
Chapter 9. Strategies for Ubiquitous Deployment
In today’s market, enterprises need the flexibility to migrate, expand, and burst their storage and compute capacity both on-premises and in the cloud. As companies move to the cloud, the ability to span on-premises and cloud deployments remains a critical enterprise enabler. In this chapter, we take a look at hybrid cloud strategies.
Introduction to the Hybrid Cloud Model
Hybrid cloud generally refers to a combination of deployments across traditional on-premises infrastructure and public cloud infrastructure. Given the relatively new deployment options available, this can lead to a host of questions about more specific definitions. We will use the following broad terms to delineate.
Single Application Stack
In this model, different parts of the entire architecture will span across on-premises and cloud into a single application stack, as depicted in Figure 9-1. For example, the database might reside in a corporate datacenter, but the business intelligence (BI) layer might reside on the cloud. The BI application in the cloud will issue queries to the on-premises database, which will return results back to the cloud.
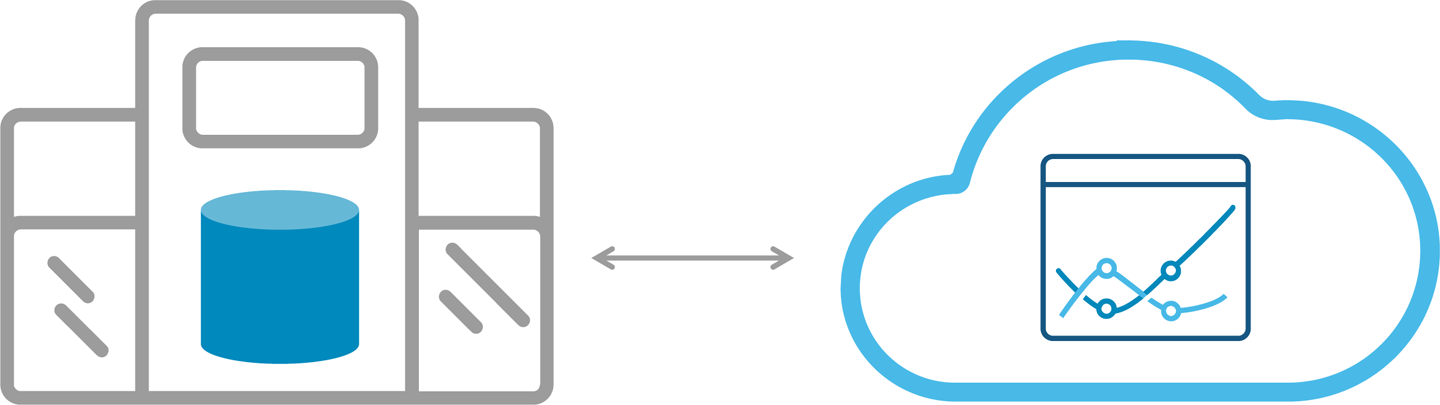
Figure 9-1. Single application stack hybrid deployment
Use Case-Centric
Figure 9-2 shows a use case-centric scenario in which different elements of the application might reside across on-premises and the cloud, depending on the need. Common examples are having the primary database on-premises and a backup or disaster recovery replica, located in the cloud. Other options in this model include test and development, which might reside in the cloud for quick spin up and adjustments, but later production deployments reside on-premises.
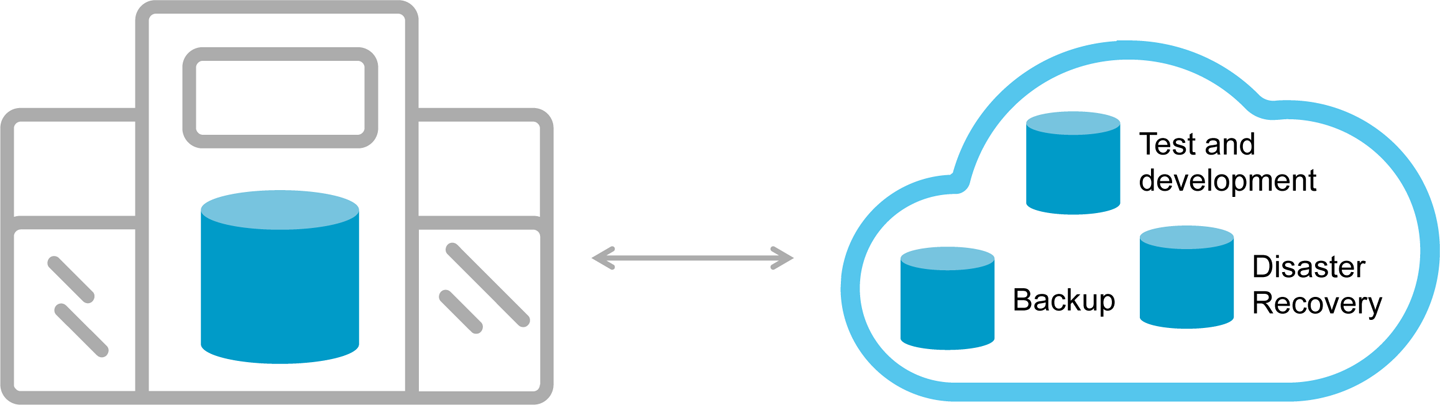
Figure 9-2. Use-case centric hybrid cloud deployment
Multicloud
The multicloud approach (Figure 9-3) takes the two prior deployment models and extends them to multiple clouds. This is likely the direction for a majority of the industry, because few companies will want to put all of their efforts into one cloud provider. With a combination of on-premises and multicloud flexibility, businesses have all the necessary tools at their disposal.
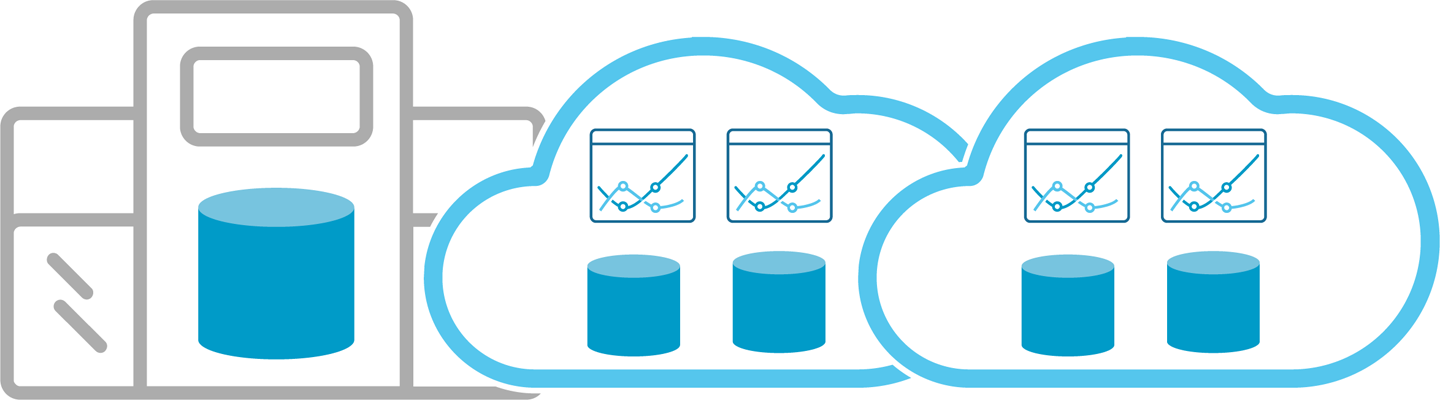
Figure 9-3. Multicloud deployment approach
On-Premises Flexibility
Many sensitive workloads require an on-premises deployment. When large amounts of data are produced locally, such as for manufacturing analytics, an on-premises model often makes sense.
However, on-premises deployments must remain compatible with cloud deployments, therefore requiring similar architectural foundations.
When considering an on-premises deployment, your solutions also need to be able to do the following:
-
Run on any industry standard hardware, allowing architects to choose the CPU, memory, flash, and disk options that suit their needs.
-
Run on any standard Linux platform for flexibility across environments in large organizations.
-
Enable NUMA optimization, so scale-up, multicore servers can be put to full use.
-
Use Advanced Vector Extensions (AVX) optimizations, to take advantage of the latest Intel and AMD features.
-
Be virtual machine–ready, and be able to run with local or remote storage.
-
Be container-ready, which is ideal for development and testing. Running stateful systems like databases within containers for production workloads is still an emerging area.
-
Suited to using orchestration tools for smooth deployments.
Together these characteristics make datastore choices suitable for both on-premises and cloud.
Hybrid Cloud Deployments
Most new datastore deployments will need to span from on-premises to the cloud. Making use of hybrid architectures begins with the simplicity of the replicate database command. Specifically the ability to replicate a database from one cluster to another, preferably with a single command. In more flexible implementations, the two clusters do not need to be the same unit count. However, the receiving cluster must have enough capacity to absorb the data being replicated to it.
High Availability and Disaster Recovery in the Cloud
Robust datastores replicate data locally within a single cluster across multiple nodes for instant high availability, but additional layers of availability, including disaster recovery, can be deployed by replicating the database to the cloud.
Test and Development
Other cloud uses include test and development where data architects can rapidly deploy clusters to test a variety of workloads. Experiments can be run to determine the advantages of one instance type over another. Ultimately those deployments can migrate on-premises with much of the heavy lifting already accomplished.
Multicloud
The multicloud approach combines elements of on-premises and hybrid cloud, and extend those models to multiple public cloud providers. For example, you might use Amazon QuickSight, the Amazon Web Services BI layer, to query data in another database on Microsoft Azure or Google Compute Platform. Although this is just a hypothetical example, the prevailing direction is independence to use a variety of services and infrastructure layers across public cloud providers.
Today’s cloud directions are dominated by on-premises-to-cloud discussions; multicloud is the next evolution as companies seek to prevent themselves from being stuck in one “silo.”
When companies are able to move fluidly between cloud providers, they derive the following benefits:
-
Pricing leverage
-
No single source reliance
-
An expanded potential footprint across more datacenters
-
Better reach internationally
Multicloud also presents challenges when the intent is a single application stack. Automated deployments as well as security might differ between providers. Further, the incentives for cloud providers to work together on interoperability are not present, making technical challenges more difficult to solve.
Charting an On-Premises-to-Cloud Security Plan
One oft-cited reason against moving to the cloud is the lack of an appropriate security model. Understandably, companies want to have this model in place before moving to the cloud.
Common Security Requirements
Following are some of the common security-related issues that you must address:
-
Encryption
-
Audit logging
-
Role-based access control
-
Protection against insider threat
Encryption
Encryption can be implemented at different layers, but common solutions in the data processing world include offerings like Navencrypt or Vormetric.
Audit logging
Audit logging takes all database activity and writes the generated logs to an external location. Many logging levels are available, and each level provides limited or exhaustive information about user actions and database responses. This capability is useful for performing common information security tasks such as auditing, investigating suspicious activity, and validating access control policies.
Role-based access control is essential to database security
Role-based access control (RBAC) provides a methodology for regulating an individual user’s access to information systems or network resources based on their role in an organization. RBAC enables security teams to efficiently create, change, or discontinue roles as the unique needs of an organization evolve over time, without having to endure the hardship of updating the privileges of individual users.
Protecting against insider threat
Whether a large government agency or commercial company, protecting your data is critical to successful operations. A data breach can cause significant amounts of lost revenue, a tarnished brand, as well as diminished customer loyalty. For government agencies, the consequences can be more severe.
Here are three critical pillars to securing your data in a database:
-
Separation of administrative duties
-
Data confidentially, integrity, and availability
-
360-degree view of all database activity
Separation of administrative duties
The primary goal here is to disintermediate the database administrator (DBA) from the data. Central to this is to not allow a DBA to grant themself privileges without approval by a second administrator. There also should be special application-specific DBAs separate from operations and maintenance administrators. The developers and users should not be able to execute DBA tasks. This can all be done by setting up the following recommended roles.
At the organization level:
- Compliance officer
-
-
Manages all role permissions
-
Most activity occurs at the beginning project stages
-
Shared resource across the organization
-
- Security officer
-
-
Manages groups, users, passwords in the datastore
-
Most activity occurs at the beginning project stages
-
Shared resource across the organization
-
At the project level:
- Datastore maintenance and operations DBA
-
-
Minimal privileges to operate, maintain, and run the datastore
-
Can be shared resource across projects
-
- DBA per database application (application DBA)
-
-
Database and schema owner
-
Does not have permissions to view the data
-
- Developer/user per database application
-
-
Read and write data as permitted by the application DBA
-
Does not have permission to modify database
-
After the roles and groups are established, you assign users to these groups. You can then set up row-level table access filtered by the user’s identity to restrict content access at the row level. For example, a agency might want to restrict user access to data marked at higher government classification levels (e.g., Top Secret) than their clearance level allows.
Too frequently, data architects have had to compromise on security for select applications. With the proper architecture, you can achieve real-time performance and distributed SQL operations while maintaining the utmost in security controls.