
Chapter 8 Tracking Down Web Servers, Login Portals, and Network Hardware
Solutions in this chapter:
 Locating and Profiling Web Servers
Locating and Profiling Web Servers- Locating Login Portals
- Locating Other Network Hardware
- Using and Locating Various Web Utilities
- Targeting Web-Enabled Network Devices
Introduction
Penetration (pen) testers are sometimes thought of as professional hackers since they essentially break into their customers’ networks in an attempt to locate, document, and ultimately help resolve security flaws in a system or network. However, pen testers and hackers differ quite a bit in several ways.
For example, most penetration testers are provided with specific instructions about which networks and systems they will be testing. Their targets are specified for many reasons, but in all cases, their targets are clearly defined or bounded in some fashion. Hackers, on the other hand, have the luxury of selecting from a wider target base. Depending on his or her motivations and skill level, the attacker might opt to select a target based on known exploits at his disposal. This reverses the model used by pen testers, and as such it affects the structure we will use to explore the topic of Google hacking. The techniques we’ll explore in the next few chapters are most often employed by hackers—the “bad guys.”
Penetration testers have access to the techniques we’ll explore in these chapters, but in many cases these techniques are too cumbersome for use during a vulnerability assessment, when time is of the essence. Security professionals often use specialized tools that perform these tasks in a much more streamlined fashion, but these tools make lots of noise and often overlook the simplest form of information leakage that Google is so capable of revealing—and revealing in a way that’s nearly impossible to catch on the “radar.” The techniques we’ll examine here are used on a daily basis to locate and explore the systems and networks attached to the Internet, so it’s important that we explore how these techniques are used to better understand the level of exposure and how that exposure can be properly mitigated.
The techniques we explore in this chapter are used to locate and analyze the front-end systems on an Internet-connected network. We look at ways an attacker can profile Web servers using seemingly insignificant clues found with Google queries. Next, we’ll look at methods used to locate login portals, the literal front door of most Web sites. As we will see, some login portals provide administrators of a system an access point for performing various administrative functions. Most login portals provide clues to an attacker about what software is in use on the server, and act as a magnet, drawing attackers that are armed with an exploit for that particular type of software. We round out the chapter by showing techniques that can be used to locate all sorts of network devices—firewalls, routers, network printers, and even Web cameras.
Locating and Profiling Web Servers
If an attacker hasn’t already decided on a target, he might begin with a Google search for specific targets that match an exploit at his disposal. He might focus specifically on the operating system, the version and brand of Web server software, default configurations, vulnerable scripts, or any combination of factors.
There are many different ways to locate a server. The most common way is with a simple portscan. Using a tool such as Nmap, a simple scan of port 80 across a class C network will expose potential Web servers. Integrated tools such as Nessus, H.E.A.T., or Retina will run some type of portscan, followed by a series of security tests. These functions can be replicated with Google queries, although in most cases the results are nowhere near as effective as the results from a well thought out vulnerability scanner or Web assessment tool. Remember, though, that Google queries are less obvious and provide a degree of separation between an attacker and a target. Also remember that hackers can use Google hacking techniques to find systems you may be charged with protecting. The bottom line is that it’s important to understand the capabilities of the Google hacker and realize the role Google can play in an attacker’s methodology.
Directory Listings
We discussed directory listings in Chapter 3, but the importance of directory listings with regard to profiling methods is important. The server tag at the bottom of a directory listing can provide explicit detail about the type of Web server software that’s running. If an attacker has an exploit for Apache 2.0.52 running on a UNIX server, a query such as server.at"Apache/2.0.52” will locate servers that host a directory listing with an Apache 2.0.52 server tag, as shown in Figure 8.1.

Remember to always check the real page (as opposed to the cached page), because server version numbers could change between crawls.
Not all Web servers place this tag at the bottom of directory listings, but most Apache derivatives turn on this feature by default. Other platforms, such as Microsoft’s Internet Information Server (IIS), display server tags as well, as a query for “Microsoft-IIS/5.0 server at” shows in Figure 8.2.
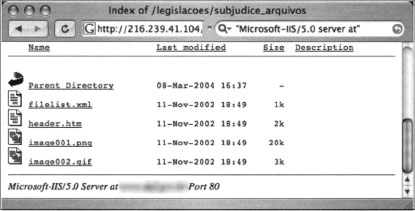
When searching for these directory tags, keep in mind that your syntax is very important. There are many irrelevant results from a query for “Microsoft-IIS/6.0” “server at”, whereas a query like “Microsoft-IIS/6.0 server at” provides very relevant results. Since we’ve already covered directory listings, we won’t dwell on it here. Refer back to Chapter 3 if you need a refresher on directory listings.
Web Server Software Error Messages
Error messages contain a lot of useful information, but in the context of locating specific servers, we can use portions of various error messages to locate servers running specific software versions. We’ll begin our discussion by looking at error messages that are generated by the Web server software itself.
Microsoft IIS
The absolute best way to find error messages is to figure out what messages the server is capable of generating. You could gather these messages by examining the server source code or configuration files or by actually generating the errors on the server yourself. The best way to get this information from IIS is by examining the source code of the error pages themselves.
IIS 5.0 and 6.0, by default, display static Hypertext Transfer Protocol (HTTP)/1.1 error messages when the server encounters some sort of problem. These error pages are stored by default in the %SYSTEMROOT%helpiisHelpcommon directory. These files are essentially Hypertext Markup language (HTML) files named by the type of error they produce, such as 400.htm, 401–1.htm, 501.htm, and so on. By analyzing these files, we can come up with trends and commonalities between the pages that are essential for effective Google searching. For example, the file that produces 400 error pages, 400.htm, contains a line (line 12) that looks like this:
This is a dead giveaway for an effective intitle query such as intitle:” “The page cannot be found”. Unfortunately, this search yields (as you might guess) far too many results. We’ll need to dig deeper into the 400.htm file to get more clues about what to look for. Lines 65–88 of 400.htm are shown here:

The phrase “Please try the following” in line 65 exists in every single error file in this directory, making it a perfect candidate for part of a good base search. This line could effectively be reduced to “please * * following.” Line 88 shows another phrase that appears in every error document; “Internet Information Services,” These are “golden terms” to use to search for IIS HTTP/1.1 error pages that Google has crawled. A query such as intitle: “The page cannot be found” “please * * following” “Internet * Services” can be used to search for IIS servers that present a 400 error page, as shown in Figure 8.3.
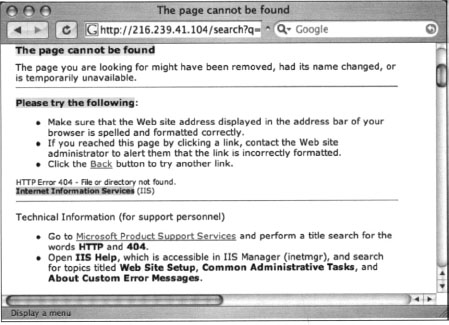
Looking at this cached page carefully, you’ll notice that the actual error code itself is printed on the page, about halfway down. This error line is also printed on each of IIS’s error pages, making for another good limiter for our searching. The line on the page begins with “HTTP Error 404,” which might seem out of place, considering we were searching for a 400 error code, not a 404 error code. This occurs because several IIS error pages produce similar pages. Although commonalities are often good for Google searching, they could lead to some confusion and produce ineffective results if we are searching for a specific, less benign error page. It’s obvious that we’ll need to sort out exactly what’s what in these error page files. Table 8.1 lists all the unique HTML error page titles and error codes from a default IIS 5 installation.
Table 8.1 IIS HTTP/1.1 Error Page Titles
| Error Code | Page Title |
|---|---|
| 400 | The page cannot be found |
| 401.1, 401.2, 401.3, 401.4, 401.5 | You are not authorized to view this page |
| 403.1, 403.2 | The page cannot be displayed |
| 403.3 | The page cannot be saved |
| 403.4 | The page must be viewed over a secure channel |
| 403.5 Web browser | The page must be viewed with a high-security |
| 403.6 | You are not authorized to view this page |
| 403.7 | The page requires a client certificate |
| 403.8 | You are not authorized to view this page |
| 403.9 | The page cannot be displayed |
| 403.10, 403.11 | You are not authorized to view this page |
| 403.12, 403.13 | The page requires a valid client certificate |
| 403.15 | The page cannot be displayed |
| 403.16, 403.17 | The page requires a valid client certificate |
| 404.1, 404b | The Web site cannot be found |
| 405 | The page cannot be displayed |
| 406 | The resource cannot be displayed |
| 407 | Proxy authentication required |
| 410 | The page does not exist |
| 412 | The page cannot be displayed |
| 414 | The page cannot be displayed |
| 500, 500.11, 500.12, 500.13, 500.14, 500.15 | The page cannot be displayed |
| 502 | The page cannot be displayed |
These page titles, used in an intitle search, combined with the other golden IIS error searches, make for very effective searches, locating all sorts of IIS servers that generate all sorts of telling error pages. To troll for IIS servers with the esoteric 404.1 error page, try a query such as intitle: “The Web site cannot be found” “please * * following”. A more common error can be found with a query such as intitle: “The page cannot be displayed” “Internet Information Services” “please * * following”, which is very effective because this error page is shown for many different error codes.
In addition to displaying the default static HTTP/1.1 error pages, IIS can be configured to display custom error messages, configured via the Management Console. An example of this type of custom error page is shown in Figure 8.4. This type of functionality makes the job of the Google hacker a bit more difficult since there is no apparent way to home in on a customized error page. However, some error messages, including 400, 403.9, 411, 414, 500, 500.11, 500.14, 500.15, 501, 503, and 505 pages, cannot be customized. In terms of Google hacking, this means that there is no easy way an IIS 6.0 server can prevent displaying the static HTTP/1.1 error pages we so effectively found previously. This opens the door for locating these servers through Google, even if the server has been configured to display custom error pages.
Besides trolling through the IIS error pages looking for exact phrases, we can also perform more generic queries, such as intitle: “the page cannot be found” inetmgr”, which focuses on the fairly unique term used to describe the IIS Management console, inetmgr, as shown near the bottom of Figure 8.3. Other ways to perform this same search might be intitle: “the page cannot be found” “internet information services”, or intitle: “Under construction” “Internet Information Services”.
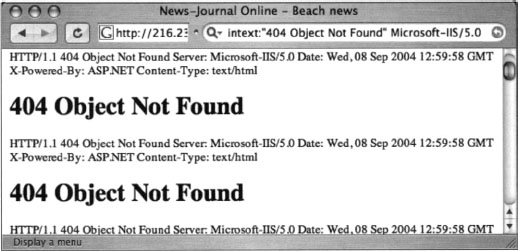
Other, more specific searches can reveal the exact version of the IIS server, such as a query for intext:” “404 Object Not Found” Microsoft-IIS/5.0, as shown in Figure 8.4.
Apache Web Server
Apache Web servers can also be located by focusing on server-generated error messages. Some generic searches such as “Apache/1.3.27 Server at” “-intitle:index.of intitle:inf” or “Apache/1.3.27 Server at” -intitle:index.of intitle:error (shown in Figure 8.5) can be used to locate servers that might be advertising their server version via an info or error message.

A query such as “Apache/2.0.40” intitle: “Object not found!” will locate Apache 2.0.40 Web servers that presented this error message. Figure 8.6 shows an error page from an Apache 2.0.40 server shipped with Red Hat 9.0.

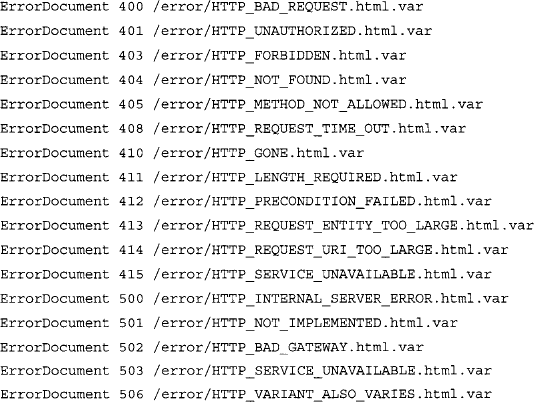
Although there might be nothing wrong with throwing queries around looking for commonalities and good base searches, we’ve already seen in the IIS section that it’s more effective to consult the server software itself for search clues. Most Apache installations rely on a configuration file called httpd.conf. Searching through Apache 2.0.40’s httpd.conf file reveals the location of the HTML templates for error messages. The referenced files (which follow) are located in the Web root directory, such as /error/http_BAD_REQUEST.html.var, which refers to the /var/wuw/error directory on the file system:
Taking a look at one of these template files, we can see recognizable HTML code and variable listings that show the construction of an error page. The file itself is divided into sections by language. The English portion of the HTTP_NOT_FOUND.html.var file is shown here:


Notice that the sections of the error page are clearly labeled, making it easy to translate into Google queries. The TITLE variable, shown near the top of the listing, indicates that the text “Object not found!” will be displayed in the browser’s title bar. When this file is processed and displayed in a Web browser, it will look like Figure 8.2. However, Google hacking is not always this easy. A search for intitle: “Object not found!” is too generic, returning the results shown in Figure 8.7.
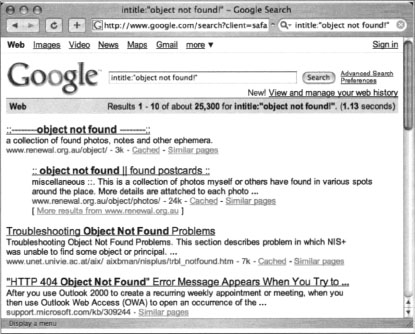
These results are not what we’re looking for. To narrow our results, we need a better base search. Constructing our base search from the template files included with the Apache 2.0 source code not only enables us to locate all the potential error messages the server is capable of producing, it also shows us how those messages are translated into other languages, resulting in very solid multilingual base searches.
The HTTP_NOT_FOUND.html.var file listed previously references two virtual include lines, one near the top (include/top.html) and one near the bottom (include/bottom.html). These lines instruct Apache to read and insert the contents of these two files (located in our case in the /var/www/error/include directory) into the current file. The following code lists the contents of the bottom.html file and show some subtleties that will help construct that perfect base search:

First, notice line 4, which will display the word “Error” on the page. Although this might seem very generic, it’s an important subtlety that would keep results like the ones in Figure 8.7 from displaying. Line 2 shows that another file (/var/www/error/contact.html.var) is read and included into this file. The contents of this file, listed as follows, contain more details that we can include into our base search:

This file, like the file that started this whole “include chain,” is broken up into sections by language. The portion of this file listed here shows yet another unique string we can use. We’ll select a fairly unique piece of this line, “think this is a server error,” as a portion of our base search instead of just the word error, which we used initially to remove some false positives. The other part of our base search, intitle: “Object not found!”, was originally found in the /error/http_BAD_REQUEST.html.var file. The final base search for this file then becomes intitle: “Object Not Found!” “think this is a server error”, which returns more accurate results, as shown in Figure 8.8.
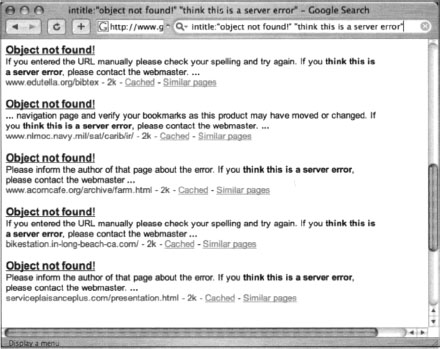
Now that we’ve found a good base search for one error page, we can automate the query-hunting process to determine good base searches for the other error pages referenced in the httpd.conf file, helping us create solid base searches for each and every default Apache (2.0) error page. The contact.html.var file that we saw previously is included in each and every Apache 2.0 error page via the bottom.html file. This means that “think this is a server error” will work for all the different error pages that Apache 2.0 will produce. The other critical element to our search was the intitle search, which we could grep for in each of the error files. While we’re at it, we should also try to grab a snippet of the text that is printed in each of the error pages, remembering that in some cases a more specific search might be needed. Using some basic shell commands, we can isolate both the title of an error page and the text that might appear on the error page:
This Linux bash shell command, when run against the Apache 2.0 source code tree, will produce output similar to that shown in Table 8.2. This table lists the title of each English Apache (2.0 and newer) error page as well as a portion of the text that will be located on the page. Instead of searching for English messages only, we could search for errors in other Apache-supported languages by simply replacing the Content-language string in the previous grep command from en to either de, es, fr, or sv, for German, Spanish, French, or Swedish, respectively.


To use this table, simply supply the text in the Error Page Title column as an intitle search and a portion of the text column as an additional phrase in the search query. Since some of the text is lengthy, you might need to select a unique portion of the text or replace common words with an asterisk, which will reduce your search query to the 10-word limit imposed on Google queries. For example, a good query for the first line of the table might be “response from * upstream server.” intitle: “Bad Gateway!”. Alternately, you could also rely on the “think this is a server error” phrase combined with a title search, such as “think this is a server error” intitle: “Bad Gateway!”. Different versions of Apache will display slightly different error messages, but the process of locating and creating solid base searches from software source code is something you should get comfortable with to stay ahead of the ever-changing software market.
This technique can be expanded to find Apache servers in other languages by reviewing the rest of the contact.html.var file. The important strings from that file are listed in Table 8.3. Because these sentences and phrases are included in every Apache 2.0 error message, they should appear in the text of every error page that the Apache server produces, making them ideal for base searches. It is possible (and fairly easy) to modify these error pages to provide a more polished appearance when a user encounters an error, but remember, hackers have different motivations. Some are simply interested in locating particular versions of a server, perhaps to exploit. Using this criteria, there is no shortage of servers on the Internet that are using these default error phrases, and by extension may have a default, less-secured configuration.
Table 8.3 Phrases Located on All Default Apache (2.0.28–2.0.52) Error Pages
| Language | Phrases |
|---|---|
| German | Sofern Sie dies f$uUr eine Fehlfunktion des Servers halten, informieren Sie bitte den hier$uUber. |
| English | If you think this is a server error, please contact. |
| Spanish | En caso de que usted crea que existe un error en el servidor. |
| French | Si vous pensez qu’il s’agit d’une erreur du serveur, veuillez contacter. |
| Swedish | Om du tror att detta beror p$aR ett serverfei, v$aUnligen kontakta. |
Besides Apache and IIS, other servers (and other versions of these servers) can be located by searching for server-produced error messages, but we’re trying to keep this book just a bit thinner than your local yellow pages, so we’ll draw the line at just these two servers.
Application Software Error Messages
The error messages we’ve looked at so far have all been generated by the Web server itself. In many cases, applications running on the Web server can generate errors that reveal information about the server as well. There are untold thousands of Web applications on the Internet, each of which can generate any number of error messages. Dedicated Web assessment tools such as SPI Dynamic’s Weblnspect excel at performing detailed Web application assessments, making it seem a bit pointless to troll Google for application error messages. However, we search for error message output throughout this book simply because the data contained in error messages should not be overlooked.
We’ve looked at various error messages in previous chapters, and we’ll see more error messages in later chapters, but let’s take a quick look at how error messages can help profile a Web server and its applications. Admittedly, we will hardly scratch the surface of this topic, but we’ll make an effort to stimulate your thinking about Google’s ability to locate these sometimes very telling error messages.
One query, “Fatal error: Call to undefined function” -reply -the—next, will locate Active Server Page (ASP) error messages. These messages often reveal information about the database software in use on the server as well as information about the application that caused the error (see Figure 8.9).

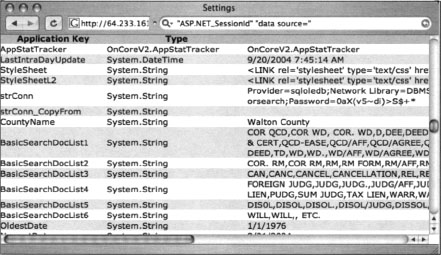
Although this ASP message is fairly benign, some ASP error messages are much more revealing. Consider the query “ASP.NET_SessionId” “data source=", which locates unique strings found in ASP.NET application state dumps, as shown in Figure 8.10. These dumps reveal all sorts of information about the running application and the Web server that hosts that application. An advanced attacker could use encrypted password data and variable information in these stack traces to subvert the security of the application and perhaps the Web server itself.
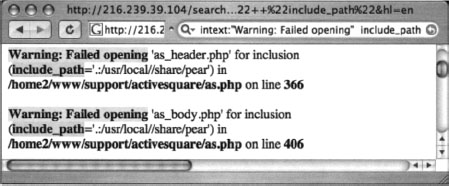
Hypertext Preprocessor (PHP) application errors are fairly commonplace. They can reveal all sorts of information that an attacker can use to profile a server. One very common error can be found with a query such as intext: “Warning: Failed opening” include_path, as shown in Figure 8.11.
CGI programs often reveal information about the Web server and its applications in the form of environment variable dumps. A typical environmental variable output page is shown in Figure 8.12.

This screen shows information about the Web server and the client that connected to the page when the data was produced. Since Google’s bot crawls pages for us, one way to find these CGI environment pages is to focus on the trail left by the bot, reflected in these pages as the “HTTP_FROM=googlebot” line. We can search for pages like this with a query such as “HTTP_FROM=googlebot"googlebot.com “Server_Software”. These pages are dynamically generated, which means that you must look at Google’s cache to see the document as it was crawled.
To locate good base searches for a particular application, it’s best to look at the source code of that application. Using the techniques we’ve explored so far, it’s simple to create these searches.
Default Pages
Another way to locate specific types of servers or Web software is to search for default Web pages. Most Web software, including the Web server software itself, ships with one or more default or test pages. These pages can make it easy for a site administrator to test the installation of a Web server or application. By providing a simple page to test, the administrator can simply connect to his own Web server with a browser to validate that the Web software was installed correctly. Some operating systems even come with Web server software already installed. In this case, the owner of the machine might not even realize that a Web server is running on his machine. This type of casual behavior on the part of the owner will lead an attacker to rightly assume that the Web software is not well maintained and is, by extension, insecure. By further extension, the attacker can also assume that the entire operating system of the server might be vulnerable by virtue of poor maintenance.
In some cases, Google crawls a Web server while it is in its earliest stages of installation, still displaying a set of default pages. In these cases there’s generally a short window of time between the moment when Google crawls the site and when the intended content is actually placed on the server. This means that there could be a disparity between what the live page is displaying and what Google’s cache displays. This makes little difference from a Google hacker’s perspective, since even the past existence of a default page is enough for profiling purposes. Remember, we’re essentially searching Google’s cached version of a page when we submit a query. Regardless of the reason a server has default pages installed, there’s an attacker somewhere who will eventually show interest in a machine displaying default pages found with a Google search.
A classic example of a default page is the Apache Web server default page, shown in Figure 8.13.

Notice that the administrator’s e-mail is generic as well, indicating that not a lot of attention was paid to detail during the installation of this server. These default pages do not list the version number of the server, which is a required piece of information for a successful attack. It is possible, however, that an attacker could search for specific variations in these default pages to find specific ranges of server versions. As shown in Figure 8.14, an Apache server running versions 1.3.11 through 1.3.26 shows a slightly different page than the Apache server version 1.3.11 through 1.3.26, as shown in Figure 8.13.
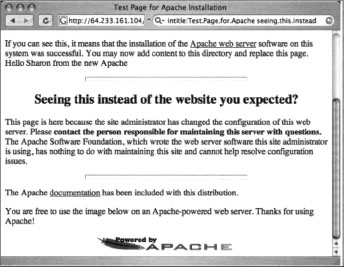
Using these subtle differences to our advantage, we can use specific Google queries to locate servers with these default pages, indicating that they are most likely running a specific version of Apache. Table 8.4 shows queries that can be used to locate specific families of Apache running default pages.
Table 8.4 Queries That Locate Default Apache Installations
| Apache Server Version | Query |
|---|---|
| Apache 1.2.6 | intitle:“Test Page for Apache Installation” “You are free” |
| Apache 1.3.0–1.3.9 | intitle:“Test Page for Apache” “It worked!” “this Web site’” |
| Apache 1.3.11–1.3.31 | intitle:Test.Page.for.Apache seeing.this.instead |
| Apache 2.0 | intitle:Simple.page.for.Apache Apache.Hook.Functions |
| Apache SSL/TLS | intitle:test.page “Hey, it worked!” “SSL/TLS-aware” |
| Apache on Red Hat | “Test Page for the Apache Web Server on Red Hat Linux” |
| Apache on Fedora | intitle:“test page for the apache http server on fedora core “ |
| Apache on Debian | intitle:“Welcome to Your New Home Page!” debian |
| Apache on other Linux | intitle:“Test Page * * Apache Web Server on “-red.hat-fedora |
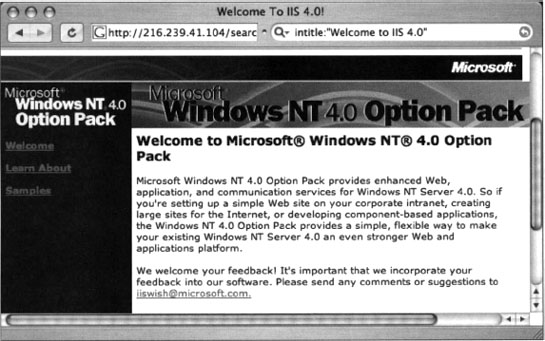
IIS also displays a default Web page when first installed. A query such as intitle:“Welcome to IIS 4.0” can locate very specific versions of IIS, as shown in Figure 8.15.
Table 8.5 Queries That Locate Specific IIS Server Versions
| IIS Server Version | Query |
|---|---|
| Many | intitle:“welcome to” intitle:internet IIS |
| Unknown | intitle:“Under construction” “does not currently have” |
| IIS 4.0 | intitle:“welcome to IIS 4.0” |
| IIS 4.0 | allintitle:Welcome to Windows NT4.0 Option Pack |
| IIS 4.0 | allintitle:Welcome to Internet Information Server |
| IIS 5.0 | allintitle:Welcome to Windows 2000 Internet Services |
| IIS 6.0 | allintitle:Welcome to Windows XP Server Internet Services |
Although each version of IIS displays distinct default Web pages, in some cases service packs or hotfixes could alter the content of a default page. In these cases, the subtle page changes can be incorporated into the search to find not only the operating system version and Web server version, but also the service pack level and security patch level. This information is invaluable to an attacker bent on hacking not only the Web server, but hacking beyond the Web server and into the operating system itself. In most cases, an attacker with control of the operating system can wreak more havoc on a machine than a hacker who controls only the Web server.
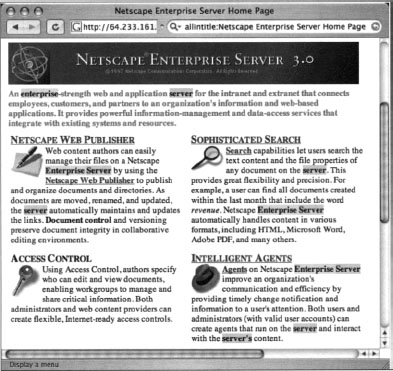
Netscape servers can also be located with simple queries such as allintitle:Netscape Enterprise Server Home Page, as shown in Figure 8.16.
Other Netscape servers can be found with simple allintitle searches, as shown in Table 8.6.
Table 8.6 Queries That Locate Netscape Servers
| Netscape Server Type | Query |
|---|---|
| Enterprise Server | allintitle:Netscape Enterprise Server Home Page |
| FastTrack Server | allintitle:Netscape FastTrack Server Home Page |
Many different types of Web server can be located by querying for default pages as well. Table 8.7 lists a sample of more esoteric Web servers that can be profiled with this technique.
Table 8.7 Queries That Locate More Esoteric Servers
| Server/Version | Query |
|---|---|
| Cisco Micro Webserver 200 | “micro webserver home page” |
| Generic Appliance | “default web page” congratulations “hosting appliance” |
| HP appliance sa1* | intitle:“default domain page” “congratulations” “hp web” |
| iPlanet/Many | intitle:“web server, enterprise edition” |
| Intel NetStructure | “congratulations on choosing” intel netstructure |
| JWS/1.0.3–2.0 | allintitle:default home page Java web server |
| J2EE/Many | intitle:“default j2ee home page” |
| Jigsaw/2.2.3 | intitle:“jigsaw overview” “this is your” |
| Jigsaw/Many | intitle: “jigsaw overview” |
| KFSensor honeypot | “KF Web Server Home Page” |
| Kwiki | “Congratulations! You’ve created a new Kwiki website.” |
| Matrix Appliance | “Welcome to your domain web page” matrix |
| NetWare 6 | intitle:“welcome to netware 6” |
| Resin/Many | allintitle:Resin Default Home Page |
| Resin/Enterprise | allintitle:Resin-Enterprise Default Home Page |
| Sambar Server | intitle:“sambar server” “1997..2004 Sambar” |
| Sun AnswerBook Server | inurl:“Answerbook2options “ |
| TivoConnect Server | inurl:/TiVo Connect |
Default Documentation
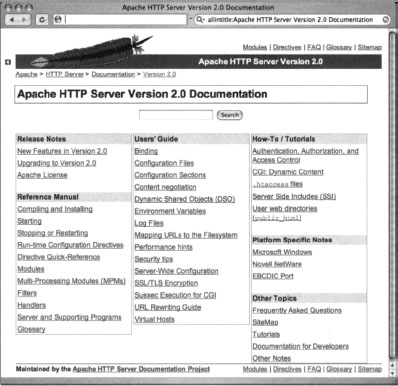
Web server software often ships with manuals and documentation that ends up in the Web directories. An attacker could use this documentation to either profile or locate Web software. For example, Apache Web servers ship with documentation in HTML format, as shown in Figure 8.17.
In most cases, default documentation does not as accurately portray the server version as well as error messages or default pages, but this information can certainly be used to locate targets and to gain an understanding of the potential security posture of the server. If the server administrator has forgotten to delete the default documentation, an attacker has every reason to believe that other details such as security have been overlooked as well. Other Web servers, such as IIS, ship with default documentation as well, as shown in Figure 8.18.
In most cases, specialized programs such as CGI scanners or Web application assessment tools are better suited for finding these default pages and programs, but if Google has crawled the pages (from a link on a default main page for example), you’ll be able to locate these pages with Google queries. Some queries that can be used to locate default documentation are listed in Table 8.8.
Table 8.8 Queries That Locate Default Documentation
| Query | |
|---|---|
| Apache 1.3 | intitle:“Apache 1.3 documentation” |
| Apache 2.0 | intitle: “Apache 2.0 documentation” |
| Apache Various | intitle:“Apache HTTP Server” intitle:” documentation" |
| ColdFusion | inurl:cfdocs |
| EAServer | intitle:” Easerver” “Easerver Version * Documents” |
| iPlanet Server 4.1/Enterprise Server 4.0 | inurl:“Imanuallservlets/” intitle:“programmer” |
| IIS/Various | inurl:iishelp core |
| Lotus Domino 6 | intext:/help/help6_client.nsf |
| Novell Groupwise 6 | inurl:/com/novell/gwmonitor |
| Novell Groupwise WebAccess | inurl:“Icom/novell/webaccess” |
| Novell Groupwise WebPublisher | inurl:“/com/novell/webpublisher” |
Sample Programs
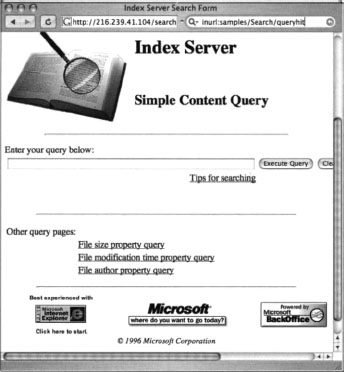
In addition to documentation and manuals that ship with Web software, it is fairly common for default applications to be included with a software package. These default applications, like default Web pages, help demonstrate the functionality of the software and serve as a starting point for developers, providing sample routines and code that could be used as learning tools. Unfortunately, these sample programs can be used to not only profile a Web server; often these sample programs contain flaws or functionality an attacker could use to compromise the server. The Microsoft Index Server simple content query page, shown in Figure 8.19, allows Web visitors to search through the content of a Web site. In some cases, this query page could locate pages that are not linked from any other page or that contain sensitive information.
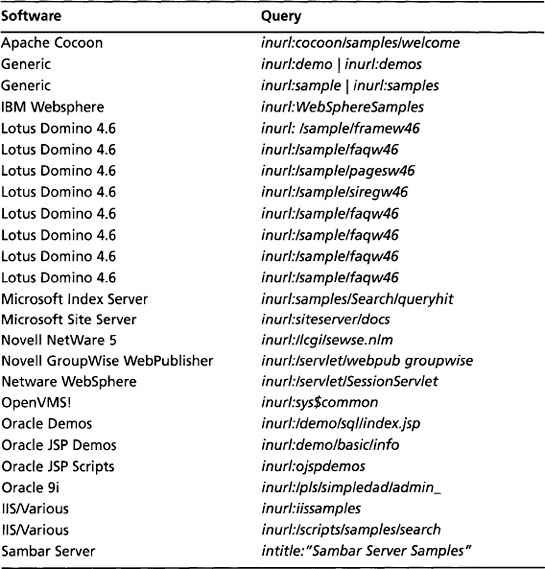
As with default pages, specialized programs designed to crawl a Web site in search of these default programs are much better suited for finding these pages. However, if a default page provided with a Web server contains links to demonstration pages and programs, Google will find them. In some cases, the cache of these pages will remain even after the main page has been updated and the links removed. And remember, you can use the cache page, along with the &strip=1 option to view the page anonymously. This keeps the information gathering exercise away from the watchful eye of the server’s admin. Table 8.9 shows some queries that can be used to locate default-installed programs.
Table 8.9 Queries That Locate Default Programs
| Software | Query |
|---|---|
| Apache Cocoon | inurl:cocoon/samples/welcome |
| Generic | inurl:demo | inurl:demos |
| Generic | inurl:sample inurl:samples |
| IBM Websphere | inurl:WebSphereSamples |
| Lotus Domino 4.6 | inurl:/sample/framew46 |
| Lotus Domino 4.6 | inurl:/sample/faqw46 |
| Lotus Domino 4.6 | inurl:/sample/pagesw46 |
| Lotus Domino 4.6 | inurl:/sample/siregw46 |
| Lotus Domino 4.6 | inurl:/sample/faqw46 |
| Lotus Domino 4.6 | inurl:/sample/faqw46 |
| Lotus Domino 4.6 | inurl:/sample/faqw46 |
| Lotus Domino 4.6 | inurl:/sample/faqw46 |
| Microsoft Index Server | inurl:samples/Search/queryhit |
| Microsoft Site Server | inurl:siteserver/docs |
| Novell NetWare 5 | inurl:/lcgi/sewse.nlm |
| Novell GroupWise WebPublisher | inurl:/servlet/webpub groupwise |
| Netware WebSphere | inurl:/servlet/SessionServlet |
| OpenVMS! | inurl:sys$common |
| Oracle Demos | inurl:/demo/sql/index.jsp |
| Oracle JSP Demos | inurl.demo/basidinfo |
| Oracle JSP Scripts | inurl:ojspdemos |
| Oracle 9i | inurl:/pls/simpledad/admin_ |
| IIS/Various | inurl:iissamples |
| IIS/Various | inurl:/scripts/samples/search |
| Sambar Server | intitle:“Sambar Server Samples” |
Locating Login Portals
Login portal is a term I use to describe a Web page that serves as a “front door” to a Web site. Login portals are designed to allow access to specific features or functions after a user logs in. Google hackers search for login portals as a way to profile the software that’s in use on a target, and to locate links and documentation that might provide useful information for an attack. In addition, if an attacker has an exploit for a particular piece of software, and that software provides a login portal, the attacker can use Google queries to locate potential targets.
Some login portals, like the one shown in Figure 8.20, captured with “microsoft outlook” “web access” version, are obviously default pages provided by the software manufacturer—in this case, Microsoft. Just as an attacker can get an idea of the potential security of a target by simply looking for default pages, a default login portal can indicate that the technical skill of the server’s administrators is generally low, revealing that the security of the site will most likely be poor as well. To make matters worse, default login portals like the one shown in Figure 8.20, indicate the software revision of the program—in this case, version 5.5 SP4. An attacker can use this information to search for known vulnerabilities in that software version.

By following links from the login portal, an attacker can often gain access to other information about the target. The Outlook Web Access portal is particularly renowned for this type of information leak, because it provides an anonymous public access area that can be viewed without logging in to the mail system. This public access area sometimes provides access to a public directory or to broadcast e-mails that can be used to gather usernames or information, as shown in Figure 8.21.

Some login portals provide more details than others. As shown in Figure 8.22, the Novell Management Portal provides a great deal of information about the server, including server software version and revision, application software version and revision, software upgrade date, and server uptime. This type of information is very handy for an attacker staging an attack against the server.
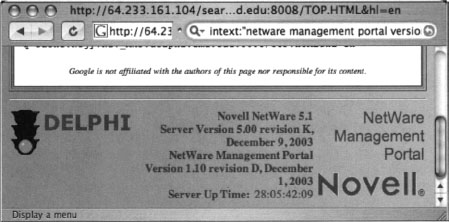
Table 8.9 shows some queries that can be used to locate various login portals. Refer to Chapter 4 for more information about login portals and the information they reveal.











Login portals provide great information for use during a vulnerability assessment. Chapter 4 provides more details on getting the most from these pages.
Using and Locating Various Web Utilities
Google is amazing and very flexible, but it certainly can’t do everything. Some things are much easier when you don’t use Google. Tasks like WHOIS lookups, “pings,” traceroutes, and port scans are much easier when performed outside of Google. There is a wealth of tools available that can perform these functions, but with a bit of creative Googling, it’s possible to perform all of these arduous functions and more, preserving the level of anonymity Google hackers have come to expect. Consider a tool called the Network Query Tool (NQT), shown in Figure 8.23.

Default installations of NQT allow any Web user to perform Internet Protocol (IP) host name and address lookups, Domain Name Server (DNS) queries, WHOIS queries, port testing, and traceroutes. This is a Web-based application, meaning that any user who can view the page can generally perform these functions against just about any target. This is a very handy tool for any security person, and for good reason. NQT functions appear to originate from the site hosting the NQT application. The Web server masks the real address of the user. The use of an anonymous proxy server would further mask the user’s identity.
We can use Google to locate servers hosting the NQT program with a very simple query. The NQT program is usually called nqt.php, and in its default configuration displays the title “Network Query Tool.” A simple query like inurl:nqt.php intitle: “Network Query Tool” returns many results, as shown in Figure 5.11.
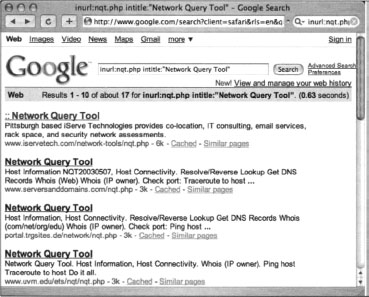
After submitting this query, it’s a simple task to simply click on the results pages to locate a working NQT program. However, the NQT program accepts remote POSTS, which means it’s possible to send an NQT “command” from your Web server to the foo.com server, which would execute the NQT “command” on your behalf. If this seems pointless, consider the fact that this would allow for simple extension of NQT’s layout and capabilities. We could, for example, easily craft an NQT “rotator” that would execute NQT commands against a target, first bouncing it off an Internet NQT server. Let’s take a look at how that might work.
First, we’ll scrape the results page shown in Figure 8.24, creating a list of sites that host NQT. Consider the following Linux/Mac OSX command:

This command grabs 100 results of the Google query inurl:nqt.php intitle:“Network Query Tool”, locates the word nqt.php at the end of a line, removes any line that contains the word google, prints the second field in the list (which is the URL of the NQT site), and uniquely sorts that list. This command will not catch NQT URLs that contain parameters (since nqt.php will not be the last word in the link), but it produces clean output that might look something like this:

We could dump this output into a file by appending >> nqtfile.txt to the end of the previous sort command. Now that we have a working list of NQT servers, we’ll need a copy of the NQT code that produces the interface displayed in Figure 8.23. This interface, with its buttons and “enter host or IP” field, will serve as the interface for our “rotator” program. Getting a copy of this interface is as easy as viewing the source of an existing nqt.php Web page (say, from the list of sites in the nqtfile.txt file), and saving the HTML content to a file we’ll call rotator.php on our own Web server. At this point, we have two files in the same directory of our Web server—an nqtfile.txt file containing a list of NQT servers, and a rotator.php file that contains the HTML source of NQT. We’ll be replacing a single line in the rotator.php file to create our “rotator” program. This line, which is the beginning of the NQT input form, reads:
This line indicates that once the “Do it” button is pressed, data will be sent to a script called nqt.php. If we were to modify this form field to <form method="post" action="http://foo.com/nqt.php">, our rotator program would send the NQT command to the NQT program located at foo.com, which would execute it on our behalf. We’re going to take this one step further, inserting PHP code that will read a random site from the nqtfile.txt program, inserting it into the form line for us. This code might look something like this (lines numbered for clarity):

This PHP code segment is meant to replace the <form method="post” action="/nqt.php"> line in the original NQT HTML code. Line 1 indicates that a PHP code segment is about to begin. Since the rest of the rotator.php file is HTML, this line, as well as line 7 that terminates the PHP code segment, is required. Line 2 reads our nqtsites.txt file, assigning each line in the file (a URL to an NQT site) to an array element. Line 3, included as a separate line for readability, assigns one random line from the nqtsites.txt program to the variable $site. Line 4 outputs the modified version of the original form line, modifying the action target to point to a random remote NQT site. Lines 5 and 6 simply output informative messages about the NQT site that was selected, and instructions for loading a new NQT site. The next line in the rotator.php script would be the table line that draws the main NQT table. When rotator.php is saved and viewed in a browser, it should look similar to Figure 8.25.
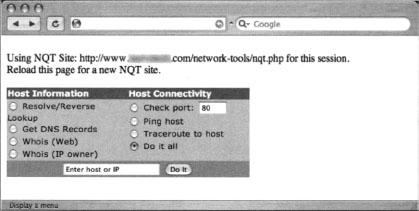
Our rotator program looks very similar to the standard NQT program interface, with the addition of the two initial lines of text. However, when the “check port” box is checked, www.microsoft.com is entered into the host field, and the Do It button is clicked, we are whisked away to the results page on a remote NQT server that displays the results—port 80 is, in fact, open and accepting connections, as shown in Figure 8.26.

This example is designed to suggest that Google can be used to supplement the use of many Web-based applications. All that’s required is a bit of Google know-how and a healthy dose of creativity.
Targeting Web-Enabled Network Devices
Google can also be used to detect the presence of many Web-enabled network devices. Many network devices come preinstalled with a Web interface to allow an administrator to query the status of the device or to change device settings with a Web browser. While this is convenient, and can even be primitively secured through the use of an Secure Sockets Layer (SSL)-enabled connection, if the Web interface of a device is crawled with Google, even the mere existence of that device can add to a silently created network map. For example, a query like intitle:“BorderManager information alert” can reveal the existence of a Novell BorderManager Proxy/Firewall server, as shown in Figure 8.27.

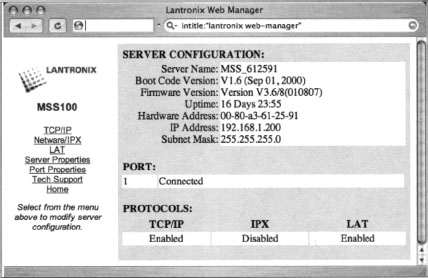
A crafty attacker could use the mere existence of this device to craft his attack against the target network. For example, if this device is acting as a proxy server, the attacker might attempt to use it to gain access to machines inside a trusted network by bouncing connections off this server. Additionally, an attacker might search for any public vulnerabilities for this product in an attempt to exploit this device directly. Although many different devices can be located in this way, it’s generally easier to harvest IP and network data using the output from network statistical programs as we’ll see in the next section. To get an idea of the types of devices that can be located with this technique, consider queries like “Version Info” “Boot Version” “Internet Settings”, which locate Belkin Cable/DSL routers; intitle: “wbem” Compaq login, which locates HP Insight Management Agents; intitle: “lantronix web-manager”, which locates Lantronix Web managers; inurl:tech-support inurl:show Cisco or intitle: “switch home page” “cisco systems” “Telnet — to”, which locates various Cisco products; or intitle:“axis storpoint CD” intitle:“ip address”, which can locate Axis StorPoint servers. Each of these queries reveals pages that report various bits of information about the networks on which they’re installed.
Locating Various Network Reports
In addition to targeting network devices directly, various network documents and status reports can be located with Google that give an outsider access to everything from IP addresses on the network to complete, ready-to-use network diagrams. For example, the query “Looking Glass” (inurl:“lg/” | inurl:lookingglass) will locate looking glass servers that show router statistical information, as shown in Figure 8.28.

The ntop program shows network traffic statistics that can be used to determine the network architecture of a target. The query intitle: “Welcome to ntop!” will locate servers that have publicized their ntop programs, which produces the output shown in Figure 8.29.

Practically any Web-based network statistics package can be located with Google. Table 8.10 reveals several examples from the Google Hacking Database (GHDB) that show searches for various network documentation.
Table 8.10 Examples of Network Documentation from the GHDB
This type of information is a huge asset during a security audit, which can save a lot of time, but realize that any information found in this manner should be validated before using it in any type of finished report.
Locating Network Hardware
It’s not uncommon for a network-connected device to have a Web page of some sort. If that device is connected to the Internet and a link to that device’s Web page ever existed, there’s a good chance that that page is in Google’s database, waiting to be located with a crafty query. As we discussed in Chapter 5, these pages can reveal information about the target network, as shown in Figure 8.30. This type of information can play a very important role in mapping a target network.
All types of devices can be connected to a network. These devices, ranging from switches and routers to printers and even firewalls, are considered great finds for any attacker interested in network reconnaissance, but some devices such as Webcams are interesting finds for an attacker as well.
In most cases, a network-connected Webcam is not considered a security threat but more a source of entertainment for any Web surfer. Keep a few things in mind, however. First, some companies consider it trendy and cool to provide customers a look around their workplace. Netscape was known for this back in its heyday. The Webcams located on these companies’ premises were obviously authorized by upper management. A look inside a facility can be a huge benefit if your job boils down to a physical assessment. Second, it’s not all that uncommon for a Webcam to be placed outside a facility, as shown in Figure 8.31. This type of cam is a boon for a physical assessment. Also, don’t forget that what an employee does at work doesn’t necessarily reflect what he does on his own time. If you locate an employee’s personal Web space, there’s a fair chance that these types of devices will exist.

Most network printers manufactured these days have some sort of Web-based interface installed. If these devices (or even the documentation or drivers supplied with these devices) are linked from a Web page, various Google queries can be used to locate them.
Once located, network printers can provide an attacker with a wealth of information. As shown in Figure 8.32, it is very common for a network printer to list details about the surrounding network, naming conventions, and more. Many devices located through a Google search are still running a default, insecure configuration with no username or password needed to control the device. In a worst-case scenario, attackers can view print jobs and even coerce these printers to store files or even send network commands.

Table 8.11 shows queries that can be used to locate various network devices.








Summary
Attackers use Google for a variety of reasons. An attacker might have access to an exploit for a particular version of Web software and may be on the prowl for vulnerable targets. Other times the attacker might have decided on a target and is using Google to locate information about other devices on the network. In some cases, an attacker could simply be looking for Web devices that are poorly configured with default pages and programs, indicating that the security around the device is soft.
Directory listings provide information about the software versions in use on a device. Server and application error messages can provide a wealth of information to an attacker and are perhaps the most underestimated of all information-gathering techniques. Default pages, programs, and documentation not only can be used to profile a target, but they serve as an indicator that the server is somewhat neglected and perhaps vulnerable to exploitation. Login portals, while serving as the “front door” of a Web server for regular users, can be used to profile a target, used to locate more information about services and procedures in use, and used as a virtual magnet for attackers armed with matching exploits. In some cases, login portals are set up by administrators to allow remote access to a server or network. This type of login portal, if compromised, can provide an entry point for an intruder as well.
Google can be used to locate or augment Web-based networking tools like NQT, which enables remote execution of various network-querying applications. Using creative queries, Google may even locate Web-enabled network devices in use by the target or output from network statistical packages. Whatever your goal during a network-based assessment, there’s a good chance Google can be used to augment your existing tools and techniques.
Solutions Fast Track
Locating and Profiling Web Servers
Locating Login Portals
Locating Network Hardware
Using and Locating Various Web Utilities
Locating Various Network Reports
Frequently Asked Questions
The following Frequently Asked Questions, answered by the authors of this book, are designed to both measure your understanding of the concepts presented in this chapter and to assist you with real-life implementation of these concepts. To have your questions about this chapter answered by the author, browse to www.syngress.com/solutions and click on the “Ask the Author” form.
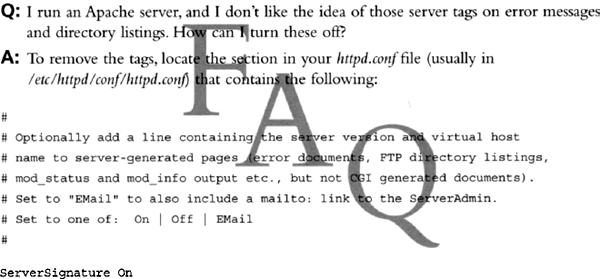
The ServerSignature setting can be changed to Off to remove the tag altogether or to Email, which presents an e-mail link with the ServerAdmin e-mail address as it appears in the httpd.conf file.