
Chapter 14: Model Comparison
Perform a Model Comparison with Continuous Dependent Variable
Understand Correlation between Variable and Prediction
Explore the Uses of the Different Measures
Perform a Model Comparison with Binary Dependent Variable
Understand the Confusion Matrix and Its Limitations
Understand True Positive Rate and False Positive Rate
Interpret Receiving Operator Characteristic Curves
Compare Two Example Models Predicting Churn
Perform a Model Comparison Using the Lift Chart
Examine the Results of Stepwise Regression
Compute the MSE, MAE, and Correlation
Examine the Results for MSE, MAE, and Correlation
Understand Overfitting from a Coin-Flip Example
Use the Model Comparison Platform
Introduction
You know how to compare two linear regression models with the same number of independent variables: look at R2. When the number of independent variables is different between the two regressions, look at adjusted R2. What should you do, though, to compare a linear regression model with a nonlinear regression model, the latter of which really has no directly comparable definition for R2? Suppose that you want to compare the results of the linear probability model (linear regression applied to a binary variable) to the results of a logistic regression. R2 doesn’t work in this case, either.
There is a definite need to compare different types of models so that the better model might be chosen, and that’s the topic of this chapter. Because this chapter addresses model comparison, not a statistical technique, no technique is highlighted in the multivariate framework (Figure 14.1).
Figure 14.1: A Framework for Multivariate Analysis

First, this chapter will examine the case of a continuous dependent variable, which is rather straightforward, if somewhat tedious. Subsequently, the binary dependent variable will be discussed. It permits many different types of comparisons, and its discussion will be quite lengthy.
Perform a Model Comparison with Continuous Dependent Variable
Comparing models when the dependent variable is continuous relies largely on different ways of using the residuals to compute a measure of accuracy.
These performance measures are but a few of many such measures that can be used to distinguish between competing models. Others are the Akaike Information Criterion (AIC), which was discussed in Chapter 8, as well as the similar Bayesian Information Criterion.
Understand Absolute Measures
Three common measures used to compare predictions of a continuous variable are the mean square error (MSE), its square root (RMSE), and the mean absolute error (MAE). The last is less sensitive to outliers. All three of these become smaller as the quality of the prediction improves.
MSE is as follows:
∑ni=1(ˆyi−yi)2n
RMSE is as follows:
√∑ni=1(ˆyi−yi)2n
MAE is as follows:
∑ni=1|ˆyi−y|n
Understand Relative Measures
These performance measures do not consider the level of the variable that is being predicted. For example, an error of 10 units is treated the same way, regardless of whether the variable has a level of 20 or 2,000. To account for the magnitude of the variable, relative measures can be used, as shown here.
The relative squared error is as follows:
∑ni=1(ˆyi−yi)2∑ni=1(yi−ˉy)2
The relative absolute error is as follows:
∑ni=1|ˆyi−y|∑ni=1|yi−ˉy|
The relative measures are particularly useful when comparing variables that have different levels.
Understand Correlation between Variable and Prediction
Another performance measure is the correlation between the variable and its prediction. Correlation values are constrained to be between −1 and +1 and to increase in absolute value as the quality of the prediction improves.
The Correlation Coefficient is as follows:
∑ni=1(yi−ˉy)(ˆyi−ˉˆyi)(n−1)sysˆy
Sy and Sŷ are the standard deviations of y and ŷ, and ˉˆyi is the average of the predicted values.
Explore the Uses of the Different Measures
In what follows, you will primarily use the absolute rather than the relative measures, because you will be comparing variables that have the same levels.
Which measure should be used can be determined only by a careful study of the problem. Does the data set have outliers? If so, then absolute rather than squared error might be appropriate. If an error of 5 units when the prediction is 100 is the same as an error of 20 units when the prediction is 400 (5% error), then relative measures might be appropriate. Frequently, these measures all give the same answer. In that case, it is obvious that one model is not superior to another. On the other hand, there are cases where the measures contradict, and then careful thought is necessary to decide which model is superior.
To explore the uses of these measures, open the file McDonalds48.jmp, which gives monthly returns on McDonalds and the S&P 500 from January 2002 through December 2005. You will run a regression on the first 40 observations and use this regression to make out-of-sample predictions for the last 8 observations. These 8 observations can be called a holdout sample.
To exclude the last 8 observations from the regression, select observations 41–48 (click in row 41, hold down the Shift key, and click in row 48). Then right-click and select Exclude/Unexclude. Each of these rows should have a red circle with a slash through it.
Now run the regression:
1. Select Analyze ▶ Fit Model, click Return on McDonalds, and then click Y.
2. Select Return on SP500 and click Add.
3. Click Run.
4. To place the predicted values in the data table, click the red triangle, and select Save Columns ▶ Predicted Values.
Notice that JMP has made predictions for observations 41–48, even though these observations were not used to calculate the regression estimates. It is probably easiest to calculate the desired measures by using Excel. So either save the datasheet as an Excel file, and then open it in Excel, or just open Excel and copy the variables Return on McDonalds and Predicted Return on McDonalds into columns A and B respectively. In Excel, perform the following steps:
1. Create the residuals in column C, as Return on McDonalds – Predicted Return on McDonalds.
2. Create the squared residuals in column D, by squaring column C.
3. Create the absolute residuals in column E, by taking the absolute value of column C.
4. Calculate the in-sample MSE by summing the first 40 squared residuals, which will be cells 2–41 in column D. Then divide the sum by 40.
5. Calculate the in-sample MAE by summing the first 40 absolute residuals, which will be cells 2–41 in column E. Then divide the sum by 40.
6. Calculate the out-of-sample MSE by summing the last 8 squared residuals, cells 42-49 in column D. Then divide the sum by 8.
7. Calculate the out-of-sample MAE by summing the last 8 absolute residuals, cells 42-49 in column E. Then divide the sum by 8.
8. Calculate the in-sample correlation between Return on McDonalds and Predicted Return on McDonalds for the first 40 observations using the Excel CORREL( ) function.
9. Calculate the out-of-sample correlation between Return on McDonalds and Predicted Return on McDonalds for the last 8 observations using the Excel CORREL( ) function.
The calculations and results can be found in the file McDonaldsMeasures48.xlsx and are summarized in Table 14.1.
Table 14.1: Performance Measures for the McDonalds48.jmp File
| Mean Squared Error | Mean Absolute Error | Correlation | |
| In-Sample | 0.00338668 | 0.04734918 | .68339270 |
| Out-of-Sample | 0.00284925 | 0.04293491 | .75127994 |
The in-sample and out-of-sample MSE and MAE are quite close, which leads you to think that the model is doing about as well at predicting out-of-sample as it is at predicting in-sample. The correlation confirms this notion. To gain some insight into this phenomenon, look at a graph of Return on McDonalds against Predicted Return on McDonalds:
1. Select Graph ▶ Scatterplot Matrix (or select Graph ▶ Overlay Plot), select Return on McDonalds, and click Y, Columns.
2. Select Predicted Return on McDonalds and click X.
3. Click OK.
Alternatively, this graph could be made with Graph Builder.
In the data table, select observations 41–48, which will make them appear as bold dots on the graph. These can be a bit difficult to distinguish. To remedy the problem, while still in the data table, right-click on the selected observations, select Markers, and then choose the plus sign (+). (See Figure 14.2.)
These out-of-sample observations appear to be in agreement with the in-sample observations. This suggests that the relationship between Y and X that existed during the in-sample period continued through the out-of-sample period. Hence, the in-sample and out-of-sample correlations are approximately the same. If the relationship that existed during the in-sample period had broken down and no longer existed during the out-of-sample period, then the correlations might not be approximately the same, or the out-of-sample points in the scatterplot would not be in agreement with the in-sample points.
Figure 14.2: Scatterplot with Out-of-Sample Predictions as Plus Signs

Perform a Model Comparison with Binary Dependent Variable
Comparison measures for binary variables are based on the usual contingency table for binary variables.
Understand the Confusion Matrix and Its Limitations
When actual values are compared against predicted values for a binary variable, a contingency table is used. This table is often called an error table or a confusion matrix. It displays correct versus incorrect classifications, where 1 may be thought of as a “positive/successful” case and 0 might be thought of as a “negative/failure” case.
It is important to understand that the confusion matrix is a function of some threshold score. Imagine making binary predictions from a logistic regression. The logistic regression produces a probability. If the threshold is, for example, 0.50, then all observations with a score above 0.50 will be classified as positive, and all observations with a score below 0.50 will be classified as negative. Obviously, if the threshold changes to, for example, 0.55, so will the elements of the confusion matrix.
Table 14.2: An Error Table or Confusion Matrix
| Predicted 1 | Predicted 0 | |
| Actual 1 | True positive (TP) | False negative (FN) |
| Actual 0 | False positive (FP) | True negative (TN) |
A wide variety of statistics can be calculated from the elements of the confusion matrix, as labeled in Table 14.2. For example, the overall accuracy of the model is measured by the Accuracy:
Accuracy = TP + TNTP + FP + FN + TN=Number correctly classifiedTotal number of observations
This is not a particularly useful measure because it gives equal weight to all components. Suppose that you are trying to predict a rare event—for example, cell phone churn—when only 1% of customers churn. If you simply predict that all customers do not churn, your accuracy rate will be 99%. (Since you are not predicting any churn, FP = 0 and TN = 0.) Clearly, better statistics that make better use of the elements of the confusion matrix are needed.
Understand True Positive Rate and False Positive Rate
One such measure is the sensitivity, or true positive rate, which is defined as follows:
Sensitivity = TPTP + FN= Number correctly classified as positiveNumber of positives
This is also known as recall. It answers the question, “If the model predicts a positive event, what is the probability that it really is positive?” Similarly, the true negative rate is also called the specificity and is given by the following:
Specificity = TNTN + FP = Number correctly classified as negativeNumber of negatives
It answers the question, “If the model predicts a negative event, what is the probability that it really is negative?” The false positive rate equals 1 − specificity and is given by the following:
False positive rate (FPR)=FPTN + FP = Number incorrectly classified as positiveNumber of negatives
It answers the question, “If the model predicts a negative event, what is the probability that it is making a mistake?”
Interpret Receiving Operator Characteristic Curves
When the FPR is plotted on the x-axis, and the true positive rate (TPR) is plotted on the y-axis, the resulting graph is called a receiver operating characteristic curve (ROC curve); the name derives from the analysis of radar transmissions in World War II when this graph originated).
In order to draw the ROC curve, the classifier has to produce a continuous-valued output that can be used to sort the observations from most likely to least likely. The predicted probabilities from a logistic regression are a good example. In an ROC graph, such as that depicted in Figure 14.3, the vertical axis shows the proportion of 1s that are correctly identified, and the horizontal axis shows the proportion of zeros that are misidentified as 1s.
Figure 14.3: An ROC Curve

To interpret the ROC curve, first note that the point (0, 0) represents a classifier that never issues a positive classification: Its FPR is zero, which is good. But it never correctly identifies a positive case, so its TPR is zero, also, which is bad. The point (0, 1) represents the perfect classifier: It always correctly identifies positives and never misclassifies a negative as a positive.
In order to understand the curve, you need to identify two extreme cases. First is the random classifier that simply guesses at whether a case is 0 or 1. The ROC for such a classifier is the dotted diagonal line A, from (0, 0) to (1, 1). To see this, suppose that a fair coin is flipped to determine classification. This method will correctly identify half of the positive cases and half of the negative cases, and corresponds to the point (0.5, 0.5). To understand the point (0.8, 0.8), if the coin is biased so that it comes up heads 80% of the time (let “heads” signify “positive”), then it will correctly identify 80% of the positives and incorrectly identify 80% of the negatives. Any point beneath this 45o line is worse than random guessing.
The second extreme case is the perfect classifier, which correctly classifies all positive cases and has no false positives. It is represented by the dot-dash line D, from (0, 0) through (0, 1) to (1, 1). The closer an ROC curve gets to the perfect classifier, the better it is. Therefore, the classifier represented by the solid line C is better than the classifier represented by the dashed line B. Note that the line C is always above the line B; essentially, the lines do not cross. Remember that each point on an ROC curve corresponds to a particular confusion matrix that, in turn, depends on a specific threshold. This threshold is usually a percentage. For example, classify the observation as “1” if the probability of its being a “1” is 0.50 or greater. Therefore, any ROC curve represents various confusion matrices generated by a classifier as the threshold is changed. For an example of how to calculate an ROC curve, see Tan, Steinbach, and Kumar (2006, pp. 300−301).
Points in the lower left region of the ROC space identify “conservative” classifiers. They require strong evidence to classify a point as positive. So they have a low false positive rate; necessarily they also have low true positive rates. On the other hand, classifiers in the upper right region can be considered “liberal.” They do not require much evidence to classify an event as positive. So they have high true positive rates; necessarily, they also have high false positive rates.
Figure 14.4: ROC Curves and Line of Optimal Classification

When two ROC curves cross, as they do in Figure 14.3, neither is unambiguously better than the other. But it is possible to identify regions where one classifier is better than the other. Figure 14.4 shows the ROC curve as a dotted line for a classifier produced by Model 1—say, logistic regression. And the ROC curve is shown as a solid line for a classifier produced by Model 2—say, a classification tree. Suppose it is important to keep the FPR low at 0.2. Then, clearly, Model 2 would be preferred because when FPR is 0.2, it has a much higher TPR than Model 1. Conversely, if it was important to have a high TPR (for example, 0.9), then Model 1 would be preferable to Model 2 because when TPR = 0.9, Model 1 has an FPR of about 0.7, and Model 2 has an FPR of about 0.8.
The ROC can also be used to determine the point with optimal classification accuracy. Straight lines with equal classification accuracy can be drawn, and these lines will all be from the lower left to the upper right. The line that is tangent to an ROC curve marks the optimal point on that ROC curve. In Figure 14.4, the point marked A for Model 2, with an FPR of about 0.1 and a TPR of about 0.45, is an optimal point. Precise details for calculating the line of optimal classification can be found in Vuk and Curk (2006, Section 4.1).
This point is optimal, assuming that the costs of misclassification are equal and that a false positive is just as harmful as a false negative. This assumption is not always true, as shown by misclassifying the issuance of credit cards. A good customer might charge $5,000 per year and carry a monthly balance of $200, resulting in a net profit of $100 to the credit card company. A bad customer might run up charges of $1,000 before his or her card is canceled. Clearly, the cost of refusing credit to a good customer is not the same as the cost of granting credit to a bad customer.
A popular method for comparing ROC curves is to calculate the area under the curve (AUC). Since both the x-axis and y-axis are from zero to 1, and since the perfect classifier passes through the point (0, 1), the largest AUC is 1. The AUC for the random classifier (the diagonal line) is 0.5. In general, then, an ROC with a higher AUC is preferred to an ROC curve with a lower AUC. The AUC has a probabilistic interpretation. It can be shown that AUC = P (random positive example > random negative example). That is, this is the probability that the classifier will assign a higher score to a randomly chosen positive case than to a randomly chosen negative case.
Compare Two Example Models Predicting Churn
To illustrate the concepts discussed here, examine a pair of examples with real data. You will construct two simple models for predicting churn, and then compare them on the basis of ROC curves. Open the churn data set (from Chapter 6), and fit a logistic regression:
1. Churn is the dependent variable (make sure that it is classified as nominal), where true, or 1, indicates that the customer switched carriers. For simplicity, choose D_VMAIL_PLAN, VMail_Message, Day_Mins, and Day_Charge as explanatory variables, and leave them as continuous. (If you don’t recall what these variables are, refer to Chapter 6.)
2. Click Run.
3. Under the red triangle for the Nominal Logistic Fit window, click ROC Curve.
4. Since you are interested in identifying churners, when the pop-up box instructs you to Select which level is the positive, select 1 and click OK.
Figure 14.5: ROC Curves for Logistic (Left) and Partition (Right)

Observe the ROC curve together with the line of optimal classification. In Figure 14.5, the AUC is 0.65778, and the left ROC curve. The line of optimal classification appears to be tangent to the ROC at about 0.10 for 1-Specificity and about 0.45 for Sensitivity. At the bottom of the window, click the drop-down menu for the ROC Table. Expand it to see various statistics for the entire data set. Suppose that there is a column between Sens = (1 − Spec) and True Pos. Scroll down until Prob = 0.2284, and you will see an asterisk in the imagined column. This asterisk denotes the row with the highest value of Sensitivity = (1 − Specificity), which is the point of optimal classification accuracy. Should you happen to have 200,000 rows, right-click in the ROC Table and select Make into Data Table, which will be easy to manipulate to find the optimal point. Try it on the present example:
1. In the Logistic Table beneath the ROC Curve, click to expand ROC Table.
2. Right-click in the table itself and select Make into Data Table.
3. In the data table that appears, Column 5 is the imaginary column (JMP creates it for you). Select Rows ▶ Data Filter.
4. Select Column 5 and click Add.
5. In the Data Filter that appears (see Figure 14.6), select the asterisk by clicking the box with the asterisk.
6. Close the data filter by clicking the red X in the upper right corner.
Figure 14.6: Data Filter

In the data table that you have created, select Rows ▶ Next Selected to go to Row 377, which contains the asterisk in Column 5.
You want to see how JMP compares models, so go back to the churn data set and use the same variables to build a classification tree:
1. Select Analyze ▶ Predictive Modeling ▶ Partition.
2. Use the same Y and X variables as for the logistic regression (Churn versus D_VMAIL_PLAN, VMail_Message, Day_Mins, and Day_Charge).
3. Click Split five times so that RSquare equals 0.156.
4. Under the red triangle for the Partition window, click ROC Curve.
This time you are not asked to select which level is positive; you are shown two ROC Curves, one for False and one for True, as shown in the right ROC curve in Figure 14.5. They both have the same AUC because they represent the same information. Observe that one is a reflection of the other. Note that the AUC is 0.6920. The partition method does not produce a line of optimal classification because it does not produce an ROC Table. On the basis of AUC, the classification tree seems to be marginally better than the logistic regression.
Perform a Model Comparison Using the Lift Chart
Now we show how to use the lift chart in practice.
Assess the Business Case. Suppose you intend to send out a direct mail advertisement to all 100,000 of your customers and, on the basis of experience, you expect 1% of them to respond positively (for example, to buy the product). Suppose further that each positive response is worth $200 to your company. Direct mail is expensive; it will cost $1 to send out each advertisement. You expect $200,000 in revenue, and you have $100,000 in costs. Hence, you expect to make a profit of $100,000 for the direct mail campaign. Wouldn’t it be nice if you could send out 40,000 advertisements from which you could expect 850 positive responses? You would save $60,000 in mailing costs and forego $150 * 200 = $30,000 in revenue for a profit of $170,000 − $40,000 = $130,000.
The key is to send the advertisement only to those customers most likely to respond positively, and not to send the advertisement to those customers who are not likely to respond positively. A logistic regression, for example, can be used to calculate the probability of a positive response for each customer. These probabilities can be used to rank the customers from most likely to least likely to respond positively. The only remaining question is how many of the most likely customers to target.
A standard lift chart is constructed by breaking the population into deciles, and noting the expected number of positive responses for each decile. Continuing with the direct mail analogy, you might see lift values as shown in Table 14.3.
Table 14.3: Lift Values
| Decile | Customer | Responses | Response Rate | Lift |
| 1 | 10,000 | 280 | 2.80 | 2.80 |
| 2 | 10,000 | 235 | 2.35 | 2.35 |
| 3 | 10,000 | 205 | 2.05 | 2.05 |
| 4 | 10,000 | 130 | 1.30 | 1.30 |
| 5 | 10,000 | 45 | 0.45 | 0.45 |
| 6 | 10,000 | 35 | 0.35 | 0.35 |
| 7 | 10,000 | 25 | 0.25 | 0.25 |
| 8 | 10,000 | 20 | 0.20 | 0.20 |
| 9 | 10,000 | 15 | 0.15 | 0.15 |
| 10 | 10,000 | 10 | 0.10 | 0.10 |
| Total | 100,000 | 1,000 | 1.00 | NA |
Note: NA = not applicable.
If mailing were random, then you would expect to see 100 positive responses in each decile. (The overall probability of “success” is 1,000/100,000 = 1%, and the expected number of successful mailings in a decile is 1% of 10,000 = 100.) However, since the customers were scored (had probabilities of positive response calculated for each of them), you can expect 280 responses from the first 10,000 customers. Compared to the 100 that would be achieved by random mailing, scoring gives a lift of 280/100 = 2.8 for the first decile. Similarly, the second decile has a lift of 2.35.
A lift chart does the same thing, except on a more finely graduated scale. Instead of showing the lift for each decile, it shows the lift for each percentile. Necessarily, the lift for the 100th percentile equals 1. Consequently, even a poor model lift is always equal to or greater than 1.
To create a lift chart, refer back to the previous section in this chapter, “Compare Two Example Models Predicting Churn,” where you produced a simple logistic regression and a simple classification tree. This time, instead of selecting ROC Curve, select Lift Curve. It is difficult to compare graphs when they are not on the same scale. Furthermore, you cannot see the top of the lift curve for the classification tree. See Figure14.7.
Figure 14.7: Initial Lift Curves for Logistic (Left) and Classification Tree (Right)
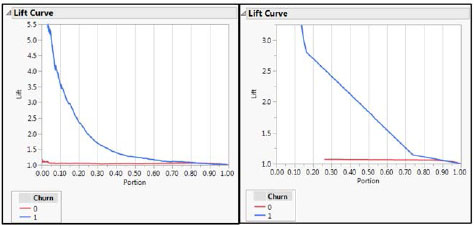
Extend the y-axis for both curves to 6.0:
1. Right-click inside the Lift Curve for the classification tree and select Size/Scale ▶ Y Axis.
2. Near the top of the pop-up box, change the Maximum from 3.25 to 6.
3. Click OK.
4. Do the same thing for the Logistic Lift Curve. (Alternatively, if you have one axis the way you like it, you can right-click it and select Edit ▶ Copy Axis Settings. Then go to the other graph, right-click on the axis, and select Edit ▶ Paste Axis Settings.)
Both lift curve graphs, in Figure 14.8, show two curves, one for False and one for True. You are obviously concerned with True, since you are trying to identify churners. Suppose you wanted to launch a campaign to contact customers who are likely to churn, and you want to offer them incentives not to churn. Suppose further that, due to budgetary factors, you could contact only 40% of them. Clearly you would want to use the classification tree, because the lift is so much greater in the range 0 to 0.40.
Figure 14.8: Lift Curves for Logistic (Left) and Classification Tree (Right)

Train, Validate, and Test
It is common in the social sciences and in some business settings to build a model and use it without checking whether the model actually works. In such situations, the model often overfits the data. That is, it is unrealistically optimistic because the analyst has fit not just the underlying model, but also the random errors. The underlying model might persist into the future, but the random errors will definitely be different in the future. In data mining, when real money is on the line, such an approach is a recipe for disaster.
Therefore, data miners typically divide their data into three sets: a training set, a validation set, and a test set. The training set is used to develop different types of models. For example, an analyst might estimate twenty different logistic models before settling on the one that works the best. Similarly, the analyst might build 30 different trees before finding the best one. In both cases, the model probably will be overly optimistic.
Rather than compare the best logistic and best tree based on the training data, the analyst should then compare them on the basis of the validation data set, and choose the model that performs best. Even this will be somewhat overly optimistic. So to get an unbiased assessment of the model’s performance, the model that wins on the validation data set should be run on the test data set.
Perform Stepwise Regression
To illustrate these ideas, open McDonalds72.jmp, which contains the monthly returns on McDonald’s stock, the monthly return on the S&P 500, and the monthly returns on 30 other stocks, for the period January 2000 through December 2005. You will analyze the first 60 observations, using the last 12 as a holdout sample:
1. As you did earlier in this chapter, select observations 61–72, right-click, and select Exclude/Unexclude.
2. Then select Fit Y by X and click the red triangle to regress McDonalds (Y, response) on the S&P 500 (X, factor).
Observe that RSquared is an anemic 0.271809, which, since this is a bivariate regression, implies that the correlation between y and ŷ is √0.27189=0.52413. This can easily be confirmed:
1. Select Analyze ▶ Multivariate Methods ▶ Multivariate.
2. Select Return on McDonalds and Return on SP500, click Y, Columns, and click OK.
Surely some of the other 30 stocks in the data set could help improve the prediction of McDonald’s monthly returns. Rather than check each stock manually, use stepwise regression to automate the procedure:
1. Select Analyze ▶ Fit Model.
2. Click Return on McDonalds and click Y.
3. Click Return on S&P 500 and each of the other thirty stocks. Then click Add.
4. Under Personality, click Stepwise.
5. Click Run. The Fit Stepwise page will open.
6. Under Stepwise Regression Control, for the Stopping Rule, select P-value Threshold. Observe that Prob to enter is 0.25 and Prob to leave is 0.1.
7. For Direction, select Mixed.
8. Note that Prob to enter is still 0.25, but Prob to leave is now 0.25. Change Prob to leave back to 0.1.
9. Next to each variable are the options Lock and Entered. Entered will include a variable, but it might be dropped later. To keep it always, select Lock after selecting Entered. If you want a variable always omitted, then leave Entered blank and check Lock. You always want Return on SP500 in the model, so check Entered and then Lock for this variable (Figure 14.9).
10. Click Go.
11. Observe that all the p-values (Prob > F) for the included variables (checked variables) in the stepwise output (not counting the intercept) are less than 0.05 except for Stock 21. So uncheck the box next to Stock 21 and click Run Model at the top of the Control Panel. The regression output for the selected model then appears (Figure 14.10).
Figure 14.9: Control Panel for Stepwise Regression

Figure 14.10: Regression Output for Model Chosen by Stepwise Regression

Examine the Results of Stepwise Regression
You now have a much higher R2 of .525575 and five stocks (in addition to S&P500) that contribute to explaining the variation in the Return on McDonalds. Stocks 02, 06, 09, 17, and 18 all have p-values of less than .05. In all, you have a very respectable regression model. You shouldn’t expect to get an R2 of .9 or .95 when trying to explain stock returns.
Indeed, this is where many such analyses stop–with a decent R2 and high t statistics on the coefficients. Concerned as you are with prediction, you have to go further and ask, “How well does this model predict?” If you have correctly fitted the model, then you should expect to see an R2 of about .53 on the holdout sample. This would correspond to a correlation between predicted and actual of √0.53=0.73.
Compute the MSE, MAE, and Correlation
You can compute the MSE, MAE, and Correlation for both in-sample and out-of-sample as shown in Table 14.4:
1. In the Fit Model window, click the red triangle next to Response Return on McDonalds.
2. Select Save Columns ▶ Predicted Values.
3. Follow the same steps (outlined earlier in the chapter) that were used to create Table 14.1. An Excel spreadsheet for the calculations is McDonaldsMeasures72.xlsx.
You will find results matching Table 14.4.
Table 14.4: Performance Measures for the McDonalds72.jmp File
| Mean Squared Error | Mean Absolute Error | Correlation | |
| In-Sample | 0.00318082 | 0.04520731 | 0.72496528 |
| Out-of-Sample | 0.00307721 | 0.04416216 | 0.52530075 |
(If you have trouble reproducing Table 14.4, see the steps at the end of the exercises.)
Examine the Results for MSE, MAE, and Correlation
MSE and MAE are commonly used to compare in-sample and out-of-sample data sets, but they can be misleading. In this case, the MSE and MAE for both in-sample and out-of-sample appear to be about the same, but look at the correlations. The in-sample correlation of .725 compares with the RSquared of the model. Yet the out-of-sample correlation is the same as the original bivariate regression. What conclusion can you draw from this discrepancy? It is clear that the five additional stocks boost only the in-sample R2 and have absolutely no effect on out-of-sample. How can this be?
The reason is that the additional stocks have absolutely no predictive power for McDonald’s monthly returns. The in-sample regression is simply fitting the random noise in the 30 stocks, not the underlying relationship between the stocks and McDonalds. In fact, the 30 additional stock returns are not really stock returns, but random numbers that were generated from a random normal distribution with mean zero and unit variance.1 For other examples of this phenomenon, see Leinweber (2007).
Understand Overfitting from a Coin-Flip Example
Now take another look at this overfitting phenomenon, using coin flips. Suppose that you have forty coins, some of which might be biased. You have ten each of pennies, nickels, dimes, and quarters. You do not know the bias of each coin, but you want to find the coin of each type that most often comes up heads. You flip each coin fifty times and count the number of heads to get the results shown in Table 14.5.
Table 14.5: The Number of Heads Observed When Each Coin Was Tossed 50 Times
| Coin Type | Coin 1 | Coin 2 | Coin 3 | Coin 4 | Coin 5 | Coin 6 | Coin 7 | Coin 8 | Coin 9 | Coin 10 |
| Penny | 21 | 27 | 25 | 28 | 26 | 25 | 19 | 32 | 26 | 27 |
| Nickel | 22 | 29 | 25 | 17 | 31 | 22 | 25 | 23 | 29 | 20 |
| Dime | 28 | 23 | 24 | 23 | 33 | 18 | 22 | 19 | 29 | 28 |
| Quarter | 27 | 17 | 24 | 26 | 22 | 26 | 25 | 22 | 28 | 21 |
Apparently, none of the quarters is biased toward coming up heads. But one penny comes up heads 32 times (64% of the time); one nickel comes up heads 31 times (62%); and one dime comes up heads 33 times (66%). You are now well-equipped to flip coins for money with your friends, having three coins that come up heads much more often than random. As long as your friends are using fair coins, you will make quite a bit of money. Won’t you?
Suppose you want to decide which coin is most biased. You flip each of the three coins 50 times and get the results shown in Table 14.6.
Table 14.6: The Number of Heads in 50 Tosses with the Three Coins That You Believe to Be Biased
| Coin Type | Coin Toss | Number of Heads |
| Penny | No. 8 | 26 |
| Nickel | No. 5 | 32 |
| Dime | No. 5 | 28 |
Maybe the penny and dime weren’t really biased, but the nickel certainly is. Maybe you’d better use this nickel when you flip coins with your friends. You use the nickel to flip coins with your friends, and, to your great surprise, you don’t win any money. You don’t lose any money. You break even. What happened to your nickel? You take your special nickel home, flip it 100 times, and it comes up heads 51 times. What happened to your nickel?
In point of fact, each coin was fair, and what you observed in the trials was random fluctuation. When you flip ten separate pennies fifty times each, some pennies are going to come up heads more often. Similarly, when you flip a penny, a nickel, and a dime fifty times each, one of them is going to come up heads more often.
You know this is true for coins, but it’s also true for statistical models. If you try 20 different specifications of a logistic regression on the same data set, one of them is going to appear better than the others if only by chance. If you try 20 different specifications of a classification tree on the same data set, one of them is going to appear better than the others. If you try 20 different specifications of other methods like discriminant analysis, neural networks, and nearest neighbors, you have five different types of coins, each of which has been flipped 20 times. If you take a new data set and apply it to each of these five methods, the best method probably will perform the best. But its success rate will be overestimated due to random chance. To get a good estimate of its success rate, you will need a third data set to use on this one model.
Thus, you have the train-validate-test paradigm for model evaluation to guard against overfitting. In data mining, you almost always have enough data to split it into three sets. (This is not true for traditional applied statistics, which frequently has small data sets.) For this reason, you split your data set into three parts: training, validating, and testing. For each statistical method (for example, linear regression and regression trees), you develop your best model on the training data set. Then you compare the best linear regression and the best regression tree on the validation data set. This comparison of models on the validation data set is often called a horse race. Finally, you take the winner (say, linear regression) and apply it to the test data set to get an unbiased estimate of its R2, or other measure of accuracy.
Use the Model Comparison Platform
In Chapter 9, you learned how to create a Validation variable to divide the data into Training and Validation sets. This feature also enables you to divide the data in Training, Validation and Test sets if you want. In what follows, to keep things manageable, you will use only the Validation variable to define Training and Validation sets, although you could extend this to Test sets if desired. This section describes the model comparison process for continuous and discrete dependent variables.
Continuous Dependent Variable
Suppose you were concerned with predicting the variable mvalue in the Mass Housing data set, MassHousing.jmp. In previous chapters, you have learned several methods for selecting a subset of variables. Now you will compare two of these methods, the LASSO and stepwise regression, using the Train-Validate-Test framework. To set the stage properly, first use both methods on the entire data set.
Perform the Stepwise Regression
First, run the forward selection version of stepwise regression:
1. Open the Mass Housing data set, MassHousing.jmp.
2. Select Analyze ▶ Fit Model.
3. Select mvalue as Y. Then, after selecting all the remaining variables, click Add under Construct Model Effects.
4. Under Personality, select Generalized Regression and click Run.
5. In the Generalized Regression window, under Estimation Method, choose Forward Selection and click Go. As you can see under Parameter Estimates for Original Predictors, only the variables indus and age have been zeroed out.
Perform the Linear Regression
Run the linear regression with only the nonzeroed variables:
1. Again in the Generalized Regression output, click the red triangle next to Forward Selection with AICc Validation and choose Select Nonzero Terms.
2. Return to the data table, where you can see that the variables indus and age are not highlighted.
3. Select Analyze ▶ Fit Model and click Add to move the nonzero variables to the Construct Model Effects space.
4. Select mvalue and click Y.
5. Under Personality select Generalized Regression and click Run.
6. In the Generalized Regression window, under Estimation Method choose Forward Selection and click Go. You can see that the Generalized RSquare is 0.740582 as showed in Figure 14.11.
Figure 14.11: The Generalized Regression Output for the Mass Housing Data Set with Nonzero Variables

Perform the LASSO
Next, run the LASSO:
1. As above, from the data table, select Analyze ▶ Fit Model, select Recall, and click Run.
2. In the Generalized Regression dialog box, under Estimation Method, choose Lasso and click Go.
3. In the rightmost graph, under Solution Path, move the solid red line until it is on the value 150, as shown in Figure 14.12. Choose the value 150 simply for ease of exposition. There is a very clear break in the data that makes it easy for the reader to reproduce what you do in the text.
Figure 14.12: Solution Path Graphs and Parameter Estimates for Original Predictors

In addition to the intercept, there are three nonzero variables: rooms, pt, and lstat. The coefficient on the intercept should be close to 13.8. It can be hard to move the red line to exactly match a coefficient to several decimals. So if your intercept is close to 13.8, then you have moved the red line correctly.
Next, complete the following steps:
1. Click the red triangle next to Adaptive Lasso with AICc Validation and choose Select Nonzero Terms. You need to make sure that nothing is selected in the data table before doing so.
2. Now return to the data table, select Analyze ▶ Fit Model, and click Add to move the nonzero variables to the Construct Model Effects space.
3. Select mvalue and click Y.
4. Click Run, and click OK. See that the RSquare is 0.678624, substantially lower than that reported by Forward Model Selection.
Compare the Models Using the Training and Validation Sets
Now see how these models do when compared according to the Train-Validate-Test paradigm. (But obviously you are only using Training and Validation sets in this example.) First, you must create the Validation variable:
1. Select Analyze ▶ Predictive Modeling ▶ Make Validation Column, which defaults to 75% for the Training set and 25% for the Validation set.
2. Click Fixed Random and see that the Validation variable has been added to the data table. Note that the random number generator has been used to do this. Your random numbers will differ, so your results will not agree precisely with those in the book.
Next, you must exclude the validation set from your future calculations. To do so, complete the following steps:
1. Select Rows ▶ Data Filter. In the Data Filter dialog box, select the Validation variable and click Add. The dialog box changes slightly.
2. The Select box already is checked, but you want to also check the Include box. Near the bottom of the Data Filter window are two gray rectangles, Training and Validation. Click the Training rectangle.
3. Click the check box to Include. Look at the data table. You can see that the Training data are selected and included, and the validation data are excluded.
Perform Forward Selection and LASSO on the Training Set
nNext, run Forward Selection and the LASSO on the Training set. You will then make predictions on both the Training and Validation sets and compare the predictions by using the Model Comparison Platform.
To run a Forward Selection, complete the following steps:
1. Select Analyze ▶ Fit Model and select mvalue as Y. After selecting all the remaining variables (not including Validation), click Add under Construct Model Effects. Under Personality, select Generalized Regression and click Run.
2. In the Generalized Regression dialog box, under Estimation Method, choose Forward Selection and click Go.
The Generalized Regression will look similar to Figure 14.13.
Figure 14.13: Forward Selection Generalized Regression for Training Data from the Mass Housing Data Set

As can be seen, the Number of rows is 506, but the Sum of Frequencies is 380. (Your number might differ slightly because the number of Training records will be approximately 75%, which is the actual number of observations used in the estimation.) As before, only the variables indus and age are zero, so now run the linear regression with the nonzero variables:
1. Click the red triangle next to Forward Selection with AICc Validation and choose Select Nonzero Terms.
2. Return to the data table and select Analyze ▶ Fit Model.
3. Click Add, select mvalue, and click Y. (Leave the Personality as Standard Least Squares.)
4. Click Run.
The RSquare is about 0.72 or so as shown in Figure 14.14. Remember that the use of the random number generator to select the training and validation sets means that you always have a different training data (and a different validation set) set every time you execute this procedure. Now make predictions from this model:
1. Click the red triangle next to Response mvalue and select Save Columns ▶ Predicted Values. A column Predicted mvalue appears in the data table, with values for both Training and Validation observations.
2. Change the name of this new variable. Right-click at the top of the column Predicted mvalue, select Column Info, and insert FS Predicted mvalue (for Forward Selection) in the box for Column Name.
3. Click OK.
Figure 14.14: Regression Output for Mass Housing Data Set, with Forward Selection

Perform LASSO on the Validation Set
Next, run the LASSO on the Validation set:
1. As before, from the data table, select Analyze ▶ Fit Model.
2. Select mvalue as Y. Then, after selecting all the original remaining variables, click Add under Construct Model Effects.
3. Under Personality, select Generalized Regression and click Run.
4. In the Generalized Regression dialog box, under Estimation Method, choose Lasso and click Go.
5. As before, move the red line in the Solution Path graphs to 150, so that three variables are nonzero: rooms, pt and lstat. Click the red triangle next to Adaptive Lasso with AICc Validation and choose Select Nonzero Terms.
6. In the data table, select Analyze ▶ Fit Model. Note that, for some reason, FS Predicted mvalue has been selected along with the three variables. Click Add and then double-click FS Predicted mvalue to remove it from the Construct Model Effects space.
7. Select mvalue and click Y.
8. Click Run.
The RSquare is about 0.66 as shown in Figure 14.15. Now make the predictions and save them:
Click the red triangle next to Response mvalue and select Save Columns ▶ Predicted Values. You have a new column of Predicted mvalue in the data table. As described earlier, change its name to Lasso Predicted mvalue.
This result does not necessarily compare unfavorably with the 0.72 RSquare from Forward Selection, because they are both in-sample estimates. The real comparison will come on the Validation data.
First, you have to return to the data table and “unexclude” the validation data. In the data table at the top of the row numbers column, are two red triangles. The one at the top right is for the columns. The one at the bottom left is for the rows. Click the one at the bottom left and select Clear Row States. You should see that no rows are selected and no rows are excluded.
Compare Model Results for Training and Validation Observations
To compare the two models results for both the Training and Validation observations, complete the following steps:
1. Select Analyze ▶ Predictive Modeling ▶ Model Comparison.
2. In the Model Comparison dialog box, as shown in Figure 14.16, select FS Predicted mvalue and Lasso Predicted mvalue. Then click Y, Predictors.
3. Select the Validation variable and click Group.
4. Click OK.
The results are presented in Figure 14.17. It is a good thing that you changed the names of the predicted values to include FS and Lasso. Otherwise, you would have a difficult time comparing results.
Figure 14.15: Regression Output for Mass Housing Data Set with Lasso

Figure 14.16: Model Comparison Dialog Box

Figure 14.17: Model Comparison of Mass Housing Data Set Using Forward Selection and Lasso

You can see that the training and validation are approximately the same, so you can be sure that neither method is overfitting. You can also see that the Forward Selection RSquare is noticeably higher than that of the Lasso. So you would prefer the former to the latter in this case. Hopefully, you can see how this method can be extended to Training, Validation, and Test sets if the need arises. For more details, see the Help files to learn about RASE and AAE.
Discrete Dependent Variable
The output for classification problems is a bit different, so let us try such a problem. Let us compare a logistic regression to a Bootstrap Forest. Let us use the logistic regression from Chapter 6 and the data set Churn.jmp. Churn is the dependent variable, and there are ten independent variables:
● State
● Intl_Plan
● D_VMAIL_PLAN (all three of which must be nominal)
● VMail_Message
● Day_Mins
● Even_Mins
● Night_Mins
● Intl_Mins
● Intl_Calls
● CustServ_Call
Create a validation variable and accept the defaults:
1. Select Analyze ▶ Predictive Modeling ▶ Make Validation Column.
2. Click Fixed Random.
3. Click OK.
4. To exclude the Validation observations, selectRows ▶ Data Filter.
5. In the Data Filter dialog box select the Validation variable and click Add. The dialog box changes slightly.
6. The Select box already is checked, but you also want to check the Include box. Near the bottom of the Data Filter window are two gray rectangles, Training and Validation. Click the Training rectangle and click the Include check box.
Run the logistic regression with the dependent and independent variables specified in the previous paragraph, and save the predicted values:
1. Click the red triangle next to Nominal Logistic Fit for Churn and select Save Probability Formula.
2. Four columns are added to the data table; change the name of all of these by adding LR_ at the beginning.
Run a Bootstrap Forest with Churn as the dependent variable and all the other variables (excluding the recently created ones like “Most Likely Churn”!) as independent variables. Save the predicted values:
1. Click the red triangle next to Bootstrap Forest for Churn, select Save Columns ▶ Save Prediction Formula.
2. Three columns are added to the data table. Change the name of all of these by adding BF_ at the beginning.
Before you can use the Model Comparison Platform to compare these two sets of results across the Training and Validation sets, you must unexclude the validation data in the data table. Proceed with the model comparison.
Select Analyze ▶ Predictive Modeling ▶ Model Comparison. For classification problems, for Y, Predictors it is necessary to enter the probabilities of both success and failure for each predictor. This will be represented by a sideways white triangle that can be clicked to show the variables it contains. As seen in Figure 14.18, the first of these has been selected: Prob for Churn (2/0). If you click it, you will see LR_Prob(0) and LR_Prob(1). The predictor variables for the bootstrap forest can be seen already below BF_Prob.
Figure 14.18: Model Comparison Dialog Box

Next complete the following steps:
1. Select Prob for Churn (2/0) and click Y, Predictors.
2. Select BF_Prob(Churn==0) and BF_Prob(Churn==1), and click Y, Predictors.
3. Select the variable Validation and click Group, as shown in Figure 14.18.
4. Click OK.
In the Model Comparison window, click the red triangle and select ROC Curve. A portion of the result is shown in Figure 14.19. (Remember, you will have different numbers due to the use of the random number generator.)
Figure 14.19: Model Comparison Output Using the Churn Data Set

Look at the misclassification rate for the training set on the Bootstrap Forest: 0.0764. As remarked in the chapter on the Bootstrap Forest, you should not be surprised if your result is zero or near zero. The Bootstrap Forest is very flexible and capable of correctly classifying every observation in a training sample. It also seems like the Bootstrap Forest is overfitting, as the misclassification rate is significantly lower. If you were comparing Logistic and Bootstrap Forest models for this problem, you would choose the Bootstrap Forest. However, you would not expect as low of a misclassification rate. How could you get a better estimate of its performance on new data? You would have to use the Train-Validate-Test instead of just Train-Validate!
Exercises
1. Create 30 columns of random numbers and use stepwise regression to fit them (along with S&P500) to the McDonalds return data.
To create the 30 columns of random normal, first copy the McDonalds72 data set to a new file (say, McDonalds72-A). Open the new file and delete the 30 columns of “stock” data. Select Cols ▶ New Columns. Leave the Column prefix as Column and for How many columns to add? Enter 30. Under Initial Data Values, select Random, and then select Random Normal, and click OK.
After running the stepwise procedure, take note of the RSquared and the number of “significant” variables added to the regression. Repeat this process 10 times. What are the highest and lowest R2 that you observe? What are the highest and lowest number of statistically significant random variables added to the regression?
a. Use the churn data set and run a logistic regression with three independent variables of your choosing. Create Lift and ROC charts, as well as a confusion matrix. Now do the same again, this time with six independent variables of your choosing. Compare the two sets of charts and confusion matrices.
b. Use the six independent variables from the previous exercise and develop a neural network for the churn data. Compare this model to the logistic regression that was developed in that exercise.
2. Use the Freshmen1.jmp data set. Use logistic regression and classification trees to model the decision for a freshman to return for the sophomore year. Compare the two models using Lift and ROC charts, as well as confusion matrices.
3. Reproduce Table 14.4. Open a new Excel spreadsheet and copy the variables Return on McDonalds and Predicted Return on McDonalds into columns A and B, respectively. In Excel perform the following steps:
a. Create the residuals in column C, as Return on McDonalds – Predicted Return on McDonalds.
b. Create the squared residuals in column D, by squaring column C.
c. Create the absolute residuals in column E, by taking the absolute value of column C.
d. Calculate the in-sample MSE by summing the first 60 squared residuals (which will be cells 2-61 in column D). Then divide the sum by 60.
e. Calculate the in-sample MAE by summing the first 60 absolute residuals (which will be cells 2-61 in column E). Then divide the sum by 60.
f. Calculate the out-of-sample MSE by summing the last 12 squared residuals (cells 62-73 in column D). Then divide the sum by 12.
g. Calculate the out-of-sample MAE by summing the last 12 absolute residuals (cells 62-73 in column E). Then divide the sum by 12.
h. Calculate the in-sample correlation between Return on McDonalds and Predicted Return on McDonalds for the first 60 observations using the Excel CORREL( ) function.
i. Calculate the out-of-sample correlation between Return on McDonalds and Predicted Return on McDonalds for the last 12 observations using the Excel CORREL( ) function.
4. Using the Churn data set, repeat the above exercise for Logistic, Bootstrap Forest, and Boosted Trees. Which model performs best? (Which does best on the validation data set?) What is the expected performance of this model on new data? (How does it perform on the test data set?)
1 This example is based on Foster and Stine (2006). We thank them for providing the McDonalds and S&P 500 monthly returns.