
The previous chapter demonstrated complete control over an index’s definition and life cycle. Map and MultiMap indexes were introduced, along with various ways to compute fields that can be used to filter and sort documents. This chapter will show how to perform grouping and aggregation in RavenDB. Concepts of MapReduce and MultiMapReduce indexes will be introduced, along with a way to materialize the content of the index into a new collection.
Grouping
Grouping orders by the country of shipment
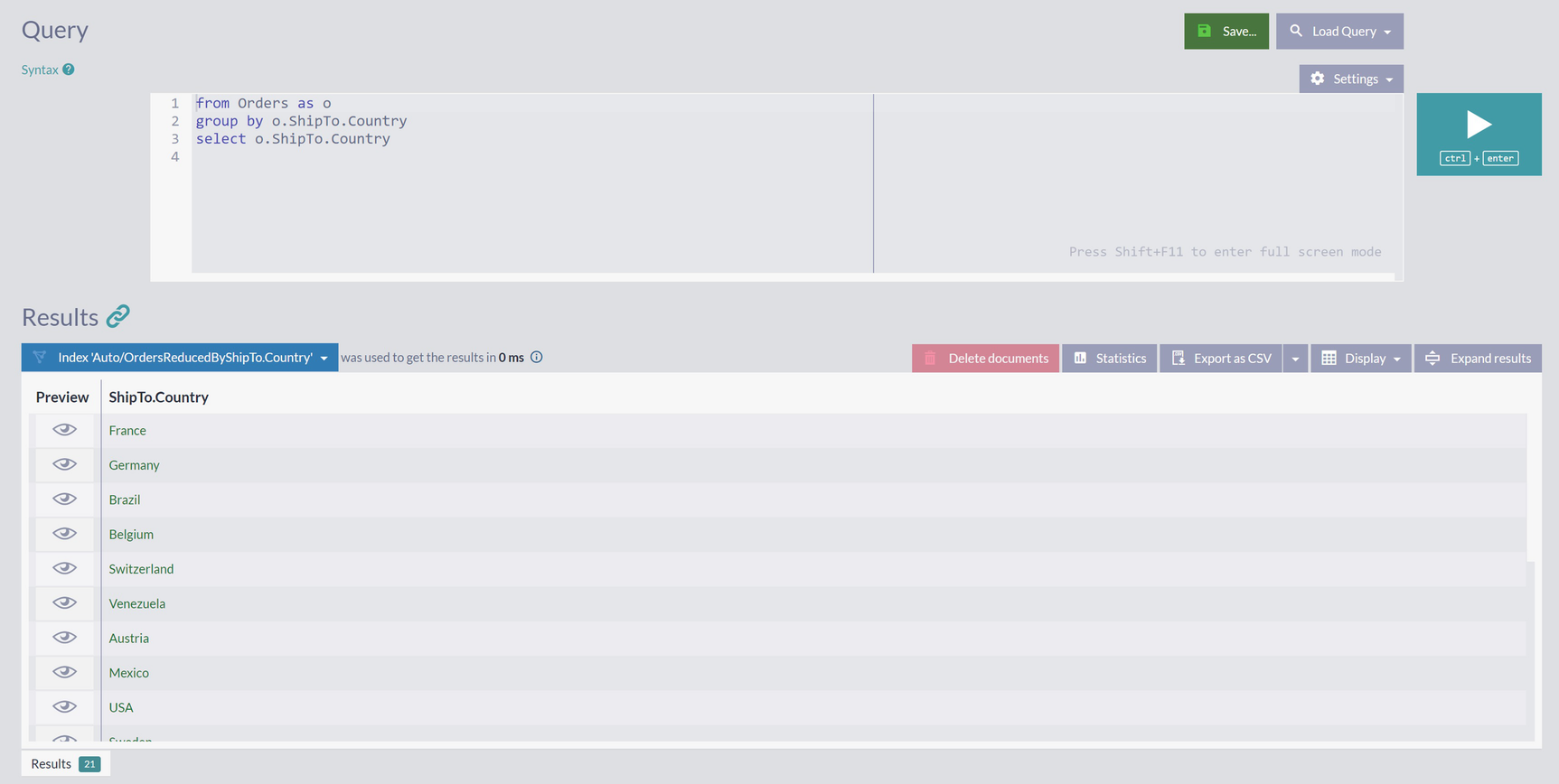
A snapshot of the query result of a list of 21 countries. France, Germany, Belgium, Brazil are some of the countries in the list.
Shipping Countries for Orders

A snapshot of all indexes database for the country available in the database.
Structure of Auto Index Auto/OrdersReducedByShipTo.Country
Documents from Orders collection were processed, their ShipTo.Country values were extracted, and IDs of orders with the same values were stored in index entries. RavenDB uses a specific programming model we will examine in the next section for processing grouping tasks .
MapReduce
Figure 6-2 displays a visualization of the data grouping pipeline in an index. At the top of this diagram, you will see the Map-Reduce heading, denoting this index type. Alternatively spelled as MapReduce, this technique popularized by Google is used for the parallel processing of data across many machines. In a typical setup, data is first split into batches. Every batch is sent to a different device, which will use the map function to transform all entries in the received collection. Mapped entries are then combined via reduce function to produce the final result set.
The previous chapter saw examples of automatic and static indexes implementing map functions to transform documents into indexing entries. MapReduce index will take such mapped entries and apply reduce function to them, emitting grouped entries. RavenDB is using a variant of this programming model.
Unlike original MapReduce used at companies like Google, where data batches are distributed across hundreds and thousands of machines, RavenDB performs this process on a single machine. Multiple threads will receive packs, apply map function to emit projections first, and then apply reduce function to these projections.
A snapshot of the selecting index, entering documents, area of interest, and map-reduce details options for the map-reduce menu.
Map-Reduce Visualizer Initial Screen

A snapshot of the orders being ready to ship to France.
Map-Reduce Visualization of Auto/OrdersReducedByShipTo.Country Index for orders/1-a and orders/103-a
Map phase of the index extracted ShipTo.Country, while Reduce phase collected all orders with same shipping country. In Figure 6-4, you can see that the reduction phase gathered these two orders together since their shipping countries match. If you check the documents for these two orders, you will know that they went to France.

A snapshot of the tree roots expansion for the two orders.
Reduction Outcome Details

A snapshot of the scrollable listing of all the orders.
Reducing Orders Shipped to France
The ability for a database to perform groupings like this one is nice, but it is not too valuable. The full power of grouping comes with aggregation, which we will cover in the next section.
Aggregation
Grouping and counting orders by the country of shipment

A snapshot of the shipping countries and their order counts.
Shipping Countries for Orders Expanded with Count
and obtain a piece of useful information regarding the “Northwind Traders” business – most of their orders, 122, were delivered to customers in the United States and Germany.

A snapshot of the collection, group by, and result of the orders reduced.
Structure of Auto/Orders/ByCountReducedByShipTo.Country
If you compare this with Figure 6-2, you can see that the original automatic index was augmented with count operation in the aggregation phase.
Static MapReduce Indexes
The previous chapter introduced the concept of static Map indexes . They are a natural extension of Map indexes, providing a way to map documents and then specify how to aggregate those maps. It is also possible to write static MapReduce indexes. This section will recreate a static version of automatic index Auto/Orders/ByCountReducedByShipTo.Country.
Orders/ByCountry map index
This index is not much different from the Employees/ByFirstName index in the previous chapter – for every order document, RavenDB will create one indexing entry with Country value.
Expanding Orders/ByCountry map index with count
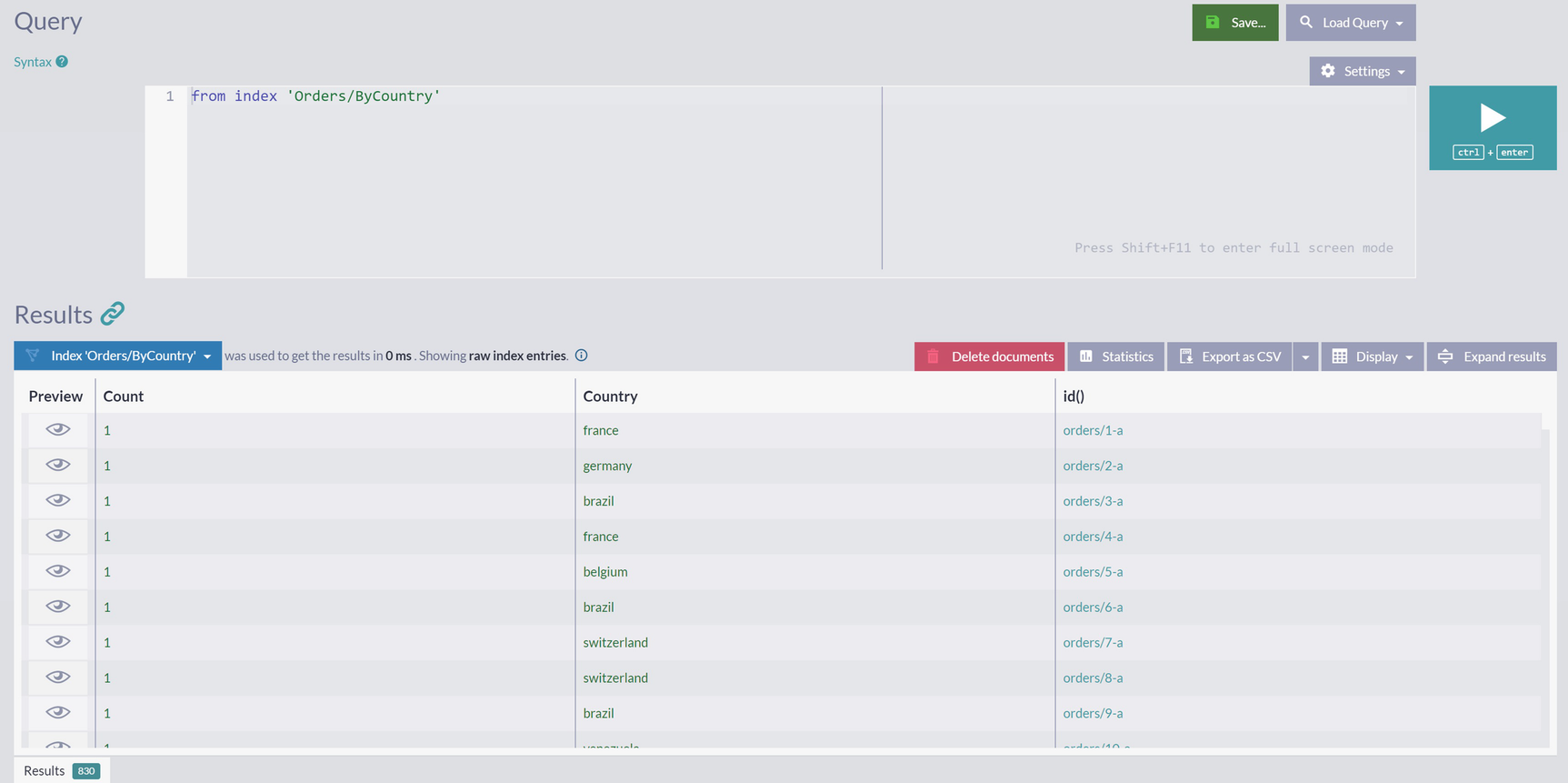
A snapshot of the index orders by countries.
Raw Indexing Entries for Expanded Map Index Orders/ByCountry
This index is now performing the same task that you would do manually – going one by one order and writing down every occurrence of each country from ShipTo.Country field. After writing down marks of this kind for all orders, you would go back and sum it up. And that is precisely what the reduction phase of the MapReduce index does.
Reduction code for index Orders/ByCountry
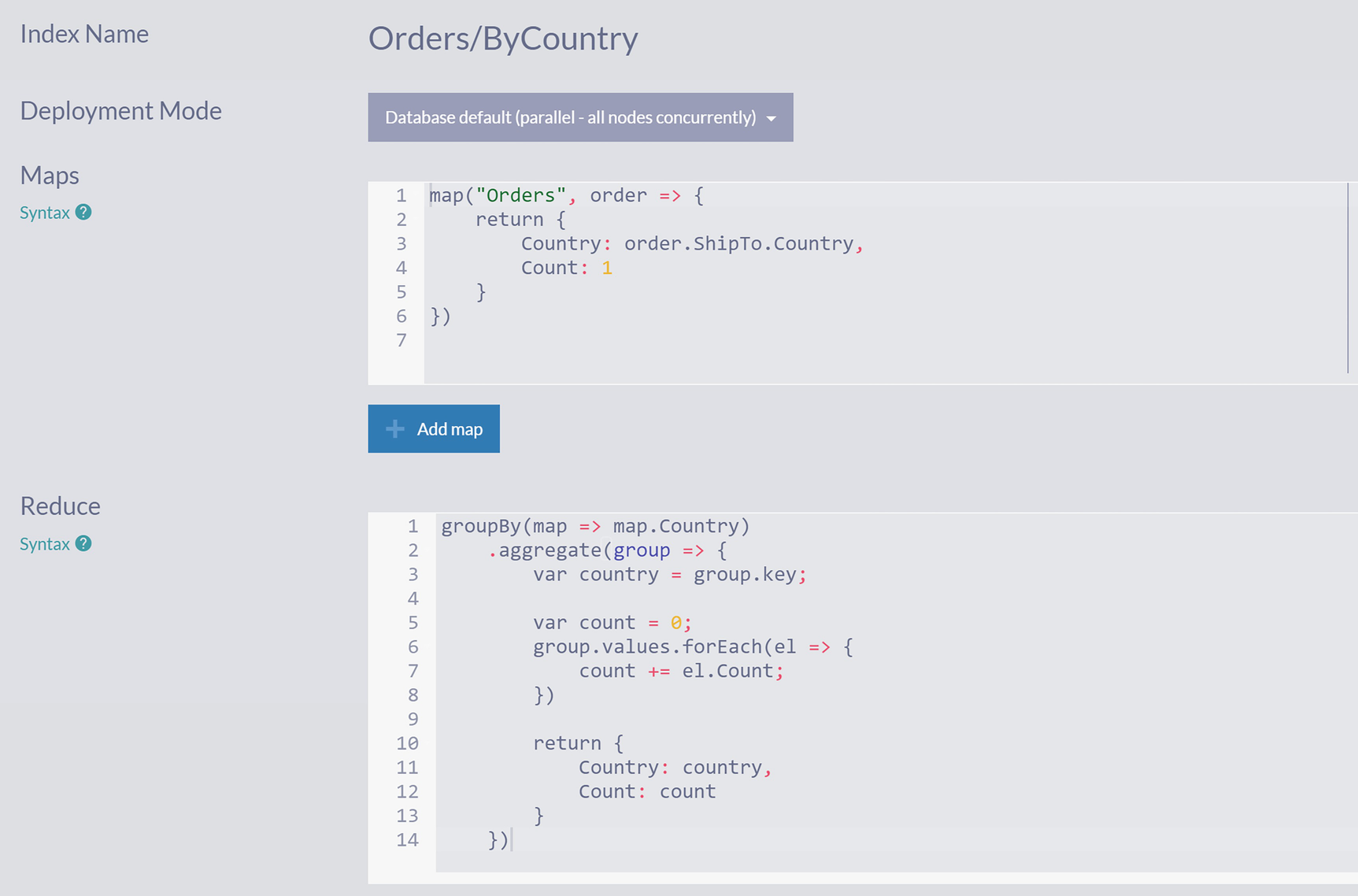
A snapshot of the code for the orders by country.
MapReduce Index Orders/ByCountry
Reduce script from Listing 6-5 can be refactored. Refactoring is the process of changing implementation without changing behavior. Let’s reorganize the code to make it more concise.
This process will continue until all array elements are processed. Hence, we iterated over all array elements in a recursive declarative way.
Static Versus Automatic Indexes
You just spent some effort implementing a static alternative to the index that was created automatically by RavenDB, and you may ask yourself, “why?” Indeed, if RavenDB can do the work on its own, what is the point?
There are several reasons why you would want to take control over index creation and its definition. Two of the most important reasons are discussed in the following sections.
Moment of Initial Indexing
Upon creating an index (both automatic and static), initial indexing will be performed. All documents will be fetched from the disk and processed by the index. If the indexed collection is empty, the newly created index will be ready immediately. However, if the collection is not empty, processing all documents will take a certain amount of time.
might omit some countries because not all orders have been processed yet. In this situation, RavenDB may wait up to 15 seconds for the index to become nonstale. After 15 seconds, if the index is still stale, you will get partial results set, and indexing will continue in the background. The reasoning behind this decision is simple – instead of reporting an error, RavenDB will return a potentially incomplete result set with notification that some of the results might be missing.
In the production environment, you usually want to deploy or create indexes on live databases, wait for indexing processes to complete, and then deploy code using these new indexes.
With static indexes, you take more control over this process. Unlike automatic ones created on the first query, static indexes are explicitly defined. Hence, the indexing process will start after saving the static index definition. Overall, static indexes are more explicit and predictable, and you will create them intentionally before querying the database .
Aggregation Complexity
Query from Listing 6-2 that created automatic index Auto/Orders/ByCountReducedByShipTo.Country is doing aggregation by summing occurrences of orders with the same shipping country. Unfortunately, this simple aggregation is the limit of automatic MapReduce indexes. You will have to write a static MapReduce index for anything more advanced.
Orders/ByCountryTotals index
The mapping phase of this index is processing order lines, taking into account line discount to compute the total value of each order. After that, these totals are summed up for a group of orders with the same shipping country .
In this example, we applied complex aggregation and used its result as a part of our data model without altering documents in the database.
MultiMapReduce Indexes
Looking at companies we sell to and suppliers we buy from, you can perform the following two aggregations. In Listing 6-2, we analyzed orders by the country of shipping. Let’s continue examining our dataset to explore the most active countries.
These two queries will return companies aggregated by countries and suppliers aggregated by countries. Additionally, these two queries will produce two automatic indexes. Manual aggregation of these two result sets will answer which countries Northwind Traders do the most business.
In the previous chapter, we covered the topic of MultiMap indexes , which are operating on more than one collection simultaneously. To write one static index that would replace two automatic ones, we can take MultiMap as a basis and then apply the reduction phase against generated projections. Such an index is called the MultiMapReduce index .
MultiMap index Countries/Business
If you compare this listing with Listing 6-4, you can see that we are counting again, but this time slightly modified. We need to count one for every company occurrence, but at the same time, we need to count events of suppliers as well.
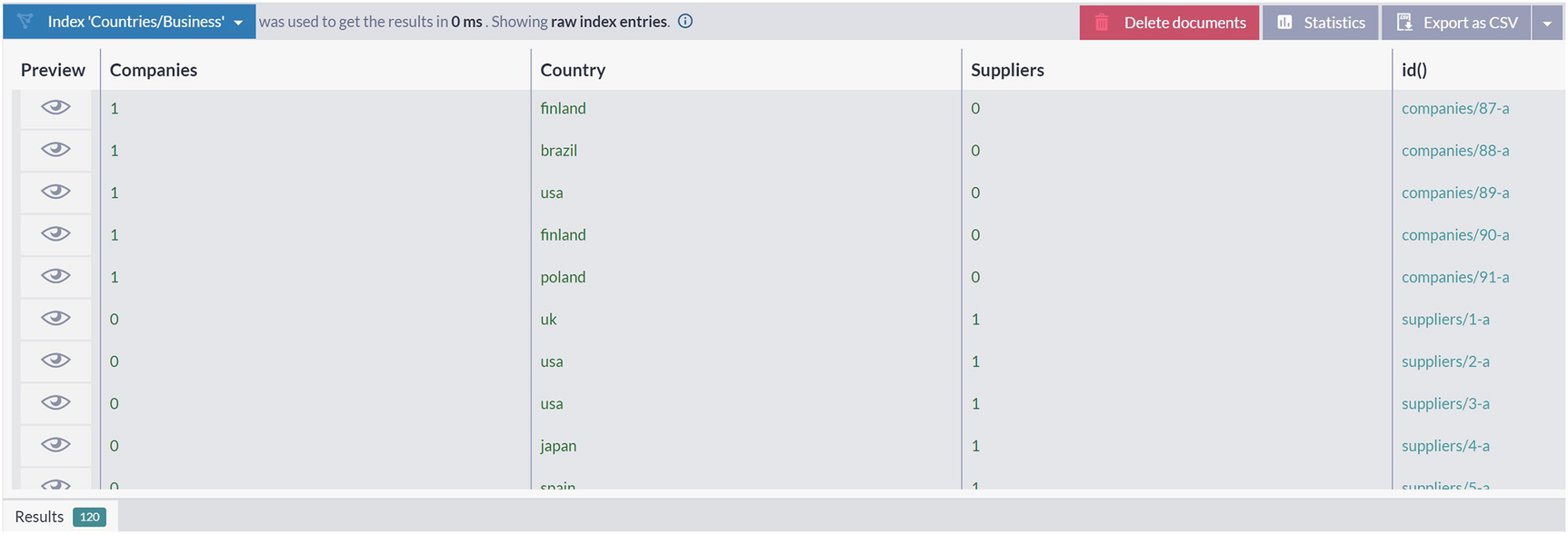
A snapshot of the company, suppliers, and country lists.
Raw Indexing Entries of MultiMap Index Countries/Business
As you can see, for every company and supplier document being processed, the index will extract its country, along with a count of one in an appropriate property.
MultiMapReduce index Countries/Business
to get a listing of countries with the number of companies and suppliers .
Artificial Documents
In addition to computing aggregations and storing them in an index, you can also materialize such indexing entries into documents called artificial documents. They will reside in a collection with an arbitrary name; every time the index is updated, this collection is also updated. This section will show scenarios when you want to create an artificial document, a walkthrough of their configuration, and to know how to perform indexing on them.
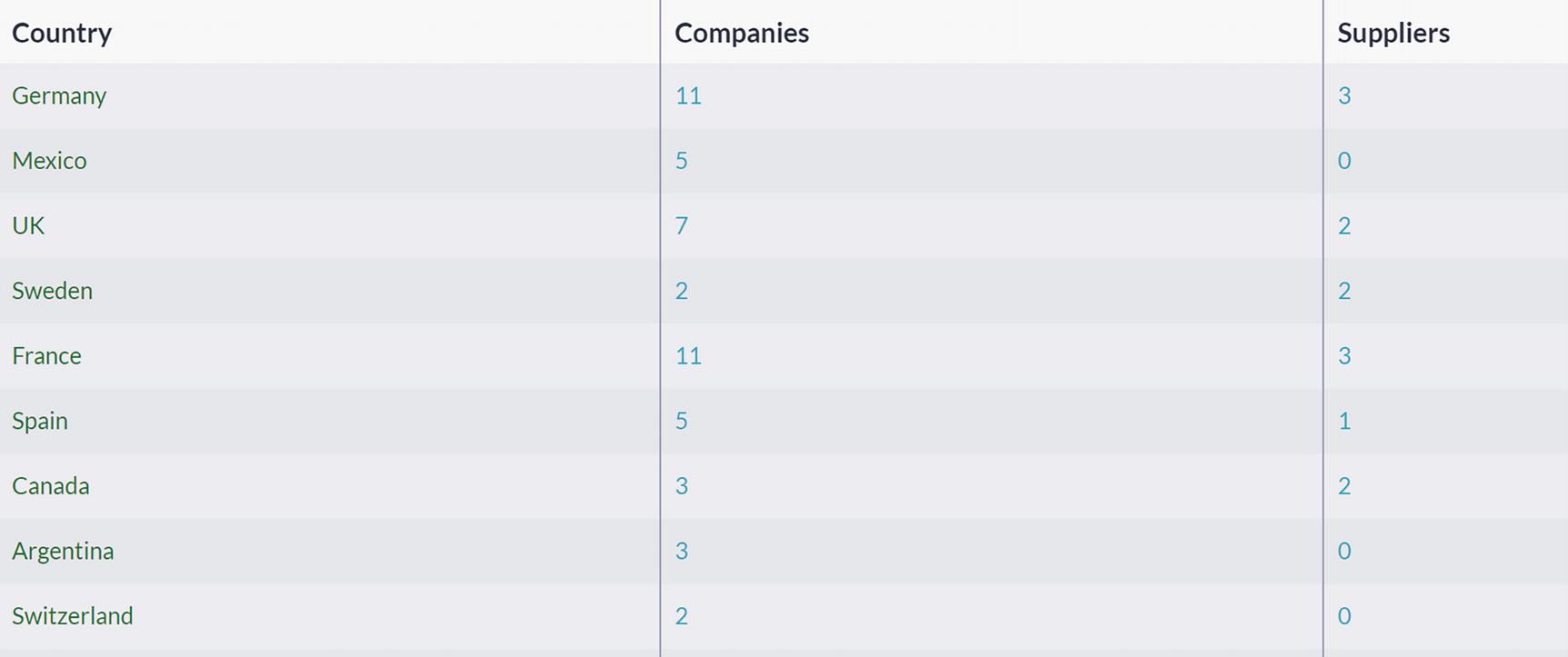
A snapshot of the country, company, and suppliers list.
Raw Indexing Entries of Countries/Business Index
However, what if we want to see totals? If you are making a business trip, which city would be your first choice? At which location would you have a chance to visit the most significant number of business entities your company is doing business with?
Countries/Business Index Expanded with Total
to get desired information.
Querying index with a computed field
Executing this query will result in an error.
In Chapter 4 , we talked about RavenDB’s approach to indexing – all of your queries are always executed against indexes, and precomputed index entries are used to provide blazingly fast responses from the database. Under no circumstances can queries contain any computation. All such calculations must be done within the index itself, ahead of query time. Precisely for this reason, a query from Listing 6-10 will result in an error – we attempted to sum up Companies and Suppliers and then order countries based on that criterion. Revisiting the expanded index from Listing 6-9, you can see that we are performing totals summing in the indexing phase indeed.
Inspecting raw indexing entries of the index before expansion, shown in Figure 6-12, reveals a data structure that would be appropriate for writing a simple map index. Unfortunately, RavenDB indexes can operate only on documents, not on raw indexing entries within other indexes.
However, RavenDB provides a way to materialize raw indexing entries into actual documents, so you can query or even index them. In the next section, we will show how to achieve this.
Creating Artificial Documents
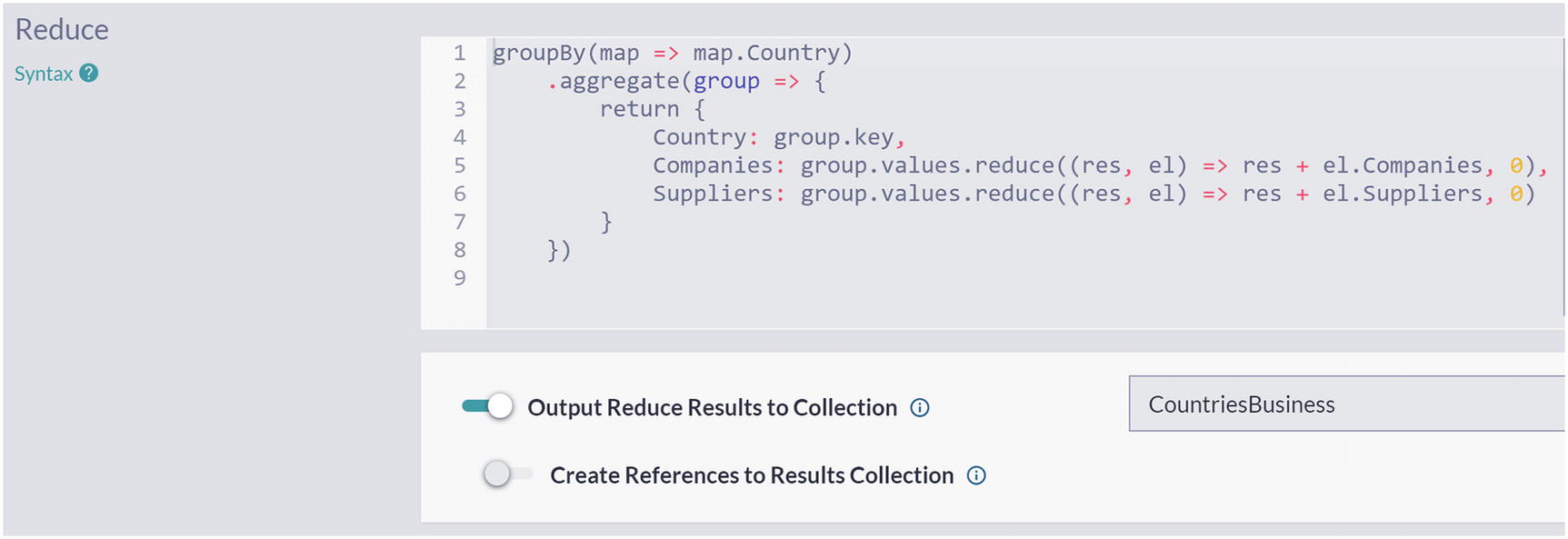
A snapshot of the company and supplier group value code.
Outputting Index Reduce Results to CountriesBusiness Artificial Collection

A snapshot of the document id, company, supplier, and country list.
Documents in the Artificial Collection CountriesBusiness
Structure of one artificial document
Artificial documents can be created from MapReduce or MultiMapReduce indexes, containing indexing entries. If you compare raw indexing entries from Figure 6-12 with the content of the generated artificial collection, you will see that artificial collection represents a dump of an index. Artificial documents will contain all index fields as properties, and its metadata property will have a flag marking it as Artificial, FromIndex.
Every time a new order is created or an existing one is updated/deleted, all indexes indexing orders will be updated. The same thing will happen with the Countries/Business index, and its aggregated entries will be incrementally updated to take into account the latest changes. Additionally, since Countries/Business has output collection defined, this artificial collection will be updated.
to get a list of countries with at least one Company and Supplier .
Indexing Artificial Documents
After executing two queries from the previous section, you will discover that RavenDB created automatic index Auto/CountriesBusiness/ByCompaniesAndCountryAndSuppliers, which is expected behavior from your database.
CountriesBusiness/Totals index
It is easy to see that your next business trip should be to the United States, Germany, and France.
Summary
This chapter introduced MapReduce and MultiMapReduce indexes to group and aggregate data. We introduced techniques for writing static versions of these indexes, along with a way to materialize their content into artificial documents. The next chapter will show how you can use RavenDB for full-text searching of your data.