
Developing in MRUnit and local mode are complementary. MRUnit provides an elegant way to test the map and reduce phases of a MapReduce job. Initial development and testing of jobs should be done using this framework. However, there are several key components of a MapReduce job that are not exercised when running MRUnit tests. Two key class types are InputFormats and OutFormats.
Running jobs in local mode will test a larger portion of a job. When testing in local mode, it is also much easier to use a significant amount of real-world data.
This recipe will show an example of configuring Hadoop to use local mode and then debugging that job using the Eclipse debugger.
You will need to download the weblog_entries_bad_records.txt dataset from the Packt website, http://www.packtpub.com/support. This example will use the CounterExample.java class provided with the Using Counters in a MapReduce job to track bad records recipe.
- Open the
$HADOOP_HOME/conf/mapred-site.xmlfile in a text editor. - Set the
mapred.job.trackerproperty value tolocal:<property> <name>mapred.job.tracker</name> <value>local</value> </property> - Open the
$HADOOP_HOME/conf/core-site.xmlfile in a text editor. - Set the
fs.default.nameproperty value tofile:///:<property> <name>fs.default.name</name> <value>file:///</value> </property>
- Open the
$HADOOP_HOME/conf/hadoop-env.shfile and add the following line:export HADOOP_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=7272"
- Run the
CountersExample.jarfile by passing the local path to theweblog_entries_bad_records.txtfile, and give a local path to an output file:$HADOOP_HOME/bin/hadoop jar ./CountersExample.jar com.packt.hadoop.solutions.CounterExample /local/path/to/weblog_entries_bad_records.txt /local/path/to/weblog_entries_clean.txtYou'll get the following output:
Listening for transport dt_socket at address: 7272 - Open the Counters project in Eclipse, and set up a new remote debug configuration.
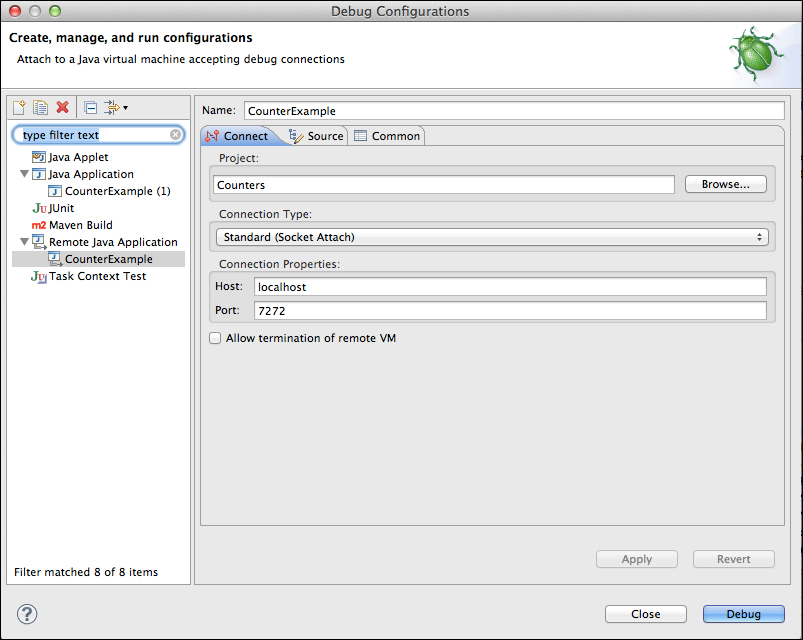
- Create a new breakpoint and debug.
A MapReduce job that is configured to execute in local mode runs entirely in one JVM instance. Unlike the pseudo-distributed mode, this mode makes it possible to hook up a remote debugger to debug a job. The
mapred.job.tracker property set to local informs the Hadoop framework that jobs will now run in the local mode. The
LocalJobRunner class, which is used when running in local mode, is responsible for implementing the MapReduce framework locally in a
single process. This has the benefit of keeping jobs that run in local mode as close as possible to the jobs that run distributed on a cluster. One downside to using LocalJobRunner
is that it carries the baggage of setting up an instance of Hadoop. This means even the smallest jobs will require at least several seconds to run. Setting the fs.default.name property value to file:/// configures the job to look for input and output files on the local filesystem. Adding export HADOOP_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=7272" to the hadoop-env.sh file configures the JVM to suspend processing and listen for a remote debugger on port 7272 on start up.