
Chapter 7. Exposing Services to External Clients
In earlier chapters we have explored how network policy is one of the primary tools for securing Kubernetes. This is true for both pod-to-pod traffic within the cluster (east-west traffic) and for traffic between pods and external entities outside of the cluster (north-south traffic). For all of these traffic types the best practice is the same: use network policy to limit which network connections are allowed to the narrowest scope needed, so the only connections that are allowed are the connections you expect and need for your specific applications or microservices to work.
In the case of pods that need to be accessed by external clients outside of the cluster, this means restricting connections:
-
to the specific port(s) that the corresponding microservice is expecting incoming connections to
-
and from the specific clients that need to connect to the microservice.
It’s not uncommon for a particular microservice to be consumed just within the enterprise (whether on-prem or in public cloud) by a limited number of clients. In this case the Kubernetes network policy rules ideally should limit incoming connections to just the IP addresses, or IP address range, associated with the clients. Even if a microservice is being exposed to the public internet (for example, exposing the front-end microservices for a publicly accessible SaaS or web site) then there are still cases where access may need to be restricted to some extent. For example, it may be a requirement to block access from certain geographies for compliance reasons, or it may be desirable to block access from known bad-actors or threat feeds.
Unfortunately, how you go about implementing this best practice needs to include consideration of which network plugins and Kubernetes primitives are used to expose the microservice outside the cluster. In particular, in some cases the original client source IP address is preserved all the way to the pod, which allows Kubernetes network policies to easily limit access to specific clients. In other cases the client source IP gets obscured by NAT associated with network load balancing, or by connection termination associated with application layer load balancing.
In this chapter we will explore different client source IP behaviors available across the three main options for exposing an application or microservice outside of the cluster: direct pod connections, Kubernetes Services, and Kubernetes Ingress.
Understanding direct pod connections
It’s relatively uncommon for pods to be directly accessed by clients outside of the cluster rather than being accessed via a Kubernetes Service or Kubernetes Ingress. However, there are scenarios where this may be desired or required. For example, some types of distributed data stores may require multiple pods each with specific IP addresses that can be configured for data distribution or clients to peer with.
Supporting direct connections to pod IPs from outside of the cluster requires a pod network that makes pod IPs routable beyond the boundary of the cluster. This typically means using either:
-
a cloud provider network plugin in public cloud clusters (e.g. the Amazon VPC CNI plugin, as used by default in EKS)
-
or a network plugin that can use BGP to integrate with an on-prem enterprise network (e.g. kube router, Calico CNI plugin).
In addition to the underlying networking supporting the connectivity, the clients need a way of finding out the pod IP addresses. This may be done via DNS, via explicit configuration of the client, or via some other third part service discovery mechanism.
From a security point of view, connections from clients directly to pods are straightforward: they have the original client source IP address in place all the way to the pod, which means network policy can easily be used to restrict access to clients with particular IP addresses or from particular IP address ranges.
Note though that in any cluster where pod IPs are routable beyond the boundary of the cluster, it becomes even more important to ensure network policy best practices are followed. Without network policy in place, pods that should only be receiving east-west connections could be accessed from outside of the cluster without the need for configuring a corresponding externally accessible Kubernetes Service type or Kubernetes Ingress.
Understanding Kubernetes Services
Kubernetes Services provide a convenient mechanism for accessing pods from outside of the cluster using Services of type Node Port or Load Balancer, or by explicitly configuring an External IP for the Service. By default Kubernetes Services are implemented by kube-proxy. Kube-proxy runs on every node in the cluster and is responsible for intercepting connections to Kubernetes Services and load balancing them across the pods backing the corresponding service. This connection handling has a well defined behavior for when source IP addresses are preserved and when they are not, which we look at now for each service type.
Cluster IP services
Before we dig into exposing pods to external clients using Kubernetes Services, it is worth understanding how Kubernetes Services behave for connections originating from inside the cluster. The primary mechanism for service discovery and load balancing of these connections within the cluster (i.e. pod-to-pod connectivity) makes use of Services of type Cluster IP. For Cluster IP services, kube-proxy is able to use DNAT (Destination Network Address Translation) to map connections to the service’s cluster IP to the pods backing the service. This mapping is reversed for any return packets on the connection. The mapping is done without changing the source IP address, as illustrated in Figure 7-1.

Figure 7-1. Network path for a Kubernetes service advertising Cluster IP
Importantly the destination pod sees the connection from having originated from the IP address of the client pod. This means that any network policy applied to the destination pod behaves as expected and is not impacted by the fact the connection was load balanced via the service’s cluster IP. In addition, any network policy egress rules that apply to the client pod are evaluated after the mapping from cluster IP to destination pod has happened. This means that network policy applied to the client pod also behaves as expected, independent of the fact the connection was load balanced via the service’s cluster IP. (As a reminder, network policy rules match on pods labels, not on service labels.)
Node port services
The most basic way to access a service from outside the cluster is to use a Service of type NodePort. A node port is a port reserved on each node in the cluster through which the service can be accessed. In a typical Kubernetes deployment, kube-proxy is responsible for intercepting connections to Node Ports and load balancing them across the pods backing each service.
As part of this process NAT (Network Address Translation) is used to map the destination IP address and port from the node IP and Node Port, to the chosen backing pod and service port. However, unlike connections to cluster IPs, where the NAT only maps the destination IP address, in the case of node ports the source IP address is also mapped from the client IP to the node IP.
If the source IP address was not mapped in this way then any response packets on the connection would flow directly back to the external client, bypassing the ability for kube-proxy on the original ingress node to reverse the mapping of the destination IP address. (It’s the node which performed the NAT that has the connection tracking state needed to reverse the NAT.) As a result the external client would drop the packets because it would not recognize them as being part of the connection it made to the node port on the original ingress node.
The process is illustrated in Figure 7-2.

Figure 7-2. Network path for a Kubernetes service using node ports
Since the NAT changes the source IP address, any network policy that applies to the destination pod cannot match on the original client IP address. Typically this means that any such policy is limited to restricting the destination protocol and port, and cannot restrict based on the external client’s IP address. This in turn means the best practice of limiting access to the specific clients that need to connect to the microservice cannot easily be implemented with Kubernetes network policy in this configuration.
Fortunately there are a number of solutions which can be used to circumvent the limitations of this default behavior of Node Ports in a variety of different ways:
-
Configuring the Service with
externalTrafficPolicy:local. -
Using a network plugin that supports node-port aware network policy extensions.
-
Using an alternative implementation for service load balancing in place of kube-proxy that preserves client source IP addresses.
We will cover each of these shortly, later in this chapter. But before that, to complete our picture of how the default behavior of mainline Kubernetes services work, let’s look at Services of type Load Balancer.
Load Balancer Services
Services of type LoadBalancer build on the behavior of node ports by integrating with external network load balancers (NLBs). The exact type of network load balancer depends on which public cloud provider or, if on-prem, which specific hardware load balancer integration, is integrated with your cluster.
The service can be accessed from outside of the cluster via a specific IP address on the network load balancer, which by default will load balance evenly across the nodes to the service’s node port.
Most network load balancers are located at a point in the network where return traffic on a connection will always be routed via the network load balancer, and therefore they can implement their load balancing using only DNAT (Destination Network Address Translation) leaving the client source IP address unaltered by the network load balancer, as illustrated in Figure 7-3.

Figure 7-3. Network path for a Kubernetes service of type load balancer
However, because the network load balancer is load balancing to the service’s node port, and kube-proxy’s default node port behavior changes the source IP address as part of its load balancing implementation, the destination pod still cannot match on the original client source IP address. Just like with vanilla node port services, this in turn means the best practice of limiting access to the specific clients that need to connect to the microservice cannot easily be implemented with Kubernetes network policy in this configuration.
Fortunately the same solutions that can be used to circumvent the limitations of the default behavior of services of type NodePort can be used in conjunction with services of type LoadBalancer:
Configuring the Service with externalTrafficPolicy:local.
Using a network plugin that supports node-port aware network policy extensions.
Using an alternative implementation for service load balancing in place of kube-proxy that preserves client source IP addresses.
Let’s look at each of those now.
externalTrafficPolicy:local
By default, the node port associated with a service is available on every node in the cluster, and services of type LoadBalancer load balances to the service’s node port evenly across all of the nodes, independent of which nodes may actually be hosting backing pods for the service. This behavior can be changed by configuring the service with externalTrafficPolicy:local which specifies that connections should only be load balanced to pods backing the service on the local node.
When combined with services of type LoadBalancer, connections to the service are only directed to nodes that host at least one pod backing the service. This reduces the potential extra network hop between nodes associated with kube-proxy’s normal node port handingly. Perhaps more importantly, since each node’s kube-proxy is only load balancing to pods on the same node, kube-proxy does not need to perform SNAT (Source Network Address Translation) as part of the load balancing, meaning that the client source IP address is preserved all the way to the pod. (As a reminder, kube-proxy’s default handling of node ports on the ingress node normally needs to NAT the source IP address so that return traffic flows back via the original ingress node, since that is the node which has the required traffic state to reverse the NAT.)
This is illustrated in Figure 7-4.

Figure 7-4. Network path for a Kubernetes service leveraging the optimization to route to the node backing the pod.
As the original client source IP address is preserved all the way to the backing pod, network policy applied to the backing pod is now able to restrict access to the service to only the specific clients IP addresses or address ranges that need to be able access the service.
Note that, not all load balancers support this mode of operation. So it is important to check whether this is supported by the specific public cloud provider or, if on-prem, the specific hardware load balancer integration, that is integrated with your cluster. The good news is that most of the large public providers do support this mode. Some load balancers can even go a step further, bypassing kube-proxy and load balancing directly to the backing pods without using the node port.
Network policy extensions
Some Kubernetes network plugins provide extensions to the standard Kubernetes network policy capabilities which can be used to help secure access to services from outside of the cluster.
There are many solutions that provide network policy extensions (e.g. Weave Net, Kube Router, Calico). Let’s look at Calico once again, as it’s our area of expertise. Calico includes support for “host endpoints” which allow network policies to be applied to the nodes within a cluster, not just pods within the cluster. Whereas standard Kubernetes network policy can be thought of as providing a virtual firewall within the pod network in front of every pod, Calico’s host endpoint extensions can be thought of as providing a virtual firewall in front of every node/host, as illustrated in this conceptual diagram.

Figure 7-5. Virtual firewall using host endpoint protection
In addition, Calico’s network policy extensions support the ability to specify whether the policy rules applied to host endpoints apply before or after the NAT associated with kube-proxy’s load balancing. This means that they can be used to limit which clients can connect to specific node ports, unencumbered by whatever load balancing decisions kube-proxy may be about to do.
Alternatives to kube-proxy
Kube-proxy provides the default implementation for Kubernetes Services and is included as standard in most clusters. However, some network plugins provide alternative implementations of Kubernetes Services to replace kube-proxy.
For some network plugins, this alternative implementation is necessary because the particular way the plugin implements pod networking is not compatible with kube-proxy’s dataplane (that uses the standard Linux networking pipeline controlled by iptables and/or IPVS). For other network plugins the alternative implementation is optional. For example, a CNI that implements a Linux eBPF dataplane will choose to replace kube-proxy in favor of its natvie service implementation.
Some of these alternative implementations provide additional capabilities beyond kube-proxy’s behavior. One such additional capability that is relevant from a security perspective is the ability to preserve the client source IP address all the way to the back pods when load balancing from external clients.
For example, Figure 7-6 illustrates how an eBPF based dataplane implements this behavior.

Figure 7-6. Network path for a Kubernetes service with an eBPF based implementation
This allows the original client source IP address to be preserved all the way to the packing pod for services of type NodePort or LoadBalancer, without requiring support for externalTrafficPolicy:local in network load balancers or node selection for node ports. This in turn means that network policy applied to the backing pod is able to restrict access to the service to only the specific clients IP addresses or address ranges that need to be able access the service.
Beyond the security considerations, these alternative Kubernetes Services implementations ( e.g. eBPF based dataplanes) provide other advantages over kube-proxy’s implementation, such as:
-
Improved performance when running with very high numbers of services, including reduced first packet latencies and reduced control plane CPU usage.
-
DSR (Direct Server Return) which reduces the number of network hops for return traffic.
We will look at DSR more closely next, since it does have some security implications.
Direct Server Return
DSR allows the return traffic from the destination pod to flow directly back to the client rather than going via the original ingress node. There are several network plugins that are able to replace kube-proxy’s service handling with their own implementations that support DSR. For example, An example eBPF dataplane that includes native service handling and (optionally) can use DSR for return traffic, is illustrated in Figure 7-7.

Figure 7-7. Network path for a Kubernetes service with Direct Server Return (DSR)
Eliminating one network hop for the return traffic reduces:
-
the overall latency for the service (since every network hop introduces latency)
-
the CPU load on the original ingress node (since it is no longer dealing with return traffic)
-
the east-west network traffic within the cluster.
For particularly network intensive or latency sensitive applications, this can be a big win. However, there are also security implications of DSR. In particular, the underlying network may need to be configured with fairly relaxed RPF (Reverse Path Filtering) settings.
RPF is a network routing mechanism that blocks any traffic from a particular source IP address where there is not a corresponding route to that IP address over the same link. I.e. If the router doesn’t have a route that says it can send traffic to a particular IP address over the network link, then it will not allow traffic from that IP address over the network link. RPF makes it harder for attackers to “spoof” IP addresses - i.e. pretending to be a different IP address than the device has been allocated.
In the context of DSR and Kubernetes services, using the example diagram above to illustrate:
-
If the service is being accessed via a node port on Node 1, then the return traffic from Node 2 will have the source IP address of Node 1. So the underlying network must be configured with relaxed RPF settings otherwise the network will filter out the return traffic because the network would not normally route traffic to Node 1 via the network link to Node 2.
-
If the service is being accessed via service IP advertisement (e.g. sending traffic directly to a Service’s cluster IP, external IP, or load balancer IP), then the return traffic from Node 2 will have the source IP address of the service IP. In this case, no relaxation of RPF is required, since the service IP should be being advertised from all nodes in the cluster, meaning that the network will have routes to the service IP via all nodes. We’ll cover service IP advertising in more detail later in this chapter.
As explained above, DSR is an excellent optimization that you can use but you need to review your use case and ensure that you are comfortable with disabling the RPF check
Limiting service external IPs
So far in this chapter we have focussed on how service types and implementations impact how network policy can be used to restrict access to services to only the specific clients IP addresses or address ranges that need to be able access each service.
Another important security consideration is the power associated with users who have permissions to create or configure Kubernetes Services. In particular, any user who has RBAC permissions to modify a Kubernetes Service effectively has control over which pods that service is load balanced to. If used maliciously this could mean the user diverting traffic that was intended for a particular microservice to their own malicious pods.
As Kubernetes Services are namespaces resources, this rarely equates to a genuine security issue for mainline service capabilities. For example, a user who has been granted permissions to define services in a particular namespace will typically also have permission to modify pods in that namespace. So for standard service capabilities such as handling of cluster IPs, node ports, or load balancers, the permissions to define and modify services in the namespace doesn’t really represent any more trust than having permissions to define or modify pods in the namespace.
There is one notable exception though, which is the ability to specify external IPs for services. The externalIP field in a Service definition allows the user to associate an arbitrary IP address with the service. Connections to this IP address received on any node in the cluster are load balanced to the pods backing the service.
The normal use case is to provide an IP oriented alternative to node ports that can be used by external clients to connect to a service. This use case usually requires special handling within the underlying network in order to route connections to the external IP to the nodes in the cluster. This may be achieved by programming static routes into the underlying network, or in a BGP capable network, using BGP to dynamically advertise the external IP. (See next section for more details on advertising service IP addresses.)
Like the mainline service capabilities, this use case is relatively benign in terms of the level of trust for users. It allows them to offer an additional way to reach the pods in the namespaces they have permission to manage, but does not interfere with traffic destined to pods in other namespaces.
However, just like with node ports, connections from pods to external IPs are also intercepted and load balanced to the service backing pods. As Kubernetes does not police or attempt to provide any level of validation on external IP addresses. This means a malicious user can effectively intercept traffic to any IP address, without any namespace or other scope restrictions. This is an extremely powerful tool for a malicious user and represents a correspondingly large security risk.
If you are following the best practice of having default deny style policies for both ingress and egress traffic that apply across all pods in the cluster, then this significantly hampers the malicious user’s attempt to get access to traffic that should have been between two other pods. However, although the network policy will stop them from accessing the traffic, it doesn’t stop the service load balancing from diverting the traffic from its intended destination, which means that the malicious user can effectively block traffic between any two pods even though they cannot receive the traffic themselves.
So in addition to following network policy best practices, it is recommended to use an admission controller to restrict which users can specify or modify the externalIP field. For users who are allowed to specify external IP addresses, it may also be desirable to restrict the IP address values to a specific IP address range which is deemed safe (i.e a range that is not being used for any other purpose). For more discussion of admission controllers, see the Managing Trust Across teams chapter.
Advertising service IPs
One alternative to using node ports or network load balancers is to advertise service IP addresses over BGP. This requires the cluster to be running on an underlying network that supports BGP, which typically means an on-prem deployment with standard Top of Rack routers.
For example, Calico supports advertising the service clusterIP, loadBalancerIP, or externalIP for services configured with one. If you are not using Calico as your network plugin then MetalLB provides similar capabilities that work with a variety of different network plugins.
Advertising service IPs effectively allows the underlying network routers to act as load balancers, without the need for an actual network load balancer.
The security considerations for advertising service IPs are equivalent to those of normal node port or load balancer based services discussed earlier in this chapter. When using kube-proxy the original client IP address is obscured by default, as illustrated in the following diagram.

Figure 7-8. Network path for a Kubernetes service advertising Cluster IP via BGP
This behavior can be changed using externalTrafficPolicy:local, which (at the time of writing) is supported by kube-proxy for both loadBalancerIP and extenalIP addresses but not clusterIP addresses. However, it should be noted that when using externalTrafficPolicy:local, the evenness of the load balancing becomes topology dependent. To circumvent this, pod anti-affinity rules can be used to ensure even distribution of backing pods across your topology, but this does add some complexity to deploying the service.
Alternatively, a network plugin with native service handling (replacing kube-proxy) that supports source IP address preservation can be used. This combination can be very appealing for on-prem deployments due to its operational simplicity and removal of the need to build network load balancer appliances into the network topology.
Understanding Kubernetes Ingress
Kubernetes Ingress builds on top of Kubernetes Services to provide load balancing at the application layer, mapping HTTP and HTTPS requests with particular domains or URLs to Kubernetes Services. Kubernetes Ingress can be a convenient way of exposing multiple microservices via a single external point of contact, if for example multiple microservices make up a single web application. In addition, they can be used to terminate SSL / TLS (for receiving HTTPS encrypted connections from external clients) before load balancing to the backing microservices.
The details of how Kubernetes Ingress is implemented depend on which Ingress Controller you are using. The Ingress Controller is responsible for monitoring Kubernetes Ingress resources and provisioning / configuring one or more ingress load balancers to implement the desired load balancing behavior.
Unlike Kubernetes services, which are handled at the network layer (L3-4), ingress load balancers operate at the application layer (L5-7). Incoming connections are terminated at the load balancer so it can inspect the individual HTTP / HTTPS requests. The requests are then forwarded via separate connections from the load balancer to the chosen service. As a result, network policy applied to the pods backing a service sees the ingress load balancer as the client source IP address, rather than the original external client IP address. This means they can restrict access to only allow connections from the load balancer, but cannot restrict access to specific external clients.
To restrict access to specific external clients, the access control needs to be enforced either within the application load balancer, or in front of the application load balancer. In case you choose an IP based access control it needs to happen before the traffic is forwarded to the backing services. How you do this depends on the specific Ingress Controller you are using.
Broadly speaking there are two types of ingress solutions:
- In-cluster ingress
-
Where ingress load balancing is performed by pods within the cluster itself.
- External ingress
-
Where ingress load balancing is implemented outside of the cluster by appliances or cloud provider capabilities.
Now that we have covered Kubernetes ingress, let’s review ingress solutions.
In-cluster ingress solutions
In-cluster ingress solutions use software application load balancers running in pods within the cluster itself. There are many different Ingress Controllers that follow this pattern. For example, the NGINX Ingress Controller, which instantiates and configures NGINX pods to act as application load balancers.
The advantages of in-cluster ingress solutions are that:
-
You can horizontally scale your Ingress solution up to the limits of Kubernetes.
-
There are many different in-cluster Ingress Controller solutions, so you can choose the Ingress Controller that best suits your specific needs. For example, with particular load balancing algorithms, security options, or observability capabilities.
To get your ingress traffic to the in-cluster Ingress pods, the Ingress pods are normally exposed externally as a Kubernetes Service, as illustrated in the following conceptual diagram.
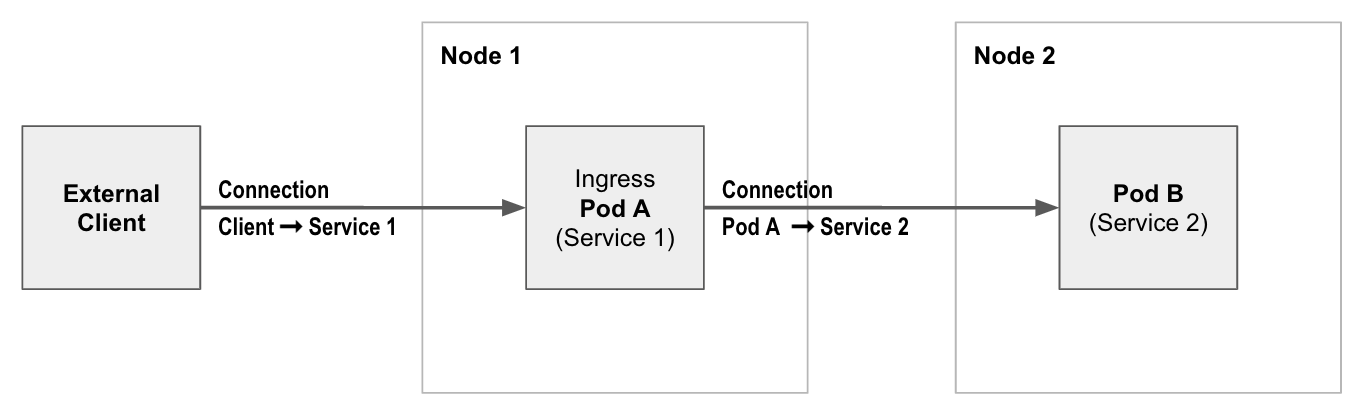
Figure 7-9. An example of an in cluster ingress implementation in a Kuebernetes cluster
This means you can use any of the standard ways of accessing the service from outside of the cluster. One common approach is to use an external network load balancer or service IP advertisement, along with either:
-
a network plugin with native Kubernetes Service handling that always preserves the original client source IP
-
or using
exterrnalTrafficPolicy:local(and pod anti-affinity rules to ensure even load balancing across the ingress pods) to preserve the original client source IP.
Network policy applied to the ingress pods can then restrict access to specific external clients as described earlier in this chapter, and the pods backing any microservices being exposed via Ingress can restrict connections to just those from the ingress pods.
External ingress solutions
External ingress solutions use application load balancers outside of the cluster, as illustrated in the following conceptual diagram.

Figure 7-10. An example of an external ingress in a Kuebernetes cluster
The exact details and features depend on which Ingress Controller you are using. Most public cloud providers have their own Ingress Controllers that automate the provisioning and management of the cloud provider’s application load balancers to provide ingress.
Most application load balancers support a basic mode of operation of forwarding traffic to the chosen service backing pods via the node port of the corresponding service. In addition to this basic approach of load balancing to service node ports, some cloud providers support a second mode of application load balancing that load balances directly to the pods backing each service, without going via node-ports or other kube-proxy service handling. This has the advantage of eliminating the potential second network hop associated with node ports load balancing to a pod on a different node.
The main advantage of an external ingress solution is that the cloud provider handles the operational complexity of the ingress for you. The potential downsides are
-
The set of features available is usually more limited compared to the rich range of available in-cluster ingress solutions. For example, if you require a specific load balancing algorithm, or security controls, or observability capabilities, these may or may not be supported by the cloud provider’s implementation
-
The maximum supported number of services (and potentially the number of pods backing the services) is constrained by cloud provider specific limits. For example, if you are operating at very high scales, for example with hundreds of pods backing a service, you may exceed the application layer load balancer’s maximum limit of IPs it can load balance to in this mode. In this case switching to an in-cluster ingress solution is likely the better fit for you.
-
Since the application load balancer is not hosted within the Kubernetes cluster, if you need to restrict access to specific external clients, you cannot use Kubernetes network policy and instead must use the cloud provider’s specific mechanisms. It is still possible to follow the best practices laid out at the start of this chapter, but doing so will be cloud provider specific and will likely introduce a little additional operational complexity compared to being able to use native Kubernetes capabilities independent of the cloud provider capabilities and APIs.
In this section we covered how Kubernetes ingress works and the solutions available. We recommend you review the sections above and decide if the in-cluster ingress solution works for you or you should go with an external ingress solution.
Conclusion
In this chapter, we covered the topic of exposing Kubernetes services outside the cluster. The following are the key concepts covered in this chapter:
-
Kubernetes Services concepts like direct pod connections, advertising service IPs and node ports are techniques you can leverage to expose Kubernetes services outside the cluster
-
We recommend using a eBPF based dataplane to optimize the ingress path to route traffic to the pods hosting the service backend.
-
An eBPF dataplane is an excellent alternative to the default Kubernetes services implementation, kube-proxy due to its capability to preserve source IP to the pod.
-
The choice of a Kubernetes ingress implementation will depend on your use case, we recommend that you consider an in-cluster ingress solution as it is more natvie to Kubernetes and will give you more control as opposed to using an external ingress solution
We hope you are able to leverage these concepts based on your use case as you implement Kubernetes services.