
Chapter 6 Locating Exploits and Finding Targets
 Locating Exploit Code
Locating Exploit Code- Locating Vulnerable Targets
- Links to Sites
Introduction
Exploits, are tools of the hacker trade. Designed to penetrate a target, most hackers have many different exploits at their disposal. Some exploits, termed zero day or 0day, remain underground for some period of time, eventually becoming public, posted to newsgroups or Web sites for the world to share. With so many Web sites dedicated to the distribution of exploit code, it’s fairly simple to harness the power of Google to locate these tools. It can be a slightly more difficult exercise to locate potential targets, even though many modern Web application security advisories include a Google search designed to locate potential targets.
In this chapter we’ll explore methods of locating exploit code and potentially vulnerable targets. These are not strictly “dark side” exercises, since security professionals often use public exploit code during a vulnerability assessment. However, only black hats use those tools against systems without prior consent.
Locating Exploit Code
Untold hundreds and thousands of Web sites are dedicated to providing exploits to the general public. Black hats generally provide exploits to aid fellow black hats in the hacking community. White hats provide exploits as a way of eliminating false positives from automated tools during an assessment. Simple searches such as remote exploit and vulnerable exploit locate exploit sites by focusing on common lingo used by the security community. Other searches, such as inurl:0day, don’t work nearly as well as they used to, but old standbys like inurl:sploits still work fairly well. The problem is that most security folks don’t just troll the Internet looking for exploit caches; most frequent a handful of sites for the more mainstream tools, venturing to a search engine only when their bookmarked sites fail them. When it comes time to troll the Web for a specific security tool, Google’s a great place to turn first.
Locating Public Exploit Sites
One way to locate exploit code is to focus on the file extension of the source code and then search for specific content within that code. Since source code is the text-based representation of the difficult-to-read machine code, Google is well suited for this task. For example, a large number of exploits are written in C, which generally uses source code ending in a .c extension. Of course, a search for filetype:c c returns nearly 500,000 results, meaning that we need to narrow our search. A query for filetype:c exploit returns around 5,000 results, most of which are exactly the types of programs we’re looking for. Bearing in mind that these are the most popular sites hosting C source code containing the word exploit, the returned list is a good start for a list of bookmarks. Using page-scraping techniques, we can isolate these sites by running a UNIX command such as:
against the dumped Google results page. Using good, old-fashioned cut and paste or a command such as lynx —dump works well for capturing the page this way. The slightly polished results of scraping 20 results from Google in this way are shown in the list below.
download2.rapid7.com/r7-0025
securityvulns.com/files
www.outpost9.com/exploits/unsorted
downloads.securityfocus.com/vulnerabilities/exploits
packetstorm.linuxsecurity.com/0101-exploits
packetstorm.linuxsecurity.com/0501-exploits
packetstormsecurity.nl/0304-exploits
www.packetstormsecurity.nl/0009-exploits
archives.neohapsis.com/archives/
packetstormsecurity.org/0311-exploits
packetstormsecurity.org/0010-exploits
synnergy.net/downloads/exploits
www.safemode.org/files/zillion/exploits
vdb.dragonsoft.com.tw
unsecure.altervista.org
www.w00w00.org/files/exploits/
Google also makes a great tool for performing digital forensics. If a suspicious tool is discovered on a compromised machine, it’s pretty much standard practice to run the tool through a UNIX command such as strings -8 to get a feel for the readable text in the program. This usually reveals information such as the usage text for the tool, parts of which can be tweaked into Google gueries to locate similar tools. Although obfuscation programs are becoming more and more commonplace, the combination of strings and Google is very powerful, when used properly—capable of taking some of the mystery out of the vast number of suspicious tools on a compromised machine.
Locating Exploits Via Common Code Strings
Since Web pages display source code in various ways, a source code listing could have practically any file extension. A PHP page might generate a text view of a C file, for example, making the file extension from Google’s perspective .PHP instead of .C.
Another way to locate exploit code is to focus on common strings within the source code itself. One way to do this is to focus on common inclusions or header file references. For example, many C programs include the standard input/output library functions, which are referenced by an include statement such as #include <stdio.h> within the source code. A query such as “#include <stdio.h>” exploit would locate C source code that contained the word exploit, regardless of the file’s extension. This would catch code (and code fragments) that are displayed in HTML documents. Extending the search to include programs that include a friendly usage statement with a query such as “#include <stdio.h>” usage exploit returns the results shown in Figure 6.1.

This search returns quite a few hits, nearly all of which contain exploit code. Using traversal techniques (or simply hitting up the main page of the site) can reveal other exploits or tools. Notice that most of these hits are HTML documents, which our previous filetype:c query would have excluded. There are lots of ways to locate source code using common code strings, but not all source code can be fit into a nice, neat little box. Some code can be nailed down fairly neatly using this technique; other code might require a bit more query tweaking. Table 6.1 shows some suggestions for locating source code with common strings.

In using this table, a filetype search is optional. In most cases, you might find it’s easier to focus on the sample strings so that you don’t miss code with funky extensions.
Locating Code with Google Code Search
Google Code Search (www.google.com/codesearch) can be used to search for public source code. In addition to allowing queries that include powerful regular expressions, code search introduces unique operators, some of which are listed in Table 6.2.


Code search is a natural alternative to the techniques we covered in the previous section. For example, in Table 6.1 we used the web search term “#include <stdio.h>” to locate programs written in the C programming language. This search is effective, and locates C code, regardless of the file extension. This same query could be reformatted as a code search query by simply removing the quotes as shown in Figure 6.2.
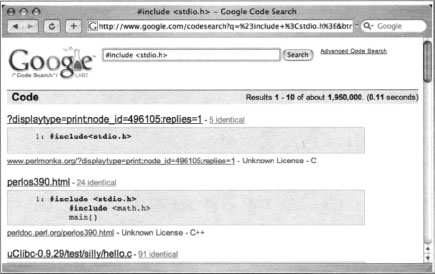
If we’re trying to locate C code, it makes more sense to query code search for lang:c or lang:c++. Although this may feel an awful lot like searching by file extension, this is a bit more advanced than a file extension search. Google’s Code Search does a decent job of analyzing the code (regardless of extension) to determine the programming language the code was written in. Check out the second hit in Figure 6.2. As the snippet clearly shows, this is C code, but is embedded in an HTML file, as revealed by the file name, perlos390.html.
As many researchers and bloggers have reported, Google Code Search can also be used to locate software that contains potential vulnerabilities, as shown in Table Table 6.3.


Locating Malware and Executables
Since the first edition of this book was published, researchers discovered that Google not only crawls, but analyzes binary, or executable files. The query “Time Date Stamp: 4053c6c2” (shown in Figure 6.3) returns one hit for a program named Message.pif. A PIF (or Program Information File) is a type of Windows executable.
Since executable files are machine (and not human) readable, it might seem odd to see text in the snippet of the search result. However, the snippet text is the result of Google’s analysis of the binary file. Clicking the View as HTML link for this result displays the full analysis of the file, as shown in Figure 6.4. If the listed information seems like hardcore geek stuff, it’s because the listed information is hardcore geek stuff.


Clicking the file link (instead of the HTML link) will most likely freak out your browser, as shown in Figure 6.5.

Binary files were just not meant to be displayed in a browser. However, if we right-click the file link and choose Save As... to save it to our local machine, we can run our own basic analysis on the file to determine exactly what it is. For example, running the file command on a Linux or Mac OS X machine reveals that Message.pif is indeed a Windows Executable file:
So Google snatches and analyzes binary files it finds on the web. So what? Well, first, it’s interesting to see that Google has moved into this space. It’s an indication that they’re expanding their capabilities. For example, Google now has the ability to recognize malware. Consider the search for Backup4all backup software shown in Figure 6.6.

Notice the warning below the site description: This site may harm your computer. Clicking on the file link will not take you to the systemutils.net URL, but will instead present a warning page as show in Figure 6.7.

So this is certainly a handy feature, but since this book is about Google Hacking, not about Google’s plans to save the world’s Internet surfers from themselves, it’s only right that we get to the dark heart of the matter: Google can be used to search for live malware. As Websense announced in 2006, this feature can be leveraged to search for very specific executables by focusing on specific details of individual files, such as the Time Stamp, Size and Entry Point fields. H.D. Moore took this one step further and created a sort of malware search engine, which can be found at http://metasploit.com/research/misc/mwsearch, as shown in Figure 6.8.

A search for bagle, for example, reveals several hits, as shown in Figure 6.9.

Clicking the second link in this search result will forward you to a Google web search results page for “Time Date Stamp: 4053c6c2” “Size of Image: 00010000” “Entry Point: 0000e5b0” “Size of Code: 00005000”—a very long query that uniquely describes the binary signature for the Win32.Bagle.M worm. The Google results page for this query is shown in Figure 6.3. Remember this file? It’s the one we successfully downloaded and plopped right onto our desktop!
So even though Google’s binary analysis capability has the potential for good, skillful attackers can use it for malicious purposes as well.
Locating Vulnerable Targets
Attackers are increasingly using Google to locate Web-based targets vulnerable to specific exploits. In fact, it’s not uncommon for public vulnerability announcements to contain Google links to potentially vulnerable targets, as shown in Figure 6.10.

Locating Targets Via Demonstration Pages
The process of locating vulnerable targets can be fairly straightforward, as we’ll see in this section. Other times, the process can be a bit more involved, as we’ll see in the next section. Let’s take a look at a Web application security advisory posted to Secunia (www.secunia.com) on October 10, 2004, as shown in Figure 6.11.

This particular advisory displays a link to the affected software vendor’s Web site. Not all advisories list such a link, but a quick Google query should help you locate the vendor’s page. Since our goal is to develop a query string to locate vulnerable targets on the Web, the vendor’s Web site is a good place to discover what exactly the product’s Web pages look like. Like many software vendors’ Web sites, the CubeCart site shows links for product demonstrations and live sites that are running the product, as shown in Figure 6.12.

At the time of this writing, this site’s demonstration pages were offline, but the list of live sites was active. Live sites are often better for this purpose because we can account for potential variations in how a Web site is ultimately displayed. For example, some administrators might modify the format of a vendor-supplied Web page to fit the theme of the site. These types of modifications can impact the effectiveness of a Google search that targets a vendor-supplied page format.
Perusing the list of available live sites in Figure 6.4, we find that most sites look very similar and that nearly every site has a “powered by” message at the bottom of the main page, as shown in the (highly edited) example in Figure 6.13.
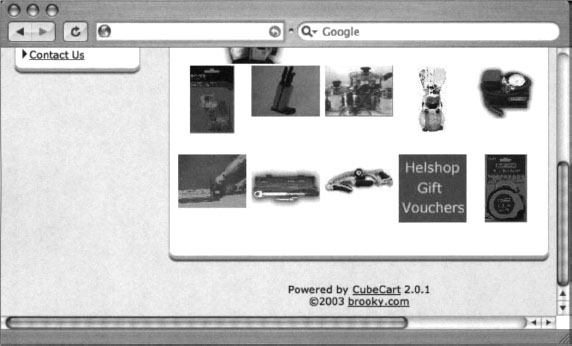
In this case, the live page displays “Powered by CubeCart 2.0.1” as a footer on the main page. Since CubeCart 2.0.1 is the version listed as vulnerable in the security advisory, we need do little else to create a query that locates vulnerable targets on the Web. The final query, “Powered by CubeCart 2.0.1”, returns results of over 27,000 potentially vulnerable targets, as shown in Figure 6.14.
Combining this list of sites with the exploit tool released in the Secunia security advisory, an attacker has access to a virtual smorgasbord of online retailers that could likely be compromised, potentially revealing sensitive customer information such as address, products purchased, and payment details.

Locating Targets Via Source Code
In some cases, a good query is not as easy to come by, although as we’ll see, the resultant query is nearly identical in construction. Although this method is more drawn out (and could be short-circuited by creative thinking), it shows a typical process for detecting an exact working query for locating vulnerable targets. Here we take a look at how a hacker might use the source code of a program to discover ways to search for that software with Google. For example, an advisory was released for the CuteNews program, as shown in Figure 6.15.
As explained in the security advisory, an attacker could use a specially crafted URL to gain information from a vulnerable target. To find the best search string to locate potentially vulnerable targets, we can visit the Web page of the software vendor to find the source code of the offending software. In cases where source code is not available, an attacker might opt to simply download the offending software and run it on a machine he controls to get ideas for potential searches. In this case, version 1.3.1 of the CuteNews software was readily available for download from the author’s Web page.

Once the software is downloaded and optionally unzipped, the first thing to look for is the main Web page that would be displayed to visitors. In the case of this particular software, PHP files are used to generate Web pages. Figure 6.16 shows the contents of the top-level CuteNews directory.

Of all the files listed in the main directory of this package, index.php is the most likely candidate to be a top-level page. Parsing through the index.php file, line 156 would most likely catch our eye.
Line 156 shows a typical informative comment. This comment reveals the portion of the code that would display a login page. Scrolling down farther in the login page code, we come to lines 173–178:

These lines show typical HTML code and reveal username and password prompts that are displayed to the user. Based on this code, a query such as “username:” “password:” would seem reasonable, except for the fact that this query returns millions of results that are not even close to the types of pages we are looking for. This is because the colons in the query are effectively ignored and the words username and password are far too common to use for even a base search. Our search continues to line 191 of index.php, shown here:
This line prints a footer at the bottom of the Web page. This line is a function, an indicator that it is used many times through the program. A common footer that displays on several CuteNews pages could make for a very nice base query. We’ll need to uncover what exactly this footer looks like by locating the code for the echofooter function. Running a command such as grep —r echofooter * will search every file in each directory for the word echofooter. This returns too many results, as shown in this abbreviated output:

Most of the lines returned by this command are calls to the echofooter function, not the definition of the function itself. One line, however, precedes the word echofooter with the word function, indicating the definition of the function. Based on this output, we know that the file inc/functions.inc.php contains the code to print the Web page footer. Although there is a great deal of information in this function, as shown in Figure 6.17, certain things will catch the eye of any decent Google hacker. For example, line 168 shows that copyrights are printed and that the term “Powered by” is printed in the footer.
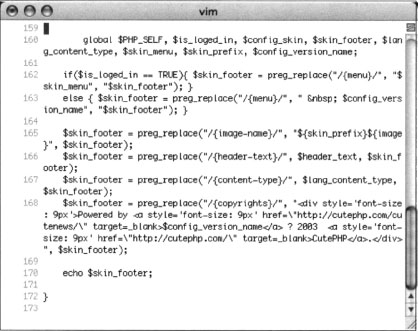
A phrase like “Powered by” can be very useful in locating specific targets due to their high degree of uniqueness. Following the “Powered by” phrase is a link to http://cutephp.com/cutenews/ and the string $config_version_name, which will list the version name of the CuteNews program. To have a very specific “Powered by” search to feed Google, the attacker must either guess the exact version number that would be displayed (remembering that version 1.3.1 of CuteNews was downloaded) or the actual version number displayed must be located in the source code. Again, grep can quickly locate this string for us. We can either search for the string directly or put an equal sign ( = ) after the string to find where it is defined in the code. A grep command such as grep -r “$config_version_name =” * will do the trick:

As shown here, the version name is listed as CuteNews v1.3.1. Putting the two pieces of the footer together creates a very specific string: “Powered by CuteNews v1.3.1 “. This in turn creates a very nice Google query, as shown in Figure 6.18. This very specific query returns nearly perfect results, displaying nearly 500 sites running the potentially vulnerable version 1.3.1 of the CuteNews software.

Too many examples of this technique are in action to even begin to list them all, but in the tradition of the rest of this book, Table 6.4 lists examples of some queries designed to locate targets running potentially vulnerable Web applications. These examples were all pulled from the Google Hacking Database.
















Locating Targets Via CGI Scanning
One of the oldest and most familiar techniques for locating vulnerable Web servers is through the use of a CGI scanner. These programs parse a list of known “bad” or vulnerable Web files and attempt to locate those files on a Web server. Based on various response codes, the scanner could detect the presence of these potentially vulnerable files. A CGI scanner can list vulnerable files and directories in a data file, such as the snippet shown here:

Instead of connecting directly to a target server, an attacker could use Google to locate servers that might be hosting these potentially vulnerable files and directories by converting each line into a Google query. For example, the first line searches for a filename userreg.cgi located in a directory called cgi-bin. Converting this to a Google query is fairly simple in this case, as a search for inurl:/cgi-bin/userreg.cgi shows in Figure 6.19.
This search locates many hosts that are running the supposedly vulnerable program. There is certainly no guarantee that the program Google detected is the vulnerable program. This highlights one of the biggest problems with CGI scanner programs. The mere existence of a file or directory does not necessarily indicate that a vulnerability is present. Still, there is no shortage of these types of scanner programs on the Web, each of which provides the potential for many different Google queries.

There are other ways to go after CGI-type files. For example, the filetype operator can be used to find the actual CGI program, even outside the context of the parent cgi-bin directory, with a query such as filetype:cgi inurl: userreg.cgi. This locates more results, but unfortunately, this search is even more sketchy, since the cgi-bin directory is an indicator that the program is in fact a CGI program. Depending on the configuration of the server, the userreg.cgi program might be a text file, not an executable, making exploitation of the program interesting, if not altogether impossible!
Another even sketchier way of finding this file is via a directory listing with a query such as intitle:index.of userreg.cgi. This query returns no hits at the time of this writing, and for good reason. Directory listings are not nearly as common as URLs on the Web, and a directory listing containing a file this specific is a rare occurrence indeed.
Obviously, automation is required to effectively search Google in this way, but two tools, Wikto (from www.sensepost.com) and Gooscan (from http://Johnny. ihackstuff.com) both perform automated Google and CGI scanning. The Wikto tool uses the Google API; Gooscan does not. See the Protection chapter for more details about these tools.
Summary
There are so many ways to locate exploit code that it’s nearly impossible to categorize them all. Google can be used to search the Web for sites that host public exploits, and in some cases you might stumble on “private” sites that host tools as well. Bear in mind that many exploits are not posted to the Web. New (or 0day) exploits are guarded very closely in many circles, and an open public Web page is the last place a competent attacker is going to stash his or her tools. If a toolkit is online, it is most likely encrypted or at least password protected to prevent dissemination, which would alert the community, resulting in the eventual lockdown of potential targets. This isn’t to say that new, unpublished exploits are not online, but frankly it’s often easier to build relationships with those in the know. Still, there’s nothing wrong with having a nice hit list of public exploit sites, and Google is great at collecting those with simple queries that include the words exploit, vulnerability, or vulnerable. Google can also be used to locate source code by focusing on certain strings that appear in that type of code.
Locating potential targets with Google is a fairly straightforward process, requiring nothing more than a unique string presented by a vulnerable Web application. In some cases these strings can be culled from demonstration applications that a vendor provides. In other cases, an attacker might need to download the product or source code to locate a string to use in a Google query. Either way, a public Web application exploit announcement, combined with the power of Google, leaves little time for a defender to secure a vulnerable application or server.
Solutions Fast Track
Locating Exploit Code
Google Code Search
Locating Malware
Locating Vulnerable Targets
Links to Sites
Michael Sutton’s Blog:
Frequently Asked Questions
The following Frequently Asked Questions, answered by the authors of this book, are designed to both measure your understanding of the concepts presented in this chapter and to assist you with real-life implementation of these concepts. To have your questions about this chapter answered by the author, browse to www.syngress.com/solutions and click on the “Ask the Author” form.
Also remember that for Google to show a result, the site must have been crawled earlier. If that’s not the case, try using a more generic search such as “powered by XYZ” to locate pages that could be running a particular family of software.