
▶ 6.2 Evolution of Password Systems
Early timesharing systems used a combined keyboard and printer to interact with its users (the first computer terminals). These devices were often teletypes or special models of IBM’s Selectric typewriters. FIGURE 6.4 shows Dennis Ritchie and Ken Thompson, two developers of the Unix timesharing system, using a teletype with a minicomputer. In normal operation, these terminals would echo the text the user typed by printing each character on a roll of paper. Unfortunately, this enabled the first of the five attack vectors just discussed.

FIGURE 6.4 Unix developers using a teletype.
Reused with permission of Nokia Corporation and AT&T Archives.
It made perfect sense to echo the characters in most cases, but it posed a problem for passwords; once the user had typed it in, there was now a written copy of the password. A passerby could shoulder surf and read the user name and password. Even worse, much of the printed paper was discarded after the computing session, and this left printed copies of passwords in trash cans.
Teletype machines allowed an easy solution: It was possible to disable the printer while typing on the keyboard. Computing systems that used teletypes would disable the printer when asking for a password. Systems that used Selectric-based terminals, however, could not disable its printer. Instead, the systems would print a mask by repeatedly typing characters over the first several places on the line, making the user’s typing unreadable. When the user typed the password, the letters were typed on top of the mask. FIGURE 6.5 shows an example of password masking, taken from Boston University’s timesharing system.

FIGURE 6.5 Masking the space for typing a password.
Courtesy of Dr. Richard Smith.
Timesharing system designers in the United States did not immediately worry about the remaining attack vectors on passwords, despite problems with the authentication database. The fifth attack vector, however, posed a worry at the University of Cambridge, England, where they were developing the Titan timesharing system. Their authentication database also contained all user names and passwords in the system. The Titan system was regularly copied to a backup tape, and they could not protect those tapes against weak threats within the local computing community.
Password Hashing
Roger Needham and Mike Guy, two of the Titan developers, were discussing the problem one evening at a local pub. They discussed ways of protecting the passwords with secret codes of various kinds. They finally hit upon the idea of using a “one-way cipher” function. The cipher would take a password and transform it (“hash” it) into unreadable gibberish.
Today, we call such a function a one-way hash. This function had two essential properties:
Whenever it hashed a particular password, it yielded the same gibberish every time.
There was no practical way to analyze the gibberish and derive the password that produced it.
The technique worked as shown in FIGURE 6.6. In preparation, Needham and Guy applied the hash function to the readable, plain text passwords in the password file, replacing each one with its hashed version.

FIGURE 6.6 Procedure diagram of password hashing.
Whenever a user logged in, the system collected the password and applied the hash function. Then the password checking procedure compared the hashed password against the user’s hashed password stored in the password file.
Password hashing made the fifth attack vector, retrieve from offline, impractical, at least at first. In older versions of Unix, the password file itself was protected from writing, but allowed read access to all users. Unix relied on hashing to keep the passwords secret. Starting in the 1990s, however, improvements in password cracking strategies (see Section 6.4) placed hashed passwords at risk of disclosure.
Procedure Diagrams
Note that Figure 6.6 is different from earlier diagrams in this text. It is a procedure diagram. So far, the other diagrams illustrated processes, and we can call those process diagrams. Both diagrams may refer to data in RAM or in files.
In a process diagram, we show processes with ovals. The processes may all be running more or less simultaneously. Arrows show information flow between the processes.
In a procedure diagram, we show individual procedures with round-cornered rectangles. Each procedure represents a step in the larger procedure being illustrated. The procedures execute in a strict order, following the flow of data as shown by arrows.
Moreover, when we show a particular type of procedure, like a hash function, there are a specific number of inputs and outputs. Every typical implementation of a hash function has one input and one output.
Password Hashing in Practice
Password hashing on modern systems protects from the following attack vectors:
■ Social engineering. In these attacks, someone tries to talk a system administrator into divulging a user’s password, often by posing as the user in question. Such attacks are impossible with hashed passwords. No one, including the administrator, can retrieve the password using only the hash.
■ Stolen authentication database. These are the same as classic attacks. Today, however the stakes are higher, because many users try to use the same password for many different purposes. Knowing the password for one system may help an attacker guess the right password for another system.
Modern computing systems still use passwords, but the environment is radically different from the earliest timesharing systems. Password files often reside on single-user systems as well as on personally managed websites and on larger-scale systems. Some systems hash their stored passwords, while others do not. Modern Unix-based and Windows-based systems hash their passwords. Some, but not all, web-based systems hash their passwords.
Hint: Checking a system for plain text passwords: Sometimes we can find out if a system stores plain text passwords. We contact the system’s help desk and ask them to retrieve our lost password. If the system stores readable passwords, then there may be a way for the help desk to retrieve it.
On the other hand, many help desks aren’t provided the tools to retrieve passwords, regardless of whether the passwords are hashed or not. This is a sensible policy decision. It is very easy to disclose a password to the wrong person, especially if help desk operators can retrieve passwords.
6.2.1 One-Way Hash Functions
The key to successful password hashing is to use a well-written hash function. A hash function takes a larger block of data and produces a smaller result of a fixed size, called the hash value. Although early hash functions worked with a few dozen bytes of data, modern hash functions can work with very large inputs, including entire documents (FIGURE 6.7).

FIGURE 6.7 Procedure diagram of a one-way hash function.
In the early days of timesharing, hash functions typically were used to speed up searching for data in tables. Those hash functions were not appropriate for protecting passwords.
Today, we are careful to distinguish classic hash functions from one-way hash functions. The one-way hash is a cryptographic function. We use such functions to protect information against strong attacks. A well-designed cryptographic function resists trial-and-error attacks as well as analytical attacks that seek patterns in its behavior. It is hard to construct a reliable cryptographic function.
Cryptographic Hash Functions
Ron Rivest, a professor at MIT and prolific cryptographer, produced a series of one-way hash functions in the early 1990s. He called these “message digest” functions because they took a message and computed a “digest” reflecting its contents. Rivest’s Message Digest 5, or MD5, was widely used to protect e-commerce messages between early desktop web browsers and secure web servers. MD5 distills the contents of such messages down to a 16-byte hash value.
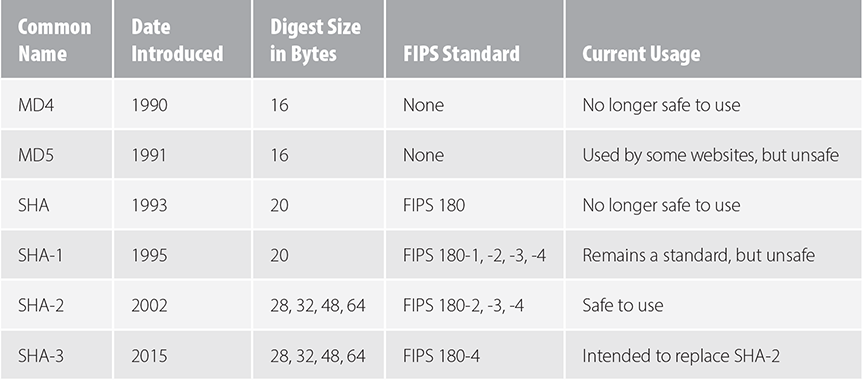
Hash functions have evolved since the 1990s. Newer functions benefit from advances in cryptographic analysis and design. Older functions became obsolete as researchers found successful attacks against them. TABLE 6.3 illustrates the evolution of modern hash functions. The “common names” identify different hashing strategies. Each new strategy sought to address weaknesses of earlier designs.
TABLE 6.3 Cryptographic One-Way Hash Functions |
|---|
|
Hash functions play such a fundamental cybersecurity role that the U.S. government has published a series of standards for them. These are called the Secure Hash Algorithms (SHA-x), where x represents the digest size in bits. The algorithms are published in the Federal Information Processing Standards 180 series, abbreviated FIPS-180. As shown in Table 6.3, we also use the SHA acronym to identify different hashing strategies. The SHA-2, SHA-1, and SHA (sometimes called SHA-0) strategies were developed by the NSA. SHA-3 was developed through an open competition managed by NIST.
The hash algorithms approved in the latest standard, FIPS 180-4, appear below. The official names reflect the digest size. If two numbers appear, as in 512/224, the second number is the digest size.
■ SHA-1 (still in the standard, but unsafe)
■ SHA-224 (uses SHA-2)
■ SHA-256 (uses SHA-2)
■ SHA-384 (uses SHA-3)
■ SHA-512 (uses SHA-3)
■ SHA-512/224 (uses SHA-3)
■ SHA-512/256 (uses SHA-3)
As of this date, SHA-1 still appears in the FIPS 180-4 standard. Since 2011, NIST has published recommendations that SHA-1 not be used in the future. It remains in use to support equipment that contains embedded data hashed using SHA-1. For example, older public-key certificates may legitimately contain SHA-1 hashes. Unfortunately, some vendors continued to use it in newer certificates and in other applications. Software vendors have tried to encourage transition to SHA-2 or SHA-3 hashes by indicating SHA-1 hashes as unsafe.
A hash function by itself protects passwords in an authentication database. We also can use the function as an especially sensitive error detection code. While checksums and CRCs work well for disk sectors or similarly sized blocks of data, a one-way hash can detect minor changes in enormous blocks of data, like programs downloaded from the internet. (See Section 5.4.1.)
When a software publisher posts a program to be downloaded, there are risks that the user won’t download the program correctly. In some cases, the program is damaged while being downloaded, and in other cases, a hacker might substitute a subverted version of the program for the legitimate one. To detect such failures, some publishers display the file’s correct hash value along with the link to download the file. A careful user can use the hash procedure to calculate the file’s hash and compare it with the publisher’s hash value. If they match, the user downloaded the file correctly.
A Cryptographic Building Block
However, the one-way hash isn’t always easy to use by itself. It’s not easy to compare hash values just by looking at them, and it’s easier to have the computer do the checking. To make this work, we use the hash as a cryptographic building block and combine it with other functions to achieve better protection. Although there are many cryptographic functions, we will see the building blocks used in effective security systems.
To work reliably as a building block, a modern hash function must meet stronger requirements and resist more sophisticated attacks. Today, we expect a one-way hash function to perform as follows:
■ If we change a document in any way, whether changing a single bit, a few bytes, or a large amount, the hash value will change in a large and unpredictable way.
■ If we make a document longer or shorter, the hash value will change in a large and unpredictable way.
■ If we have a hash value, we cannot construct a password or document that yields the same hash value.
■ If we have a document and its hash value, we cannot build a different document that yields the same hash value.
■ We cannot construct two different documents from scratch that both yield the same hash value.
A practical hash yields a unique hash value for every input. In reality this is theoretically impossible: If the hash values are only 20 bytes long and the files are 20,000 bytes long or longer, the hash values must collide once in a while. What makes hash functions work in practice is that there are far, far more hash values than there are documents. A 20-byte hash value represents a 160-bit binary number, and that number can cover a huge range of values:
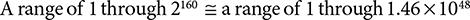
It is possible through the workings of random chance that two different documents or passwords could yield the same hash value, but it’s very, very unlikely in practice. Software vendors made a special effort to abandon SHA-1 in 2017 after researchers at Google produced two different PDF documents that yielded the same SHA-1 hash value.
6.2.2 Sniffing Credentials
A popular attack vector actively sniffs authentication credentials as the user types them in. Sniffers exist as both hardware and software and are sometimes called keystroke loggers. Vendors supply a variety of justifications for customers. Parents are urged to use loggers to monitor childrens’ computer use. Other vendors sell them as employee surveillance devices and, in fact, some employers use them to monitor their employees.
The lowest cost approach is, of course, to install sniffing software in the victim’s computer. In some cases, sniffing software arrives unexpectedly from a worm or virus infection. Botnet software often includes a sniffer to try to retrieve authentication information for financial sites, like banks. The ZeuS botnet, for example, focuses on retrieving such information from infected computers. The botnet operators then use the stolen credentials in financial fraud. (See Section 10.1.3.)
Hardware keystroke loggers connect through the keyboard’s cable. A typical model appears to be an innocuous extender plugged into the keyboard’s USB socket (FIGURE 6.8). The keyboard itself plugs into a socket on the logger. Internally, the logger contains flash memory to collect the logged data. Physical keystroke loggers may be relatively easy to spot, assuming we know that we should look for one. However, there is no need for the devices to be large and obvious. Newer devices will be smaller and much harder to spot.

FIGURE 6.8 Keystroke logger.
Courtesy of KeyGhost.com.
An alternative to keystroke logging is to intercept electronic signals sent by the victim’s computer. Wireless keyboards, for example, transmit the keystrokes, and these transmissions may be intercepted and logged. Many such keyboards include an encryption feature, but these features often are easy to circumvent. Really sophisticated attackers could analyze stray signals generated by the computer or its peripherals; these are called TEMPEST attacks.
Once the keystrokes have been collected, the attacker needs to sort through the data to locate passwords. In some cases, the process may be relatively obvious. For example, the password keystrokes often follow an obvious user name. In other cases, the attacker may need to use the keystroke data to identify possible passwords, and then proceed with a trial-and-error guessing attack.