
The Aggregator transformation is used for calculations using aggregate functions in a column as opposed to the Expression transformation that is used for row-wise manipulation.
You can use aggregate functions, such as SUM, AVG, MAX, and MIN, in the Aggregator transformation.
Use the EMPLOYEE Oracle table as the source and get the sum of the salaries of all employees in the target.
Perform the following steps to implement the functionality:
- Import the source using the
EMPLOYEEOracle table in Source Analyzer and create theTGT_TOTAL_SALARYtarget in Target Designer. - Create the
m_AGG_TOTAL_SALARYmapping and drag the source and target from the navigator to the workspace. Create the Aggregator transformation with theAGG_TOTAL_SALname. - As we need to calculate
TOTAL_SALARY, drag only theSALARYcolumn from the source qualifier to the Aggregator transformation.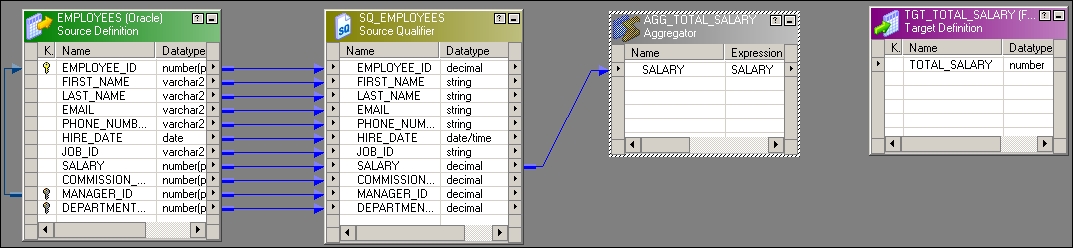
- Add a new
TOTAL_SALARYcolumn to the Aggregator transformation to calculate the total salary, as shown in the following screenshot:
- Add the function to the
TOTAL_SALARYport by opening the expression editor, as described in the preceding section. The function we need to add to get the total salary isSUM(JAN_SAL).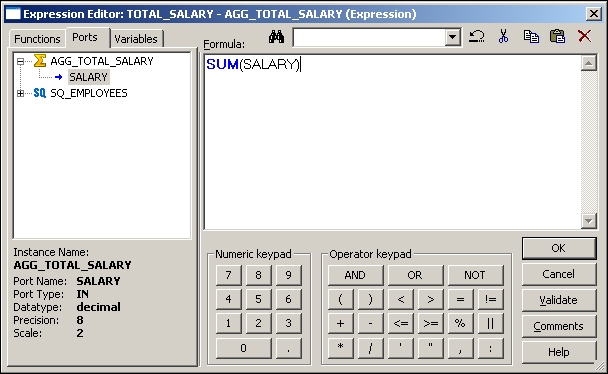
- Connect the
TOTAL_SALARYport to the target, as shown in the following screenshot:
With this, we are done using the Aggregator transformation. When you use the Aggregator transformation, Integration Service temporarily stores the data in the cache memory. The cache memory is created because the data flows in a row-wise manner in Informatica and the calculations required in the Aggregator transformation are column-wise. Unless we temporarily store the data in the cache, we cannot calculate the result. In the preceding scenario, the cache starts storing the data as soon as the first record flows into the Aggregator transformation. The cache will be discussed in detail later in the chapter in the Lookup transformation section.
In the next section, we will talk about the added features of the Aggregator transformation. The Aggregator transformation comes with features such as group by and sorted input.
Using the Group By option in the Aggregator transformation, you can get the result of the aggregate function based on groups. Suppose you wish to get the sum of the salaries of all employees based on Department_ID, we can use the group by option to implement the scenario, as shown in the following screenshot:
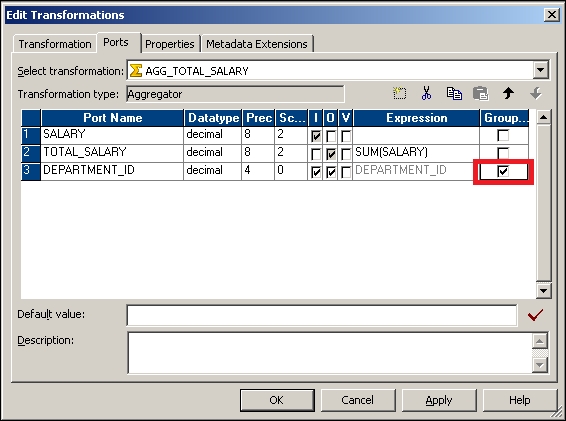
It is always recommended that we pass the Sorted Input to the Aggregator transformation, as this will enhance performance. When you pass the sorted input to the Aggregator transformation, Integration Service enhances the performance by storing less data in the cache. When you pass unsorted data, the Aggregator transformation stores all the data in the cache, which takes more time. When you pass the sorted data to the Aggregator transformation, it stores comparatively less data. The aggregator passes the result of each group as soon as the data for a particular group is received.
Note that the Aggregator transformation cannot perform the operation of sorting the data. It will only internally sort the data for the purpose of calculations. When you pass the sorted data to the Aggregator transformation, check the Sorted Input option in the properties, as shown in the following screenshot:
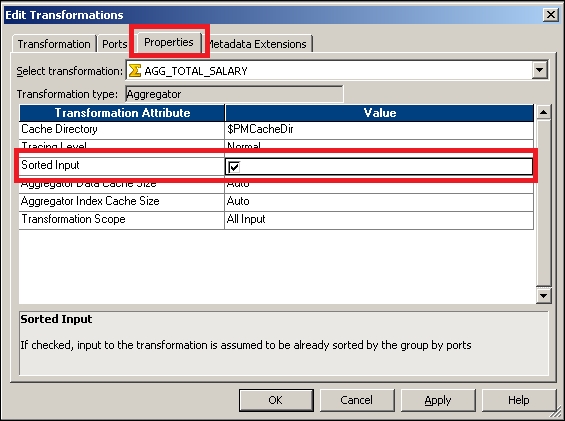
With this we have seen various option and functionality of Aggregator transformation.