
Chapter 1 – The Aster Data Architecture
“Design is not just what it looks like and feels like. Design is how it works.”
- Steve Jobs
What is Parallel Processing?
“After enlightenment, the laundry”
- Zen Proverb

“After parallel processing the laundry, enlightenment!”
-Aster Zen Proverb
Two guys were having fun on a Saturday night when one said, “I’ve got to go and do my laundry.” The other said, “What?!” The man explained that if he went to the laundry mat the next morning, he would be lucky to get one machine and be there all day. But, if he went on Saturday night, he could get all the machines. Then, he could do all his wash and dry in two hours. Now that’s parallel processing mixed in with a little dry humor!
Aster Data is a Parallel Processing System

The queen takes the request from the user and builds the plan for the vworkers. The vworkers retrieve their portion of the data and pass the results to the queen. The queen delivers the answer set to the user.
Each vworker holds a portion of every table and is responsible for reading and writing the data that it is assigned to and from its disk. Queries are submitted to the queen who plans, optimizes, and manages the execution of the query by sending the necessary subqueries to each vworker. Each vworker performs its subquery or subqueries independent of the others, completely following only the queen’s plan. The final results of queries performed on each vworker is returned to the queen where they can be combined and delivered back to the user.
Each vworker holds a Portion of Every Table

Every vworker has the exact same tables, but each vworker holds different rows of those tables.
When a table is created on Aster, each vworker receives that table. When data is loaded, the rows are hashed by a distribution key, so each vworker holds a certain portion of the rows. If the queen orders a full table scan of a particular table, then all vworkers simultaneously read their portion of the data. This is the concept of parallel processing.
The Rows of a Table are Spread Across All vworkers
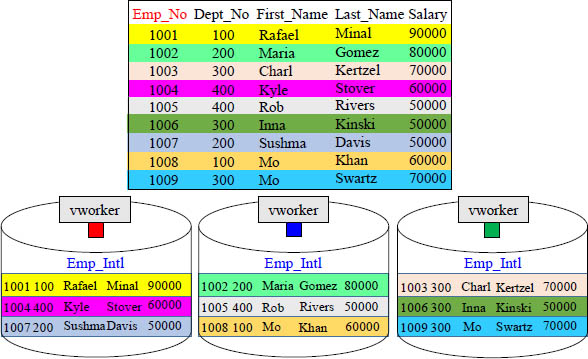
A Distribution Key will be hashed to distribute the rows among the vworkers. Each vworker will hold a portion of the rows. This is the concept behind parallel processing.
The Aster Data Architecture

Aster can scale to thousands of nodes which are standard, inexpensive commodity x86 servers with locally-attached disk storage and networked with other nodes using commodity Gigabit Ethernet (GigE) technology. The Queen Node is the brains behind the operation. The Worker Nodes hold the data and do the processing based on the Queen’s plan. The Loader Nodes load the data and export data off of Aster. The Backup node provides large disks that backup and restore data to the Aster system.
The Queen Node
Queen Node
• The queen node comes up with a plan for the vworkers to retrieve their portion of the data.
• The queen is the coordinator of how the data is distributed across vworkers.
• The queen delivers the answer set to the end user.
• The queen node is the software coordinator and keeper of the data dictionary and other system tables.
• You can maintain an inactive queen as a backup.
• The queen provides the cluster logic that glues all nodes of the system together. The queen is responsible for all cluster, transaction, and storage management aspects of the system.
The Worker Node

• Worker nodes are where the data is stored and analyzed.
• A worker node is comprised of multiple vworkers.
• Each vworker has their own storage, and the vworkers work in parallel to process data simultaneously.
• The queen communicates with vworkers via standard SQL, and the vworkers on various worker nodes communicate with each other.
The Loader Node

• The Aster Database Loader utility and loader nodes form the massively parallel backbone of the Aster Database for performing data loads and exports.
• Loader nodes are designed to be CPU-heavy nodes that have no major disk capacity.
• These independent nodes also help isolate loads and exports from query processing.
• The Aster Database Loader utility communicates with loader nodes and acts as a landing zone for bulk data during both loads and exports.
• Because of this brilliant design, Aster can process queries while loading fresh data, and it can process queries and loads while exporting data off of Aster.
The loader nodes handle all aspects of load and export: transforming and reformatting data. When loading, the loader nodes also generate the hash keys and perform compression. The loader nodes handle the processor intensive functions normally required by the host in most systems, thus providing great import and export capabilities while queries and backups are running simultaneously.
The Backup Node

• Aster can backup your entire Aster system or just individual tables on backup nodes.
• The backup nodes are not an Aster Database. Instead, they are a set of disk-heavy Aster Database Backup Nodes designed for backup purposes only.
• The Backup Nodes can be used to restore data to the Aster Database.
• A backup administrator starts a backup by interacting with the Aster Database Backup Terminal.
• The data on the Backup Nodes are compressed (about 3:1 ratio) for smart space savings on data storage. Recovery is fast and easy.
• Aster can process queries or loads while backing up data.
The Backup nodes store compressed data that is transferred in parallel directly from the worker nodes. Backup nodes are configured with large, high capacity disks to reduce the cost per unit of backup storage. Most systems require backups to tape, but Aster Data uses Backup Nodes to accomplish this so data can be restored easily and quickly. Aster requires no downtime for either restoring replicas after a node failure or redistributing data after a new node is added.
The Aster Architecture Interconnect

The Interconnect allows the Queen to communicate with the vworkers and also allows the vworkers to communicate and transfer data to each other.
The Interconnect is the network that is used for queries. The Queen accepts the SQL or Map Reduce statement from the user, builds a plan for the vworkers to follow, and communicates the plan over the Interconnect. Each vworker receives its instructions simultaneously and begins processing. If the vworkers need to transfer data among themselves, the Interconnect provides that communications highway. Once the vworkers have completed their assignment, they pass their portion of the answer set to the queen via the Interconnect. The Queen then puts together the final answer set and delivers it to the user.
Backup and Loader Nodes Do Not use the Interconnect
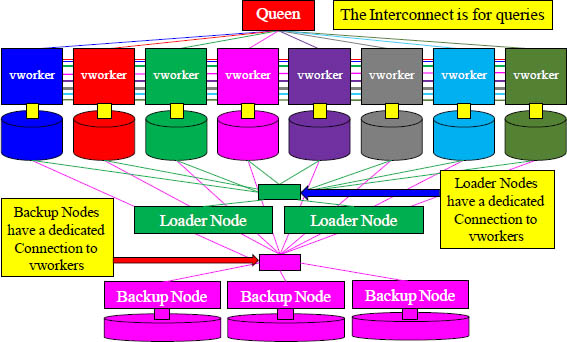
The Interconnect is the network the Queen and vworkers use for queries, so it is of the utmost importance to keep this communications highway clear and dedicated to queries. The Loader and Backup nodes use a different communications connection to load, export, backup, and restore data. This allows for data loading and exporting as well as backup and restore, to happen without disrupting the queries.
The Aster Architecture has Spare Nodes

Each node is a commodity server
The Queen is the brains behind everything. She comes up with a plan and instructs the workers how to retrieve the data. The workers hold the database tables and read and write the data. The loader nodes load the data into Aster and export the data off of Aster. The backup nodes backup the Aster Database and are used to recover the data upon a disaster. The spare nodes can be configured quickly in case of a failure. Each Spare node can be configured for whatever purpose is needed.
The Aster Architecture Allows Flexibility based on Need

This system was configured to place more emphasis on the vworkers and the loading.
The Aster Architecture allows you to scale nodes to achieve true Massively Parallel Processing, but the brilliance of the architecture is that you can configure nodes to place more power where you need it.
Aster Data Provides Four Fundamental Hardware Strengths

![]() Commodity hardware – Nodes can be from HP, Dell, IBM, Sun Servers, and Cisco Switches.
Commodity hardware – Nodes can be from HP, Dell, IBM, Sun Servers, and Cisco Switches.
![]() Processor Capacity–Adding a Worker Node adds additional processor capacity.
Processor Capacity–Adding a Worker Node adds additional processor capacity.
![]() Memory Capacity – Adding a Worker Node adds additional memory capacity that is balanced with the additional processors.
Memory Capacity – Adding a Worker Node adds additional memory capacity that is balanced with the additional processors.
![]() Bandwidth Capacity – Adding a Worker Node adds additional disk capacity that is balanced with the additional processors and the additional memory providing enhanced bandwidth.
Bandwidth Capacity – Adding a Worker Node adds additional disk capacity that is balanced with the additional processors and the additional memory providing enhanced bandwidth.
The Aster Architecture allows you to purchase commodity hardware and then provides a shared-nothing architecture that adds nodes to the network, thus providing processor, memory and bandwidth growth as needed.
Replication Failover

Each vworker is designed to have a replication partition in case of a failure. This doubles the data. The Aster DBA sets the replication factor to two to ensure each vworker has a replica at all times. On any failure of the primary partition, the secondary partition is used automatically.
Data is Compressed on Data Transfers

When Worker nodes transfer data to other Worker nodes, the data is compressed by the sender and uncompressed by the receiver.
Aster utilizes data compression for internode transfers of data. Data is compressed by the sending node and uncompressed by the receiving node. Since data traveling over the interconnect is compressed, this decreases the congestion and increases the bandwidth by about a 3-to-1 ratio. One of the strengths of Aster Data is a design aiming to eliminate the network bottleneck limitations naturally occurring with MPP systems, complex queries, and big data. Just the compression technique alone eliminates almost 75% of the traffic.
Aster Utilizes Dual Optimizers

Aster utilizes a 2-stage optimizer. The first is a Global Optimizer in the Queen node. The second is a local optimizer that runs on each Worker node.
Aster's 2-stage optimizer is designed to maximize query performance by avoiding un-needed data shuffling over the Interconnect. The Optimizer residing in the Queen node is a Global optimizer. This is what provides the initial plan to the vworkers. This plan includes all the steps that are needed to be performed, what order the steps should be performed in, and any and all data transfers required. The second stage optimizer resides on each individual Worker node. This provides additional optimization based on specific characteristics of the data and the node configuration.
Aster Allows a Hybrid of SQL and MapReduce

Aster data utilizes Postgres as the underlying database structure. Aster also utilizes both SQL and MapReduce, naming it SQL/MR because both types of analysis can be combined into a single operation.
Aster Data supports both SQL and MapReduce capabilities, or you can utilize both in a single statement. The SQL abilities allow Aster to use standard SQL for traditional table analysis and MapReduce for less structured data that might need to use a procedural approach. MapReduce was made popular by Google. Aster Data’s integration of SQL and MapReduce is named SQL/MR because both types of analysis can be combined into a single operation.
MapReduce History
MapReduce is a programming framework which is used to process enormous data sets. It began getting taken seriously in 2004 when Google released a paper “MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat”.
Since then its use has grown exponentially, and today, many of the largest companies in the world are using MapReduce technology in the form of Hadoop or Aster Data to solve some very complex problems traditional databases would find difficult. While MapReduce works elegantly in some situations it is not a replacement for a traditional database, however, if implemented correctly it can compliment one beautifully.
MapReduce was designed to process extremely large data sets such as clickstream data from a website, large text files (html, logs etc.) or perhaps a digital version of every book housed in the Library of Congress! Google uses MapReduce to perform analytics on data entered into its search engine. If you have ever used the search engine of a tiny company named Google your data has most likely been run through MapReduce!
What is MapReduce?
MapReduce does what it says it is going to do. It maps data and then reduces data by utilizing a Master node and one or more Worker nodes.
The Map Step
The Master node will take input data and it will slice and dice it into smaller sub-problems and then distribute these to Worker nodes. The Master node is also know as the Queen node in Aster Data.
The Worker nodes will then take these sub-problems and may decide to break these down into smaller sub-problems, but eventually they finish their processing and send their individual answers back to the Master node.
The Reduce Step
The Master node then takes all of the answers from the Worker nodes and combines them to form the answer to the problem which needed to be solved.
What is SQL-MR?
SQL-MapReduce (SQL-MR) was created by Aster Data, and it is referred to as an "In-Database MapReduce framework".
It is implemented using two basic steps:
![]() Programmers write SQL-MR functions and then load them inside Aster Data using the Aster Command Line Tools (ACT).
Programmers write SQL-MR functions and then load them inside Aster Data using the Aster Command Line Tools (ACT).
Programming languages which are supported are:
• Java
• C#
• C++
• Python
• R
![]() Analysts then call the SQL-MR functions using familiar SELECT query syntax, and data is returned as a set of rows.
Analysts then call the SQL-MR functions using familiar SELECT query syntax, and data is returned as a set of rows.
Sessionize – An Example of SQL-MR

Above is an example of an Aster SQL-MR function called Sessionize. As you can see, it looks different than normal SQL but similar at the same time. We will get in-depth in this course about the Map Reduce functions that come with the Aster Database. Also, notice the Nexus Query Chameleon and just how many systems are in the tree. Nexus can query all databases, including Aster, Teradata, and Hadoop simultaneously.
Support for Mixed Workload Management and Prioritization

If there were one user in each of the above workloads, for each CPU second:
• The Tactical user could read and process 8 blocks of data
• The Ad Hoc user could read and process 4 blocks of data
• The DSS user could read and process 2 blocks of data
The DBA can give users, or define a group of users, in a workload and govern when queries are accepted. This is called a "Fairshare" concept where only a certain number of queries, or time allowance relative to other users with the same priority, are allowed to execute queries. A dynamic workload manager distributes both CPU and Disk I/O resources to each "service class". If higher priority queries are executed, the system can re-prioritize workloads on-the-fly, so the new query gets priority. The DBA can even set up a series of rules for each "service class" or "workload". This helps control the system as more users are added.