
1 Introducing the Istio service mesh
- Addressing the challenges of service-oriented architectures with service meshes
- Introducing Istio and how it helps solve microservice issues
- Comparing service meshes to earlier technologies
Software is the lifeblood of today’s companies. As we move to a more digital world, consumers will expect convenience, service, and quality when interacting with businesses, and software will be used to deliver these experiences. Customers don’t conform nicely to structure, processes, or predefined boxes. Customers’ demands and needs are fluid, dynamic, and unpredictable, and our companies and software systems will need to have these same characteristics. For some companies (such as startups), building software systems that are agile and able to respond to unpredictability will be the difference between surviving or failing. For others (such as existing companies), the inability to use software as a differentiator will mean slower growth, decay, and eventual collapse.
As we explore how to go faster and take advantage of newer technology like cloud platforms and containers, we’ll encounter an amplification of some past problems. For example, the network is not reliable and when we start to build larger, more distributed systems, the network must become a central design consideration in our applications. Should applications implement network resilience like retries, timeouts, and circuit breakers? What about consistent network observability? Application-layer security?
Resilience, security, and metrics collection are cross-cutting concerns and not application-specific. Moreover, they are not processes that differentiate your business. Developers are critical resources in large IT systems, and their time is best spent writing capabilities that deliver business value in a differentiating way. Application networking, security, and metrics collection are necessary practices, but they aren’t differentiating. What we’d like is a way to implement these capabilities in a language- and framework-agnostic way and apply them as policy.
Service mesh is a relatively recent term used to describe a decentralized application-networking infrastructure that allows applications to be secure, resilient, observable, and controllable. It describes an architecture made up of a data plane that uses application-layer proxies to manage networking traffic on behalf of an application and a control plane to manage proxies. This architecture lets us build important application-networking capabilities outside of the application without relying on a particular programming language or framework.
Istio is an open source implementation of a service mesh. It was created initially by folks at Lyft, Google, and IBM, but now it has a vibrant, open, diverse community that includes individuals from Lyft, Red Hat, VMWare, Solo.io, Aspen Mesh, Salesforce, and many others. Istio allows us to build reliable, secure, cloud-native systems and solve difficult problems like security, policy management, and observability in most cases with no application code changes. Istio’s data plane is made up of service proxies, based on the Envoy proxy, that live alongside the applications. Those act as intermediaries between the applications and affect networking behavior according to the configuration sent by the control plane.
Istio is intended for microservices or service-oriented architecture (SOA)-style architectures, but it is not limited to those. The reality is, most organizations have a lot of investment in existing applications and platforms. They’ll most likely build services architectures around their existing applications, and this is where Istio really shines. With Istio, we can implement these application-networking concerns without forcing changes in existing systems. Since the service proxies live outside of the application, any application for any architecture is a welcome first-class citizen in the service mesh. We’ll explore more of this in a hybrid brownfield application landscape.
This book introduces you to Istio, helps you understand how all this is possible, and teaches you how to use Istio to build more resilient applications that you can monitor and operate in a cloud environment. Along the way, we explore Istio’s design principles, explain why it’s different from past attempts to solve these problems, and discuss when Istio is not the solution for your problem.
But we certainly don’t want to start using new technology just because it’s “new,” “hip,” or “cool.” As technologists, we find ourselves easily getting excited about technology; however, we’d be doing ourselves and our organizations a disservice by not fully understanding when and when not to use a technology. Let’s spend a few moments understanding why you would use Istio, what problems it solves, what problems to avoid, and why this technology is exciting going forward.
1.1 Challenges of going faster
The technology teams at ACME Inc. have bought into microservices, automated testing, containers, and continuous integration and delivery (CI/CD). They decided to split out module A and B from ACMEmono, their core revenue-generation system, into their own standalone services. They also needed some new capabilities that they decided to build as service C, resulting in the services shown in figure 1.1.
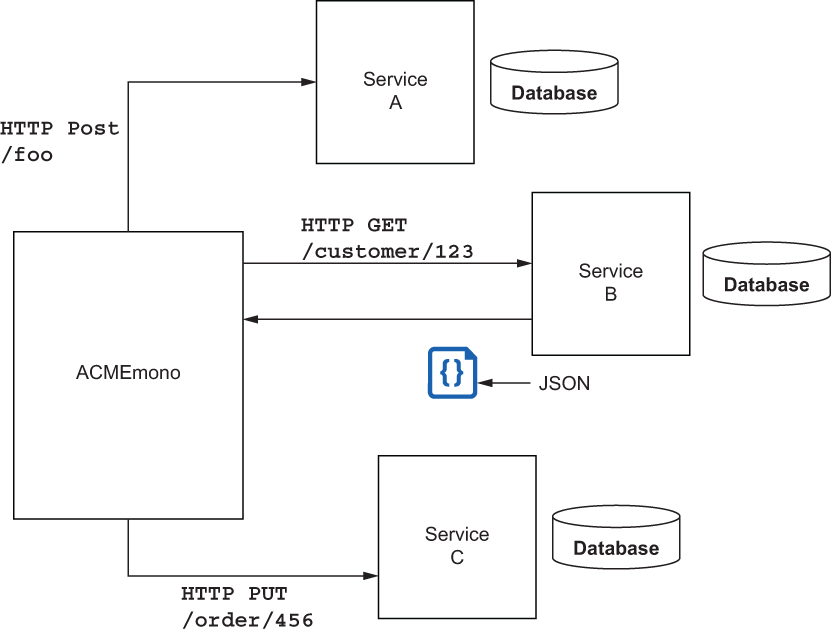
Figure 1.1 ACMEMono modernization with complementary services
They packaged their new services in containers and used a Kubernetes-based platform into which to deploy. As they began to implement these approaches, they quickly experienced some challenges.
The first thing ACME noticed was that sometimes services in the architecture were very inconsistent in how long they took to process requests. During peak customer usage, some services experienced intermittent issues and were unable to serve any traffic. Furthermore, ACME identified that if service B experienced trouble processing requests, service A also did, but only for certain requests.
The second thing ACME noticed was that when they practiced automated deployments, at times they introduced bugs into the system that weren’t caught by automated testing. They practiced a deployment approach called blue-green deployment, which means they brought up the new deployment (the green deployment) in its own cluster and then at some point cut over the traffic from the old cluster (the blue deployment) to the new cluster. They had hoped the blue-green approach would lower the risk of doing deployments, but instead they experienced more of a “big bang” release, which is what they wanted to avoid.
Finally, ACME found that the teams implementing services A and B were handling security completely differently. Team A favored secure connections with certificates and private keys, while team B created their own custom framework built on passing tokens and verifying signatures. The team operating service C decided they didn’t need any additional security since these were “internal” services behind the company firewall.
These challenges are not unique to ACME, nor is the extent of the challenges limited to what they encountered. The following things must be addressed when moving to a services-oriented architecture:
-
Building applications/services capable of responding to changes in their environment
-
Building systems capable of running in partially failed conditions
-
Understanding what’s happening to the overall system as it constantly changes and evolves
-
Enforcing policies about who or what can use system components, and when
As we dig into Istio, we’ll explore these in more detail and explain how to deal with them. These are core challenges to building services-based architectures on any cloud infrastructure. In the past, non-cloud architectures did have to contend with some of these problems; but in today’s cloud environments, they are highly amplified and can take down your entire system if not taken into account correctly. Let’s look a little bit closer at the problems encountered with unreliable infrastructure.
1.1.1 Our cloud infrastructure is not reliable
Even though, as consumers of cloud infrastructure, we don’t see the actual hardware, clouds are made up of millions of pieces of hardware and software. These components form the compute, storage, and networking virtualized infrastructure that we can provision via self-service APIs. Any of these components can, and do, fail. In the past, we did everything we could to make infrastructure highly available, and we built our applications on top of it with assumptions of availability and reliability. In the cloud, we have to build our apps assuming the infrastructure is ephemeral and will be unavailable at times. This ephemerality must be considered upfront in our architectures.
Let’s take a very simple example. Let’s say a Preference service is in charge of managing customer preferences and ends up making calls to a Customer service. In figure 1.2, the Preference service calls the Customer service to update some customer data and experiences severe slowdowns when it sends a message. What does it do? A slow downstream dependency can wreak havoc on the Preference service, including causing it to fail (thus initiating a cascading failure). This scenario can happen for any number of reasons, such as these:
-
The network experienced some failed hardware and is rerouting traffic.
-
The network card on the
Customerservice hardware is experiencing failures.

Figure 1.2 Simple service communication over an unreliable network
The problem is, the Preference service cannot distinguish whether this is a failure of the Customer service. Again, in a cloud environment with millions of hardware and software components, these types of scenarios happen all the time.
1.1.2 Making service interactions resilient
The Preference service can try a few things. It can retry the request, although in a scenario where things are overloaded, that might just add to the downstream issues. If it does retry the request, it cannot be sure that previous attempts didn’t succeed. It can time out the request after some threshold and throw an error. It can also retry to a different instance of the Customer service, maybe in a different availability zone. If the Customer service experiences these or similar issues for an extended period of time, the Preference service may opt to stop calling the Customer service altogether for a cool-off period (a form of circuit breaking, which we’ll cover in more depth in later chapters).
Some patterns have evolved to help mitigate these types of scenarios and help make applications more resilient to unplanned, unexpected failures:
-
Client-side load balancing—Give the client the list of possible endpoints, and let it decide which one to call.
-
Service discovery—A mechanism for finding the periodically updated list of healthy endpoints for a particular logical service.
-
Circuit breaking—Shed load for a period of time to a service that appears to be misbehaving.
-
Bulkheading—Limit client resource usage with explicit thresholds (connections, threads, sessions, and so on) when making calls to a service.
-
Timeouts—Enforce time limitations on requests, sockets, liveness, and so on when making calls to a service.
-
Retry budgets—Apply constraints to retries: that is, limit the number of retries in a given period (for example, only retry 50% of the calls in a 10-second window).
-
Deadlines—Give requests context about how long a response may still be useful; if outside the deadline, disregard processing the request.
Collectively, these types of patterns can be thought of as application networking. They have a lot of overlap with similar constructs at lower layers of the networking stack, except that they operate at the layer of messages instead of packets.
1.1.3 Understanding what’s happening in real time
A very important aspect of going faster is making sure we’re going in the right direction. We try to get deployments out quickly, so we can test how customers react to them, but they will not have an opportunity to react (or will avoid our service) if it’s slow or not available. As we make changes to our services, do we understand what impact (positive or negative) they will have? Do we know how things are running before we make changes?
It is critical to know things about our services architecture like which services are talking to each other, what typical service load looks like, how many failures we expect to see, what happens when services fail, service health, and so on. Each time we make a change by deploying new code or configuration, we introduce the possibility of negatively impacting our key metrics. When network and infrastructure unreliability rear their ugly heads, or if we deploy new code with bugs in it, can we be confident we have enough of a pulse on what’s really happening to trust that the system isn’t on verge of collapse? Observing the system with metrics, logs, and traces is a crucial part of running a services architecture.
1.2 Solving these challenges with application libraries
The first organizations to figure out how to run their applications and services in a cloud environment were the large internet companies, many of which pioneered cloud infrastructure as we know it today. These companies invested massive amounts of time and resources into building libraries and frameworks for a select set of languages that everyone had to use, which helped solve the challenges of running services in a cloud-native architecture. Google built frameworks like Stubby, Twitter built Finagle, and, in 2012, Netflix open sourced its microservices libraries to the open source community. For example, with NetflixOSS, libraries targeted for Java developers handle cloud-native concerns:
Since these libraries were targeted for Java runtimes, they could only be used in Java projects. To use them, we’d have to create an application dependency on them, pull them into our classpath, and then use them in our application code. The following example of using NetflixOSS Hystrix pulls a dependency on Hystrix into your dependency control system:
<dependency>
<groupId>com.netflix.hystrix</groupId>
<artifactId>hystrix-core</artifactId>
<version>x.y.z</version>
</dependency>To use Hystrix, we wrap our commands with a base Hystrix class, HystrixCommand.
public class CommandHelloWorld extends HystrixCommand<String> {
private final String name;
public CommandHelloWorld(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
@Override
protected String run() {
// a real example would do work like a network call here
return "Hello " + name + "!";
}
}If each application is responsible for building resilience into its code, we can distribute the handling of these concerns and eliminate central bottlenecks. In large-scale deployments on unreliable cloud infrastructure, this is a desirable system trait.
1.2.1 Drawbacks to application-specific libraries
Although we’ve mitigated a concern about large-scale services architectures when we decentralize and distribute the implementation of application resiliency into the applications themselves, we’ve introduced some new challenges. The first challenge is around the expected assumptions of any application. If we wish to introduce a new service into our architecture, it will be constrained to implementation decisions made by other people and other teams. For example, to use NetflixOSS Hystrix, you must use Java or a JVM-based technology. Typically, circuit breaking and load balancing go together, so you’d need to use both of those resilience libraries. To use Netflix Ribbon for load balancing, you’d need some kind of registry to discover service endpoints, which might mean using Eureka. Going down this path of using libraries introduces implicit constraints around a very undefined protocol for interacting with the rest of the system.
The second issue is around introducing a new language or framework to implement a service. You may find that NodeJS is a better fit for implementing user-facing APIs but the rest of your architecture uses Java and NetflixOSS. You may opt to find a different set of libraries to implement resilience patterns. Or you may try to find analogous packages like resilient (www.npmjs.com/package/resilient) or hystrixjs (www.npmjs.com/package/hystrixjs). And you’ll need to search for each language you wish to introduce (microservices enable a polyglot development environment, although standardizing on a handful of languages is usually best), certify it, and introduce it to your development stack. Each of these libraries will have a different implementation making different assumptions. In some cases you may not be able to find analogous replacements for each framework/language combination. You end up with a partial implementation for some languages and overall inconsistency in the implementation that is very difficult to reason about in failure scenarios and possibly contributes to obscuring/propagating failures. Figure 1.3 shows how services end up implementing the same set of libraries to manage application networking.
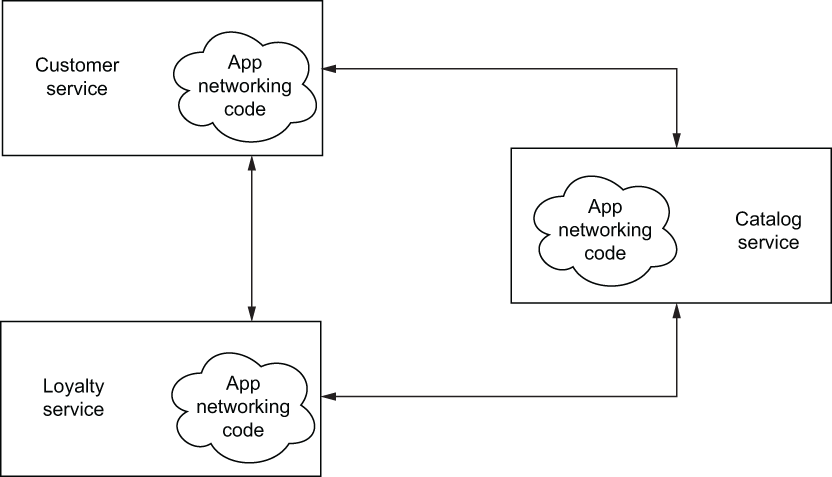
Figure 1.3 Application networking libraries commingled with an application
Finally, maintaining a handful of libraries across a bunch of programming languages and frameworks requires a lot of discipline and is very hard to get right. The key is ensuring that all of the implementations are consistent and correct. One deviation, and you’ve introduced more unpredictability into your system. Pushing out updates and changes across a fleet of services all at the same time can be a daunting task as well.
Although the decentralization of application networking is better for cloud architectures, the operational burden and constraints this approach puts on a system in exchange will be difficult for most organizations to swallow. Even if they take on that challenge, getting it right is even harder. What if there was a way to get the benefits of decentralization without paying the price of massive overhead in maintaining and operating these applications with embedded libraries?
1.3 Pushing these concerns to the infrastructure
These basic application-networking concerns are not specific to any particular application, language, or framework. Retries, timeouts, client-side load balancing, circuit breaking, and so on are also not differentiating application features. They are critical concerns to have as part of your service, but investing massive time and resources into language-specific implementations for each language you intend to use (including the other drawbacks from the previous section) is a waste of time. What we really want is a technology-agnostic way to implement these concerns and relieve applications from having to do so themselves.
1.3.1 The application-aware service proxy
Using a proxy is a way to move these horizontal concerns into the infrastructure. A proxy is an intermediate infrastructure component that can handle connections and redirect them to appropriate backends. We use proxies all the time (whether we know it or not) to handle network traffic, enforce security, and load balance work to backend servers. For example, HAProxy is a simple but powerful reverse proxy for distributing connections across many backend servers. mod_proxy is a module for the Apache HTTP server that also acts as a reverse proxy. In our corporate IT systems, all outgoing internet traffic is typically routed through forwarding proxies in a firewall. These proxies monitor traffic and block certain types of activities.
What we want for this problem, however, is a proxy that’s application aware and able to perform application networking on behalf of our services (see figure 1.4). To do so, this service proxy will need to understand application constructs like messages and requests, unlike more traditional infrastructure proxies, which understand connections and packets. In other words, we need a layer 7 proxy.
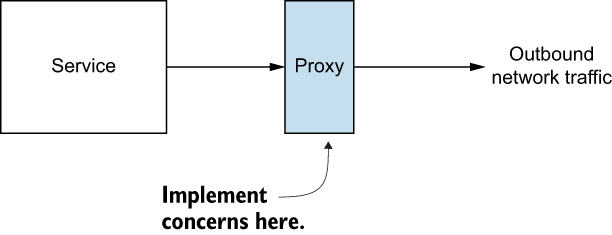
Figure 1.4 Using a proxy to push horizontal concerns such as resilience,traffic control, and security out of the application implementation
1.3.2 Meet the Envoy proxy
Envoy (http://envoyproxy.io) is a service proxy that has emerged in the open source community as a versatile, performant, and capable application-layer proxy. Envoy was developed at Lyft as part of the company’s SOA infrastructure and is capable of implementing networking concerns like retries, timeouts, circuit breaking, client-side load balancing, service discovery, security, and metrics collection without any explicit language or framework dependencies. Envoy implements all of that out-of-process from the application, as shown in figure 1.5.

Figure 1.5 The Envoy proxy is an out-of-process participant in application networking.
The power of Envoy is not limited to these application-layer resilience aspects. Envoy also captures many application-networking metrics like requests per second, number of failures, circuit-breaking events, and more. By using Envoy, we can automatically get visibility into what’s happening between our services, which is where we start to see a lot of unanticipated complexity. The Envoy proxy forms the foundation for solving cross-cutting, horizontal reliability and observability concerns for a services architecture and allows us to push these concerns outside of the applications and into the infrastructure. We’ll cover more of Envoy in ensuing sections and chapters.
We can deploy service proxies alongside our applications to get these features (resilience and observability) out-of-process from the application, but at a fidelity that is very application specific. Figure 1.6 shows how in this model, applications that wish to communicate with the rest of the system do so by passing their requests to Envoy first, which then handles the communication upstream.
Service proxies can also do things like collect distributed tracing spans so we can stitch together all the steps taken by a particular request. We can see how long each step took and look for potential bottlenecks or bugs in our system. If all applications talk through their own proxy to the outside world, and all incoming traffic to an application goes through our proxy, we gain some important capabilities for our application without changing any application code. This proxy + application combination forms the foundation of a communication bus known as a service mesh.
We can deploy a service proxy like Envoy along with every instance of our application as a single atomic unit. For example, in Kubernetes, we can co-deploy a service proxy with our application in a single Pod. Figure 1.7 visualizes the sidecar deployment pattern in which the service proxy is deployed to complement the main application instance.

Figure 1.6 The Envoy proxy out-of-process from the application

Figure 1.7 A sidecar deployment is an additional process that works cooperatively with the main application process to deliver a piece of functionality.
1.4 What’s a service mesh?
Service proxies like Envoy help add important capabilities to our services architecture running in a cloud environment. Each application can have its own requirements or configurations for how a proxy should behave, given its workload goals. With an increasing number of applications and services, it can be difficult to configure and manage a large fleet of proxies. Moreover, having these proxies in place at each application instance opens opportunities for building interesting higher-order capabilities that we would otherwise have to do in the applications themselves.
A service mesh is a distributed application infrastructure that is responsible for handling network traffic on behalf of the application in a transparent, out-of-process manner. Figure 1.8 shows how service proxies form the data plane through which all traffic is handled and observed. The data plane is responsible for establishing, securing, and controlling the traffic through the mesh. The data plane behavior is configured by the control plane. The control plane is the brains of the mesh and exposes an API for operators to manipulate network behaviors. Together, the data plane and the control plane provide important capabilities necessary in any cloud-native architecture:
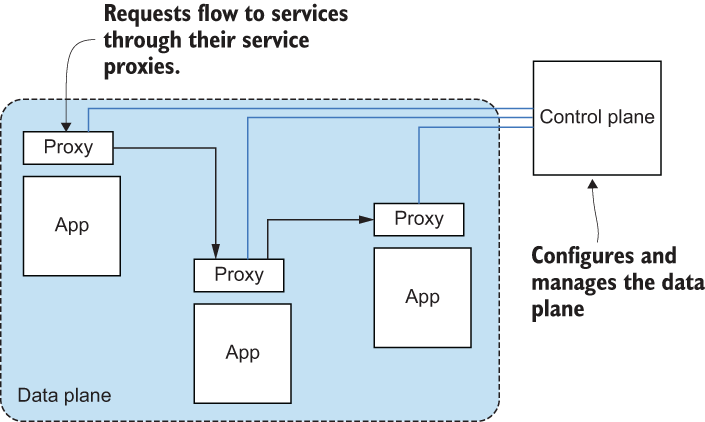
Figure 1.8 A service mesh architecture with co-located application-layer proxies (data plane) and management components (control plane)
The service mesh takes on the responsibility of making service communication resilient to failures by implementing capabilities like retries, timeouts, and circuit breakers. It’s also capable of handling evolving infrastructure topologies by handling things like service discovery, adaptive and zone-aware load balancing, and health checking. Since all the traffic flows through the mesh, operators can control and direct traffic explicitly. For example, if we want to deploy a new version of our application, we may want to expose it to only a small fraction, say 1%, of live traffic. With the service mesh in place, we have the power to do that. Of course, the converse of control in the service mesh is understanding its current behavior. Since traffic flows through the mesh, we’re able to capture detailed signals about the behavior of the network by tracking metrics like request spikes, latency, throughput, failures, and so on. We can use this telemetry to paint a picture of what’s happening in our system. Finally, since the service mesh controls both ends of the network communication between applications, it can enforce strong security like transport-layer encryption with mutual authentication: specifically, using the mutual Transport Layer Security (mTLS) protocol.
The service mesh provides all of these capabilities to service operators with very few or no application code changes, dependencies, or intrusions. Some capabilities require minor cooperation with the application code, but we can avoid large, complicated library dependencies. With a service mesh, it doesn’t matter what application framework or programming language you’ve used to build your application; these capabilities are implemented consistently and correctly and allow service teams to move quickly, safely, and confidently when implementing and delivering changes to systems to test their hypotheses and deliver value.
1.5 Introducing the Istio service mesh
Istio is an open source implementation of a service mesh founded by Google, IBM, and Lyft. It helps you add resilience and observability to your services architecture in a transparent way. With Istio, applications don’t have to know that they’re part of the service mesh: whenever they interact with the outside world, Istio handles the networking on their behalf. It doesn’t matter if you’re using microservices, monoliths, or anything in between—Istio can bring many benefits. Istio’s data plane uses the Envoy proxy and helps you configure your application to have an instance of the service proxy (Envoy) deployed alongside it. Istio’s control plane is made up of a few components that provide APIs for end users/operators, configuration APIs for the proxies, security settings, policy declarations, and more. We’ll cover these control-plane components in future sections of this book.
Istio was originally built to run on Kubernetes but was written from the perspective of being deployment-platform agnostic. This means you can use an Istio-based service mesh across deployment platforms like Kubernetes, OpenShift, and even traditional deployment environments like virtual machines (VMs). In later chapters, we’ll take a look at how powerful this can be for hybrid deployments across combinations of clouds, including private data centers.
NOTE Istio is Greek for “sail,” which goes along nicely with the rest of the Kubernetes nautical words.
With a service proxy next to each application instance, applications no longer need language-specific resilience libraries for circuit breaking, timeouts, retries, service discovery, load balancing, and so on. Moreover, the service proxy also handles metrics collection, distributed tracing, and access control.
Since traffic in the service mesh flows through the Istio service proxy, Istio has control points at each application to influence and direct its networking behavior. This allows a service operator to control traffic flow and implement fine-grained releases with canary releases, dark launches, graduated roll outs, and A/B style testing. We’ll explore these capabilities in later chapters.
Figure 1.9 shows the following:
-
Traffic comes into the cluster from a client outside the mesh through the Istio ingress gateway.
-
Traffic goes to the
Shopping Cartservice. The traffic first passes through its service proxy. The service proxy can apply timeouts, metric collection, security enforcement, and so on, for the service. -
As the request makes its way through various services, Istio’s service proxy can intercept the request at various steps and make routing decisions (for example, to route some requests intended for the
Taxservice to v1.1 of theTaxservice, which may have a fix for certain tax calculations). -
Istio’s control plane (
istiod) is used to configure the Istio proxies, which handle routing, security, telemetry collection, and resilience. -
Request metrics are periodically sent back to various collection services. Distributed tracing spans (like Jaeger or Zipkin) are sent back to a tracing store, which can be used later to track the path and latency of a request through the system.

Figure 1.9 Istio is an implementation of a service mesh with a data plane based on Envoy and a control plane.
An important requirement for any services-based architecture is security. Istio has security enabled by default. Since Istio controls each end of the application’s networking path, it can transparently encrypt the traffic by default. In fact, to take it a step further, Istio can manage key and certificate issuance, installation, and rotation so that services get mutual TLS out of the box. If you’ve ever experienced the pain of installing and configuring certificates for mutual TLS, you’ll appreciate both the simplicity of operation and how powerful this capability is. Istio can assign a workload identity and embed that into the certificates. Istio can also use the identities of different workloads to further implement powerful access-control policies.
Finally, but no less important than the previous capabilities, with Istio you can implement quotas, rate limiting, and organizational policies. Using Istio’s policy enforcement, you can create very fine-grained rules about what services are allowed to interact with each other, and which are not. This becomes especially important when deploying services across clouds (public and on premises).
Istio is a powerful implementation of a service mesh. Its capabilities allow you to simplify running and operating a cloud-native services architecture, potentially across a hybrid environment. Throughout the rest of this book, we’ll show you how to take advantage of Istio’s functionality to operate your microservices in a cloud-native world.
1.5.1 How a service mesh relates to an enterprise service bus
An enterprise service bus (ESB) from SOA days has some similarities to a service mesh, at least in spirit. If we take a look at how the ESB was originally described in the early days of SOA, we even see some similar language:
The enterprise service bus (ESB) is a silent partner in the SOA logical architecture. Its presence in the architecture is transparent to the services of your SOA application. However, the presence of an ESB is fundamental to simplifying the task of invoking services—making the use of services wherever they are needed, independent of the details of locating those services and transporting service requests across the network to invoke those services wherever they reside within your enterprise. (http://mng.bz/5K7D)
In this description of an ESB, we see that it’s supposed to be a silent partner, which means applications should not know about it. With a service mesh, we expect similar behavior. The service mesh should be transparent to the application. An ESB also is “fundamental to simplifying the task of invoking services.” For an ESB, this included things like protocol mediation, message transformation, and content-based routing. A service mesh is not responsible for all the things an ESB does, but it does provide request resilience through retries, timeouts, and circuit breaking, and it does provide services like service discovery and load balancing.
Overall, there are a few significant differences between a service mesh and an ESB:
-
The ESB introduced a new silo in organizations that was the gatekeeper for service integrations within the enterprise.
-
It mixed application networking and service mediation concerns.
-
It was often based on complicated proprietary vendor software.
Figure 1.10 shows how ESB integrated applications by placing itself in the center and then comingled application business logic with application routing, transformation, and mediation.

Figure 1.10 An ESB as a centralized system that integrates applications
A service mesh’s role is only in application networking concerns. Complex business transformations (such as X12, EDI, and HL7), business process orchestration, process exceptions, service orchestration, and so on do not belong in a service mesh. Additionally, the service mesh data plane is highly distributed, with its proxies collocated with applications. This eliminates single points of failure or bottlenecks that often appear with an ESB architecture. Finally, both operator and service teams are responsible for establishing service-level objectives (SLOs) and configuring the service mesh to support them. The responsibility for integration with other systems is no longer the purview of a centralized team; all service developers share that duty.
1.5.2 How a service mesh relates to an API gateway
Istio and service-mesh technology also have some similarities to and differences from API gateways. API gateway infrastructure (not the microservices pattern from http://microservices.io/patterns/apigateway.html) is used in API management suites to provide a public-facing endpoint for an organization’s public APIs. Its role is to provide security, rate limiting, quota management, and metrics collection for these public APIs and tie into an overall API management solution that includes API plan specification, user registration, billing, and other operational concerns. API gateway architectures vary wildly but have been used mostly at the edge of architectures to expose public APIs. They have also been used for internal APIs to centralize security, policy, and metrics collection. However, this creates a centralized system through which traffic travels, which can become a source of bottlenecks, as described for the ESB and messaging bus.
Figure 1.11 shows how all internal traffic between services traverses the API gateway when used for internal APIs. This means for each service in the graph, we’re taking two hops: one to get to the gateway and one to get to the actual service. This has implications not just for network overhead and latency but also for security. With this multi-hop architecture, the API gateway cannot secure the transport mechanism with the application unless the application participates in the security configuration. And in many cases, an API gateway doesn’t implement resilience capabilities like circuit breakers or bulkheading.

Figure 1.11 API gateway for service traffic
In a service mesh, proxies are collocated with the services and do not take on additional hops. They’re also decentralized so each application can configure its proxy for its particular workloads and not be affected by noisy neighbor scenarios.1 Since each proxy lives with its corresponding application instance, it can secure the transport mechanism from end to end without the application knowing or actively participating.
Figure 1.12 shows how the service proxies are becoming a place to enforce and implement API gateway functionality. As service mesh technologies like Istio continue to mature, we’ll see API management built on top of the service mesh and not need specialized API gateway proxies.

Figure 1.12 The service proxies implement ESB and API gateway functionalities.
1.5.3 Can I use Istio for non-microservices deployments?
Istio’s power shines as you move to architectures that experience large numbers of services, interconnections, and networks over unreliable cloud infrastructure, potentially spanning clusters, clouds, and data centers. Furthermore, since Istio runs out-of-process from the application, it can be deployed to existing legacy or brownfield environments as well, thus incorporating those into the mesh.
For example, if you have existing monolith deployments, the Istio service proxy can be deployed alongside each monolith instance and will transparently handle network traffic for it. At a minimum, this can add request metrics that become very useful for understanding the application’s usage, latency, throughput, and failure characteristics. Istio can also participate in higher-level features like policy enforcement about what services are allowed to talk to it. This capability becomes highly important in a hybrid-cloud deployment with monoliths running on premises and cloud services potentially running in a public cloud. With Istio, we can enforce policies such as “cloud services cannot talk to and use data from on-premises applications.”
You may also have an older vintage of microservices implemented with resilience libraries like NetflixOSS. Istio brings powerful capabilities to these deployments as well. Even if both Istio and the application implement functionality like a circuit breaker, you can feel secure, knowing that the more restrictive policies will kick in and everything should work fine. Scenarios with timeouts and retries may conflict, but using Istio, you can test your service and find these conflicts before you ever make it to production.
1.5.4 Where Istio fits in distributed architectures
You should pick the technology you use in your implementations based on the problems you have and the capabilities you need. Technologies like Istio, and service meshes in general, are powerful infrastructure capabilities and touch a lot of areas of a distributed architecture—but they are not right for and should not be considered for every problem you may have. Figure 1.13 shows how an ideal cloud architecture would separate different concerns from each layer in the implementation.
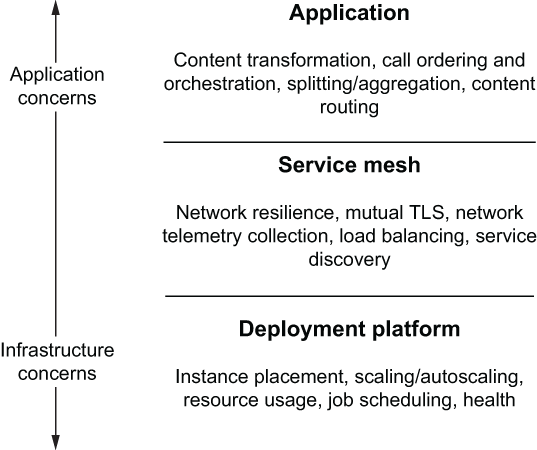
Figure 1.13 An overview of separation of concerns in cloud-native applications. Istio plays a supporting role to the application layer and sits above the lower-level deployment layer.
At the lower level of your architecture is your deployment automation infrastructure. This is responsible for getting code deployed onto your platform (containers, Kubernetes, public cloud, VMs, and so on). Istio does not encroach on or prescribe what deployment automation tools you should use.
At a higher level, you have application business logic: the differentiating code that a business must write to stay competitive. This code includes the business domain as well as knowing which services to call and in what order, what to do with service interaction responses (such as how to aggregate them together), and what to do when there are process failures. Istio does not implement or replace any business logic. It does not do service orchestration, business payload transformation, payload enrichment, splitting/aggregating, or rules computation. These capabilities are best left to libraries and frameworks inside your applications.
Istio plays the role of connective tissue between the deployment platform and the application code. Its role is to facilitate taking complicated networking code out of the application. It can do content-based routing based on external metadata that is part of the request (HTTP headers, and so on). It can do fine-grained traffic control and routing based on service and request metadata matching. It can also secure the transport and offload security token verification and enforce quota and usage policies defined by service operators.
Now that we have a basic understanding of what Istio is, the best way to get further acquainted with its power is to use it. In chapter 2, we’ll look at using Istio to achieve basic metrics collection, reliability, and traffic control.
1.5.5 What are the drawbacks to using a service mesh?
We’ve talked a lot about the problems of building a distributed architecture and how a service mesh can help, but we don’t want to give the impression that a service mesh is the one and only way to solve these problems or that a service mesh doesn’t have drawbacks. Using a service mesh does have a few drawbacks you must be aware of.
First, using a service mesh puts another piece of middleware, specifically a proxy, in the request path. This proxy can deliver a lot of value; but for those unfamiliar with the proxy, it can end up being a black box and make it harder to debug an application’s behavior. The Envoy proxy is specifically built to be very debuggable by exposing a lot about what’s happening on the network—more so than if it wasn’t there—but for someone unfamiliar with operating Envoy, it could look very complex and inhibit existing debugging practices.
Another drawback of using a service mesh is in terms of tenancy. A mesh is as valuable as the services running in the mesh. That is, the more services in the mesh, the more valuable the mesh becomes for operating those services. However, without proper policy, automation, and forethought going into the tenancy and isolation models of the physical mesh deployment, you could end up in a situation where misconfiguring the mesh impacts many services.
Finally, a service mesh becomes a fundamentally important piece of your services and application architecture since it’s on the request path. A service mesh can expose a lot of opportunities to improve security, observability, and routing control posture. The downside is that a mesh introduces another layer and another opportunity for complexity. It can be difficult to understand how to configure, operate, and, most importantly, integrate it within your existing organizational processes and governance and between existing teams.
In general, a service mesh brings a lot of value—but not without trade-offs. Just as with any tool or platform, you should evaluate these trade-offs based on your context and constraints, determine whether a service mesh makes sense for your scenarios, and, if so, make a plan to successfully adopt a mesh.
Overall, we love service meshes; and now that Istio is mature, it is already improving the operations of many businesses. With the continuous stream of contributions to both Istio and Envoy, it is exciting to see where it’s going next. Hopefully, this chapter has passed some of the excitement on to you and given you ideas about how Istio can improve the security and reliability of your services.
Summary
-
Operating microservices in the cloud involves many challenges: network unreliability, service availability, traffic flow that is hard to understand, traffic encryption, application health, and performance, to name a few.
-
Those difficulties are alleviated by patterns (such as service discovery, client-side load balancing, and retries) that are implemented using libraries within every application.
-
Additional libraries and services are required to create and distribute metrics and traces to gain observability over the services.
-
A service mesh is an infrastructure that implements those cross-cutting concerns on behalf of applications in a transparent, out-of-process manner.
-
Istio is an implementation of a service mesh composed of the following:
-
-
The data plane, which is composed of service proxies that are deployed alongside applications and complement them by implementing policies, managing traffic, generating metrics and traces, and much more.
-
The control plane, which exposes an API for operators to manipulate the data plane’s network behavior.
-
-
Istio uses Envoy as its service proxy due to its versatility and because it can be dynamically configured.
1. The term noisy neighbor describes the scenario where a service is degraded due to the activity of another service. Learn more at http://mng.bz/mxvM.