
13.2. Selecting a fetch strategy
Hibernate executes SQL SELECT statements to load objects into memory. If you load an object, a single or several SELECTs are executed, depending on the number of tables which are involved and the fetching strategy you've applied.
Your goal is to minimize the number of SQL statements and to simplify the SQL statements, so that querying can be as efficient as possible. You do this by applying the best fetching strategy for each collection or association. Let's walk through the different options step by step.
By default, Hibernate fetches associated objects and collections lazily whenever you access them (we assume that you map all to-one associations as FetchType.LAZY if you use Java Persistence). Look at the following trivial code example:
Item item = (Item) session.get(Item.class, new Long(123));
You didn't configure any association or collection to be nonlazy, and that proxies can be generated for all associations. Hence, this operation results in the following SQL SELECT:
select item.* from ITEM item where item.ITEM_ID = ?
(Note that the real SQL Hibernate produces contains automatically generated aliases; we've removed them for readability reasons in all the following examples.) You can see that the SELECT queries only the ITEM table and retrieves a particular row. All entity associations and collections aren't retrieved. If you access any proxied association or uninitialized collection, a second SELECT is executed to retrieve the data on demand.
Your first optimization step is to reduce the number of additional on-demand SELECTs you necessarily see with the default lazy behavior—for example, by prefetching data.
13.2.1. Prefetching data in batches
If every entity association and collection is fetched only on demand, many additional SQL SELECT statements may be necessary to complete a particular procedure. For example, consider the following query that retrieves all Item objects and accesses the data of each items seller:
List allItems = session.createQuery("from Item").list();
processSeller( (Item)allItems.get(0) );
processSeller( (Item)allItems.get(1) );
processSeller( (Item)allItems.get(2) );
Naturally, you use a loop here and iterate through the results, but the problem this code exposes is the same. You see one SQL SELECT to retrieve all the Item objects, and an additional SELECT for every seller of an Item as soon as you process it. All associated User objects are proxies. This is one of the worst-case scenarios we'll describe later in more detail: the n+1 selects problem. This is what the SQL looks like:
select items... select u.* from USERS u where u.USER_ID = ? select u.* from USERS u where u.USER_ID = ? select u.* from USERS u where u.USER_ID = ? ...
Hibernate offers some algorithms that can prefetch User objects. The first optimization we now discuss is called batch fetching, and it works as follows: If one proxy of a User must be initialized, go ahead and initialize several in the same SELECT. In other words, if you already know that there are three Item instances in the persistence context, and that they all have a proxy applied to their seller association, you may as well initialize all the proxies instead of just one.
Batch fetching is often called a blind-guess optimization, because you don't know how many uninitialized User proxies may be in a particular persistence context. In the previous example, this number depends on the number of Item objects returned. You make a guess and apply a batch-size fetching strategy to your User class mapping:
<class name="User"
table="USERS"
batch-size="10">
...
</class>
You're telling Hibernate to prefetch up to 10 uninitialized proxies in a single SQL SELECT, if one proxy must be initialized. The resulting SQL for the earlier query and procedure may now look as follows:
select items... select u.* from USERS u where u.USER_ID in (?, ?, ?)
The first statement that retrieves all Item objects is executed when you list() the query. The next statement, retrieving three User objects, is triggered as soon as you initialize the first proxy returned by allItems.get(0).getSeller(). This query loads three sellers at once—because this is how many items the initial query returned and how many proxies are uninitialized in the current persistence context. You defined the batch size as "up to 10." If more than 10 items are returned, you see how the second query retrieves 10 sellers in one batch. If the application hits another proxy that hasn't been initialized, a batch of another 10 is retrieved—and so on, until no more uninitialized proxies are left in the persistence context or the application stops accessing proxied objects.
FAQ
What is the real batch-fetching algorithm? You can think about batch fetching as explained earlier, but you may see a slightly different algorithm if you experiment with it in practice. It's up to you if you want to know and understand this algorithm, or if you trust Hibernate to do the right thing. As an example, imagine a batch size of 20 and a total number of 119 uninitialized proxies that have to be loaded in batches. At startup time, Hibernate reads the mapping metadata and creates 11 batch loaders internally. Each loader knows how many proxies it can initialize: 20, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1. The goal is to minimize the memory consumption for loader creation and to create enough loaders that every possible batch fetch can be produced. Another goal is to minimize the number of SQL SELECTs, obviously. To initialize 119 proxies Hibernate executes seven batches (you probably expected six, because 6 × 20 > 119). The batch loaders that are applied are five times 20, one time 10, and one time 9, automatically selected by Hibernate.
Batch fetching is also available for collections:
<class name="Item" table="ITEM">
...
<set name="bids"
inverse="true"
batch-size="10">
<key column="ITEM_ID"/>
<one-to-many class="Bid"/>
</set>
</class>
If you now force the initialization of one bids collection, up to 10 more collections of the same type, if they're uninitialized in the current persistence context, are loaded right away:
select items... select b.* from BID b where b.ITEM_ID in (?, ?, ?)
In this case, you again have three Item objects in persistent state, and touching one of the unloaded bids collections. Now all three Item objects have their bids loaded in a single SELECT.
Batch-size settings for entity proxies and collections are also available with annotations, but only as Hibernate extensions:
@Entity
@Table(name = "USERS")
@org.hibernate.annotations.BatchSize(size = 10)
public class User { ... }
@Entity
public class Item {
...
@OneToMany
@org.hibernate.annotations.BatchSize(size = 10)
private Set<Bid> bids = new HashSet<Bid>();
...
}
Prefetching proxies and collections with a batch strategy is really a blind guess. It's a smart optimization that can significantly reduce the number of SQL statements that are otherwise necessary to initialize all the objects you're working with. The only downside of prefetching is, of course, that you may prefetch data you won't need in the end. The trade-off is possibly higher memory consumption, with fewer SQL statements. The latter is often much more important: Memory is cheap, but scaling database servers isn't.
Another prefetching algorithm that isn't a blind guess uses subselects to initialize many collections with a single statement.
13.2.2. Prefetching collections with subselects
Let's take the last example and apply a (probably) better prefetch optimization:
List allItems = session.createQuery("from Item").list();
processBids( (Item)allItems.get(0) );
processBids( (Item)allItems.get(1) );
processBids( (Item)allItems.get(2) );
You get one initial SQL SELECT to retrieve all Item objects, and one additional SELECT for each bids collection, when it's accessed. One possibility to improve this would be batch fetching; however, you'd need to figure out an optimum batch size by trial. A much better optimization is subselect fetching for this collection mapping:
<class name="Item" table="ITEM">
...
<set name="bids"
inverse="true"
fetch="subselect">
<key column="ITEM_ID"/>
<one-to-many class="Bid"/>
</set>
</class>
Hibernate now initializes all bids collections for all loaded Item objects, as soon as you force the initialization of one bids collection. It does that by rerunning the first initial query (slightly modified) in a subselect:
select i.* from ITEM i
select b.* from BID b
where b.ITEM_ID in (select i.ITEM_ID from ITEM i)
In annotations, you again have to use a Hibernate extension to enable this optimization:
@OneToMany
@org.hibernate.annotations.Fetch(
org.hibernate.annotations.FetchMode.SUBSELECT
)
private Set<Bid> bids = new HashSet<Bid>();}
Prefetching using a subselect is a powerful optimization; we'll show you a few more details about it later, when we walk through a typical scenario. Subselect fetching is, at the time of writing, available only for collections, not for entity proxies. Also note that the original query that is rerun as a subselect is only remembered by Hibernate for a particular Session. If you detach an Item instance without initializing the collection of bids, and then reattach it and start iterating through the collection, no prefetching of other collections occurs.
All the previous fetching strategies are helpful if you try to reduce the number of additional SELECTs that are natural if you work with lazy loading and retrieve objects and collections on demand. The final fetching strategy is the opposite of on-demand retrieval. Often you want to retrieve associated objects or collections in the same initial SELECT with a JOIN.
13.2.3. Eager fetching with joins
Lazy loading is an excellent default strategy. On other hand, you can often look at your domain and data model and say, "Every time I need an Item, I also need the seller of that Item." If you can make that statement, you should go into your mapping metadata, enable eager fetching for the seller association, and utilize SQL joins:
<class name="Item" table="ITEM">
...
<many-to-one name="seller"
class="User"
column="SELLER_ID"
update="false"
fetch="join"/>
</class>
Hibernate now loads both an Item and its seller in a single SQL statement. For example:
Item item = (Item) session.get(Item.class, new Long(123));
This operation triggers the following SQL SELECT:
select i.*, u.*
from ITEM i
left outer join USERS u on i.SELLER_ID = u.USER_ID
where i.ITEM_ID = ?
Obviously, the seller is no longer lazily loaded on demand, but immediately. Hence, a fetch="join" disables lazy loading. If you only enable eager fetching with lazy="false", you see an immediate second SELECT. With fetch="join", you get the seller loaded in the same single SELECT. Look at the resultset from this query shown in figure 13.4.
Figure 13-4. Two tables are joined to eagerly fetch associated rows.

Hibernate reads this row and marshals two objects from the result. It connects them with a reference from Item to User, the seller association. If an Item doesn't have a seller all u.* columns are filled with NULL. This is why Hibernate uses an outer join, so it can retrieve not only Item objects with sellers, but all of them. But you know that an Item has to have a seller in CaveatEmptor. If you enable <many-to-one not-null="true"/>, Hibernate executes an inner join instead of an outer join.
You can also set the eager join fetching strategy on a collection:
<class name="Item" table="ITEM">
...
<set name="bids"
inverse="true"
fetch="join">
<key column="ITEM_ID"/>
<one-to-many class="Bid"/>
</set>
</class>
If you now load many Item objects, for example with createCriteria(Item.class).list(), this is how the resulting SQL statement looks:
select i.*, b.*
from ITEM i
left outer join BID b on i.ITEM_ID = b.ITEM_ID
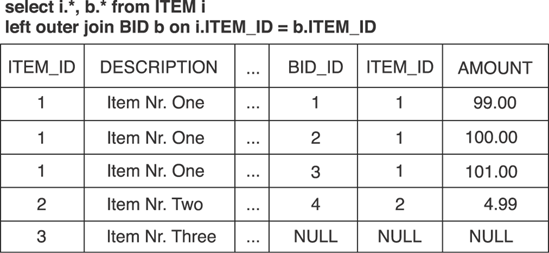
The resultset now contains many rows, with duplicate data for each Item that has many bids, and NULL fillers for all Item objects that don't have bids. Look at the resultset in figure 13.5.
Hibernate creates three persistent Item instances, as well as four Bid instances, and links them all together in the persistence context so that you can navigate this graph and iterate through collections—even when the persistence context is closed and all objects are detached.
Eager-fetching collections using inner joins is conceptually possible, and we'll do this later in HQL queries. However, it wouldn't make sense to cut off all the Item objects without bids in a global fetching strategy in mapping metadata, so there is no option for global inner join eager fetching of collections.
With Java Persistence annotations, you enable eager fetching with a FetchType annotation attribute:
@Entity
public class Item {
...
@ManyToOne(fetch = FetchType.EAGER)
private User seller;
@OneToMany(fetch = FetchType.EAGER)
private Set<Bid> bids = new HashSet<Bid>();
...
}
This mapping example should look familiar: You used it to disable lazy loading of an association and a collection earlier. Hibernate by default interprets this as an eager fetch that shouldn't be executed with an immediate second SELECT, but with a JOIN in the initial query.
Figure 13-5. Outer join fetching of associated collection elements
You can keep the FetchType.EAGER Java Persistence annotation but switch from join fetching to an immediate second select explicitly by adding a Hibernate extension annotation:
@Entity
public class Item {
...
@ManyToOne(fetch = FetchType.EAGER)
@org.hibernate.annotations.Fetch(
org.hibernate.annotations.FetchMode.SELECT
)
private User seller;
}
If an Item instance is loaded, Hibernate will eagerly load the seller of this item with an immediate second SELECT.
Finally, we have to introduce a global Hibernate configuration setting that you can use to control the maximum number of joined entity associations (not collections). Consider all many-to-one and one-to-one association mappings you've set to fetch="join" (or FetchType.EAGER) in your mapping metadata. Let's assume that Item has a successfulBid association, that Bid has a bidder, and that User has a shippingAddress. If all these associations are mapped with fetch="join", how many tables are joined and how much data is retrieved when you load an Item?
The number of tables joined in this case depends on the global hibernate.max_fetch_depth configuration property. By default, no limit is set, so loading an Item also retrieves a Bid, a User, and an Address in a single select. Reasonable settings are small, usually between 1 and 5. You may even disable join fetching for many-to-one and one-to-one associations by setting the property to 0! (Note that some database dialects may preset this property: For example, MySQLDialect sets it to 2.)
SQL queries also get more complex if inheritance or joined mappings are involved. You need to consider a few extra optimization options whenever secondary tables are mapped for a particular entity class.
13.2.4. Optimizing fetching for secondary tables
If you query for objects that are of a class which is part of an inheritance hierarchy, the SQL statements get more complex:
List result = session.createQuery("from BillingDetails").list();
This operation retrieves all BillingDetails instances. The SQL SELECT now depends on the inheritance mapping strategy you've chosen for BillingDetails and its subclasses CreditCard and BankAccount. Assuming that you've mapped them all to one table (a table-per-hierarchy), the query isn't any different than the one shown in the previous section. However, if you've mapped them with implicit polymorphism, this single HQL operation may result in several SQL SELECTs against each table of each subclass.
Outer joins for a table-per-subclass hierarchy
If you map the hierarchy in a normalized fashion (see the tables and mapping in chapter 5, section 5.1.4, "Table per subclass"), all subclass tables are OUTER JOINed in the initial statement:
select
b1.BILLING_DETAILS_ID,
b1.OWNER,
b1.USER_ID,
b2.NUMBER,
b2.EXP_MONTH,
b2.EXP_YEAR,
b3.ACCOUNT,
b3.BANKNAME,
b3.SWIFT,
case
when b2.CREDIT_CARD_ID is not null then 1
when b3.BANK_ACCOUNT_ID is not null then 2
when b1.BILLING_DETAILS_ID is not null then 0
end as clazz
from
BILLING_DETAILS b1
left outer join
CREDIT_CARD b2
on b1.BILLING_DETAILS_ID = b2.CREDIT_CARD_ID
left outer join
BANK_ACCOUNT b3
on b1.BILLING_DETAILS_ID = b3.BANK_ACCOUNT_ID
This is already a interesting query. It joins three tables and utilizes a CASE ... WHEN ... END expression to fill in the clazz column with a number between 0 and 2. Hibernate can then read the resultset and decide on the basis of this number what class each of the returned rows represents an instance of.
Many database-management systems limit the maximum number of tables that can be combined with an OUTER JOIN. You'll possibly hit that limit if you have a wide and deep inheritance hierarchy mapped with a normalized strategy (we're talking about inheritance hierarchies that should be reconsidered to accommodate the fact that after all, you're working with an SQL database).
Switching to additional selects
In mapping metadata, you can then tell Hibernate to switch to a different fetching strategy. You want some parts of your inheritance hierarchy to be fetched with immediate additional SELECT statements, not with an OUTER JOIN in the initial query.
The only way to enable this fetching strategy is to refactor the mapping slightly, as a mix of table-per-hierarchy (with a discriminator column) and table-per-subclass with the <join> mapping:
<class name="BillingDetails"
table="BILLING_DETAILS"
abstract="true">
<id name="id"
column="BILLING_DETAILS_ID"
.../>
<discriminator
column="BILLING_DETAILS_TYPE"
type="string"/>
...
<subclass name="CreditCard" discriminator-value="CC">
<join table="CREDIT_CARD" fetch="select">
<key column="CREDIT_CARD_ID"/>
...
</join>
</subclass>
<subclass name="BankAccount" discriminator-value="BA">
<join table="BANK_ACCOUNT" fetch="join">
<key column="BANK_ACCOUNT_ID"/>
...
</join>
</subclass>
</class>
This mapping breaks out the CreditCard and BankAccount classes each into its own table but preserves the discriminator column in the superclass table. The fetching strategy for CreditCard objects is select, whereas the strategy for BankAccount is the default, join. Now, if you query for all BillingDetails, the following SQL is produced:
select
b1.BILLING_DETAILS_ID,
b1.OWNER,
b1.USER_ID,
b2.ACCOUNT,
b2.BANKNAME,
b2.SWIFT,
b1.BILLING_DETAILS_TYPE as clazz
from
BILLING_DETAILS b1
left outer join
BANK_ACCOUNT b2
on b1.BILLING_DETAILS_ID = b2.BANK_ACCOUNT_ID;
select cc.NUMBER, cc.EXP_MONTH, cc.EXP_YEAR
from CREDIT_CARD cc where cc.CREDIT_CARD_ID = ?
select cc.NUMBER, cc.EXP_MONTH, cc.EXP_YEAR
from CREDIT_CARD cc where cc.CREDIT_CARD_ID = ?
The first SQL SELECT retrieves all rows from the superclass table and all rows from the BANK_ACCOUNT table. It also returns discriminator values for each row as the clazz column. Hibernate now executes an additional select against the CREDIT_CARD table for each row of the first result that had the right discriminator for a CreditCard. In other words, two queries mean that two rows in the BILLING_DETAILS superclass table represent (part of) a CreditCard object.
This kind of optimization is rarely necessary, but you now also know that you can switch from a default join fetching strategy to an additional immediate select whenever you deal with a <join> mapping.
We've now completed our journey through all options you can set in mapping metadata to influence the default fetch plan and fetching strategy. You learned how to define what should be loaded by manipulating the lazy attribute, and how it should be loaded by setting the fetch attribute. In annotations, you use FetchType.LAZY and FetchType.EAGER, and you use Hibernate extensions for more fine-grained control of the fetch plan and strategy.
Knowing all the available options is only one step toward an optimized and efficient Hibernate or Java Persistence application. You also need to know when and when not to apply a particular strategy.
13.2.5. Optimization guidelines
By default, Hibernate never loads data that you didn't ask for, which reduces the memory consumption of your persistence context. However, it also exposes you to the so-called n+1 selects problem. If every association and collection is initialized only on demand, and you have no other strategy configured, a particular procedure may well execute dozens or even hundreds of queries to get all the data you require. You need the right strategy to avoid executing too many SQL statements.
If you switch from the default strategy to queries that eagerly fetch data with joins, you may run into another problem, the Cartesian product issue. Instead of executing too many SQL statements, you may now (often as a side effect) create statements that retrieve too much data.
You need to find the middle ground between the two extremes: the correct fetching strategy for each procedure and use case in your application. You need to know which global fetch plan and strategy you should set in your mapping metadata, and which fetching strategy you apply only for a particular query (with HQL or Criteria).
We now introduce the basic problems of too many selects and Cartesian products and then walk you through optimization step by step.
The n+1 selects problem
The n+1 selects problem is easy to understand with some example code. Let's assume that you don't configure any fetch plan or fetching strategy in your mapping metadata: Everything is lazy and loaded on demand. The following example code tries to find the highest Bids for all Items (there are many other ways to do this more easily, of course):
List<Item> allItems = session.createQuery("from Item").list();
// List<Item> allItems = session.createCriteria(Item.class).list();
Map<Item, Bid> highestBids = new HashMap<Item, Bid>();
for (Item item : allItems) {
Bid highestBid = null;
for (Bid bid : item.getBids() ) { // Initialize the collection
if (highestBid == null)
highestBid = bid;
if (bid.getAmount() > highestBid.getAmount())
highestBid = bid;
}
highestBids.put(item, highestBid);
}
First you retrieve all Item instances; there is no difference between HQL and Criteria queries. This query triggers one SQL SELECT that retrieves all rows of the ITEM table and returns n persistent objects. Next, you iterate through this result and access each Item object.
What you access is the bids collection of each Item. This collection isn't initialized so far, the Bid objects for each item have to be loaded with an additional query. This whole code snippet therefore produces n+1 selects.
You always want to avoid n+1 selects.
A first solution could be a change of your global mapping metadata for the collection, enabling prefetching in batches:
<set name="bids"
inverse="true"
batch-size="10">
<key column="ITEM_ID"/>
<one-to-many class="Bid"/>
</set>
Instead of n+1 selects, you now see n/10+1 selects to retrieve the required collections into memory. This optimization seems reasonable for an auction application: "Only load the bids for an item when they're needed, on demand. But if one collection of bids must be loaded for a particular item, assume that other item objects in the persistence context also need their bids collections initialized. Do this in batches, because it's somewhat likely that not all item objects need their bids."
With a subselect-based prefetch, you can reduce the number of selects to exactly two:
<set name="bids"
inverse="true"
fetch="subselect">
<key column="ITEM_ID"/>
<one-to-many class="Bid"/>
</set>
The first query in the procedure now executes a single SQL SELECT to retrieve all Item instances. Hibernate remembers this statement and applies it again when you hit the first uninitialized collection. All collections are initialized with the second query. The reasoning for this optimization is slightly different: "Only load the bids for an item when they're needed, on demand. But if one collection of bids must be loaded, for a particular item, assume that all other item objects in the persistence context also need their bids collection initialized."
Finally, you can effectively turn off lazy loading of the bids collection and switch to an eager fetching strategy that results in only a single SQL SELECT:
<set name="bids"
inverse="true"
fetch="join">
<key column="ITEM_ID"/>
<one-to-many class="Bid"/>
</set>
This seems to be an optimization you shouldn't make. Can you really say that "whenever an item is needed, all its bids are needed as well"? Fetching strategies in mapping metadata work on a global level. We don't consider fetch="join" a common optimization for collection mappings; you rarely need a fully initialized collection all the time. In addition to resulting in higher memory consumption, every OUTER JOINed collection is a step toward a more serious Cartesian product problem, which we'll explore in more detail soon.
In practice, you'll most likely enable a batch or subselect strategy in your mapping metadata for the bids collection. If a particular procedure, such as this, requires all the bids for each Item in-memory, you modify the initial HQL or Criteria query and apply a dynamic fetching strategy:
List<Item> allItems =
session.createQuery("from Item i left join fetch i.bids")
.list();
List<Item> allItems =
session.createCriteria(Item.class)
.setFetchMode("bids", FetchMode.JOIN)
.list();
// Iterate through the collections...
Both queries result in a single SELECT that retrieves the bids for all Item instances with an OUTER JOIN (as it would if you have mapped the collection with join="fetch").
This is likely the first time you've seen how to define a fetching strategy that isn't global. The global fetch plan and fetching strategy settings you put in your mapping metadata are just that: global defaults that always apply. Any optimization process also needs more fine-grained rules, fetching strategies and fetch plans that are applicable for only a particular procedure or use case. We'll have much more to say about fetching with HQL and Criteria in the next chapter. All you need to know now is that these options exist.
The n+1 selects problem appears in more situations than just when you work with lazy collections. Uninitialized proxies expose the same behavior: You may need many SELECTs to initialize all the objects you're working with in a particular procedure. The optimization guidelines we've shown are the same, but there is one exception: The fetch="join" setting on <many-to-one> or <one-to-one> associations is a common optimization, as is a @ManyToOne(fetch = FetchType.EAGER)annotation (which is the default in Java Persistence). Eager join fetching of single-ended associations, unlike eager outer-join fetching of collections, doesn't create a Cartesian product problem.
The Cartesian product problem
The opposite of the n+1 selects problem are SELECT statements that fetch too much data. This Cartesian product problem always appears if you try to fetch several "parallel" collections.
Let's assume you've made the decision to apply a global fetch="join" setting to the bids collection of an Item (despite our recommendation to use global prefetching and a dynamic join-fetching strategy only when necessary). The Item class has other collections: for example, the images. Let's also assume that you decide that all images for each item have to be loaded all the time, eagerly with a fetch="join" strategy:
<class name="Item">
...
<set name="bids"
inverse="true"
fetch="join">
<key column="ITEM_ID"/>
<one-to-many class="Bid"/>
</set>
<set name="images"
fetch="join">
<key column="ITEM_ID"/>
<composite-element class="Image">...
</set>
</class>
If you map two parallel collections (their owning entity is the same) with an eager outer-join fetching strategy, and load all Item objects, Hibernate executes an SQL SELECT that creates a product of the two collections:
select item.*, bid.*, image.*
from ITEM item
left outer join BID bid on item.ITEM_ID = bid.ITEM_ID
left outer join ITEM_IMAGE image on item.ITEM_ID = image.ITEM_ID
Look at the resultset of that query, shown in figure 13.6.
This resultset contains lots of redundant data. Item 1 has three bids and two images, item 2 has one bid and one image, and item 3 has no bids and no images. The size of the product depends on the size of the collections you're retrieving: 3 times 2, 1 times 1, plus 1, total 8 result rows. Now imagine that you have 1,000 items in the database, and each item has 20 bids and 5 images—you'll see a resultset with possibly 100,000 rows! The size of this result may well be several megabytes. Considerable processing time and memory are required on the database server to create this resultset. All the data must be transferred across the network. Hibernate immediately removes all the duplicates when it marshals the resultset into persistent objects and collections—redundant information is skipped. Three queries are certainly faster!
Figure 13-6. A product is the result of two outer joins with many rows.

You get three queries if you map the parallel collections with fetch="subselect"; this is the recommended optimization for parallel collections. However, for every rule there is an exception. As long as the collections are small, a product may be an acceptable fetching strategy. Note that parallel single-valued associations that are eagerly fetched with outer-join SELECTs don't create a product, by nature.
Finally, although Hibernate lets you create Cartesian products with fetch="join" on two (or even more) parallel collections, it throws an exception if you try to enable fetch="join" on parallel <bag> collections. The resultset of a product can't be converted into bag collections, because Hibernate can't know which rows contain duplicates that are valid (bags allow duplicates) and which aren't. If you use bag collections (they are the default @OneToMany collection in Java Persistence), don't enable a fetching strategy that results in products. Use subselects or immediate secondary-select fetching for parallel eager fetching of bag collections.
Global and dynamic fetching strategies help you to solve the n+1 selects and Cartesian product problems. Hibernate offers another option to initialize a proxy or a collection that is sometimes useful.
Forcing proxy and collection initialization
A proxy or collection wrapper is automatically initialized whenever any of its methods are invoked (except for the identifier property getter, which may return the identifier value without fetching the underlying persistent object). Prefetching and eager join fetching are possible solutions to retrieve all the data you'd need.
You sometimes want to work with a network of objects in detached state. You retrieve all objects and collections that should be detached and then close the persistence context.
In this scenario, it's sometimes useful to explicitly initialize an object before closing the persistence context, without resorting to a change in the global fetching strategy or a different query (which we consider the solution you should always prefer).
You can use the static method Hibernate.initialize() for manual initialization of a proxy:
Session session = sessionFactory.openSession(); Transaction tx = session.beginTransaction(); Item item = (Item) session.get(Item.class, new Long(1234)); Hibernate.initialize( item.getSeller() ); tx.commit(); session.close(); processDetached( item.getSeller() ); ...
Hibernate.initialize() may be passed a collection wrapper or a proxy. Note that if you pass a collection wrapper to initialize(), it doesn't initialize the target entity objects that are referenced by this collection. In the previous example, Hibernate.initalize( item.getBids() ) wouldn't load all the Bid objects inside that collection. It initializes the collection with proxies of Bid objects!
Explicit initialization with this static helper method is rarely necessary; you should always prefer a dynamic fetch with HQL or Criteria.
Now that you know all the options, problems, and possibilities, let's walk through a typical application optimization procedure.
Optimization step by step
First, enable the Hibernate SQL log. You should also be prepared to read, understand, and evaluate SQL queries and their performance characteristics for your specific database schema: Will a single outer-join operation be faster than two selects? Are all the indexes used properly, and what is the cache hit-ratio inside the database? Get your DBA to help you with that performance evaluation; only he has the knowledge to decide what SQL execution plan is the best. (If you want to become an expert in this area, we recommend the book SQL Tuning by Dan Tow, [Tow, 2003].)
The two configuration properties hibernate.format_sql and hibernate.use_sql_comments make it a lot easier to read and categorize SQL statements in your log files. Enable both during optimization.
Next, execute use case by use case of your application and note how many and what SQL statements are executed by Hibernate. A use case can be a single screen in your web application or a sequence of user dialogs. This step also involves collecting the object retrieval methods you use in each use case: walking the object links, retrieval by identifier, HQL, and Criteria queries. Your goal is to bring down the number (and complexity) of SQL statements for each use case by tuning the default fetch plan and fetching strategy in metadata.
It's time to define your fetch plan. Everything is lazy loaded by default. Consider switching to lazy="false" (or FetchType.EAGER) on many-to-one, one-to-one, and (sometimes) collection mappings. The global fetch plan defines the objects that are always eagerly loaded. Optimize your queries and enable eager fetching if you need eagerly loaded objects not globally, but in a particular procedure—a use case only.
Once the fetch plan is defined and the amount of data required by a particular use case is known, optimize how this data is retrieved. You may encounter two common issues:
The SQL statements use join operations that are too complex and slow. First optimize the SQL execution plan with your DBA. If this doesn't solve the problem, remove fetch="join" on collection mappings (or don't set it in the first place). Optimize all your many-to-one and one-to-one associations by considering if they really need a fetch="join" strategy or if the associated object should be loaded with a secondary select. Also try to tune with the global hibernate.max_fetch_depth configuration option, but keep in mind that this is best left at a value between 1 and 5.
Too many SQL statements may be executed. Set fetch="join" on many-to-one and one-to-one association mappings. In rare cases, if you're absolutely sure, enable fetch="join" to disable lazy loading for particular collections. Keep in mind that more than one eagerly fetched collection per persistent class creates a product. Evaluate whether your use case can benefit from prefetching of collections, with batches or subselects. Use batch sizes between 3 and 15.
After setting a new fetching strategy, rerun the use case and check the generated SQL again. Note the SQL statements and go to the next use case. After optimizing all use cases, check every one again and see whether any global optimization had side effects for others. With some experience, you'll easily be able to avoid any negative effects and get it right the first time.
This optimization technique is practical for more than the default fetching strategies; you may also use it to tune HQL and Criteria queries, which can define the fetch plan and the fetching strategy dynamically. You often can replace a global fetch setting with a new dynamic query or a change of an existing query—we'll have much more to say about these options in the next chapter.
In the next section, we introduce the Hibernate caching system. Caching data on the application tier is a complementary optimization that you can utilize in any sophisticated multiuser application.