
In this chapter, we will open the door to the world of Cassandra data modeling. We will briefly go through its building blocks, the main differences to the relational data model, and examples of constructing queries on a Cassandra data model.
Cassandra describes its data model components by using the terms that are inherited from the Google BigTable parent, for example, column family, column, row, and so on. Some of these terms also exist in a relational data model. They, however, have completely different meanings. It often confuses developers and administrators who have a background in the relational world. At first sight, the Cassandra data model is counterintuitive and very difficult to grasp and understand.
In the relational world, you model the data by creating entities and associating them with relationships according to the guidelines governed by the relational theories. It means that you can solely concentrate on the logical view or structure of the data without any considerations of how the application accesses and manipulates the data. The objective is to have a stable data model complying with the relational guidelines. The design of the application can be done separately. For instance, you can answer different queries by constructing different SQL statements, which is not of your concern during data modeling. In short, relational data modeling is process oriented, based on a clear separation of concerns.
On the contrary, in Cassandra, you reverse the above steps and always start from what you want to answer in the queries of the application. The queries exert a considerable amount of influence on the underlying data model. You also need to take the physical storage and the cluster topology into account. Therefore, the query and the data model are twins, as they were born together. Cassandra data modeling is result oriented based on a clear understanding of how a query works internally in Cassandra.
Owing to the unique architecture of Cassandra, many simple things in a relational database, such as sequence and sorting, cannot be presumed. They require your special handling in implementing the same. Furthermore, they are usually design decisions that you need to make upfront in the process of data modeling. Perhaps it is the cost of the trade-off for the attainment of superb scalability, performance, and fault tolerance.
To enjoy reading this book, you are advised to temporarily think in both relational and NoSQL ways. Although you may not become a friend of Cassandra, you will have an eye-opening experience in realizing the fact that there exists a different way of working in the world.
If you want me to use just one sentence to describe Cassandra's data model, I will say it is a non-relational data model, period. It implies that you need to forget the way you do data modeling in a relational database.
You focus on modeling the data according to relational theories. However, in Cassandra and even in other NoSQL databases, you need to focus on the application in addition to the data itself. This means you need to think about how you will query the data in the application. It is a paradigm shift for those of you coming from the relational world. Examples are given in the subsequent sections to make sure that you understand why you cannot apply relational theories to model data in Cassandra.
Another important consideration in Cassandra data modeling is that you need to take the physical topology of a Cassandra cluster into account. In a relational database, the primary goal is to remove data duplication through normalization to have a single source of data. It makes a relational database ACID compliant very easily. The related storage space required is also optimized. Conversely, Cassandra is designed to work in a massive-scale, distributed environment in which ACID compliance is difficult to achieve, and replication is a must. You must be aware of such differences in the process of data modeling in Cassandra.
In Chapter 1, Bird's Eye View of Cassandra, you learned that Cassandra's storage model is based on BigTable, a column-oriented store. A column-oriented store is a multidimensional map. Specifically, it is a data structure known as Map. An example of the declaration of map data structure is as follows:
Map<RowKey, SortedMap<ColumnKey, ColumnValue>>
The Map data structure gives efficient key lookup, and the sorted nature provides efficient scans. RowKey is a unique key and can hold a value. The inner SortedMap data structure allows a variable number of ColumnKey values. This is the trick that Cassandra uses to be schemaless and to allow the data model to evolve organically over time. It should be noted that each column has a client-supplied timestamp associated, but it can be ignored during data modeling. Cassandra uses the timestamp internally to resolve transaction conflicts.
In a relational database, column names can be only strings and be stored in the table metadata. In Cassandra, both RowKey and ColumnKey can be strings, long integers, Universal Unique IDs, or any kind of byte arrays. In addition, ColumnKey is stored in each column. You may opine that it wastes storage space to repeatedly store the ColumnKey values. However, it brings us a very powerful feature of Cassandra. RowKey and ColumnKey can store data themselves and not just in ColumnValue. We will not go too deep into this at the moment; we will revisit it in later chapters.
Note
Universal Unique ID
Universal Unique ID (UUID) is an Internet Engineering Task Force (IETF) standard, Request for Comments (RFC) 4122, with the intent of enabling distributed systems to uniquely identify information without significant central coordination. It is a 128-bit number represented by 32 lowercase hexadecimal digits, displayed in five groups separated by hyphens, for example: 0a317b38-53bf-4cad-a2c9-4c5b8e7806a2
There are a few logical building blocks to come up with a Cassandra data model. Each of them is introduced as follows.
Column is the smallest data model element and storage unit in Cassandra. Though it also exists in a relational database, it is a different thing in Cassandra. As shown in the following figure, a column is a name-value pair with a timestamp and an optional Time-To-Live (TTL) value:

The elements of a column
The name and the value (ColumnKey and ColumnValue in SortedMap respectively) are byte arrays, and Cassandra provides a bunch of built-in data types that influence the sort order of the values. The timestamp here is for conflict resolution and is supplied by the client application during a write operation. Time-To-Live is an optional expiration value used to mark the column deleted after expiration. The column is then physically removed during compaction.
One level up is a row, as depicted in the following figure. It is a set of orderable columns with a unique row key, also known as a primary key:
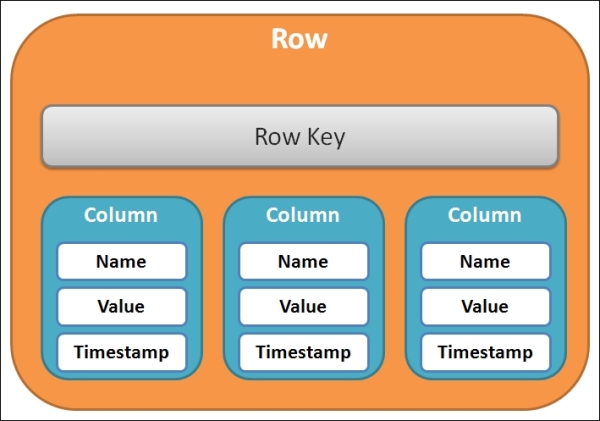
The structure of a row
The row key can be any one of the same built-in data types as those for columns. What orderable means is that columns are stored in sorted order by their column names.
Different names in columns are possible in different rows. That is why Cassandra is both row oriented and column oriented. It should be remarked that there is no timestamp for rows. Moreover, a row cannot be split to store across two nodes in the cluster. It means that if a row exists on a node, the entire row exists on that node.
The next level up is a column family. As shown in the following figure, it is a container for a set of rows with a name:
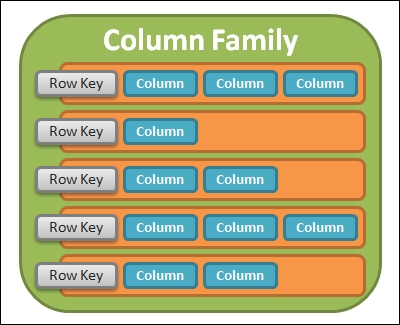
The structure of a column family
The row keys in a column family must be unique and are used to order rows. A column family is analogous to a table in a relational database, but you should not go too far with this idea. A column family provides greater flexibility by allowing different columns in different rows. Any column can be freely added to any column family at any time. Once again, it helps Cassandra be schemaless.
Columns in a column family are sorted by a comparator. The comparator determines how columns are sorted and ordered when Cassandra returns the columns in a query. It accepts long, byte and UTF8 for the data type of the column name, and the sort order in which columns are stored within a row.
Physically, column families are stored in individual files on a disk. Therefore, it is important to keep related columns in the same column family to save disk I/O and improve performance.
The outermost data model element is keyspace, as illustrated in the following figure:
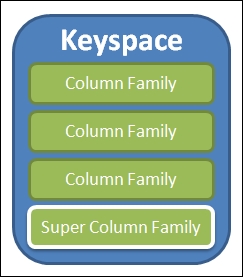
The structure of a keyspace
Keyspace is a set of column families and super column families, which will be introduced in the following section. It is analogous to a schema or database in the relational world. Each Cassandra instance has a system keyspace to keep system-wide metadata.
Keyspace contains replication settings controlling how data is distributed and replicated in the cluster. Very often, one cluster contains just one keyspace.
As shown in the following figure, a super column is a named map of columns and a super column family is just a collection of super columns:
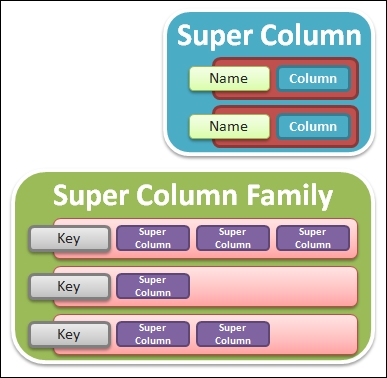
The structure of a super column and a super column family
Super columns were popular in the earlier versions of Cassandra but are not recommended anymore since they are not supported by the Cassandra Query Language (CQL), a SQL-like language to manipulate and query Cassandra, and must be accessed by using the low-level Thrift API. A column family is enough in most cases.
Note
Thrift
Thrift is a software framework for the development of scalable cross-language services. It combines a software stack with a code generation engine to build services that work efficiently and seamlessly with numerous programming languages. It is used as a remote procedure call (RPC) framework and was developed at Facebook Inc. It is now an open source project in the Apache Software Foundation.
There are other alternatives, for example, Protocol Buffers, Avro, MessagePack, JSON, and so on.
Cassandra allows collections, namely sets, lists, and maps, as parts of the data model. Collections are a complex type that can provide flexibility in querying.
Cassandra allows the following collections:
- Sets: These provide a way of keeping a unique set of values. It means that one can easily solve the problem of tracking unique values.
- Lists: These are suitable for maintaining the order of the values in the collection. Lists are ordered by the natural order of the type selected.
- Maps: These are similar to a store of key-value pairs. They are useful for storing table-like data within a single row. They can be a workaround of not having joins.
Here we only provided a brief introduction, and we will revisit the collections in subsequent chapters.
Foreign keys are used in a relational database to maintain referential integrity that defines the relationship between two tables. They are used to enforce relationships in a relational data model such that the data in different but related tables can be joined to answer a query. Cassandra does not have the concept of referential integrity and hence, joins are not allowed either.
Foreign keys and joins are the product of normalization in a relational data model. Cassandra has neither foreign keys nor joins. Instead, it encourages and performs best when the data model is denormalized.
Indeed, denormalization is not completely disallowed in the relational world, for example, a data warehouse built on a relational database. In practice, denormalization is a solution to the problem of poor performance of highly complex relational queries involving a large number of table joins.
Foreign keys and joins can be avoided in Cassandra with proper data modeling.
In a relational database, sequences are usually used to generate unique values for a surrogate key. Cassandra has no sequences because it is extremely difficult to implement in a peer-to-peer distributed system. There are however workarounds, which are as follows:
- Using part of the data to generate a unique key
- Using a UUID
In most cases, the best practice is to select the second workaround.
A counter column is a special column used to store a number that keeps counting values. Counting can be either increment or decrement and timestamp is not required.
The counter column should not be used to generate surrogate keys. It is just designed to hold a distributed counter appropriate for distributed counting. Also bear in mind that updating a counter is not idempotent.
Time-To-Live (TTL) is set on columns only. The unit is in seconds. When set on a column, it automatically counts down and will then be expired on the server side without any intervention of the client application.
Typical use cases are for the generation of security token and one-time token, automatic purging of outdated columns, and so on.
One important thing you need to remember is that the secondary index in Cassandra is not identical to that in a relational database. The secondary index in Cassandra can be created to query a column that is not a part of the primary key. A column family can have more than one secondary index. Behind the scenes, it is implemented as a separate hidden table which is maintained automatically by Cassandra's internal process.
The secondary index does not support collections and cannot be created on the primary key itself. The major difference between a primary key and a secondary index is that the former is a distributed index while the latter is a local index. The primary key is used to determine the node location and so, for a given row key, its node location can be found immediately. However, the secondary index is used just to index data on the local node, and it might not be possible to know immediately the locations of all matched rows without having examined all the nodes in the cluster. Hence, the performance is unpredictable.
More information on secondary keys will be provided as we go through the later chapters.