

Chapter 4
The Machine That Learns
A Look inside Chase's Prediction of Mortgage Risk
What form of risk has the perfect disguise? How does prediction transform risk to opportunity? What should all businesses learn from insurance companies? Why does machine learning require art in addition to science? What kind of predictive model can be understood by everyone? How can we confidently trust a machine's predictions? Why couldn't prediction prevent the global financial crisis?
This is a love story about a man named Dan and a bank named Chase, and how they learned to persevere against all odds—more precisely, how they deployed machine learning to empower prediction, which in turn mitigates risk. Exploring this story, we'll uncover how machine learning really works under the hood.1
Boy Meets Bank
Once upon a time, a scientist named Dan Steinberg received a phone call because the largest U.S. bank faced new levels of risk. To manage risk, they were prepared to place their bets on this man of machine learning.
'Twas a fortuitous engagement, as Dan had just the right means and method to assist the bank. An entrepreneurial scientist, he had built a commercial predictive analytics (PA) system that delivered leading research from the lab into corporate hands. The bank held as dowry electronic plunder: endless rows of 1's and 0's that recorded its learning experience.
The bank had the fuel, and Dan had the machine. It was a match made in heaven. Daydreaming, I often doodle in the margins:

A more adult business professional might open his heart in a more formal way, depicting this as we did in a previous chapter:

Machine learning processes data to produce a predictive model.
Bank Faces Risk
For any organization, financial risk creeps up stealthily, hidden by a perfect, simple disguise: Major loss accumulates from many small losses, each of which alone seems innocuous. Minor individual misfortunes, boring and utterly undramatic, slip below the radar. They're practically invisible.
Soon after a megamerger in 1996 that rendered Chase Bank the nation's largest, the bank's home finance team recognized a new degree of risk. Their pool of mortgage holders had grown significantly. It was now composed of what had originally been six banks' worth of mortgages: millions of them. Each one represented a bit of risk—a microrisk. That's when Dan received the call.
Ironically, there are two seemingly opposite ways a mortgage customer can misbehave. They can fail to pay you back, or they can pay you back in full but too quickly:
- Microrisk A: Customer defaults on the mortgage payments.
- Microrisk B: Customer prepays the mortgage all at once, early, due to refinancing with a competing bank or selling the house. Prepayment is a loss because the bank fails to collect the mortgage's planned future interest payments.
These losses are demoted to “micro” because, for a bank, any one mortgage customer just isn't that big a deal. But microlosses threaten to add up. In the financial world, the word risk most often refers to credit risk; that is, microrisk A, wherein an outstanding debt is never recovered and is lost forever. But when your bread and butter is interest payments, microrisk B is no picnic either. To put it plainly, your bank doesn't want you to get out of debt.2
Prediction Battles Risk
Most discussions of decision making assume that only senior executives make decisions or that only senior executives' decisions matter. This is a dangerous mistake.
—Peter Drucker, an American educator and writer born in 1909
Chase's mortgage portfolio faced risk factors amounting to hundreds of millions of dollars. Every day is like a day at the beach—each grain of sand is one of a million microrisks. Once a mortgage application is stamped “low-risk” and approved, the risk management process has actually only just begun. The bank's portfolio of open mortgages must be tended to like cows on a dairy farm. The reason? Risk lurks. Millions of mortgages await decisions as to which to sell to other banks, which to attempt to keep alive, and which to allow refinancing for at a lower interest rate.
PA serves as an antidote to the poisonous accumulation of microrisks. PA stands vigil, prospectively flagging each microrisk so the organization can do something about it.
It's nothing new. The notion is mainstream and dates back to the very origin of PA. Predicting consumer risk is well known as the classic credit score, provided by FICO and credit bureaus such as Experian. The credit score's origin dates back to 1941, and the term is now a part of the common vernacular. Its inception was foundational for PA, and its success has helped propel PA's visibility. Modern-day risk scores are often built with the same predictive modeling methods that fuel PA projects.
The benefits of fighting risk with PA can be demonstrated with ease. While prediction itself may be an involved task, it only takes basic arithmetic to calculate the value realized once prediction is working. Imagine you run a bank with thousands of outstanding loans, 10 percent of which are expected to default. With one of every 10 debtors an impending delinquent account, the future drapes its usual haze: You just don't know which will turn out to be bad.
Say you score each loan for risk with an effective predictive model. Some get high-risk scores and others low-risk scores. If these risk scores are assigned well, the top half predicted as most risky could see almost twice as many as average turn out to be defaulters—to be more realistic, let's say 70 percent more than the overall default rate. That would be music to your ears. A smidgeon of arithmetic shows you've divided your portfolio into two halves, one with a 17 percent default rate (70 percent more than the overall 10 percent rate), and the other with a 3 percent default rate (since 17 and 3 average out to 10).
- High-risk loans: 17 percent will default.
- Low-risk loans: 3 percent will default.
You've just divided your business into two completely different worlds, one safe and one hazardous. You now know where to focus your attention.
Following this promise, Chase took a large-scale, calculated macrorisk. It put its faith in prediction, entrusting it to drive millions of dollars' worth of decisions. But Chase's story will earn its happy ending only if prediction works—if what's learned from data pans out in the great uncertainty that is the future.
Prediction presents the ultimate dilemma. Even with so much known of the past, how can we justify confidence in technology's vision of the unknowable future?
Before we get into how prediction works, here are a few words on risk.
Risky Business
The revolutionary idea that defines the boundary between modern times and the past is the mastery of risk: the notion that the future is more than a whim of the gods and that men and women are not passive before nature. Until human beings discovered a way across that boundary, the future was a mirror of the past or the murky domain of oracles and soothsayers who held a monopoly over knowledge of anticipated events.
—Peter Bernstein, Against the Gods: The Remarkable Story of Risk
There's no such thing as bad risk, only bad pricing.
—Stephen Brobst, Chief Technology Officer, Teradata
Of course, banks don't bear the entire burden of managing society's risk. Insurance companies also play a central role. In fact, their core business is the act of data crunching to quantify risk so it can be efficiently distributed. Eric Webster, a vice president at State Farm Insurance, put it brilliantly: “Insurance is nothing but management of information. It is pooling of risk, and whoever can manipulate information the best has a significant competitive advantage.” Simply put, these companies are in the business of prediction.
The insurance industry has made an art of risk management. In his book The Failure of Risk Management, Douglas Hubbard points out what is poignant for all organizations that aren't insurance companies: “No certified, regulated profession like the actuarial practice exists outside of what is strictly considered insurance.”
Despite this, any and all organizations can master risk the way insurance does. How? By applying PA to predict bad things. For any organization, a predictive model essentially achieves the same function as an insurance company's actuarial approach: rating individuals by the chance of a negative outcome. In fact, we can define PA in these very terms.3
Here's the original definition:
Predictive analytics (PA)—Technology that learns from experience (data) to predict the future behavior of individuals in order to drive better decisions.
What an organization effectively learns with PA is how to decrease risk by way of anticipating microrisks. Here's an alternative, risk-oriented definition:
Predictive analytics (PA)—Technology that learns from experience (data) to manage microrisk.
Both definitions apply, since each one implies the other.
Like the opportunistic enterprise Tom Cruise's adolescent entrepreneur launches in his breakout movie of 1983, Risky Business, all businesses are risky businesses. And, like insurance companies, all organizations benefit from measuring and predicting the risk of bad behavior, including defaults, cancellations, dropouts, accidents, fraud, and crime. In this way, PA transforms risk to opportunity.
For the economy at large, where could risk management be more important than in the world of mortgages? The mortgage industry, measured in the trillions of dollars, serves as the financial cornerstone of homeownership, the hallmark of family prosperity. And, as important as mortgages are, risky ones are generally considered a central catalyst to the recent financial crisis or Great Recession.
Microrisks matter. Left unchecked, they threaten to snowball. Our best bet is to learn to predict.
The Learning Machine
To learn from data: the process isn't nearly as complex as you might think.4
Start with a modest question: What's the simplest way to begin distinguishing between high- and low-risk mortgages? What single factor about a mortgage is the most telling?
Dan's learning system made a discovery within Chase's data: If a mortgage's interest rate is under 7.94 percent, then the risk of prepayment is 3.8 percent; otherwise, the risk is 19.2 percent.5
Drawn as a picture:

What a difference! Based only on interest rate, we divide the pool of mortgages into two groups, one five times riskier than the other with respect to the chances of prepayment (a customer making an unforeseen payoff of the entire debt, thereby denying the bank future earnings from interest payments).
This discovery is valuable, even if not entirely surprising. Homeowners paying a higher interest rate are more inclined to refinance or sell than those paying a lower rate. If this was already suspected, it's now confirmed empirically, and the effect is precisely quantified.
Machine learning has taken its first step.
Building the Learning Machine
You're already halfway there. Believe it or not, there is only one more step before you witness the full essence of machine learning—the ability to generate a predictive model from data, to learn from examples and form an electronic Sherlock Holmes that sizes up an individual and predicts.
You're inches away from the key to one of the coolest things in science, the most audacious of human ambitions: the automation of learning.
No sophisticated math or computer code required; in fact, I can explain the rest in two words. But first, let's take a moment to fully define the scientific challenge at hand.
The insight established so far, that interest rate predicts risk, makes for a crude predictive model. It puts each individual mortgage into one of two predictive categories: high risk and low risk. Since it considers only one factor, or predictor variable, about the individual, we call this a univariate model. All the examples in the previous chapter's tables of bizarre and surprising insights are univariate—they each pertain to one variable such as your salary, your e-mail address, or your credit rating.
We need to go multivariate. Why? An effective predictive model surely must consider multiple factors at once, instead of just one. And therein lies the rub. As a refresher, here's the definition:
Predictive model—A mechanism that predicts a behavior of an individual, such as click, buy, lie, or die (or prepay a mortgage). It takes characteristics (variables) of the individual as input and provides a predictive score as output. The higher the score, the more likely it is that the individual will exhibit the predicted behavior.
Once created with machine learning, a predictive model predicts the outcome for one customer at a time:

Consider a mortgage customer who looks like this:
- Borrower: Sally Smithers
- Mortgage: $174,000
- Property value: $400,000
- Property type: Single-family residence
- Interest rate: 8.92 percent
- Borrower's annual income: $86,880
- Net worth: $102,334
- Credit score: Strong
- Late payments: 4
- Age: 38
- Marital status: Married
- Education: College
- Years at prior address: 4
- Line of work: Business manager
- Self-employed: No
- Years at job: 3
Those are the predictor variables, the characteristics fed into the predictive model. The model's job will be to consider any and all such variables and squeeze them into a single predictive score. Call it the calculation of a new über-variable. The model spits out the score, putting all the pieces together to proclaim a singular conclusion.
That's the challenge of machine learning. Your mission is to program your mindless laptop to crunch data about individuals and automatically build the multivariate predictive model. If you succeed, your computer will be learning how to predict.
Learning from Bad Experiences
Experience is the name everyone gives to his mistakes.
—Oscar Wilde
My reputation grows with every failure.
—George Bernard Shaw
There's another requirement for machine learning. A successful method must be designed to gain knowledge from a bittersweet mix of good and bad experience, from both the positive and the negative outcomes listed in the data. Some past mortgages went smoothly, whereas others suffered the fate of prepayment. Both of these flavors of data must be leveraged.
To predict, the question we strive to answer is: “How can you distinguish between positive and negative individuals ahead of time?” Learning how to replicate past successes by examining only the positive cases won't work.6 Negative examples are critical. Mistakes are your friend.
How Machine Learning Works
And now, here's the intuitive, elegant answer to the big dilemma, the next step of learning that will move beyond univariate to multivariate predictive modeling, guided by both positive and negative cases: Keep going.
So far, we've established two risk groups. Next, in the low-risk group, find another factor that best breaks it down even further, into two subgroups that themselves vary in risk. Then do the same thing in the high-risk group. And then keep going within the subgroups. Divide and conquer and then divide some more, breaking down to smaller and smaller groups. And yet, as we'll discover, don't go too far.
This learning method, called decision trees, isn't the only way to create a predictive model, but it's consistently voted as the most or second most popular by practitioners, due to its balance of relative simplicity with effectiveness. It doesn't always deliver the most precise predictive models, but since the models are easier on the eyes than impenetrable mathematical formulas, it's a great place to start, not only for learning about PA, but at the outset of almost any project that's applying PA.
Let's start growing the decision tree. Here's what we had so far:

Now let's find a predictor variable that breaks the low-risk group on the left down further. On this data set, Dan's decision tree software picks the debtor's income:7skiptop

You can see the tree is growing downward. As any computer scientist will tell you, trees are upside down and the root is on the top (but if you prefer, you may turn this book upside down).
As shown, the mortgage holder's income is very telling of risk. The lower-left leaf (end point of the tree) labeled “Segment 1” corresponds with a subgroup of mortgage holders for whom the interest rate is under 7.94 percent and income is under $78,223. So far, this is the lowest-risk group identified, with only a 2.6 percent chance of prepayment.
Data trumps the gut. Who would have thought individuals with lower incomes would be less likely to prepay? After all, people with lower incomes usually have a higher incentive to refinance their mortgages. It's tough to interpret; perhaps those with a lower income tend to pursue less aggressive financial tactics. As always, we can only conjecture on the causality behind these insights.
Moving to the right side of the tree, to further break down the high-risk group, the learning software selects mortgage size:

With only two factors taken into consideration, we've identified a particularly risky pocket: higher-interest mortgages that are larger in magnitude, which show a whopping 36 percent chance of prepayment (Segment 4).
Before this model grows even bigger and becomes more predictive, let's talk trees.
Decision Trees Grow on You
It's simple, elegant, and precise. It's practically mathless. To use a decision tree to predict for an individual, you start at the top (the root) and answer yes/no questions to arrive at a leaf. The leaf indicates the model's predictive output for that individual. For example, beginning at the top, if your interest rate is not less than 7.94 percent, proceed to the right. Then, if your mortgage is under $182,926, take a left. You end up in a leaf that says, based on these two factors, the risk that you will prepay is 13.9 percent.
Here's an example that decides what you should do if you accidentally drop your food on the floor (excerpted from “The 30-Second Rule: A Decision Tree” by Audrey Fukuman and Andy Wright)—this one was not, to my knowledge, derived from real data:

Imagine you just dropped an inexpensive BLT sandwich in front of your mom. Follow the tree from the top and you'll be instructed to eat it anyway.
A decision tree grows upon the rich soil that is data, repeatedly dividing groups of individuals into subgroups. Data is a recording of prior events, so this procedure is learning from the way things turned out in the past. The data determines which variables are used and at what splitting value (e.g., “Income < $78,223” in the mortgage decision tree). Like other forms of predictive modeling, its derivation is completely automatic—load the data, push a button, and the decision tree grows, all on its own. It's a rich discovery process, the kind of data mining that strikes gold.
Extending far beyond the business world, decision trees are employed to decide almost anything, whether it is medical, legal, governmental, astronomical, industrial, or you name it. The learning process is intrinsically versatile, since a decision tree's area of specialty is determined solely by the data upon which it grows. Provide data from a new field of study, and the machine is learning about an entirely new domain.
One decision tree was trained to predict votes on U.S. Supreme Court rulings by former Justice Sandra Day O'Connor. This tree, built across several hundred prior rulings, is from a research project by four university professors in political science, government, and law (“Competing Approaches to Predicting Supreme Court Decision Making,” by Andres D. Martin et al.):

It's simple yet effective. The professors' research shows that a group of such decision trees working together outperforms human experts in predicting Supreme Court rulings. By employing a separate decision tree for each justice, plus other means to predict whether a ruling will be unanimous, the gaggle of trees succeeded in predicting subsequent rulings with 75 percent accuracy, while human legal experts, who were at liberty to use any and all knowledge about each case, predicted at only 59 percent. Once again, data trumps the gut.8
Computer, Program Thyself
Find a bug in a program, and fix it, and the program will work today. Show the program how to find and fix a bug, and the program will work forever.
—Oliver Selfridge
The logical flow of a decision tree amounts to a simple computer program, so, in growing it, the computer is literally programming itself. The decision tree is a familiar structure you have probably already come across, if you know about any of these topics:
- Taxonomy. The hierarchical classification of species in the animal kingdom is in the form of a decision tree.
- Computer programs. A decision tree is a nested if-then-else statement. It may also be viewed as a flow chart with no loops.
- Business rules. A decision tree is a way to encode a series of if-then business rules; each path from the root to a leaf is one rule (aka a pattern, thus the data mining term pattern discovery).
- Marketing segmentation. The time-honored tradition of segmenting customers and prospects for marketing purposes can be conceived in the form of a decision tree. The difference is that marketing segments are usually designed by hand, following the marketer's intuition, whereas decision trees generated automatically with machine learning tend to drill down into a larger number of smaller, more specific subsegments. Also, decision trees usually have a larger group of candidate variables to select from than does handmade segmentation. We could call it hyper-segmentation.
- The game “20 Questions.” To pass time during long car rides, you think of something and your opponent tries to guess what it is, narrowing down the possibilities by asking up to 20 yes/no questions. Your knowledge for playing this game can be formed into a decision tree. In fact, you can play “Guess the Dictator or Sitcom Character” against the computer at www.smalltime.com/Dictator; if, after asking yes/no questions, it comes up dry, it will add the person you were thinking of to its internal decision tree by saying “I give up” and asking for a new yes/no question (a new variable) with which to expand the tree. My first computer in 1980 came with this game (“Animal,” on the Apple][+). It kept the decision tree saved on my 5¼″ floppy disk.
Learn Baby Learn
Old statisticians never die; they just get broken down by age and sex.
—Anonymous
Let's keep growing on Chase's data. This is the fun part: pushing the “go” button, which feels like pressing the gas pedal did the first time you drove a car. There's a palpable source of energy at your disposal: the data, and the power to expose discoveries from it. As the tree grows downward, defining smaller subsegments that are more specific and precise, it feels like a juice squeezer that is crushing out knowledge juice. If there are ways in which human behavior follows patterns, the patterns can't escape undetected—they'll be squeezed out into view.
Before modeling, data must be properly arranged in order to access its predictive potential. Like preparing crude oil, it takes a concerted effort to prepare this digital resource as learning data (aka training data). This involves organizing the data so two time frames are juxtaposed: (1) stuff we knew in the past, and (2) the outcome we'd like to predict, which we came to find out later. It's all in the past—history from which to learn—but pairing and relating these two distinct points in time is an essential mechanical step, a prerequisite that makes learning to predict possible. This data preparation phase can be quite tedious, an involved hands-on technical process often more cumbersome than anticipated, but it's a small price to pay.9
Given this potent load of prepared training data, PA software is ready to pounce. “If only these walls could speak…” Actually, they can. Machine learning is a universal translator that gives a voice to data.
Here's the tree on Chase mortgage data after several more learning steps (this depiction has less annotation—per convention, go left for “yes” and right for “no”):

Learning has now discovered 10 distinct segments (tree leaves), with risk levels ranging from 2.6 percent all the way up to 40 percent. This wide variety means something is working. The process has successfully found groups that differ greatly from one another in the likelihood the thing being predicted—prepayment—will happen. Thus, it has learned how to rank by future probabilities.
To be predicted, an individual tumbles down the tree from top to bottom like a ball in the pinball-like game Pachinko, cascading down through an obstacle course of pins, bouncing left and right. For example, Sally Smithers, the example mortgage customer from earlier in this chapter, starts at the top (tree root) and answers yes/no questions:
- Q: Interest rate < 7.94 percent?
- A: No, go right.
- Q: Mortgage < $182,926?
- A: Yes, go left.
- Q: Loan-to-value ratio < 87.4 percent?
- A: Yes, go left (the loan is less than 87.4 percent of the property value).
- Q: Mortgage < $67,751?
- A: No, go right.
- Q: Interest rate < 8.69 percent?
- A: No, go right.
Thus, Sally comes to a landing in the segment with a 25.6 percent propensity. The average risk overall is 9.4 percent, so this tells us there is a relatively high chance she will prepay her mortgage.
Business rules are found along every path from root to leaf. For example, following the path Sally took, we derive a rule that applies to Sally as well as many other homeowners like her (the path has five steps, but the rule can be summarized in fewer lines because some steps revisit the same variable):
Bigger Is Better
Continuing to grow the mortgage risk model, the learning process goes further and lands on an even bigger tree, with 39 segments (leaves), that has this shape to it:

A decision tree with 39 segments.
As the decision tree becomes bigger and more complex, the predictive performance continues to increase, but more gradually. There are diminishing returns.
A single metric compares the performance of predictive models: lift. A common measure, lift is a kind of predictive multiplier. It tells you how many more target customers you can identify with a model than without one.
Think of the value of prediction from the perspective of the bank. Every prepayment is the loss of a profitable customer. More broadly, the departure of customers is called customer attrition, churn, or defection. Predicting customer attrition helps target marketing outreach designed to keep customers around. Offers designed to retain customers are expensive, so instead of contacting every borrower, the bank must target very precisely.
- What's predicted: Which customers will leave.
- What's done about it: Retention efforts target at-risk customers.
Suppose the bank stands to lose 10 percent of its mortgage borrowers. Without a predictive model, the only way to be sure to reach all of them is to contact every single borrower. More realistically, if the marketing budget will allow only one in five borrowers to be contacted, then by selecting randomly without a model, only one in five of those customers soon to be lost will be contacted (on average). Of course, with a crystal ball that predicted perfectly, we could zero in on just the right customers—wouldn't that be nice! Instead, with a less fantastical but reasonably accurate predictive model, we can target much more effectively.
Three times more effectively, to be precise. With the full-sized decision tree model shown previously, it turns out that the 20 percent scored as most high risk includes 60 percent of all the would-be defectors. That is 300 percent as many as without the model, so we say that the model has a lift of three at the 20 percent mark. The same marketing budget now has three times as many opportunities to save a defecting customer as before. The bank's bang for its marketing buck just tripled.
The trees we've seen achieve various lifts at the 20 percent mark:
| Decision Tree | Lift at 20 Percent |
| 4 segments | 2.5 |
| 10 segments | 2.8 |
| 39 segments | 3.0 |
As the tree gets bigger, it keeps getting better, so why stop there? Shall we keep going? Slow down, Icarus! I've got a bad feeling about this.
Overlearning: Assuming Too Much
If you torture the data long enough, it will confess.
—Ronald Coase, Professor of Economics, University of Chicago
There are three kinds of lies: lies, damned lies, and statistics.
—British Prime Minister Benjamin Disraeli (quote popularized by Mark Twain)
An unlimited amount of computational resources is like dynamite: If used properly, it can move mountains. Used improperly, it can blow up your garage or your portfolio.
—David Leinweber, Nerds on Wall Street
A few years ago, Berkeley Professor David Leinweber made waves with his discovery that the annual closing price of the S&P 500 stock market index could have been predicted from 1983 to 1993 by the rate of butter production in Bangladesh. Bangladesh's butter production mathematically explains 75 percent of the index's variation over that time. Urgent calls were placed to the Credibility Police, since it certainly cannot be believed that Bangladesh's butter is closely tied to the U.S. stock market. If its butter production boomed or went bust in any given year, how could it be reasonable to assume that U.S. stocks would follow suit? This stirred up the greatest fears of PA skeptics and vindicated nonbelievers. Eyebrows were raised so vigorously, they catapulted Professor Leinweber onto national television.
Crackpot or legitimate educator? It turns out Leinweber had contrived this analysis as a playful publicity stunt, within a chapter entitled “Stupid Data Miner Tricks” in his book Nerds on Wall Street. His analysis was designed to highlight a common misstep by exaggerating it. It's dangerously easy to find ridiculous correlations, especially when you're “predicting” only 11 data points (annual index closings for 1983 to 1993). By searching through a large number of financial indicators across many countries, something or other will show similar trends, just by chance. For example, shiver me timbers, a related study showed buried treasure discoveries in England and Wales predicted the Dow Jones Industrial Average a full year ahead from 1992 to 2002.
Predictive modeling can worsen this problem. If, instead of looking at how one factor simply shadows another, you apply the dynamics of machine learning to create models that combine factors, the match can appear even more perfect. It's a catchphrase favored by naysayers: “Hey, throw in something irrelevant like the daily temperature as another factor, and a regression model gets better—what does that say about this kind of analysis?” Leinweber got as far as 99 percent accuracy predicting the S&P 500 by allowing a regression model to work with not only Bangladesh's butter production, but Bangladesh's sheep population, U.S. butter production, and U.S. cheese production. As a lactose-intolerant data scientist, I protest!
Leinweber attracted the attention he sought, but his lesson didn't seem to sink in. “I got calls for years asking me what the current butter business in Bangladesh was looking like and I kept saying, ‘Ya know, it was a joke, it was a joke!’ It's scary how few people actually get that.” As Black Swan author Nassim Taleb put it in his suitably titled book, Fooled by Randomness, “Nowhere is the problem of induction more relevant than in the world of trading—and nowhere has it been as ignored!” Thus the occasional overzealous yet earnest public claim of economic prediction based on factors like women's hemlines, men's necktie width, Super Bowl results, and Christmas day snowfall in Boston.
The culprit that kills learning is overlearning (aka overfitting). Overlearning is the pitfall of mistaking noise for information, assuming too much about what has been shown within data. You've overlearned if you've read too much into the numbers, led astray from discovering the underlying truth.
Decision trees can overlearn like nobody's business. Just keep growing the tree deeper and deeper—a clear temptation—until each leaf narrows down to just one individual in the training data. After all, if a rule in the tree (formed by following a path from root to leaf) references many variables, it can eliminate all but one individual. But such a rule isn't general; it applies to only one case. Believing in such a rule is accepting proof by example. In this way, a large tree could essentially memorize the entire training data. You've only rewritten the data in a new way.
Rote memorization is the antithesis of learning. Say you're teaching a high school class and you give your students the past few years of final exams to help them study for the exam they'll take next week. If a student simply memorizes the answer to each question in the prior exams, he hasn't actually learned anything and he won't do well on a new exam with all-new questions. Our learning machine has got to be a better student than that.
Even without going to that extreme, striking a delicate balance between learning and overlearning is a profound challenge. For any predictive model a pressing question persists: Has it learned something true that holds in general, or has it discovered patterns that only hold within this data set? How can we be confident a model will work tomorrow when it is called upon to predict under unique circumstances never before encountered?
The Conundrum of Induction
It must be allowed that inductive investigations are of a far higher degree of difficulty and complexity than any questions of deduction.
—William Stanley Jevons, economist and logician, 1874
To understand God's thoughts, we must study statistics, for these are the measure of his purpose.
—Florence Nightingale
Though this be madness, yet there is method in it.
—Hamlet, by William Shakespeare
Life would be so much easier if we only had the source code.
—Hacker aphorism
The objective of machine learning is induction:
Induction—Reasoning from detailed facts to general principles.
This is not to be confused with deduction, which is essentially the very opposite:
Deduction—Reasoning from the general to the particular (or from cause to effect).
Deduction is much more straightforward. It's just applying known rules. If all men are mortal and Socrates is a man, then deduction tells us Socrates is mortal.
Induction is an art form. At our disposal we have a detailed manifestation of how the world works: data's recording of what happened. From that we seek to generalize, to draw grand conclusions, to ascertain patterns that will hold true in situations not yet seen. We attempt to reverse engineer the world's laws and principles. It's the discovery of the method in the madness.
Although a kind of reasoning, induction always behaves unreasonably. This is because it must be based on overly simplistic assumptions. Assumptions are key to the inductive leap we strive to take. You simply cannot design a learning method without them. We don't know enough about the way the world works to design perfect learning. If we did, we wouldn't need machine learning to begin with. For example, with decision trees, the implicit assumption is that the rules within a decision tree, as simple as they may be, are an astute way to capture and express true patterns.
Carnegie Mellon professor Tom Mitchell, founding chair of the world's first machine learning department and the author of the first academic textbook on the subject, Machine Learning, calls this kind of assumption an inductive bias. Establishing these foundational assumptions—part and parcel to inventing new induction methods—is the art behind machine learning. There's no one best answer, no one learning method that always wins above all others. It depends on the data.10
Machine induction and the induction of birth have something in common. In both cases, there's a genesis.
The Art and Science of Machine Learning
The method is to modify your model incrementally. Tweak the technique, geek, improving it incessantly. Each step is taken to improve prediction on the training cases. One small step for man; one giant leap—the human race is going places!
Modeling methods vary, but they all face the same challenge: to learn as much as possible, yet not learn too much. Among the competing approaches to machine learning, decision trees are often considered the most user friendly, since they consist of rules you can read like a long (if cumbersome) English sentence, while other methods are more mathy, taking the variables and plugging them into equations.
Most learning methods search for a good predictive model, starting with a trivially simple and often inept model and tweaking it repeatedly, as if applying “genetic mutations,” until it evolves into a robust prediction apparatus. In the case of a decision tree, the process starts with a small tree and grows it. In the case of most mathematical equation-based methods, it starts with a random model by selecting random parameters and then repeatedly nudges the parameters until the equation is predicting well. For all learning techniques, the training data guides each tweak as it strives to improve prediction across that data set. To put names on the mathy methods that compete with decision trees, they include artificial neural networks, loglinear regression, support vector machines, and TreeNet.
Machine learning's ruthless, incessant adaptation displays an eerie power. It even discovers and exploits weaknesses or loopholes inadvertently left in place by the data scientist. In one project with my close friend Alex Chaffee (a multitalented software architect), we set up the computer to “evolve” a Tetris game player, learning how to decide where to drop each piece while playing the game. In one run of the system, we accidentally reversed the objective (a single errant minus sign instead of a plus sign within thousands of lines of computer code!) so that, instead of striving to tightly pack the game pieces, it was rewarded for packing less densely by creating big, vacant holes. Before we realized it was chasing a bug, we were perplexed to see the resulting game player stacking pieces up diagonally from the bottom left of the game board to the top right, a creative way to play as poorly as possible.11 It conjures the foreboding insight of brooding scientist Ian Malcolm in Michael Crichton's dinosaur thriller Jurassic Park: “Life finds a way.”
Regardless of the learning technique and its mathematical sophistication, there's always the potential to overlearn. After all, commanding a computer to learn is like teaching a blindfolded monkey to design a fashion diva's gown. The computer knows nothing. It has no notion of the meaning behind the data, the concept of what a mortgage, salary, or even a house is. The numbers are just numbers. Even clues like “$” and “%” don't mean anything to the machine. It's a blind, mindless automaton stuck in a box forever enduring its first day on the job.
Every attempt to predictively model faces this central challenge to establish general principles and weed out the noise, the artifacts peculiar only to the limited data at hand. It's the nature of the problem. Even if there are millions or billions of examples in the data from which to learn, it's still a limited portion compared to how many conceivable situations could be encountered in the future. The number of possible combinations that may form a learning example is exponential. And so, architecting a learning process that strikes the balance between learning too much and too little is elusive and mysterious to even the most hard-core scientist.
In solving this conundrum, art comes before science, but the two are both critical components. Art enables it to work, and science proves it works:
- Artistic design: Research scientists craft machine learning to attempt to avert overlearning, often based on creative ideas that sound just brilliant.
- Scientific measure: The predictive model's performance is objectively evaluated.
In the case of number 2, though, what method of evaluation could possibly suffice? If we can't entirely trust the design of machine learning, how can we trust a measure of its performance? Of course, all predictions could be evaluated by simply waiting to see if they come true. But since we plan to pay heed to a model's predictions and take actions accordingly, we must establish confidence in the model immediately. We need an almost instantaneous means to gauge performance so that, if overlearning takes place, it can be detected and the course of learning corrected by backtracking and trying again.
Feeling Validated: Test Data
The proof is in the pudding.
There's no fancy math required to test for true learning. Don't get me wrong; they've tried. Theoretical work abounds—these deep thinkers have even met for their 28th Annual Conference on Learning Theory. But the results to date are limited. It seems impossible to design a learning method that's guaranteed not to overlearn. It's a seriously hard scientific problem.
Instead, a clever, mind-numbingly simple trick is employed to test for overlearning: Hold aside some data to test the model. Randomly select a test set (aka validation or out-of-sample set) and quarantine it. Use only the remaining portion of data, the training set, to create the model. Then, evaluate the resulting model across the test set. Since the test set was not used to create the model, there's no way the model could have captured its esoteric aspects, its eccentricities. The model didn't have the opportunity to memorize it in any way. Therefore, however well the model does on the test set is a reasonable estimation of how well the model does in general, a true evaluation of its ability to predict. For evaluating the model, the test set is said to be unbiased.

No mathematical theory, no advanced science, just an elegant, practical solution. This is how it's done, always. It's common practice. Every predictive modeling software tool has a built-in routine to hold aside and evaluate over test data. And every research journal article reports predictive performance over test data (unless you're poking fun at the industry's more egregious errors with a humorous example about Bangladesh's butter and the stock market).12
There's one downside to this approach. You sacrifice the opportunity to learn from the examples in the test set, generating the model only from the now-smaller training set. Typically this is a loss of 20 percent or 30 percent of the training data, which is held aside as test data. But the training set that remains is often plenty big, and the sacrifice is a small price to pay for a true measure of performance.
Following this practice, let's take a look at the true test performance of the decision tree models we've looked at so far. Recall that the lift performance of our increasingly larger trees, as evaluated over the 21,816 cases in the training set, was:
| Decision Tree | Lift at 20 Percent on the Training Set |
| 4 segments | 2.5 |
| 10 segments | 2.8 |
| 39 segments | 3.0 |
It turns out, for these trees, no overlearning took place. As evaluated on another 5,486 examples that had been held aside all along as the test set, the lifts for these three models held at 2.5, 2.8, and 3.0, respectively. Success!
| Decision Tree | Lift on the Training Set | Lift on the Test Set |
| 4 segments | 2.5 | 2.5 |
| 10 segments | 2.8 | 2.8 |
| 39 segments | 3.0 | 3.0 |
Keep going, though, and you'll pass your limit. If the tree gets even bigger, branching out to a greater number of smaller segments, learning will become overlearning. Taking it to an extreme, once we get to a tree with 638 segments (i.e., end points or leaves), the lift on the training set is 3.8, the highest lift yet. But the performance on that data, which was used to form the model in the first place, is a biased measure. Trying out this large tree on the test set reveals a lift of 2.4, lower than that of the small tree with only four segments.
| Decision Tree | Lift on the Training Set | Lift on the Test Set |
| 638 segments | 3.8 | 2.4 (overlearning) |
The test data guides learning, showing when it has worked and when it has gone too far.
Carving out a Work of Art
In every block of marble I see a statue as plain as though it stood before me, shaped and perfect in attitude and action. I have only to hew away the rough walls that imprison the lovely apparition to reveal it to the other eyes as mine see it.
—Michelangelo
Everything should be made as simple as possible, but not simpler.
—Albert Einstein (as paraphrased by Roger Sessions)
The decision tree fails unless we tame its wild growth. This presents a tough balance to strike. Like a parent, we strive to structure our progeny's growth and development so they're not out of control, and yet we cannot bear to quell creativity. Where exactly to draw the line?
When they first gained serious attention in the early 1960s, decision trees failed miserably, laughed out of court for their propensity to overlearn. “They were called ‘a recipe for learning something wrong,’” says Dan Steinberg. “This was a death sentence, like a restaurant with E. coli. Trees were finished.”
For those researchers who didn't give up on trees, formally defining the line between learning and overlearning proved tricky. It seemed as though, no matter where you drew the line, there was still a risk of learning too little or too much. Dramatic tension mounted like an unresolvable tug-of-war.
As with the theater, irony eases the tension. The most popular solution to this dilemma is ironic. Instead of holding back so as to avoid learning too much, don't hold back at all. Go all the way—learn way too much…and then take it all back, piece by piece, unlearning until you're back to square one and have learned too little. Set forth and make mistakes! Why? Because the mistakes are apparent only after you've made them.
In a word, grow the tree too big and bushy, and then prune it back. The trick is that pruning is guided not by the training data that determined the tree's growth, but by the testing data that now reveals where that growth went awry. It's an incredibly elegant solution that strikes the delicate balance between learning and overlearning.
To prune back a tree is to backtrack on steps taken, undoing some of machine learning's tweaks that have turned out to be faulty. By way of these undo's that hack and chop tree branches, a balanced model is unearthed, not timidly restricted and yet not overly self-confident. Like Michelangelo's statue, revealed within his block of marble by carving away the extraneous material that shrouds it, an effective predictive model is discovered within.
It's easy to take a wrong turn while building a predictive model. The important thing is to ensure that such steps are undone. In a training workshop I lead, trainees build predictive models by hand, following their own process of trial and error. When they try out a change that proves to hurt a model rather than improve it, they've been heard to exclaim, “Go back, go back—we should go back!”
To visualize the effect, consider the improvement of a decision tree during the training process:skiptop
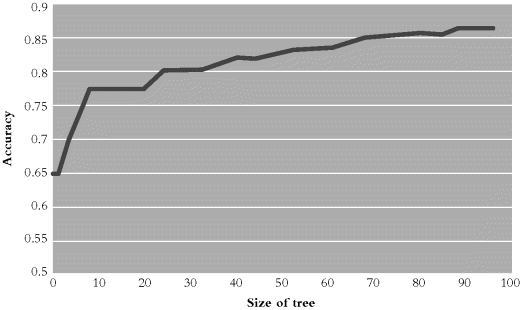
From Machine Learning, by Tom Mitchell
As shown, while the tree grows, the accuracy—as measured over the training data used to grow it—just keeps improving. But during the same growth process, if we test for true, unbiased accuracy over the test set, we see that it peaks early on, and then further growth makes for overlearning, only hurting its predictions:

From Machine Learning, by Tom Mitchell
Hedging these bushes follows the principle known as Occam's razor: Seek the simplest explanation for the data available. The philosophy is, by seeking more parsimonious models, you discover better models. This tactic defines part of the inductive bias that intentionally underlies decision trees. It's what makes them work. If you care about your model, give it a KISS: “Keep it simple, stupid!”
The leading decision tree modeling standard, called Classification and Regression Trees (CART), employs this elegant form of pruning, plus numerous other bells and whistles in its routines.13 CART was established by a 1984 book of the same name by four legendary researchers from Berkeley and Stanford: Leo Breiman, Jerome Friedman, Charles Stone, and Richard Olshen. I call them the “Fab Four.” As with most major inventions such as the television and the airplane, other parties released competing decision tree–based techniques around the same time, including researchers in Australia (ID3) and South Africa (CHAID). CART is the most commonly adopted; PA software tools from the likes of IBM and Dell include a version of CART. Dan Steinberg's company, Salford Systems, sells the only CART product codeveloped by the Fab Four, who are also investors.
An entrepreneurial scientist, Dan earned the Fab Four's trust to deliver CART from their research lab to the commercial world. Dan hails from Harvard with a PhD in econometrics. Not to put the CART before the horse, he founded his company soon after CART was invented.
The validation of machine learning methods such as CART is breaking news: “Human Intuition Achieves Astounding Success.” The fact that machine learning works tells us that we humans are smart enough—the hunches and intuitions that drive the design of methods to learn yet not overlearn pan out. I call this The Induction Effect:
Putting Decision Trees to Work for Chase
Dan agreed to help Chase with mortgage prediction (in a collaborative effort alongside a large consulting company), and the rubber hit the road. He pulled together a small team of scientists to apply CART to Chase's mortgage data.
Chase had in mind a different use of churn prediction than the norm.14 Most commonly, a company predicts which customers will leave (aka churn or defect—in the case of mortgage customers, prepay) in order to target retention activities meant to convince them to stay.
But Chase's plans put a new twist on the value of predicting churn. The bank intended to use the predictive scores to estimate the expected future value of individual mortgages in order to decide whether it would be a good move to sell them to other banks. Banks buy and sell mortgages at will. At any time, a mortgage could be sold based on its current market price, given the profile of the mortgage. But the market at large didn't have access to these predictive models, so Chase held a strong advantage. It could estimate the future value of a mortgage based on the predicted chance of prepayment. In a true manifestation of prediction's power, Chase could calculate whether selling a mortgage was likely to earn more than holding on to it. Each decision could be driven with prediction.
- What's predicted: Which mortgage holders will prepay within the next 90 days.
- What's done about it: Mortgages are valued accordingly in order to decide whether to sell them to other banks.
Chase intended to drive decisions across many mortgages with these predictions. Managing millions of mortgages, Chase was putting its faith in prediction to drive a large-scale number of decisions.
PA promised a tremendous competitive edge for Chase in the mortgage marketplace. While the market price for a mortgage depended on only several factors, a CART model incorporates many more variables, thus serving to more precisely predict each mortgage's future value.
With prediction, risk becomes opportunity. A mortgage destined to suffer the fate of prepayment is no longer bad news if it's predicted as such. By putting it up for sale accordingly, Chase could tip the outcome in its favor.
With data covering millions of mortgages, the amount available for analysis far surpassed the training set of about 22,000 cases employed to build the example decision trees depicted in this chapter. Plus, for each mortgage, there were in fact hundreds of predictor variables detailing its ins and outs, including summaries of the entire history of payments, home neighborhood data, and other information about the individual consumer. As a result, the project demanded 200 gigabytes of storage. You could buy this much today for $25 and place it into your pocket, but in the late 1990s, the investment was about $250,000, and the storage unit was the size of a refrigerator.
The Chase project required numerous models, each specialized for a different category of mortgage. CART trees were grown separately for fixed-rate versus variable-rate mortgages, for mortgages of varying terms, and at different stages of tenure. After grouping the mortgages accordingly, a separate decision tree was generated for each group. Since each tree addressed a different type of situation, the trees varied considerably, employing their own particular group of variables in divergent ways. Dan's team delivered these eclectic decision trees to Chase for integration into the bank's systems.
Money Grows on Trees
The undertaking was an acclaimed success. People close to the project at Chase reported that the predictive models generated millions of dollars of additional profit during the first year of deployment. The models correctly identified 74 percent of mortgage prepayments before they took place, and drove the management of mortgage portfolios successfully.15
As an institution, Chase was bolstered by this success. To strengthen its brand, it issued press releases touting its competency with advanced analytics.
Soon after the project launch, in 2000, Chase achieved yet another mammoth milestone to expand. It managed to buy JPMorgan, thus becoming JPMorgan Chase, now the largest U.S. bank by assets.
The Recession—Why Microscopes Can't Detect Asteroid Collisions
Needless to say, PA didn't prevent the global financial crisis that began several years later, in late 2007. That wasn't its job. Applied to avert microrisks, PA packs a serious punch. But tackling macroscopic risk is a completely different ballgame. PA is designed to rank individuals by their relative risk, but not to adjust the absolute measurements of risk when a broad shift in the economic environment is nigh. The predictive model operates on variables about the individual, such as age, education, payment history, and property type. These factors don't change even as the world around the individual changes, so the predictive score for the individual doesn't change, either.16
Predicting macroscopic risk is a tall order, with challenges surpassing those of microrisk prediction. The pertinent factors can be intangible and human. As the New York Times's Saul Hansell put it, “Financial firms chose to program their risk-management systems with overly optimistic assumptions…. Wall Street executives had lots of incentives to make sure their risk systems didn't see much risk.” Professor Bart Baesens of the University of Southampton's Centre for Risk Research adds, “There's an inherent tension between conservative instincts and profit-seeking motives.” If we're not measuring and reporting on the truth, there's no analytical cure.
Efforts in economic theory attempt to forecast macroscopic events, although such work in forecasting is not usually integrated within the scope of PA. However, Baesens has suggested, “By incorporating macroeconomic factors into a model, we can perform a range of data-driven stress tests.” Such work must introduce a new set of variables in order to detect worldwide shifts and requires a different analytical approach, since there are no sets of training data replete with an abundance of Black Swan events from which PA may learn. The rarest things in life are the hardest to predict.
After Math
Decision trees vanquish, but do they satisfy the data scientist's soul? They're understandable to the human eye when viewed as rules, each one an interpretable (albeit clunky) English sentence. This is surely an advantage for some organizations, but on other occasions we'd gladly exchange simplicity for performance.
In the next chapter, we pursue Netflix's heated public competition to outpredict movie ratings. Fine-tuning predictive performance is the name of the game. Must souping up model precision involve overwhelming complexity, or is there an elegant way to build and scale?