
![]()
XQuery and XPath
As we described in Chapter 12, SQL Server 2014 continues the high level of XML integration begun in SQL Server 2005. As part of that integration, SQL Server’s xml data type provides built-in functionality for shredding XML data into relational format, querying XML nodes and singleton atomic values via XQuery, and modifying XML data via XML Data Modification Language (XML DML). This chapter focuses on how to get the most out of SQL Server’s implementation of the powerful and flexible XPath and XQuery standards.
The XML data model represents a departure from the relational model SQL Server developers know so well. XML is not a replacement for the relational model, but it does nicely complement relational data. XML is very useful for sharing data with a wide variety of web services and message systems including MSMQ and disparate systems, and highly structured XML data from remote data sources is often shredded to relational format for easy storage and querying. The SQL Server 2014 xml data type and XML-specific query and conversion tools represent a marriage of some of the best features of relational database and XML technologies.
![]() Note This chapter is not meant to be a comprehensive guide to XPath and XQuery, but rather an introduction to SQL Server’s XPath and XQuery implementations, which are both subsets of the W3C XPath 2.0 and XQuery 1.0 recommendations. In addition to the discussion in this chapter, Appendix B provides a reference to the XQuery Data Model (XDM) type system as implemented by SQL Server.
Note This chapter is not meant to be a comprehensive guide to XPath and XQuery, but rather an introduction to SQL Server’s XPath and XQuery implementations, which are both subsets of the W3C XPath 2.0 and XQuery 1.0 recommendations. In addition to the discussion in this chapter, Appendix B provides a reference to the XQuery Data Model (XDM) type system as implemented by SQL Server.
XPath and FOR XML PATH
The FOR XML PATH clause of the SELECT statement uses XPath 2.0-style path expressions to specify the structure of the XML result. Listing 13-1 demonstrates a simple FOR XML PATH query that returns the names and e-mail addresses of people in the AdventureWorks database. Partial results are shown in Figure 13-1, which you can display by clicking on the XML within the column.
Listing 13-1. Retrieving Names and E-mail Addresses with FOR XML PATH
SELECT
p.BusinessEntityID AS "Person/ID",
p.FirstName AS "Person/Name/First",
p.MiddleName AS "Person/Name/Middle",
p.LastName AS "Person/Name/Last",
e.EmailAddress AS "Person/Email"
FROM Person.Person p INNER JOIN Person.EmailAddress e
ON p.BusinessEntityID = e.BusinessEntityID
FOR XML PATH, ROOT('PersonEmailAddress'),

Figure 13-1. Partial Results of Retrieving Names and E-mail Addresses with FOR XML PATH
Because they are used specifically to define the structure of an XML result, FOR XML PATH XPath expressions are somewhat limited in their functionality. Specifically, you cannot use features that contain certain filter criteria or use absolute paths. Briefly, here are the restrictions:
- A FOR XML PATH XPath expression may not begin or end with the /step operator, and it may not begin with, end with, or contain //.
- FOR XML PATH XPath expressions cannot specify axis specifiers such as child:: or parent::.
- The . (context node) and .. (context node parent) axis specifiers are not allowed.
- The functions defined in Part 4 of the XPath specification, Core Function Library, are not allowed.
- Predicates, which are used to filter result sets, are not allowed. [ position() = 4 ] is an example of a predicate.
Basically, the FOR XML PATH XPath subset allows you to specify the structure of the resulting XML relative to the implicit root node. This means that advanced functionality of XPath expressions above and beyond defining a simple relative path expression is not allowed. In general, XPath 2.0 features that can be used to locate specific nodes, return sets of nodes, or filter result sets are not allowed with FOR XML PATH.
By default, FOR XML PATH uses the name row for the root node of each row it converts to XML format. The results of FOR XML PATH also default to an element-centric format, meaning that results are defined in terms of element nodes.
In Listing 12-1, we’ve aliased the column names using the XPath expressions that define the structure of the XML result. Because the XPath expressions often contain characters that are not allowed in SQL identifiers, you will probably want to use quoted identifiers.
SELECT p.BusinessEntityID AS “Person/ID”, p.FirstName AS “Person/Name/First”, p.MiddleName AS “Person/Name/Middle”, p.LastName AS “Person/Name/Last”, e.EmailAddress AS “Person/Email”
XPath expressions are defined as a path separated by step operators. The step operator (/) indicates that a node is a child of the preceding node. For instance, the XPath expression Person/ID in the example indicates that a node named ID will be created as a child of the node named Person in a hierarchical XML structure.
Alternatively, you can define a relational column as an attribute of a node. Listing 13-2 modifies Listing 13-1 slightly to demonstrates this. We’ve shown the differences between the two listings in bold print. Partial results are shown in Figure 13-2, reformatted slightly for easier reading.
Listing 13-2. FOR XML PATH Creating XML Attributes
SELECT p.BusinessEntityID AS "Person/@ID",
e.EmailAddress AS "Person/@Email",
p.FirstName AS "Person/Name/First",
p.MiddleName AS "Person/Name/Middle",
p.LastName AS "Person/Name/Last"
FROM Person.Person p INNER JOIN Person.EmailAddress e
ON p.BusinessEntityID = e.BusinessEntityID FOR XML PATH;

Figure 13-2. Creating Attributes with FOR XML PATH
The bold portion of the SELECT statement in Listing 13-2 generates XML attributes of the ID and Email nodes by preceding their names in the XPath expression with the @ symbol. The result is that ID and Email become attributes of the Person element in the result:
p.BusinessEntityID AS "Person/@ID", e.EmailAddress AS "Person/@Email",
Columns without Names and Wildcards
Some of the other XPath expression features you can use with FOR XML PATH include columns without names and wildcard expressions, which are turned into inline content. The sample in Listing 13-3 demonstrates this.
Listing 13-3. Using Columns without Names and Wildcards with FOR XML PATH
SELECT p.BusinessEntityID AS "*", ',' + e.EmailAddress,
p.FirstName AS "Person/Name/First",
p.MiddleName AS "Person/Name/Middle",
p.LastName AS "Person/Name/Last" FROM Person.Person p INNER JOIN Person.EmailAddress e
ON p.BusinessEntityID = e.BusinessEntityID FOR XML PATH;
In this example, the XPath expression for BusinessEntityID is the wildcard character *. The second column is defined as ',' + EmailAddress and the column is not given a name. Both of these columns are turned into inline content immediately below the row element, as shown in Figure 13-3. This is particularly useful functionality when creating lists within your XML data, or when your XML data conforms to a schema that looks for combined, concatenated, or list data in XML text nodes.

Figure 13-3. Columns without Names and Wildcard Expressions in FOR XML PATH
As you saw in the previous examples, FOR XML PATH groups together nodes that have the same parent elements. For instance, the First, Middle, and Last elements are all children of the Name element. They are grouped together in all of the examples because of this. However, as shown in Listing 13-4, this is not the case when these elements are separated by an element with a different parent element.
Listing 13-4. Two Elements with a Common Parent Element Separated
SELECT p.BusinessEntityID AS "@ID",
e.EmailAddress AS "@EmailAddress",
p.FirstName AS "Person/Name/First",
pp.PhoneNumber AS "Phone/BusinessPhone",
p.MiddleName AS "Person/Name/Middle",
p.LastName AS "Person/Name/Last"
FROM Person.Person p
INNER JOIN Person.EmailAddress e
ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN Person.PersonPhone pp
ON p.BusinessEntityID = pp.BusinessEntityID
AND pp.PhoneNumberTypeID = 3 FOR XML PATH;
The results of this query include a new Phone element as a direct child of the Person element. Because this new element is positioned between the Person/Name/First and Person/Name/Middle elements, FOR XML PATH creates two separate Person/Name elements: one to encapsulate the First element, and another to encapsulate the Middle and Last elements, as shown in Figure 13-4.

Figure 13-4. Breaking Element Grouping with FOR XML PATH
The FOR XML PATH XPath expression provides support for a function called data(). If the column name is specified as data(), the value is treated as an atomic value in the generated XML. If the next item generated is also an atomic value, FOR XML PATH appends a space to the end of the data returned. This is useful for using subqueries to create lists of items, as in Listing 13-5, which demonstrates use of the data() function.
Listing 13-5. The FOR XML PATH XPath data Node Test
SELECT DISTINCT soh.SalesPersonID AS "SalesPerson/@ID", (
SELECT soh2.SalesOrderID AS "data()"
FROM Sales.SalesOrderHeader soh2
WHERE soh2.SalesPersonID = soh.SalesPersonID FOR XML PATH ('') ) AS "SalesPerson/@Orders",
p.FirstName AS "SalesPerson/Name/First",
p.MiddleName AS "SalesPerson/Name/Middle",
p.LastName AS "SalesPerson/Name/Last",
e.EmailAddress AS "SalesPerson/Email"
FROM Sales.SalesOrderHeader soh
INNER JOIN Person.Person p
ON p.BusinessEntityID = soh.SalesPersonID
INNER JOIN Person.EmailAddress e
ON p.BusinessEntityID = e.BusinessEntityID
WHERE soh.SalesPersonID IS NOT NULL FOR XML PATH;
This sample retrieves all SalesPerson ID numbers from the Sales.SalesOrderHeader table (eliminating NULLs for simplicity) and retrieves their names in the main query. The subquery uses the data() function to retrieve a list of each salesperson’s sales order numbers and places them in a space-separated list in the Orders attribute of the SalesPerson element. A sample of the results is shown in Figure 13-5.

Figure 13-5. Creating Lists with the data Node Test
The SQL Server 2014 FOR XML PATH expression provides access to both the text() function and the data() node test. In terms of FOR XML PATH, the text() function returns the data in the text node as inline text with no separator. The data() node test returns the data in the XML text node as a space-separated concatenated list.
In XQuery expressions, the data() node test, the text() function, and the related string() function all return slightly different results. The following code snippet demonstrates their differences:
DECLARE @x xml;
SET @x = N'<a>123<b>456</b><c>789</c></a><a>987<b>654</b><c>321</c></a>';
SELECT @x.query('/a/text()'),
SELECT @x.query('data(/a)'),
SELECT @x.query('string(/a[1])'),
The text() function in this example returns the concatenated text nodes of the <a> elements; in this example, it returns 123987.
The data() node test returns the concatenated XML text nodes of the <a> elements and all their child elements. In this example, data() returns 123456789 987654321, the concatenation of the <a> elements and the <b> and <c> subelements they contain. The data() node test puts a space separator between the <a> elements during the concatenation.
The string() function is similar to the data() node test in that it concatenates the data contained in the specified element and all child elements. The string() function requires a singleton node instance, which is why we specified string(/a[i]) in the example. The result of the string() function used in the example is 123456789. We’ll discuss the text() and string() functions in greater detail later in this chapter.
In all of the previous examples, FOR XML PATH maps SQL NULL to a missing element or attribute. Consider the results of Listing 13-1 for Kim Abercrombie, shown in Figure 13-6. Because her MiddleName in the table is NULL, the Name/Middle element is missing from the results.
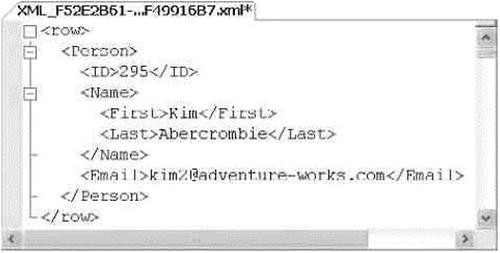
Figure 13-6. NULL Middle Name Eliminated from the FOR XML PATH Results
If you want SQL NULL-valued elements and attributes to appear in the final results, use the ELEMENTS XSINIL option of the FOR XML clause, as shown in Listing 13-6.
Listing 13-6. FOR XML with the ELEMENTS XSINIL Option
SELECT
p.BusinessEntityID AS "Person/ID",
p.FirstName AS "Person/Name/First",
p.MiddleName AS "Person/Name/Middle",
p.LastName AS "Person/Name/Last",
e.EmailAddress AS "Person/Email" FROM Person.Person p INNER JOIN Person.EmailAddress e
ON p.BusinessEntityID = e.BusinessEntityID FOR XML PATH,
ELEMENTS XSINIL;
With the ELEMENTS XSINIL option, Kim’s results now look like the results shown in Figure 13-7. The FOR XML PATH clause adds a reference to the xsi namespace, and elements containing SQL NULL are included but marked with the xsi:nil="true" attribute.

Figure 13-7. NULL Marked with the xsi:nil Attribute
Namespace support is provided for FOR XML clauses and other XML functions by the WITH XMLNAMESPACES clause. The WITH XMLNAMESPACES clause is added to the front of your SELECT queries to specify XML namespaces to be used by FOR XML clauses or xml data type methods. Listing 13-7 demonstrates the use of the WITH XMLNAMESPACES clause with FOR XML PATH.
Listing 13-7. Using WITH XMLNAMESPACES to Specify Namespaces
WITH XMLNAMESPACES('http://www.apress.com/xml/sampleSqlXmlNameSpace' as ns)
SELECT
p.BusinessEntityID AS "ns:Person/ID",
p.FirstName AS "ns:Person/Name/First",
p.MiddleName AS "ns:Person/Name/Middle",
p.LastName AS "ns:Person/Name/Last",
e.EmailAddress AS "ns:Person/Email"
FROM Person.Person p
INNER JOIN Person.EmailAddress e
ON p.BusinessEntityID = e.BusinessEntityID
FOR XML PATH;
The WITH XMLNAMESPACES clause in this example declares a namespace called ns with the URI http://www.apress.com/xml/sampleSqlXmlNameSpace. The FOR XML PATH clause adds this namespace prefix to the Person element, as indicated in the XPath expressions used to define the structure of the result. A sample of the results is shown in Figure 13-8.

Figure 13-8. Adding an XML Namespace to the FOR XML PATH Results
In addition to the previous options, the FOR XML PATH XPath implementation supports four node tests, including the following:
- The text() node test turns the string value of a column into a text node.
- The comment() node test turns the string value of a column into an XML comment.
- The node() node test turns the string value of a column into inline XML content; it is the same as using the wildcard * as the name.
- The processing-instruction(name) node test turns the string value of a column into an XML-processing instruction with the specified name.
Listing 13-8 demonstrates use of XPath node tests as column names in a FOR XML PATH query. The results are shown in Figure 13-9.
Listing 13-8. FOR XML PATH Using XPath Node Tests
SELECT
p.NameStyle AS "processing-instruction(nameStyle)",
p.BusinessEntityID AS "Person/@ID",
p.ModifiedDate AS "comment()",
pp.PhoneNumber AS "text()",
FirstName AS "Person/Name/First",
MiddleName AS "Person/Name/Middle",
LastName AS "Person/Name/Last",
EmailAddress AS "Person/Email"
FROM Person.Person p
INNER JOIN Person.EmailAddress e
ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN Person.PersonPhone pp
ON p.BusinessEntityID = pp.BusinessEntityID
FOR XML PATH;

Figure 13-9. Using Node Tests with FOR XML PATH
In this example, the NameStyle column value is turned into an XML-processing instruction called nameStyle, the ModifiedDate column is turned into an XML comment, and the contact PhoneNumber is turned into a text node for each person in the AdventureWorks database.
XQuery and the xml Data Type
XQuery represents the most advanced standardized XML querying language to date. Designed as an extension to the W3C XPath 2.0 standard, XQuery is a case-sensitive, declarative, functional language with a rich type system based on the XDM. The SQL Server 2014 xml data type supports querying of XML data using a subset of XQuery via the query() method. Before diving into the details of the SQL Server implementation, we are going to start this section with a discussion of XQuery basics.
XQuery introduces several advances on the concepts introduced by XPath and other previous XML query tools and languages. Two of the most important concepts in XQuery are expressions and sequences. A sequence is an ordered collection of items—either nodes or atomic values. The word ordered, as it applies to sequences, does not necessarily mean numeric or alphabetic order. Sequences are generally in document order (the order in which their contents appear in the raw XML document or data) by default, unless you specify a different ordering. The roughly analogous XPath 1.0 structure was known as a node set, a name that implies ordering was unimportant. Unlike the relational model, however, the order of nodes is extremely important to XML. In XML, the ordering of nodes and content provides additional context and can be just as important as the data itself. The XQuery sequence was defined to ensure that the importance of proper ordering is recognized. There are also some other differences that we will cover later in this section.
Sequences can be returned by XQuery expressions or created by enclosing one of the following in parentheses:
- Lists of items separated by the comma operator (,)
- Range expressions
- Filter expressions
![]() Tip Range expressions and the range expression keyword to are not supported in SQL Server 2014 XQuery. If you are converting an XQuery with range expressions like (1 to 10), you will have to modify it to run on SQL Server 2014.
Tip Range expressions and the range expression keyword to are not supported in SQL Server 2014 XQuery. If you are converting an XQuery with range expressions like (1 to 10), you will have to modify it to run on SQL Server 2014.
A sequence created as a list of items separated by the comma operator might look like the following:
(1, 2, 3, 4, (5, 6), 7, 8, (), 9, 10)
The comma operator evaluates each of the items in the sequence and concatenates the result. Sequences cannot be nested, so any sequences within sequences are “flattened out.” Also, the empty sequence (a sequence containing no items, denoted by empty parentheses: ()) is eliminated. Evaluation of the previous sample sequence results in the following sequence of ten items:
(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
Notice that the nested sequence (5, 6) has been flattened out, and the empty sequence () is removed during evaluation.
![]() Tip SQL Server 2014 XQuery does not support the W3C-specified sequence operators union, intersect, and except. If you are porting XQuery code that uses these operators, it will have to be modified to run on SQL Server 2008.
Tip SQL Server 2014 XQuery does not support the W3C-specified sequence operators union, intersect, and except. If you are porting XQuery code that uses these operators, it will have to be modified to run on SQL Server 2008.
Another method of generating a sequence is with a filter expression. A filter expression is a primary expression followed by zero or more predicates. An example of a filter expression to generate a sequence might look like the following:
(//Coordinates/*/text())
An important property of sequences is that a sequence of one item is indistinguishable from a singleton atomic value. So the sequence (1.0) is equivalent to the singleton atomic value 1.0.
Sequences come in three flavors: empty sequences, homogeneous sequences, and heterogeneous sequences. Empty sequences are sequences that contain no items. As mentioned before, the empty sequence is annotated with a set of empty parentheses: ().
Homogeneous sequences are sequences of one or more items of the same or compatible types. The examples already given are all examples of homogenous sequences.
Heterogeneous sequences are sequences of two or more items of incompatible types, or singleton atomic types and nodes. The following is an example of a heterogeneous sequence:
(“Harry”, 299792458, xs:date(“2006-12-29Z”))
SQL Server does not allow heterogeneous sequences that mix nodes with singleton atomic values. Trying to declare the following sequence results in an error:
(<tag/>, “you are it!”)
![]() Note Singleton atomic values are defined as values that are in the value space of the atomic types. The value space is the complete set of values that can be expressed with a given type. For instance, the complete value space for the xs:boolean type is true and false. Singleton atomic values are indivisible for purposes of the XDM standard (although you can extract portions of their content in some situations). Values that fall into this space are decimals, integers, dates, strings, and other primitive data types.
Note Singleton atomic values are defined as values that are in the value space of the atomic types. The value space is the complete set of values that can be expressed with a given type. For instance, the complete value space for the xs:boolean type is true and false. Singleton atomic values are indivisible for purposes of the XDM standard (although you can extract portions of their content in some situations). Values that fall into this space are decimals, integers, dates, strings, and other primitive data types.
Primary expressions are the building blocks of XQuery. An expression in XQuery evaluates to a singleton atomic value or a sequence. Primary expressions can be any of several different items, including the following:
- Literals: These include string and numeric data type literals. String literals can be enclosed in either single or double quotes and may contain the XML-defined entity references >, <, &, ", and ', or Unicode character references such as €, which represents the euro symbol (€).
- Variable references: These are XML-qualified names (QNames) preceded by a $ sign. A variable reference is defined by its local name. Note that SQL Server 2012 does not support variable references with namespace URI prefixes, which are allowed under the W3C recommendation. An example of a variable reference is $count.
- Parenthesized expressions: These are expressions enclosed in parentheses. Parenthesized expressions are often used to force a specific order of operator evaluation. For instance, in the expression (3 + 4) * 2, the parentheses force the addition to be performed before the multiplication.
- Context item expressions: These are expressions that evaluate to the context item. The context item is the node or atomic value currently being referenced by the XQuery query engine.
- Function calls: These are composed of a QName followed by a list of arguments in parentheses. Function calls can reference built-in functions. SQL Server 2014 does not support XQuery user-defined functions.
The query() method can be used to query and retrieve XML nodes from xml variables or xml-typed columns in tables, as demonstrated in Listing 13-9, with partial results shown in Figure 13-10.
Listing 13-9. Retrieving Job Candidates with the query Method
SELECT Resume.query
(
N'//*:Name.First,
//*:Name.Middle,
//*:Name.Last,
//*:Edu.Level'
)
FROM HumanResources.JobCandidate;

Figure 13-10. Sample Job Candidate Returned by the query Method
The simple XQuery query retrieves all first names, middle names, last names, and education levels for all AdventureWorks job candidates. The XQuery path expressions in the example demonstrate some key XQuery concepts, including the following:
- The first item of note is the // axis at the beginning of each path expression. This axis notation is defined as shorthand for the descendant-or-self::node(), which we’ll describe in more detail in the next section. This particular axis retrieves all nodes with a name matching the location step, regardless of where it occurs in the XML being queried.
- In the example, the four node tests specified are Name.First, Name.Middle, Name.Last, and Edu.Level. All nodes with the names that match the node tests are returned no matter where they occur in the XML.
- The * namespace qualifier is a wildcard that matches any namespace occurring in the XML. Each node in the result node sequence includes an xmlns namespace declaration.
- This XQuery query is composed of four different paths denoting the four different node sequences to be returned. They are separated from one another by commas.
The location path determines which nodes should be accessed by XQuery. Following a location path from left to right is generally analogous to moving down and to the right in your XML node tree (there are exceptions, of course, which we discuss in the section on axis specifiers). If the first character of the path expression is a single forward slash (/), then the path expression is an absolute location path, meaning that it starts at the root of the XML. Listing 13-10 demonstrates the use of an XQuery absolute location path. The results are shown in Figure 13-11.
Listing 13-10. Querying with an Absolute Location Path
DECLARE @x xml = N'<?xml version = "1.0"?>
<Geocode>
<Info ID = "1">
<Coordinates Resolution = "High">
<Latitude>37.859609</Latitude>
<Longitude>-122.291673</Longitude>
</Coordinates>
<Location Type = "Business">
<Name>APress, Inc.</Name>
</Location>
</Info>
<Info ID = "2">
<Coordinates Resolution = "High">
<Latitude>37.423268</Latitude>
<Longitude>-122.086345</Longitude>
</Coordinates>
<Location Type = "Business">
<Name>Google, Inc.</Name>
</Location>
</Info>
</Geocode>';
SELECT @x.query(N'/Geocode/Info/Coordinates'),

Figure 13-11. Absolute Location Path Query Result
![]() Tip The left-hand forward slash actually stands for a conceptual root node that encompasses your XML input. The conceptual root node doesn’t actually exist, and can neither be viewed in your XML input nor accessed or manipulated directly. It’s this conceptual root node that allows XQuery to properly process XML fragments that are not well formed (i.e., XML with multiple root nodes) as input. Using a path expression that consists of only a single forward slash returns every node below the conceptual root node in your XML document or fragment.
Tip The left-hand forward slash actually stands for a conceptual root node that encompasses your XML input. The conceptual root node doesn’t actually exist, and can neither be viewed in your XML input nor accessed or manipulated directly. It’s this conceptual root node that allows XQuery to properly process XML fragments that are not well formed (i.e., XML with multiple root nodes) as input. Using a path expression that consists of only a single forward slash returns every node below the conceptual root node in your XML document or fragment.
Listing 13-10 defines an xml variable and populates it with an XML document containing geocoding data for a couple of businesses. We’ve used an absolute location path in the query to retrieve a node sequence of the latitude and longitude coordinates for the entire XML document.
A relative location path indicates a path relative to the current context node. The context node is the current node being accessed by the XQuery engine at a given point when the query is executed. The context node changes during execution of the query. Relative location paths are specified by excluding the leading forward slash, as in the following modification to Listing 13-10:
SELECT @x.query(N'Geocode/Info/Coordinates'),
And, as previously mentioned, using a double forward slash (//) in the lead position returns nodes that match the node test anywhere they occur in the document. The following modification to Listing 13-10 demonstrates this:
SELECT @x.query(N'//Coordinates'),
In addition, the wildcard character (*) can be used to match any node by name. The following example retrieves the root node, all of the nodes on the next level, and all Coordinates nodes below that:
SELECT @x.query(N'//*/*/Coordinates'),
Because the XML document in the example is a simple one, all the variations of Listing 13-10 return the same result. For more complex XML documents or fragments, the results of different relative location paths could return completely different results.
The node tests in the previous example are simple name node tests. For a name node test to return a match, the nodes must have the same names as those specified in the node tests. In addition to name node tests, SQL Server 2014 XQuery supports four node kind tests, as listed in Table 13-1.
Table 13-1. Supported Node Tests
|
Node Kind Test |
Description |
|---|---|
|
comment() |
Returns true for a comment node only. |
|
node() |
Returns true for any kind of node. |
|
processing-instruction("name") |
Returns true for a processing instruction node. The name parameter is an optional string literal. If it is included, only processing instruction nodes with that name are returned; if not included, all processing instructions are returned. |
|
text() |
Returns true for a text node only. |
![]() Tip Keep in mind that XQuery, like XML, is case sensitive. This means your node tests and other identifiers must all be of the proper case. The identifier PersonalID, for instance, does not match personalid in XML or XQuery. Also note that your database collation case sensitivity settings do not affect XQuery queries.
Tip Keep in mind that XQuery, like XML, is case sensitive. This means your node tests and other identifiers must all be of the proper case. The identifier PersonalID, for instance, does not match personalid in XML or XQuery. Also note that your database collation case sensitivity settings do not affect XQuery queries.
Listing 13-11 demonstrates use of the processing-instruction() node test to retrieve the processing instruction from the root level of a document for one product model. The results are shown in Figure 13-12.
Listing 13-11. Sample Processing-instruction Node Test
SELECT CatalogDescription.query(N'/processing-instruction()') AS Processing_Instr
FROM Production.ProductModel
WHERE ProductModelID = 19;

Figure 13-12. Results of the Processing-instruction Node Test Query
The sample can be modified to retrieve all XML comments from the source by using the comment() node test, as in Listing 13-12. The results are shown in Figure 13-13.
Listing 13-12. Sample comment Node Test
SELECT CatalogDescription.query(N'//comment()') AS Comments
FROM Production.ProductModel
WHERE ProductModelID = 19;

Figure 13-13. Results of the comment Node Test Query
Listing 13-13 demonstrates use of another node test, node(), to retrieve the specifications for product model 19. Results are shown in Figure 13-14.
Listing 13-13. Sample node Node Test
SELECT CatalogDescription.query(N'//*:Specifications/node()') AS Specifications
FROM Production.ProductModel
WHERE ProductModelID = 19;

Figure 13-14. Results of the node Node Test Query
SQL Server 2014 XQuery does not support other node kind tests specified in the XQuery recommendation. Specifically, the schema-element(), schema-attribute(), and document-node() kind tests are not implemented. SQL Server 2013 also doesn’t provide support for type tests, which are node tests that let you query nodes based on their associated type information.
You might notice that the first node of the result shown in Figure 13-14 is not enclosed in XML tags. This node is a text node located in the Specifications node being queried. You might also notice that the * namespace wildcard mentioned previously is used in this query. This is because namespaces are declared in the XML of the CatalogDescription column. Specifically the root node declaration looks like this:
<pl:ProductDescription xmlns:pl="http://schemas.microsoft.com/sqlserver/2004![]() 07/adventure-works/ProductModelDescription" xmlns:wm="http://schemas.microsoft.com/sqlserver/2004/07/
07/adventure-works/ProductModelDescription" xmlns:wm="http://schemas.microsoft.com/sqlserver/2004/07/![]()
adventure-works/ProductModelWarrAndMain" xmlns:wf="http://www.adventure-works.com/schemas/OtherFeatures" xmlns:html="http://www.w3.org/1999/xhtml" ProductModelID="l9" ProductModelName="Mountain 100">
The Specifications node of the XML document is declared with the pi namespace in the document. Not using a namespace in the query at all, as shown in Listing 13-14, results in an empty sequence being returned (no matching nodes).
Listing 13-14. Querying CatalogDescription with No Namespaces
SELECT CatalogDescription.query(N'//Specifications/node()') AS Specifications
FROM Production.ProductModel
WHERE ProductModelID = 19;
In addition to the wildcard namespace specifier, you can use the XQuery prolog to define namespaces for use in your query. Listing 13-15 shows how the previous example can be modified to include the p1 namespace with a namespace declaration in the prolog.
Listing 13-15. Prolog Namespace Declaration
SELECT CatalogDescription.query
(
N'declare namespace
p1 = "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
//p1:Specifications/node()'
)
FROM Production.ProductModel
WHERE ProductModelID = 19;
The keywords declare namespace allow you to declare specific namespaces that will be used in the query. You can also use the declare default element namespace keywords to declare a default namespace, as in Listing 13-16.
Listing 13-16. Prolog Default Namespace Declaration
SELECT CatalogDescription.query
(
N'declare default element namespace
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
//Specifications/node()'
)
FROM Production.ProductModel
WHERE ProductModelID = 19;
Declaring a default namespace with the declare default element namespace keywords allows you to eliminate namespace prefixes in your location paths (for steps that fall within the scope of the default namespace, of course). Listings 13-15 and 13-16 both generate the same result as the query in Listing 13-13.
![]() Tip You can also use the T-SQL WITH XMLNAMESPACES clause, described previously in this chapter, to declare namespaces for use by xml data type methods.
Tip You can also use the T-SQL WITH XMLNAMESPACES clause, described previously in this chapter, to declare namespaces for use by xml data type methods.
SQL Server defines an assortment of predeclared namespaces that can be used in your queries. With the exception of the xml namespace, you can redeclare these namespaces in your queries using the URIs of your choice. The predeclared namespaces are listed in Table 13-2.
Table 13-2. SQL Server Predeclared XQuery Namespaces
|
Namespace |
URI |
Description |
|---|---|---|
|
Fn |
XQuery 1.0, XPath 2.0, XSLT 2.0 functions and operators namespace. | |
|
Sqltypes |
This namespace provides SQL Server 2005 to base type mapping. | |
|
Xdt |
XQuery 1.0/XPath 2.0 data types namespace. | |
|
Xml |
Default XML namespace. | |
|
Xs |
XML schema namespace. | |
|
Xsi |
XML schema instance namespace; XMLSchema-instance. |
![]() Tip The W3C-specified local functions namespace, local (http://www.w3.org/2005/xquery-local-functions), is not predeclared in SQL Server. SQL Server 2014 does not support XQuery user-defined functions.
Tip The W3C-specified local functions namespace, local (http://www.w3.org/2005/xquery-local-functions), is not predeclared in SQL Server. SQL Server 2014 does not support XQuery user-defined functions.
Another useful namespace is http://www.w3.org/2005/xqt-errors, which is the namespace for XPath and XQuery function and operator error codes. In the XQuery documentation, this URI is bound to the namespace err, though this is not considered normative.
Axis specifiers define the direction of movement of a location path step relative to the current context node. The XQuery standard defines several axis specifiers, which can be defined as forward axes or reverse axes. SQL Server 2014 supports a subset of these axis specifiers, as listed in Table 13-3.
Table 13-3. SQL 2014 Supported Axis Specifiers
|
Axis Name |
Direction |
Description |
|---|---|---|
|
child:: |
Forward |
Retrieves the children of the current context node. |
|
descendant:: |
Forward |
Retrieves all descendents of the current context node, recursive style. This includes children of the current node, children of the children, and so on. |
|
self:: |
Forward |
Contains just the current context node. |
|
descendant-or-self:: |
Forward |
Contains the context node and children of the current context node. |
|
attribute:: |
Forward |
Returns the specified attribute(s) of the current context node. This axis specifier may be abbreviated using an at sign (@). |
|
parent:: |
Reverse |
Returns the parent of the current context node. This axis specifier may be abbreviated as two periods (..). |
In addition, the context-item expression, indicated by a single period (.), returns the current context item (which can be either a node or an atomic value). The current context item is the current node or atomic value being processed by the XQuery engine at any given point during query execution.
![]() Note The following axes, defined as optional axes by the XQuery 1.0 specification, are not supported by SQL Server 2014: following-sibling::, following::, ancestor::, preceding-sibling::, preceding::, ancestor-or-self::, and the deprecated namespace::. If you are porting XQuery queries from other sources, they may have to be modified to avoid these axis specifiers.
Note The following axes, defined as optional axes by the XQuery 1.0 specification, are not supported by SQL Server 2014: following-sibling::, following::, ancestor::, preceding-sibling::, preceding::, ancestor-or-self::, and the deprecated namespace::. If you are porting XQuery queries from other sources, they may have to be modified to avoid these axis specifiers.
In all of the examples so far, the axis has been omitted, and the default axis of child:: is assumed by XQuery in each step. Because child:: is the default axis, the two queries in Listing 13-17 are equivalent.
Listing 13-17. Query with and Without Default Axes
SELECT CatalogDescription.query(N'//*:Specifications/node()') AS Specifications
FROM Production.ProductModel
WHERE ProductModelID = 19;
SELECT CatalogDescription.query(N'//child::*:Specifications/child::node()')
AS Specifications
FROM Production.ProductModel
WHERE ProductModelID = 19;
Listing 13-18 demonstrates the use of the parent:: axis to retrieve Coordinates nodes from the sample XML.
Listing 13-18. Sample Using the parent:: Axis
DECLARE @x xml = N'<?xml version = "1.0"?>
<Geocode>
<Info ID = "1">
<Coordinates Resolution = "High">
<Latitude>37.859609</Latitude>
<Longitude>-122.291673</Longitude>
</Coordinates>
<Location Type = "Business">
<Name>APress, Inc.</Name>
</Location>
</Info>
<Info ID = "2">
<Coordinates Resolution = "High">
<Latitude>37.423268</Latitude>
<Longitude>-122.086345</Longitude>
</Coordinates>
<Location Type = "Business">
<Name>Google, Inc.</Name>
</Location>
</Info>
</Geocode>';
SELECT @x.query(N'//Location/parent::node()/Coordinates'),
This particular query locates all Location nodes, then uses the parent:: axis to retrieve their parent nodes (Info nodes), and finally returns the Coordinates nodes, which are children of the Info nodes. The end result is shown in Figure 13-15.

Figure 13-15. Retrieving Coordinates Nodes with the parent:: Axis
The XQuery 1.0 recommendation is based on XPath 2.0, which is in turn based largely on XPath 1.0. The XPath 1.0 recommendation was designed to consolidate many of the best features of both the W3C XSLT and XPointer recommendations. One of the benefits of XQuery’s lineage is its ability to query XML and dynamically construct well-formed XML documents from the results. Consider the example in Listing 13-19, which uses an XQuery direct constructor to create an XML document. Figure 13-16 shows the results.
Listing 13-19. XQuery Dynamic XML Construction
DECLARE @x xml = N'<?xml version = "1.0"?>
<Geocode>
<Info ID = "1">
<Location Type = "Business">
<Name>APress, Inc.</Name>
</Location>
</Info>
<Info ID = "2">
<Location Type = "Business">
<Name>Google, Inc.</Name>
</Location>
</Info>
</Geocode>';
SELECT @x.query(N'<Companies>
{
//Info/Location/Name
}
</Companies>'),

Figure 13-16. Dynamic Construction of XML with XQuery
The direct constructor in the XQuery example looks like this:
<Companies>
{
//Info/Location/Name
}
</Companies>
The <Companies> and </Companies> opening and closing tags in the direct constructor act as the root tag for the XML result. The opening and closing tags contain the content expression, which consists of the location path used to retrieve the nodes. The content expression is wrapped in curly braces between the <Companies> and </Companies> tags:
{
//Info/Location/Name
}
![]() Tip If you need to output curly braces in your constructed XML result, you can escape them by doubling them up in your query using {{ and }}.
Tip If you need to output curly braces in your constructed XML result, you can escape them by doubling them up in your query using {{ and }}.
You can also use the element, attribute, and text computed constructors to build your XML result, as demonstrated in Listing 13-20, with the result shown in Figure 13-17.
Listing 13-20. Element and Attribute Dynamic Constructors
SELECT CatalogDescription.query
(
N'declare namespace
p1 = "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
//p1:Specifications/node()'
)
FROM Production.ProductModel
WHERE ProductModelID = 19;
DECLARE @x xml = N'<?xml version = "1.0"?>
<Geocode>
<Info ID = "1">
<Location Type = "Business">
<Name>APress, Inc.</Name>
<Address>
<Street>2560 Ninth St, Ste 219</Street>
<City>Berkeley</City>
<State>CA</State>
<Zip>94710-2500</Zip>
<Country>US</Country>
</Address>
</Location>
</Info>
</Geocode>';
SELECT @x.query
(
N'element Companies
{
element FirstCompany
{
attribute CompanyID
{
(//Info/@ID)[1]
},
(//Info/Location/Name)[1]
}
}'
);

Figure 13-17. Results of the XQuery Computed Element Construction
The element Companies computed element constructor creates the root Companies node. The FirstCompany node is constructed as a child node using another element constructor:
element Companies
{
element FirstCompany
{
...
}
}
The content expressions of the FirstCompany elements are where the real action takes place:
element FirstCompany
{
attribute CompanyID
{
(//Info/@ID)[1]
},
(//Info/Location/Name)[1]
}
The CompanyID dynamic attribute constructor retrieves the ID attribute from the first Info node. The predicate [l] in the path ensures that only the first //Info/@ID is returned. This path location could also be written like this:
//Info[l]/@ID
The second path location retrieves the first Name node for the first Location node of the first Info node. Again, the [1] predicate ensures that only the first matching node is returned. The path is equivalent to the following:
//Info[l]/Location[l]/Name[l]
To retrieve the second node, change the predicate to [2], and so on.
![]() Tip By definition, a predicate that evaluates to a numeric singleton value (such as the integer constant 1) is referred to as a numeric predicate. The effective Boolean value is true only when the context position is equal to the numeric predicate expression. When the numeric predicate is 3, for instance, the predicate truth value is true only for the third context position. This is a handy way to limit the results of an XQuery query to a single specific node.
Tip By definition, a predicate that evaluates to a numeric singleton value (such as the integer constant 1) is referred to as a numeric predicate. The effective Boolean value is true only when the context position is equal to the numeric predicate expression. When the numeric predicate is 3, for instance, the predicate truth value is true only for the third context position. This is a handy way to limit the results of an XQuery query to a single specific node.
XQuery Comments
XQuery comments (not to be confused with XML comment nodes) are used to document your queries inline. You can include them in XQuery expressions by enclosing them with the (: and :) symbols (just like the smiley face emoticon). Comments can be used in your XQuery expressions anywhere ignorable whitespace is allowed, and they can be nested. XQuery comments have no effect on query processing. The following example modifies the query in Listing 13-19 to include XQuery comments:
SELECT @x.query ( N'<Companies> (: This is the root node :) {
//Info/Location/Name (: Retrieves all company names (: ALL of them :) :) } </Companies>' );
You will see XQuery comments used in some of the examples later in this chapter.
XQuery maintains the string value and typed value for all nodes in the referenced XML. XQuery defines the string value of an element node as the concatenated string values of the element node and all its child element nodes. The type of a node is defined in the XML schema collection associated with the xml variable or column. As an example, the built-in AdventureWorks Production.ManuInstructionsSchemaCollection XML schema collection defines the LocationID attribute of the Location element as an xsd:integer:
<xsd:attribute name="LocationID" type="xsd:integer" use="required" />
Every instance of this attribute in the XML of the Instructions column of the Production.ProductModel table must conform to the requirements of this data type. Typed data can also be manipulated according to the functions and operators defined for this type. For untyped XML, the typed data is defined as xdt:untypedAtomic. A listing of XDM data types available to SQL Server via XQuery is given in Appendix B.
An XQuery predicate is an expression that evaluates to one of the xs:boolean values true or false. In XQuery, predicates are used to filter the results of a node sequence, discarding nodes that don’t meet the specified criteria from the results. Predicates limit the results by converting the result of the predicate expression into an xs:boolean value, referred to as the predicate truth value. The predicate truth value is determined for each item of the input sequence according to the following rules:
- If the type of the expression is numeric, the predicate truth value is true if the value of the predicate expression is equal to the context position; otherwise for a numeric predicate, the predicate truth value is false.
- If the type of the expression is a string, the predicate is false if the length of the expression is 0. For a string type expression with a length greater than 0, the predicate truth value is true.
- If the type of the expression is xs:boolean, the predicate truth value is the value of the expression.
- If the expression results in an empty sequence, the predicate truth value is false.
- If the value of the predicate expression is a node sequence, the predicate truth value is true if the sequence contains at least one node; otherwise it is false.
Queries that include a predicate return only nodes in a sequence for which the predicate truth value evaluates to true. Predicates are composed of expressions, conveniently referred to as predicate expressions, enclosed in square brackets ([ ]). You can specify multiple predicates in a path, and they are evaluated in order of occurrence from left to right.
![]() Note The XQuery specification says that multiple predicates are evaluated from left to right, but it also gives some wiggle room for vendors to perform predicate evaluations in other orders, allowing them to take advantage of vendor-specific features such as indexes and other optimizations. You don’t have to worry too much about the internal evaluation order of predicates, though. No matter what order predicates are actually evaluated in, the end results have to be the same as if the predicates were evaluated left to right.
Note The XQuery specification says that multiple predicates are evaluated from left to right, but it also gives some wiggle room for vendors to perform predicate evaluations in other orders, allowing them to take advantage of vendor-specific features such as indexes and other optimizations. You don’t have to worry too much about the internal evaluation order of predicates, though. No matter what order predicates are actually evaluated in, the end results have to be the same as if the predicates were evaluated left to right.
As we mentioned, the basic function of predicates is to filter results. Results are filtered by specified comparisons, and XQuery offers a rich set of comparison operators. These operators fall into three main categories: value comparison operators, general comparison operators, and node comparison operators. Value comparison operators compare singleton atomic values only. Trying to compare sequences with value comparison operators results in an error. The value comparison operators are listed in Table 13-4.
Table 13-4. Value Comparison Operators
|
Operator |
Description |
|---|---|
|
Eq |
Equal |
|
Ne |
Not equal |
|
Lt |
Less than |
|
Le |
Less than or equal to |
|
Gt |
Greater than |
|
Ge |
Greater than or equal to |
Value comparisons follow a specific set of rules:
- The operands on the left and right sides of the operator are atomized.
- If either atomized operand is an empty sequence, the result is an empty sequence.
- If either atomized operand is a sequence with a length greater than 1, an error is raised.
- If either atomized operand is of type xs:untypedAtomic, it is cast to xs:string.
- If the operands have compatible types, they are compared using the appropriate operator. If the comparison of the two operands using the chosen operator evaluates to true, the result is true; otherwise the result is false. If the operands have incompatible types, an error is thrown.
Consider the value comparison examples in Listing 13-21, with results shown in Figure 13-18.
Listing 13-21. Value Comparison Examples
DECLARE @x xml = N'<?xml version = "1.0" ?>
<Animal>
Cat
</Animal>';
SELECT @x.query(N'9 eq 9.0 (: 9 is equal to 9.0 :)'),
SELECT @x.query(N'4 gt 3 (: 4 is greater than 3 :)'),
SELECT @x.query(N'(/Animal/text())[1] lt "Dog" (: Cat is less than Dog :)') ;

Figure 13-18. Results of the XQuery Value Comparisons
Listing 13-22 attempts to compare two values of incompatible types, namely an xs:decimal type value and an xs:string value. The result is the error message shown in the results following.
Listing 13-22. Incompatible Type Value Comparison
DECLARE @x xml = N'';
SELECT @x.query(N'3.141592 eq "Pi"') ;
Msg 2234, Level 16, State 1, Line 2
XQuery [query()]: The operator "eq" cannot be applied to "xs:decimal" and "xs:string" operands.
General comparisons are existential comparisons that work on operand sequences of any length. Existential simply means that if one atomized value from the first operand sequence fulfills a value comparison with at least one atomized value from the second operand sequence, the result is true. The general comparison operators will look familiar to programmers who are versed in other computer languages, particularly C-style languages. The general comparison operators are listed in Table 13-5.
Table 13-5. General Comparison Operators
|
Operator |
Description |
|---|---|
|
= |
Equal |
|
!= |
Not equal |
|
< |
Less than |
|
> |
Greater than |
|
<= |
Less than or equal to |
|
>= |
Greater than or equal to |
Listing 13-23 demonstrates comparisons using general comparisons on XQuery sequences. The results are shown in Figure 13-19.
Listing 13-23. General Comparison Examples
DECLARE @x xml = '';
SELECT @x.query('(3.141592, 1) = (2, 3.141592) (: true :) '),
SELECT @x.query('(1.0, 2.0, 3.0) = 1 (: true :) '),
SELECT @x.query('("Joe", "Harold") < "Adam" (: false :) '),
SELECT @x.query('xs:date("1999-01-01") < xs:date("2006-01-01") (: true :)'),

Figure 13-19. General XQuery Comparison Results
Here’s how the general comparison operators work. The first query compares the sequences (3.141592, 1) and (2, 3.141592) using the = operator. The comparison atomizes the two operand sequences and compares them using the rules for the equivalent value comparison operators. Since the atomic value 3.141592 exists in both sequences, the equality test result is true.
The second example compares the sequence (1.0, 2.0, 3.0) to the atomic value 1. The atomic values 1.0 and 1 are compatible types and are equal, so the equality test result is true. The third query returns false because neither of the atomic values Doe or Harold are lexically less than the atomic value Adam.
The final example compares two xs:date values. Since the date 1999-01-01 is less than the date 2006-01-01, the result is true.
The XQuery implementation in SQL Server 2005 had a special requirement concerning xs:date, xs:time, xs:dateTime, and derived types. According to a subset of the ISO 8601 standard that SQL Server 2005 uses, date and time values had to include a mandatory time offset specifier. SQL Server 2014 does not strictly enforce this rule. When you leave the time offset information off an XQuery date or time value, SQL Server 2014 defaults to the zero meridian (Zspecifier).
SQL Server 2014 also differs from SQL Server 2005 in how it handles time offset information. In SQL Server 2005, all dates were automatically normalized to coordinated universal time (UTC). SQL Server 2014 stores the time offset information you indicate when specifying a date or time value. If a time zone is provided, it must follow the date or time value, and can be either of the following:
The capital letter Z, which stands for the zero meridian, or UTC. The zero meridian runs through Greenwich, England.
An offset from the zero meridian in the format [+/-]hh:mm. For instance, the US Eastern Time zone would be indicated as -05:00.
Here are a few sample ISO 8601 formatted dates and times acceptable to SQL Server, with descriptions:
- 1999-05-16: May 16,1999, no time, UTC
- 09:15:00-05:00: No date, 9:15 am, US and Canada Eastern time
- 2003-12-25T20:00:00-08:00: December 25, 2003, 8:00 pm, US and Canada Pacific time
- 2004-07-06T23:59:59.987+01:00: July 6, 2004,11:59:59.987 pm (.987 is fractional seconds), Central European time
Unlike the homogenous sequences in Listing 13-23, a heterogeneous sequence is one that combines nodes and atomic values, or atomic values of incompatible types (such as xs:string and xs:decimal). Trying to perform a general comparison with a heterogeneous sequence causes an error in SQL Server, as demonstrated by Listing 13-24.
Listing 13-24. General Comparison with Heterogeneous Sequence
DECLARE @x xml = '';
SELECT @x.query('(xs:date("2006-10-09"), 6.02E23) > xs:date("2007-01-01")'),
The error generated by Listing 13-24 looks like the following:
Msg 9311, Level 16, State 1, Line 3
XOuery [queryQ]: Heterogeneous sequences are not allowed in V, found
'xs:date' and 'xs:double'.
SQL Server also disallows heterogeneous sequences that mix nodes and atomic values, as demonstrated by Listing 13-25.
Listing 13-25. Mixing Nodes and Atomic Values in Sequences
DECLARE @x xml = '';
SELECT @x.query('(1, <myNode>Testing</myNode>)'),
Trying to mix and match nodes and atomic values in a sequence like this results in an error message indicating that you tried to create a sequence consisting of atomic values and nodes, similar to the following:
Msg 2210, Level 16, State 1, Line 3
XOuery [queryQ]: Heterogeneous sequences are not allowed: found
'xs:integer' and 'element(myllode,xdt:untyped)'
The third type of comparison that XQuery allows is a node comparison. Node comparisons allow you to compare XML nodes in document order. The node comparison operators are listed in Table 13-6.
Table 13-6. Node Comparison Operators
|
Operator |
Description |
|---|---|
|
Is |
Node identity equality |
|
<< |
Left node precedes right node |
|
>> |
Left node follows right node |
The is operator compares two nodes to each other and returns true if the left node is the same node as the right node. Note that this is not a test of the equality of node content but rather of the actual nodes themselves based on an internally generated node ID. Consider the sample node comparisons in Listing 13-26 with results shown in Figure 13-20.
Listing 13-26. Node Comparison Samples
DECLARE @x xml = N'<?xml version = "1.0"?>
<Root>
<NodeA>Test Node</NodeA>
<NodeA>Test Node</NodeA>
<NodeB>Test Node</NodeB>
</Root>';
SELECT @x.query('((/Root/NodeA)[1] is (//NodeA)[1]) (: true :)'),
SELECT @x.query('((/Root/NodeA)[1] is (/Root/NodeA)[2]) (: false :)'),
SELECT @x.query('((/Root/NodeA)[2] << (/Root/NodeB)[1]) (: true :)'),

Figure 13-20. Results of the XQuery Node Comparisons
The first query uses the is operator to compare (/Root/NodeA)[l] to itself. The [l] numeric predicate at the end of the path ensures that only a single node is returned for comparison. The right-hand and left-hand expressions must both evaluate to a singleton or empty sequence. The result of this comparison is true only because (/Root/NodeA)[l] is the same node returned by the (//NodeA)[l] path on the right-hand side of the operator.
The second query compares (/Root/NodeA)[l] with (/Root/NodeA)[2]. Even though the two nodes have the same name and content, they are in fact different nodes. Because they are different nodes, the is operator returns false.
The final query retrieves the second NodeA node with the path (/Root/NodeA)[2]. Then it uses the " operator to determine if this node precedes the NodeB node from the path (/Root/NodeB)[l]. Since the second NodeA precedes NodeB in document order, the result of this comparison is true.
A node comparison results in an xs:boolean value or evaluates to an empty sequence if one of the operands results in an empty sequence. This is demonstrated in Listing 13-27.
Listing 13-27. Node Comparison That Evaluates to an Empty Sequence
DECLARE @x xml = N'<?xml version = "1.0"?>
<Root>
<NodeA>Test Node</NodeA>
</Root>';
SELECT @x.query('((/Root/NodeA)[1] is (/Root/NodeZ)[1]) (: empty sequence :)'),
The result of the node comparison is an empty sequence because the right-hand path expression evaluates to an empty sequence (because no node named NodeZ exists in the XML document).
Conditional Expressions (if...then...else)
As shown in the previous examples, XQuery returns xs:boolean values or empty sequences as the result of comparisons. XQuery also provides support for the conditional if...then...else expression. The if...then...else construct returns an expression based on the xs:boolean value of another expression. The format for the XQuery conditional expression is shown in the following:
if (test-expression) then then-expression else else-expression
In this syntax, test-expression represents the conditional expression that is evaluated, the result of which will determine the returned result. When evaluating test-expression, XQuery applies the following rules:
- If test-expression results in an empty sequence, the result is false.
- If test-expression results in an xs:boolean value, the result is the xs:boolean value of the expression.
- If test-expression results in a sequence of one or more nodes, the result is true.
- If these steps fail, a static error is raised.
If test-expression evaluates to true, then-expression is returned. If test-expression evaluates to false, else-expression is returned.
The XQuery conditional is a declarative expression. Unlike the C# if...else statement and Visual Basic’s If...Then...Else construct, XQuery’s conditional if...then...else doesn’t represent a branch in procedural logic or a change in program flow. It acts like a function that accepts a conditional expression as input and returns an expression as a result. In this respect, XQuery’s if...then...else has more in common with the SQL CASE expression and the C# ?: operator than the if statement in procedural languages. In the XQuery if...then...else, syntax parentheses are required around test-expression, and the else clause is mandatory.
XQuery arithmetic expressions provide support for the usual suspects—standard mathematical operators found in most modern programming languages, including the following:
- Multiplication (*)
- Division (div)
- Addition (+)
- Subtraction (-)
- Modulo (mod)
SQL Server 2014 XQuery does not support the idiv integer division operator. Fortunately, the W3C XQuery recommendation defines the idiv operator as equivalent to the following div expression:
($argl div $arg2) cast as xs:integer?
If you need to convert XQuery code that uses idiv to SQL Server, you can use the div and cast operators as shown to duplicate idiv functionality.
XQuery also supports the unary plus (+) and unary minus (-) operators. Because the forward slash character is used as a path separator in XQuery, the division operator is specified using the keyword div. The modulo operator, mod, returns the remainder of division.
Of the supported operators, unary plus and unary minus have the highest precedence. Multiplication, division, and modulo are next. Binary addition and subtraction have the lowest precedence. Parentheses can be used to force the evaluation order of mathematical operations.
XQuery provides several built-in functions defined in the XQuery Functions and Operators specification (sometimes referred to as F&O), which is available at www.w3.org/TR/xquery-operators/ . Built-in XQuery functions are in the predeclared namespace fn.
![]() Tip The fn namespace does not have to be specified when calling a built-in function. Some people leave it off to improve readability of their code.
Tip The fn namespace does not have to be specified when calling a built-in function. Some people leave it off to improve readability of their code.
We’ve listed the XQuery functions that SQL Server 2014 supports in Table 13-7.
Table 13-7. Supported Built-in XQuery Functions
|
Function |
Description |
|---|---|
|
fn:avg(x) |
Returns the average of the sequence of numbers x. For example, fn:avg( (10, 20, 30, 40, 50) ) returns 30. |
|
fn:ceiling(n) |
Returns the smallest number without a fractional part that is not less than n. For example, fn:ceiling(1.1) returns 2. |
|
fn:concat(s1, s2, ...) |
Concatenates zero or more strings and returns the concatenated string as a result. For example, fn:concat("hi", ",", "how are you?") returns "hi, how are you?". |
|
fn:contains(s1, s2,) |
Returns true if the string s1 contains the string s2. For example, fn:contains("fish", "is") returns true. |
|
fn:count(x) |
Returns the number of items in the sequence x. For example, fn:count( (1, 2, 4, 8, 16) ) returns 5. |
|
fn:data(a) |
Returns the typed value of each item specified by the argument a. For example, fn:data( (3.141592, "hello") ) returns "3.141592 hello". |
|
fn:distinct-values(x) |
Returns the sequence x with duplicate values removed. For example, fn:distinct-values( (1, 2, 3, 4, 5, 4, 5) ) returns "1 2 3 4 5". |
|
fn:empty(i) |
Returns true if i is an empty sequence; returns false otherwise. For example, fn:empty( (1, 2, 3) ) returns false. |
|
fn:expanded-QName(u, l) |
Returns an xs:QName. The arguments u and l represent the xs:QName’s namespace URI and local name, respectively. |
|
fn:false() |
Returns the xs:boolean value false. For example, fn:false() returns false. |
|
fn:floor(n) |
Returns the largest number without a fractional part that is not greater than n. For example, fn:floor(1.1) returns 1. |
|
fn:id(x) |
Returns the sequence of element nodes with ID values that match one or more of the IDREF values supplied in x. The parameter x is treated as a whitespace-separated sequence of tokens. |
|
fn:last() |
Returns the index number of the last item in the sequence being processed. The first index in the sequence has an index of 1. |
|
fn:local-name(n) |
Returns the local name, without the namespace URI, of the specified node n. |
|
fn:local-name-from-QName(q) |
Returns the local name part of the xs:QName argument q. The value returned is an xs:NCName. |
|
fn:max(x) |
Returns the item with the highest value from the sequence x. For example, fn:max( (1.0, 2.5, 9.3, 0.3, -4.2) ) returns 9.3. |
|
fn:min(x) |
Returns the item with the lowest value from the sequence x. For example, fn:min( ("x", "q", "u", "e", "r", "y") ) returns "e". |
|
fn:namespace-uri(n) |
Returns the namespace URI of the specified node n. |
|
fn:namespace-uri-from-QName(q) |
Returns the namespace URI part of the xs:QName argument q. The value returned is an xs:NCName. |
|
fn:not(b) |
Returns true if the effective Boolean value of b is false; returns false if the effective Boolean value is true. For example, fn:not(xs:boolean("true")) returns false. |
|
fn:number(n) |
Returns the numeric value of the node indicated by n. For example, fn:number("/Root/NodeA[1]"). |
|
fn:position() |
Returns the index number of the context item in the sequence currently being processed. |
|
fn:round(n) |
Returns the number closest to n that does not have a fractional part. For example, fn:round(10.5) returns 11. |
|
fn:string(a) |
Returns the value of the argument a, expressed as an xs:string. For example, fn:string(3.141592) returns "3.141592". |
|
fn:string-length(s) |
Returns the length of the string s. For example, fn:string- length("abcdefghij") returns 10. |
|
fn:substring(s, m, n) |
Returns n characters from the string s, beginning at position m. If n is not specified, all characters from position m to the end of the string are returned. The first character in the string is position 1. For example, fn:substring("Money", 2, 3) returns "one". |
|
fn:sum(x) |
Returns the sum of the sequence of numbers in x. For example, fn:sum( (1, 4, 9, 16, 25) ) returns 55. |
|
fn:true() |
Returns the xs:boolean value true. For example, fn:true() returns true. |
In addition, two functions from the sql: namespace are supported. The sql:column function allows you to expose and bind SQL Server relational column data in XQuery queries. This function accepts the name of an SQL column and exposes its values to your XQuery expressions. Listing 13-28 demonstrates the sql:column function.
Listing 13-28. The sql:column Function
DECLARE @x xml = N'';
SELECT @x.query(N'<Name>
<ID>
{
sql:column("p.BusinessEntityID")
}
</ID>
<FullName>
{
sql:column("p.FirstName"),
sql:column("p.MiddleName"),
sql:column("p.LastName")
}
</FullName>
</Name>')
FROM Person.Person p
WHERE p.BusinessEntityID <= 5
ORDER BY p.BusinessEntityID;
The result of this example, shown in Figure 13-21, is a set of XML documents containing the BusinessEntitylD and full name of the first five contacts from the Person.Person table.

Figure 13-21. Results of the sql:column Function Query
The sql variable function goes another step, allowing you to expose T-SQL variables to XQuery. This function accepts the name of a T-SQL variable and allows you to access its value in your XQuery expressions. Listing 13-29 is an example that combines the sql:column and sql:variable functions in a single XQuery query.
Listing 13-29. XQuery sql:column and sql:variable Functions Example
/* 10% discount */
DECLARE @discount NUMERIC(3, 2);
SELECT @discount = 0.10;
DECLARE @x xml;
SELECT @x = '';
SELECT @x.query('<Product>
<Model-ID> { sql:column("ProductModelID") }</Model-ID>
<Name> { sql:column("Name") }</Name>
<Price> { sql:column("ListPrice") } </Price>
<DiscountPrice>
{ sql:column("ListPrice") -
(sql:column("ListPrice") * sql:variable("@discount") ) }
</DiscountPrice>
</Product>
')
FROM Production.Product p
WHERE ProductModelID = 30;
The XQuery generates XML documents using the sql:column function to retrieve the ListPrice from the Production.Product table. It also uses the sql:variable function to calculate a discount price for the items retrieved. Figure 13-22 shows partial results of this query (formatted for easier reading):

Figure 13-22. Partial Results of the Query with the sql:column and sql:variable Functions
The XDM provides constructor functions to dynamically create instances of several supported types. The constructor functions are all in the format xs:TYP(value), where TYP is the XDM type name. Most of the XDM data types have constructor functions; however, the following types do not have constructors in SQL Server XQuery: xs:yearMonthDuration, xs:dayTimeDuration, xs: OName, xs:NMTOKEN, and xs:NOTATION.
The following are examples of XQuery constructor functions:
xs:boolean("1") (: returns true :)
xs:integer(1234) (: returns 1234 :)
xs:float(9.8723E+3) (: returns 9872.3 :)
xs:NCName("my-id") (: returns the NCName "my-id" :)
Numeric types can be implicitly cast to their base types (or other numeric types) by XQuery to ensure proper results of calculations. The process of implicit casting is known as type promotion. For instance, in the following sample expression, the xs:integer type value is promoted to an xs:decimal to complete the calculation:
xs:integer(100) + xs:decimal(l00.99)
![]() Note Only numeric types can be implicitly cast. String and other types cannot be implicitly cast by XQuery.
Note Only numeric types can be implicitly cast. String and other types cannot be implicitly cast by XQuery.
Explicit casting is performed using the cast as keywords. Examples of explicit casting include the following:
xs:string("98d3f4") cast as xs:hexBinary? (: 98d3f4 :)
100 cast as xs:double? (: 1.0E+2 :)
"0" cast as xs:boolean? (: true :)
The ? after the target data type is the optional occurrence indicator. It is used to indicate that an empty sequence is allowed. SQL Server XQuery requires the ? after the cast as expression. SQL Server BOL provides a detailed description of the XQuery type casting rules at http://msdn.microsoft.com/en-us/library/ms191231.aspx.
The instance of Boolean operator allows you to determine the type of a singleton value. This operator takes a singleton value on its left side and a type on its right. The xs:boolean value true is returned if the atomic value represents an instance of the specified type. The following examples demonstrate the instance of operator:
10 instance of xs:integer (: returns true :) 100 instance of xs:decimal (: returns true :) "hello" instance of xs:bytes (: returns false :)
The ? optional occurrence indicator can be appended after the data type to indicate that the empty sequence is allowable (though it is not mandatory, as with the cast as operator), as in this example:
9.8273 instance of xs:double? (: returns true :)
FLWOR expressions provide a way to iterate over a sequence and bind intermediate results to variables. FLWOR is an acronym for the keywords that define this type of expression: for, let, where, order by, and return. This section discusses XQuery’s powerful FLWOR expressions.
The for and return keywords have long been a part of XPath, though in not nearly so powerful a form as the XQuery FLWOR expression. The for keyword specifies that a variable is iteratively bound to the results of the specified path expression. The result of this iterative binding process is known as a tuple stream. The XQuery for expression is roughly analogous to the T-SQL SELECT statement. The for keyword must, at a minimum, have a matching return clause after it. The sample in Listing 13-30 demonstrates a basic for expression.
Listing 13-30. Basic XQuery for...return Expression
SELECT CatalogDescription.query(N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
for $spec in //ns:ProductDescription/ns:Specifications/*
return fn:string($spec)') AS Description FROM Production.ProductModel WHERE ProductModelID = 19;
The for clause iterates through all elements returned by the path expression. It then binds the elements to the $spec variable. The tuple stream that is bound to $spec consists of the following nodes in document order:
$spec = <Material>Almuminum Alloy</Material>
$spec = <Color>Available in most colors</Color>
$spec = <ProductLine>Mountain bike</ProductLine>
$spec = <Style>Unisex</Style>
$spec = <RiderExperience>Advanced to Professional riders</RiderExperience>
The return clause applies the fn:string function to the $spec variable to return the string value of each node as it is bound. The results look like the following:
Almuminum Alloy Available in most colors Mountain bike Unisex Advanced to Professional riders.The sample can be modified to return an XML result, using the techniques described previously in the “Dynamic XML Construction” section. Listing 13-31 demonstrates with results shown in Figure 13-23.
Listing 13-31. XQuery for...return Expression with XML Result
SELECT CatalogDescription.query (
N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
for $spec in //ns:ProductDescription/ns:Specifications/* return <detail> {
$spec/text() } </detail>' ) AS Description
FROM Production.ProductModel WHERE ProductModelID = 19;

Figure 13-23. Results of the for...return Expression with XML Construction
XQuery allows you to bind multiple variables in the for clause. When you bind multiple variables, the result is the Cartesian product of all possible values of the variables. SQL Server programmers will recognize the Cartesian product as being equivalent to the SQL CROSS JOIN operator. Listing 13-32 modifies the previous example further to generate the Cartesian product of the Specifications and Warranty child node text.
Listing 13-32. XQuery Cartesian Product with for Expression
SELECT CatalogDescription.query(N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
for $spec in //ns:ProductDescription/ns:Specifications/*,
$feat in //ns:ProductDescription/*:Features/*:Warranty/node()
return <detail>
{
$spec/text()
} +
{
fn:string($feat/.)
}
</detail>'
) AS Description
FROM Production.ProductModel
WHERE ProductModelID = 19;
The $spec variable is bound to the same nodes shown previously. A second variable binding, for the variable $feat, is added to the for clause in this example. Specifically, this second variable is bound to the child nodes of the Warranty element, as shown following:
<pl:WarrantyPeriod>3 years</pl:WarrantyPeriod> <pl:Description>parts and labor</pl:Description
The Cartesian product of the text nodes of these two tuple streams consists of ten possible combinations. The final result of the XQuery expression is shown in Figure 13-24 (formatted for easier reading).

Figure 13-24. Cartesian Product XQuery
A bound variable can be used immediately after it is bound, even in the same for clause. Listing 13-33 demonstrates this.
Listing 13-33. Using a Bound Variable in the for Clause
SELECT CatalogDescription.query
(
N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
for $spec in //ns:ProductDescription/ns:Specifications,
$color in $spec/Color
return <color>
{
$color/text()
}
</color>'
) AS Color
FROM Production.ProductModel
WHERE ProductModelID = 19;
In this example, the $spec variable is bound to the Specifications node. It is then used in the same for clause to bind a value to the variable $color. The result is shown in Figure 13-25.

Figure 13-25. Binding a Variable to Another Bound Variable in the for Clause
The where keyword specifies an optional clause to filter tuples generated by the for clause. The expression in the where clause is evaluated for each tuple, and those for which the effective Boolean value evaluates to false are discarded from the final result. Listing 13-34 demonstrates use of the where clause to limit the results to only those tuples that contain the letter A. The results are shown in Figure 13-26.
Listing 13-34. where Clause Demonstration
SELECT CatalogDescription.query
(
N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
for $spec in //ns:ProductDescription/ns:Specifications/*
where $spec[ contains( . , "A" ) ]
return <detail>
{
$spec/text()
}
</detail>'
) AS Detail
FROM Production.ProductModel
WHERE ProductModelID = 19;

Figure 13-26. Results of a FLWOR Expression with the where Clause
The functions and operators described previously in this chapter (such as the contains function used in the example) can be used in the where clause expression to limit results as required by your application.
The order by clause is an optional clause of the FLWOR statement. The order by clause reorders the tuple stream generated by the for clause, using criteria that you specify. The order by criteria consists of one or more ordering specifications that are made up of an expression and an optional order modifier. Ordering specifications are evaluated from left to right.
The optional order modifier is either ascending or descending to indicate the direction of ordering. The default is ascending, as shown in Listing 13-35. The sample uses the order by clause to sort the results in descending (reverse) order. The results are shown in Figure 13-27.
Listing 13-35. order by Clause
SELECT CatalogDescription.query(N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
for $spec in //ns:ProductDescription/ns:Specifications/*
order by $spec/. descending
return <detail> { $spec/text() } </detail>') AS Detail
FROM Production.ProductModel
WHERE ProductModelID = 19;

Figure 13-27. Results of a FLWOR Expression with the order by Clause
SQL Server 2012 added support for the FLWOR expression let clause. The let clause allows you to bind tuple streams to variables inside the body of the FLWOR expression. You can use the let clause to name repeating expressions. SQL Server XQuery inserts the expression assigned to the bound variable everywhere the variable is referenced in the FLWOR expression. Listing 13-36 demonstrates the let clause in a FLWOR expression, with results shown in Figure 13-28.
Listing 13-36. let Clause
SELECT CatalogDescription.query
(
N'declare namespace ns =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
for $spec in //ns:ProductDescription/ns:Specifications/*
let $val := $spec/text()
order by fn:string($val[1]) ascending
return <spec>
{
$val
}
</spec>'
) AS Detail
FROM Production.ProductModel
WHERE ProductModelID = 19;

Figure 13-28. Results of a FLWOR Expression with the let Clause
When SQL Server stores unicode data types with nchar and nvarchar it stores using UCS-2 encoding (UCS – Universal Character Set), meaning it counts every 2-byte character as single character. In recent years the charater limit was increased to 31 bits, and it would be difficult to store these characters given the fact that we only have 2 bytes per character. This led to the problem of SQL Server not handling some of the characters properly. In the previous versions of SQL Server, even though SQLXML supports UTF-16, the string functions only supported for UCS-2 unicode values. This means that even though the data can be stored and retrieved without losing the property, some of the string operations such as string length or substring functions provided wrong results since they don’t recognize surrogate pairs.
Let’s review this with an example, and in our case, let’s say we have to store UTF-16 encoding such as musical symbol drum cleff-1 as a part of a name in our database. Drum-cleff-1 is represented by surrogate values 0xD834 and 0xDD25. Let’s say we calculate the length of the string to see if SQL Server checks for surrogate pairs. Listing 13-37 demonstrates the creation of the sample row for our usage and Listing 13-38 uses the row that was created using Listing 13-37 to demonstrate UTF-16 encoding handling in SQL Server. Results for Listing 13-38 are shown in Figure 13-29.
Listing 13-37. Create Record to Demonstrate UTF-16
declare @BusinessEntityId int
INSERT INTO Person.BusinessEntity(rowguid, ModifiedDate)
VALUES (NEWID(),CURRENT_TIMESTAMP)
SET @BusinessEntityId = SCOPE_IDENTITY()
INSERT INTO [Person].[Person]
([BusinessEntityID]
,[PersonType]
,[NameStyle]
,[Title]
,[FirstName]
,[MiddleName]
,[LastName]
,[Suffix]
,[EmailPromotion]
,[AdditionalContactInfo]
,[Demographics]
,[rowguid]
,[ModifiedDate])
VALUES
(@BusinessEntityId,
'EM',
0,
NULL,
N'T' + nchar(0xD834) + nchar(0xDD25),
'J',
'Kim',
NULL,
0,
NULL,
'<IndividualSurvey xmlns="http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey"><TotalPurchaseYTD>0</TotalPurchaseYTD></IndividualSurvey>',
NEWID(),
CURRENT_TIMESTAMP)
Listing 13-38. SQL Server to Check for Presence of Surrogates
SELECT
p.NameStyle AS "processing-instruction(nameStyle)",
p.BusinessEntityID AS "Person/@ID",
p.ModifiedDate AS "comment()",
FirstName AS "Person/Name/First",
Len(FirstName) AS "Person/FirstName/Length",
MiddleName AS "Person/Name/Middle",
LastName AS "Person/Name/Last"
FROM Person.Person p
WHERE BusinessEntityID = 20778
FOR XML PATH;

Figure 13-29. Results of SQL Server UTF-16 Surrogate Pair
From Figure 13-29, you can see that the query returns the column length to be 3 whereas the length should be 2 because length function calculates the number of characters and we have 2 characters in our string. Since the surrogate pair is not recognized, the number of characters is listed as 3 instead of 2.
To mitigate the above issue, in SQL Server 2014 there is full support for UTF-16/UCS-4, meaning the Xquery handles the surrogate pairs properly and returns the correct results for string operations and the operators such as =,==,<,>=and LIKE. Note that some of the string operators may already be surrogate aware. However since some of the applications are already developed and being used based on the older behavior, SQL Server 2012 added a new set of flags to the collation names to indicate that the collation is UTF-16 aware. The _SC (Supplementary Characters) flag will be appended to the version 100 collation names and it be applicable for nchar, nvarchar, and sql_variant data types.
Let’s modify the code snippet we have from Listing 13-38 and add the _SC collation to the query to see how SQL Server calculates the column length properly. In this example let’s include the supplementary characters collation so that SQL Server is UTF-16 aware. The modified code snippet is shown in Listing 13-39 and results are shown in Figure 13-30.
Listing 13-39. Surroage Pair with UTF-16 and _SC collation
SELECT
p.NameStyle AS "processing-instruction(nameStyle)",
p.BusinessEntityID AS "Person/@ID",
p.ModifiedDate AS "comment()",
FirstName AS "Person/Name/First",
Len(FirstName COLLATE Latin1_General_100_CS_AS_SC) AS "Person/FirstName/Length",
MiddleName AS "Person/Name/Middle",
LastName AS "Person/Name/Last"
FROM Person.Person p
WHERE BusinessEntityID = 20778
FOR XML PATH;

Figure 13-30. Results of SQL Server UTF-16 Surrogate Pair with _SC collation
Figure 13-30 demonstrates that by using supplementary characters collation, SQL Server now is UTF-16 aware, and it calculates the column length as it should: we see the proper value of 2 for the column length.
To maintain backward compatibility SQL Server is surrogate pair aware only when the compatibility mode is set to SQL11 or higher. If the compatability mode is set to SQL10 or lower, the fn:string-length and fn:substring will not be surrogate aware and the older behavior will continue.
Summary
This chapter has expanded the discussion of SQL Server XML functionality that we began in Chapter 12. In particular, we focused on the SQL Server implementations of XPath and XQuery. We provided a more detailed discussion of the SQL Server FOR XML PATH clause XPath implementation, including XPath expression syntax, axis specifiers, and supported node tests. We also discussed SQL Server support for XML namespaces via the WITH XMLNAMESPACES clause.
We used the majority of this chapter to detail SQL Server support for XQuery, which provides a powerful set of expression types, functions, operators, and support for the rich XDM data type system. SQL Server support for XQuery has improved with the release of SQL Server 2014, including new options like the FLWOR expression let clause, support for date and time literals without specifying explicit time offsets, and UTF-16 support and Supplementary Characters collation.
The next chapter discusses SQL Server 2014 catalog views and dynamic management views and functions that provide a way to look under the hood of your databases and server instances.
Exercises
- [True/False] The FOR XML PATH clause supports a subset of the W3C XPath recommendation.
- [Choose one] Which of the following symbols is used in XQuery and XPath as an axis specifier to identify XML attributes:
- An at sign (@)
- An exclamation point (!)
- A period (.)
- Two periods (..)
- [Fill in the blanks] The context item, indicated by a single period (.) in XPath and XQuery, specifies the current _________ or scalar _________ being accessed at any given point in time during query execution.
- [Choose all that apply] You can declare namespaces for XQuery expressions in SQL Server using which of the following methods:
e. The T-SQL WITH XMLNAMESPACES clause
f. The XQuery declare default element namespace statement
g. he T-SQL CREATE XML NAMESPACE statement
h. The XQuery declare namespace statement
- [Fill in the blanks] In XQuery, you can dynamically construct XML via ____________ constructors or ___________ constructors.
- [True/False] SQL Server 2012 supports the for, let, where, order by, and return clauses of XQuery FLWOR expressions.
- [Fill in the blanks] _SC collation enables SQL Server to be __________________.
- [Choose all that apply] SQL Server supports the following types of XQuery comparison operators:
i. Array comparison operators
j. General comparison operators
k. Node comparison operators
l. Value comparison operators