 Chapter 2 – Vertica Data Distribution
by Leslie Nolander, Tom Coffing
HP Vertica - Architecture and SQL
Chapter 2 – Vertica Data Distribution
by Leslie Nolander, Tom Coffing
HP Vertica - Architecture and SQL
- Cover
- The Tera-Tom Video Series
- The Tera-Tom Genius Series
- Tera-Tom- Author of over 50 Books
- The Best Query Tool Works on all Systems
- Trademarks and Copyrights
- About Tom Coffing
- About Leslie Nolander
- Contents
- Chapter 1 – What is Columnar?
- What is Parallel Processing?
- Nothing Happens on Disk
- Data in Memory is fast as Lightning
- Parallel Processing Of Data
- The Problem with Row-Based Data
- Columnar Data Can Store Each Column in Their Own Block
- Why Columnar?
- Row Based Blocks vs. Columnar Based Blocks
- Visualize the Data – Rows vs. Columns
- The Architecture of Vertica
- Vertica Architecture Terms
- Vertica has Linear Scalability
- Chapter 2 – Vertica Data Distribution
- Distribution Strategy 1 - Segmented By Hash
- Distribution Strategy 2 - Unsegmented
- Sorting the Data in a Table CREATE Statement
- Even Distribution
- Uneven Distribution Where the Data is Non-Unique
- Matching Distribution Keys for Co-Location of Joins
- Big Table / Small Table Joins
- Fact and Dimension Table Distribution Key Designs
- Why a Sort Key Improves Performance
- Sort Keys Help Group By, Order By and Window Functions
- Chapter 3 – Clever Features of Vertica
- Super Projections
- Vertica Projections
- The Five Advantages of Projections
- Creating a Projection
- Read-Optimized Store (ROS)/Write-Optimized Store (WOS)
- Write-Optimized Store (WOS) is Memory Resident
- Updates are collected in Time-Based Buckets called Epochs
- Vertica Does Not Support In-Place Updates
- K-Safety
- K-Safety of 2
- The Five Data Isolation Modes
- Import/Export between Multiple Vertica Systems
- Roles
- Compression
- Runlength encoding
- LZO Encoding
- Delta Encoding
- Block Based Dictionary Encoding for Character Data
- Chapter 4 - Nexus
- Nexus is Available on the Cloud
- Nexus Queries Every Major System
- How to Use Nexus
- Why is Nexus Special? Visualization and Automatic SQL
- Why is Nexus Special? Cross-System Joins
- Why is Nexus Special? The Amazing Hub System
- Why is Nexus Special? Save Answer Sets as Tables
- Why is Nexus Special? Automated Data Movement
- Why is Nexus Special? Nexus makes the Servers Talk Directly
- What Makes Nexus Special? The Garden of Analysis
- The Garden of Analysis Grouping Sets Tab
- The Garden of Analysis - Grouping Sets Answer Sets
- The Garden of Analysis – Join Tab (1 of 4)
- The Garden of Analysis – Join Tab (2 of 4)
- The Garden of Analysis – Join Tab (3 of 4)
- The Garden of Analysis – Join Tab (4 of 4)
- The Garden of Analysis – Charts/Graphs Tab (1 of 4)
- The Garden of Analysis – Charts/Graphs Tab (2 of 4)
- The Garden of Analysis – Charts/Graphs Tab (3 of 4)
- The Garden of Analysis – Charts/Graphs Tab (4 of 4)
- The Garden of Analysis – Dynamic Charts Tab (1 of 4)
- The Garden of Analysis – Dynamic Charts Tab (2 of 4)
- The Garden of Analysis – Dynamic Charts Tab (3 of 4)
- The Garden of Analysis – Dynamic Charts Tab (4 of 4)
- The Garden of Analysis – Dashboard Tab (1 of 5)
- The Garden of Analysis – Dynamic Charts Tab (2 of 5)
- The Garden of Analysis – Dynamic Charts Tab (3 of 5)
- The Garden of Analysis – Dynamic Charts Tab (4 of 5)
- The Garden of Analysis – Dynamic Charts Tab (5 of 5)
- Getting to the Super Join Builder
- The Super Join Builder is the First Entry in the Menu
- The Super Join Builder Shows Tables Visually
- Using the Add Join Button
- What to Do When No Tables are Joinable?
- Drag a Joinable Object into the Super Join Builder
- You will see the Add Custom Join Window
- Defining the Join Columns
- Your Tables Will Appear Together
- Select the Columns You Want on the Report
- Check out the SQL Tab to See the SQL that has been built
- SQL Tab
- Hit Execute to get the Report inside the Super Join Builder
- The Report is delivered inside the Super Join Builder
- Let's Join Two Tables Again (1 of 6)
- Let's Join Two Tables Again (2 of 6)
- Let's Join Two Tables Again (3 of 6)
- Let's Join Two Tables Again (4 of 6)
- Let's Join Two Tables Again (5 of 6)
- Let's Join Two Tables Again (6 of 6)
- The Tabs of the Super Join Builder Philosophy – One Query
- The Tabs of the Super Join Builder – Objects Tab
- The Tabs of the Super Join Builder – Columns Tab)
- The Tabs of the Super Join Builder – Sorting Tab
- The Tabs of the Super Join Builder – Joins Tab
- The Tabs of the Super Join Builder – SQL Tab
- The Tabs of the Super Join Builder – Metadata Tab
- The Tabs of the Super Join Builder – Analytics Tab
- The Tabs of the SJB – Analytics Tab – OLAP Screen
- Getting a Simple CSUM in the Analytics Tab – OLAP
- Getting a Simple CSUM – The SQL Automatically Generated
- The Answer Set of the CSUM
- Getting all of the OLAP functions in the Analytics Tab
- A Five Table Join Using the Menu
- The First Table is placed in the Super Join Builder
- Using the Add Join Cascading Menu
- All Five Tables Are In the Super Join Builder
- A Five Table Join Two Steps (Cube)
- Choose Cube with Columns from the Left Top of the Table
- All Tables are Cubed (Joined Together Instantly)
- Choose Cube and then Choose Your Columns
- Create Cube - Tables Are Joined Without Columns Selected
- Create Cube – Select the Columns You Want on the Report
- How to join Vertica, Oracle and SQL Server Tables
- The Vertica Table is now in the Super Join Builder
- Drag the Joining Oracle Table to the Super Join Builder
- Defining the Join Columns
- Choose the Columns You Want on Your Report
- Let's Add a SQL Server Table to our Vertica and Oracle Join
- Defining the Join Columns
- All Three Tables are now in the Super Join Builder
- Change the Hub and Run the Join on Oracle
- Change the Hub and Run the Join on SQL Server
- Simply Amazing - Change the Hub to the Garden of Analysis
- Have the Answer Set Saved Automatically to Any System
- Saving the Answer Set to an Oracle or SQL Server System
- Saving the Answer Set to a Vertica System
- Saving the Answer Set to a Teradata System
- Chapter 5 – The Basics of SQL
- Introduction
- Setting your Path
- Setting Your Default Database
- SELECT * (All Columns) in a Table
- Fully Qualifying a Database, Schema and Table
- SELECT Specific Columns in a Table
- Commas in the Front or Back?
- Place your Commas in front for better Debugging Capabilities
- Sort the Data with the ORDER BY Keyword
- ORDER BY Defaults to Ascending
- Use the Name or the Number in your ORDER BY Statement
- Two Examples of ORDER BY using Different Techniques
- Changing the ORDER BY to Descending Order
- NULL Values sort First in Ascending Mode (Default)
- NULL Values sort Last in Descending Mode (DESC)
- Major Sort vs. Minor Sorts
- Multiple Sort Keys using Names vs. Numbers
- Sorts are Alphabetical, NOT Logical
- Using A CASE Statement to Sort Logically
- How to ALIAS a Column Name
- A Missing Comma can by Mistake become an Alias
- Aliasing a Column Name with Spaces or Reserved Words
- Comments using Double Dashes are Single Line Comments
- Comments for Multi-Lines
- Comments for Multi-Lines as Double Dashes per Line
- Formatting Number
- Formatting Number Examples
- Formatting Dates
- Formatting Date Example
- Chapter 6 – The WHERE Clause
- The WHERE Clause limits Returning Rows
- Double Quoted Aliases are for Reserved Words and Spaces
- Character Data needs Single Quotes in the WHERE Clause
- Character Data needs Single Quotes, but Numbers Don’t
- Comparisons against a Null Value
- NULL means UNKNOWN DATA so Equal (=) won’t Work
- Use IS NULL or IS NOT NULL when dealing with NULLs
- NULL is UNKNOWN DATA so NOT Equal won’t Work
- Use IS NULL or IS NOT NULL when dealing with NULLs
- Using Greater Than or Equal To (>=)
- AND in the WHERE Clause
- Troubleshooting AND
- OR in the WHERE Clause
- Troubleshooting Or
- Troubleshooting Character Data
- Using Different Columns in an AND Statement
- Quiz – How many rows will return?
- Answer to Quiz – How many rows will return?
- What is the Order of Precedence?
- Using Parentheses to change the Order of Precedence
- Using an IN List in place of OR
- The IN List is an Excellent Technique
- IN List vs. OR brings the same Results
- The IN List Can Use Character Data
- Using a NOT IN List
- Null Values in a NOT IN List Bring Back No Rows
- A Technique for Handling Nulls with a NOT IN List
- BETWEEN is Inclusive
- NOT BETWEEN is Also Inclusive
- LIKE uses Wildcards Percent ‘%’ and Underscore ‘_’
- LIKE command Underscore is Wildcard for one Character
- LIKE Command Works Differently on Char Vs Varchar
- LIKE Command on Character Data Auto Trims
- Quiz – What Data is Left Justified and what is Right?
- Numbers are Right Justified and Character Data is Left
- Answer – What Data is Left Justified and what is Right?
- An Example of Data with Left and Right Justification
- A Visual of CHARACTER Data vs. VARCHAR Data
- Use the TRIM command to remove spaces on CHAR Data
- Escape Character in the LIKE Command changes Wildcards
- Escape Characters Turn off Wildcards in the LIKE Command
- Quiz – Turn off that Wildcard
- ANSWER – To Find that Wildcard
- The Distinct Command
- Distinct vs. GROUP BY
- Quiz – How many rows come back from the Distinct?
- Answer – How many rows come back from the Distinct?
- Chapter 7 – Aggregation
- Quiz – You calculate the Answer Set in your own Mind
- Answer – You calculate the Answer Set in your own Mind
- Quiz – You calculate the Answer Set in your own Mind
- Answer – You calculate the Answer Set in your own Mind
- The 3 Rules of Aggregation
- There are Five Aggregates
- Quiz – How many rows come back?
- Answer – How many rows come back?
- Troubleshooting Aggregates
- GROUP BY when Aggregates and Normal Columns Mix
- GROUP BY delivers one row per Group
- GROUP BY Dept_No or GROUP BY 1 the same thing
- Limiting Rows and Improving Performance with WHERE
- WHERE Clause in Aggregation limits unneeded Calculations
- Keyword HAVING tests Aggregates after they are totaled
- Keyword HAVING is like an Extra WHERE Clause for totals
- Keyword HAVING tests Aggregates after they are totaled
- Getting the Average Values per Column
- GROUP BY Rollup
- GROUP BY Rollup Result Set
- Chapter 8 – Join Functions
- A Two-Table Join Using Traditional Syntax
- A two-table join using Non-ANSI Syntax with Table Alias
- You Can Fully Qualify All Columns
- A two-table join using ANSI Syntax
- Both Queries have the same Results and Performance
- Quiz – Can You Finish the Join Syntax?
- Answer to Quiz – Can You Finish the Join Syntax?
- Quiz – Can You Find the Error?
- Answer to Quiz – Can You Find the Error?
- Super Quiz – Can You Find the Difficult Error?
- Answer to Super Quiz – Can You Find the Difficult Error?
- Quiz – Which rows from both tables won’t return?
- Answer to Quiz – Which rows from both tables Won’t Return?
- LEFT OUTER JOIN
- LEFT OUTER JOIN Results
- RIGHT OUTER JOIN
- RIGHT OUTER JOIN Example and Results
- FULL OUTER JOIN
- FULL OUTER JOIN Results
- Which Tables are the Left and which Tables are Right?
- Answer - Which Tables are the Left and which are the Right?
- INNER JOIN with Additional AND Clause
- ANSI INNER JOIN with Additional AND Clause
- ANSI INNER JOIN with Additional WHERE Clause
- OUTER JOIN with Additional WHERE Clause
- OUTER JOIN with Additional AND Clause
- OUTER JOIN with Additional AND Clause Results
- Quiz – Why is this considered an INNER JOIN?
- Evaluation Order for Outer Queries
- The DREADED Product Join
- The DREADED Product Join Results
- The Horrifying Cartesian Product Join
- The ANSI Cartesian Join will ERROR
- Quiz – Do these Joins Return the Same Answer Set?
- Answer – Do these Joins Return the Same Answer Set?
- The CROSS JOIN
- The CROSS JOIN Answer Set
- The Self Join
- The Self Join with ANSI Syntax
- Quiz – Will both queries bring back the same Answer Set?
- Answer – Will both queries bring back the same Answer Set?
- Quiz – Will both queries bring back the same Answer Set?
- Answer – Will both queries bring back the same Answer Set?
- How would you join these two tables?
- An Associative Table is a Bridge that Joins Two Tables
- Quiz – Can you write the 3-Table Join?
- Answer to quiz – Can you Write the 3-Table Join?
- Quiz – Can you write the 3-Table Join to ANSI Syntax?
- Answer – Can you write the 3-Table Join to ANSI Syntax?
- Quiz – Can you Place the ON Clauses at the End?
- Answer – Can you Place the ON Clauses at the End?
- The 5-Table Join – Logical Insurance Model
- Quiz - Write a Five Table Join Using ANSI Syntax
- Answer - Write a Five Table Join Using ANSI Syntax
- Quiz - Write a Five Table Join Using Non-ANSI Syntax
- Answer - Write a Five Table Join Using Non-ANSI Syntax
- Quiz –Re-Write this putting the ON clauses at the END
- Answer –Re-Write this putting the ON clauses at the END
- Chapter 9 – Date Functions
- Current_Date
- Current_Date, Current_Time and Current_Timestamp
- Timestamp Differences
- Getdate
- Date and Time Keywords
- Using CAST in Literal Values
- Add or Subtract Days from a date
- Formatting Dates
- Formatting Date Example
- A Summary of Math Operations on Dates
- The ADD_MONTHS Command
- Using the ADD_MONTHS Command to Add 1 Year
- Using the ADD_MONTHS Command to Add 1 Year
- Using the ADD_MONTHS Command to Add 5 Years
- The EXTRACT Command
- YEAR, MONTH, and DAY Functions
- A Better Technique for YEAR, MONTH, and DAY Functions
- Another Version of the EXTRACT Command
- EXTRACT from DATES and TIME
- Why EXTRACT is a Better Form
- EXTRACT with DATE and TIME Literals
- EXTRACT of the Month on Aggregate Queries
- AGE_IN_MONTHS
- AGE_IN_YEARS
- DATE_TRUNC
- DATEDIFF
- DAYOFWEEK
- Intervals for Date, Time and Timestamp
- Interval Data Types and the Bytes to Store Them
- Using Intervals
- How a Simple Interval Handles Leap Year
- Interval Arithmetic Results
- A Time Interval Example
- A DATE Interval Example Going Back in Time
- A Complex Time Interval Example using CAST
- A Complex Time Interval Example using CAST
- The OVERLAPS Command
- An OVERLAPS Example that Returns No Rows
- The OVERLAPS Command using TIME
- Chapter 10 – OLAP Functions
- The Row_Number Command
- Quiz – How did the Row_Number Reset?
- Quiz – How did the Row_Number Reset?
- Using a Derived Table and Row_Number
- Finding the First Occurrence using a WITH Derived Table
- Finding the Last Occurrence using a WITH Derived Table
- Ordered Analytics OVER
- RANK and DENSE RANK
- RANK Defaults to Ascending Order
- Getting RANK to Sort in DESC Order
- RANK OVER and PARTITION BY
- PERCENT_RANK OVER
- PERCENT_RANK OVER with 14 rows in Calculation
- PERCENT_RANK OVER with 21 rows in Calculation
- Quiz – What Causes the Product_ID to Reset?
- Answer to Quiz – What Cause the Product_ID to Reset?
- Finding Gaps between Dates
- CSUM – Rows Unbounded Preceding Explained
- CSUM – Making Sense of the Data
- CSUM – Making Even More Sense of the Data
- CSUM – The Major and Minor Sort Key(s)
- The ANSI CSUM – Getting a Sequential Number
- Troubleshooting the ANSI OLAP on a GROUP BY
- Reset with a PARTITION BY Statement
- PARTITION BY only Resets a Single OLAP not ALL of them
- CURRENT ROW AND UNBOUNDED FOLLOWING
- Different Windowing Options
- Moving Sum has a Moving Window
- How ANSI Moving SUM Handles the Sort
- Quiz – How is that Total Calculated?
- Answer to Quiz – How is that Total Calculated?
- Moving SUM every 3-rows Vs a Continuous Average
- PARTITION BY Resets an ANSI OLAP
- The Moving Window is Current Row and Preceding
- How Moving Average Handles the Sort
- Moving Average
- Moving Average
- Quiz – How is that Total Calculated?
- Answer to Quiz – How is that Total Calculated?
- Quiz – How is that 4th Row Calculated?
- Answer to Quiz – How is that 4th Row Calculated?
- Moving Average every 3-rows vs a Continuous Average
- PARTITION BY Resets an ANSI OLAP
- Moving Difference using ANSI Syntax
- Moving Difference using ANSI Syntax with Partition By
- COUNT OVER for a Sequential Number
- COUNT OVER without Rows Unbounded Preceding
- Quiz – What caused the COUNT OVER to Reset?
- Answer to Quiz – What caused the COUNT OVER to Reset?
- The MAX OVER Command
- MAX OVER with PARTITION BY Reset
- MAX OVER without Rows Unbounded Preceding
- The MIN OVER Command
- MIN OVER without Rows Unbounded Preceding
- Finding a Value of a Column in the Next Row with MIN
- The CSUM for Each Product_Id and the Next Start Date
- Quiz – Fill in the Blank
- Answer – Fill in the Blank
- How Ntile Works
- Ntile
- Ntile Continued
- Ntile Percentile
- Another Ntile Example
- Using Tertiles (Partitions of Four)
- NTILE
- NTILE Using a Value of 10
- NTILE with a Partition
- Using FIRST_VALUE
- FIRST_VALUE
- FIRST_VALUE after Sorting by the Highest Value
- FIRST_VALUE with Partitioning
- Using LAST_VALUE
- LAST_VALUE
- Using LAG and LEAD
- Using LEAD
- Using LEAD With and Offset of 2
- LEAD
- LEAD With Partitioning
- Using LAG
- Using LAG with an Offset of 2
- LAG
- LAG with Partitioning
- MEDIAN with Partitioning
- CUME_DIST
- CUME_DIST with a Partition
- SUM (SUM (n))
- Chapter 11 – Temporary Tables
- There are three types of Temporary Tables
- CREATING A Derived Table
- Naming the Derived Table
- Aliasing the Column Names in The Derived Table
- Multiple Ways to Alias the Columns in a Derived Table
- CREATING a Derived Table using the WITH Command
- The Same Derived Query shown Three Different Ways
- Most Derived Tables Are Used To Join To Other Tables
- The Three Components of a Derived Table
- Visualize This Derived Table
- Our Join Example with a Different Column Aliasing Style
- Column Aliasing Can Default for Normal Columns
- A Derived example Using the WITH Syntax
- Quiz - Answer the Questions
- Answer to Quiz - Answer the Questions
- Clever Tricks on Aliasing Columns in a Derived Table
- A Derived Table lives only for the lifetime of a single query
- An Example of Two Derived Tables in a Single Query
- Example of Two Derived Tables in a Single WITH Statement
- Finding the First Occurrence of a Row using WITH
- Finding the Last Occurrence of a Row using WITH
- Syntax for Temporary Tables
- Temporary Tables Explained
- Key Temporary Table Terms
- Creating and Populating a Local Temporary Table
- Using a Local Temporary Table
- Creating and Populating a Global Temporary Table
- Creating and Populating a Global Temporary Table
- Some Great Examples of Creating a Temporary Table Quickly
- Creating a Temporary Table That is sorted
- A Temp Table That Populates some of the Rows
- A Temporary Table with Some of the Columns
- Chapter 12 – Sub-query Functions
- An IN List is much like a Subquery
- An IN List Never has Duplicates – Just like a Subquery
- The Subquery
- The Three Steps of How a Basic Subquery Works
- These are Equivalent Queries
- The Final Answer Set from the Subquery
- Quiz- Answer the Difficult Question
- Answer to Quiz- Answer the Difficult Question
- Should you use a Subquery or a Join?
- Quiz- Write the Subquery
- Answer to Quiz- Write the Subquery
- Quiz- Write the More Difficult Subquery
- Answer to Quiz- Write the More Difficult Subquery
- Quiz – Write the Extreme Subquery
- Answer to Quiz- Write the Extreme Subquery
- Quiz- Write the Subquery with an Aggregate
- Answer to Quiz- Write the Subquery with an Aggregate
- Quiz- Write the Correlated Subquery
- Answer to Quiz- Write the Correlated Subquery
- The Basics of a Correlated Subquery
- The Top Query always runs first in a Correlated Subquery
- Correlated Subquery Example vs. a Join with a Derived Table
- Quiz- A Second Chance to Write a Correlated Subquery
- Answer - A Second Chance to Write a Correlated Subquery
- Quiz- A Third Chance to Write a Correlated Subquery
- Answer - A Third Chance to Write a Correlated Subquery
- Quiz- Last Chance to Write a Correlated Subquery
- Answer – Last Chance to Write a Correlated Subquery
- Quiz – Write the Extreme Correlated Subquery
- Answer To Quiz – Write the Extreme Correlated Subquery
- Quiz- Write the NOT Subquery
- Answer to Quiz- Write the NOT Subquery
- Quiz- Write the Subquery using a WHERE Clause
- Answer - Write the Subquery using a WHERE Clause
- Quiz- Write the Subquery with Two Parameters
- Answer to Quiz- Write the Subquery with Two Parameters
- How the Double Parameter Subquery Works
- More on how the Double Parameter Subquery Works
- Quiz – Write the Triple Subquery
- Answer to Quiz – Write the Triple Subquery
- Quiz – How many rows return on a NOT IN with a NULL?
- Answer – How many rows return on a NOT IN with a NULL?
- How to handle a NOT IN with Potential NULL Values
- IN is equivalent to =ANY
- Using a Correlated Exists
- How a Correlated Exists matches up
- The Correlated NOT Exists
- The Correlated NOT Exists Answer Set
- Quiz – How many rows come back from this NOT Exists?
- Answer – How many rows come back from this NOT Exists?
- Chapter 13 – Strings
- The LENGTH Command Counts Characters
- The LENGTH Command – Spaces can Count too
- The LENGTH Command and Character Data
- LENGTH and CHARACTER_LENGTH Are Equivalent
- OCTET_LENGTH
- UPPER and LOWER Commands
- Using the LOWER Command
- A LOWER Command Example
- Using the UPPER Command
- An UPPER Command Example
- Non-Letters are Unaffected by UPPER and LOWER
- The TRIM Command trims both Leading and Trailing Spaces
- Trim Combined with the CHARACTERS Command
- How to TRIM only the Trailing Spaces
- A Visual of the TRIM Command Using Concatenation
- Trim and Trailing is Case Sensitive
- How to TRIM Trailing Letters
- The SUBSTRING Command
- SUBSTRING and SUBSTR are equal, but use different syntax
- How SUBSTRING Works with NO ENDING POSITION
- Using SUBSTRING to move backwards
- How SUBSTRING Works with a Starting Position of -1
- How SUBSTRING Works with an Ending Position of 0
- An Example using SUBSTRING, TRIM and CHAR Together
- The POSITION Command finds a Letters Position
- Quiz – Find that SUBSTRING Starting Position
- Answer to Quiz – Find that SUBSTRING Starting Position
- Using the SUBSTRING to Find the Second Word On
- Quiz – Why did only one Row Return
- Answer to Quiz – Why Did only one Row Return
- Concatenation
- Concatenation and SUBSTRING
- Four Concatenations Together
- Troubleshooting Concatenation
- Chapter 14 – Interrogating the Data
- Numeric Manipulation Functions
- Finding the Cube Root
- Ceiling Gets the Smallest Integer Not Smaller Than X
- Floor Finds the Largest Integer Not Greater Than X
- The Round Function and Precision
- Quiz – What would the Answer be?
- Answer to Quiz – What would the Answer be?
- The NULLIFZERO Command
- The NULLIFZERO vs. Zeroes
- Quiz – Fill in the Blank Values in the Answer Set
- Answer to Quiz – Fill in the Blank Values in the Answer Set
- Quiz – Fill in the Answers for the NULLIF Command
- Answer – Fill in the Answers for the NULLIF Command
- The ZEROIFNULL Command
- Answer to the ZEROIFNULL Question
- The COALESCE Command
- The COALESCE Answer Set
- The Coalesce Quiz
- Answer – The Coalesce Quiz
- The COALESCE Command – Fill In the Answers
- The COALESCE Answer Set
- COALESCE is Equivalent to This CASE Statement
- Some Great CAST (Convert and Store) Examples
- Some Great CAST (Convert and Store) Examples
- A Rounding Example
- Some Great CAST (Convert and Store) Examples
- Quiz - The Basics of the CASE Statements
- Answer to Quiz - The Basics of the CASE Statements
- Using an ELSE in the Case Statement
- Using an ELSE as a Safety Net
- Rules for a Valued Case Statement
- Rules for a Searched Case Statement
- The Basics of the CASE Statements
- The Basics of the CASE Statement
- Valued Case vs. a Searched Case
- Quiz - Valued Case Statement
- Answer - Valued Case Statement
- Quiz - Searched Case Statement
- Answer - Searched Case Statement
- Quiz - When NO ELSE is present in CASE Statement
- Answer - When NO ELSE is present in CASE Statement
- When an ELSE is present in CASE Statement
- Answer - When an ELSE is present in CASE Statement
- The CASE Challenge
- The CASE Challenge Answer
- Combining Searched Case and Valued Case
- A Trick for getting a Horizontal Case
- Nested Case
- Put a CASE in the ORDER BY
- Chapter 15 – View Functions
- The Fundamentals of Views
- Creating a Simple View to Restrict Sensitive Columns
- You SELECT From a View
- Creating a Simple View to Restrict Rows
- A View Provides Security for Columns and Rows
- Basic Rules for Views
- How to Modify a View
- An Exception to the ORDER BY Rule inside a View
- Views Are Sometimes CREATED for Formatting
- Creating a View to Join Tables Together
- How to Alias Columns in a View CREATE
- The Standard Way Most Aliasing is done
- What Happens When Both Aliasing Options Are Present
- Resolving Aliasing Problems in a View CREATE
- Answer to Resolving Aliasing Problems in a View CREATE
- Aggregates on View Aggregates
- Altering A Table After a View Has Been Created
- A View that Errors after An ALTER
- Chapter 16 – Set Operators Functions
- Rules of Set Operators
- INTERSECT Explained Logically
- INTERSECT Explained Logically
- UNION Explained Logically
- UNION Explained Logically
- UNION ALL Explained Logically
- UNION ALL Explained Logically
- EXCEPT Explained Logically
- EXCEPT Explained Logically
- Minus Explained Logically
- Minus Explained Logically
- Testing Your Knowledge
- Answer - Testing Your Knowledge
- Testing Your Knowledge
- Answer - Testing Your Knowledge
- An Equal Amount of Columns in both SELECT List
- Columns in the SELECT list should be from the same Domain
- The Top Query handles all Aliases
- The Bottom Query does the ORDER BY (a Number)
- Great Trick: Place your Set Operator in a Derived Table
- UNION Vs UNION ALL
- Using UNION ALL and Literals
- A Great Example of how EXCEPT works
- USING Multiple SET Operators in a Single Request
- Changing the Order of Precedence with Parentheses
- Using UNION ALL for speed in Merging Data Sets
- Chapter 17 – Table Create and Data Types
- Distribution Strategy 1 - Segmented By Hash
- Distribution Strategy 2 - Unsegmented
- Sorting the Data in a Table CREATE Statement
- Even Distribution
- Uneven Distribution Where the Data is Non-Unique
- Matching Distribution Keys for Co-Location of Joins
- Big Table / Small Table Joins
- Fact and Dimension Table Distribution Key Designs
- Why a Sort Key Improves Performance
- Sort Keys Help GROUP BY, ORDER BY and Window Functions
- Syntax for Temporary Tables
- Temporary Tables Explained
- Key Temporary Table Terms
- Creating and Populating a Local Temporary Table
- Using a Local Temporary Table
- Creating and Populating a Global Temporary Table
- Creating and Populating a Global Temporary Table
- Some Great Examples of Creating a Temporary Table Quickly
- Creating a Temporary Table That is sorted
- A Temp Table That Populates Some of the Rows
- A Temporary Table with Some of the Columns
- Chapter 18 – Data Manipulation Language (DML)
- INSERT Syntax # 1
- INSERT example with Syntax 1
- INSERT Syntax # 2
- INSERT example with Syntax 2
- INSERT/SELECT Command
- INSERT/SELECT example using All Columns (*)
- INSERT/SELECT example with Less Columns
- Two UPDATE Examples
- Subquery UPDATE Command Syntax
- Example of Subquery UPDATE Command
- Join UPDATE Command Syntax
- Example of an UPDATE Join Command
- Fast UPDATE
- Example of Subquery DELETE Command
- Chapter 19 – Statistical Aggregate Functions
- The Stats Table
- The STDDEV_POP Function
- A STDDEV_POP Example
- The STDDEV_SAMP Function
- A STDDEV_SAMP Example
- The VAR_POP Function
- A VAR_POP Example
- The VAR_SAMP Function
- A VAR_SAMP Example
- The VARIANCE Function
- A VARIANCE Example
- The CORR Function
- A CORR Example
- Another CORR Example so you can compare
- The COVAR_POP Function
- A COVAR_POP Example
- Another COVAR_POP Example so you can compare
- The COVAR_SAMP Function
- A COVAR_SAMP Example
- Another COVAR_SAMP Example so you can compare
- The REGR_INTERCEPT Function
- A REGR_INTERCEPT Example
- Another REGR_INTERCEPT Example so you can compare
- The REGR_SLOPE Function
- REGR_SLOPE Example
- Another REGR_SLOPE Example so you can compare
- The REGR_AVGX Function
- A REGR_AVGX Example
- Another REGR_AVGX Example so you can compare
- The REGR_AVGY Function
- A REGR_AVGY Example
- Another REGR_AVGY Example so you can compare
- The REGR_COUNT Function
- A REGR_COUNT Example
- The REGR_R2 Function
- A REGR_R2 Example
- The REGR_SXX Function
- A REGR_SXX Example
- The REGR_SXY Function
- A REGR_SXY Example
- The REGR_SYY Function
- A REGR_SYY Example
- Using GROUP BY
Chapter 2 – Vertica Data Distribution
“Fall seven times, stand up eight.”
– Japanese Proverb
Distribution Strategy 1 - Segmented By Hash

The entire row of a table is on a segment, but each column in the row is in a separate block. Vertica spreads the rows of a table evenly across the nodes. A good Distribution Key is the key to good distribution!
Distribution Strategy 2 - Unsegmented

When Unsegmented is chosen for distribution, the entire table is copied to each segment. This is often termed replicated. The general idea is to Segment by Hash all large tables and to use Unsegmented on smaller tables.
Sorting the Data in a Table CREATE Statement

We have chosen the Order_Date column as the sort key and the Order_No column as the Hash Key.
Even Distribution

The data has spread evenly among the segments for this table. Do you know why? The Hash Key is Order_No and it is a unique value. Hashing unique values results in near perfect distribution every single time.
Uneven Distribution Where the Data is Non-Unique

The data did not spread evenly among the segments for this table. Do you know why? The Hash Key is Cust_No. All like values went to the same Node. This distribution isn't perfect, but it is reasonable, so it is an acceptable practice.
Matching Distribution Keys for Co-Location of Joins

Notice that both tables are distributed by Hash on the column Dept_No. When these two tables are joined WHERE Dept_No = Dept_No, the rows with matching department numbers are on the same segment. This is called Co-Location. This makes joins efficient and fast.
Big Table / Small Table Joins

Notice that the Department_Table has only four rows. Those four rows are copied to every segment. This is distributed by UNSEGMENTED. Now, the Department_Table can be joined to the Employee_Table with a guarantee that matching rows are co-located. They are co-located because the smaller table has copied ALL of its rows to each Node. When two joining tables have one large table (fact table) and one small table (dimension table), then use the UNSEGMENTED keyword to distribute the smaller table. This theory is also called a "Big Table/ Small Table Join".
Fact and Dimension Table Distribution Key Designs
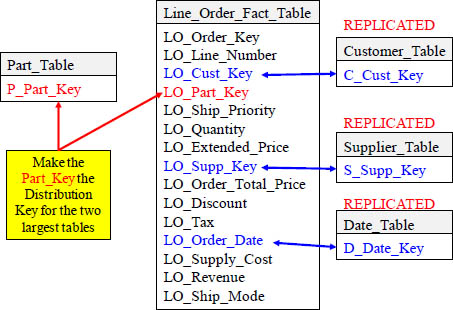
The fact table (Line_Order_Fact_Table) is the largest table, but the Part_Table is the largest dimension table. That is why you make Part_Key the distribution key for both tables. Now, when these two tables are joined together, the matching Part_Key rows are on the same Node. You can then distribute by UNSEGMENTED, which replicates the other dimension tables to each node. Each table will have all their rows on each Node. Now, everything that joins to the fact table is co-located!
Why a Sort Key Improves Performance

There are three basic reasons to use the sortkey keyword when creating a table. 1) If recent data is queried most frequently, specify the timestamp or date column as the leading column for the sort key. 2) If you do frequent range filtering or equality filtering on one column, specify that column as the sort key. 3) If you frequently join a (dimension) table, specify the join column as the sort key. Above, you can see we have made our sortkey the Order_Date column. Look how the data is sorted!
Sort Keys Help Group By, Order By and Window Functions

When data is sorted on a strategic column, it will improve (GROUP BY and ORDER BY operations), window functions (PARTITION BY and ORDER BY operations), and even as a means of optimizing compression. But, as new rows are incrementally loaded, these new rows are sorted but they reside temporarily in a separate region on disk. In order to maintain a fully sorted table, you need to run the VACUUM command at regular intervals. You will also need to run ANALYZE.
-
No Comment