
As a starting point for this chapter about database access and SQL, we look at how to create a database schema using Groovy. The database model outlined in this recipe will serve as a reference for the rest of this chapter.
The Data Definition Language (DDL) is an essential part of the SQL standard. Through its syntax, it allows defining database objects. These database objects include schemas, tables, views, sequences, catalogs, indexes, and aliases.
Groovy doesn't come with any specific support for this portion of the SQL language. Nevertheless, we can leverage Groovy's conciseness to simplify the database creation operations.
The following image contains a diagram depicting the tables of the schema we will create in this recipe:
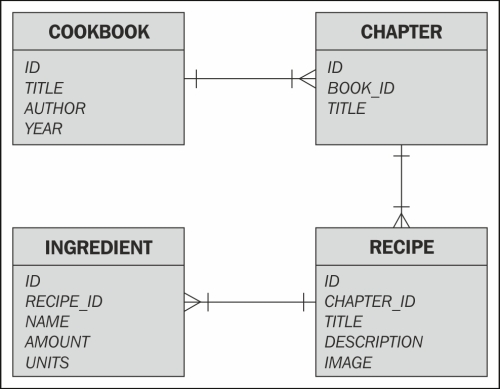
As you can notice, the model represents a cookbook which consists of a set of chapters with cooking recipes. Each recipe has a title, detailed description, image of the desired result, and a list of ingredients required to implement it.
The database that we are going to use all along is HyperSQL 2.3.0 (HSQLDB) in-memory database. HSQLDB is a very popular database written in Java that is very often used for unit testing and creation of application prototypes—thanks to its lightweight nature.
In order to get started, create a new Groovy script named DBUtil.groovy that will contain some routines that will be used throughout this chapter:
- Add the following code to the script:
@GrabConfig(systemClassLoader=true) @Grab('org.hsqldb:hsqldb:2.3.0') import org.hsqldb.Server class DBUtil { static dbSettings = [ url: 'jdbc:hsqldb:hsql://localhost/cookingdb', driver: 'org.hsqldb.jdbcDriver', user: 'sa', password: '' ] static startServer() { Server server = new Server() def logFile = new File('db.log') server.setLogWriter(new PrintWriter(logFile)) server.with { setDatabaseName(0, 'cookingdb') setDatabasePath(0, 'mem:cookingdb') start() } server } } - In a second script,
createDb.groovy, add the following import statements for theDBUtilclass and Groovy's SQL utilities to be visible:import static DBUtil.* import groovy.sql.Sql
- We need to define a list of DDL statements we want to run in order to create the database schema. Let's use just a list of strings for that purpose:
def ddls = [ ''' CREATE TABLE COOKBOOK( ID INTEGER PRIMARY KEY, TITLE VARCHAR(100), AUTHOR VARCHAR(100), YEAR INTEGER) ''', ''' CREATE TABLE CHAPTER( ID INTEGER PRIMARY KEY, BOOK_ID INTEGER, TITLE VARCHAR(100)) ''', ''' CREATE TABLE RECIPE( ID INTEGER PRIMARY KEY, CHAPTER_ID INTEGER, TITLE VARCHAR(100), DESCRIPTION CLOB, IMAGE BLOB) ''', ''' CREATE TABLE INGREDIENT( ID INTEGER PRIMARY KEY, RECIPE_ID INTEGER, NAME VARCHAR(100), AMOUNT DOUBLE, UNITS VARCHAR(20)) ''' ] - Complete the second script with the following code that executes all the previous SQL statements through a
groovy.sql.Sqlinstance in a loop:startServer() Sql sql = Sql.newInstance(dbSettings) ddls.each { ddl -> sql.execute(ddl) } println 'Schema created successfully' - Assuming that both scripts are in the same folder, launch the
createDb.groovyscript passing the folder path (or "." if it's a current directory), where both scripts reside to the-cpparameter:groovy -cp . createDb.groovy - The script should print the following line:
Schema created successfully
The script process will continue to run since the database server thread is still active. You can reuse that to connect to the database and perform queries for later recipes (see the Connecting to an SQL database and Querying an SQL database recipes).
In this first recipe, we have covered quite a lot of ground and some explanation is due. The first script contains a utility class to start the HyperSQL server. The database is started with a name (cookingdb) and the path is set to use memory as storage. This means that when we kill the database process, all the data is lost.
Most of the recipes in this chapter can be run against any relational database. After all this is what SQL is about, a vendor-independent language to query data provided that the proper JDBC drivers are available in the classpath.
This is exactly what the @Grab annotation is there for. It fetches the HyperSQL database drivers as well as the server libraries. This is actually an exception, because, in most database scenarios (MySQL, Oracle, etc.) you'd fetch the drivers only and not a full database engine implementation! The @Grab annotation is accompanied by a second annotation:
@GrabConfig(systemClassLoader=true)
This annotation is forcing Grape to place the dependencies in the system class loader. By default, the dependencies are available in the same class loader as our Groovy script or application. But sometimes this is not enough; a typical case is exactly our case, a database driver which is required to be in the system classpath for the java.sql.DriverManager class to access it.
The DBUtil class also contains the database connection settings that we need to access the in-memory database: one those are defined as a Map and contain the standard information required to connect to any relational database, such as the driver or the server host. You will need to adjust all the parameters to newInstance to connect to your database, especially username and password.
The second script, in which the database tables are actually created, is very simple but contains a key class that we will see over and over in the rest of this chapter's recipes, groovy.sql.Sql (see the Connecting to an SQL database and the Querying an SQL database recipes).
This class does all the connectivity heavy lifting: it connects to the database specified in the dbSettings variable (note that the newInstance method of the Sql class accepts also a plain string) and returns an object that is ready to be used to fire queries to the database to which we are connected to.
Once we get a valid connection, the code simply iterates over the list of SQL statements defined in the ddls variable, and runs them through the execute method of the Sql class.
- Connecting to an SQL database
- Querying an SQL database
- http://hsqldb.org/
- http://groovy.codehaus.org/api/groovy/sql/Sql.html