
5
Worker Pools and Pipelines
This chapter is about two interrelated concurrency constructs: worker pools and pipelines. While a worker pool deals with splitting work among multiple instances of the same computation, a data pipeline deals with splitting work into a sequence of different computations, one after the other.
In this chapter, you will see several working examples of worker pools and data pipelines. These patterns naturally come up as solutions to many problems, and there is no single best solution. I try to separate the concurrency concerns from the computation logic. If you can do the same for your problems, you can iteratively find the best solution for your use case.
The topics that this chapter will cover are as follows:
- Worker pools, using a file scanner example
- Data pipelines, using a CSV file processor example
Technical Requirements
The source code for this particular chapter is available on GitHub at https://github.com/PacktPublishing/Effective-Concurrency-in-Go/tree/main/chapter5.
Worker pools
Many concurrent Go programs are combinations of variations on worker pools. One reason could be that channels provide a really good mechanism for assigning tasks to waiting goroutines. A worker pool is simply a group of one or more goroutines that performs the same task on multiple instances of inputs. There are several reasons why a worker pool may be more practical than creating goroutines as needed. One reason is that creation of a worker instance in the worker pool could be expensive (not the creation of a goroutine, that’s cheap, but the initialization of a worker goroutine can be expensive), so a fixed number of workers can be created once and then reused. Another reason is that you potentially need an unbounded number of them, so you create a reasonable number once. Regardless of the situation, once you decide you need a worker pool, there are easy-to-repeat patterns that you can use over and over to create high-performing worker pools.
We first saw a simple worker pool implementation in Chapter 2. Let’s look at some variations of the same pattern here. We will work on a program that recursively scans directories and searches for regular expression matches, a simple grep utility. The Work struct is defined as a structure containing the filename and the regular expression:
type Work struct {
file string
pattern *regexp.Regexp
}In most systems, the number of files you can open is limited, so we work with a fixed-size worker pool:
func main() {
jobs := make(chan Work)
wg := sync.WaitGroup{}
for i := 0; i < 3; i++ {
wg.Add(1)
go func() {
defer wg.Done()
worker(jobs)
}()
}
...Note that we created a WaitGroup here, so we can wait for all workers to finish processing before the program exits. Also note that by using an anonymous function that wraps the actual worker, we can isolate the worker itself from the mechanics of the WaitGroup. Then we compile the regular expression that will be used by all goroutines:
rex, err := regexp.Compile(os.Args[2])
if err != nil {
panic(err)
}The rest of the main function walks the directories and sends files to the workers:
filepath.Walk(os.Args[1], func(path string, d fs.FileInfo, err error) error {
if err != nil {
return err
}
if !d.IsDir() {
jobs <- Work{file: path, pattern: rex}
}
return nil
})And finally, we terminate all the workers and wait for them to complete:
... close(jobs) wg.Wait() }
The actual worker function reads the file line by line and checks whether there are any pattern matches. If so, it prints the filename and the matching line:
func worker(jobs chan Work) {
for work := range jobs {
f, err := os.Open(work.file)
if err != nil {
fmt.Println(err)
continue
}
scn := bufio.NewScanner(f)
lineNumber := 1
for scn.Scan() {
result := work.pattern.Find(scn.Bytes())
if len(result) > 0 {
fmt.Printf("%s#%d: %s
", work.file,
lineNumber, string(result))
}
lineNumber++
}
f.Close()
}
}Note that the worker function continues until the jobs channel closes. When the program is run, each file is sent to the worker function, and the worker function processes the file. Since the worker pool has three workers in it, at any given moment, there will be at most three files that are being processed concurrently. Also note that the workers print the results concurrently, so the matching lines for each file are randomly interleaved.
This worker pool prints the results instead of returning them to the caller. In many cases, it is necessary to get the results from the worker pool after the work is submitted. A good way to do this is to include a return channel in the Work struct itself:
type Work struct {
file string
pattern *regexp.Regexp
result chan Result
}We change the worker function to send the results via the result channel. Also, do not forget to close that result channel once the processing of the file is done, so the receiving end knows there will be no more results coming from that channel:
...
for scn.Scan() {
result := work.pattern.Find(scn.Bytes())
if len(result) > 0 {
work.result <- Result{
file: work.file,
lineNumber: lineNumber,
text: string(result),
}
}
lineNumber++
}
close(work.result)This design solves the problem of interleaved results. We can read from one result channel until it is done, then move on to the next. But we cannot use the same goroutine to submit the jobs and read the results because that would cause a deadlock. Can you see why? We would be submitting jobs to a worker pool with no one listening for the results, so after we submit enough jobs to assign to every worker, the channel send operation will block. So, the goroutine that receives the results must be different from the one that sends them. I choose to put the directory walker in its own goroutine and read the results in the main goroutine.
There is one more problem to solve: how are we going to let the receiver goroutine know about the result channels? Every submitted work contains a new channel from which we have to read from. We can use a slice and add all those channels to it, but that slice will need synchronization because it will be read and written from multiple goroutines.
We can use a channel to send those results channels:
allResults := make(chan chan Result)
We will send every new result channel to the allResults channel. When the main goroutine receives that channel, it will iterate over it to print the results, and stop the iteration once the worker goroutine closes the result channel. Then, it will receive the next channel from allResults, and continue printing. The file walker now looks like this:
go func() {
defer close(allResults)
filepath.Walk(os.Args[1], func(path string,
d fs.FileInfo, err error) error {
if err != nil {
return err
}
if !d.IsDir() {
ch := make(chan Result)
jobs <- Work{file: path, pattern: rex,
result: ch}
allResults <- ch
}
return nil
})
}()Note the defer statement at the beginning. Once all the files are sent, we close the allResults channel to signal the completion of processing. We read the results using the following code:
for resultCh := range allResults {
for result := range resultCh {
fmt.Printf("%s #%d: %s
", result.file,
result.lineNumber, result.text)
}
}Figure 5.1 shows how we can analyze this algorithm. We have three goroutines here, from left to right, the path walker, the worker, and the main goroutine. This figure only shows the synchronization points of these goroutines. Initially, the path walker starts running, finds a file, and attempts to send the Work struct to the jobs channel. The worker goroutine waits to receive from the jobs channel, and the main goroutine waits to receive from the allResults channel:
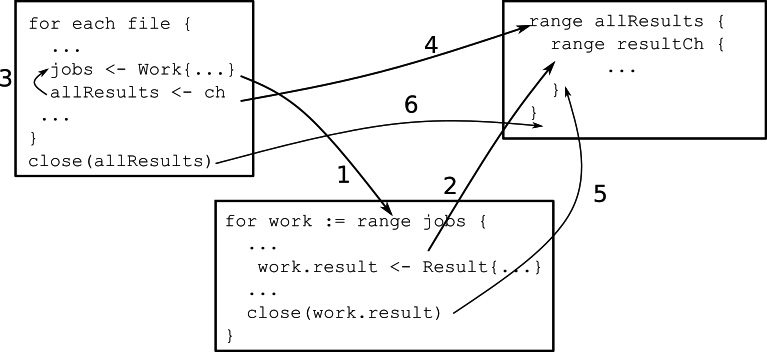
Figure 5.1 – Happened-before relationships for the worker pool
Now let’s say there is a worker available, so the send to the jobs channel succeeds, and the worker receives the work (arrow 1). At this point, the path walker goes on to send to the allResults channel (arrow 3), which depends on the main goroutine to receive from that channel (arrow 4), so the path walker continues running, and the main goroutine starts waiting to receive results from resultCh. While all these are happening, the worker goroutine computes a result and writes it to the result channel for the work, which is then received by the main goroutine (arrow 2). This continues until the worker is done, so it closes the results channel, which terminates the loop in the main goroutine (arrow 5). Now the path walker is ready to send the next piece of work. When the path walker is done, it closes the allResults channel, which terminates the forloop in the main goroutine (arrow 6).
It is also possible to use a worker pool to perform computations whose results will be used later (similar to Promise in JavaScript, or Future in Java):
resultCh:=make(chan Result)
jobs<-Work{
file:"someFile",
pattern: compiledPattern,
ch:resultCh,
}
// Do other things...
for result := range <-resultCh {
...
}How is this different from directly calling the worker function? Suppose you are writing a server program, and the request includes the filename and the pattern to search for. If thousands of requests arrive concurrently, it will use thousands of open files, which may not be possible on your platform. If you use the worker pool approach, no matter how many requests arrive concurrently, there will be, at most, the predefined number of workers (and thus, that many open file). So, worker pools are a good way of limiting concurrency in a system.
In closing, have you noticed there are no mutexes in this worker implementation? And the only explicit wait is the WaitGroup that waits for all workers to complete?
Pipelines, fan-out, and fan-in
Many times, a computation has to go through multiple stages that transform and enrich the result. Typically, there is an initial stage that acquires a sequence of data items. This stage passes those data items one by one to successive stages, where each stage operates on the data, produces a result, and passes it on to the next stage. A good example is image processing pipelines, where the image is decoded, transformed, filtered, cropped, and encoded into another image. Many data processing applications work with large amounts of data. Therefore, a concurrent pipeline can be essential for acceptable performance.
In this chapter, we will build a simple data processing pipeline that reads records from a comma-separated values (CSV) text file. Each record contains a height and weight measurement for a person captured as inches and pounds. Our pipeline will convert these measurements to centimeters and kilograms, then output them as a stream of JSON objects. We will use some generic functions to abstract the staging aspects of the problem so the actual computational units do not change from one pipeline implementation to the other.
The Record structure is defined as follows:
type Record struct {
Row int `json:"row"`
Height float64 `json:"height"`
Weight float64 `json:"weight"`
}This pipeline has three stages:
- Parse: This accepts a row of data read from the file. It then parses the row number as an integer, the height and weight values as floating point numbers, and returns a Record structure:
func newRecord(in []string) (rec Record, err error) {rec.Row, err = strconv.Atoi(in[0])
if err != nil {return
}
rec.Height, err = strconv.ParseFloat(in[1], 64)
if err != nil {return
}
rec.Weight, err = strconv.ParseFloat(in[2], 64)
return
}
func parse(input []string) Record {rec, err := newRecord(input)
if err != nil {panic(err)
}
return rec
}
- Convert: This accepts a Record structure as input. It then converts the height and weight to centimeters and kilograms and outputs the converted Record structure:
func convert(input Record) Record {input.Height = 2.54 * input.Height
input.Weight = 0.454 * input.Weight
return input
}
- Encode: This accepts a Record structure as input. It encodes the record as a JSON object.
func encode(input Record) []byte {data, err := json.Marshal(input)
if err != nil {panic(err)
}
return data
}
There are several ways a pipeline can be built. The most straightforward method is a synchronous pipeline. The synchronous pipeline simply passes the output of one function to the other. The input to the pipeline is read from the CSV file:
func synchronousPipeline(input *csv.Reader) {
// Skip the header row
input.Read()
for {
rec, err := input.Read()
if err == io.EOF {
return
}
if err != nil {
panic(err)
}
// The pipeline: parse, convert, encode
out := encode(convert(parse(rec)))
fmt.Println(string(out))
}
}The execution of this pipeline is depicted in Figure 5.2. The pipeline simply processes one record to completion and then processes the subsequent one until all records are processed. If each stage takes, say, 1 µs, it produces an output every 3 µs.
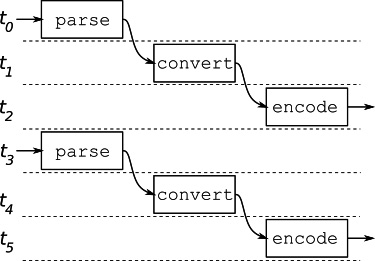
Figure 5.2 – Synchronous pipeline
Asynchronous pipeline
An asynchronous pipeline runs each stage in a separate goroutine. Each stage reads the next input from a channel, processes it, and writes it to the output channel. When the input channel closes, it closes the output channel, which causes the next stage to close its channel, and so on, until all channels are closed and the pipeline is terminated. The benefit of this type of operation is evident from Figure 5.3: assuming all the stages run in parallel, if each stage takes 1 µs, this pipeline produces an output every 1 µs after the initial 3 µs.

Figure 5.3 – Asynchronous pipeline
We can use some generic functions to wire the stages of this pipeline together. We wrap each stage in a function that reads from a channel in a forloop, calls a function to process the input, and writes the output to an output channel:
func pipelineStage[IN any, OUT any](input <-chan IN, output chan<- OUT, process func(IN) OUT) {
defer close(output)
for data := range input {
output <- process(data)
}
}Here, the IN and OUT type parameters are the input and output data types for the process function, respectively, as well as the channel types for the input and output channels.
The setup for the asynchronous pipeline is a bit more involved because we have to define a separate channel to connect each stage:
func asynchronousPipeline(input *csv.Reader) {
parseInputCh := make(chan []string)
convertInputCh := make(chan Record)
encodeInputCh := make(chan Record)
outputCh := make(chan []byte)
// We need this channel to wait for the printing of
// the final result
done := make(chan struct{})
// Start pipeline stages and connect them
go pipelineStage(parseInputCh, convertInputCh, parse)
go pipelineStage(convertInputCh, encodeInputCh, convert)
go pipelineStage(encodeInputCh, outputCh, encode)
// Start a goroutine to read pipeline output
go func() {
for data := range outputCh {
fmt.Println(string(data))
}
close(done)
}()
// Skip the header row
input.Read()
for {
rec, err := input.Read()
if err == io.EOF {
close(parseInputCh)
break
}
if err != nil {
panic(err)
}
// Send input to pipeline
parseInputCh <- rec
}
// Wait until the last output is printed
<-done
}You may have noticed this pipeline looks like worker pools connected one after another. In fact, each stage can be implemented as a worker pool. Such a design may be useful if some of the stages take a long time to complete, so multiple of them running concurrently can increase throughput.
Fan-out/fan-in
In an ideal case where all workers are running in parallel and with two workers at each stage, the pipeline operation looks like Figure 5.4. If each stage can produce an output every 1 µs, this pipeline will produce two outputs every 1 µs after the initial 3 µs:

Figure 5.4 – Asynchronous pipeline with two workers at each stage
In this design, the stages of the pipeline communicate using a shared channel, so multiple goroutines read from the same input channel (fan-out), and they write to a shared output channel (fan-in).
This pipeline requires some changes to our generic function. The previous generic function relies on the closing of the input channel to close its own output channel, so the stages can shut down one after the other. With multiple instances of the worker running at each stage, each of those workers will try to close the output channel, causing panic. We have to close the output channel once all the workers terminate. So, we need a WaitGroup:
func workerPoolPipelineStage[IN any, OUT any](input <-chan IN, output chan<- OUT, process func(IN) OUT, numWorkers int) {
// close output channel when all workers are done
defer close(output)
// Start the worker pool
wg := sync.WaitGroup{}
for i := 0; i < numWorkers; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for data := range input {
output <- process(data)
}
}()
}
// Wait for all workers to finish
wg.Wait()
}When the input channel closes, all the workers in the pipeline stage will terminate one by one. The WaitGroup ensures that the function does not return until all goroutines are done, and after that, it closes the output channel, which triggers the same sequence of events in the next stage.
The pipeline setup now uses this generic function:
numWorkers := 2 // Start pipeline stages and connect them go workerPoolPipelineStage(parseInputCh, convertInputCh, parse, numWorkers) go workerPoolPipelineStage(convertInputCh, encodeInputCh, convert, numWorkers) go workerPoolPipelineStage(encodeInputCh, outputCh, encode, numWorkers)
If you build this pipeline and run it, soon you will realize that the output may look like this:
{"row":65,"height":172.72,"weight":97.61}
{"row":64,"height":195.58,"weight":81.266}
{"row":66,"height":142.24,"weight":101.242}
{"row":68,"height":152.4,"weight":80.358}
{"row":67,"height":162.56,"weight":104.87400000000001}The rows are out of order! Because there are multiple instances of data going through the pipeline, the fastest one shows up at the output first, which may not be the first one in. There are many cases where the order of records coming out of the pipeline is not important. In some cases, though, you need them in order. This pipeline construction is not a good candidate for those problems. Sure, you can add a new stage to sort them, but you’ll need a potentially unbounded buffer: if there are multiple workers at each stage and if the first record takes so long to process that all the other records go through the pipeline before the first one, you have to buffer them all to sort them. That defeats the purpose of having a pipeline.
We will look at an alternate pipeline design that can deal with this problem. Our pipelines so far have used shared channels between stages that all workers send to and receive from. Another option is to use dedicated channels between the goroutines of each stage. This design becomes especially beneficial when some of the stages of the pipeline are expensive. Having multiple goroutines available to compute the expensive operations concurrently can increase the throughput of the whole pipeline.
For our example, let’s suppose the conversion stage performs expensive computations, so we want to have a worker pool containing multiple workers at this stage. So, after the pipeline parses the input, it fans out to multiple conversion goroutines that read from a shared channel, but these goroutines each return their responses in their own channels. So, before we can encode the output of this stage, we have to fan-in and order the results. This is depicted in Figure 5.5:
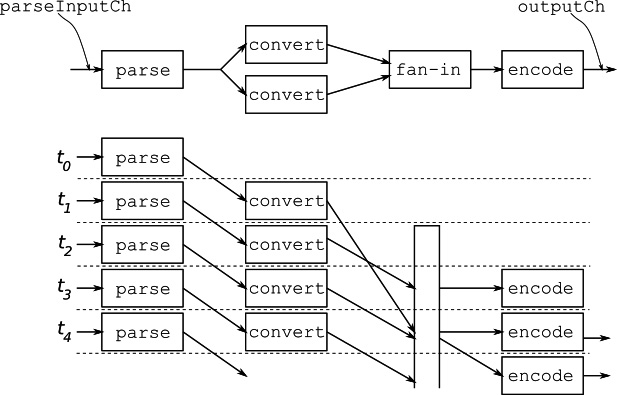
Figure 5.5 – Fan-out/fan-in without ordering
We need a new generic function that takes an input channel together with a done channel for cancellations and returns an output channel. This way we can connect the output of one goroutine to the input of another goroutine in another stage:
func cancelablePipelineStage[IN any, OUT any](input <-chan IN, done <-chan struct{}, process func(IN) OUT) <-chan OUT {
outputCh := make(chan OUT)
go func() {
for {
select {
case data, ok := <-input:
if !ok {
close(outputCh)
return
}
outputCh <- process(data)
case <-done:
return
}
}
}()
return outputCh
}Now, we can write a generic fan-in function:
func fanIn[T any](done <-chan struct{}, channels ...<-chan T) <-chan T {
outputCh := make(chan T)
wg := sync.WaitGroup{}
for _, ch := range channels {
wg.Add(1)
go func(input <-chan T) {
defer wg.Done()
for {
select {
case data, ok := <-input:
if !ok {
return
}
outputCh <- data
case <-done:
return
}
}
}(ch)
}
go func() {
wg.Wait()
close(outputCh)
}()
return outputCh
}The fanIn function gets multiple channels, reads from each channel concurrently using separate goroutines, and writes to the common output channel. When all the input channels are closed, the receiving goroutines terminate, and the output channel is closed. As you can see, the output is not necessarily in the same order as the input. The goroutines may shuffle the input based on the order in which they run.
A side note is necessary here...
If the number of input channels is fixed, a select statement is an easy way to fan-in. But here, the number of input channels can be dynamic and very large. A select statement with a variable number of channels would be perfect for these cases. The Go language syntax does not support it, but the standard library does. The reflect.Select function allows you to select using a slice of channels.
The following snippet wires the stages of the pipeline with 2 workers for the conversion stage:
// single input channel to the parse stage
parseInputCh := make(chan []string)
convertInputCh := cancelablePipelineStage(parseInputCh, done, parse)
numWorkers := 2
fanInChannels := make([]<-chan Record, 0)
for i := 0; i < numWorkers; i++ {
// Fan-out
convertOutputCh :=
cancelablePipelineStage(convertInputCh,
done, convert)
fanInChannels = append(fanInChannels, convertOutputCh)
}
convertOutputCh := fanIn(done, fanInChannels...)
outputCh := cancelablePipelineStage(convertOutputCh, done, encode)Fan-in with ordering
How can we write a fan-in function that can also order the records? The key idea is to store the out-of-order records until the expected record comes. Let’s say we have two input channels, listened to by two goroutines, and the first goroutine receives an out-of-order record. We know that the second goroutine will receive the expected record next time because the number of records in the pipeline cannot exceed the number of concurrent workers, and we already received the second record, so the first record is still in the previous stages. While waiting for that record to arrive, we have to prevent the first goroutine from returning another record. But how can we pause a running goroutine? The answer is: by making it wait on a channel.
Let’s try to put together an algorithm in pseudocode. I find it helpful to write pseudocode blocks representing goroutines and draw arrows between them to denote message exchanges. For each input channel, we will use a goroutine that receives the data element from the pipeline, sends it to a fan-in channel that the ordering goroutine is receiving from, and waits to receive from a pause channel. In the second stage, we have the ordering goroutine that receives from the fan-in channel and determines whether the record is in the correct order. If not, it stores this order at a buffer dedicated to its input channel. At this point, the goroutine for that input channel is waiting to receive from its pause channel, so it cannot accept any more inputs. When the correct input comes, the ordering goroutine outputs all queued data and releases all waiting goroutines by sending them to their pause channels. This is illustrated in Figure 5.6:
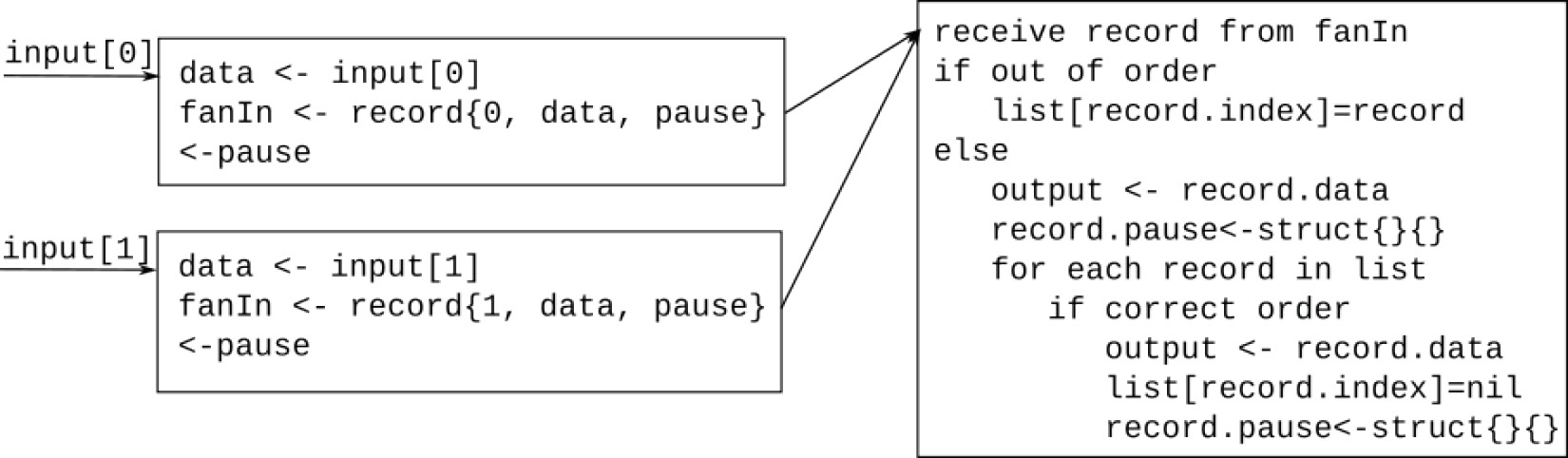
Figure 5.6 – Pseudocode for ordering fan-in
So, let’s start constructing this ordered fan-in algorithm. First, we need a way to get the sequence number of records:
type sequenced interface {
getSequence() int
}
func (r Record) getSequence() int { return r.Row }For each channel, we need a place to store the out-of-order records and a channel to pause the goroutine:
type fanInRecord[T sequenced] struct {
index int // index of the input channel
data T
pause chan struct{}
}We create a goroutine for each input channel. Each goroutine reads from its assigned channel, creates an instance of fanInRecord, and sends it via the fanInCh channel. This may be the expected record, or it may be out-of-order, but that is up to the receiving end of the fanInCh channel. This goroutine now has to pause until that determination is made. So, it receives from the associated pause channel. Another goroutine releases the goroutine by sending a signal to the pause channel, after which the goroutine starts listening to the input channel again. Of course, if the input channel is closed, the corresponding goroutine returns, and when all the goroutines return, the fanInCh channel closes:
func orderedFanIn[T indexable](done <-chan struct{}, channels ...<-chan T) <-chan T {
fanInCh := make(chan fanInRecord[T])
wg := sync.WaitGroup{}
for i := range channels {
pauseCh := make(chan struct{})
wg.Add(1)
go func(index int, pause chan struct{}) {
defer wg.Done()
for {
var ok bool
var data T
// Receive input from the channel
select {
case data, ok = <-channels[index]:
if !ok {
return
}
// Send the input
fanInCh <- fanInRecord[T]{
index: index,
data: data,
pause: pause,
}
case <-done:
return
}
// pause the goroutine
select {
case <-pause:
case <-done:
return
}
}
}(i, pauseCh)
}
go func() {
wg.Wait()
close(queue)
}()The second part of the function contains the ordering logic. When an out-of-order record is received from a channel, it is stored in the buffer dedicated to that channel, so we only need a buffer of len(channels) capacity. When the expected record is received, the algorithm scans the stored records and outputs them in the correct order:
outputCh := make(chan T)
go func() {
defer close(outputCh)
// The next record expected
expected := 1
queuedData := make([]*fanInRecord[T], len(channels))
for in := range fanInCh {
// If this input is what is expected, send
//it to the output
if in.data.getSequence() == expected {
select {
case outputCh <- in.data:
in.pause <- struct{}{}
expected++
allDone := false
// Send all queued data
for !allDone {
allDone = true
for i, d := range queuedData {
if d != nil && d.data.getSequence() ==
expected {
select {
case outputCh <- d.data:
queuedData[i] = nil
d.pause <- struct{}{}
expected++
allDone = false
case <-done:
return
}
}
}
}
case <-done:
return
}
} else {
// This is out-of-order, queue it
in := in
queuedData[in.index] = &in
}
}
}()
return outputCh
}The idea of this goroutine is to listen to the queue channel, and if the received record is out-of-order, queue it. The sending goroutine will be blocked until this goroutine releases it. If the correct record comes, it is directly sent to the output channel, the goroutine that sent it is unblocked, and all queued records are scanned to see if the next expected record is already queued. If so, that record is sent, the corresponding goroutine is unblocked by a send to the pause channel, and the record is dequeued.
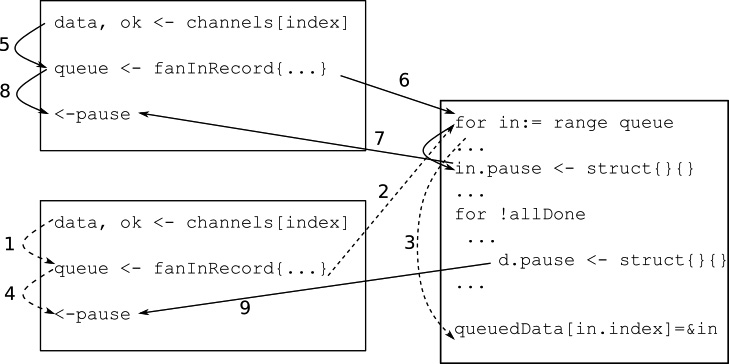
Figure 5.7 – Ordered fan-in happened-before relationships
Let’s look at how these goroutines interact, which is depicted in Figure 5.7. One of the goroutines reads an out-of-order input (arrow 1) and sends it to the fan-in goroutine through the fanInCh channel (arrow 2). The fan-in goroutine, realizing this is an out-of-order record, queues it (arrow 3). While these are happening, the goroutine starts waiting to receive from its pause channel (arrow 4). Concurrently, another goroutine receives another input (arrow 5) and sends it to the fan-in goroutine via the fanInCh channel (arrow 6). The fan-in goroutine, realizing this is the expected packet, releases the goroutine (arrow 7), which is already waiting or will soon wait to receive from its pause channel. The fan-in goroutine also looks at the stored requests and sees that there is one record waiting, which now becomes the expected packet. So, it releases that goroutine as well (arrow 9).
As you can see, pipelines can get complicated based on the exact needs. There is no single way to solve these problems. These examples show several ways to abstract away the underlying complexities of building and running high-performance data pipelines so that the actual processing stages can concentrate on only data processing. As I tried to illustrate in this chapter, different types of pipelines can be constructed and connected using concurrent components and generic functions without a need to change the processing logic. Start simple, profile your programs, find the bottlenecks, and then you can decide if and when to fan out, how to fan in, how to size worker pools, and what type of pipeline works best for your use case.
Finally, note that all pipeline implementations here used channels, goroutines, and waitgroups. There are no critical sections, no mutexes or condition variables, and yet, no data races. Each goroutine makes progress as soon as new data becomes available.
Summary
In this chapter, we studied worker pools and pipelines – two patterns that show up in different shapes and forms in almost every non-trivial project. There are many ways these patterns can be implemented with different runtime behaviors. You should build your systems so that they do not rely on the exact structure of the pipeline or the worker pools. I tried to show some ways to abstract away concurrency concerns from computation logic. These ideas may make your job easier when you need to iterate among different designs.
Next, we will talk about error handling and how error handling can be added to these patterns.
Questions
- Can you change the worker implementation so that the submitted work can be canceled by the caller?
- Many languages offer frameworks with dynamically sized worker pools. Can you think of a way to implement that in Go? Would that worker pool be more performant than a fixed-sized worker pool that uses the same number of goroutines as the maximum for the dynamically sized one?
- Try writing a generic fan-in/fan-out function (without ordering) that takes n input channels and m output channels.