVs+" from "+hashKey);jedis.disconnect();}publicbooleannextKeyValue()throwsIOException,InterruptedException{// If the key/value map still has valuesif(keyValueMapIter.hasNext()){// Get the current entry and set the Text objects to the entrycurrentEntry=keyValueMapIter.next();key.set(currentEntry.getKey());value.set(currentEntry.getValue());returntrue;}else{// No more values? return false.returnfalse;}}publicTextgetCurrentKey()throwsIOException,InterruptedException{returnkey;}publicTextgetCurrentValue()throwsIOException,InterruptedException{returnvalue;}publicfloatgetProgress()throwsIOException,InterruptedException{returnprocessedKVs/totalKVs;}publicvoidclose()throwsIOException{// nothing to do here}}
Driver code
Much like the previous example’s driver, we use the public static methods provided by the
input format to modify the job configuration. Since we are just
using the identity mapper, we don’t need to set any special classes.
The number of reduce tasks is set to zero to specify that this is a
map-only job.
publicstaticvoidmain(String[]args)throwsException{Configurationconf=newConfiguration();Stringhosts=otherArgs[0];StringhashKey=otherArgs[1];PathoutputDir=newPath(otherArgs[2]);Jobjob=newJob(conf,"Redis Input");job.setJarByClass(RedisInputDriver.class);// Use the identity mapperjob.setNumReduceTasks(0);job.setInputFormatClass(RedisHashInputFormat.class);RedisHashInputFormat.setRedisHosts(job,hosts);RedisHashInputFormat.setRedisHashKey(job,hashKey);job.setOutputFormatClass(TextOutputFormat.class);TextOutputFormat.setOutputPath(job,outputDir);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);System.exit(job.waitForCompletion(true)?0:3);}
Partition Pruning
Pattern Description
Partition pruning configures the way the framework picks input splits and drops files from being loaded into MapReduce based on the name of the file.
Intent
You have a set of data that is partitioned by a predetermined value, which you can use to dynamically load the data based on what is requested by the application.
Motivation
Typically, all the data loaded into a MapReduce job is assigned into map tasks and read in parallel. If entire files are going to be thrown out based on the query, loading all of the files is a large waste of processing time. By partitioning the data by a common value, you can avoid significant amounts of processing time by looking only where the data would exist. For example, if you are commonly analyzing data based on date ranges, partitioning your data by date will make it so you only need to load the data inside of that range.
The added caveat to this pattern is this should be handled transparently, so you can run the same MapReduce job over and over again, but over different data sets. This is done by simply changing the data you are querying for, rather than changing the implementation of the job. A great way to do this would be to strip away how the data is stored on the file system and instead put it inside an input format. The input format knows where to locate and get the data, allowing the number of map tasks generated to change based on the query.
Tip
This is exceptionally useful if the data storage is volatile and likely to change. If you have dozens of analytics using some type of partitioned input format, you can change the input format implementation and simply recompile all analytics using the new input format code. Since all your analytics get input from a query rather than a file, you don’t need to re-implement how the data is read into the analytic. This can save a massive amount of development time, making you look really good to your boss!
Structure
Figure 7-4 shows the structure for partition pruning, explained below.
The
InputFormatis where this pattern comes to life. ThegetSplitsmethod is where we pay special attention, because it determines the input splits that will be created, and thus the number of map tasks. While the configuration is typically a set of files, configuration turns into more of a query than a set of file paths. For instance, if data is stored on a file system by date, theInputFormatcan accept a date range as input, then determine which folders to pull into the MapReduce job. If data is sharded in an external service by date, say 12 shards for each month, only one shard needs to be read by the MapReduce job when looking for data in March. The key here is that the input format determines where the data comes from based on a query, rather than passing in a set of files.The
RecordReaderimplementation depends on how the data is being stored. If it is a file-based input, something like aLineRecordReadercan be used to read key/value pairs from a file. If it is an external source, you’ll have to customize something more to your needs.

Consequences
Partition pruning changes only the amount of data that is read by the MapReduce job, not the eventual outcome of the analytic. The main reason for partition pruning is to reduce the overall processing time to read in data. This is done by ignoring input that will not produce any output before it even gets to a map task.
Resemblances
- SQL
Many modern relational databases handle partition pruning transparently. When you create the table, you specify how the database should partition the data and the database will handle the rest on inserts. Hive also supports partitioning.
CREATETABLEparted_data(foo_dateDATE)PARTITIONBYRANGE(foo_date)(PARTITIONfoo_2012VALUESLESSTHAN(TO_DATE('01/01/2013','DD/MM/YYYY')),PARTITIONfoo_2011VALUESLESSTHAN(TO_DATE('01/01/2012','DD/MM/YYYY')),PARTITIONfoo_2010VALUESLESSTHAN(TO_DATE('01/01/2011','DD/MM/YYYY')),);Then, when you query with a specific value in the
WHEREclause, the database will automatically use only the relevant partitions.SELECT*FROMparted_dataWHEREfoo_date=TO_DATE('01/31/2012');
Performance analysis
The data in this pattern is loaded into each map task is as fast as in any other pattern. Only the number of tasks changes based on the query at hand. Utilizing this pattern can provide massive gains by reducing the number of tasks that need to be created that would not have generated output anyways. Outside of the I/O, the performance depends on the other pattern being applied in the map and reduce phases of the job.
Partition Pruning Examples
Partitioning by last access date to Redis instances
This example demonstrates a smarter way to store and read data in Redis. Rather than randomly distributing the user-to-reputation mappings, we can partition this data on particular criteria. The user-to-reputation mappings are partitioned based on last access date and stored in six different Redis instances. Two months of data are stored in separate hashes on each Redis instance. That is, January and February are stored in different hashes on Redis instance 0, March and April on instance 1, and so on.
By distributing the data in this manner, we can more intelligently read it based on a user query. Whereas the previous examples took in a list of Redis instances and a hash key via the command line, this pattern hardcodes all the logic of where and how to store the data in the output format, as well as in the input format. This completely strips away knowledge from the mapper and reducer of where the data is coming from, which has its advantages and disadvantages for a developer using our input and output formats.
Caution
It may not be the best idea to actually hardcode information into the Java code itself, but instead have a rarely-changing configuration file that can be found by your formats. This way, things can still be changed if necessary and prevent a recompile. Environment variables work nicely, or it can just be passed in via the command line.
The sections below with its corresponding code explain the following problem.
Problem: Given a set of user data, partition the user-to-reputation mappings by last access date across six Redis instances.
Custom WritableComparable code
To help better store information, a custom WritableComparable is implemented in order
to allow the mapper to set information needed by the record writer.
This class contains methods to set and get the field name to be
stored in Redis, as well as the last access month. The last access
month accepts a zero-based integer value for the month, but is later
turned into a string representation for easier querying in the next
example. Take the time to implement the compareTo, toString, and hashCode methods (like every good Java
developer!).
publicstaticclassRedisKeyimplementsWritableComparable<RedisKey>{privateintlastAccessMonth=0;privateTextfield=newText();publicintgetLastAccessMonth(){returnthis.lastAccessMonth;}publicvoidsetLastAccessMonth(intlastAccessMonth){this.lastAccessMonth=lastAccessMonth;}publicTextgetField(){returnthis.field;}publicvoidsetField(Stringfield){this.field.set(field);}publicvoidreadFields(DataInputin)throwsIOException{lastAccessMonth=in.readInt();this.field.readFields(in);}publicvoidwrite(DataOutputout)throwsIOException{out.writeInt(lastAccessMonth);this.field.write(out);}publicintcompareTo(RedisKeyrhs){if(this.lastAccessMonth==rhs.getLastAccessMonth()){returnthis.field.compareTo(rhs.getField());}else{returnthis.lastAccessMonth<rhs.getLastAccessMonth()?-1:1;}}publicStringtoString(){returnthis.lastAccessMonth+" "+this.field.toString();}publicinthashCode(){returntoString().hashCode();}}
OutputFormat code
This output format is extremely basic, as all the grunt work is handled in
the record writer. The main thing to focus on is the templated
arguments when extending the OutputFormat
class. This output format accepts our custom class as the output key
and a Text object as the output
value. Any other classes will cause errors when trying to write any
output.
Since our record writer implementation is coded to a specific
and known output, there is no need to verify any output
specification of the job. An output committer is still required by
the framework, so we use NullOutputFormat’s
output committer.
publicstaticclassRedisLastAccessOutputFormatextendsOutputFormat<RedisKey,Text>{publicRecordWriter<RedisKey,Text>getRecordWriter(TaskAttemptContextjob)throwsIOException,InterruptedException{returnnewRedisLastAccessRecordWriter();}publicvoidcheckOutputSpecs(JobContextcontext)throwsIOException,InterruptedException{}publicOutputCommittergetOutputCommitter(TaskAttemptContextcontext)throwsIOException,InterruptedException{return(newNullOutputFormat<Text,Text>()).getOutputCommitter(context);}publicstaticclassRedisLastAccessRecordWriterextendsRecordWriter<RedisKey,Text>{// Code in next section}}
RecordWriter code
The RedisLastAccessRecordWriter is templated to accept the same classes as the output
format. The construction of the class connects to all six Redis
instances and puts them in a map. This map stores the
month-to-Redis-instance mappings and is used in the write method to retrieve the proper
instance. The write method then
uses a map of month int to a three character month code for
serialization. This map is omitted for brevity, but looks something
like 0→JAN, 1→FEB, ..., 11→DEC. This means all the hashes in Redis are
named based on the three-character month code. The close method disconnects all the Redis
instances.
publicstaticclassRedisLastAccessRecordWriterextendsRecordWriter<RedisKey,Text>{privateHashMap<Integer,Jedis>jedisMap=newHashMap<Integer,Jedis>();publicRedisLastAccessRecordWriter(){// Create a connection to Redis for each hostinti=0;for(Stringhost:MRDPUtils.REDIS_INSTANCES){Jedisjedis=newJedis(host);jedis.connect();jedisMap.put(i,jedis);jedisMap.put(i+1,jedis);i+=2;}}publicvoidwrite(RedisKeykey,Textvalue)throwsIOException,InterruptedException{// Get the Jedis instance that this key/value pair will be// written to -- (0,1)->0, (2-3)->1, ... , (10-11)->5Jedisj=jedisMap.get(key.getLastAccessMonth());// Write the key/value pairj.hset(MONTH_FROM_INT.get(key.getLastAccessMonth()),key.getField().toString(),value.toString());}publicvoidclose(TaskAttemptContextcontext)throwsIOException,InterruptedException{// For each jedis instance, disconnect itfor(Jedisjedis:jedisMap.values()){jedis.disconnect();}}}
Mapper code
The mapper code parses each input record and sets the values
for the output RedisKey and the
output value. The month of the last access data is parsed via the
Calendar and SimpleDateFormat classes.
publicstaticclassRedisLastAccessOutputMapperextendsMapper<Object,Text,RedisKey,Text>{// This object will format the creation date string into a Date objectprivatefinalstaticSimpleDateFormatfrmt=newSimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS");privateRedisKeyoutkey=newRedisKey();privateTextoutvalue=newText();publicvoidmap(Objectkey,Textvalue,Contextcontext)throwsIOException,InterruptedException{Map<String,String>parsed=MRDPUtils.transformXmlToMap(value.toString());StringuserId=parsed.get("Id");Stringreputation=parsed.get("Reputation");// Grab the last access dateStringstrDate=parsed.get("LastAccessDate");// Parse the string into a Calendar objectCalendarcal=Calendar.getInstance();cal.setTime(frmt.parse(strDate));// Set our output key and valuesoutkey.setLastAccessMonth(cal.get(Calendar.MONTH));outkey.setField(userId);outvalue.set(reputation);context.write(outkey,outvalue);}}
Driver code
The driver looks very similar to a more basic job configuration. All the special configuration is entirely handled by the output format class and record writer.
publicstaticvoidmain(String[]args)throwsException{Configurationconf=newConfiguration();PathinputPath=newPath(args[0]);Jobjob=newJob(conf,"Redis Last Access Output");job.setJarByClass(PartitionPruningOutputDriver.class);job.setMapperClass(RedisLastAccessOutputMapper.class);job.setNumReduceTasks(0);job.setInputFormatClass(TextInputFormat.class);TextInputFormat.setInputPaths(job,inputPath);job.setOutputFormatClass(RedisHashSetOutputFormat.class);job.setOutputKeyClass(RedisKey.class);job.setOutputValueClass(Text.class);intcode=job.waitForCompletion(true)?0:2;System.exit(code);}
Querying for user reputation by last access date
This example demonstrates how to query for the information we just stored in Redis. Unlike most examples, where you provide some path to files in HDFS, we instead just pass in the months of data we want. Figuring out where to get the data is entirely handled intelligently by the input format.
The heart of partition pruning is to avoid reading data that you don’t have to read. By storing the user-to-reputation mappings across six different Redis servers, we need to connect only to the instances that are hosting the requested month’s data. Even better, we need to read only from the hashes that are holding the specific month. For instance, passing in “JAN,FEB,MAR,NOV” on the command line will create three input splits, one for each Redis instance hosting the data (0, 1, and 5). All the data on Redis instance 0 will be read, but only the first months on Redis instances 1 and 5 will be pulled. This is much better than having to connect to all the desired instances and read all the data, only to throw most of it away!
The sections below with its corresponding code explain the following problem.
Problem: Given a query for user to reputation mappings by months, read only the data required to satisfy the query in parallel.
InputSplit code
The input split shown here is very similar to the input split in External Source Input Example. Instead of storing one hash key, we are going to store multiple hash keys. This is because the data is partitioned based on month, instead of all the data being randomly distributed in one hash.
publicstaticclassRedisLastAccessInputSplitextendsInputSplitimplementsWritable{privateStringlocation=null;privateList<String>hashKeys=newArrayList<String>();publicRedisLastAccessInputSplit(){// Default constructor for reflection}publicRedisLastAccessInputSplit(StringredisHost){this.location=redisHost;}publicvoidaddHashKey(Stringkey){hashKeys.add(key);}publicvoidremoveHashKey(Stringkey){hashKeys.remove(key);}publicList<String>getHashKeys(){returnhashKeys;}publicvoidreadFields(DataInputin)throwsIOException{location=in.readUTF();intnumKeys=in.readInt();hashKeys.clear();for(inti=0;i<numKeys;++i){hashKeys.add(in.readUTF());}}publicvoidwrite(DataOutputout)throwsIOException{out.writeUTF(location);out.writeInt(hashKeys.size());for(Stringkey:hashKeys){out.writeUTF(key);}}publiclonggetLength()throwsIOException,InterruptedException{return0;}publicString[]getLocations()throwsIOException,InterruptedException{returnnewString[]{location};}}
InputFormat code
This input format class intelligently creates RedisLastAccessInputSplit objects from the
selected months of data. Much like the output format we showed
earlier in OutputFormat code, this output
format writes RedisKey objects,
this input format reads the same objects and is templated to enforce
this on mapper implementations. It initially creates a hash map of
host-to-input splits in order to add the hash keys to the input
split, rather than adding both months of data to the same split. If
a split has not been created for a particular month, a new one is
created and the month hash key is added. Otherwise, the hash key is
added to the split that has already been created. A List is then created out of the values
stored in the map. This will create a number of input splits
equivalent to the number of Redis instances required to satisfy the
query.
There are a number of helpful hash maps to help convert a
month string to an integer, as well as figure out which Redis
instance hosts which month of data. The initialization of these hash
maps are ommitted from the static
block for brevity.
publicstaticclassRedisLastAccessInputFormatextendsInputFormat<RedisKey,Text>{publicstaticfinalStringREDIS_SELECTED_MONTHS_CONF="mapred.redilastaccessinputformat.months";privatestaticfinalHashMap<String,Integer>MONTH_FROM_STRING=newHashMap<String,Integer>();privatestaticfinalHashMap<String,String>MONTH_TO_INST_MAP=newHashMap<String,String>();privatestaticfinalLoggerLOG=Logger.getLogger(RedisLastAccessInputFormat.class);static{// Initialize month to Redis instance map// Initialize month 3 character code to integer}publicstaticvoidsetRedisLastAccessMonths(Jobjob,Stringmonths){job.getConfiguration().set(REDIS_SELECTED_MONTHS_CONF,months);}publicList<InputSplit>getSplits(JobContextjob)throwsIOException{Stringmonths=job.getConfiguration().get(REDIS_SELECTED_MONTHS_CONF);if(months==null||months.isEmpty()){thrownewIOException(REDIS_SELECTED_MONTHS_CONF+" is null or empty.");}// Create input splits from the input monthsHashMap<String,RedisLastAccessInputSplit>instanceToSplitMap=newHashMap<String,RedisLastAccessInputSplit>();for(Stringmonth:months.split(",")){Stringhost=MONTH_TO_INST_MAP.get(month);RedisLastAccessInputSplitsplit=instanceToSplitMap.get(host);if(split==null){split=newRedisLastAccessInputSplit(host);split.addHashKey(month);instanceToSplitMap.put(host,split);}else{split.addHashKey(month);}}LOG.info("Input splits to process: "+instanceToSplitMap.values().size());returnnewArrayList<InputSplit>(instanceToSplitMap.values());}publicRecordReader<RedisKey,Text>createRecordReader(InputSplitsplit,TaskAttemptContextcontext)throwsIOException,InterruptedException{returnnewRedisLastAccessRecordReader();}publicstaticclassRedisLastAccessRecordReaderextendsRecordReader<RedisKey,Text>{// Code in next section}}
RecordReader code
The RedisLastAccessRecordReader is a
bit more complicated than the other record readers we
have seen. It needs to read from multiple hashes, rather than just
reading everything at once in the initialize method. Here, the configuration
is simply read in this method.
In nextKeyValue, a new
connection to Redis is created if the iterator through the hash is
null, or if we have reached the end of all the hashes to read. If
the iterator through the hashes does not have a next value, we
immediately return false, as
there is no more data for the map task. Otherwise, we connect to
Redis and pull all the data from the specific hash. The hash
iterator is then used to exhaust all the field value pairs from
Redis. A do-while loop is used to ensure that once a hash iterator
is complete, it will loop back around to get data from the next hash
or inform the task there is no more data to be read.
The implementation of the remaining methods are identical to
that of the RedisHashRecordReader
and are omitted.
publicstaticclassRedisLastAccessRecordReaderextendsRecordReader<RedisKey,Text>{privatestaticfinalLoggerLOG=Logger.getLogger(RedisLastAccessRecordReader.class);privateEntry<String,String>currentEntry=null;privatefloatprocessedKVs=0,totalKVs=0;privateintcurrentHashMonth=0;privateIterator<Entry<String,String>>hashIterator=null;privateIterator<String>hashKeys=null;privateRedisKeykey=newRedisKey();privateStringhost=null;privateTextvalue=newText();publicvoidinitialize(InputSplitsplit,TaskAttemptContextcontext)throwsIOException,InterruptedException{// Get the host location from the InputSplithost=split.getLocations()[0];// Get an iterator of all the hash keys we want to readhashKeys=((RedisLastAccessInputSplit)split).getHashKeys().iterator();LOG.info("Connecting to "+host);}publicbooleannextKeyValue()throwsIOException,InterruptedException{booleannextHashKey=false;do{// if this is the first call or the iterator does not have a// nextif(hashIterator==null||!hashIterator.hasNext()){// if we have reached the end of our hash keys, return// falseif(!hashKeys.hasNext()){// ultimate end condition, return falsereturnfalse;}else{// Otherwise, connect to Redis and get all// the name/value pairs for this hash keyJedisjedis=newJedis(host);jedis.connect();StringstrKey=hashKeys.next();currentHashMonth=MONTH_FROM_STRING.get(strKey);hashIterator=jedis.hgetAll(strKey).entrySet().iterator();jedis.disconnect();}}// If the key/value map still has valuesif(hashIterator.hasNext()){// Get the current entry and set// the Text objects to the entrycurrentEntry=hashIterator.next();key.setLastAccessMonth(currentHashMonth);key.setField(currentEntry.getKey());value.set(currentEntry.getValue());}else{nextHashKey=true;}}while(nextHashKey);returntrue;}...}
Driver code
The driver code sets the months most recently accessed passed in via the command line. This configuration parameter is used by the input format to determine which Redis instances to read from, rather than reading from every Redis instance. It also sets the output directory for the job. Again, it uses the identity mapper rather than performing any analysis on the data retrieved.
publicstaticvoidmain(String[]args)throwsException{Configurationconf=newConfiguration();StringlastAccessMonths=args[0];PathoutputDir=newPath(args[1]);Jobjob=newJob(conf,"Redis Input");job.setJarByClass(PartitionPruningInputDriver.class);// Use the identity mapperjob.setNumReduceTasks(0);job.setInputFormatClass(RedisLastAccessInputFormat.class);RedisLastAccessInputFormat.setRedisLastAccessMonths(job,lastAccessMonths);job.setOutputFormatClass(TextOutputFormat.class);TextOutputFormat.setOutputPath(job,outputDir);job.setOutputKeyClass(RedisKey.class);job.setOutputValueClass(Text.class);System.exit(job.waitForCompletion(true)?0:2);}