
3 Designing microservices
- Principles of microservices design
- Service decomposition by business capability
- Service decomposition by subdomain
When we design a microservices platform, the first questions we face are, “How do you break down a system into microservices? How do you decide where a service ends and another one starts?” In other words, how do you define the boundaries between microservices? In this chapter, you’ll learn to answer these questions and how to evaluate the quality of a microservices architecture by applying a set of design principles.
The process of breaking down a system into microservices is called service decomposition. Service decomposition is a fundamental step in the design of our microservices since it helps us define applications with clear boundaries, well-defined scopes, and explicit responsibilities. A well-designed microservices architecture is essential to reduce the risk of a distributed monolith. In this chapter, you’ll learn two service decomposition strategies: decomposition by business capability and decomposition by subdomains. We’ll see how these methods work and use a practical example to learn to apply them. Before we delve into service decomposition strategies, we introduce the project that will guide our examples throughout this chapter and the rest of the book: CoffeeMesh.
3.1 Introducing CoffeeMesh
CoffeeMesh is a fictitious company that allows customers to order all sorts of products derived from coffee, including beverages and pastries. CoffeeMesh has one mission: to make and deliver the best coffee in the world on demand to its customers, no matter where they are or when they place their order. The production factories owned by CoffeeMesh form a dense network, a mesh of coffee production units that spans several countries. Coffee production is fully automated, and deliveries are carried out by an unmanned fleet of drones operating 24/7.
When a customer places an order through the CoffeeMesh website, the ordered items are produced on demand. An algorithm determines which factory is the most suitable place to produce each item based on available stock, the number of pending orders the factory is taking care of, and distance to the customer. Once the items are produced, they’re immediately dispatched to the customer. It’s part of CoffeeMesh’s mission statement that the customer receives each item fresh and hot.
Now that we have an example to work with, let’s see how we design the microservices architecture for the CoffeeMesh platform. Before we learn to apply service decomposition strategies for microservices, the next section teaches you three principles that will guide our designs.
3.2 Microservices design principles
What makes a well-designed microservice? As we established in chapter 1, microservices are designed around well-defined business subdomains, they have clearly defined application boundaries, and they communicate with each other through lightweight protocols. What does this mean in practice? In this section, we explore three design principles that help us test whether our microservices are correctly designed:
Following these principles will help you avoid the risk of building a distributed monolith. In the following sections, we evaluate our architectural design against these principles, and they help us spot errors in the design.
3.2.1 Database-per-service principle
The database-per-service principle states that each microservice owns a specific set of the data, and no other service should have access to such data except through an API. Despite this pattern’s name, it does not mean that each microservice should be connected to a completely different database. It could be different tables in an SQL database or different collections in a NoSQL database. The point of this pattern is to ensure that the data owned by a specific service is not accessed directly by another service.
Figure 3.1 shows how microservices share their data. In the illustration, the orders service calculates the price of a customer order. To calculate the price, the orders service needs the price of each item in the order, which is available in the Products database. It also needs to know whether the user has an applicable discount, which can be checked in the Users database. However, instead of accessing both databases directly, the orders service requests this data from the products and users services.

Figure 3.1 Each microservice has its own database, and access to another service’s data happens through an API.
Why is this principle important? Encapsulating data access behind a service allows us to design our data models for optimal access for the service. It also allows us to make changes to the database without breaking another service’s code. If the orders service in figure 3.1 had direct access to the Products database, schema changes in that database would require updates to both the products and orders services. We’d be coupling the orders service’s code to the Products database, and therefore we’d be breaking the loose coupling principle, which we discuss in the next section.
3.2.2 Loose coupling principle
Loose coupling states that we must design services with clear separation of concerns. Loosely coupled services don’t rely on another’s implementation details. What does this mean in practice? This principle has two practical implications:
-
Each service can work independently of others. If we have a service that can’t fulfill a single request without calling another service, there’s no clear separation of concerns between both services and they belong together.
-
Each service can be updated without impacting other services. If changes to a service require updates to other services, we have tight coupling between those services, and therefore they need to be redesigned.
Figure 3.2 shows a sales forecast service that knows how to calculate a forecast based on historical data. It also shows a historical data service that owns historical sales data. To calculate a forecast, the sales forecast service makes an API call to the historical data service to obtain historical data. In this case, the sales forecast service can’t serve any request without calling the historical data service, and therefore there’s tight coupling between both services. The solution is to redesign both services so that they don’t rely on each other, or to merge them into a single service.

Figure 3.2 When a service can’t serve a single request without calling another service, we say both are tightly coupled.
3.2.3 Single Responsibility Principle
The SRP states that we must design components with few responsibilities, and ideally with only one responsibility. When applied to the microservices architecture design, this means we should strive for the design of services around a single business capability or subdomain. In the following sections, you’ll learn how to decompose services by business capability and by subdomain. If you follow any of those methods, you’ll be able to design microservices that follow the SRP.
3.3 Service decomposition by business capability
When using decomposition by business capability, we look into the activities a business performs and how the business organizes itself to undertake them. We then design microservices that mirror the organizational structure of the business. For example, if the business has a customer management team, we build a customer management service; if the business has a claims management team, we build a claims management service; for a kitchen team, we build the corresponding kitchen service; and so on. For businesses that are structured around products, we may have a microservice per product. For example, a company that makes pet food may have a team dedicated to dog food, another team dedicated to cat food, another team dedicated to turtle food, and so on. In this scenario, we build microservices for each of these teams.
As you can see in figure 3.3, decomposition by business capability generally results in an architecture that maps every business team to a microservice. Let’s see how we apply this approach to the CoffeeMesh platform.

Figure 3.3 Using service decomposition by business capability, we reflect the structure of the business in our microservices architecture.
3.3.1 Analyzing the business structure of CoffeeMesh
To apply decomposition by business capability, we need to analyze the structure and organization of the business. Let’s do this analysis for CoffeeMesh. Through the CoffeeMesh website, customers can order different types of coffee-related products out of a catalogue managed by the products team, who is in charge of creating new products. The availability of products and ingredients depends on the CoffeeMesh stock of ingredients at the time of the order, which is looked after by the inventory team.
A sales team is dedicated to improving the experience of ordering products through the CoffeeMesh website. Their goal is to maximize sales and ensure customers are happy with their experience and wish to come back. A finance team makes sure that the company is profitable and looks after the financial infrastructure required to process customer payments and return their money when they cancel an order.
Once a user places an order, the kitchen picks up its details to commence production. Kitchen work is fully automated, and a dedicated team of engineers and chefs called the kitchen team monitors kitchen operations to ensure no faults happen during production. When the order is ready for delivery, a drone picks it up and flies it to the customer. A dedicated team of engineers called the delivery team monitors this process to ensure the operational excellence of the delivery process.
This completes our analysis of the organizational structure of CoffeeMesh. We’re now ready to design a microservices architecture based on this analysis.
3.3.2 Decomposing microservices by business capabilities
To decompose services by business capability, we map each business team to a microservice. Based on the analysis in section 3.3.1, we can map the following business teams to microservices:
-
Products team maps to the products service—This service owns CoffeeMesh product catalogue data. The products team uses this service to maintain CoffeeMesh’s catalogue by adding new products or updating existing products through the service’s interface.
-
Ingredients team maps to the ingredients service—This service owns data about CoffeeMesh stock of ingredients. The ingredients team uses this service to keep the ingredients database in sync with CoffeeMesh warehouses.
-
Sales team maps to the sales service—This service guides customers through their journey to place orders and keep track of them. The sales team owns data about customer orders, and it manages the life cycle of each order. It collects data from this service to analyze and improve the customer journey.
-
Finance team maps to the finance service—This service implements payment processors, and it owns data about user payment details and payment history. The finance team uses this service to keep the company accounts up to date and to ensure payments work correctly.
-
Kitchen team maps to the kitchen service—This service sends orders to the automated kitchen system and keeps track of its progress. It owns data about the orders produced in the kitchen. The kitchen team collects data from this service to monitor the performance of the automated kitchen system.
-
Delivery team maps to the delivery service—This service arranges the delivery of the order to the customer once it has been produced by the kitchen. This service knows how to translate the user location into coordinates and how to calculate the best route to that destination. It owns data about every delivery made by CoffeeMesh. The delivery team collects data from this service to monitor the performance of the automated delivery system.
In this microservices architecture, we named every service after the business structure it represents. We did this for convenience in this example, but it does not have to be that way. For example, the finance service could be renamed to payments service, since all user interactions with this service will be related to their payments.
Decomposition by business capability gives us an architecture in which every service maps to a business team. Is this result in agreement with the principles of microservices design we learned in section 3.2? Let’s look at this question.
From the previous analysis, it’s clear that every service owns its own data: the products service owns product data, the ingredients service owns ingredients data, and so on. The SRP also applies, as every service is restricted to one business area: the finance service only processes payments, the delivery service only manages deliveries, and so on.
However, as you can see in figure 3.4, this solution doesn’t satisfy the loose coupling principle. To serve the CoffeeMesh catalogue, the products service needs to determine the availability of each product, which depends on the available stock of ingredients. Since the stock of ingredients data is owned by the ingredients service, the products service needs to make an API call per product to the ingredients service.

Figure 3.4 To determine whether a product is available, the products service checks the stock of ingredients with the ingredients service.
There’s a high degree of coupling between the products and ingredients services, and therefore both business capabilities should be implemented within the same service. Figure 3.5 shows the final layout of the CoffeeMesh microservices architecture using the decomposition by business capability strategy.

Now that we know how to decompose services by business capability, let’s see how decomposition by subdomain works.
3.4 Service decomposition by subdomains
Decomposition by subdomains is an approach that draws inspiration from the field of domain-driven design (DDD)—an approach to software development that focuses on modeling the processes and flows of the business with software using the same language business users employ. When applied to the design of a microservices platform, DDD helps us define the core responsibilities of each service and their boundaries.
3.4.1 What is domain-driven design?
DDD is an approach to software that focuses on modeling the processes and flows of the business users. The methods of DDD were best described by Eric Evans in his influential book Domain-Driven Design (Addison-Wesley, 2003), otherwise called “the big blue book.” DDD offers an approach to software development that tries to reflect as accurately as possible the ideas and the language that businesses, or end users of the software, use to refer to their processes and flows. To achieve this alignment, DDD encourages developers to create a rigorous, model-based language that software developers can share with the end users. Such language must not have ambiguous meanings and is called ubiquitous language.
To create an ubiquitous language, we must identify the core domain of a business, which corresponds with the main activity an organization performs to generate value. For a logistics company, it may be the shipment of products around the world. For an e-commerce company, it may be the sale of products. For a social media platform, it may be feeding a user with relevant content. For a dating app, it may be matching users. For CoffeeMesh, the core domain is to deliver high-quality coffee to customers as quickly as possible regardless of their location.
The core domain is often not sufficient to cover all areas of activity in a business, so DDD also distinguishes supportive subdomains and generic subdomains. A supportive subdomain represents an area of the business that is not directly related to value generation, but it is fundamental to support it. For a logistics company, it may be providing customer support to the users shipping their products, leasing equipment, managing partnerships with other businesses, and so on. For an e-commerce company, it may be marketing, customer support, warehousing, and so on.
The core domain gives you a definition of the problem space : the problem you are trying to solve with software. The solution consists of a model, understood here as a system of abstractions that describes the domain and solves the problem. Ideally, there is only one generic model that provides a solution space for the problem, with a clearly defined ubiquitous language. However, in practice, most problems are complex enough that they require the collaboration of different models, with their own ubiquitous languages. We call the process of defining such models strategic design.
3.4.2 Applying strategic analysis to CoffeeMesh
How does DDD work in practice? How do we apply it to decompose CoffeeMesh into subdomains? To break down a system into subdomains, it helps to think about the operations the system has to perform to accomplish its goal. With CoffeeMesh, we want to model the process of taking an order and delivering it to the customer. As you can see in figure 3.6, we break down this process into eight steps:
-
When the customer lands on the website, we show them the product catalogue. Each product is marked as available or unavailable. The customer can filter the list by availability and sort it by price (from lowest to highest and highest to lowest).
-
Once the customer has paid, we pass on the details of the order to the kitchen.
-
The customer tracks the drone’s itinerary until their order is delivered.

Figure 3.6 To place an order, the customer lands on the CoffeeMesh website, selects items from the product catalogue, and pays for the order. After payment, we pass the order’s details to the kitchen, which produces it while the customer monitors its progress. Finally, we arrange the order’s delivery.
Let’s map each step to its corresponding subdomain (see figure 3.7 for a representation of this analysis). The first step represents a subdomain that serves the CoffeeMesh product catalogue. We can call it the products subdomain. This subdomain tells us which products are available and which are not. To do so, the products subdomain tracks the amount of each product and ingredient in stock.
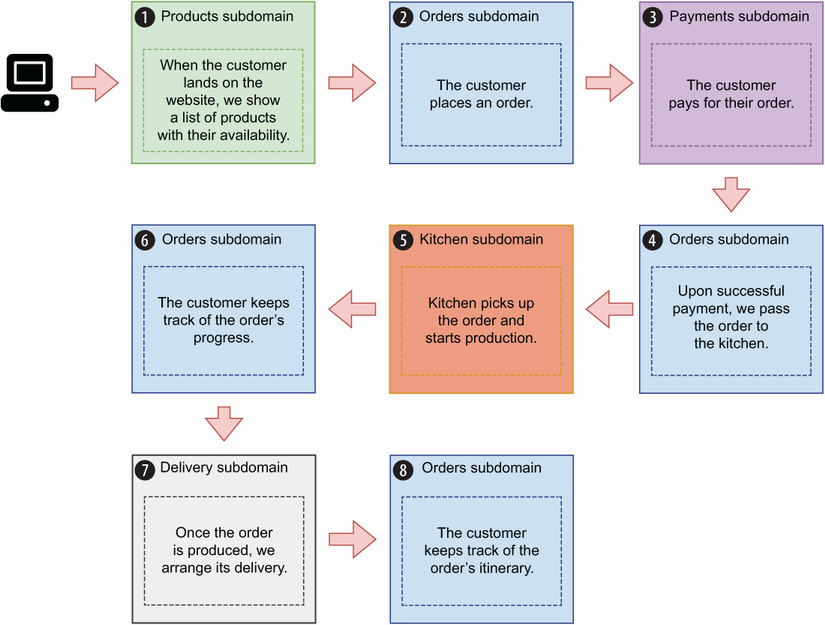
Figure 3.7 We map to a subdomain every step in the process of placing and delivering an order. For example, the process of serving the product catalogue is satisfied by the products subdomain, while the process of taking an order is satisfied by the orders subdomain.
The second step represents a subdomain that allows users to select products. This subdomain manages the life cycle of each order, and we call it the orders subdomain. This subdomain owns data about users’ orders, and it exposes an interface that allows us to manage orders and check their status. It hides the complexity of the platform so that the user doesn’t have to know about different endpoints and know what to do with them. The orders subdomain also takes care of the second part of the fourth step: passing the details of the order to the kitchen once the payment has been successfully processed. It also meets the requirements for step 6: allow the user to check the state of their order. As an orders manager, the orders subdomain also works with the delivery subdomain to arrange the delivery.
The third step represents a subdomain that can handle user payments. We will call it the payments subdomain. This domain contains specialized logic for payment processing, including card validation, integration with third-party payment providers, handling different methods of payment, and so on. The payments subdomain owns data related to user payments.
The fifth step represents a subdomain that works with the kitchen to manage the production of customer orders. We call it the kitchen subdomain. The production system in the kitchen is fully automated, and the kitchen subdomain interfaces with the kitchen system to schedule the production of customer orders and track their progress. Once an order is produced, the kitchen subdomain notifies the orders subdomain, which then arranges its delivery. The kitchen subdomain owns data related to the production of customer orders, and it exposes an interface that allows us to send orders to the kitchen and keep track of their progress. The orders subdomain interfaces with the kitchen subdomain to update the order’s status to meet the requirements for the sixth step.
The seventh step represents a subdomain that interfaces with the automated delivery system. We call it the delivery subdomain. This subdomain contains specialized logic to resolve the geolocation of a customer and to calculate the most optimal route to reach them. It manages the fleet of delivery drones and optimizes the deliveries, and it owns data related to all the deliveries. The orders subdomain interfaces with the delivery subdomain to update the itinerary of the customer’s order to meet the requirements for the eighth step.
Using strategic analysis, we obtain a decomposition for CoffeeMesh in five subdomains, which can be mapped to microservices, as each encapsulates a well-defined and clearly differentiated area of logic that owns its own data. DDD’s strategic analysis results in microservices that satisfy the design principles we enumerated in section 3.2: all these subdomains can perform their core tasks without relying on other microservices, and therefore we say they’re loosely coupled; each service owns its own data, hence complying with the database-per-service principle; finally, each service performs tasks within a narrowly defined subdomain, which complies with the SRP.
As you can see in figure 3.8, strategic analysis gives us the following microservices architecture:
-
Products subdomain maps to the products service—Manages CoffeeMesh’s product catalogue
-
Orders subdomain maps to the orders service—Manages customer orders
-
Payments subdomain maps to the payments service—Manages customer payments
-
Kitchen subdomain maps to the kitchen service—Manages the production of orders in the kitchen
-
Delivery subdomain maps to the delivery service—Manages customer deliveries

Figure 3.8 Applying DDD’s strategic analysis breaks down the CoffeeMesh platform into five subdomains that can be mapped directly to microservices.
In the next section, we compare the results of DDD’s strategic analysis with the outcome of service decomposition by business capability, and we evaluate the benefits and challenges of each approach.
3.5 Decomposition by business capability vs. decomposition by subdomain
Which service decomposition strategy should we use to design our microservices: decomposition by business capability or decomposition by subdomains? While decomposition by business capability focuses on business structure and organization, decomposition by subdomain analyzes business processes and flows. Therefore, both approaches give us different perspectives on the business, and if you can spare the time, the best strategy is to apply both approaches to service decomposition.
Sometimes we can combine the results of both approaches. For example, the CoffeeMesh platform could allow customers to write reviews for each product, and CoffeeMesh could leverage this information to recommend new products to other customers. The company could have an entire team dedicated to this aspect of the business. From a technical point of view, reviews could be just another table in the Products database. However, to facilitate collaboration with the business, it could make sense to build a reviews service. The reviews service would be able to feed new reviews into the recommendation system, and the orders service would use the reviews service’s interface to serve recommendations to new users.
The advantage of decomposition by business capability is that the architecture of the platform aligns with the existing organizational structure of the business. This alignment might facilitate the collaboration between business and technical teams. The downside of this approach is that the existing organizational structure of the business is not necessarily the most efficient one. As a matter of fact, it can be outdated and reflect old business processes. In that case, the inefficiencies of the business will be mirrored in the microservices architecture. Decomposition by business capability also risks falling out of alignment with the business if the organization is restructured.
When we applied decomposition by business capability in section 3.3.2, we obtained an undesirable division between the products and ingredients services. After further analysis of the dependencies between both services, we concluded that both capabilities should go into the same service. However, in real-life situations, this additional analysis is often missing, and the resulting architecture isn’t optimal. From the analysis in sections 3.3 and 3.4, we can say that decomposition by subdomain gives you a better architectural fit to model the business processes and flows, and if you must choose only one approach, decomposition by subdomain is the better strategy.
Now that we know how to design our microservices, it’s time to design and build their interfaces. In the upcoming chapters, you’ll learn to build REST and GraphQL interfaces for microservices.
Summary
-
We call the process of breaking down a system into microservices service decomposition. Service decomposition defines the boundaries between services, and we must get this process right to avoid the risk of building a distributed monolith.
-
Decomposition by business capability analyzes the structure of the business and designs microservices for each team in the organization. This approach aligns the business with our system architecture, but it also reproduces the inefficiencies of the business into the platform.
-
Decomposition by subdomains applies DDD to model the processes and flows of the business through subdomains. By using this approach, we design a microservice for each subdomain, which results in a more robust technical design.
-
To assess the quality of our microservices architecture, we apply three design principles:
- Database-per-service principle—Each microservice owns its own data, and access to that data happens through the service’s API.
- Loose coupling principle—You must be able to update a service without impacting other services, and each service should be able to work without constantly calling other services.
- Single Responsibility Principle—We must design each service around a specific business capability or subdomain.