
chapter eight
loading data
SAS Visual Analytics 7.3 relies exclusively on the SAS LASR Analytic Server as both data repository and analytic engine. For this section of the book, we want to look at how data gets into LASR. As it turns out, data can be loaded from several sources directly into the LASR Analytic Server. Each source has different potential options, dependencies, and features.
In this chapter we will do the following:
• look at how the SAS LASR Analytic Server is optimized to work with large volumes of data
• explore the SASHDAT file format, which is specifically designed to work with high-performance distributed data
• illustrate other techniques for parallel loading of data.
• investigate the automatic loading of data into the LASR Analytic server, which is available to SAS Visual Analytics
In-memory is different
The LASR Analytic Server is the key component that makes SAS Visual Analytics unique. The LASR Analytic Server is an in-memory data storage area that lets users quickly access and combine data. Before the LASR Analytic Server, each time that you queried data or performed a calculation, the computer would have to retrieve data off disk. This would take up a lot of time for large volumes of data, especially if multiple users were on the server at once. With the LASR Analytic Server, all tables are pre-loaded into RAM, so the data is easily accessible for various analyses. And if you want to increase the amount of data or otherwise improve performance, additional servers can be added to the system, enabling the LASR Analytic Server to distribute the workload across more machines.
It’s about speed
There are now two different ways that data can be loaded into the LASR Analytic Server, serial or parallel. Remember that the LASR Analytic Server is in-memory, so when it goes down or gets restarted, all tables in the server need to be reloaded. In the serial loading process, data is loaded from a source system, passing through a single I/O connection that can act as a bottleneck, not allowing data to flow into the system as fast as possible. By using a parallel loading process, data is transferred from source over to LASR across multiple I/O channels simultaneously, which is far more time effective.
Understanding the non-distributed deployment
When the SAS LASR Analytic Server software is running on a single host machine, SAS Visual Analytics is operating as a non-distributed deployment. This means that all of the data loaded in memory for LASR is kept to a single physical machine—not distributed across the memory of multiple hosts. Other software components of the SAS system can be deployed together on just one host alongside LASR or could split across different hosts themselves as licensed for your site.
Figure 8.1 SAS Visual Analytics non-distributed deployment

In the illustration above, users access the SAS Visual Analytics web application from the web browser on their PCs or from the SAS Mobile BI app on their mobile devices. The SAS Visual Analytics web application coordinates user access and authorization with the SAS Metadata Server. User requests for report content and other data-driven displays are sent from SAS Visual Analytics to the LASR Analytic Server, where it acts upon data in memory to perform the necessary analytic tasks. Administration of the LASR Analytic Server—namely loading and unloading tables as well as stopping and starting the LASR service—requires use of the SAS Workspace Server by an authorized user. Data from any source that is accessible to Base SAS (with an optional SAS/ACCESS engine) can be loaded into the non-distributed LASR Analytic Server.
When working with a non-distributed LASR Analytic Server, data is always loaded serially because the data flows through a single point in two places:
• The LASR Analytic Server itself is a single entity.
• The Workspace server is also a single entity that acts as a bridge for transferring data into the LASR Analytic Server.
Understanding the distributed deployment
Instead of running on one server host, a distributed LASR Analytic Server is deployed in pieces across multiple machines. All of the in-memory analytics features offered by LASR in a distributed deployment are the same as the features offered in a non-distributed deployment. The only difference now is that the data is spread across the memory of the LASR Worker nodes—effectively breaking a large problem into several smaller ones that can be processed simultaneously. This is why the distributed LASR Analytic Server is so fast. The following figure shows how the distributed environment is set up.
Figure 8.2 SAS Visual Analytics distributed deployment

Just like the non-distributed deployment of SAS Visual Analytics, many of the SAS software components can reside on a single server or be split across multiple machines. The difference is that the LASR Analytic Server is now hosted on at least four machines, across a root node and multiple worker nodes. The LASR root node controls the actions of the LASR workers. The LASR workers store the data, which is loaded in RAM, and each performs operations on its own share of data.
When working with a distributed LASR Analytic Server, data can be loaded either serially or in parallel. We can use the same technique to serially load data into a distributed LASR Analytic Server as shown above for the non-distributed LASR Analytic Server by using the SAS Workspace Server. When loading serially, data is sent only to the LASR root node, which then distributes the data individually to each of the LASR workers.
But a distributed LASR Analytic Server can also load data in parallel from a supported set of data sources. Data loaded in parallel is sent to each LASR worker directly from the source, while the LASR root node coordinates and tracks the activity. The actual distribution of the data at load time is handled by the data source.
Loading data to LASR from HDFS
The Distributed SAS LASR Analytic Server can load data directly from a Hadoop Distributed File System (HDFS). This only works with specific data types and in an environment where LASR services are deployed symmetrically alongside HDFS.
Figure 8.3 LASR deployed symmetrically alongside HDFS

When the LASR Analytic Server is deployed with this type of configuration, it can be directed to load data that is hosted in HDFS directly into RAM. The data must be stored either as plain-text files in CSV (comma-separated values) format or, preferably, from SASHDAT files.
SASHDAT is unique
SASHDAT is the fastest and most efficient technique to (re-)load data into LASR.
Enabling support for SASHDAT files
SASHDAT is where things get really interesting. So let's look at some facts about this file format:
• The “H” is less about Hadoop and more about High-performance–it’s optimized for analytics and concurrent processing.
• The metadata for SASHDAT (labels, encoding, formats, partitioning, and so on) are carefully managed for each HDFS file block.
• SASHDAT explicitly avoids fractional rows (which is a common challenge with other HDFS-stored data).
• The SASHDAT file format is binary, compressible (in SAS 9.4 M2), encryptable (in SAS 9.4 M3), and backward-compatible with older software releases.
• Because the SASHDAT file format was developed for working in massively parallel processing (MPP) environments like Hadoop, it provides the fastest and most efficient way to load large amounts of data into the LASR Analytic Server.
To make SASHDAT work, there are some architectural requirements to attend to:
• We must have a LASR Analytic Server running in Distributed mode. That is, the LASR Analytic Server software is deployed to run simultaneously across multiple machines at the same time. We call this massively parallel processing (MPP) because it provides a way to scale up the processing power of LASR substantially.
• Distributed mode LASR is provided by the SAS High-Performance Analytics Environment software—the same software that also enables the SAS High-Performance Analytics Procedures (assuming that software is licensed as well).
• We need to use the Hadoop Distributed File System (HDFS). HDFS is the primary underpinning technology on which most Hadoop technologies are based. Like Distributed LASR, HDFS is also deployed to run simultaneously across multiple machines at the same time. HDFS is able to leverage this type of environment for massive scalability as well as for improving availability.
• Finally, distributed LASR must be symmetrically co-located with HDFS. "Co-located" means that both software solutions must be deployed alongside each other on the same set of machines. "Symmetrically" means that the LASR root node (which acts as the “boss” of LASR) must reside on the same host machine as the HDFS name node (which acts as the HDFS boss) and further that LASR worker nodes must be placed one-for-one alongside the HDFS data nodes.
If these requirements are not all met, then we cannot use the SASHDAT file format. Notably, this means that SASHDAT is not available to us if we're using single-machine (SMP) LASR, or if HDFS resides on a different collection of hosts in our environment, or if we simply don't have HDFS at all.
The exception to the rule
One exception to the requirements of SASHDAT is the MapR Distribution of Hadoop. MapR is shipped with its own closed-source file system known as MapR-FS.
Figure 8.4 A remote (or asymmetric) MapR Hadoop cluster can also host SASHDAT files

When it comes to SASHDAT, the SAS R&D team devised a way to leverage MapR NFS to place SASHDAT files into MapR-FS. Ultimately, this means that LASR can read and write SASHDAT files from MapR-FS over NFS, so co-location of services is not required. (Foreshadowing: Look for similar functionality when you are using any distributed file system that appears locally mounted on the in-memory workers of CAS on the SAS Viya platform.)
SASHDAT does not require SAS/ACCESS
Let’s briefly clarify what we do not need to have in order to use SASHDAT: SAS/ACCESS Interface to Hadoop software. SAS/ACCESS does not provide any of the SASHDAT capabilities. Distributed LASR is fully baked with the ability to implement SASHDAT tables in HDFS without using SAS/ACCESS at all.
The SAS/ACCESS Interface to Hadoop software is, of course, powerful and flexible software that enables a wide range of possibilities in working with the native strengths of a Hadoop cluster. So while it’s not directly responsible for creating SASHDAT tables, it definitely comes in handy for working with Hive tables, Pig and Map Reduce jobs, and much more that might be on the ETL path to creating SASHDAT tables.
Loading data to LASR from Base SAS
We can use Base SAS—and services built on top of it like the SAS Workspace Server and SAS Stored Process Server—to transfer data over to LASR (or into SASHDAT tables in HDFS). Pretty much any data source that Base SAS has access to can be used to feed LASR as part of your enterprise's data management processing.
Examples of data sources which Base SAS can load over into LASR include:
• Base SAS data sets
• SAS Scalable Performance Data Engine (SPD Engine) tables
• Raw text files
And more
Any data source that is accessible to Base SAS (with optional SAS/ACCESS engine) can be loaded into LASR.
Figure 8.5 Some of the default data sources available to Base SAS

If additional SAS software has been licensed at your site, then those products can be used as well, such as the following:
• SAS/ACCESS software: provides the ability for SAS to communicate directly with third-party data providers. Specific offerings are available for providers such as Oracle, DB2, Aster, Hadoop, and many more.
• SAS Scalable Performance Data Server (SPD Server) tables
Figure 8.6 Some of the additional data sources available when optional SAS software is installed
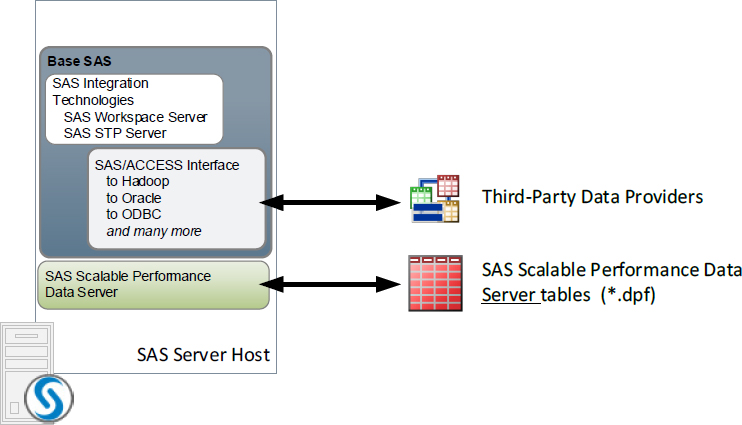
Either PROC LASR or the SASIOLA LIBNAME engine can be used to load data from supported sources directly into LASR memory. Once the data is in the LASR memory, either it can be dropped from RAM (to be reloaded from source later), or LASR can save it out to disk in CSV format or in SASHDAT format.
SAS also provides the SASHDAT LIBNAME engine to simplify the process of saving data straight to SASHDAT format. There are a couple of important things to remember about the SASHDAT LIBNAME engine:
1. LASR, not SAS, is responsible for actually reading and writing the SASHDAT content to HDFS.
2. The SASHDAT LIBNAME engine is unidirectional. Data can be written from SAS (through LASR) into SASHDAT files, but it's not possible to read that data back to SAS directly through the same libref. The intent of SASHDAT is to act as a high-performance repository for loading large volumes of data into LASR, not SAS.
Of course, saying "it can't be done" is not something that usually applies to SAS. So if you really want to read data from SASHDAT (through LASR) back to SAS, there is a way to do it: Use the HPDS2 Procedure.
Figure 8.7 Using SAS PROCs or LIBNAME engines to load data into or out of LASR

Loading data to LASR with SAS In-Database technology
We've talked a lot about SASHDAT and its speed and efficiency in support of parallel loading of data out of HDFS into a Distributed LASR Analytic Server. But it's not the only parallel loading technique available to us. SAS offers In-Database technology that works with a number of third-party data providers which can also provide a mechanism for parallel loading of data into LASR.
The key component of SAS In-Database technology is the SAS Embedded Process (EP). The EP is also based on MPP architecture and is deployed across all of the host nodes of a supported data provider.
Figure 8.8 The SAS Embedded Process is often deployed to a separate cluster of machines apart from LASR
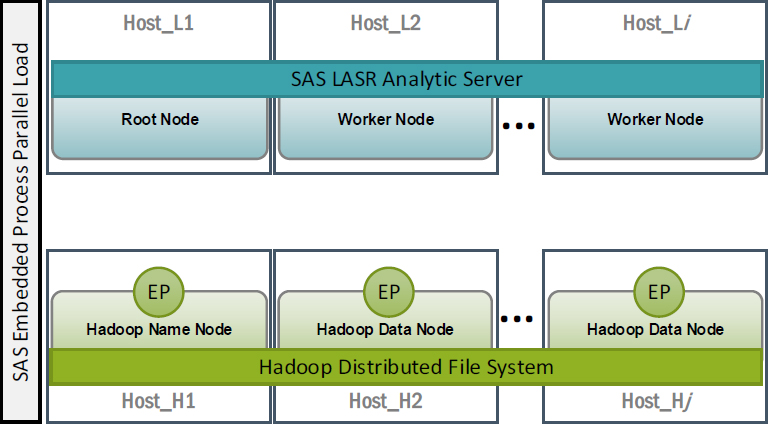
The idea with the EP is that it can take data as directed from its host data provider, and the individual nodes of the EP can each stream their respective portions of the data equally to each of the LASR Workers.
Figure 8.9 Each EP node will distribute its data evenly to each of the LASR Workers

To be clear, parallel loading of data to LASR is not the sole reason why the EP exists—it’s just a really nice side benefit that we can use when we need it. The primary goal of SAS In-Database technology is to bring the statistics to the data as a more efficient approach for working with data in very large volumes. In particular, the SAS Embedded Process is deployed into the remote data provider to work directly where the data resides, so it can perform the requested analysis and return only the results. This approach minimizes large-scale data movement. SAS In-Database technology provides SQL pass-through; code, data quality, and scoring acceleration capabilities; as well as support for SAS High-Performance procedures.
Even with the EP’s significant set of features, there are still many occasions where we will want to use the SAS Visual Analytics software for analysis, discovery, and reporting. This means transferring the data that we need from the remote data provider using the EP’s ability to stream that data efficiently over parallel channels to the LASR Workers.
Loading data to LASR from a different LASR Analytic Server
Often, sites will use more than one LASR Analytic Server at a time. In those situations, it is sometimes necessary to copy in-memory tables from one LASR Analytic Server to another LASR Analytic Server using the IMXFER procedure.
Figure 8.10 Use PROC IMXFER to copy data from one LASR Analytic Server to another

The LASR servers can reside in the same collection of host machines alongside each other, or they can be physically separate, running on different machines. Other than having enough physical RAM available to complete the transfer, there’s no requirement for both LASR servers to span the same number of hosts.
By default, LASR will attempt a parallel transfer of data, equally distributing the data from each source node to each of the destination worker nodes (see the arrows between worker nodes in Figure 8.10 above). However, if there are network limitations such that the workers in one LASR server cannot “see” the other LASR server’s workers, then use the HOSTONLY argument to force a serial transfer of the data between the root nodes of the two LASR Servers (illustrated by the single arrow between root nodes in Figure 8.10).
Loading data into LASR automatically
It’s often helpful when data is automatically loaded or updated in the LASR Analytic Server. SAS Visual Analytics offers two techniques to accomplish this goal. Which one you’ll use primarily depends on the type of data source you’re working with.
SAS Autoload to LASR facility
SAS offers an Autoload facility for loading data into LASR. The Autoload facility does not run on the LASR Analytic Server host machines—it is deployed to a host where the SAS Workspace Server for SAS Visual Analytics resides. Each LASR library in your environment will need its own Autoload implementation.
The Autoload facility is scheduled in the host operating system to run at repeated intervals (usually every 15 minutes). It offers the ability to automatically start the associated LASR Analytic Server (if it is not running already) and then load, append, or unload tables in that LASR Analytic Server as directed.
In its current incarnation, the Autoload facility can work only with data files that reside locally on the SAS Workspace Server host machine in the following formats:
• Base SAS data sets
• Microsoft Excel spreadsheets (XLS, XLSX, XLSB, and XLSM formats)
• CSV (text-delimited file format)
Figure 8.11 The SAS Autoload Facility works with SAS data sets, Excel documents, and CSV files

To be clear, the Autoload facility is not suitable for use with data stored in any other medium. It does not work with third-party DBMS tables, SASHDAT tables, nor SAS Scalable Performance Data Engine or SAS Scalable Performance Data Server tables. It also does not integrate in any way with the SAS In-Database Embedded Process.
The SAS Autoload to LASR facility is very useful within the constraints of its operation. Use it to enable the following:
• Automatic (re-)start of the associated LASR Analytic Server
• Automatic (re-)load of data to the associated LASR Analytic Server
• Configurable scheduling to minimize downtime
Keep the following in mind when you’re using those capabilities:
• Data must be copied to the Autoload drop zone in a supported format.
• Data is loaded serially to LASR.
Keep data fresh
Use the SAS Autoload Facility to ensure that a LASR Analytic Server is automatically started and loaded with data that is frequently used.
LASR Reload-on-Start feature
LASR also offers a feature known as Reload-on-Start, which will automatically reload previous data back into LASR when it’s started. When enabled, it makes a copy of participating tables and places them in the designated backing store. The backing store keeps copies in only one format: Base SAS data sets. Reload-on-Start is enabled on a per-library basis and supports the option to exclude individual tables as needed.
Reload-on-Start only works with select data sources:
• Imports of local files from users
• Imports of Google Analytics, Facebook, or Twitter data
Figure 8.12 Reload-on-Start relies on SAS data sets as a backing store for data loaded from user-imported data, Google Analytics, Facebook, and Twitter

Like the Autoload facility, Reload-on-Start also does not work with third-party DBMS tables, SASHDAT tables, nor SPD Engine or SPD Server tables. Nor does it integrate with the SAS In-Database Embedded Process.
This feature is intended for relatively smaller size tables. The data that is reloaded to LASR comes only from Base SAS data sets over a single, serial network connection to LASR. As table size increases, watch out for increased disk consumption on the SAS server as well as longer loading times from SAS to LASR.
Within these constraints, the Reload-on-Start feature can be very helpful to ensure that the supported tables from the backing store (not from the original upload source) which users expect are indeed available when LASR is (re-)started.
References
The ability to quickly and efficiently load tables into the LASR Analytic Server is important to ensure that SAS Visual Analytics has the data necessary for users to get their jobs done. To get the specific details that you need to be successful working with various data sources and LASR, refer to the following SAS documentation online at support.sas.com:
SAS Institute Inc. 2016. SAS Visual Analytics 7.3: Administration Guide. Cary, NC: SAS Institute Inc.
SAS Institute Inc. 2016. SAS LASR Analytic Server 2.7: Reference Guide. Cary, NC: SAS Institute Inc.
SAS Institute Inc. 2016. SAS High-Performance Analytics Infrastructure 3.5: Installation and Configuration Guide. Cary, NC: SAS Institute Inc.
SAS Institute Inc. 2016. SAS/ACCESS 9.4 for Relational Databases: Reference, Ninth Edition. Cary, NC: SAS Institute Inc.
SAS Institute Inc. 2016. SAS Scalable Performance Data Server 5.3: Administrator’s Guide. Cary, NC: SAS Institute Inc.
SAS Institute Inc. 2016. SAS Scalable Performance Data Server 5.3: User’s Guide. Cary, NC: SAS Institute Inc.