
2.4 Substitution Ciphers
One of the more popular cryptosystems is the substitution cipher. It is commonly used in the puzzle section of the weekend newspapers, for example. The principle is simple: Each letter in the alphabet is replaced by another (or possibly the same) letter. More precisely, a permutation of the alphabet is chosen and applied to the plaintext. In the puzzle pages, the spaces between the words are usually preserved, which is a big advantage to the solver, since knowledge of word structure becomes very useful. However, to increase security it is better to omit the spaces.
The shift and affine ciphers are examples of substitution ciphers. The Vigenère cipher (see Section 2.3) is not, since it permutes blocks of letters rather than one letter at a time.
Everyone “knows” that substitution ciphers can be broken by frequency counts. However, the process is more complicated than one might expect.
Consider the following example. Thomas Jefferson has a potentially treasonous message that he wants to send to Ben Franklin. Clearly he does not want the British to read the text if they intercept it, so he encrypts it using a substitution cipher. Fortunately, Ben Franklin knows the permutation being used, so he can simply reverse the permutation to obtain the original message (of course, Franklin was quite clever, so perhaps he could have decrypted it without previously knowing the key).
Now suppose we are working for the Government Code and Cypher School in England back in 1776 and are given the following intercepted message to decrypt.
LWNSOZBNWVWBAYBNVBSQWVWOHWDIZWRBBNPBPOOUWRPAWXAW
PBWZWMYPOBNPBBNWJPAWWRZSLWZQJBNWIAXAWPBSALIBNXWA
BPIRYRPOIWRPQOWAIENBVBNPBPUSREBNWVWPAWOIHWOIQWAB
JPRZBNWFYAVYIBSHNPFFIRWVVBNPBBSVWXYAWBNWVWAIENBV
ESDWARUWRBVPAWIRVBIBYBWZPUSREUWRZWAIDIREBNWIATYV
BFSLWAVHASUBNWXSRVWRBSHBNWESDWARWZBNPBLNWRWDWAPR
JHSAUSHESDWARUWRBQWXSUWVZWVBAYXBIDWSHBNWVWWRZVIB
IVBNWAIENBSHBNWFWSFOWBSPOBWASABSPQSOIVNIBPRZBSIR
VBIBYBWRWLESDWARUWRBOPJIREIBVHSYRZPBISRSRVYXNFAI
RXIFOWVPRZSAEPRIKIREIBVFSLWAVIRVYXNHSAUPVBSVWWUU
SVBOICWOJBSWHHWXBBNWIAVPHWBJPRZNPFFIRWVV
A frequency count yields the following (there are 520 letters in the text):
| W | B | R | S | I | V | A | P | N | O | |
| 76 | 64 | 39 | 36 | 36 | 35 | 34 | 32 | 30 | 16 |
The approximate frequencies of letters in English were given in Section 2.3. We repeat some of the data here in Table 2.2. This allows us to guess with reasonable confidence that represents (though is another possibility). But what about the other letters? We can guess that , , with maybe an exception or two, are probably the same as in some order. But a simple frequency count is not enough to decide which is which. What we need to do now is look at digrams, or pairs of letters. We organize our results in Table 2.3 (we only use the most frequent letters here, though it would be better to include all).
Table 2.2 Frequencies of Most Common Letters in English
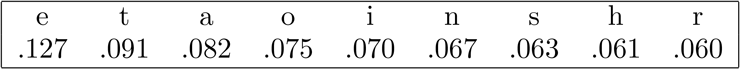
Table 2.3 Counting Digrams
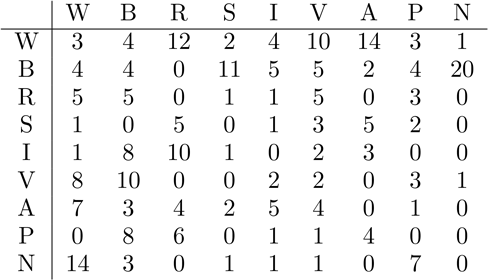
The entry 1 in the row and column means that the combination appears 1 time in the text. The entry 14 in the row and column means that appears 14 times.
We have already decided that , but if we had extended the table to include low-frequency letters, we would see that contacts many of these letters, too, which is another characteristic of . This helps to confirm our guess.
The vowels tend to avoid each other. If we look at the row, we see that does not precede very often. But a look at the column shows that follows fairly often. So we suspect that is not one of and are out because they would require , , or to precede quite often, which is unlikely. Continuing, we see that the most likely possibilities for are in some order.
The letter has the property that around 80% of the letters that precede it are vowels. Since we already have identified as vowels, we see that and are the most likely candidates. We’ll have to wait to see which is correct.
The letter often appears before and rarely after it. This tells us that .
The most common digram is . Therefore, .
Among the frequent letters, and remain, and they should equal and one of . Since pairs more with vowels and pairs more with consonants, we see that must be and is represented by either or .
The combination should appear more than , and is more frequent than , so our guess is that and .
We can continue the analysis and determine that (note that is much more common than ), , and are the most likely choices. We have therefore determined reasonable guesses for 382 of the 520 characters in the text:
| L | W | N | S | O | Z | B | N | W | V | W | B | A | Y | B | N | V | B | S |
| e | h | o | t | h | e | s | e | t | r | t | h | s | t | o | ||||
| Q | W | V | W | O | H | W | D | I | Z | W | R | B | B | N | P | B | P | |
| e | s | e | e | i | e | n | t | t | h | a | t | a |
At this point, knowledge of the language, middle-level frequencies (), and educated guesses can be used to fill in the remaining letters. For example, in the first line a good guess is that since then the word appears. Of course, there is a lot of guesswork, and various hypotheses need to be tested until one works.
Since the preceding should give the spirit of the method, we skip the remaining details. The decrypted message, with spaces (but not punctuation) added, is as follows (the text is from the middle of the Declaration of Independence):
we hold these truths to be self evident that all men are created equal that they are endowed by their creator with certain unalienable rights that among these are life liberty and the pursuit of happiness that to secure these rights governments are instituted among men deriving their just powers from the consent of the governed that whenever any form of government becomes destructive of these ends it is the right of the people to alter or to abolish it and to institute new government laying its foundation on such principles and organizing its powers in such form as to seem most likely to effect their safety and happiness