
CHAPTER 4
Service Design
In this chapter, you will
• Understand the purpose of the Service Design lifecycle stage
• Recognize the five ingredients of holistic service design and the four principles of Service Design
• Appreciate the importance of the service design package (SDP)
• Examine in more detail the eight processes that sit in Service Design
You left Chapter 3 and the Service Strategy stage of the lifecycle with a specification for a new or changed service together with an approved business case. By now you should have a clear idea of how value is intended to be created for your customer, particularly regarding the balance between utility and warranty, in other words, between the promise that’s been made and what is needed to ensure that promise can be kept. In addition, the Service Pipeline of the Service Portfolio will now show this new or changed service moving into Service Design, releasing the resources that were specifically required in Service Strategy and now taking up different resources as required for the Service Design stage.
In this chapter, you will consider the features of the Service Design stage, examine the eight processes that are included in it, review the roles and responsibilities specific to this stage, and look at how tools can help you. You will pay particular attention to the major deliverable that is produced at the end of this lifecycle stage: the service design package (SDP) that is handed on to Service Transition.
It is important to appreciate that in this stage and in Service Transition there is an almost complete integration between IT Infrastructure Library (ITIL) and what is happening in projects and programs. The principles of ITIL should be followed by projects, and your organization’s methods and management systems should ensure that project and nonproject work does not exist in parallel but unconnected worlds. Of course, project and program managers have specific responsibilities for driving their work to completion, but the prescription they are given should make it clear that conforming to the organization’s service management policy is mandatory.
The Purpose of Service Design
This stage of the lifecycle provides guidance on the design and development not only of services but also of service management practices. Those services are to meet both the current and the future needs of the business. Specific purposes (objectives, if you prefer) can be considered under the following headings:
• Coordinate Design Activities To ensure that the resources required in this stage are used as efficiently and effectively as possible.
• Policies and Standards To produce a number of Service Design policies subordinate to those in Service Strategy; those earlier policies should be developed in this lifecycle stage alongside local standards and applied in all areas of service design and planning.
• Process Quality To assess the effectiveness and efficiency of the eight design processes.
• Forward-Compatible Design To ensure that new or changed services can be developed and enhanced in the future as easily as possible within appropriate timescales.
• Plans To produce and maintain plans, processes, policies, architectures, frameworks, and documents for the design of high-quality IT services.
• Costs To control the long-term costs of service provision, reducing, minimizing, or constraining them as necessary.
• Service Management System To design a system that is efficient and effective.
• Security and Resilience To design IT infrastructures that are both secure and resilient.
• Efficiency of Effort To reduce the need for reworking or for urgent, interim enhancement of services.
• Skills and Capabilities To develop the skills and capabilities of the individuals and the functions of the service provider.
Holistic Service Design
There are five major aspects of Service Design, all of which must be addressed when designing new or changed services: solutions; management information systems and tools; technology architectures and management architectures; processes; and measurement methods and metrics. They are described in the following sections.
Service Solutions
This should be obvious. These are the actual new or changed services themselves, to be designed using a structured and formal approach and incorporating adequate flexibility for easy future evolution.
Management Information Systems and Tools
These include the service portfolio (with which you are already familiar) and systems you will meet later such as the service knowledge management system (SKMS) and the configuration management system (CMS). In many cases, these systems and tools are used throughout the service lifecycle, but they are designed in Service Design (unsurprisingly!) using the same structured and formal approach that is used in the design of service solutions.
Technology Architectures and Management Architectures
On one hand, you have the technical aspect of the IT infrastructure, its constituent components, and their relationship to each other. On the other hand, you need to align the management architecture with the business, not with the technology. That should ensure that the needs of the business have the greatest weight.
Processes
The 26 processes don’t just happen by accident. They have to be designed, and that is done in Service Design (there’s a remorseless logic about that, isn’t there?).
Measurement Methods and Metrics
There appears to have been a long tradition in IT that people think about measurement only once a new application is running reasonably well in the live environment. However, you are a professional service manager, so you should start thinking in detail about this aspect now. Provision should have been made in the business case for the necessary resources, and you will be seeing how the Continual Service Improvement stage of the lifecycle (Chapter 7) provides invaluable guidance and assistance.

EXAM TIP These five aspects of holistic service design are a gift for exam question setters. You would be wise to remember these five aspects; put them in your list of top revision topics.
The Principles of Service Design
ITIL seems to love having enumerated lists; you’ve just had the five aspects of holistic service design, and you’ll coming across others later. However, you’re now going to consider the four P’s of Service Design, which are the four all-important areas that need to be considered in successful Service Design (so ITIL says). The four Ps are as follows:
• People This is perhaps the most challenging P. People (IT staff, customers, users, board executives, and so on) have to be managed, persuaded, motivated, supervised, trained, paid, and so on.
• Processes This is ITIL, so it’s no surprise to see processes here.
• Products This P covers services, technology, and tools (I think it’s a bit contrived to link these three under the P word products, but there you are!).
• Partners This means suppliers, manufacturers, and vendors with whom things work better if you view them as “partners” in your quest for service management excellence.
Keeping these four Ps in mind helps you prepare better and manage better toward achieving the successful delivery of IT services.
EXAM TIP These four Ps are as equally attractive to question setters as the five aspects of holistic service design. Please add the four Ps and their significance to your list of top revision topics.
The Service Design Package
It is fundamental to an understanding of ITIL that you see the service lifecycle as a set of interconnected and interreliant stages. As you progress from one lifecycle stage to the next, there is a formal handover/acceptance and, in the reverse direction, continual service improvement ensures that the necessary feedback takes place (go back and look again at Figure 2-2 if needed). From Service Strategy into Service Design, you see the specification of new or changed services (you may come across the concept of “service packages” in this context); then, when you get to the end of Service Transition, you will see how Release and Deployment Management covers the crucial move into the live environment. But now, covering the move from Service Design into Service Transition, you have the service design package (SDP). But there’s more to it than that. The SDP is not just a blueprint to guide Service Transition but provides detailed requirements and plans for operating the new or changed service in the live environment, for continual service improvement and for the ongoing development of the service concerned.
You also use an SDP for the retirement of a service. You shouldn’t just switch off a service like you would turn off a light. You need to ensure that there are no remaining interdependencies from other services on the service you are retiring, you should be equally careful to ensure that any infrastructure components you plan to remove or redeploy are not being used by some other system or service, and you must not forget to update all relevant documentation.
Whether you are moving a new or changed service into transition or perhaps requiring Service Transition to retire a service, I’m sure you can appreciate that not only must the Service Portfolio and the Service Catalog be updated but so must your configuration information (but let’s not rush on too fast; you’ll be looking specifically at Configuration Management in Chapter 5).
I think you’re now ready to examine the sort of things that go into your SDP.
Business Requirements These should have been clearly documented in Service Strategy and developed in Service Design. Any changes made to the business requirements during Service Design should have been controlled by Change Management (see Chapter 5).
Functional Requirements When you think of functionality, you should automatically think of utility, shouldn’t you? This is the promise of all the good things the new or changed service is going to give you. Functional requirements should logically be derived from the business requirements; any changes to functionality should also be equally controlled.
Operational Requirements Ah, yes! Projects (formal or informal) are sometimes tempted to downplay this aspect. Inescapable elements such as capacity and security aspects are normally addressed seriously, but there can be a temptation for other considerations, such as those that come under the headings of availability, service continuity, service desk support, and so on, to be glossed over. You’ll doubtless remember that in Chapter 3, when I discussed warranty, I made the point that you must make as much provision for the warranty as you do for utility; otherwise, you won’t be able to deliver on your promise.
Service Level Requirements Service level requirements (SLRs) record the desired level of warranty. They are a vital input to the negotiation of service level agreements (SLAs), which should specify service and quality targets. You keep a record of the SLRs in the SDP in order to have a reference to what the customer originally wanted.
Design Topology Topology is a splendid word for ITIL to use, isn’t it? (The Concise Oxford Dictionary defines topology as the “study of geometrical properties and spatial relationships unaffected by continuous change of shape or size of figures,” so there you have it!). Whatever may be the dictionary definition of topology, this part of the SDP covers the following:
• The definition of the service
• Hardware, software, applications, tools, networks, and so on (essentially the components of the service—configuration management again)
• All relevant documentation (including user, business, support, and so on)
• Processes, measurements and metrics, and reports
• Supporting products and services
In your studies you could at this point usefully revisit the five aspects of holistic service design and the four Ps of Service Design that you encountered earlier in this chapter. They’re still relevant, aren’t they?
Organizational Readiness Assessment This leads on from your business, functional, and operational requirements as covered earlier. If you haven’t defined and documented those, you’ll find it difficult to undertake an organizational readiness assessment. The readiness assessment should cover such areas as finance, technology, resources, service provider skills and competencies, and the capabilities of potential suppliers.
Service Transition Plan You may argue that this is up to Service Transition. Not so, I’m afraid. Those involved in Service Transition cannot have anything like the same knowledge and understanding of the new or changed service as those who are developing it. Therefore, the SDP tells Service Transition in detail how the new or changed service is to be built, tested, and deployed. Of course, Service Design’s instructions must conform to the agreed-on Service Transition policies, but it may be necessary to introduce some new transition techniques and resources; those aspects would be covered here too.
Acceptance Criteria Transition staff can be expected to be the experts in testing, but they shouldn’t be expected to set the criteria for deeming tests to be successful for each specific new or changed service. Those criteria must already have been documented by Service Design in the SDP.
Service Program This covers all stages of the service lifecycle for the new or changed service in question. It should include any phasing and the timescales for Transition, Operation, and subsequent Continual Service Improvement. In doing so, it draws together all the aspects covered in the SDP.
No new or changed service should be accepted for work in Service Transition until an SDP for it has been formally agreed on and documented between Service Design and Service Transition.
If you want to see a detailed specification for an SDP, please look at Appendix A of the main ITIL Service Design volume.
Service Design Processes
The eight processes described next were briefly outlined in Chapter 2. You will now examine them in detail, but before you get caught up in that, it will be useful to consider how they are connected to each other.
EXAM TIP You must have a clear idea of which processes fit into which lifecycle stage. If you can remember the eight processes that belong to Service Design, it will help you place the other 18 in their rightful places.
Design Coordination is largely focused on the Service Design stage of the service lifecycle, and its name gives a clue to the lifecycle stage it belongs to. The next process you should think about is Service Catalog Management, and, as I’m sure you’ll remember, the service catalog is in some respects a more detailed subset of the service portfolio you encountered in Service Strategy. In the same way that Service Design adds detail to the concepts of Service Strategy, the Service Catalog amplifies part of the Service Portfolio.
Having got your services cataloged, you can then do Service Level Management (SLM). SLM is about negotiating SLAs, negotiating operational level agreements (OLAs), working closely with Supplier Management regarding underpinning contracts (UCs), carrying out review meetings, and running a continual service improvement program. Clearly, you can’t carry out those service-related activities until you’ve first defined what your services are. That hasn’t stopped many from attempting to do it the wrong way around!
When you are negotiating SLAs, many of the targets you set are dependent on inputs from the Availability Management and Capacity Management processes. It is also a good idea to include IT Service Continuity and Information Security aspects in SLAs. Thus, you have four processes that fit together: Availability, Capacity, Continuity, and Security. Where have you seen these four listed together previously? Yes, they comprise warranty, don’t they? These are the aspects you must address if you are to be able to deliver on the promise you made under utility.
Now let’s get down to looking at each process individually.
Design Coordination Process
Design Coordination works within Service Design in a somewhat similar way to how Strategy Management does in Service Strategy. Its purpose is to ensure that the objectives of the Service Design stage are met by providing and maintaining a single point of coordination and control for all activities and processes that fall within this stage of the service lifecycle. That, of course, includes the relevant activities of programs and projects.
To meet that purpose, Design Coordination should do the following:
• Monitor Service Design activities to ensure consistency.
• Ensure the production of SDPs that conform to the agreed-on template and that are acceptable to Service Transition.
• Manage the handover of new or changed services from Service Strategy to Service Transition. This also includes services that are being retired.
• Ensure that Service Design conforms to strategic, architectural, and governance needs.
• Seek to improve the Service Design processes themselves in conjunction with the process owners.
• Review, measure, and improve the performance of all Service Design activities and processes.
• Create and maintain a common framework of Service Design practices.
• Support and guide each project or change through all the Service Design activities and processes.
• Maintain policies, guidelines, standards, budgets, models, resources, and capabilities for Service Design activities and processes.
• Plan, forecast, coordinate, prioritize, and schedule all resources used in Service Design.
• Ensure that utility and warranty requirements are addressed in service designs along with all other requirements.
Effective Design Coordination will resolve conflicting demands for shared Service Design resources, will ensure that SDPs are accurate and consistent, and will help to produce new or changed services that will meet the expectations of the service provider’s customers.
Service Catalog Management Process
Service Catalogs complement the Service Portfolio you encountered in Service Strategy and can appear in many shapes and sizes depending on the complexity of the service provider, the type of service provider (Type I, Type II, or Type III; see Chapter 1), and the maturity of their IT service management arrangements. The crucial point is that unless you have some sort of a list and a definition of your services, how can you begin to “do service management”? What you haven’t defined you can’t manage. Well, you can manage it only by inspiration and guesswork, which does not guarantee consistent and effective results!
An outsourced service provider (a Type III service provider) will almost invariably have some sort of a service catalog, although it may be just a glossy brochure of their offerings to potential customers. This will of course be a product of the “marketing mind-set” mentioned in Chapter 3. However, there’s more to a service catalog than a tempting brochure, so, ask yourself, is it a good idea for your service catalog to be owned and published exclusively by the sales and marketing team? You’ll find out more later in this chapter. Furthermore, the situation I’ve often come across regarding Type I and Type II service providers is even more disparate (or even “desperate,” shall I say!).
What I found when I created and published the first service catalog for Tradeteam was that it was certainly useful for users to see the services available to them together with important information about those services. But, more than that, it was equally useful not only for all in the IS department (a Type I service provider) but also for those in Exel who were providing shared services acting as a Type II service provider and for Computacenter who provided service desk and server management and administration services as a Type III service provider. The service catalog enabled all stakeholders to have a clear view of what was being provided to support Tradeteam’s business. It gave a clear picture of how the outcomes of the customer (Tradeteam is a drinks logistics business) were being facilitated by the services provided by the IS department and how the specific costs and risks behind those services were managed by the IS department, thereby leaving Tradeteam’s core logistics business to get on trucking the drinks. We’re back with your old friend the definition of service again, aren’t we?
Definition of a Service Catalog
ITIL defines a Service Catalog as “a database or structured document with information about all live services including those available for deployment.”
EXAM TIP This definition is a gift for examiners writing questions. Remember this definition and you won’t be looking a gift horse in the mouth!
Purpose of a Service Catalog
The purpose of the service catalog can be summarized as “providing a single source of consistent information on all live services and those being prepared to go live and to ensure that it is widely available to those who are approved to access it.”
To meet that purpose, the Service Catalog Management process has to do the following:
• Manage the structure and contents of the catalog, ensuring that it is complete, accurate, and up-to-date. This includes the checking and authorization of all proposed changes.
• Work with Availability Management and Security Management to ensure that those who need access to the catalog can actually see what they need while excluding those without a need to see specific elements. However, in general the service catalog should be widely accessible unless there is a justification to restrict access to certain defined areas.
These are other factors that need to be considered:
• Developing and maintaining service descriptions. It can be a useful mental discipline for the author to have to encapsulate in no more than, say, 200 words exactly what each particular service is about. But take care to ensure that the customer-facing services are defined as such; customers don’t need to be concerned with specific application or technical components (application modules and particular servers, for example). Customers want e-mail; they don’t want applications and servers.
• Using language that is appropriate for the readers of the catalog. Don’t forget, this is an important element of communication with the user community. You want users to consult the catalog to understand how the services help them do their job, how to obtain support when they need it, and how to get the best out of the technology they’ve been given.
• The technical platform on which the catalog will be established. For example, it may be published in an intranet or be a document within a document management system such as SharePoint. In such cases the owner of the catalog needs to have some form of SLA or OLA with the provider of that resource to ensure that the catalog can be managed efficiently and effectively.
• There is a close relationship between the Service Catalog and the configuration management system (CMS); see Chapter 5. The Service Catalog gives the important features of the services it contains and the relationships between those services, while the CMS is at a more detailed level and contains information on the actual components of each service and the relationships between those components. It is possible to conceive of a Service Catalog as being a report derived from the CMS.
In the following sections you’ll consider various types of Service Catalogs, but you must remain aware that your service catalog will evolve over time. New services will be added, old ones retired, and the maturity and usefulness of your catalog should grow—it’s all continual service improvement (CSI)! So, let’s look at some options.
The Simple Service Catalog
If you’re starting with a blank piece of paper, I suggest that rather than plunging into detail and, perhaps, acquiring a sophisticated tool, you keep it simple to begin with. A straightforward matrix as shown in the example in Figure 4-1 provides simple but valuable information and will provide a solid foundation to develop your catalog further. It enables you to achieve quickly a single source of comprehensive and accurate information on all live services and services being prepared to go live. You can then add more detail as necessary and as available resources permit.

Figure 4-1 Example of a simple service catalog
Business or Customer Service Catalog
It won’t be long before you’ve built a catalog that is useful to the business you support and the customers whose outcomes your services are facilitating (see Figure 4-2). Here you are not only showing which customers are using which services but also enabling your customers to see what other services are available and which they may want to use too. Moreover, the information provided compared to the simple catalog mentioned earlier will cover such useful areas as support hours, escalation paths, and so on; these are areas you’ll have extracted from the relevant service level agreement. There’s usually no need to publish the whole SLA because it will contain a lot of detail, which can be unhelpful and misleading outside of the particular audience for which the SLA has been produced.

Figure 4-2 Business or customer service catalog
Technical or Supporting Service Catalog
As I’ve mentioned several times, you must bear in mind your definition of service. The business/customer catalog shows the services that facilitate the customer’s outcomes (such as e-mail). So, where do you show all those specific costs and risks that the service provider has to manage? They’re in the technical/supporting service catalog, as in the diagram at Figure 4-3. This catalog covers not only the technical infrastructure but also such items as applications and outsourced services.

Figure 4-3 Technical or supporting service catalog
Alternative Views of the Service Catalog
The model you have been considering so far is known in ITIL as the two-view service catalog, as shown in Figure 4-4.

Figure 4-4 Two-view service catalog
However, you may want to provide a selection of different views of the service catalog depending on the audiences to be addressed and the use to which the catalog will be put. ITIL gives the example of a three-view service catalog (Figure 4-5) where the service provider want to differentiate between the set of services provided to (in this example) a wholesale operation and a retail operation while identifying which services are used by both operations.

Figure 4-5 Three-view service catalog
EXAM TIP The two-view and three-view service catalogs are deemed by examiners to be permissible views of the service catalog along with the business or customer service catalog and technical or supporting service catalog.
To summarize, the Service Catalog Management process does the following:
• Enables the service provider to identify those services that can be bundled together to provide a solution to a particular customer’s set of requirements
• Informs customers of the services that are available and that they might want to avail themselves of
• Enables the service provider’s staff and contractors to see where and how their activities underpin the services being provided to customers
• Helps manage the expectations and preparedness of both the customer and the service provider regarding those services that will be rolled out in the near future
• Defines the communication paths between the service provider and the customer and users, including escalation, the handling of service requests, and so on
• Publishes appropriate service-level commitments and targets
• Addresses the first of the five aspects of holistic service design: service solutions
It can also cover other useful areas such as pricing or costs, service continuity arrangements, and information security considerations.
Service Level Management (SLM) Process
I hope you’re now familiar with the definition of service. I’ve also covered how all services are included in the Service Portfolio and that the services that are live or being prepared to go live are in the Service Catalog part of the Service Portfolio. Furthermore, the Service Catalog provides customers, users, and IT staff with a good deal of useful information. Having confirmed that, you’re now in a position to look at the formal, detailed ingredients of your services; this is where SLM comes in.
ITIL says the purpose of SLM is to ensure that all current and planned IT services (in other words, those in the Service Catalog) are delivered to agreed-on, achievable targets. Let’s look a bit closer at that last phrase.
• “IT services . . . are delivered . . .” SLM is looking forward to live operation where you are actually going to deliver value to your customers and collect the evidence to show that you are.
• “. . . to agreed-on . . .” You are going to negotiate with your customers not only to agree on the functionality of the service (the utility, of course) but also the warranty aspects (availability, capacity, continuity, and security).
• “. . . achievable . . .” The targets you agree on must be achievable. You may think that this is obvious. Well, you’d be surprised how many targets agreed on in SLAs are not just unachievable at the time they were agreed on but could never be achieved with the resources available. Furthermore, I’ve seen some agreed-on targets that are actually unmeasurable!
• “. . . targets.” Do the chosen targets make sense, and are they relevant? Are you selecting certain metrics as targets purely because you can measure them regardless of whether they are relevant? This where the fifth aspect of the five aspects of holistic service design should be considered: measurement systems and metrics. You’ll return to this point in Chapter 7.
This purpose is achieved through a constant cycle of negotiation, agreement, monitoring, reporting, and review of service targets and achievements supported by Continual Service Improvement (CSI). Do you remember my ten commandments from Chapter 1?
Thou shalt have . . .
1. Clearly defined, agreed-on, and documented roles and responsibilities
2. Clearly defined, agreed-on, and documented services
3. Clearly defined, agreed-on, and documented processes
4. Clear ownership of services and processes, as well as all other components of the infrastructure
5. Meaningful process and service metrics
6. Measurement of performance at the point of service delivery
7. Review of performance of services and processes
8. Publication of reports on performance
9. A service improvement program
10. Clear communication between IT and users to establish and nurture trust between IT and the business
I hope you agree that all ten are relevant to SLM, which shows just how important a process this is.
In achieving that purpose, you need to do the following:
• Ensure that the Service Level Management and Business Relationship Management processes are aligned and coordinated. The owners of the two processes must maintain a close liaison (of course, in some organizations, they may be the same person, which should help).
• Negotiate. The owner and the manager of the process should be good negotiators. Negotiations start with the service level requirements, which record the customers’ wishes regarding the level of warranty and which are an important element of the SDP. Constructive negotiations then take place with the stakeholders to formalize the SLAs (and the underpinning OLAs) and contracts. You’ll look at these in more detail later.
• Monitor, report, and review. Having produced your SLAs, you shouldn’t lock them away in a four-drawer filing cabinet never to see the light of day again. These are living documents the contents of which the stakeholders should be able to change as necessary. Monitoring and reporting performance against the SLA targets enables you to identify where improvements need to be made, where targets are too ambitious, or where resources may be over-generous and could be better deployed elsewhere. These reviews not only help manage customer expectations and improve communication but also enable potential improvements to be identified and action instigated.
Figure 4-6 shows the process diagrammatically.

Figure 4-6 Service Level Management process
You need to examine these three documents (SLA, OLA, and UC) in greater detail.
Service Level Agreement (SLA)
First, let’s clear away some common misapprehensions. In ITIL an SLA itself is not a contract (although contracts will commonly have SLAs in them). The ITIL definition is as follows (emphasis mine): “An SLA is a written agreement between IT service provider and customer defining the key service targets and the responsibilities of both parties.”
An SLA is a formal document that should be signed at an appropriately high management level. It should never be a stick with which the two parties can beat each other! It should be clearly understandable and written in language appropriate to the customer. Moreover, it should be a document that reflects an emotionally mature, partnership relationship, not the equivalent of a Nelsonian Articles of War!
Operational Level Agreement (OLA)
OLAs are similar to SLAs in being formal documents that should be signed at an appropriate management level. The ITIL definition is as follows (again, emphasis mine): “An OLA is an underpinning written agreement between two elements of the service provider organization regarding the key service targets and responsibilities of both parties relating to the services being supported.”
Again, it should never be a stick with which the two parties can beat each other up, and it should be clearly understandable, written in language (probably technical) appropriate to the service provider.
Underpinning Contract (UC)
Underpinning contracts are looked after by Supplier Management, and unlike SLAs and OLAs, underpinning contracts are legally binding agreements that will have to conform to contract law and the contract policy of the organization concerned. Again, they should be clearly understandable, but, being contracts, they will probably be written in legal language and may be clear only to a trained lawyer!
EXAM TIP SLAs and OLAs are negotiated by SLM; all contracts are negotiated by Supplier Management. Examiners like to establish whether you have this concept clear in your mind.
It is a major challenge to SLM to keep all SLAs, OLAs, and UCs in alignment. Some organizations, therefore, take an unhelpful view that these SLAs, OLAs, and UCs should not be changed once agreed on. That flies against the principles of service management, which requires reporting, reviewing, and subsequent change to be a fundamental element of best practice. Stay flexible!
Let’s now look at how they fit together in Figure 4-7.
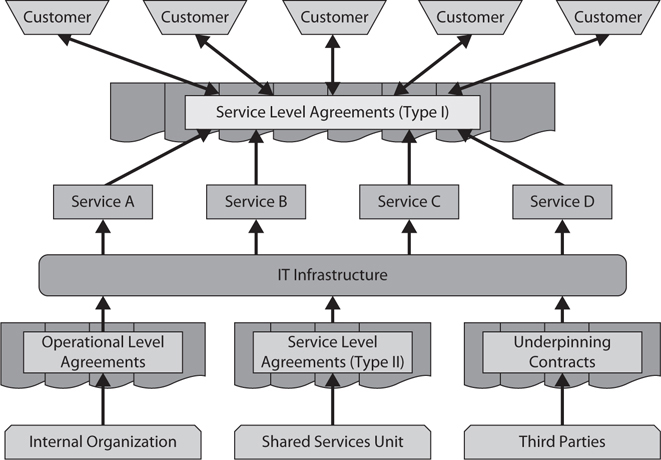
Figure 4-7 Service Level Management, single-level overview
You may like to compare this to the service catalog in Figure 4-4 and see how the SLAs (“classic” SLAs as I call them) align with the business/customer service catalog, while the OLAs and UCs align with the technical/supporting service catalog.
However, I find that diagram is a little over-simplistic and that in reality relationships are more complex; Figure 4-8 is a better reflection of the real world.

Figure 4-8 Service Level Management, multiple-level overview
Here, if you take the example of Tradeteam, the ultimate customer, it is the logistics business of Tradeteam that is having its outcomes facilitated by the services being delivered by Tradeteam IS out of the IT infrastructure as documented in SLAs with its underpinning OLAs and UCs. In turn, those UCs are themselves services being provided to Tradeteam by a third-party service provider (Type III service provider), for example Computacenter. From Computacenter’s viewpoint, it is in the position of Figure 4-7, but, in the big world, it is sitting between the ultimate customer and Computacenter’s own underpinning contractors (who would be subcontractors as far as Tradeteam is concerned).
You could of course continue this concatenation ad infinitum (there’s another good word and even some Latin for you!). At the bottom of Figure 4-8, what you see as subcontractors would have their own contractors too. At the top end of the chain, Tradeteam as a business has its own customers (pubs and breweries) for whom Tradeteam is itself an outsourced service provider. Somewhere above all of this are you and me who’ve popped down to the pub for a quiet beer—it’s enough to drive you to drink, isn’t it?
Exercise 4-1: Service Level Agreement Contents
Now you should have a clear picture of SLAs, OLAs, and UCs, and I hope you can see how the SLA is crucial and that it is underpinned by OLAs and UCs. You should also have an idea of what an SLA contains. I suggest you get yourself a piece of paper and list as many specific things as you can that you believe should be found in an SLA; I gave you earlier the definition of SLA, and (always being helpful) I’ll add that an SLA should include a description of the IT service, of service level targets, and of the specific responsibilities of the parties to the agreement. Take about ten minutes to scratch your head and produce your list. My suggested answer is at the end of this chapter.
Have you done the exercise? Yes? Good, then let’s move on.
I see Service Level Management as having five major themes. Three you’ve encountered already: SLAs, OLAs, and UCs. The other two are service reviews and service improvement plans.
Service Reviews
These typically take place at various management levels and frequencies. You’d expect the service manager and the customer’s management representative to meet on a monthly basis, the service owner and the equivalent customer manager to meet quarterly, and an annual top-level review to take place between the appropriate higher management grades. Whatever the management level, each meeting should review the performance against targets, consider the impact and cost of breaches, note the recommendations and actions of subordinate reviews, look ahead to future plans and their impact, and provide inputs to the service improvement plan (or service improvement program, if you prefer). These reviews will be informed by appropriate reports of which a common style is the service level agreement monitoring (SLAM) chart, as shown in Figure 4-9.

Figure 4-9 SLAM chart
SLAM charts provide an attractive, visual representation of achievement against target. Red indicates a target breached, amber indicates a target that was nearly breached, and green indicates a target met with reasonable comfort; what would constitute “nearly breached” and “reasonable comfort” would be specified in the appropriate SLAs. These color-coded charts are sometimes called red-amber-green (RAG) charts.
Service Improvement Plan
This is a formal plan to implement improvements to an IT service (or a process for that matter). It should conform to the service provider’s continual service improvement policy and program (see Chapter 7).
Service Level Agreement Structures
Good questions to ask are, how many SLAs should you have, and how should you arrange them? You know that there’s going to be some common ground between them, and you don’t want to create a bureaucratic nightmare. ITIL helps you work through this conundrum by giving some useful guidance.
There are two basic SLA structures: service-based and customer based.
• Service based Here you have an SLA for each service, notwithstanding the number of different customers using it. One service, lots of customers.
• Customer based You guessed it! You have an SLA for each customer, notwithstanding the number of different services shared between several customers. One customer, lots of services.
You can readily see that going for just one or the other of these two structures would lead to a great deal of duplication, nugatory administrative work, and an increased risk of things getting out of alignment. In practice, you find that service providers have adopted a multilayer structure.
Multilayer Structure At the top you have corporate-layer matters that apply to all customers; the SLA for the e-mail service would be a typical example. Beneath the corporate layer you have a set of customer-layer SLAs that cover the services used uniquely by each individual customer plus a reference both to the corporate-layer SLAs and to the service-layer SLAs for any services shared with other customers. Finally, you find the service-layer SLAs for those services that I’ve just mentioned, in other words, those that are shared by two or more customers. This multilayer structure is the one adopted by many organizations because it is clearer and administratively more efficient.
Summary of Service Level Management
By this stage of discussing Service Level Management I often find that delegates’ eyes are becoming glazed over. So, let’s get back to the basics. Wake up at the back there! Service level agreements (SLAs) are between the service provider and the customer (the customer can be internal or external). Operational level agreements (OLAs) are between teams and groups within the service provider’s own organization. For underpinning contracts (UCs), the clue is in the name; they are contracts, in other words, legally binding agreements between a third-party and its customer. Thus, OLAs and UCs are straightforward, but SLAs are a little more complex. Picking up on the concept of service provider types (see Chapter 1) I see there being three equivalent types of SLA.
• Type I SLA This is the classic SLA between an internal service provider and its internal customers. Tradeteam would have SLAs between the IS department and the depots, the finance department, and so on.
• Type II SLA These are SLAs between a shared services unit (a Type II service provider as described in Chapter 1) and the Type I service providers in the business units that are receiving the service and that are under the umbrella of the top-level business. These SLAs should not be contractual. This is because the service provider and the business units are within the same organization.
• Type III SLA These are the contractual SLAs that are typically found in the appendixes to contract documents. They are not stand-alone contracts in themselves, but their provisions are upheld by the contract of which they are part.
Earlier in your consideration of this process I mentioned that you must ensure that the Service Level Management (SLM) and Business Relationship Management (BRM) processes are aligned and coordinated. Now that you’ve looked at SLM in some detail, it should be helpful to compare BRM and SLM. See Table 4-1.

Table 4-1 BRM and SLM Compared
Capacity Management
You’ll now examine the four processes that cover the aspect of value creation that is defined as warranty; those four processes are Capacity Management, Availability Management, IT Service Continuity Management, and IT Security Management. You’ll start with Capacity Management.
The purpose of the Capacity Management process is to “ensure that the capacity of IT services and of the IT infrastructure meets the agreed capacity and performance-related requirements in a cost-effective and timely manner. Capacity Management is concerned with meeting both the current and the future capacity and performance-related needs of the business.”
I’d like to highlight a few words in the previous quotation.
• “. . . agreed . . .” The capacity requirements should not be dreamt up by the service provider alone, nor should the business abdicate its responsibilities and leave this to the service provider to do. The outline capacity requirements and related costs should have been identified in Service Strategy, specifically in the Demand Management process if you remember. In Service Design you are going to review those in detail, and in Service Level Management, your skilled negotiators will have agreed on detailed capacity requirements with the customer. Capacity Management has a vital, expert role in that negotiation at the conclusion of which the agreed-on capacity aspects will be documented in the SLAs.
• “. . . performance-related . . .” In ITIL when you talk about performance, you almost invariably link it to Capacity Management.
EXAM TIP If you see the word performance in an exam question, think capacity.
• “. . . cost-effective and timely . . .” Capacity costs money—sometimes a lot of money. Good service management practice requires you to justify what you spend on providing capacity. You need to make sure you maximize the return on investment (ROI). You also want to ensure that the right capacity is in the right place at the right time. You don’t want to spend money unnecessarily early, but you don’t want to overlook a developing capacity requirement or miss an opportunity for a discount-price purchase and then end up having to make an expensive panic buy.
• “. . . current and the future . . . needs . . .” How clearly is your crystal ball working? Capacity Management needs to have good communication with Business Relationship Management and Service Level Management to get the earliest possible indication of future needs.
Subprocesses of Capacity Management
Capacity Management can be complex; to help you understand it better, ITIL considers it within three, hierarchical subprocesses.
• Business Capacity Management This ensures that Capacity Management is aligned to business plans and strategy, translating requirements into services and infrastructure. An example is a logistics business expanding and building more depots that will significantly impact the amount and location of the IT resources needed to deliver services. The Business Capacity Management subprocess and the Business Relationship Management process need to work closely together.
• Service Capacity Management Working within the context of Business Capacity Management, Service Capacity Management ensures that the services themselves underpin the business processes (facilitating those all-important outcomes) and keeps in focus the end-to-end performance of operational services and their associated workloads. The Service Capacity Management subprocess and Service Portfolio Management process need to work closely together and also with the other processes in Service Design.
• Component Capacity Management At its heart, Capacity Management is one of the most technical of ITIL processes. It ensures there is an appropriate technical understanding of all the components of the infrastructure, and it employs techniques of data analysis and tuning to get the maximum value from them. Component Capacity Management relies on the information held in the configuration management system (CMS) and should work closely with Service Operation regarding capacity-related aspects of the live environment.
Reactive and Proactive Activities
As in every process there is a number of activities, which in Capacity Management fall under two broad headings: reactive and proactive.
In Capacity Management reactive activities are
• Monitoring, measuring, reporting, and reviewing the current performance of services and of components. The raw data will be captured in the Service Operation phase of the lifecycle and then passed to Capacity Management for processing and analysis.
• Responding to occurrences in the live environment where activity against preset thresholds triggers the intervention of Capacity Management. An example of such a threshold would be disk utilization reaching 80 percent. You’ll be looking specifically at these sorts of occurrences in Event Management in Chapter 6.
• Responding to and assisting with any other specific performance issues.
In Capacity Management proactive activities are
• Analyzing performance data and associated trends and taking appropriate action to preempt developing performance issues.
• Employing techniques such as mathematical modeling and application sizing to estimate the impact of changes in IT services and their components.
• Ensuring that capacity-related infrastructure changes are budgeted, planned, and implemented in a timely fashion.
• Tuning services and components to optimize performance. An example would be to balance the load on data circuits. However, there is only so much benefit to be gained from tuning; once you’ve achieved as perfect a balance as you can, you may not be able to avoid having to spend money to increase total capacity.
• Following technological developments to identify new advances that should be pursued.
• Producing and maintaining the capacity plan (there’s more on this in a moment).
Demand Management
I mentioned in Chapter 3 during your brief consideration of the Demand Management process that you’d be revisiting it when you got to Capacity Management. That moment has arrived.
The first point to make is that, in contrast to Demand Management in Chapter 3, what I’ll cover now is in the syllabus for the ITIL Foundation exam.
Those patterns of business activity (PBAs) that you met in Chapter 3 can show some extreme fluctuations, whether that be over a daily, weekly, monthly, or annual period. The impact could be that, to meet the peaks, you would have to invest a lot of money in resources that would be underutilized for most of the time. It’s similar to the challenge facing the London Underground subway, which has to provide a lot more trains during the rush hour than for the rest of the time.
To try to keep a lid on costs, the service provider needs to work with its customers to see whether some reasonable changes to business practice could help smooth out those peaks. However, an ideal result may not be possible. In that case, it may mean that the business would have to accept some constraint on its activities during “prime time” unless it was prepared to pay a lot of money to avoid doing so. Under those circumstances, it could be agreed that higher charges would be levied at peak times (as some energy companies do) to dissuade users from taking up the service, or some physical constraint could be applied such as limiting the number of concurrent logons to a particular application. However, whatever method is employed, it must be agreed on with the customer because it affects their service. The employment of such a constraint should be formally recorded and reviewed periodically to see whether some relaxation has become possible.
Capacity Plan
Capacity Management focuses on producing the capacity plan, which is used to help manage the resources needed to deliver IT services, so it’s quite important! The production of the capacity plan is often aligned with the service provider’s budget cycle because it forms the basis for inputs to the financial plan. A capacity plan should include the following:
• Details of the current and historic levels of resource utilization and service performance.
• Projections for changes in capacity to meet future service needs.
• The assumptions on which the plan is founded. Business-related assumptions should be provided to the service provider by the customer. If the customer doesn’t know what their future business is going to look like, how can the service provider be expected to know better?
• A set of recommendations based on the varying possible scenarios of business developments and available finance. These recommendations should comprise a set of costed options.
The capacity plan is an extremely useful tool for the IT director (or whoever is considered to be “top management” in this context). The capacity plan sits alongside the service portfolio as a valuable tool for managing current and planned resources. It is also valuable in circumstances such as those that can arise when finance directors announce that budget cuts are necessary. In the absence of an agreed-on capacity plan, IT directors have found themselves not just advising but actually making decisions that have a business impact—decisions that should properly be made by the customer of the service whose outcomes will no longer be facilitated as well as they have been! Because the capacity plan in conjunction with the service portfolio clearly links service assets to the business outcomes, it puts the onus for making decisions with a business impact where they belong, with the business.
Conclusion
To wrap up Capacity Management, you can see that it is quite a technical process and that it is crucial to ensuring the right resources are in the right place at the right time to enable services to be delivered at a performance level that the business requires. In other words, it makes a vital contribution to the warranty of a service. The process itself is a careful balancing act: supply against demand; cost against resources needed.
Availability Management
An intimate bedfellow of Capacity Management is Availability Management, the second of the four processes you’re examining that cover the aspect of value creation that is defined as warranty. Availability Management has a number of themes common to Capacity Management; therefore, if you feel some wording here is similar to that used previously, don’t be surprised!
The purpose of the Availability Management process is to “ensure that the level of availability delivered in all IT services meets the agreed availability needs and/or service level targets in a cost-effective and timely manner. Availability Management is concerned with meeting both the current and the future availability needs of the business.”
As I did for the previous process, I’d like to highlight a few words in the this definition:
• “. . . agreed . . .” The availability targets should not be imposed by the customer nor by the service provider. The outline availability requirements and related costs should have been identified in Service Strategy and documented in the customer’s service level requirements. In Service Level Management you take those SLRs and negotiate and agree on appropriate availability targets, which should be relevant and achievable. You then document them in the SLAs.
• “. . . cost-effective and timely . . .” The higher the level of availability required, the higher the cost; as with capacity, you need to make sure you maximize the value of your investments. You also want to ensure that changes to availability are introduced in alignment with the business requirements and that you gain the benefit of improved availability as soon as resources permit.
• “. . . current and the future . . . needs . . .” I hope you haven’t put away your crystal ball yet! Business Relationship Management and Service Level Management should be keeping open good communication with Availability Management to give notification as early as possible of any changes that will affect availability-related resources and targets.
The Four Aspects of Availability
In achieving the purpose of Availability Management, ITIL asks you to consider four aspects.
• A—Availability This means the ability of a service or a component to perform its agreed-on, documented function when required.
• R—Reliability This is how long a service or component can perform its function without interruption. In other words, how long does it work before it breaks? You can increase reliability by adding resilience to failure.
• M—Maintainability This is how quickly and effectively a service or component can be returned to its agreed-on functionality after failure. In other words, how quickly, efficiently, and effectively can you fix it when it does break?
• S—Serviceability This is a more ITIL-specific word. It refers to the ability of a supplier (a third party) to meet the contractual targets for availability, reliability, and maintainability. This takes you back to the definition of service, doesn’t it? If you outsource a service, you now become the customer and so availability, reliability, and maintainability of that which has been outsourced becomes a specific risk. As a customer, you do not own the specific, detailed risks; they are now the contractor’s. But you are still, of course, interested in the performance of the service; you are interested in serviceability.
EXAM TIP In the previous list you have a helpful acronym, ARMS, for these four aspects. Remember ARMS and you won’t forget the essentials of availability.
Other Important Principles
There are also other important principles regarding Availability Management that you need to consider.
• There are two levels of availability: service availability and component availability. Service availability is focused on the end-to-end service as experienced by the user and the customer; component availability concentrates on the links in the chain that together provide service availability.
• Service availability is directly linked to customer satisfaction, specifically, the targets in SLAs and those published in the Service Catalog.
• How the service provider reacts to failures is a key factor. Most reasonable people understand that sometimes things break. If it is clear to them that the service provider always takes swift action to restore service, customer satisfaction may not be impaired. Of course, you do get the “odd bod” who’s never satisfied, but that’s life.
• Availability can be truly improved only when you understand the business. You should ask yourself what targets are important to the business and which ones aren’t? By all means have excellent component availability, but ensure that service availability is your primary focus.
• Availability is only as good as the weakest link. This underpins the previous point. To improve service availability, you need to have effective, focused component availability.
• Prevention is better than cure. If you can become proactive rather than reactive, that’ll be clearly a good thing.
• It’s always more expensive to retrofit availability. This goes for all areas of Service Design. Making corrections at this lifecycle stage involves minimal cost, probably no more than an amendment to a specification or plan. Once you’ve acquired, built, and tested the necessary configuration, let alone rolled it out, significant changes can be expensive and disruptive.
Reactive and Proactive Activities
In common with Capacity Management, Availability Management has reactive and proactive sides to it.
In Availability Management reactive activities are:
• Monitoring, measuring, reporting, and reviewing the current live availability data relating to services and components. The raw data will be captured in the Service Operation phase of the lifecycle and then passed to Availability Management for processing and analysis.
• Responding to and assisting with any availability-related issues in the Service Transition and Service Operation lifecycle stages.
In Availability Management proactive activities are:
• Analyzing reliability and maintainability data and associated trends and taking appropriate action to preempt developing availability issues
• Employing techniques such as risk analysis, component failure impact analysis, fault-tree analysis, and the expanded incident lifecycle (more details are given later in the chapter)
• Ensuring that availability-related infrastructure changes are budgeted, planned, and implemented in a timely fashion
• Following technological developments to identify on the market new components offering improved reliability and maintainability
• Producing and maintaining the availability plan
Risk Analysis
I mentioned risk analysis in Chapter 1, and I said that you undertake risk assessment in a number of processes in ITIL; a really important one is, of course, Availability Management. I’m sure you’ll remember that ITIL defines risk as “uncertainty of outcome” and that the three steps you take are identification, analysis, and management.
In Availability Management you have to identify all the resources and capabilities that enable your services and note where risk is to be found; you’re going to look for such things as single points of failure, poor skills, and unreliable resources (I’ll be mentioning some relevant techniques). You can then analyze those weaknesses to measure them, ascertain the impact of situations that are likely to arise regarding them, and prioritize the vulnerabilities you have found; you are going to be particularly interested in identifying the vital business functions. A good example of a vital business function is the automated teller. The vital business function as far as the customer is concerned is getting their hands on the money. In comparison, the little piece of paper that gives you your balance is just a “nice to have.”
Question: Who decides what constitutes a vital business function?
Answer: The customer (in discussion with the service provider).
You can then take the appropriate management steps: to remove the risk entirely or, if it is unavoidable (a frequent situation), to mitigate the risk to an acceptable level.
For example, you may decide that having a single data circuit for an important service is too high a risk. You would then invest in a duplicated circuit so that if one circuit breaks, the other can carry the load until the break is fixed. Here you are adding resilience to failure. Do you remember that I mentioned this when considering the acronym ARMS?
Many service providers are required by their customers to deliver what is called high availability. With so much activity taking place online these days, there is often a business need for 100 percent 24/7 service: the ultimate in warranty. If customers are prepared to pay the bill to achieve this, the service provider had better make sure that their risk management is pretty good!
You’ll take a further look at risk management when you come to IT Service Continuity Management.
Component Failure Impact Analysis
A useful technique for helping to identify high-impact areas of failure is component failure impact analysis (CFIA). However, before you can undertake CFIA, you need to ensure you have accurate information on either the planned configuration, the live configuration, or both. Keep that in mind for when you look at configuration management in the Service Transition stage of the lifecycle. Typically a CFIA requires the creation of a matrix such as in Figure 4-10.

Figure 4-10 Component failure impact analysis
On one axis you list the configuration components—configuration items (CIs) as you call them—and on the other the services supported by them. It’s a bit like the customer view of the Service Catalog where you can see which business processes will be impacted by the loss of a specific service. In CFIA you want to identify which specific services will be impacted by the loss of a particular configuration item. You can then apply your “management” element of Risk Management to do something about it.
Fault-Tree Analysis
Complementary to CFIA is fault-tree analysis (FTA), which helps you particularly to identify single points of failure (SPOFs). FTA uses Boolean logic, as in Figure 4-11.

Figure 4-11 Fault-tree analysis
Here you can see that for the payroll service to fail you would need to have to suffer a shortage of disk space that coincides with a period of unattended operations. The logic is that if a shortage of disk space were to arise during attended operations, it would be dealt with and failure would be prevented, and obviously if no disk space issue were to arise during unattended operations, then there would be no service failure either.
Drilling down further, you can then see that shortage of disk space could arise from either high volumes of data or a failure in archiving (in other words, a failure to release extra disk space). It isn’t necessary for both circumstances to arise to experience a failure; either will suffice (although you could have both on a bad day!).
In contrast, the situation of unattended operations would result from only two coincidental and concurrent problems: staff shortage and staff sickness. You could cope with either but not with both at the same time.
FTA is a technique that is particularly valuable during Service Design in helping you “design in” availability for new or changed services. It doesn’t provide a solution, but it highlights where the challenges lie.
Expanded Incident Lifecycle
This technique is a good example of reactive availability management because it uses incident data, which was originally captured in live operations and has then been processed for relevance before presentation to availability management.
Availability Management will then analyze this information, as shown in Figure 4-12.

Figure 4-12 Expanded incident lifecycle
As an example, you could consider a particular make and model of printer that the customer uses widely.
From all the relevant incident records you can calculate how long, on average, a printer runs before a failure occurs. This calculation is the Mean Time Between Failures (MTBF).
You can also calculate how long, on average, it takes to restore normal service after a printer failure. This calculation is known as the Mean Time to Restore Service (MTRS).
A further calculation you can make is the average length of time between one failure and the next one, notwithstanding how long the MTRS may be. This calculation is called the Mean Time Between System Incidents (MTBSI).
You can think of the MTBF as being the uptime, a measure of reliability, and the MTRS as being the downtime, a measure of maintainability. The MTBSI indicates how often you get disruption no matter how quickly you can fix it and, as such, is another measure of reliability.
There are five sequential elements that comprise downtime: the time it takes to detect a relevant incident, the time to diagnose the fault, the time to repair whatever has broken, the time to recover (in this case) the printer back to the configuration, and, finally, the time to restore normal service (including restoring any lost data and clearing any backlogs). If you can remember DDRRR, you should be able to remember these five elements.
Availability Management can then consider each element and recommend improvements such as autodetect, diagnostic scripts, prepositioning spares, configuration guidance, and restoration checklists.
The aim of this technique is to improve uptime (MTBF). Paradoxically, if you improve just the downtime (MTRS), the MTBSI could get worse. Your printers break more frequently, but you can fix them faster!
I’ve covered a number of different measurements that are used within Availability Management, but what are the measurements that are used frequently to express the availability actually experienced and what availability measurements are of interest to customers?
Measuring Availability
The “classic” availability measure is percentage availability. But percentage of what? You can measure the availability of components as a percentage of the planned uptime, but the fact that a host server has been up 100 percent is of little relevance to the customer if the data network has been down 5 percent during that time. In my “ten commandments,” I declared that you must measure service at the point of delivery, and that is what you should do.
A good way of measuring end-to-end availability is by examining the incident records because each incident should indicate a possible loss of service and should record how long it took before normal service was restored (think back to the expanded incident lifecycle previously). You can then calculate the percentage of unplanned downtime, report it, and try to improve it.
But is a percentage figure the most useful measure you could have? Unplanned downtime that occurs during periods of quiet demand (for example, late Friday afternoon when many may have gone home) has far less impact than unplanned downtime that hits during “prime time.” If you have good incident records, you should be able to capture the number of users affected and for how long. Then you can calculate the number of man-hours lost. You can even take that further and translate it into lost productivity, which would enable you to calculate the sum of money that the outage has cost the customer. That’s a powerful metric. If the same outage occurs frequently and each time it causes a loss of productivity of, say, $30,000 (about £20,000) but you could prevent it by spending, say, $15,000 (about £10,000) on a permanent improvement, it should be a “no brainer,” shouldn’t it?
Percentage figures are always going to be important when calculating and reporting the availability of the components that form the links in the chain of end-to-end availability, but service providers and customers should give thought to what is the best measure of end-to-end service.
One final thought in carrying out these calculations: you do not have to aim to achieve an accountancy level of accuracy (although if you’re following Six Sigma, you may not be able to avoid it). You need sufficient accuracy to make informed management decisions and to be able to monitor improvement. Be careful not to inadvertently turn Availability Management into an advanced MBA assignment!
IT Service Continuity Management
Some of you may remember Donald Rumsfeld, the erstwhile U.S. Secretary of Defense who, in a reply to a question in 2002 regarding the lack of evidence linking the government of Iraq with weapons of mass destruction, said, “. . . because as we know, there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns—the ones we don’t know we don’t know. . . .”
How true! You can add to that a fourth category, the “unknown known,” that which you don’t acknowledge that you know.
What’s all this got to do with IT Service Continuity Management (ITSCM)?
First, let’s go back to Capacity Management and Availability Management. There you’ve been planning for the expected—for “known knowns” as Rumsfeld put it. In contrast, ITSCM is about planning for the unexpected and certainly the unwelcome—for Rumsfeld’s “known unknowns” in fact. Then, if your ITSCM is sufficiently flexible, you may be able to cope with some of the “unknown unknowns.” However, if you suspect you’ve got some “unknown knowns,” I think you’d better make a note to yourself to pay attention when you get to Knowledge Management in Chapter 5!
I’d also like to make it clear that I’m not talking just about disaster recovery (DR), important though that is; DR is part of ITSCM, which is a much broader subject.
The purpose of ITSCM is to support the overall business continuity management (BCM) arrangements by managing the risks that could seriously affect critical IT services and to agree on minimum service levels that would apply in contingencies.
ITSCM requires you to do the following:
• Create ITSCM plans that support the BCM plans
• Participate in business impact assessment
• Perform risk assessment and management
• Provide advice and guidance on ITSCM aspects to other areas
• Implement the agreed-on service continuity mechanisms and arrangements
• Assess the impact on the ITSCM plan of all changes
• Work with Supplier Management to negotiate and agree on recovery contracts
Back in Availability Management, you undertook risk analysis where you examined your services and their components, looked at likely events and their potential impact, and then took appropriate action. In Availability Management, anything that was likely to happen and that would impact services should be addressed. In ITSCM you look at events that are unlikely but not inconceivable and that would have sufficient impact on services to make contingency planning advisable. This is illustrated in Figure 4-13.

Figure 4-13 Impact and likelihood
I must confess that as a past military contingency planner this is one of my favorite processes!
Figure 4-14 shows the process workflow.

Figure 4-14 IT Service Continuity Management process workflow
The first and most important point to repeat is that you don’t do ITSCM in isolation. It must be done in full alignment with the business whose processes your services are supporting. As elsewhere in ITIL, it is for the customer, the business, to decide priorities and to provide financial resources. A responsible business will, of course, meet the IT service provider halfway to ensure that the most cost-effective plans are agreed on.
As you can see from Figure 4-14, ITSCM comprises three sequential stages: initiation, requirements and strategy, and implementation. The fourth stage is ongoing operation and, as such, never ceases.
Initiation
Perhaps this is where an awful truth dawns and you and the business realize how vulnerable you are to unexpected events. It’s time to take action: to agree on a policy, to set the scope, to form a project, and to get some resources. All this should be done in conjunction with Business Continuity Management (BCM). If there’s no BCM, it could be time for the IT director to make an appointment to see the chief executive officer (CEO)!
Requirements and Strategy
This is where you get into the detailed work. In particular, the service provider should participate in a business impact analysis (BIA) with the customer, in other words, a risk analysis.
Here you should decide which services are critical (back to those vital business functions you encountered in Availability Management). Then you can consider the various unexpected and unwelcome events that might hit you. Such contingencies often include high-order communications failure, a major fire, or serious flooding; other contingencies could be as follows:
• Terrorism (an outrage itself or a reaction to a terrorist threat, such as an office evacuation, for example).
• Widespread staff sickness (H5N1 bird flu strikes the United Kingdom)
• Effects of a cyberattack (this is becoming more of an availability issue these days)
• Lottery win (if one of your data center shifts has a lottery syndicate and they win Euromillions, don’t expect to see them again any time soon—it has happened!)
You can produce your own list, of course, taking inspiration from the plots of Hollywood disaster movies. However, there’s not a lot you could do about an asteroid striking the earth and killing all known life (there’s a really “high-impact” event for you!).
Having identified your critical services and having agreed on the list of possible contingencies and their likelihood of coming to pass, you can then decide what to do about them. Some services you may decide to forego in an emergency because you may be able to work without them for a period or you could use some sort of limited fallback. Other services may merit greater degrees of protection, especially high-availability services where the high cost would be justified. Less critical services could be covered by some sort of disaster recovery arrangement involving perhaps an ongoing contract with a specialist disaster recovery supplier.
Implementation
Having decided what you are going to do, now you do it. You introduce the risk mitigation steps you’ve agreed on, you award the contracts for disaster recovery, you ensure that appropriate staff maintain up-to-date skills to cover emergency shortages, and you test the arrangements you have made. Once you are satisfied with your arrangements, you can then publish your ITSCM plan.
EXAM TIP ITSCM, in common with Service Level Management (SLM), has a close interest in contracts, but these two processes do not negotiate contracts. All contract negotiation is done in Supplier Management.
Ongoing Operation
It would be foolish not to keep your plan up-to-date. As changes to the live configuration and live services are made, you must update the ITSCM plan, and you must continue to ensure that all stakeholders are aware of its existence and its whereabouts. There should be regular tests of the plan to check that it remains feasible, and this should be part of formal review and audit.
If you do all this, you should be confident that if you need to invoke the ITSCM plan, it will work.
The following are other relevant points regarding ITSCM:
• In many respects in ITSCM you are designing a parallel universe to the live environment. It’s a parallel universe that you hope you’ll never actually have to inhabit. However, it is too late to consider ITSCM when the fire services are damping down the smoldering remains of your data center!
• In that vein, one of the most important activities in ITSCM is to get the customer, the business, to engage in it and to provide the necessary resources.
• It can be helpful to ongoing awareness and education to ensure that appropriate ITSCM entries are included in the service catalog (all views of it) and in the service level agreements (SLAs).
• There is a lot more about ITSCM in the main ITIL volume, Service Design, and there is also an international standard for BCM: ISO 22301.
Information Security Management Process
You are now at the fourth of your processes that comprise warranty: Information Security Management (ISyM). This is very much a prevalent topic in the world of IT management, and ITIL does not attempt to provide an alternative view of it. However, it is a topic that needs to be woven into the IT service management arrangements that you are making.
The purpose of ISyM is to align IT security with business security and to ensure that the IT security aspects always match the agreed-on needs of the business. In this, ISyM mirrors the way ITSCM aligns with BCM.
ISyM requires you to understand the following:
• The business security policy and plans.
• Current and future business operations, plans, requirements, and their associated security aspects.
• Legislative and compliance requirements.
• IT security management risks and their management.
• The need to produce and maintain an information security policy that is aligned to the business security policy. The information security policy should not be a secret document because its provisions need to be understood by all stakeholders. However, the way its provisions are implemented and monitored may well be confidential.
• The security controls necessary to support the policy.
• The need to ensure that third parties abide by the policy.
• The need to manage all security breaches and incidents.
• The need to ensure that ISyM is integral to all ITIL processes.
IsyM can be considered as having three aspects: confidentiality, integrity, and availability. These happily form the memorable initials CIA, even though this has little to do with an organization just off the Washington Beltway in Langley, Virginia.
Confidentiality This is about making sure that only those with a justifiable need to see certain data or to use certain services can do so.
Integrity You should ensure that data and services are complete and uncorrupted so that you can be confident in their accuracy.
Availability You’ve already met this word in a number of different contexts, so a less ambiguous term would be accessibility, but ITIL specifies availability, so there you are. This is the flip side to confidentiality. It is about making sure that those who do have a need to see certain data or use certain services can actually do so. If security is too tight, it can easily become “business prevention”!
Other Points to Remember
The following are other relevant points regarding Information Security Management:
• It can also be considered relevant to Availability Management (in ITIL v2, security formed a second S in those aspects of availability set out earlier, giving you the acronym ARMSS).
• ISyM is planned in Service Design and should be tested thoroughly in Service Transition. The way it is designed should ensure that live IT security management events and activities can be monitored effectively in the Service Operation lifecycle stage.
• Many of the policies of ISyM planned in Service Design are executed in Service Operation by the Access Management process.
• Make sure that contracts require third parties to conform to the ISyM policy.
• There is a lot more about ISyM in the main ITIL volume, Service Design, and there is also an international standard for IT security: the ISO 27000 series.
Supplier Management Process
You’ve now reached the eighth and last process in Service Design: Supplier Management.
Suppliers are, of course, Type III service providers, and you may have a large number of them. In Service Design you’ve already seen how Service Level Management and ITSCM have close links with Supplier Management and that ISyM is relevant too. In fact, whenever you make a decision to outsource a service, including support arrangements, you involve Supplier Management.
The purpose of Supplier Management is to obtain a seamless quality of service from suppliers that provides value for money in meeting the agreed-on needs of the business and ensuring that suppliers meet their contractual obligations.
Supplier Management requires you to do the following:
• Act in accordance with the business’s contracts management policy and produce a supplier policy that can be implemented and enforced.
• Maintain a supplier and contract management information system (SCMIS); you’ll come back to this in the Knowledge Management process in Chapter 5.
• Categorize suppliers and contracts and undertake risk assessments.
• Negotiate and manage contracts through the contract lifecycle including evaluating and selecting suppliers, and awarding and terminating contracts as necessary.
• Maintain relationships with suppliers including reporting and managing performance and resolving contract disputes and inputs to continual service improvement. (All contracts should include an obligation on suppliers to participate in their customer’s continual service improvement program.)
• Ensure that subcontracted suppliers are selected and managed openly by the prime supplier in the best interest of the customer.
ITIL defines four supplier categories as follows:
• Strategic Involves senior managers and the sharing of confidential information for long-term plans (for example, a worldwide data network service)
• Tactical Involves significant commercial activity and business interaction (for example, server maintenance)
• Operational Involves the supply of operational products or services (for example, the hosting of a minor website; these services would be managed by a comparatively junior manager)
• Commodity Involves the provision of low-value and readily available products or services (for example, printer consumables)
Supplier Management at the ITIL Foundation level is in essence a straightforward process. You’ll be looking specifically at outsourcing in the Service Transition lifecycle stage in Chapter 5.
Roles in Service Design
You’ll remember the point I made in both Chapter 1 and Chapter 3 that, while ITIL does not tell us how to organize ourselves specifically, it does give valuable guidance in each lifecycle stage in the form of sets of roles with associated responsibilities. I also pointed out that you can use these sets as checklists to make sure you’re covering everything. These points are as true in Service Design as in any other stage of the Service Lifecycle.
I’ve shown the specific Service Design roles in the organization chart in Figure 4-15. Again, don’t forget that this chart is only for illustrative purposes; it is not a model.

Figure 4-15 Roles in Service Design
The generic responsibilities of Service Owner, Process Owner, and Process Manager are set out in Chapter 1. For the specific responsibilities of each of the roles shown in Figure 4-15, you will need to refer to the ITIL publications themselves.
Tools in Service Design
Again, the comments I made on tools at the end of the Service Strategy lifecycle stage in Chapter 3 are equally relevant here. Technology can be useful in Service Design in the following areas:
• Hardware design
• Software design
• Environmental design
• Process design
• Data design
Tools help speed up the whole design work, ensuring that standards and conventions are followed, enabling modeling and simulation, running “what if” scenarios, checking and correlating interfaces and dependencies, modeling processes, validating designs, and ensuring consistency.
EXAM TIP ITIL views tools as being extremely useful in a wide variety of applications. If you get a complex exam question asking “Which of the following would be assisted by technology?” followed by a list of options, the answer is likely to be “All of them” unless there are any obviously absurd options in the list.
Chapter Review
I hope you found that, after the high-level considerations of Service Strategy, you are now dealing with some more familiar concepts. Nevertheless, I also hope you see how those high-level concepts are developed further in Service Design, including the following: how the service portfolio is expanded in part into the service catalog, how the activities of the Business Relationship Management process (along with the service catalog) form the basis for an effective Service Level Management process, how the processes of Financial Management and Demand Management define the constraints for those Service Design processes that comprise warranty (indeed, how the concept of utility balanced with warranty is crucial to effective, detailed planning in Service Design), and, finally, how the service specification passed from Service Strategy to Service Design forms the basis for the all-important service design package (SDP) passed on by Service Design to Service Transition.
Effective design is achieved by recognizing the importance of not only the five aspects of holistic service design but also the four, equally important areas that need to be considered for successful service design, the four Ps of Service Design. If you can’t remember them, take a look at the “Quick Review” section.
I also hope that you can now appreciate how Service Design looks forward to the rest of the service lifecycle, which is reflected in the contents of the SDP. There is a lot of expertise to be found in the functions involved in Service Design; that expertise will be further exploited in Service Transition and Service Operation, with everything, of course, conforming to the principles of continual service improvement. CSI of Service Design is powerfully informed by feedback from Service Transition and Service Operation.
Let’s also review the processes you’ve encountered and how they link together.
Design Coordination ensures that all the activities of the Service Design lifecycle stage (including the relevant elements of projects and programs) are aligned and that they conform to the set policies and standards. In doing so, this process will help deconflict demands for resources.
Under the umbrella of Design Coordination, the Service Catalog Management process not only provides a valuable picture of customer-facing services and how they’re underpinned by technical and supporting services but also provides the foundation for effective Service Level Management (SLM). In SLM, the formal SLAs and OLAs are negotiated, agreed on, and signed, along with the maintenance of a close liaison with Supplier Management regarding the negotiation of underpinning contacts.
Feeding SLM with expert inputs are the four processes that cover warranty: Capacity Management, Availability Management, IT Service Continuity Management, and IT Security Management. Capacity Management and Availability Management are planning for the expected; IT Service Continuity Management is planning for the unexpected (in terms of the service lifecycle I hope you’ll never actually roll out the continuity services!). IT Security Management is of ever-increasing importance and is a crucial element of all processes throughout the lifecycle.
Supplier Management covers everything to do with actual contracts. Wherever in the service lifecycle you deal with third parties, you must remember that those involved in Supplier Management are crucial stakeholders.
In the next chapter, you’ll be examining Service Transition. Without the good work that should now have been completed in Service Design, it is difficult for Service Transition to be effective and, in turn, for Service Operation to deliver the value envisaged in Service Strategy.
Quick Review
Here are the key concepts and terms you’ve encountered in this chapter. Read through this list; if anything seems unfamiliar or you can’t readily describe it, read the relevant section again.
• The purposes of Service Design
• The five aspects of holistic Service Design:
1. The new or changed services themselves
2. Management systems and tools value (such as Service Portfolio)
3. Technology architectures and management architectures
4. Processes
5. Measurement methods and metrics
• The four Ps of Service Design: people, processes, products, and partners
• The service design package (SDP)—the “blueprint” for the rest of the service lifecycle for the service concerned
• Process: Design Coordination
• Process: Service Catalog Management (an essential preliminary before you can tackle Service Level Management)
• Process: Service Level Management (SLAs, OLAs, and a stakeholder in UCs); SLM takes feeds from nearly all ITIL processes
• Process: Capacity Management (comprising three sub-processes—Business Capacity Management, Service Capacity Management, and Component Capacity Management—and the capacity plan)
• Process: Availability Management (ARMS plus MTBF, MTRS, and MTBSI)
• Process: IT Service Continuity Management (contingency planning)
• Process: IT Security Management (confidentiality, integrity, and availability, plus the IT security policy)
• Process: Supplier Management (underpinning contracts—close relations with Service Level Management and IT Service Continuity Management)
• Tools: the design of hardware, software, environment, processes, and data
Projects and programs should conform to the Service Design policies and the business requirements.
You should never forget the concepts of utility and warranty.
Answer to Exercise 4-1
The following is my suggested content of a typical SLA (Type I, Type II, or Type III). You can use this list as the basis for deciding what would be appropriate for an OLA.
• Parties to the agreement These are essentially the service provider and the customer. Specific posts should be shown (avoid using the actual names of individuals because people come and go!).
• Signatories, signatures, and dates This is the place for named individuals; the more elevated in the hierarchy the better.
• Description This is based on the description in the Service Catalog.
• Validity Start and end dates of the agreement itself; review dates are covered later.
• Scope (inclusions and exclusions) Examples are geographical or organization limitations.
• Responsibilities This is crucial and should include responsibilities of both parties. The service provider would be responsible for delivering the service as defined in the SLA. Customers and users should be equally required to abide by the SLA, particularly with reference to an obligation for the customer to provide adequate resources to that end and to ensure that all users are properly trained and supervised.
• Service hours It is vital that there is no room for ambiguity, especially when the hours are other than 24/7. Do seasonal extended hours need to be agreed on permanently to meet expected patterns of business activity (such as pre-Christmas retail activity)? Are support hours different from service hours? How are requests from either the service provider or the customer to extend hours temporarily to be dealt with?
• Service availability Classically this is expressed as a percentage of service hours, but there are alternative measurements that are explored in the Availability Management process.
• Reliability This is the minimum acceptable length of time (in service hours) the service should run without interruption. Reliability is explored further in the Availability Management process.
• Customer/user support This is based on the Service Catalog entry. Where support hours differ from service hours and when levels of support may vary depending on the calendar, this should be specified here. An important aspect will be the prioritization rules that apply to this service.
• Contact points and escalation The importance of the Service Desk as the single point of contact for the users should be reiterated here, and the opportunity can be taken to give a cross-reference to the SLA for the Service Desk service. This area must align with the Service Catalog entry.
• Service performance Workload limits and maximum transaction response times can be set out here as well as targets such as the minimum acceptable incident resolution performance (such as 95 percent of all incidents must be resolved within the target time agreed on in the prioritization rules for this service).
• Change management The first and most important statement here will be that this SLA is a formal document subject to the provisions of the service provider’s change management policy. Here should be listed the stakeholders who comprise the change authority for this service (you’ll explore this further in Chapter 5). This should also include arrangements for interim, temporary changes (such as changes to service hours to extend them to meet business backlogs or to truncate them for major releases to be completed by the service provider).
• Service continuity In certain contingencies, different arrangements may have to be put in place for this service. The details can be given either here or by a cross-reference to a separate continuity SLA.
• Security Security awareness is a vital aspect. Reference should be made here to the information security policy and to any specific security matters regarding the service in question. This section sets out the rules for granting and removing user access rights to the service and any service components (such as applications).
• Service reporting and review This includes full details of the reports to be produced: who produces them, who receives them, the report content, the format, and the frequency. It also includes when and where review meetings will take place and who should attend.
• Batch turnaround times This section is applicable when the service produces bulk outputs such as electricity bills for external customers.
• Charging As discussed in Financial Management, ITIL sees charging as optional, but if this is a Type III SLA, charges will invariably be made by the service provider. Where charges are made, this is where the agreed-on tariffs and the charging procedures should be detailed. Penalty charges can also be covered here (although care should be taken about them because issuing penalties can be unhelpful to promoting constructive provider–customer relations).
• Glossary This section gives you a useful opportunity to define the agreed-on meaning of specific terms and concepts. Cross-reference can also be made to a formal glossary document published elsewhere.
• Amendment record SLAs are “living documents” that should be under continual review. Any changes to the SLA should be controlled by a formal change request (often called a request for change [RFC]). You should record here the RFC number and relevant details for every such change.
Questions
Here’s another set of questions, 20 this time, for you to tackle. Now that I’ve covered two stages of the service lifecycle, I trust that you can see that the questions are becoming broader. That broadening will continue as you journey on. As they say, enjoy!
1. Which one of the following is an objective of Design Coordination?
A. To provide a single source of consistent information on all operational services
B. To record service level requirements
C. To review, measure, and improve the performance of all Service Design activities and processes
D. To align service level agreements and underpinning contracts
2. Which of the following statements about the Supplier Management process is correct?
A. Supplier Management negotiates service level agreements (SLAs).
B. Supplier Management maintains information in a supplier and contract management information system.
C. Supplier Management decides whether a service should be outsourced.
D. Supplier Management negotiates operational level agreements (OLAs).
3. Which one of the following is not a purpose of Availability Management?
A. To ensure that service availability matches the targets in the service level agreement (SLA)
B. To assess the impact of changes on the availability plan
C. To consider how quickly a service can be returned to its agreed-on functionality
D. To ensure business continuity plans are negotiated
4. Which of the following is the best description of a service level agreement?
A. A written agreement between the service provider and the customer defining key targets and the responsibilities of both parties
B. An agreement between a supplier and the customer about response and fix times
C. An agreement between two service providers regarding service targets
D. An agreement between two functions in a service provider regarding service targets
5. Which one of the following is not a subprocess in Capacity Management?
A. Component Capacity Management
B. Service Capacity Management
C. Business Capacity Management
D. Continuity Capacity Management
6. Which process is responsible for reviewing operational level agreements?
A. Service Level Management
B. Supplier Management
C. Availability Management
D. IT Service Continuity Management
7. Which of the following should be elements of a service design package (SDP)?
i. Service level requirements (SLRs)
ii. A plan for the transition of the service
iii. Criteria for deeming tests to be successful
iv. An assessment of the readiness of the organization to use the service
A. i and iii only
B. i and ii only
C. ii and iii only
D. All of the above
8. Who should be able to read the information security policy?
A. Information security management staff only
B. All customers, users, and IT staff
C. Senior managers only
D. IT executives and the Information Security Management process owner only
9. Which one of the following is the best definition of reliability?
A. The level of risk that would impact a service
B. The availability of a service component
C. How long a service component can perform its function without failing
D. The level of service provided by a third party
10. Which one of the following is the best description of the four Ps of Service Design?
A. The areas to be considered to achieve holistic service design
B. The aspects covered by Supplier Management as “partners”
C. The four steps in Service Level Management
D. The four major areas to be considered during service design
11. Which one of the following processes would be most likely to provide expertise in resolving issues regarding the performance of services and components?
A. Capacity Management
B. Supplier Management
C. Service Catalog Management
D. Availability Management
12. Which of the following aspects of Service Design should also be considered when designing a new or changed service?
i. Measurement methods and metrics
ii. Technology and management architectures
iii. Processes
iv. Management systems and tools
A. iii only
B. i, ii, and iii only
C. ii, iii, and iv only
D. All of the above
13. Which two processes would be principally involved in negotiating and agreeing on disaster recovery contracts?
A. Service Level Management and Availability Management
B. Service Level Management and Supplier Management
C. Supplier Management and IT Service Continuity Management
D. Service Level Management and IT Service Continuity Management
14. Which of the following are valid types of SLA structures?
i. Service-based SLA structure
ii. Priority-based SLA structure
iii. Customer-based SLA structure
iv. Multilayer SLA structure
A. iv only
B. i, ii, and iii only
C. i, iii, and iv only
D. All of the above
15. Which of the following activities is part of the Service Level Management process?
i. Designing the business element of the configuration management system
ii. Monitoring service performance against SLA targets
iii. Negotiating contracts with third-party service providers
iv. Conducting review meetings at agreed-on intervals
A. iii only
B. i, ii, and iii only
C. ii, iii, and iv only
D. ii and iv only
16. Which one of the following processes is concerned with managing risks to services?
A. Service Portfolio Management
B. Availability Management
C. Service Catalog Management
D. Design Coordination
17. Which one of the following is the correct list of the four Ps of Service Design?
A. Planning, perspective, position, and preparation
B. People, partners, products, and problems
C. People, processes, products, and partners
D. People, problems, processes, and partners
18. Which one of the following is not a recognized layer in a multilayer SLA?
A. Corporate layer
B. Service layer
C. Customer layer
D. Configuration layer
19. Which one of the following is not a responsibility of Service Catalog Management?
A. Ensuring that the SLAs are kept up to date
B. Ensuring that all live services are recorded in the Service Catalog
C. Ensuring that it includes all services that are being transitioned or have been transitioned into the live environment
D. Ensuring that the contents of the Service Catalog are accurate and up to date
20. Which of the following areas would be assisted by the use of appropriate technology?
i. Hardware design
ii. Software design
iii. Environmental design
iv. Process design
A. All of the above
B. i, ii, and iii only
C. ii, iii, and iv only
D. ii and iv only
Answers
1. C. The other three answers are all good things to do in Service Design, but they aren’t objectives of Design Coordination.
2. B. SLAs and OLAs are negotiated in Service Level Management, while decisions whether to outsource would be high-level decisions. Supplier Management would participate in the implementation of the decision.
3. D. Business continuity plans are important, but negotiating them is not a purpose of Availability Management.
4. A. Option B bypasses the service provider, option C is either nonsensical or possibly illegal, and option D is a description of an operational level agreement (OLA).
5. D. There is no such thing as Continuity Capacity Management in ITIL.
6. A. This should not have been a difficult question.
7. D. The SDP contains a lot of good things. I gave a longer list earlier in this chapter.
8. B. The information security policy usually should not be a confidential document. Of course, the methods and techniques used in applying it are a different matter.
9. C. Did you remember the acronym ARMS? Option A is not relevant, option B is the A part of ARMS, and option D alludes to serviceability (if it alludes to availability at all).
10. D. You need to know not only what the four Ps are but also their purpose.
11. A. When you see the word performance, it is a good indication that Capacity Management is relevant.
12. D. I hope you recognized that this question is about the five aspects of holistic service design.
13. C. The negotiation of contracts is the responsibility of Supplier Management, and in this case, IT Service Continuity Management is the other process because disaster recovery is involved.
14. C. There is no priority-based SLA structure in ITIL.
15. D. Option “i” is pretty meaningless; option “iii” is part of Supplier Management.
16. B. This should not have been a difficult question.
17. C. If you got this one wrong, refer to the opening part of this chapter.
18. D. I hope you picked out the “joker” without too much angst.
19. A. Ensuring that SLAs are kept up to date is a responsibility of Service Level Management.
20. A. A theme you’ll come to recognize in ITIL is that tools are viewed as extremely useful; the answer “All of the above” is likely to be the correct answer unless something absurd has been included in the question.