
HDFS provides shell command access to much of its functionality. These commands are built on top of the HDFS FileSystem API. Hadoop
comes with a shell script that drives all interaction from the command line. This shell script is named hadoop and is usually located in $HADOOP_BIN, where
$HADOOP_BIN is the full path to the Hadoop binary folder. For convenience, $HADOOP_BIN should be set in your $PATH environment variable. All of the Hadoop filesystem shell commands take the general form
hadoop fs -COMMAND.
To get a full listing of the filesystem commands, run the
hadoop shell script passing it the fs option with no commands.
hadoop fs
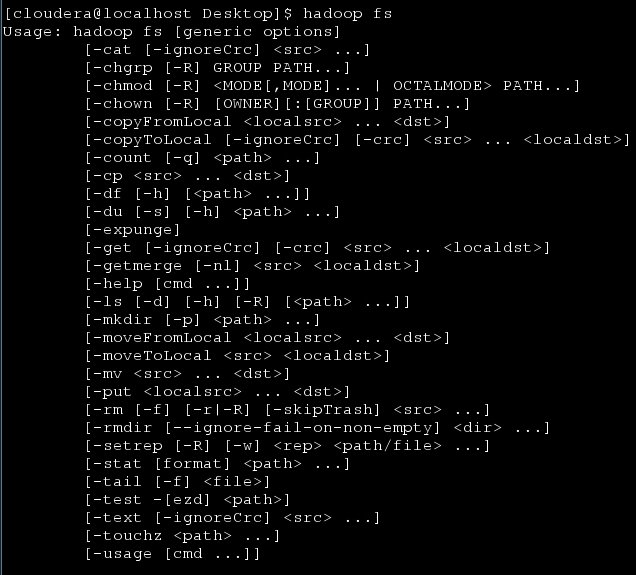
These command names along with their functionality closely
resemble Unix shell commands. To get more information about a particular command, use the help option.
hadoop fs –help ls
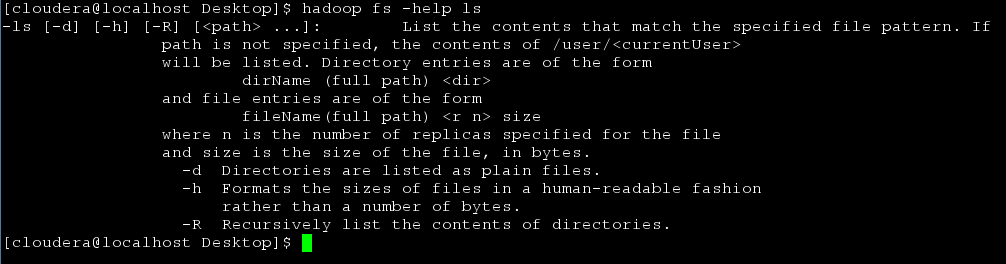
The shell commands and brief descriptions can also be found online in the official documentation located at http://hadoop.apache.org/common/docs/r0.20.2/hdfs_shell.html
In this recipe, we will be using Hadoop shell commands to import data into HDFS and export data from HDFS. These commands are often used to load ad hoc data, download processed data, maintain the filesystem, and view the contents of folders. Knowing these commands is a requirement for efficiently working with HDFS.
You will need to download the weblog_entries.txt
dataset from the Packt website http://www.packtpub.com/support.
Complete the following steps to create a new folder in HDFS and copy the weblog_entries.txt file from the local filesystem to HDFS:
- Create a new folder in HDFS to store the
weblog_entries.txtfile:hadoop fs –mkdir /data/weblogs
- Copy the
weblog_entries.txtfile from the local filesystem into the new folder created in HDFS:hadoop fs –copyFromLocal weblog_entries.txt /data/weblogs
- List the information in the
weblog_entires.txtfile:hadoop fs –ls /data/weblogs/weblog_entries.txt

Note
The result of a job run in Hadoop may be used by an external system, may require further processing in a legacy system, or the processing requirements might not fit the MapReduce paradigm. Any one of these situations will require data to be exported from HDFS. One of the simplest ways to download data from HDFS is to use the Hadoop shell.
- The following code will copy the
weblog_entries.txtfile from HDFS to the local filesystem's current folder:hadoop fs –copyToLocal /data/weblogs/weblog_entries.txt ./weblog_entries.txt

When copying a file from HDFS to the local filesystem, keep in mind the space available on the local filesystem and the network connection speed. It's not uncommon for HDFS to have file sizes in the range of terabytes or even tens of terabytes. In the best case scenario, a ten terabyte file would take almost 23 hours to be copied from HDFS to the local filesystem over a 1-gigabit connection, and that is if the space is available!
Tip
Downloading the example code for this book
You can download the example code files for all the Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
The Hadoop shell commands are a convenient wrapper around the HDFS FileSystem API. In fact, calling the hadoop shell script and passing it the fs option sets the Java application entry point to the
org.apache.hadoop.fs.FsShell class. The FsShell class then instantiates an
org.apache.hadoop.fs.FileSystem object and maps the filesystem's methods to the fs command-line arguments. For example, hadoop fs –mkdir /data/weblogs, is equivalent to FileSystem.mkdirs(new Path("/data/weblogs")). Similarly, hadoop fs –copyFromLocal weblog_entries.txt /data/weblogs is equivalent to FileSystem.copyFromLocal(new Path("weblog_entries.txt"), new Path("/data/weblogs")). The same applies to copying the data from HDFS to the local filesystem. The
copyToLocal Hadoop shell command is equivalent to FileSystem.copyToLocal(new Path("/data/weblogs/weblog_entries.txt"), new Path("./weblog_entries.txt")). More information about the FileSystem class and its methods can be found on its official Javadoc page: http://hadoop.apache.org/docs/r0.20.2/api/org/apache/hadoop/fs/FileSystem.html.
The mkdir command takes the general form of hadoop fs –mkdir PATH1 PATH2. For example, hadoop fs –mkdir /data/weblogs/12012012 /data/weblogs/12022012 would create two folders in HDFS: /data/weblogs/12012012 and /data/weblogs/12022012,
respectively. The mkdir command returns 0 on success and -1 on error:
hadoop fs –mkdir /data/weblogs/12012012 /data/weblogs/12022012 hadoop fs –ls /data/weblogs
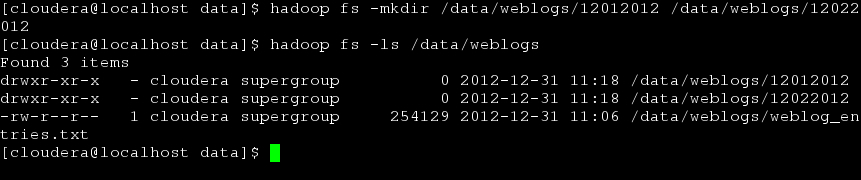
The copyFromLocal
command takes the general form of hadoop fs –copyFromLocal LOCAL_FILE_PATH URI. If the URI is not explicitly given, a default is used. The default value is set using the fs.default.name property from the core-site.xml file. copyFromLocal returns 0 on success and -1 on error.
The copyToLocal command takes the general form of hadoop fs –copyToLocal [-ignorecrc] [-crc] URI LOCAL_FILE_PATH. If the URI is not explicitly given, a default is used. The default value is set using the fs.default.name property from the core-site.xml file. The
copyToLocal command does a
Cyclic Redundancy Check (CRC) to verify that the data copied was unchanged. A
failed copy can be forced using the optional –ignorecrc argument. The file and its CRC can be copied using the optional –crc argument.
The command put is similar to copyFromLocal. Although put is slightly more general, it is able to copy multiple files into HDFS, and also can read input from stdin.
The get Hadoop shell command can be used in place of the copyToLocal command. At this time they share the same implementation.
When working with large datasets, the output of a job will be partitioned into one or more parts. The number of parts is determined by the mapred.reduce.tasks property which can be set using the
setNumReduceTasks() method on the JobConf class. There will be one part file for each reducer task. The number of reducers that should be used varies from job to job; therefore, this property should be set at the job and not the cluster level. The default value is 1. This means that the output from all map tasks will be sent to a single reducer. Unless the cumulative output from the map tasks is relatively small, less than a gigabyte, the default value should not be used. Setting the optimal number of reduce tasks can be more of an art than science. In the JobConf documentation it is recommended that one of the two formulae be used:
0.95 * NUMBER_OF_NODES * mapred.tasktracker.reduce.tasks.maximum
Or
1.75 * NUMBER_OF_NODES * mapred.tasktracker.reduce.tasks.maximum
For example, if your cluster has 10 nodes running a task tracker and the mapred.tasktracker.reduce.tasks.maximum property is set to have a maximum of five reduce slots, the formula would look like this 0.95 * 10 * 5 = 47.5. Since the number of reduce slots must be a nonnegative integer, this value should be rounded or trimmed.
The JobConf documentation provides the following rationale for using these multipliers at http://hadoop.apache.org/docs/current/api/org/apache/hadoop/mapred/JobConf.html#setNumReduceTasks(int):
With 0.95 all of the reducers can launch immediately and start transferring map outputs as the maps finish. With 1.75 the faster nodes will finish their first round of reduces and launch a second wave of reduces doing a much better job of load balancing.
The partitioned output can be referenced within HDFS using the folder name. A job given the folder name will read each part file when processing. The problem is that the get and copyToLocal
commands only work on files. They cannot be used to copy folders. It would be cumbersome and inefficient to copy each part file (there could be hundreds or even thousands of them) and merge them locally. Fortunately, the Hadoop shell provides the getmerge command to merge all of the distributed part files into a single output file and copy that file to the local filesystem.
The following Pig script illustrates the getmerge command:
weblogs = load '/data/weblogs/weblog_entries.txt' as
(md5:chararray,
url:chararray,
date:chararray,
time:chararray,
ip:chararray);
md5_grp = group weblogs by md5 parallel 4;
store md5_grp into '/data/weblogs/weblogs_md5_groups.bcp';The Pig script can be executed from the command line by running the following command:
pig –f weblogs_md5_group.pig
This Pig script reads in each line of the weblog_entries.txt file. It then groups the data by the md5 value. parallel 4 is the Pig-specific way of setting the number of mapred.reduce.tasks. Since there are four reduce tasks that will be run as part of this job, we expect four part files to be created. The Pig script stores its output into /data/weblogs/weblogs_md5_groups.bcp.

Notice that weblogs_md5_groups.bcp is actually a folder. Listing that folder will show the following output:
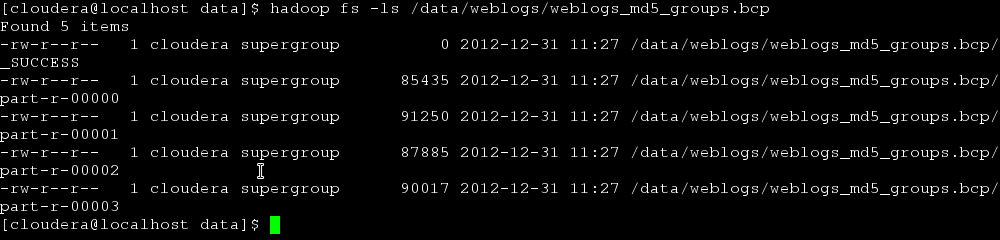
Within the /data/weblogs/weblogs_md5_groups.bcp folder, there are four part files: part-r-00000, part-r-00001, part-r-00002, and part-r-00003.
The getmerge command can be used to merge all four of the part files and then copy the singled merged file to the local filesystem as shown in the following command line:
hadoop fs –getmerge /data/weblogs/weblogs_md5_groups.bcp weblogs_md5_groups.bcp
Listing the local folder we get the following output:

- The Reading and writing data to HDFS recipe in Chapter 2, HDFS shows how to use the FileSystem API directly.
- The following links show the different filesystem shell commands and the Java API docs for the
FileSystemclass: