
Chapter 3: DataOps and Its Benefits
In Chapter 2, Data Engineering with Alteryx, we introduced Alteryx products, the DataOps framework, and how Alteryx products are accommodated within the DataOps framework. This chapter will look at the key benefits of applying DataOps and what rewards you will gain by implementing DataOps in your organization.
We will explore the principles of DataOps and investigate how they apply to Alteryx development. We will also look at the specifics of which tools in the Alteryx platform can implement the principles of DataOps.
Throughout this chapter, you will learn how Alteryx can help leverage the DataOps process and apply the principles in an Alteryx pipeline.
In this chapter, we will cover the following topics:
- The benefits the DataOps framework brings to your organization
- Understanding DataOps principles
- Applying DataOps to Alteryx
- Using Alteryx software with DataOps
- General steps for deploying DataOps in your environment
The benefits the DataOps framework brings to your organization
As a reminder, DataOps is the methodology that defines the systems and structures for building data pipelines. The most significant benefits of DataOps are as follows:
- Faster cycle times
- Faster access to actionable insights
- Improved robustness of data processes
- The ability to see the entire data flow in a workflow
- Strong security and confidence
These benefits have allowed me to deliver data pipelines to my customers and end-users faster. The speed of delivery enables end users to analyze their datasets and immediately provide the feedback needed to tune that dataset to the result they need. Additionally, the inclusion of testing, reporting, and monitoring has provided confidence in the dataset when delivering the completed project for them to maintain in the future.
For example, when building an integration pipeline for a customer, returning incremental workflow improvements faster allows feedback to be implemented in the next cycle. Next, by running a test suite that identifies our metrics during development, the end user is confident that the dataset delivers on its requirements. Additionally, we can use the test suite in production to ensure that the dataset continues to deliver on the requirements as expected.
These benefits are delivered through automation and reduced duplication. How we can achieve these benefits is explained in the next section.
Faster cycle times
With DataOps, we can achieve faster cycle times by applying a consistent process in developing the data pipelines. Furthermore, implementing this consistency means that a lot of the setup portion of a project is standardized, and we can minimize the duplication of processes across projects.
The faster cycle time also helps both end users and data engineers to enjoy the process more as they see tangible results sooner, and all parties can progress to the next step in their analysis.
Faster access to actionable insights
We can achieve actionable insights by standardizing repetitive parts of the process, for example, having a standardized and documented process for connecting external sources to internal databases. Additionally, any data tasks, such as everyday cleansing and control table updates, can be made into a reusable macro to simplify that part of the process.
Improved robustness of data processes
Implementing robust monitoring processes, such as applying Statistical Process Controls (SPCs), enables end users to be confident in the results of the data pipeline. The SPCs are an automated system for identifying when the variations in your dataset fall outside acceptable limits. These standardized processes allow teams to detect when errors might emerge and catch the outliers in the datasets so that they can be processed appropriately.
Provides an overview of the entire data flow
The core workflows in Alteryx give an overview of the process at the transformation level. For example, watching the data flow through a workflow, checking the transformations at each point, and monitoring the process controls provide an overview of the entire process.
When you add that to Connect's data lineage features, you can see the entire data flow from source through transformation, stopping at any intermediate staging files prior to final ingestion and consumption. This complete view of the data flow means we can assess the impact of any process changes. Again, this helps deliver the DataOps principles by improving data pipeline transparency and interaction between teams and developers.
Strong security and conformance
Finally, having a centralized platform for the analytics process allows for better management of the entire data estate. Having a view of who is interacting with data assets, which users should have access to those assets, and a centralized process for managing those processes allows for tight control of security and governance of the data pipeline.
With these benefits explained, we can learn what the DataOps principles are. We can also link the application of the DataOps principles to the benefits they will bring when we implement them in an organization.
Understanding DataOps principles
The DataOps principles are the set of guidelines that help deliver datasets and pipelines more efficiently. According to the DataOps manifesto (https://dataopsmanifesto.org/en/), 18 different principles are recommended. Those principles fall into three main pillars that form the basis of DataOps:
- People
- Delivery
- Confidence
We can see the pillars and a summary of the principles in Figure 3.1, and we will look at each principle in detail later in this chapter:
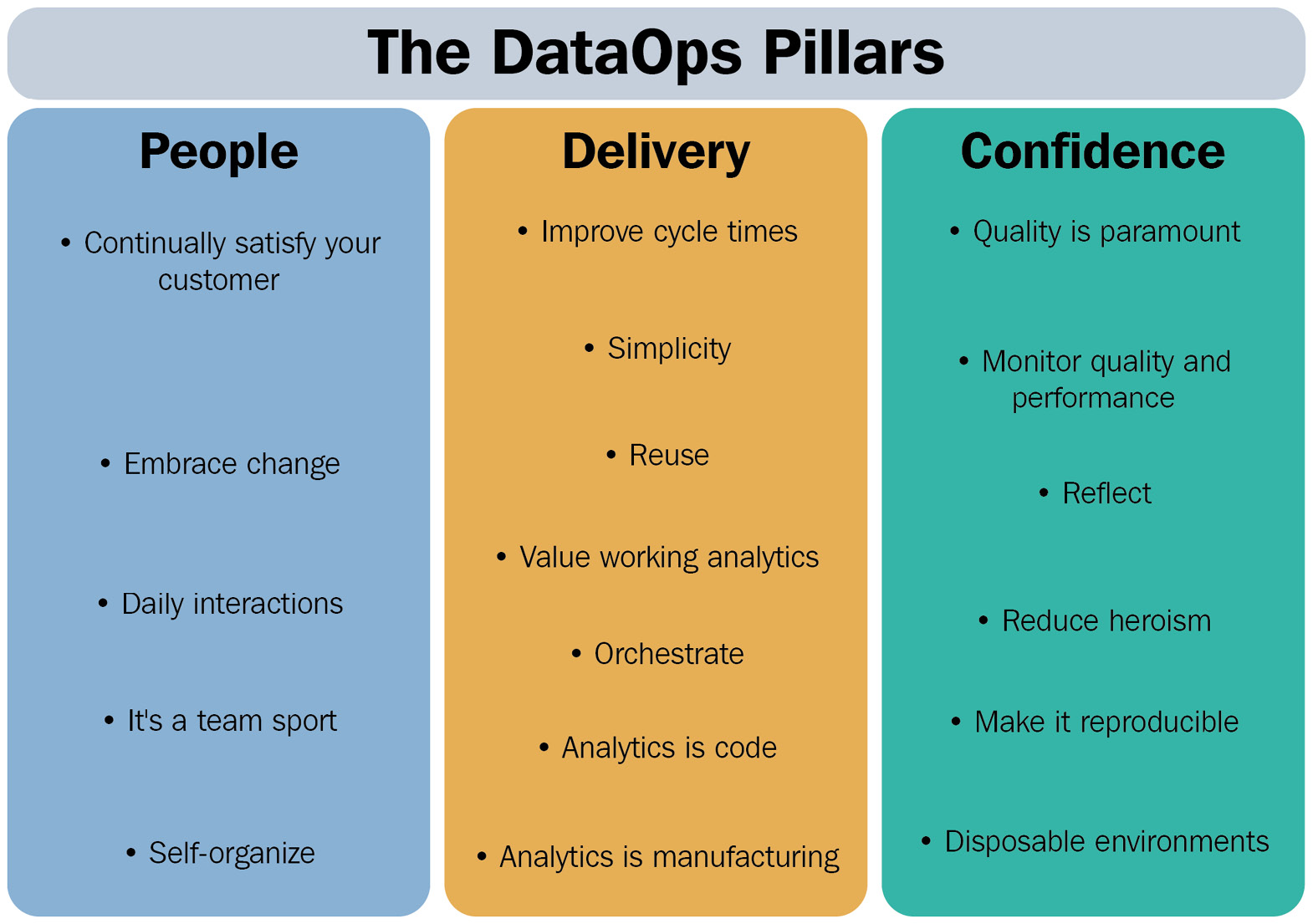
Figure 3.1 – The pillars and principles of the DataOps framework
But for now, we will investigate the themes of each pillar:
- The People pillar focuses on the culture that DataOps is trying to instill. It looks at both the data teams delivering the datasets and the end users who will consume the dataset. The principles in this pilar also encourage a close, iterative link between the end user and the data engineer, borrowing ideas from the Agile Development Framework.
- The Delivery pillar focuses on how to deliver a finished data product to the end user. It encompasses the production of resources, how the process is automated, and how, once delivered, a dataset can be continuously improved and developed.
- The Confidence pillar focuses on building each step of the data pipeline to ensure confidence in the process and that the final output is accurate; knowing that if there is a request to repeat the processing of a pipeline, the result would be the same; and knowing that when a decision is made based on the data provided, that decision and the insight it drives is the best and the most accurate it can be.
Let's look at each of the pillars and the principles that fit into those pillars.
The People pillar
As mentioned, the People pillar is all about the culture that DataOps wants to drive. It focuses on putting the end user or customer at the center of every decision made when delivering a data pipeline.
We can apply the following principles to achieve this culture:
- Continually satisfy your customer: Throughout the development process, communicate your progress with your customer and update the pipelines you are creating based on their feedback.
- Embrace change: Always be prepared to update and adapt your workflow and systems to implement the best practices as they evolve.
- Daily interactions: Communicate with your team and customers frequently to ensure expectations are always aligned.
- It's a team sport: Build a team with diverse roles, skills, and backgrounds and then, any individual assumptions about a particular topic can be tested and accessed collectively.
- Self-organize: Having a collection of skills in the team allows individuals to organize themselves into the best groups for any specific project that arises.
The DataOps principles that constitute the People pillar, described above, focus on creating a communicative culture. With a team of data engineers, data analysts, and data scientists, you can collectively solve any request made to you by the organization.
The Delivery pillar
Getting data reliably to the end user can be as challenging to deliver. Being able to serve data requests quickly and efficiently to the end user is made possible by the Delivery pillar. By following the Delivery pillar, you can make decisions quickly:
- Improve cycle times: It would be best to design processes to deliver a working data pipeline to the end user as soon as possible rather than create and deliver a monolithic approach.
- Simplicity: When you make each step in the data pipeline as simple as possible, this aids in troubleshooting the workflow. If you separate parts of the process into independent actions, it can help to isolate potential delivery issues.
- Reuse: Whenever possible, you should create reusable, easily implemented data processes. You can then reimplement those processes in new workflows.
- Value working analytics: Delivering a working dataset allows analytics to start, and the dataset can be refined once a functional pipeline is available.
- Orchestrate: This means having unified processes for managing the entire data pipeline, from pipeline creation, to automation, to monitoring.
- Analytics is code: By treating the analytic tools as code, they can be managed and reverted to a known working state and released in a systematic process.
- Analytics is manufacturing: You can continuously improve the process through many minor, incremental updates and modifications.
You are better able to serve and judge a data request by following these six principles. By implementing the improve cycle times, simplicity, and reuse principles, you can quickly create new datasets and minimize excess work. When a process is rebuilt or overcomplicated, it is harder to deliver a good data product. Improving cycle times means that a more extensive project is delivered in smaller chunks to ensure smooth completion.
The value working analytics principle focuses not on creating a pipeline or what tools you use to achieve the dataset, but on the actual data product delivered.
Finally, the last three principles are the functional parts of the data pipeline delivery. When you can orchestrate a process from ingestion to insight, you control all the different environments involved. You can manage the tool versions and server environment configuration. The Analytics is code principle highlights the fact that the process used to deliver a data product can be examined and checked. The Analytics is manufacturing principle highlights the fact that the pipeline you create is an analytic insights product, which means you can continuously improve the process.
The Confidence pillar
The Confidence pillar is about creating the conditions to support the confidence of your end users in your data pipeline. For example, suppose end users have doubts regarding the datasets due to inconsistent processing or unexplained errors. In that case, the issues erode the value of your pipeline, and those users will not engage with your datasets. The following principles help build the systems needed to ensure that your end users are confident that the data you are providing is accurate and valuable to them:
- Quality is paramount: Making sure the datasets and pipelines you deliver provide accurate values is central to producing a valuable dataset.
- Monitor quality and performance: Designing systems to monitor the datasets you create and the performance of the data pipelines should be included as part of the development cycle and not an addition to an otherwise completed project
- Reflect: You should take the time to go back over established data pipelines and apply any new skills you have learned or learn about new features added to your software stack.
- Reduce heroism: Finding ways to transfer pipeline-specific knowledge will reduce dependency on specific people and allow team members to switch between projects when needed.
- Make it reproducible: Ensuring that a pipeline can be rerun at any time so that you can recreate the dataset if needed.
- Disposable environments: You should be able to quickly and easily create development and deployment environments. This ease of creation means any testing process has minimal impact on secondary systems and developers can implement changes confidently, as what they are doing can be controlled.
These six principles combine to provide the systems and controls to support your data pipeline deployments. In addition, they provide the mechanisms for managing the data and pipelines while also emphasizing that processes should be continuously improved when put into production.
If end users don't have confidence in a dataset or developers aren't confident in the environments they are trying to develop, it can result in stagnating datasets and poor pipeline performance. However, you can manage and minimize those risks if you implement these pillars.
Applying DataOps to Alteryx
Now that we know the principles and the pillars of DataOps, how does DataOps work with Alteryx? Like any tool you can use with DataOps, some principles integrate into the Alteryx platform very easily. In contrast, other principles need to be considered carefully for the best results.
Supporting the People pillar with Alteryx
Building a culture with Alteryx to support the People pillar enables the flexibility to approach any problem. You can continually deliver the minimum viable product to the customer and adapt to customers' demands with fast development speeds. Alteryx Development follows an iterative process that matches the DataOps principles. Additionally, lean manufacturing, which also forms the basis of DataOps principles, encourages the continuous improvement that Alteryx development supports.
Another benefit of the Alteryx platform for the People pillar is the code-friendly capabilities of the software. While Alteryx is primarily a code-free, GUI-based tool, features such as the Python tool, the R tool, and the Run command tool allow external processes to be integrated into a workflow easily. This flexibility enables you to leverage a range of tools within the same platform.
Leveraging the team sport and self-organizing principles with Alteryx is about applying the mentality that delivers the best results for an Alteryx developer. This mentality is to work iteratively and take advantage of the community resources available. Additionally, with multiple team members working together, each person can look at the problem and identify any issues and questions that might impede a project's progress.
Using Alteryx to deliver data pipelines
The principles in the Delivery pillar are focused on getting data to end users as quickly and efficiently as possible. Alteryx can help by leveraging its code-free base practically and delivering quickly through fast iterations and simple, easy-to-understand workflows. Additionally, you can easily reuse processes by packaging them into macros.
How you deliver a project in Alteryx has a strong correlation with the DataOps principles. For example, development is cycled quickly through each iteration, the visual workflow can be easily understood and followed, and you can package any repeated sections or processes for reuse.
The principle of valuing working analytics, where you deliver a complete project in smaller working chunks, is leveraged at each stage in workflow development. For example, when building an Alteryx workflow, the datasets are checked frequently with the browse anywhere feature, examined in-depth with browse tools, and can be sense checked using summary functions, charts, and test checks. In addition, a working pipeline is needed to deliver a dataset to your end user and that pipeline enables you to verify the process used.
We fill the final three principles in the Alteryx platform as part of the underlying make-up of the software. Alteryx manages process orchestration either inside the ecosystem or by leveraging outside tools to deliver the end-to-end pipeline. Each Alteryx workflow contains the details of the specific software version that ran the data pipeline. Because the specifics are held in the Alteryx file's XML recording the pipeline, treating an Alteryx workflow as you would any other code with standard software version control can be executed.
One challenge with treating an Alteryx workflow as code is that because it is a visual interface, the small visible changes that an Alteryx data engineer might make can cause the difference in tracking in version control software challenging to interpret. This challenge stems from deciding whether this change in the XML is essential to the workflow or just visual.
Building confidence with Alteryx
Ensuring the quality and performance of Alteryx pipelines is not created automatically within the Alteryx platform. Recording the workflow runtime information happens automatically, saving the run details in the Alteryx Server database, but it must be deliberately extracted and analyzed. You can employ sub-workflows or sub-processes in the data pipeline to check the quality of the records.
Alteryx can leverage the principle of reducing heroism through the readability of the workflows. This readability means that other data engineers can take over a pipeline relatively quickly. Even when unplanned, this easy workflow handover is supported by the self-documenting nature of an Alteryx workflow. When documentation best practices are adhered to, the handover process is even more straightforward. Even so, you can navigate unplanned handovers with automated documentation.
Alteryx leverages the reproducible development and disposable environment principles because Alteryx does not change the underlying data without explicitly forcing a write process. Because all workflows are non-destructive, developers can test and iterate ideas and try novel processes without affecting the underlying data infrastructure. Additionally, when creating a new environment for an Alteryx developer, the base install contains the functionality required to run any workflow.
The limitation of this in the Alteryx environment is that it doesn't include any custom reusable macros. However, suppose a consistent process is implemented to save and access these reusable processes, such as saving to a consistent network location or cloud storage provider. In that case, you can easily add those macros to any new development environment.
Deploying DataOps with Alteryx starts with understanding the mindset and places where you are using Alteryx. Where we can achieve this has been discussed, but we also need to see how to use each Alteryx program in DataOps projects.
Using Alteryx software with DataOps
The Alteryx platform components of Designer, Server, and Connect deliver the parts needed to support the DataOps framework pillars and fulfill the principles that make up those pillars. Each of the different software components fits across the People, Delivery, and Confidence pillars, serving the various functions needed to deliver in a DataOps framework.
In Figure 3.2, we have the same pillars from earlier, but with an overlay of where each Alteryx product interacts with the different pillars:

Figure 3.2 – DataOps pillars overlayed with the Alteryx products
In the diagram, we can see the three DataOps principles and how Designer supports the People and Delivery pillars, Connect enables the Confidence pillar, while Server supports the principles across all pillars.
Alteryx Designer
Building a DataOps pipeline will always start with development in Alteryx Designer. First, the quick iteration that I have been speaking about allows for continuous satisfaction and allows the data engineer to embrace any changes during the project. Next, Designer enables the team sport and self-organization principles. Each person in the team can interact using the same visual design process while bringing their expertise with any specific language or tool and leveraging that in Alteryx.
For the Delivery pillar, you can find the repeated processes that appear in a data pipeline and extract them into a reusable macro. We can make these macros available to other team members so that they don't have to recreate work. It also increases the simplicity of the process as the visual clutter associated with the standardized approach can be simplified to a single tool.
Finally, you can build confidence in the datasets with Designer by designing performance and monitoring solutions. Next, ensuring the quality of datasets is enabled by creating insight dashboards that monitor data processing.
Alteryx Server
The next component for supporting DataOps is Server. This allows the automation of pipelines created in Designer. This central processing of workflows also manages the process for simple version control and the sharing of workflows and parameterized applications throughout the organization.
Once you save the workflows to Server, any insights you develop in relation to quality control can be automatically populated and monitored in the Server Gallery web interface. Automating running workflows in Server removes the heroism or key man risk that might otherwise be present for an Alteryx data pipeline.
Finally, centralizing workflows to a single server gallery allows silos to be broken across organizations and cross-company teams to be established. Additionally, those cross-company teams can self-organize using collections for sharing and management when Server administrators set the permissions to allow it.
Alteryx Connect
The final orchestrating capability is incorporated into the Alteryx platform by using Connect to share all resources across the organization from Alteryx or elsewhere. In addition, the Connect platform allows for the discovery of reusable workflow components, existing datasets and reports, and any other content assets that might answer the end user's questions without needing a new project.
Showing the lineage of the datasets strengthens users' confidence. When users see the transformations and where other colleagues use the datasets, they gain community validation for a dataset. In addition, the Connect software can reveal the quality monitoring workflows, insights, and dashboards that are already available.
The People pillar is supported by putting users who need access to an asset in contact with its owners. It can build a community knowledge base around those existing assets for users and facilitate communication to answer different questions.
We have talked about the concepts of how Alteryx works with DataOps and what each Alteryx program delivers within DataOps. We can now investigate the steps to deploy a DataOps project with Alteryx.
General steps for deploying DataOps in your environment
Now that we know what the DataOps principles are and what parts of Alteryx build the DataOps pipeline, how would you implement DataOps into your company? The best way to demonstrate this would be to introduce an example we will use for our example process throughout the rest of this book.
The data pipeline example we will be following is this:
As a company, we want to enrich our marketing efforts by integrating regularly updated public datasets. We need to identify the source of these datasets (and make sure we have the legal authority to use them) and transform them to match our company areas. Then, we have to make them available to both the data science team for machine learning and to our operational teams across the organization.
This problem statement works well in identifying the process we need to implement, shown in Figure 3.3:

Figure 3.3 – An example process for starting a DataOps project
With the method shown in the preceding diagram, we can explore what each step represents:
- Find the Data Source: When identifying the public data source, we need to ensure that we have a commercial license to use it. This license is necessary to safeguard the fact that any value we extract for the business is legal. We should also investigate the creation of the raw data and ensure that we address any ethical concerns.
- Download Raw Data: Once we have identified the dataset we want, we need to begin the extraction process. We should have an automated process for extracting the data so that any data updates are collected.
- Stage Data: With the raw data in hand, we need to save this to a company-controlled location for future transformations. This raw dataset should also never be modified so future analysis can start from the unaltered raw data.
- Build a Transformation Pipeline: With the raw data in our control, we now need to transform it into a format that will work for our application. This process will also ingest the dataset into our analytical database.
- Build a Monitoring System: With a strategy for ingesting the dataset defined, we will deploy an automated monitoring process with notifications so that we can identify any anomalies or errors and address them.
- Hand Over Initial Dataset: We can now get the dataset to end users to assess the dataset for their applications. This step is the first of our delivery milestones and should be delivered as quickly as possible.
- Review Process and Feedback Loop: The final step in our delivery process requires regular feedback from our end users to maintain data quality. We can also improve usefulness over time in response to the feedback that our users provide.
These general steps are common to any data pipeline. But, of course, we do not address every requirement, and there is plenty of flexibility to go outside this process when needed. And not all steps are necessary for every situation; the dataset might be internal and require modification for a new application. However, this provides a reasonable basis for implementing a DataOps project.
Summary
Now that we have our DataOps principles and understand how they work in the three pillars of People, Delivery, and Confidence, we learned the specifics of building a data pipeline with Alteryx and how to implement these principles.
The following section looked at the different processes for accessing data sources on the basis of the DataOps framework. Then, we learned how to transform those datasets with Alteryx and publish them in other storage locations. And finally, we used Alteryx to build reports and visualizations in value extraction processes.
In the next chapter, we will start by accessing internal data sources, whether those data sources are files or database connections. We will then look at how we can access external data sources, either open public or private secured data sources. Then we will look at some of the initial processes for making sure our sourced data is in a raw format for us to use.