
1 What is a machine learning engineer?
- The scope of knowledge and skills for machine learning engineers
- The six fundamental aspects of applied machine learning project work
- The functional purpose of machine learning engineers
Machine learning (ML) is exciting. It’s fun, challenging, creative, and intellectually stimulating. It also makes money for companies, autonomously tackles overwhelmingly large tasks, and removes the burdensome task of monotonous work from people who would rather be doing something else.
ML is also ludicrously complex. From thousands of algorithms, hundreds of open source packages, and a profession of practitioners required to have a diverse skill set ranging from data engineering (DE) to advanced statistical analysis and visualization, the work required of a professional practitioner of ML is truly intimidating. Adding to that complexity is the need to be able to work cross-functionally with a wide array of specialists, subject-matter experts (SMEs), and business unit groups—communicating and collaborating on both the nature of the problem being solved and the output of the ML-backed solution.
ML engineering applies a system around this staggering level of complexity. It uses a set of standards, tools, processes, and methodology that aims to minimize the chances of abandoned, misguided, or irrelevant work being done in an effort to solve a business problem or need. It, in essence, is the road map to creating ML-based systems that can be not only deployed to production, but also maintained and updated for years in the future, allowing businesses to reap the rewards in efficiency, profitability, and accuracy that ML in general has proven to provide (when done correctly).
This book is, at its essence, that very road map. It’s a guide to help you navigate the path of developing production-capable ML solutions. Figure 1.1 shows the major elements of ML project work covered throughout this book. We’ll move through these proven sets of processes (mostly a “lessons learned” from things I’ve screwed up in my career) to give a framework for solving business problems through the application of ML.

Figure 1.1 The ML engineering road map for project work
This path for project work is not meant to focus solely on the tasks that should be done at each phase. Rather, it is the methodology within each stage (the “why are we doing this” element) that enables successful project work.
The end goal of ML work is, after all, about solving a problem. The most effective way to solve those business problems that we’re all tasked with as data science (DS) practitioners is to follow a process designed around preventing rework, confusion, and complexity. By embracing the concepts of ML engineering and following the road of effective project work, the end goal of getting a useful modeling solution can be shorter, far cheaper, and have a much higher probability of succeeding than if you just wing it and hope for the best.
1.1 Why ML engineering?
To put it most simply, ML is hard. It’s even harder to do correctly in the sense of serving relevant predictions, at scale, with reliable frequency. With so many specialties existing in the field—such as natural language processing (NLP), forecasting, deep learning, and traditional linear and tree-based modeling—an enormous focus on active research, and so many algorithms that have been built to solve specific problems, it’s remarkably challenging to learn even slightly more than an insignificant fraction of all there is to learn about the field. Understanding the theoretical and practical aspects of applied ML is challenging and time-consuming.
However, none of that knowledge helps in building interfaces between the model solution and the outside world. Nor does it help inform development patterns that ensure maintainable and extensible solutions.
Data scientists are also expected to be familiar with additional realms of competency. From mid-level DE skills (you have to get your data for your data science from somewhere, right?), software development skills, project management skills, visualization skills, and presentation skills, the list grows ever longer, and the volumes of experience that need to be gained become rather daunting. It’s not much of a surprise, considering all of this, that “just figuring it out” in reference to all the required skills to create production-grade ML solutions is untenable.
The aim of ML engineering is not to iterate through the lists of skills just mentioned and require that a data scientist (DS) master each of them. Instead, ML engineering collects certain aspects of those skills, carefully crafted to be relevant to data scientists, all with the goal of increasing the chances of getting an ML project into production and making sure that it’s not a solution that needs constant maintenance and intervention to keep running.
ML engineers, after all, don’t need to be able to create applications and software frameworks for generic algorithmic use cases. They’re also not likely to be writing their own large-scale streaming ingestion extract, transform, and load (ETL) pipelines. They similarly don’t need to be able to create detailed and animated frontend visualizations in JavaScript.
ML engineers need to know just enough software development skills to be able to write modular code and implement unit tests. The don’t need to know about the intricacies of non-blocking asynchronous messaging brokering. They need just enough data engineering skills to build (and schedule the ETL for) feature datasets for their models, but not to construct a petabyte-scale streaming ingestion framework. They need just enough visualization skills to create plots and charts that communicate clearly what their research and models are doing, but not to develop dynamic web apps that have complex user-experience (UX) components. They also need just enough project management experience to know how to properly define, scope, and control a project to solve a problem, but need not go through a Project Management Professional (PMP) certification.
A giant elephant remains in the room when it comes to ML. Specifically, why—with so many companies going all in on ML, hiring massive teams of highly compensated data scientists, and devoting enormous amounts of financial and temporal resources to projects—do so many endeavors end up failing? Figure 1.2 depicts rough estimates of what I’ve come to see as the six primary reasons projects fail (and the rates of these failures in any given industry, from my experience, are truly surprising).

Figure 1.2 My estimation of why ML projects fail, from the hundreds I’ve worked on and advised others on
Throughout this first part of the book, we’ll discuss how to identify the reasons so many projects fail, are abandoned, or take far longer than they should to reach production. We’ll also discuss the solutions to each of these common failures and cover the processes that can significantly lower the chances of these factors derailing your projects.
Generally, these failures happen because the DS team is either inexperienced with solving a problem of the scale required (a technological or process-driven failure) or hasn’t fully understood the desired outcome from the business (a communication-driven failure). I’ve never seen this happen because of malicious intent. Rather, most ML projects are incredibly challenging, complex, and composed of algorithmic software tooling that is hard to explain to a layperson—hence the breakdowns in communication with business units that most projects endure.
Adding to the complexity of ML projects are two other critical elements that are not shared by (most) traditional software development projects: a frequent lack of detail in project expectations and the relative industry immaturity in tooling. Both aspects are no different from the state of software engineering in the early 1990s. Businesses then were unsure of how to best leverage new aspects of technological capability, tooling was woefully underdeveloped, and many projects failed to meet the expectations of those who were commissioning engineering teams to build them. ML work is (from my biased view of working with only so many companies) at the same place now in the second decade of the 21st century that software engineering was 30 years ago.
This book isn’t a doom-riddled treatise on the challenges of ML; rather, it’s meant to show how these elements can be a risk for projects. The intent is to teach the processes and tools that help minimize this failure risk. Figure 1.3 shows an overview of the detours that can arise in the execution of a project; each brings a different element of risk to a project’s successful execution.
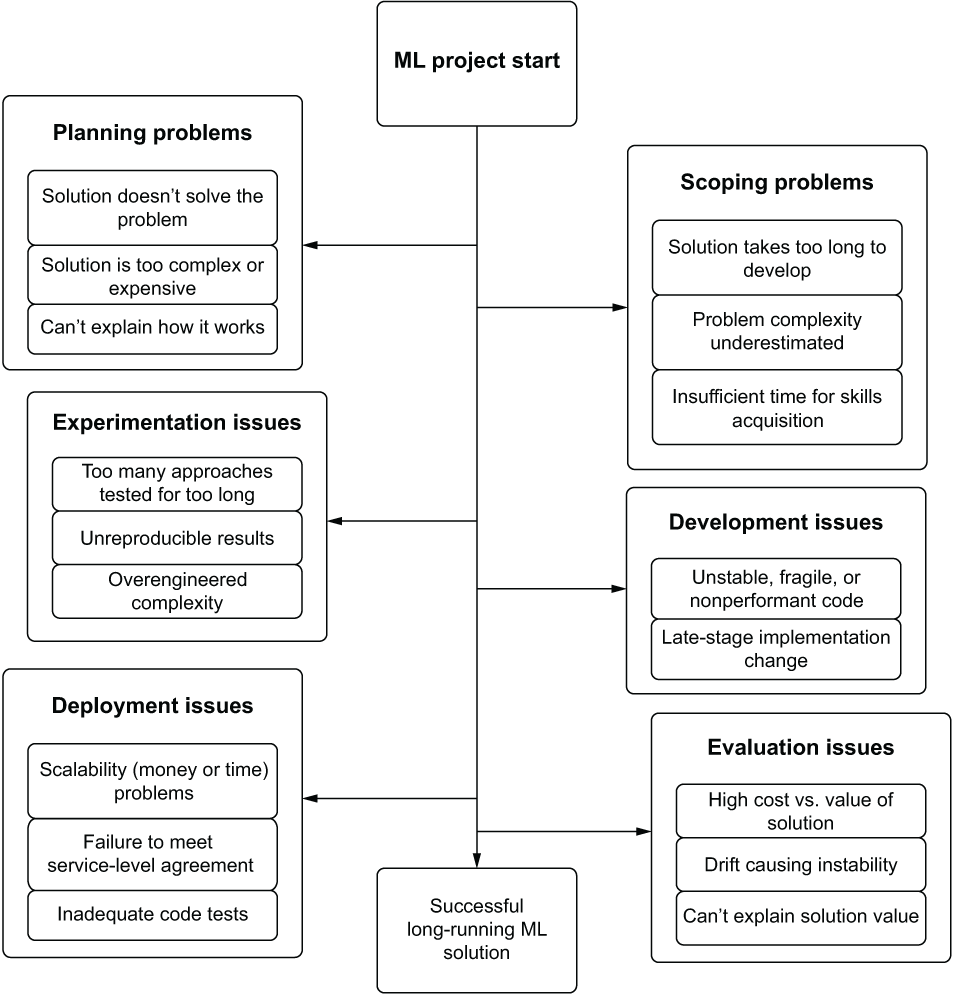
Figure 1.3 ML project detours that lead to project failure
The framework used in ML engineering is exactly dedicated to address each of these primary failure modes. Eliminating these chances of failure is at the heart of this methodology. It is done by providing the processes to make better decisions, ease communication with internal customers, eliminate rework during the experimentation and development phases, create code bases that can be easily maintained, and bring a best-practices approach to any project that is heavily influenced by DS work. Just as software engineers decades ago refined their processes from large-scale waterfall implementations to a more flexible and productive Agile process, ML engineering seeks to define a new set of practices and tools that will optimize the wholly unique realm of software development for data scientists.
1.2 The core tenets of ML engineering
Now that you have a general idea of what ML engineering is, we can focus in a bit on the key elements that make up those incredibly broad categories from figure 1.2. Each of these topics is the focus of entire chapter-length in-depth discussions later in this book, but for now we’re going to look at them in a holistic sense by way of potentially painfully familiar scenarios to elucidate why they’re so important.
1.2.1 Planning
Nothing is more demoralizing than building an ML solution that solves the wrong problem.
By far the largest cause of project failures, failing to plan out a project thoroughly, is one of the most demoralizing ways for a project to be cancelled. Imagine for a moment that you’re the first-hired DS for a company. On your first week, an executive from marketing approaches you, explaining (in their terms) a serious business issue that they are having. They need to figure out an efficient means of communicating to customers through email to let them know of upcoming sales that they might be interested in. With very little additional detail provided to you, the executive merely says, “I want to see the click and open rates go up on our emails.”
If this is the only information supplied, and repeated queries to members of the marketing team simply state the same end goal of increasing the clicking and opening rate, the number of avenues to pursue seems limitless. Left to your own devices, do you
- Focus on content recommendation and craft custom emails for each user?
- Provide predictions with an NLP-backed system that will craft relevant subject lines for each user?
- Attempt to predict a list of products most relevant to the customer base to put on sale each day?
With so many options of varying complexity and approaches, and little guidance, creating a solution that is aligned with the expectations of the executive is highly unlikely. Instead, if a proper planning discussion delved into the correct amount of detail, avoiding the complexity of the ML side of things, the true expectation might be revealed. You’d then know that the only expectation is a prediction for when each user would most likely be open to reading email. The executive simply wants to know when someone is most likely to not be at work, commuting, or sleeping so that the company can send batches of emails throughout the day to different cohorts of customers.
The sad reality is that many ML projects start off in this way. Frequently, little communication occurs with regards to project initiation, and the general expectation is that the DS team will just figure it out. However, without the proper guidance on what needs to be built, how it needs to function, and what the end goal of the predictions is, the project is almost certainly doomed to failure.
After all, what would have happened if an entire content recommendation system were built for that use case, with months of development and effort wasted, when a simple analytics query based on IP address geolocation was what was really needed? The project would not only be cancelled, but many questions would likely come from on high as to why this system was built and why its development costed so much.
Let’s look at the simplified planning discussion illustrated in figure 1.4. Even at the initial phase of discussion, we can see how just a few careful questions and clear answers can provide the one thing every data scientist should be looking for in this situation (especially as the first DS at a company working on the first problem): a quick win.
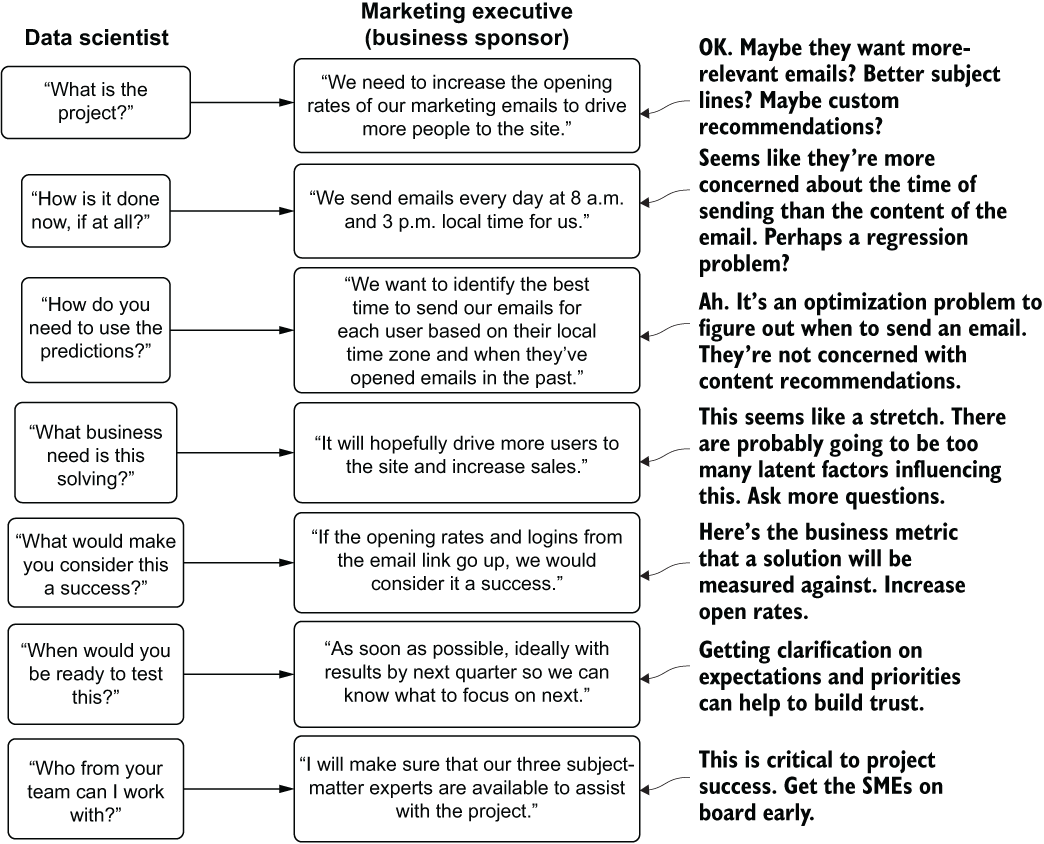
Figure 1.4 A simplified planning discussion diagram
As you can see from the DS’s internal monologue shown at the right, the problem at hand is not at all in the list of original assumptions that were made. There is no talk of email content, relevancy to the subject line, or the items in the email. It’s a simple analytical query to figure out which time zone customers are in and to analyze historic opening in local times for each customer. By taking a few minutes to plan and understand the use case fully, weeks (if not months) of wasted effort, time, and money were saved.
By focusing on what will be built and why it needs to be built, both the DS team and the business are able to guide the discussion more fruitfully. Eschewing a conversation focused on how it will be built keeps the DS members of the group focused on the problem. Ignoring when it will be built by helps the business keep its focus aligned on the needs of the project.
Avoiding discussing implementation details at this stage of the project is not merely critical for the team to focus on the problem. Keeping the esoteric details of algorithms and solution design out of discussions with the larger team keeps the business unit members engaged. After all, they really don’t care how many eggs go into the mix, what color the eggs are, or even what species laid the eggs; they just want to eat the cake when it’s done. We will cover the processes of planning, having project expectation discussions with internal business customers, and general communications about ML work with a nontechnical audience at length and in much greater depth throughout the remainder of part 1.
1.2.2 Scoping and research
If you switch your approach halfway through development, you’ll face a hard conversation with the business to explain that the project’s delays are due to you not doing your homework.
After all, there are only two questions that your internal customers (the business unit) have about the project:
Let’s take a look at another potentially familiar scenario to discuss polar opposite ways that this stage of ML project development can go awry. Say we have two DS teams at a company, each being pitted against the other to develop a solution to an escalating incidence of fraud being conducted with the company’s billing system. Team A’s research and scoping process is illustrated in figure 1.5.

Figure 1.5 Research and scoping of a fraud-detection problem for a junior team of well-intentioned but inexperienced data scientists
Team A comprises mostly junior data scientists, all of whom entered the workforce without an extensive period in academia. Their actions, upon getting the details of the project and the expectations of them, is to immediately go to blog posts. They search the internet for “detecting payment fraud” and “fraud algorithms,” finding hundreds of results from consultancy companies, a few extremely high-level blog posts from similar junior data scientists who have likely never put a model into production, and some rudimentary open source data examples.
Team B, in contrast, is filled with a group of PhD academic researchers. Their research and scoping is shown in figure 1.6.

Figure 1.6 Research and scoping for an academia-focused group of researchers for the fraud-detection problem
With Team B’s studious approach to research and vetting of ideas, the first actions are to dig into published papers on the topic of fraud modeling. Spending several days reading through journals and papers, these team members are now armed with a large collection of theory encompassing some of the most cutting-edge research being done on detecting fraudulent activity.
If we were to ask either team to estimate the level of effort required to produce a solution, we would get wildly divergent answers. Team A would likely estimate about two weeks to build its XGBoost binary classification model, while team B would tell a vastly different tale. Those team members would estimate several months for implementing, training, and evaluating the novel deep learning structure that they found in a highly regarded whitepaper whose proven accuracy for the research was significantly better than any Perforce-implemented algorithm for this use case.
The problem here with scoping and research is that these two polar opposites would both have their projects fail for two completely different reasons. Team A would fail because the solution to the problem is significantly more complex than the example shown in the blog post (the class imbalance issue alone is too challenging of a topic to effectively document in the short space of a blog). Team B, even though its solution would likely be extremely accurate, would never be allocated resources to build the risky solution as an initial fraud-detection service at the company.
Project scoping for ML is incredibly challenging. Even for the most seasoned of ML veterans, conjecturing how long a project will take, which approach is going to be most successful, and the amount of resources required is a futile and frustrating exercise. The risk associated with making erroneous claims is fairly high, but structuring proper scoping and solution research can help minimize the chances of being wildly off on estimation.
Most companies have a mix of the types of people in this hyperbolic scenario. Some are academics whose sole goal is to further the advancement of knowledge and research into algorithms, paving the way for future discoveries from within the industry. Others are “applications of ML” engineers who just want to use ML as a tool to solve a business problem. It’s important to embrace and balance both aspects of these philosophies toward ML work, strike a compromise during the research and scoping phase of a project, and know that the middle ground here is the best path to trod upon to ensure that a project actually makes it to production.
1.2.3 Experimentation
Testing approaches is a Goldilocks activity; if you don’t test enough options, you’re probably not finding the best solution, while testing too many things wastes precious time. Find the middle ground.
In the experimentation phase, the largest causes of project failure are either the experimentation taking too long (testing too many things or spending too long fine-tuning an approach) or an underdeveloped prototype that is so abysmally bad that the business decides to move on to something else.
Let’s use a similar example from section 1.2.2 to illustrate how these two approaches might play out at a company that is looking to build an image classifier for detecting products on retail store shelves. The experimentation paths that the two groups take (showing the extreme opposites of experimentation) are shown in figures 1.7 and 1.8.
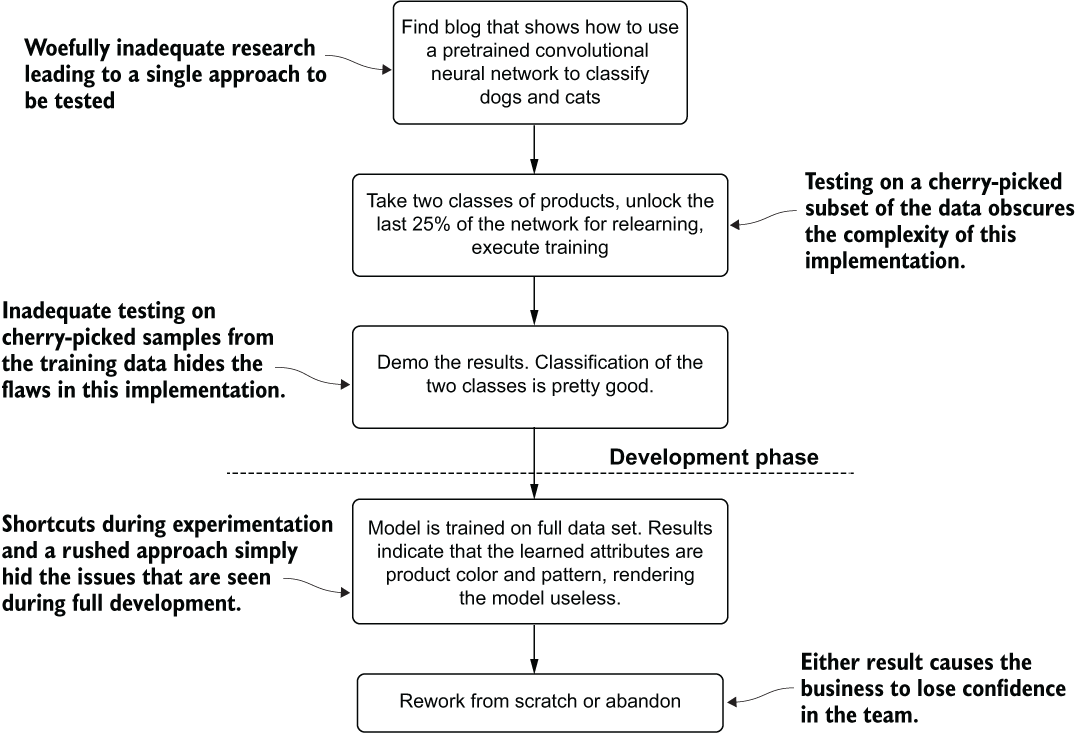
Figure 1.7 A rushed experimentation phase by a team of inexperienced data scientists
Team A embodies the example of wholly inadequate research and experimentation in the early phases of a project. A project that glosses over these critical stages of solution development runs the risk, as shown in figure 1.7, of having a result that is so woefully underdeveloped that it becomes irrelevant to the business. Projects like these erode the business’s faith in the DS team, waste money, and needlessly expend precious resources of several groups.
These inexperienced DS team members, performing only the most cursory of research, adapt a basic demo from a blog post. While their basic testing shows promise, they fail to thoroughly research the implementation details required for employing the model on their data. By retraining the pretrained model on only a few hundred images of two of the many thousands of products from their corpus of images, their misleading results hide the problem with their approach.
This is the exact opposite situation to that of the other team. Team B’s approach to this problem is shown in figure 1.8.

Figure 1.8 A case of too much testing in the experimentation phase of a project
Team B’s approach to solving this problem is to spend weeks searching through cutting-edge papers, reading journals, and understanding the theory involved in various convolutional neural network (CNN) and generative adversarial network (GAN) approaches. They settle on three broad potential solutions, each consisting of several tests that need to run and be evaluated against the entire collection of their training image dataset.
It isn’t the depth of research that fails them in this case, as it does for the other group. Team B’s research is appropriate for this use case. The team members have an issue with their minimum viable product (MVP) because they are trying too many things in too much depth. Varying the structure and depth of a custom-built CNN requires dozens (if not hundreds) of iterations to get right for the use case that they’re trying to solve. This work should be scoped into the development stage of the project, not during evaluation, after a single approach is selected based on early results.
While not the leading cause of project failure, an incorrectly implemented experimentation phase can stall or cancel an otherwise great project. Neither of these two extreme examples is appropriate, and the best course of action is a moderate approach between the two.
1.2.4 Development
No one thinks that code quality matters until it’s 4 a.m. on a Saturday, you’re 18 hours into debugging a failure, and you still haven’t fixed the bug.
Having a poor development practice for ML projects can manifest itself in a multitude of ways that can completely kill a project. Though usually not as directly visible as some of the other leading causes, having a fragile and poorly designed code base and poor development practices can make a project harder to work on, easier to break in production, and far harder to improve as time goes on.
For instance, let’s look at a rather simple and frequent modification situation that comes up during the development of a modeling solution: changes to the feature engineering. In figure 1.9, we see two data scientists attempting to make a set of changes in a monolithic code base. In this development paradigm, all the logic for the entire job is written in a single notebook through scripted variable declarations and functions.
Julie, in the monolithic code base, will likely have a lot of searching and scrolling to do, finding each individual location where the feature vector is defined and adding her new fields to collections. Her encoding work will need to be correct and carried throughout the script in the correct places as well. It’s a daunting amount of work for any sufficiently complex ML code base (as the number of code lines for feature engineering and modeling combined can reach to the thousands if developed in a scripting paradigm) and is prone to frustrating errors in the form of omissions, typos, and other transcription mistakes.
Joe, meanwhile, has far fewer edits to do. But he is still subject to the act of searching through the long code base and relying on editing the hardcoded values correctly.
The real problem with the monolithic approach comes when they try to incorporate each of their changes into a single copy of the script. As they have mutual dependencies on each other’s work, both will have to update their code and select one of their copies to serve as a master for the project, copying in the changes from the other’s work. This long and arduous process wastes precious development time and likely will require a great deal of debugging to get correct.
Figure 1.10 shows a different approach to maintaining an ML project’s code base. This time, a modularized code architecture separates the tight coupling that is present within the large script from figure 1.9.
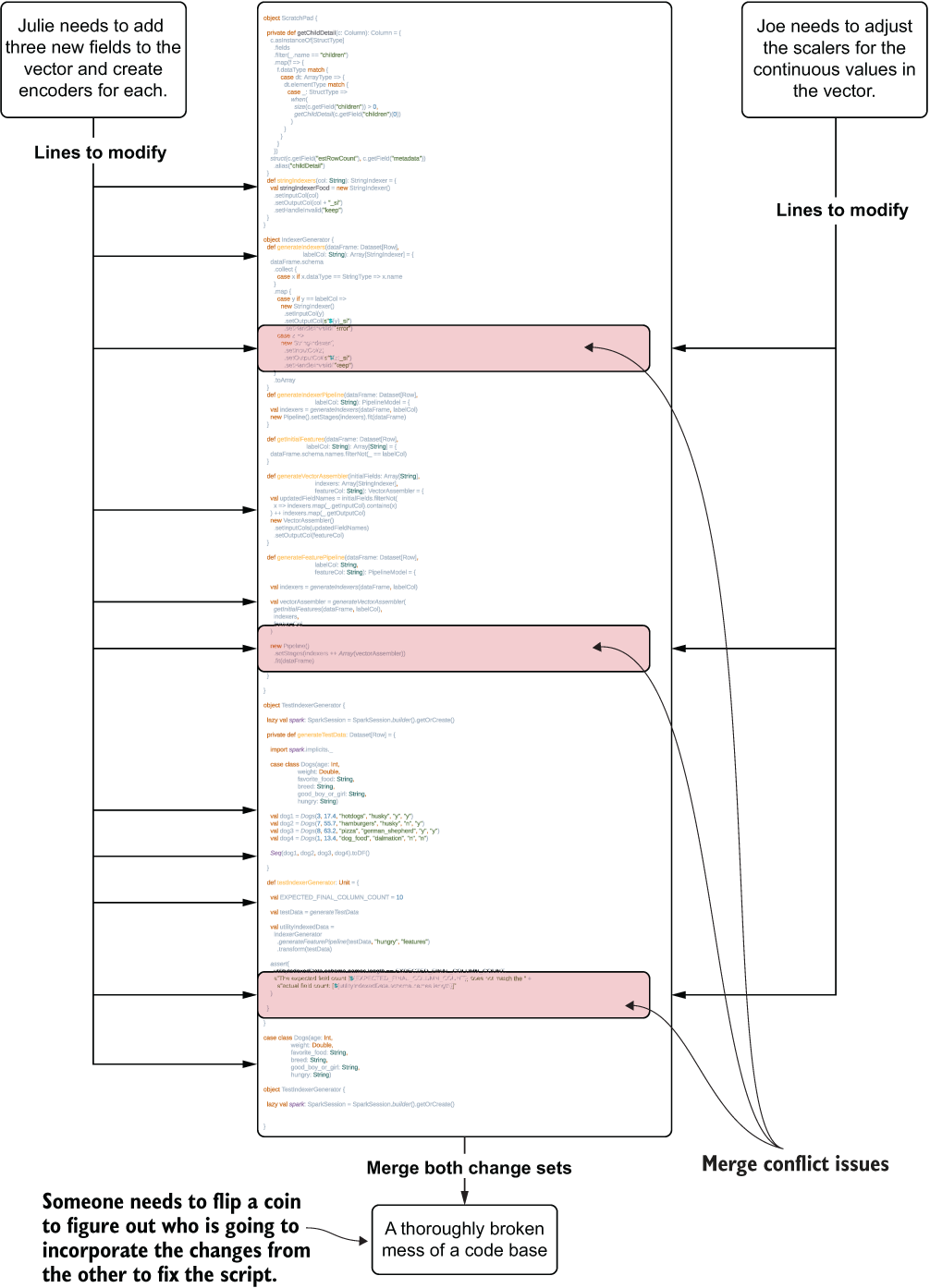
Figure 1.9 Editing a monolithic code base (a script) for ML project work
This modularized code base is written in an integrated development environment (IDE). While the changes being made by the two DSs are identical in their nature to those being made in figure 1.9 (Julie is adding a few fields to the feature vector and updating encodings for these new fields, while Joe is updating the scaler used on the feature vector), the amount of effort and time spent getting these changes working in concert with one another is dramatically different.
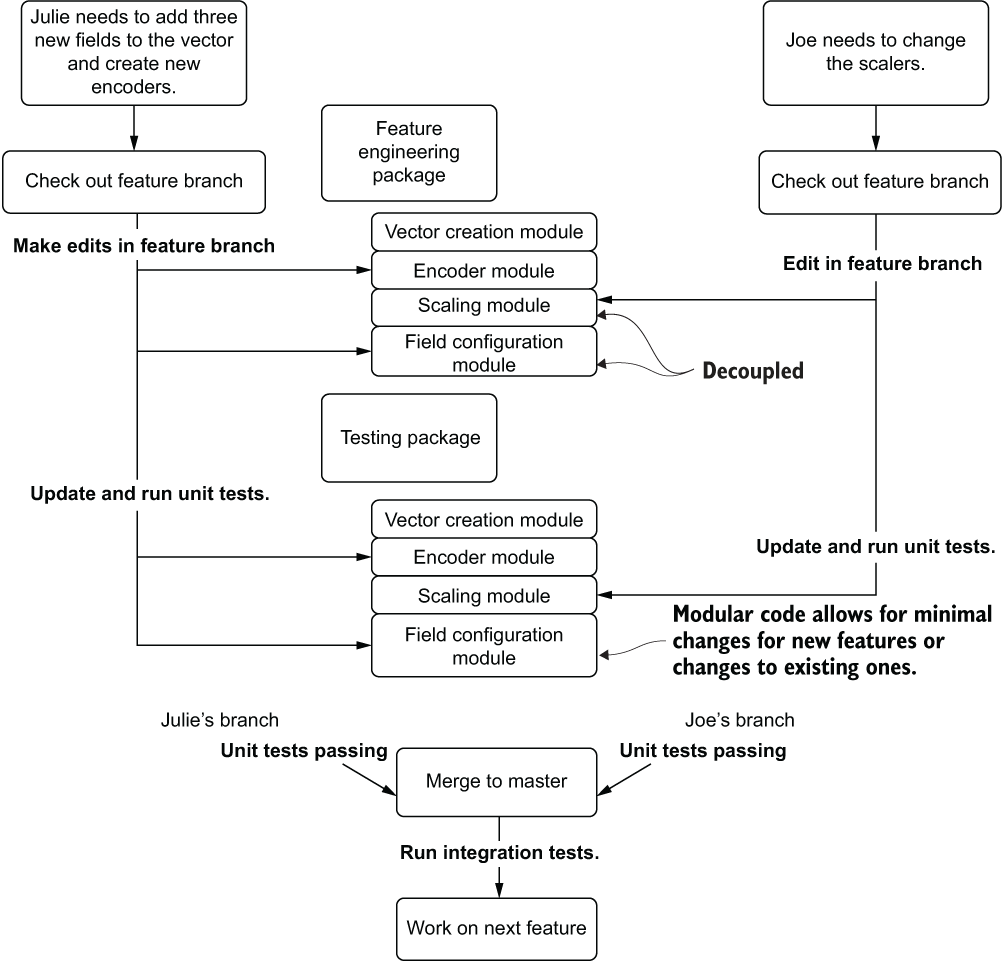
Figure 1.10 Updating a modular ML code base to prevent rework and merge conflicts
With a fully modularized code base registered in Git, each of them can check out a feature branch from the master, make small edits to the modules that are part of their features, write new tests (if needed), run their tests, and submit a pull request. Once their work is complete—because of the configuration-based code and the capability of the methods in each module class to act upon the data for their project through leveraging the job configuration—each feature branch will not impact the other and should just work as designed. Julie and Joe can cut a release branch of both of their changes in a single build, run a full integration test, and safely merge to the master, confident that their work is correct. They can, in effect, work efficiently together on the same code base, greatly minimizing the chance of errors and reducing the amount of time spent debugging code.
1.2.5 Deployment
Not planning a project around a deployment strategy is like having a dinner party without knowing how many guests are showing up. You’ll either be wasting money or ruining experiences.
Perhaps the most confusing and complex part of ML project work for newer teams is in how to build a cost-effective deployment strategy. If it’s underpowered, the prediction quality doesn’t matter (since the infrastructure can’t properly serve the predictions). If it’s overpowered, you’re effectively burning money on unused infrastructure and complexity.
As an example, let’s look at an inventory optimization problem for a fast-food company. The DS team has been fairly successful in serving predictions for inventory management at region-level groupings for years, running large batch predictions for the per-day demands of expected customer counts at a weekly level, and submitting forecasts as bulk extracts each week. Up until this point, the DS team has been accustomed to an ML architecture that effectively looks like that shown in figure 1.11.
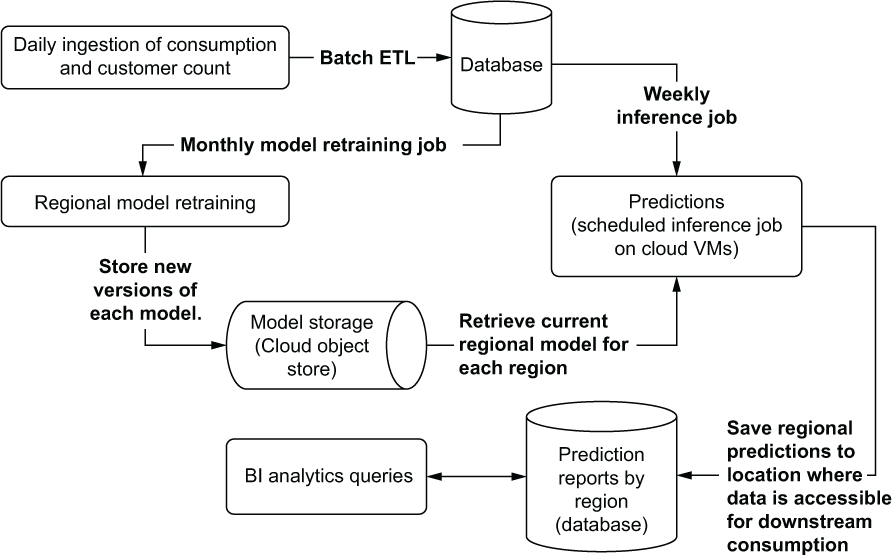
Figure 1.11 A basic batch-prediction-serving architecture
This relatively standard architecture for serving up scheduled batch predictions focuses on exposing results to internal analytics personnel who provide guidance on quantities of materials to order. This prediction-serving architecture isn’t particularly complex and is a paradigm that the DS team members are familiar with. With the scheduled synchronous nature of the design, as well as the large amounts of time between subsequent retraining and inference, the general sophistication of their technology stack doesn’t have to be particularly high (which is a good thing; see the following sidebar).
As the company realizes the benefits of predictive modeling over time with these batch approaches, its faith in the DS team increases. When a new business opportunity arises that requires near-real-time inventory forecasting at a per-store level, company executives ask the DS team to provide a solution for this use case.
The ML team members understand that their standard prediction-serving architecture won’t work for this project. They need to build a REST application programming interface (API) to the forecasted data to support the request volume and prediction updating frequency. To adapt to the granular level of a per-store inventory prediction (and the volatility involved in that), the team knows that they need to regenerate predictions frequently throughout the day. Armed with these requirements, they enlist the help of some software engineers at the company and build out the solution.
It isn’t until after the first week of going live that the business realizes that the implementation’s cloud computing costs are more than an order of magnitude higher than the cost savings seen from the more-efficient inventory management system. The new architecture, coupled with autoregressive integrated moving average (ARIMA) models needed to solve the problem, is shown in figure 1.12.
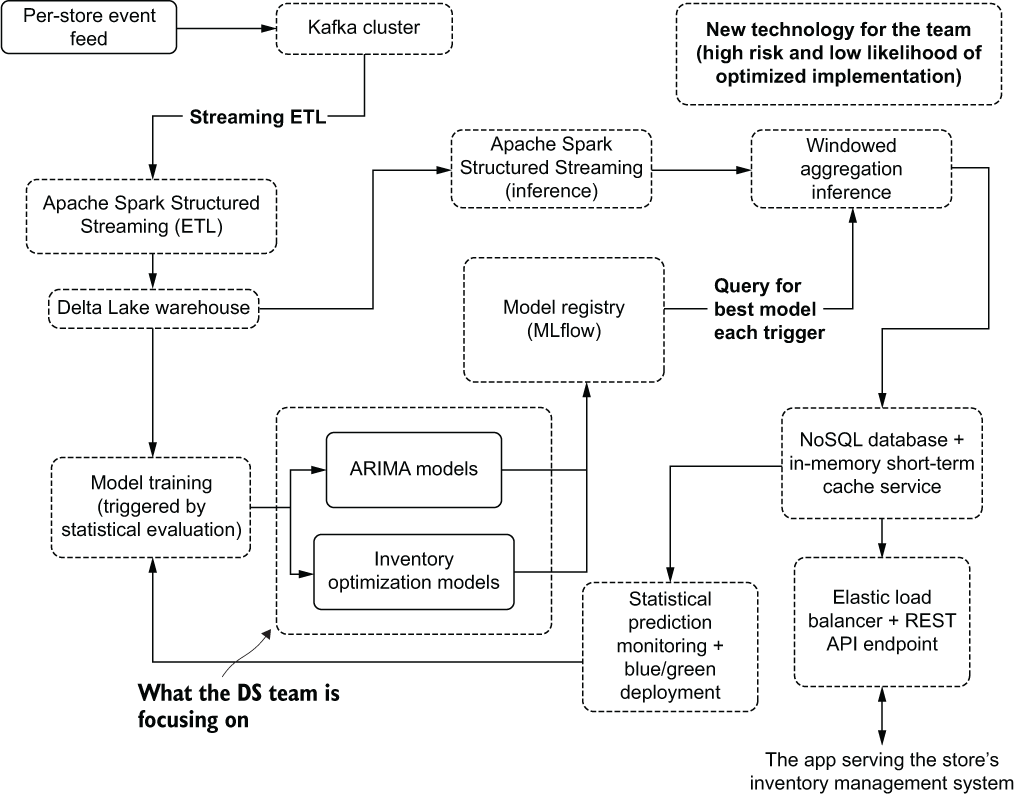
Figure 1.12 The far more complex pseudo-real-time serving architecture required to meet the business needs for the project
It doesn’t take long for the project to get cancelled and a complete redesign of the architecture for this implementation to be commissioned to keep the costs down. This is a story that plays out time and again at companies implementing ML to solve new and interesting problems (and to be fair, one that I’ve personally caused three times in my career).
Without focusing on the deployment and serving at the start of a project, the risk of building a solution that is under-engineered—doesn’t meet service-level agreement (SLA) or traffic-volume needs—or is overengineered—exceeds technical specifications at an unacceptably high cost—is high. Figure 1.13 shows some (not all, by any stretch of the imagination) elements to think about with regards to serving prediction results and the costs associated with the extremes of the ranges of those paradigms.

Figure 1.13 Deployment cost considerations
It may not seem particularly exciting or important to think about cost when faced with a novel problem to solve in a clever way with an algorithm. While the DS team might not be thinking of total cost of ownership for a particular project, rest assured that executives are. By evaluating these considerations early enough in the process of building a project, analyses can be conducted to determine whether the project is worth it.
It’s better to cancel a project in the first week of planning than to shut off a production service after spending months building it, after all. The only way to know whether a relatively expensive architecture is worth the cost of running it, however, is by measuring and evaluating its impact to the business.
1.2.6 Evaluation
If you can’t justify the benefits of your project being in production, don’t expect it to remain there for very long.
The worst reason for getting an ML project cancelled or abandoned is budget. Typically, if the project has gotten into production to begin with, the up-front costs associated with developing the solution were accepted and understood by the leadership at the company. Having a project cancelled after it’s already in production because of a lack of visibility of its impact to the company is a different matter entirely. If you can’t prove the worth of the solution, you face the real possibility of someone telling you to turn it off to save money someday.
Imagine a company that has spent the past six months working tirelessly on a new initiative to increase sales through the use of predictive modeling. The DS team members have followed best practices throughout the project’s development—making sure that they’re building exactly what the business is asking for and focusing development efforts on maintainable and extensible code—and have pushed the solution to production.
The model has been performing wonderfully over the past three months. Each time the team has done post hoc analysis of the predictions to the state of reality afterward, the predictions turn out to be eerily close. Figure 1.14 then rears its ugly head with a simple question from one of the company executives who is concerned about the cost of running this ML solution.
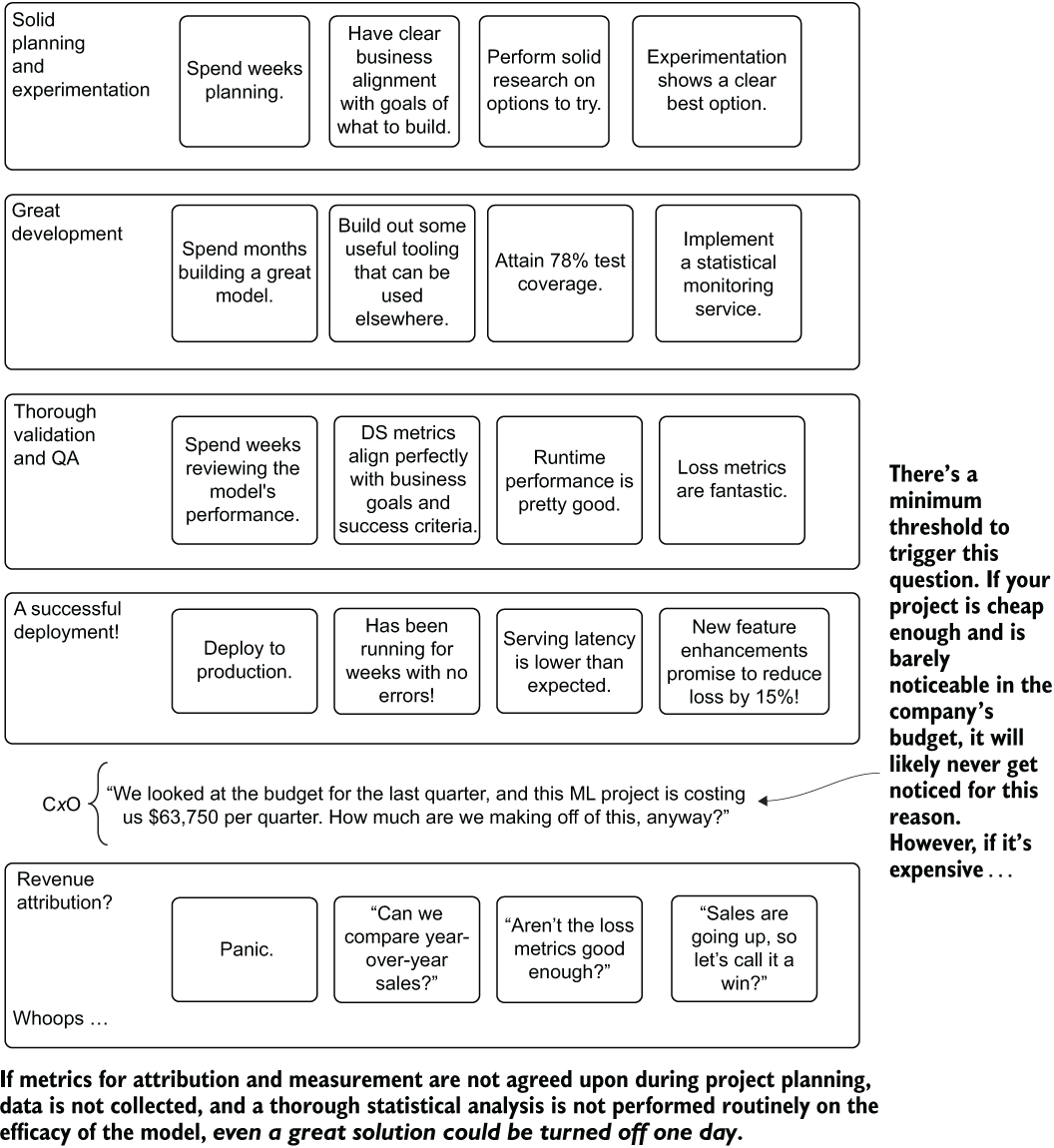
Figure 1.14 A nearly flawless ML project getting cancelled because of a lack of A/B testing and statistically valid attribution measurement
The one thing that the team forgot about in creating a great ML project is thinking of how to tie their predictions to some aspect of the business that can justify its existence. The model that they’ve been working on and that is currently running in production was designed to increase revenue, but when scrutinized for the cost of using it, the team realized that they hadn’t thought of an attribution analytics methodology to prove the worth of the solution.
Can they simply add up the sales and attribute it all to the model? No, that wouldn’t be even remotely correct. Could they look at the comparison of sales versus last year? That wouldn’t be correct either, as far too many latent factors are impacting sales.
The only thing that they can do to give attribution to their model is to perform A/B testing and use sound statistical models to arrive at a revenue lift calculation (with estimation errors) to show how much additional sales are due to their model. However, the ship has already sailed, as the solution has already been deployed for all customers. The team lost its chance at justifying the continued existence of the model. While the project might not be shut off immediately, it certainly will be on the chopping block if the company needs to reduce its budgetary spending.
It’s always a good idea to think ahead and plan for this case. Whether it’s happened to you yet or not, I can assure you that at some point it most certainly will (it took me two very hard lessons to learn this little nugget of wisdom). It is far easier to defend your work if you have the ammunition at the ready in the form of validated and statistically significant tests showing the justification for the model’s continued existence. Chapter 11 covers approaches to building A/B testing systems, statistical tests for attribution, and associated evaluation algorithms.
1.3 The goals of ML engineering
In the most elemental sense, the primary goal of any DS is to solve a difficult problem through the use of statistics, algorithms, and predictive modeling that is either too onerous, monotonous, error-prone, or complex for a human to do. It’s not to build the fanciest model, to create the most impressive research paper about their approach to a solution, or to search out the most exciting new tech to force into their project work.
We’re all here in this profession to solve problems. Among a vast quantity of tools, algorithms, frameworks, and core responsibilities that a DS has at their disposal to solve those problems, it’s easy to become overwhelmed and focus on the technical aspects of the job. Without a process guide to wrangle the complexity of ML project work, it’s incredibly easy to lose sight of the real goal of solving problems.
By focusing on the core aspects of project work highlighted in section 1.2 and covered in greater detail throughout this book, you can get to the true desired state of ML work: seeing your models run in production and having them solve a real business problem.
Before delving into the finer details of each of these methodologies and approaches for ML engineering work, see the outline detailed in figure 1.15. This is effectively a process flow plan for production ML work that I’ve seen prove successful for any project with any team.
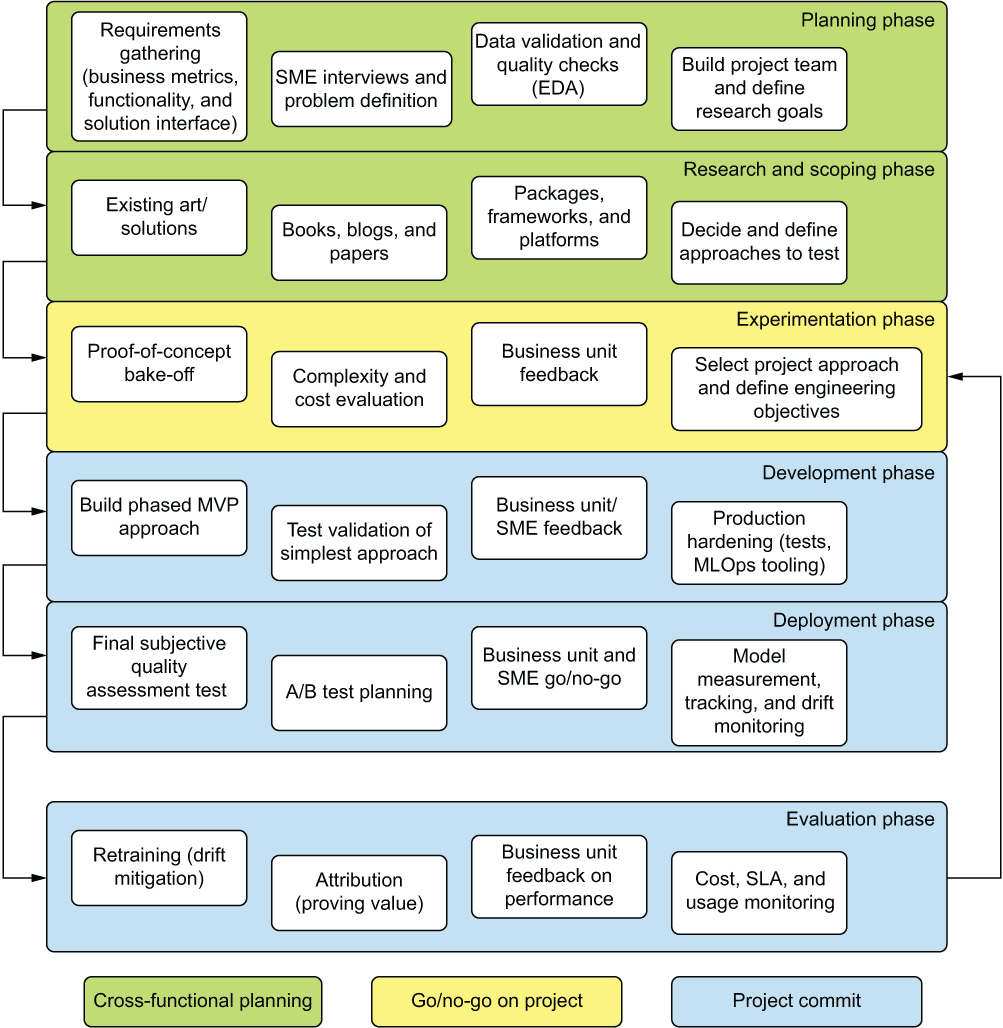
Figure 1.15 The ML engineering methodology component map
Throughout this book, we’ll cover these elements, focusing not only on discussions and implementations of each, but also on why they’re so important. This path—focusing on the people, processes, and tools to support successful ML projects—is paved over the corpses of many failed projects I’ve seen in my career. However, by following the practices that this book outlines, you will likely see fewer of these failures, allowing you to build more projects that not only make their way to production, but get used and stay in production.
Summary
- ML engineers need to know aspects of data science, traditional software engineering, and project management to ensure that applied ML projects are developed efficiently, focus on solving a real problem, and are maintainable.
- Focusing on best practices throughout the six primary project phases of applied ML work—planning, scoping and research, experimentation, development, deployment, and evaluation—will greatly help a project minimize risk of abandonment.
- Shedding concerns about technical implementation details, tooling, and novelty of approaches will help focus project work on what really matters: solving problems.