
Chapter 14: H2O at Scale in a Larger Platform Context
In the previous chapter, we broadened our view of H2O machine learning (ML) technology by introducing H2O AI Cloud, an end-to-end ML platform composed of multiple model-building engines, an MLOps platform for model deployment, monitoring, and management, a Feature Store for reusing and operationalizing model features, and a low-code software development kit (SDK) for building artificial intelligence (AI) applications on top of these components and hosting them on an app store for enterprise consumption. The focus of this book has been what we have called H2O at scale, or the use of H2O Core (H2O-3 and Sparkling Water) to build accurate and trusted models on massive datasets, H2O Enterprise Steam to manage H2O Core users and their environments, and the H2O MOJO to easily and flexibly deploy models to diverse target environments. We learned that these H2O-at-scale components are natively a part of the larger H2O AI Cloud platform, though they can be deployed separately from it.
In this chapter, we will explore how H2O at scale achieves greater capabilities as a member of the H2O AI Cloud platform. More specifically, we will cover the following topics:
- A quick recap of H2O AI Cloud
- Exploring a baseline reference solution for H2O at scale
- Exploring new possibilities for H2O at scale
- A Reference H2O Wave app as an enterprise AI integration fabric
Technical requirements
This link will get you started on developing H2O Wave applications: https://wave.h2o.ai/docs/installation. H2O Wave is open source and can be developed on your local machine. To get full familiarity with the H2O AI Cloud platform, you can sign up for a 90-day trial of H2O AI Cloud at https://h2o.ai/freetrial.
A quick recap of H2O AI Cloud
The goal of this chapter is to explore how H2O at scale, the focus of this book, picks up new capabilities when used as part of the H2O AI Cloud platform. Let's first have a quick review of H2O AI Cloud by revisiting the following diagram, which we encountered in the previous chapter:
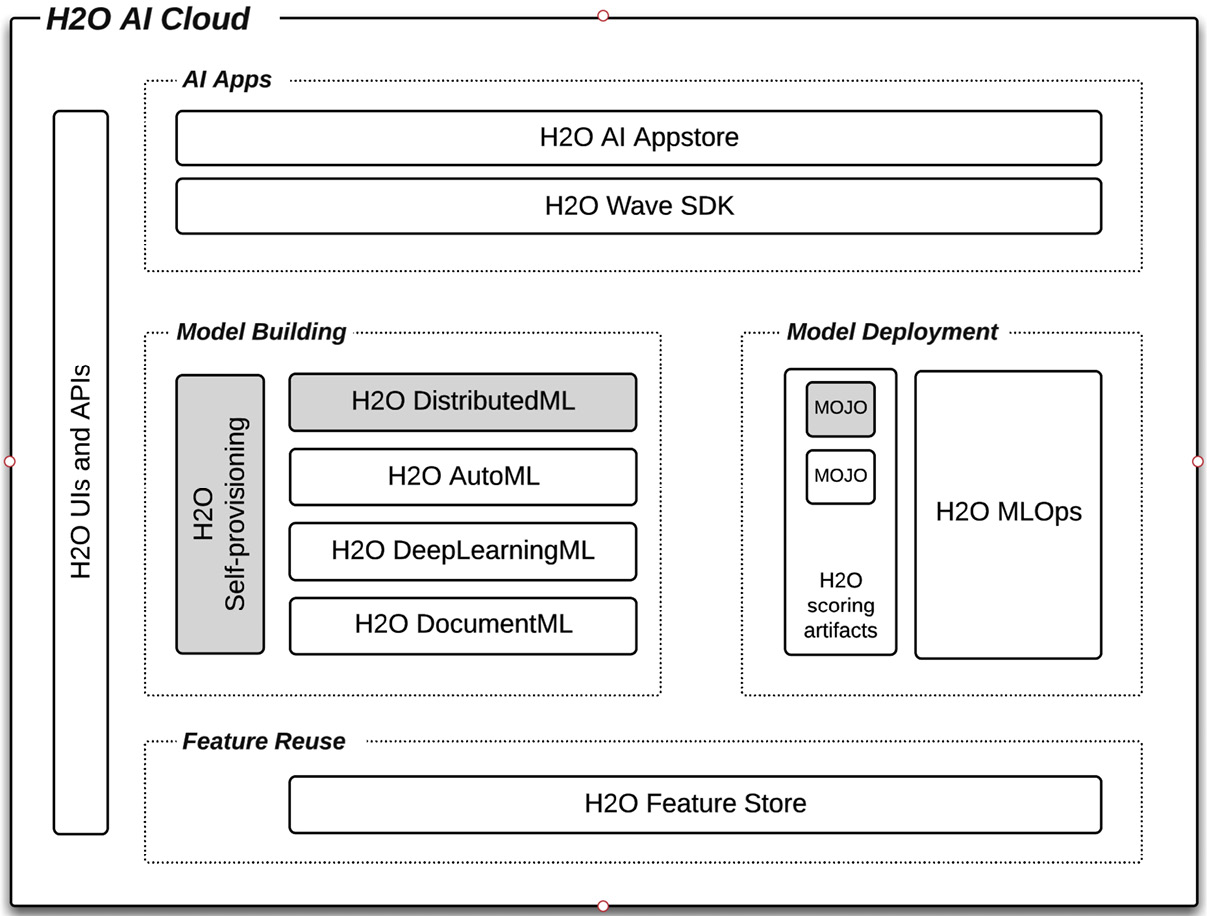
Figure 14.1 – Components of the H2O AI Cloud platform
As a quick summary, we see that H2O AI Cloud has four specialized model-building engines. H2O Core (H2O-3, H2O Sparkling Water) represents H2O DistributedML for horizontally scaling model building on massive datasets. H2O Enterprise Steam, in this context, represents a more generalized tool to manage and provision the model-building engines.
We see that the H2O MOJO, exported from H2O Core model building, can be deployed directly to the H2O MLOps model deployment, monitoring, and management platform (though, as seen in Chapter 10, H2O Model Deployment Patterns, the MOJO can be deployed openly to other targets as well). Note that the H2O specialized automated ML (AutoML) engine called Driverless AI also produces a MOJO and can be deployed in ways shown in Chapter 10, H2O Model Deployment Patterns. We also see that the H2O AI Feature Store is available to share and operationalize features both in the model-building and model-deployment contexts.
Finally, we see that H2O Wave SDK is available to build AI apps over the other components of the H2O AI Cloud platform and then publish to an H2O App Store as part of the platform.
Let's now start to put these pieces together into various H2O-at-scale solutions.
Exploring a baseline reference solution for H2O at scale
So, let's now explore how H2O-at-scale components benefit from participating in the H2O AI Cloud platform. To do so, let's first start with a baseline solution of H2O at scale outside of H2O AI Cloud. The baseline solution is shown in the following diagram. We will use this baseline to compare solutions where H2O at scale does integrate with AI Cloud components:

Figure 14.2 – Baseline solution for H2O at scale
Important Note
For this and all solutions in the chapter, it is assumed that the data scientist used H2O Enterprise Steam to launch an H2O-3 or H2O Sparkling Water environment. See Chapter 3, Fundamental Workflow – Data to Deployable Model, for an overview of this step.
A quick walkthrough of its solution flow is summarized as follows:
- The data scientist imports a large dataset and uses it to build an ML model at scale. See the chapters in Part 2, Building State-of-the-Art Models on Large Data Volumes Using H2O, for a deep exploration of this topic.
- The operations group deploys the model artifact (called the H2O MOJO) to a scoring environment. See Chapter 10, H2O Model Deployment Patterns, to explore a diversity of such target systems for H2O model deployment.
- The predictions are consumed and acted up by software or tooling within a business context. (Here, we are assuming the deployed model is a supervised learning model, though it could be an unsupervised model that generated outputs that are not predictions; for example, cluster membership of an input).
Let's use this baseline solution to start adding H2O AI Cloud components and thus see how H2O at scale gains additional capabilities through membership of this larger platform.
Exploring new possibilities for H2O at scale
Now, let's step through different ways we can integrate H2O at scale—the focus of this book—with the rest of the H2O AI Cloud platform and thereby achieve greater capabilities and value.
Leveraging H2O Driverless AI for prototyping and feature discovery
H2O's AutoML Driverless AI component is a highly automated model-building tool that uses (among other features) a genetic algorithm, AI heuristics, and exhaustive automated feature engineering to build accurate and explainable models— typically in hours—that are then deployed to production systems. Driverless AI, however, does not scale to train on the hundreds of GB to TBs sized datasets that H2O-3 and Sparkling Water handle.
It is quite useful, however, for data scientists to feed sampled data from these massive datasets to Driverless AI and then use the AutoML tool to (a) quickly prototype the model to gain an early understanding and (b) discover auto-engineered features that contribute to an accurate model but would otherwise be difficult to find from pure manual and domain knowledge means. The resulting knowledge from Driverless AI in this workflow is then used as a starting point to build models at scale against the original unsampled data using H2O-3 or Sparkling Water.
This is shown in the following diagram and then summarized:

Figure 14.3 – Leveraging H2O Driverless AI for prototyping and feature discovery
The workflow steps to leverage Driverless AI to quickly prototype and discover features for model building at scale are provided here:
- Import a large-volume dataset into the distributed in-memory architecture inherent in the H2O-at-scale environment. Sample the imported data into a smaller subset (typically 10 to 100 GB) using the H2O-3 split_frame method (here in Python) with an appropriate ratio defined as an input parameter to achieve the desired sample size. Write the output to a staging location that Driverless AI can access.
- Import the sampled dataset to Driverless AI. Use defaults to quickly prototype an accurate model. Use different settings to continue prototyping based on your domain and data-science experience. Explore explainability techniques on models. Explore engineered features with the highest contribution to models. Use Automated Model Documentation (AutoDoc) to understand the models more deeply and translate the names of engineered features into their underlying mathematical and logical representations.
- Use the knowledge from Step 2 to guide your model building against the full massive dataset on H2O-3 or Sparkling Water.
Driverless AI was overviewed in Chapter 13, Introducing H2O AI Cloud. The following screenshot shows an experiment iterating toward a final accurate model:
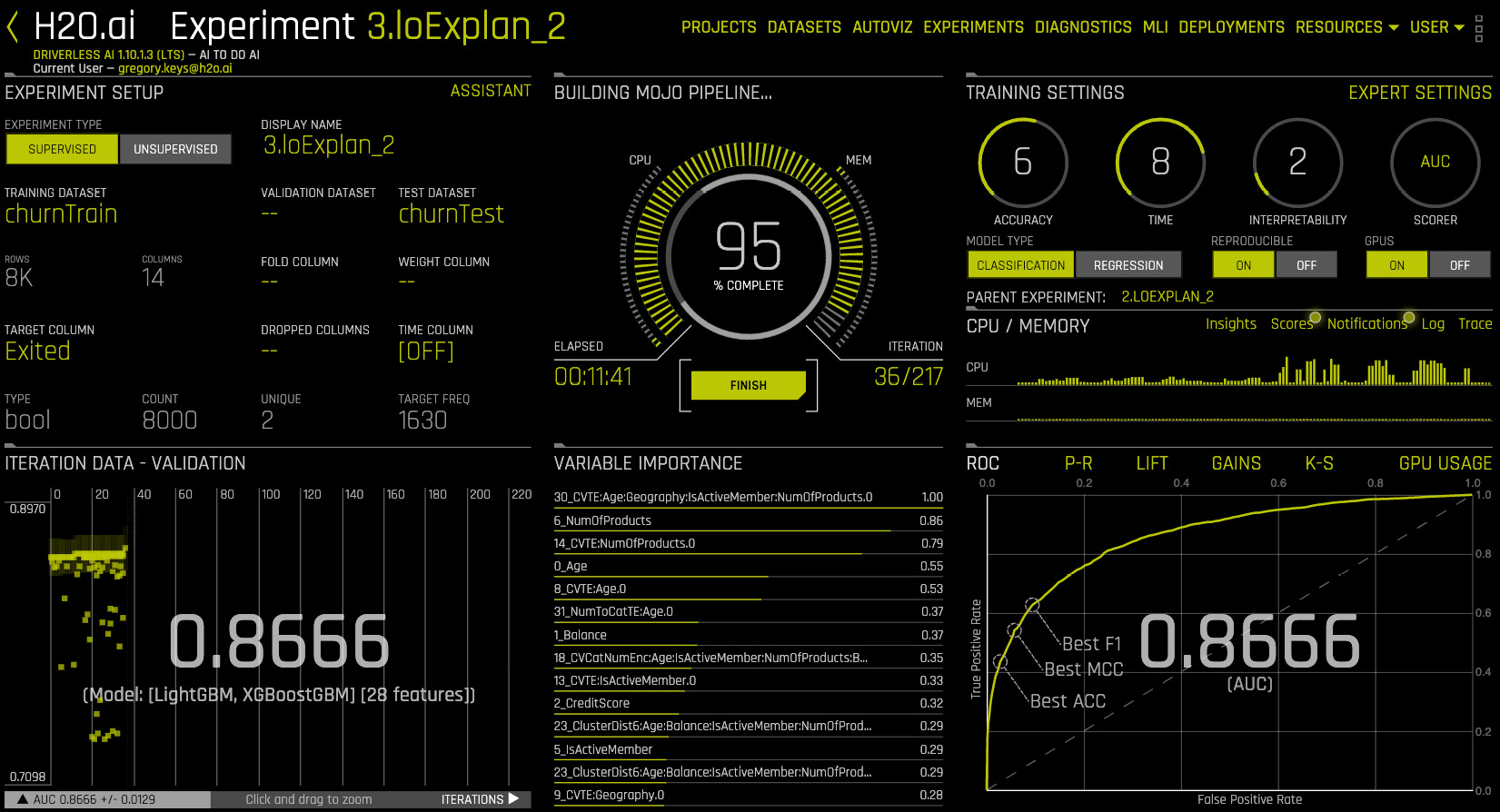
Figure 14.4 – Driverless AI finding an accurate model
Note the lower-left panel of Figure 14.4, which shows the progress of the genetic algorithm iterating across models. Each square is a separate ML model that has been built. Each of these models uses one of an automated choice of algorithms (for example, XGBoost; Light Gradient Boosting Model (LightGBM); Generalized Linear Model (GLM)) that explores an extremely wide hyperparameter space (for example, combinations of learning rates, tree depths, number of trees, to name a few).
Importantly, each model built by the genetic algorithm also explores an extremely wide space of features engineered from those in the original imported dataset. The experiment will stop with a final best model, typically a stacked ensemble of preceding top models. Users can run many experiments in short amounts of time with the intent of exploring, by changing many high-level and low-level settings and evaluating outcomes.
Knowledge gained from these rapid explorations, including feature engineering that is important to the final model, can be used as a starting point to build models at scale with H2O-3 or Sparkling Water.
Note that for smaller datasets, Driverless AI is quite effective at finding highly predictive models in short periods of time. H2O-3 and Sparkling Water, however, are needed for scaling to massive datasets or for taking a more controlled code-based approach to model building. As shown here, for the code-based approach, it is valuable to first prototype a problem with Driverless AI and then use the resulting insights and engineered features as a guide to the code-based approach.
Driverless AI (AutoML) versus H2O-3 (DistributedML): When to Use Which?
Driverless AI is a highly automated user interface (UI)-based (or application programming interface (API)-based) AutoML component of H2O AI Cloud designed to quickly find accurate and trusted models for production scoring. Use it when you want a highly automated approach (with extensive user controls) to model building and when dataset sizes are less than 100 GB (though more resource-heavy server instances can work with larger datasets).
Use H2O-3 or Sparkling Water when your datasets are greater than 100 GB (and into TBs) or for a code-based approach to model building when you want more control of the model-building process. Note that H2O-3 and Sparkling Water have AutoML capabilities, as described in Chapter 5, Advanced Model Building – Part 1, but those in Driverless AI are far more sophisticated, extensive, and automated.
Use Driverless AI to prototype a problem and take the resulting insights and discovery of engineered features to guide your model building on H2O-3 or Sparkling Water.
We have seen our first example of H2O-at-scale model building gaining capabilities by interacting with a component in the H2O AI Cloud platform. Let's now look at our next example.
Integrating H2O MLOps for model monitoring, management, and governance
Models built with H2O-3 and Sparkling Water generate their own ready-to-deploy low-latency scoring artifact called the H2O MOJO. As we showed in Chapter 10, H2O Model Deployment Patterns, this scoring artifact can be deployed to a great diversity of production systems, ranging from real-time scoring from REpresentational State Transfer (REST) servers and batch scoring from databases to scoring from streaming queues (to name a few). We also showed in that chapter that deploying to a REST server provides a useful integration pattern for integrating scored predictions into common business intelligence (BI) tools such as Microsoft Excel or Tableau.
The H2O MLOps component of H2O AI Cloud is an excellent choice for deploying H2O-3 or Sparkling Water models (or Driverless AI models and non-H2O models—for example, scikit-learn models, for that matter). The integration is quite simple, as shown in the following diagram:

Figure 14.5 – Deployment of H2O-at-scale models to the H2O MLOps platform
The steps to integrate these models are straightforward, as outlined here:
- Build your model with H2O-3 or Sparkling Water and export the MOJO for deployment.
- From H2O MLOps, deploy the staged MOJO either from the UI or the MLOps API. Recall from Chapter 13, Introducing H2O AI Cloud, that there are many deployment options, including real-time versus batch, single model versus champion/challenger, or A/B testing.
- The model is now scorable from a unique REST endpoint. Predictions with optional reason codes are ready to be consumed by your system, whether that is a web application, a BI tool, and so on.
For all models during and after this flow, MLOps performs important tasks around monitoring, managing, and governing models. The following screenshot, for example, shows the data drift monitoring screen for H2O MLOps:
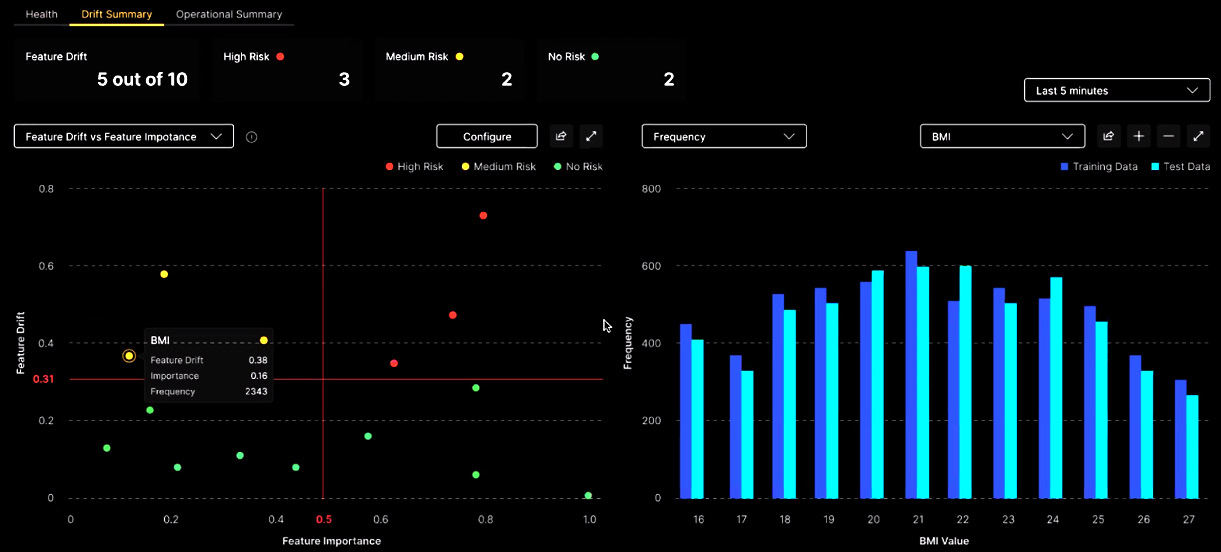
Figure 14.6 – Model-monitoring screen for H2O MLOps
The purpose of monitoring data drift is to detect whether the distribution of feature values in live scoring data is diverging from that in the training data from which the model was built. The presence of data drift suggests or indicates that the model should be retrained with more recent data and then redeployed to align with current scoring data.
In the lower-left panel in Figure 14.6, data drift for all model features is represented in two dimensions: drift on the vertical axis and feature importance on the horizontal axis. This view allows partitioning of drift into quadrants of drift importance, with high drift and high feature importance being the most important drift. Multiple settings are available to define the drift statistic, the time frame of measurement, and other aspects of viewing drift. There is also a workflow to configure automated alert messaging for drift. These can be used either for data scientists to manually decide on whether to retrain a model or for fully automated model retraining and deployment through H2O APIs.
Drift detection is just one of the capabilities of H2O MLOps. See the H2O documentation at https://docs.h2o.ai/mlops/ for a full description of H2O MLOps model deployment, monitoring, management, and governance capabilities.
Let's now look at how H2O-3 and Sparkling Water can integrate into H2O AI Feature Store.
Leveraging H2O AI Feature Store for feature operationalization and reuse
Enterprises often achieve economy of scale by centralizing and sharing environments or assets across the organization. H2O AI Feature Store achieves economy of scale by centralizing model features and the operationalization of their curation through engineering pipelines for reuse across the organization.
Reuse through the Feature Store occurs during both model-building and model-scoring contexts. For example, let's say that a valuable feature across the organization is the percentage change in asset price compared to the previous day. Imagine, though, that asset price is stored as price per day and asset prices are stored in multiple source systems. Feature Store handles retrieval of features from source systems and calculation of new values from the original (that is, the feature engineering pipeline) and caching the result (the engineered feature) to be shared for model training and model scoring. Model building uses an offline mode—that is, batched historical data—and uses an online mode for model scoring—that is, recent data. This is shown in the following diagram:

Figure 14.7 – Integration of H2O AI Feature Store with H2O-3 or Sparkling Water
Here's a summary of the workflow in Figure 14.7:
- A data scientist builds a model.
- During the model-building stage, the data scientist may interact with the feature store in two different ways, as outlined here:
- The data scientist may publish a feature to the Feature Store and include associated metadata to assist in search and operationalization by others. An ML engineer operationalizes the engineering of the feature from the data source(s) to feed the feature values in the feature store. Each feature is configured for how long it lives before being updated—for example, update each minute, day, or month.
- The data scientist may search the Feature Store for features during model building. They use the Feature Store API to import the feature and its value into the training data loaded by H2O-3 or Sparkling Water (more specifically, into the in-memory H2OFrame, which is analogous to a DataFrame).
- The model is deployed to H2O MLOps, which is configured to consume the feature from the feature store. The feature is updated at its configured interval.
- The predictions and—optionally—reason codes are consumed.
We have ended our workflows with predictions being consumed. Let's now showcase how the H2O Wave SDK can be used by data scientists and ML engineers to quickly build AI applications with sophisticated visualizations and workflows around model predictions.
Consuming predictions in a business context from a Wave AI app
ML models ultimately gain value when their outputs are consumed by personas or automation executing workflows. These workflows can be based on single predictions and underlying reason codes themselves or from insights and intelligence gained from them. For example, a customer service representative identifies customers who have a high likelihood of leaving the business and proactively reaches out to them with improvements or incentives to stay based on the reasons why the model made its prediction of likely churn. Alternatively, an analyst explores multiple interactive dashboards of churn predictions made in the past 6 months to gain insights into the causes of churn and identify where the business can improve to prevent churn.
As we learned in Chapter 13, Introducing H2O AI Cloud, H2O Wave is a low-code SDK used by data scientists and ML engineers to easily build AI applications and publish them to an App Store for enterprise or external use. What do we mean by an AI app? An AI app here is a web application that presents one or more stages of the ML life cycle as rich visualizations, user interactions, and workflow sequences. The H2O Wave SDK makes these easy to build by exposing UI elements (dashboard templates, dialogs, and widgets) as attributes-based Python code while abstracting away the complexities of building a web application.
In our example here, Wave apps are being used specifically by business personas to consume predictions, as shown in the following diagram. Note that our next example will be a Wave app used by data scientists to manage model retraining, and not to consume predictions:

Figure 14.8 – Prediction consumption in Wave AI applications
The ML workflow in Figure 14.8 is a familiar one but with a Wave app that consumes predictions. Wave's low-code SDK enables multiple integration protocols and thus allows predictions and reason codes to be consumed in real time from a REST endpoint or as a batch from a file upload or data warehouse connection, for example. As shown in the preceding diagram, from a business context, Wave apps that consume predictions can do the following:
- Visualize predictions from historical and individual prediction views
- Visualize insights from underlying prediction reason codes, from both global (model-level) and individual (single model-scoring) views
- Perform BI analytics on predictions and insights
- Perform workflows for humans in the loop to act on visualizations and analytics
Let's look at a specific example. The screenshot that follows shows one page of a Wave app that consumes and displays visualizations from predictions on employee churn—in other words, the predicted likelihood that employees will leave the company:

Figure 14.9 – A Wave app visualizing employee churn
This page shows views of the latest batch of employee-churn predictions. The upper-left panel shows the probability distribution of these predictions. We can see that most employees that were scored by the model have a low probability of leaving, though there is a long tail of higher-probability employees. The upper-right panel provides insights into why employees depart the company: it shows the Shapley values or feature contributions (reason codes) to the prediction. We see that overtime, job role, and shift schedule are the top three factors contributing to the model's predictions of churn. The bottom panels show visualizations to help understand these predictions better: the left panel displays a geographic distribution of churn likelihood, and the right shows a breakdown by job role. The thin panel above the map allows user interaction whereby the slider defines the probability threshold of classifying an employee as churn or no churn: the bottom two panels refresh accordingly as a result.
The previous screenshot of the Wave app visualized predictions at a batch level—that is, of all employees scored over a time period. The application also has a page that displays predictions visualized at the individual level. When the user clicks on an individual employee (displayed with associated churn probability and other employee data), Shapley values are displayed, showing the top features contributing to the likelihood of churn for that individual. A particular individual may show, for example, that monthly income is the larger contribution to the prediction and that overtime actually contributes to the individual not churning. This insight suggests that the employee may leave the company because they are not making enough money and are trying to make more. This allows the employee's manager to evaluate a salary increase to help guarantee they stay with the organization.
The UI in Figure 14.9 shows predictions placed in a business context where individuals can act upon them. Keep in mind that H2O Wave is quite extensible and can incorporate Python packages of your liking, including Python APIs, to non-H2O components. Also, remember that the example Wave app shown here is meant to be a capability demonstrator: it is not an out-of-the-box point solution to manage employee churn but rather an example of how data scientists and ML engineers can easily build AI applications using the Wave SDK.
H2O Wave SDK Is Very Extensible
The UI in Figure 14.9 is fairly simple but nevertheless effective in putting predictions into a business and analytical context. The H2O Wave SDK is quite extensible and thus allows greater layers of sophistication to be included in applications built from it.
You can, for example, implement HTML Cascading Style Sheets (CSS) to give the user experience (UX) a more modern or company-specific look. Because Wave applications are containerized and isolated from each other, you can install any Python package and use it in the application. You can, for example, implement Bokeh for powerful interactive visualizations or pandas for data manipulation, or a vendor or home-grown Python API to interact with parts of your technology ecosystem.
Note that the main intent of H2O Wave is for you to build your own AI applications with its SDK and to make them purpose-built for your needs. Applications are developed locally and can be prototyped quickly with intended users, then finalized, polished, and published to H2O App Store for enterprise role-based consumption. H2O will, however, provide example applications to you as code accelerators.
You can explore live Wave apps by signing up for a 90-day free trial of H2O AI Cloud at https://h2o.ai/freetrial/. You can also explore and use the H2O Wave SDK, which is open source, by visiting https://wave.h2o.ai/.
We have just explored how Wave apps can be built to consume predictions as part of a business analytic and decision-making workflow. Business users need not be the only Wave app users. Let's now look at a Wave app used by data scientists and built to drive the model-building and model-deployment stages of the ML life cycle.
Integrating an automated retraining pipeline in a Wave AI app
The H2O Wave SDK includes native APIs to other H2O AI Cloud components. This allows data scientists to build Wave apps to accomplish data-science workflows (compared to building applications in a business-user context, as shown in the previous example).
A common need in data science, for example, is to recognize data drift in deployed models and then retrain the model with recent data and redeploy the updated model. The following diagram shows how this can be done using a Wave app as both an automation orchestrator and UI for tracking the history of retraining and performing analytics around the history. This is an application idea and can be defined differently, but the general idea should be helpful.
Here, you can see an overview of the full ML workflow:

Figure 14.10 – A Wave app for automated model retraining
The workflow is summarized as follows:
- The model is built and evaluated in H2O-3 or Sparkling Water (or other H2O model-building engines, such as Driverless AI).
- The model is deployed to H2O MLOps and predictions are consumed. MLOps is configured to detect data drift on the model.
- At a point in time, drift exceeds configured thresholds for the model, and an alert is sent to the model-retraining Wave app that you have built.
- The model-retraining Wave app triggers the retraining of the model on the H2O model-building engine (in our case, H2O-3 or Sparkling Water). The Wave app deploys the retrained model as a challenger in H2O MLOps (using the MLOps API), and after a time, the Wave app evaluates the performances of the newly retrained challenger versus the existing champion model. The challenger is promoted to replace the champion if the former outperforms the latter. The cycle (steps 3 and 4) continues from this point.
The model-retraining Wave app can provide reporting, visualizations, and analytics around model retraining. For example, there could be a table of retraining history including time of retraining, drift measurement, current status (for example, training in progress, model deployed, and in challenger state or champion state), and so on. Visualizations could be provided that provide greater insights into the data drift and model-retraining and deployment pipeline. As an alternative, automation could be replaced by a human-in-the-loop workflow where steps in the pipeline are done manually based on data-scientist evaluations.
The goal of H2O Wave as an application-building framework is for you to easily build applications according to your own specifications and to integrate into the application other components in your ecosystem. So, you likely envision a model-retraining application a bit differently than what is shown here. The H2O Wave SDK allows you to build the application that you envision.
In our example model-retraining application, we integrated multiple H2O components into a Wave application workflow with visualizations and analytics. In the next section, we will expand integrations to non-H2O components of your ecosystem and thereby present a powerful framework to build Wave apps as a single pane of glass across your AI ecosystem.
A Reference H2O Wave app as an enterprise AI integration fabric
The low-code Wave SDK allows data scientists, ML engineers, and software developers to build applications that integrate one or more H2O components participating in the ML life cycle into a single application. H2O Wave is thus a powerful integration story.
Two Wave design facts need to be revisited, however, because they make this integration story even more powerful. First, Wave apps are deployed in containers and are thus isolated from other Wave apps. Second, developers can install and integrate publicly available or proprietary Python packages and APIs into the application. This means that H2O Wave apps can integrate both H2O and non-H2O components into a single application. This can effectively be restated as follows: H2O apps can be built as single panes of glass across your entire AI-related enterprise ecosystem. This is shown in the following diagram:
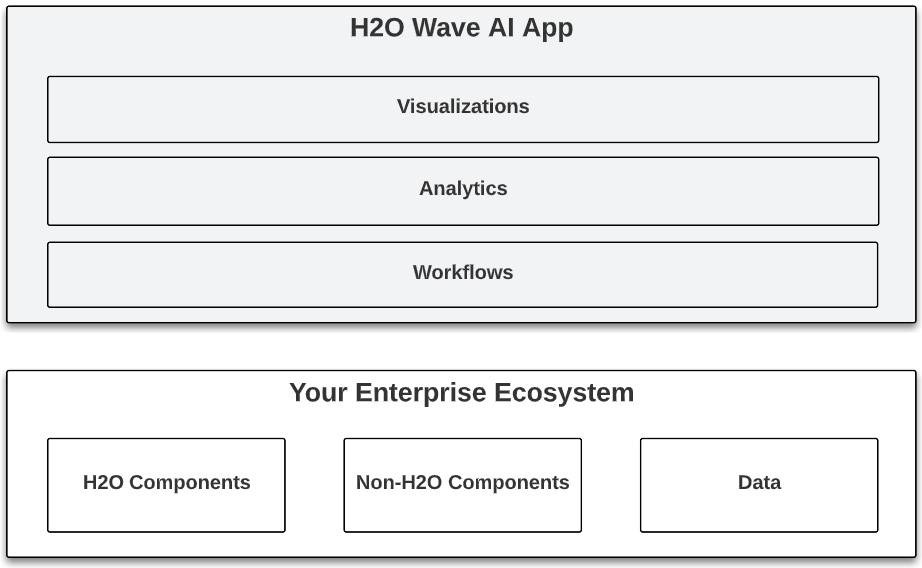
Figure 14.11 – H2O Wave AI app as a layer across your enterprise ecosystem
Data scientists, engineers, and software developers can thus build Wave apps that combine the end-to-end ML platform of H2O AI Cloud with AI-related and non-AI-related components of the enterprise ecosystem and its underlying cloud services. The diverse applications are hosted on H2O App Store with role-based access and thus made available to diverse enterprise stakeholder consumers. Let's break this down further by exploring the following diagram.

Figure 14.12 – Reference H2O Wave AI app layering across your enterprise ecosystem
This is a reference H2O Wave AI app showing its full potential to serve as a UI integration layer across your entire AI-related ecosystem. The goal is to show the full set of capabilities in this regard, and for you to use your imagination to instantiate this generalized reference into specific applications that fit your specific AI needs.
Let's review these capabilities, as follows:
- Low-code Python SDK: Wave's low-code Python SDK allows data scientists, ML engineers, and software developers to develop AI applications in a familiar Python style, focusing on populating data in widgets and templates and ignoring the complexity of web applications. The SDK can be extended with CSS style sheets to accomplish a specific look and feel if desired.
- Data connectors: The Wave SDK has over 140 connectors to diverse data sources and targets, making it easy to integrate Wave applications into your data ecosystem.
- H2O AI Cloud APIs: The Wave SDK has APIs for all components in the H2O AI Cloud platform: the four model-building engines and their provisioning tool, as well as the MLOps and Feature Store components. These integrations provide powerful ways to interact with all aspects of the ML life cycle from an application perspective. We have taken a quick glimpse of these possibilities in the scoring-consumption and model-retraining Wave applications discussed previously.
- Installed Python packages: The Wave SDK is extensible to any Python package you want to install. This allows you, for example, to extend the native Wave UI components with more specialized plotting or interactive visualization capabilities, or to use familiar packages to manipulate data.
- Installed Python APIs: You can also install Python libraries that serve as APIs to the rest of your enterprise ecosystem, whether it's your own components, non-H2O vendor components, or applications and native cloud services. This is a very powerful way to orchestrate ML workflows driven by APIs connected to H2O AI Cloud components with the capabilities across the rest of your enterprise ecosystem.
The capabilities and integrations just outlined open up a near unlimited number of ways for Wave apps to accomplish enterprise-AI analytics and workflows. You can, for example, integrate your model deployment and monitoring on H2O MLOps to existing multistep governance-process workflows. You can build UI workflows where users search data catalogs for authorized data sources, select a data source, and then launch and access an H2O model-building environment with the data source loaded. These are only two examples to get your mind started. As shown in Figure 14.11, there are many pieces you can tie together in your own specific and creative ways to extend ML beyond model building and scoring and to a larger context of workflows and multi-stakeholder business value.
Summary
In this chapter, we explored how H2O-at-scale technology (H2O-3, H2O Sparkling Water, H2O Enterprise Steam, and the H2O MOJO) expands its capabilities by participating in the larger H2O AI Cloud end-to-end machine learning ML platform. We saw, for example, how H2O-3 and Sparkling Water can gain from initial rapid prototyping and automated feature discovery. Likewise, we saw how H2O-3 and Sparkling Water models can be deployed easily to the H2O MLOps platform where they gain value from its model-scoring, monitoring, and management capabilities. We also saw how H2O AI Feature Store can operationalize features for sharing, both in model building with H2O-3 or Sparkling Water and model scoring on H2O MLOps.
We started exploring the power of H2O's open source low-code Wave SDK, and how data scientists, ML engineers, and software developers can use it to easily create visualizations, analytics, and workflows across H2O components and thus the full ML life cycle. These applications are published to the App Store component of the H2O platform where they are consumed by enterprise stakeholders or external partners or customers of the enterprise. One example Wave app that we explored was an employee-churn application to consume, understand, and respond to predictions on how likely individuals were to leave a company. Another was a model-retraining application where data scientists manage and track automated model-retraining workloads by leveraging the Wave app's underlying SDK integration with H2O-3 and H2O MLOps.
Finally, we introduced a reference Wave AI app to build applications that layer across H2O and non-H2O parts of the enterprise-AI ecosystem and thus form an enterprise-AI integration fabric.
We thus finish this book by taking ML at scale with H2O and putting it into the context of H2O's larger end to end machine learning ML platform called H2O AI Cloud. By marrying its established and proven H2O at scale technology with the new and rapidly innovating H2O AI Cloud platform, H2O.ai is continuing to prove itself as a bleeding-edge player in defining and creating new ML possibilities and value for the enterprise.