
Chapter 6. Advanced applications of function types
This chapter covers
- Using a simplified decorator pattern
- Implementing a resumable counter
- Handling long-running operations
- Writing clean asynchronous code by using promises and async/await
In chapter 5, we covered the basics of function types and scenarios enabled by the ability to treat functions like other values by passing them as arguments and returning them as results. We also looked at some powerful abstractions that implement common data processing patterns: map(), filter(), and reduce().
In this chapter, we’ll continue our discussion of function types with some more advanced applications. We’ll start by looking at the decorator pattern, its by-the-book implementation, and an alternative implementation. (Again, don’t worry if you forgot it; we’ll have a quick refresher.) We’ll introduce the concept of a closure and see how we can use it to implement a simple counter. Then we’ll look at another way to implement a counter, this time with a generator: a function that yields multiple results.
Next, we’ll talk about asynchronous operations. We’ll go over the two main asynchronous execution models—threads and event loops—and look at how we can sequence several long-running operations. We’ll start with callbacks; then we’ll look at promises, and finally, we’ll cover the async/await syntax provided nowadays by most mainstream programming languages.
All the topics discussed in this chapter are made possible because we can use functions as values, as we’ll see in the following pages.
6.1. A simple decorator pattern
The decorator pattern is a behavioral software design pattern that extends the behavior of an object without modifying the class of the object. A decorated object can perform work beyond what its original implementation provides. The pattern looks like figure 6.1.
Figure 6.1. Decorator pattern: an IComponent interface, a concrete implementation via ConcreteComponent, and a Decorator that enhances an IComponent with additional behavior

As an example, suppose that we have an IWidgetFactory that declares a make-Widget() method returning a Widget. The concrete implementation, Widget-Factory, implements the method to instantiate new Widget objects.
Suppose that we want to reuse a Widget, so instead of always creating a new one, we want to create just one and keep returning it (that is, have a singleton). Without modifying our WidgetFactory, we can create a decorator called Singleton-Decorator, which wraps an IWidgetFactory, as shown in the next listing, and extends its behavior to ensure that only a single Widget gets created (figure 6.2).
Figure 6.2. Decorator pattern for the widget factory. IWidgetFactory is the interface, WidgetFactory is a concrete implementation, and SingletonDecorator adds singleton behavior to an IWidgetFactory.

Listing 6.1. WidgetFactory decorator
class Widget { }
interface IWidgetFactory {
makeWidget(): Widget;
}
class WidgetFactory implements IWidgetFactory {
public makeWidget(): Widget {
return new Widget(); 1
}
}
class SingletonDecorator implements IWidgetFactory {
private factory: IWidgetFactory; 2
private instance: Widget | undefined = undefined;
constructor(factory: IWidgetFactory) {
this.factory = factory;
}
public makeWidget(): Widget {
if (this.instance == undefined) { 3
this.instance = this.factory.makeWidget(); 3
}
return this.instance;
}
}
- 1 WidgetFactory simply creates a new Widget.
- 2 SingletonDecorator wraps an IWidgetFactory.
- 3 makeWidget() implements the singleton logic and ensures that only a single Widget is created.
The advantage of using this pattern is that it supports the single-responsibility principle, which says that a class should have just one responsibility. In this case, the Widget-Factory is responsible for creating widgets, whereas the SingletonDecorator is responsible for the singleton behavior. If we want multiple instances, we use the Widget-Factory directly. If we want a single instance, we use SingletonDecorator.
6.1.1. A functional decorator
Let’s see how we can simplify this implementation, again by using typed functions. First, let’s get rid of the IWidgetFactory interface and replace it with a function type. That would be the type of a function that takes no arguments and returns a Widget: () => Widget.
Now we can replace our WidgetFactory class with a simple function, make-Widget(). Whenever we would’ve used an IWidgetFactory before, passing in an instance of WidgetFactory, we now require a function of type () => Widget and pass in makeWidget(), as the following listing shows.
Listing 6.2. Functional widget factory
class Widget { }
type WidgetFactory = () => Widget; 1
function makeWidget(): Widget { 2
return new Widget();
}
function use10Widgets(factory: WidgetFactory) { 3
for (let i = 0; i < 10; i++) {
let widget = factory();
/* ... */
}
}
use10Widgets(makeWidget); 4
- 1 Function type for a widget factory
- 2 makeWidget() is of type WidgetFactory.
- 3 use10Widgets() requires a WidgetFactory, which it uses to create 10 Widget instances.
- 4 Example call: we pass the makeWidget function as an argument.
With the functional widget factory, we use a technique very similar to the strategy pattern in chapter 5: we get a function as an argument and call it when needed. Now let’s see how we can add the singleton behavior.
We provide a new function, singletonDecorator(), that takes a Widget-Factory-type function and returns another WidgetFactory-type function. Remember from chapter 5 that a lambda is a function without a name, which we can return from another function. In the next listing, our decorator will take a factory and use it to build a new function that handles the singleton behavior (figure 6.3).
Figure 6.3. Functional decorator: we now have only a makeWidget() function and a singletonDecorator() function.
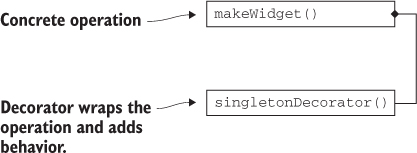
Listing 6.3. Functional widget factory decorator
class Widget { }
type WidgetFactory = () => Widget;
function makeWidget(): Widget {
return new Widget();
}
function singletonDecorator(factory: WidgetFactory): WidgetFactory {
let instance: Widget | undefined = undefined;
return (): Widget => { 1
if (instance == undefined) {
instance = factory();
}
return instance;
};
}
function use10Widgets(factory: WidgetFactory) {
for (let i = 0; i < 10; i++) {
let widget = factory();
/* ... */
}
}
use10Widgets(singletonDecorator(makeWidget)); 2
- 1 singletonDecorator() returns a lambda that implements the singleton behavior and uses the given factory to create a Widget.
- 2 Because singletonDecorator() returns a WidgetFactory, we can pass it as an argument to use10Widgets().
Now, instead of constructing 10 Widget objects, use10Widgets() will call the lambda, which will reuse the same Widget instance for all calls.
This code reduces the number of components from an interface and two classes, each with a method (the concrete operation and the decorator) to two functions.
6.1.2. Decorator implementations
As with our strategy pattern, the object-oriented and functional approaches implement the same decorator pattern. The object-oriented version requires an interface declaration (IWidgetFactory), at least one implementation of that interface (Widget-Factory), and a decorator class that handles the added behavior (Singleton-Decorator). By contrast, the functional implementation simply declares the type of the factory function (() => Widget) and uses two functions: a factory function (makeWidget()) and a decorator function (singletonDecorator()).
One thing to note is that in the functional case, the decorator does not have the same type as makeWidget(). Whereas the factory doesn’t expect any arguments and returns a Widget, the decorator takes a widget factory and returns another widget factory. In other words, singletonDecorator() takes a function as an argument and returns a function as its result. This wouldn’t be possible without first-class functions: the ability to treat functions as any other variables and use them as arguments and return values.
The more-succinct implementation, enabled by modern type systems, is good for many situations. We can use the more-verbose object-oriented solution when we are dealing with more than a single function. If our interface declares several methods, we can’t replace it with a single function type.
6.1.3. Closures
Let’s zoom in on the singletonDecorator() implementation in listing 6.4. You may have noticed something interesting: even though the function returns a lambda, the lambda references both the factory argument and the variable instance, which should be local to the singletonDecorator() function.
Listing 6.4. Decorator function
function singletonDecorator(factory: WidgetFactory): WidgetFactory {
let instance: Widget | undefined = undefined;
return (): Widget => {
if (instance == undefined) {
instance = factory();
}
return instance;
};
}
Even after we return from singletonDecorator(), the instance variable is still alive, as it was “captured” by the lambda, which is known as a lambda capture.
Closures and lambda captures
A lambda capture is an external variable captured within a lambda. Programming languages implement lambda captures through closures. A closure is something more than a simple function: it also records the environment in which the function was created, so it can maintain state between calls.
In our case, the instance variable in singletonDecorator() is part of that environment. The lambda we return will still be able to reference instance (figure 6.4).
Figure 6.4. A simple function that returns a closure: a lambda that references a variable local to the function. Even after getClosure() returns, the variable is still referenced by the closure, so it outlives the function in which it appeared.

Closures make sense only if we have higher-order functions. If we can’t return a function from another function, there is no environment to capture. In that case, all functions are in the global scope, which is their environment. They can reference global variables.
Another way to think about closures is to contrast them with objects. An object represents some state with a set of methods; a closure represents a function with some captured state. Let’s look at another example in which closures can be used: implementing a counter.
6.1.4. Exercises
Implement a function, loggingDecorator(), that takes as argument another function, factory(), that takes no arguments and returns a Widget object. Decorate the given function so that whenever it is called, it logs "Widget created" before returning a Widget object.
6.2. Implementing a counter
Let’s look at a very simple scenario: we want to create a counter that gives us consecutive numbers starting from 1. Although this example may seem trivial, it covers several possible implementations that generalize to any scenario in which we need to generate values. One way is to use a global variable and a function that returns that variable and then increments, as shown in the following code.
Listing 6.5. Global counter
let n: number = 1; 1
function next() {
return n++; 2
}
console.log(next()); 3
console.log(next()); 3
console.log(next()); 3
- 1 The counter is stored in a global variable.
- 2 next() returns n and increments.
- 3 This will log 1 2 3.
This implementation works, but it’s not ideal. First, n is a global variable, so anyone has access to it. Other code might change it from underneath us. Second, this implementation gives us a single counter. What if we want two counters, both starting from 1?
6.2.1. An object-oriented counter
The first implementation we will look at is an object-oriented one, which should be familiar. We create a Counter class, which stores the state of the counter as a private member. We provide a next() method, which returns and increments that counter. In this way, we encapsulate the counter so that external code can’t change it and we can create as many counters as we want as instances of this class.
Listing 6.6. Object-oriented counter
class Counter {
private n: number = 1; 1
next(): number {
return this.n++;
}
}
let counter1: Counter = new Counter(); 2
let counter2: Counter = new Counter(); 2
console.log(counter1.next()); 3
console.log(counter2.next()); 3
console.log(counter1.next()); 3
console.log(counter2.next()); 3
- 1 The counter value is now private to the class.
- 2 We can create multiple counters.
- 3 This will log 1 1 2 2.
This approach works better. In fact, most modern programming languages provide an interface for types such as our counter, which provides a value on each call and has special syntax to iterate over it. In TypeScript, this is done with the Iterable interface and for ... of loop. We cover this topic later in the book, when we discuss generic programming. For now, we’ll just note that this pattern is common. C# implements it with the IEnumerable interface and the foreach loop, whereas Java does it with the Iterable interface and the for : loop.
Next, let’s look at a functional alternative that leverages closures to implement the counter.
6.2.2. A functional counter
In the next listing, we’ll implement the functional counter through a makeCounter() function that returns a counter function when called. We will initialize the counter as a variable local to makeCounter() and then capture it in the return function.
Listing 6.7. Functional counter
type Counter = () => number; 1
function makeCounter(): Counter {
let n: number = 1; 2
2
return () => n++; 2
}
let counter1: Counter = makeCounter();
let counter2: Counter = makeCounter();
console.log(counter1()); 3
console.log(counter2()); 3
console.log(counter1()); 3
console.log(counter2()); 3
- 1 We define a Counter type as a function that takes no arguments and returns a number.
- 2 The counter value is declared as a variable and captured by the lambda.
- 3 This will log 1 1 2 2.
Each counter is a function now, so instead of calling counter1.next(), we simply call counter1(). We also see that each counter captures a separate value: calling counter1() does not affect counter2() because whenever we call makeCounter(), a new n gets created. Each function returned keeps its own n. The counters are closures. Also, these values persist between calls. This behavior is different from that of variables that are local to a function, which are created when the function is called and disposed of when the function returns (figure 6.5).
Figure 6.5. It’s important to understand that each closure (in our case, counter1 and counter2) ends up with a different n. Whenever we call makeCounter(), a new n is initialized to 1 and captured by the returned closure. Because the values are separate, they don’t interfere with each other.

6.2.3. A resumable counter
Another way to define a counter is to use a resumable function. An object-oriented counter keeps track of state via a private member. A functional counter keeps track of state in its captured context.
Resumable functions
A resumable function is a function that keeps track of its own state and, whenever it gets called, doesn’t run from the beginning; rather, it resumes executing from where it left off the last time it returned.
In TypeScript, instead of using the keyword return to exit the function, we use the keyword yield, as shown in listing 6.8. This keyword suspends the function, giving control back to the caller. When called again, execution is resumed from the yield statement.
There are a couple more constraints for using yield: the function must be declared as a generator, and its return type must be an iterable iterator. A generator is declared by prefixing the function name with an asterisk.
Listing 6.8. Resumable counter
function* counter(): IterableIterator<number> { 1
let n: number = 1;
while (true) {
yield n++; 2
}
}
let counter1: IterableIterator<number> = counter(); 3
let counter2: IterableIterator<number> = counter(); 3
console.log(counter1.next()); 4
console.log(counter2.next()); 4
console.log(counter1.next()); 4
console.log(counter2.next()); 4
- 1 The function is declared as a generator.
- 2 We call yield instead of return.
- 3 Our counters are objects implementing the IterableIterator interface.
- 4 This logs 1 1 2 2.
This implementation is in a way a mix between our object-oriented and functional counters. The implementation of the counter reads like a function: we start with n being 1 and then loop forever, yielding the counter value and incrementing it. On the other hand, the code generated by the compiler is object-oriented: our counter is actually an IterableIterator<number>, and we call next() on it to get the next value.
Even though we implement this with a while (true) statement, we don’t get stuck in an infinite loop; the function keeps yielding values and gets suspended after each yield. Behind the scenes, the compiler translates the code we wrote into something that looks more like our previous implementations.
The type of this function is () => IterableIterator<number>. Notice that the fact that it is a generator doesn’t affect its type. A function with no arguments that would return an IterableIterator<number> would have exactly the same type. The * declaration is used by the compiler to allow yield statements but is transparent to the type system.
We will come back to iterators and generators in a later chapter and discuss them at length.
6.2.4. Counter implementations recap
Before moving on, let’s quickly recap the four ways to implement a counter and the various language features we learned about:
- A global counter is implemented as a simple function that references a global variable. This counter has multiple drawbacks: the counter value is not properly encapsulated, and we cannot have two separate instances of the counter.
- The object-oriented counter implementation is straightforward: the counter value is private state, and we expose a next() method to read and increment it. Most languages declare an interface like Iterable to support such scenarios and provide syntactic sugar to consume them.
- A functional counter is a function that returns a function. The returned function is a counter. This implementation leverages lambda captures to hold the state of the counter. The code is more succinct than the object-oriented version.
- A generator employs special syntax to create a resumable function. Instead of returning, a generator yields; it provides a value to the caller but also keeps track of where it was and picks up from there on subsequent calls. A generator function must return an iterable iterator.
Next, we’ll look at another common application of function types: asynchronous functions.
6.2.5. Exercises
Implement a function that returns the next number in the Fibonacci sequence whenever it is called by using a closure.
Implement a function that returns the next number in the Fibonacci sequence whenever it is called by using a generator.
6.3. Executing long-running operations asynchronously
We want our applications to be as fast and responsive as possible, even when certain operations take longer to complete. Running all our code sequentially might introduce unacceptable delays. If we can’t respond to our users clicking a button because we’re waiting for a download to complete, the users get frustrated.
In general, we don’t want to wait for a long-running operation to execute a faster operation. It’s best to execute such long-running tasks asynchronously so we can keep the UI interactive while our download completes. Asynchronous execution means that the operations don’t run one after another, in the order in which they show up in the code. They could be running in parallel, but that’s not mandatory. JavaScript is single-threaded, so asynchronous execution is achieved by the run time with an event loop. We’ll go over a high-level description of both parallel execution using multiple threads and event loop–based execution with a single thread, but first, let’s look at an example in which running code asynchronously comes in handy.
Suppose that we want to perform two operations: greet our users and take them to www.weather.com so that they can see today’s weather. We’ll do this with two functions: a greet() function that asks for the user’s name and greets them, and a weather() function, which launches a browser for today’s weather. Let’s look at a synchronous implementation and then contrast it with an asynchronous one.
6.3.1. Synchronous execution
We will implement greet() by using the readline-sync node package, as shown in listing 6.9. This package provides a way to read input from stdin with the question() function. The function returns the string typed by the user. Execution blocks until the user types their answer and presses return. We can install the package with npm install –save readline-sync.
To implement weather(), we will use the open Node package, which allows us to launch a URL in the browser. We can install the package with npm install -save open.
Listing 6.9. Synchronous execution
function greet(): void {
const readlineSync = require('readline-sync');
let name: string = readlineSync.question("What is your name? "); 1
console.log(`Hi ${name}!`);
}
function weather(): void {
const open = require('open');
open('https://www.weather.com/');
}
greet(); 2
weather(); 2
- 1 Calling question() blocks execution until the user enters their answer.
- 2 We first call greet(); then we call weather().
Let’s step through what happens when we run this code. First, greet() is called, and we ask the user to give us their name. Execution stops here until we receive a reply from the user, after which it proceeds by outputting a greeting. After greet() returns, weather() is called, launching www.weather.com.
This implementation works, but it’s not optimal. The two functions—greeting the user and taking them to a website—are independent in this case, so one of them shouldn’t be blocked until the other one finishes. We could call the functions in a different order, because in this case, it’s obvious that requesting user input takes longer than launching an application. But in practice, we can’t always tell which one of two functions will take longer to complete. A better approach is to run the functions asynchronously.
6.3.2. Asynchronous execution: callbacks
An asynchronous version of greet() prompts the user for their name but does not block and wait for the reply. Execution will continue by calling weather(). We still want to print the user’s name after they enter it, so we need a way to be notified of their answer. This is done with a callback.
A callback is a function that we provide to an asynchronous function as an argument. The asynchronous function does not block execution; the next line of code gets executed. When the long-running operation completes (in this case, waiting for the user to answer with their name), the callback function is executed, so we can handle the result.
Let’s see the asynchronous greet() implementation in the next listing. We will use the readline module provided by Node. In this case, the question() function does not block execution; rather, it takes a callback as an argument.
Listing 6.10. Asynchronous execution with callback
function greet(): void {
const readline = require('readline'); 1
const rl = readline.createInterface({ 2
input: process.stdin,
output: process.stdout
});
rl.question("What is your name? ", (name: string) => { 3
console.log(`Hi ${name}!`);
rl.close();
});
}
function weather(): void {
const open = require('open');
open('https://www.weather.com/');
}
greet();
weather();
- 1 Using readline instead of readline-sync
- 2 createInterface() is extra setup required by readline and not important for our example.
- 3 The callback is a lambda that will receive the name and print it.
Stepping through this program, as soon as question() is called and the user is prompted, execution continues without waiting for the user’s answer, returning from greet() and calling weather(). Running this program prints “What is your name?”“42” on the terminal, but www.weather.com will be open before the user provides their answer.
When an answer comes in, the lambda gets called. The lambda prints the greeting to the screen with console.log() and closes the interactive session (so that no more user input is requested) with rl.close().
6.3.3. Asynchronous execution models
As briefly mentioned at the start of this section, asynchronous execution can be achieved with threads or with an event loop. The choice depends on how your run time and the library you are using implement asynchronous operations. In JavaScript, asynchronous execution is implemented with an event loop.
Threads
Each application runs as a process. A process starts with a main thread, but we can create multiple other threads on which to run code. On POSIX-compliant systems such as Linux and macOS, new threads are created with pthread_create(), whereas Windows provides CreateThread(). These APIs are provided by the operating systems. Programming languages provide libraries with different interfaces, but those libraries end up using the OS APIs internally.
Separate threads can run at the same time. Multiple CPU cores can execute instructions in parallel, each handling a different thread. If the number of threads is larger than the hardware can run in parallel, the operating system ensures that each thread gets a fair amount of run time. Threads get paused and resumed by the thread scheduler to achieve this result. The thread scheduler is a core component of the OS kernel.
We won’t look at a code sample for threads, as JavaScript (and, thus, TypeScript) has been historically single-threaded. Node recently enabled experimental support for worker threads, but this development is fairly recent at the time of this writing. That being said, if you program in any other mainstream language, you are probably familiar with how to create new threads and execute code on them in parallel (figure 6.6).
Figure 6.6. createThread() creates a new thread. The original thread continues to execute operation1() and then operation2(), and the new thread executes longRunningOperation() in parallel.

Event loops
An alternative to multiple threads is an event loop. An event loop uses a queue: asynchronous functions get enqueued, and they themselves can enqueue other functions. As long as the queue is not empty, the first function in line gets dequeued and executed.
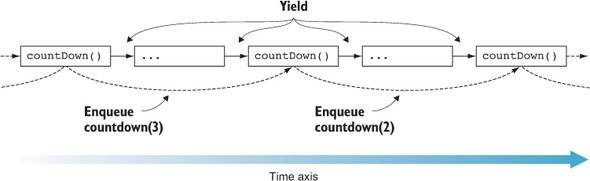
As an example, let’s look at a function that counts down from a given number, shown in the following listing. Instead of blocking execution until the countdown is complete, this function will use an event queue and enqueue another call to itself until it reaches 0 (figure 6.7).
Figure 6.7. countDown() counts one step; then it yields and allows other code to run. It also enqueus another call to countDown() with the decremented counter value. If the counter reaches 0, countDown() doesn’t enqueue another call to itself.
Listing 6.11. Counting down in an event loop
type AsyncFunction = () => void; 1
let queue: AsyncFunction[] = []; 2
function countDown(counterId: string, from: number): void {
console.log(`${counterId}: ${from}`); 3
if (from > 0)
queue.push(() => countDown(counterId, from - 1)); 4
}
queue.push(() => countDown('counter1', 4)); 5
while (queue.length > 0) { 6
let func: AsyncFunction = <AsyncFunction>queue.shift();
func();
}
- 1 We’ll restrict our asynchronous functions to functions without arguments that return void.
- 2 Our queue will be an array of functions.
- 3 The counter prints its id and current value.
- 4 If greater than 0, the counter enqueues another call to countDown(), decrementing the value.
- 5 We kick off the process by queueing a call to countDown() from 4.
- 6 While there is a function in the queue, dequeue it and call it.
This code will output
counter1: 4 counter1: 3 counter1: 2 counter1: 1 counter1: 0
When the counter reaches 0, it will not enqueue another call, so the program will stop. So far, this isn’t much more interesting than simply counting in a loop. But what happens if we start by enqueuing two counters?
Listing 6.12. Two counters in an event loop
type AsyncFunction = () => void;
let queue: AsyncFunction[] = [];
function countDown(counterId: string, from: number): void {
console.log(`${counterId}: ${from}`);
if (from > 0)
queue.push(() => countDown(counterId, from - 1));
}
queue.push(() => countDown('counter1', 4));
queue.push(() => countDown('counter2', 2)); 1
while (queue.length > 0) {
let func: AsyncFunction = <AsyncFunction>queue.shift();
func();
}
- 1 The only difference from the preceding sample is that now we enqueue a second counter.
This time around, the output is
counter1: 4 counter2: 2 counter1: 3 counter2: 1 counter1: 2 counter2: 0 counter1: 1 counter1: 0
As we can see, this time the counters are interleaved. Each counter counts down one step; then the other one gets a chance to count. We couldn’t achieve this result if we just counted down in a loop. Using the queue, the two functions yield after each step of the countdown and allow other code to run before they count down again.
The two counters do not run at the same time; either counter1 or counter2 gets some time to run. But they do run asynchronously, or independently, of each other. Either of them can finish execution first, regardless of how much longer the other one takes (figure 6.8).
Figure 6.8. Each counter runs and then enqueues another operation. Execution proceeds in the order in which operations are enqueued. Everything runs on a single thread.

For operations that wait for input, such as from the keyboard, the run time can ensure that an operation to handle that input is queued only after input is received, in which case other code can run while the input is being provided. This way, a long--running operation that requires input can be split into two shorter-running ones; the first requests input and returns, and the second processes input when it arrives. The run time handles scheduling the second operation after input is available.
Event loops don’t work as well for long-running operations that cannot be split into multiple chunks. If we enqueue an operation that doesn’t yield and runs for a long time, the event loop will be stuck until it finishes.
6.3.4. Asynchronous functions recap
If we execute long-running operations synchronously, no other code runs until the long-running operation completes. Input/output operations are good examples of long-running operations, as reading from disk or from the network has higher latency than reading from memory.
Instead of executing such operations synchronously, we can execute them asynchronously and provide a callback function to be called when the long-running operation completes. There are two main models of executing asynchronous code: one that uses multiple threads and one that uses an event loop.
Threads can run in parallel on separate CPU cores, which is their main advantage, as different pieces of code can run at the same time, and the overall program finishes faster. A drawback is the synchronization overhead: passing data between threads requires careful synchronization. We won’t cover the topic in this book, but you’ve probably heard of problems such as deadlock and livelock, in which two threads never complete because they wait on each other.
An event loop runs on a single thread but enables a mechanism to put long--running code at the back of the queue while it awaits input. The advantage of using an event loop is that it doesn’t require synchronization, as everything runs on a single thread. The disadvantage is that although queuing up I/O operations as they wait for data works fine, CPU-intensive operations still block. A CPU-intensive operation, like a complex computation, can’t just be queued; as it’s not waiting for data, it requires CPU cycles. Threads are much better suited to this task.
Most mainstream programming languages use threads, JavaScript being a notable exception. That being said, even JavaScript is being extended with support for web worker threads (background threads running in the browser), and Node has experimental support for similar worker threads outside the browser.
In the next section, we look at how we can make our asynchronous code cleaner and easier to read.
6.3.5. Exercises
Which of the following can be used to implement an asynchronous execution model?
- Threads
- An event loop
- Neither a nor b
- Both a and b
Can two functions execute at the same time in an event-loop-based asynchronous system?
- Yes
- No
Can two functions execute at the same time in a thread-based asynchronous system?
- Yes
- No
6.4. Simplifying asynchronous code
Callbacks work in the same way as our counter in the preceding example. Whereas the counter enqueues another call to itself after each run, an asynchronous function can take another function as an argument and enqueue a call to that function when it completes execution.
As an example, let’s enhance our counter in the next listing with a callback that gets queued after the counter reaches 0.
Listing 6.13. Counter with callback
function countDown(counterId: string, from: number,
callback: () => void): void { 1
console.log(`${counterId}: ${from}`);
if (from > 0)
queue.push(() => countDown(counterId, from – 1, callback));
else 2
queue.push(callback); 2
}
queue.push(() => countDown('counter1', 4,
() => console.log('Done'))); 3
- 1 We add the callback argument, which is a function with no arguments that returns void.
- 2 When we’re done counting down, we queue the callback to be executed.
- 3 We provide a callback that prints “Done” when the counter completes.
Callbacks are a common pattern for dealing with asynchronous code. In our example, we used a callback without arguments, but callbacks can also receive arguments from the asynchronous function. That was the case with our asynchronous question() call from the readline module, which passed the string provided by the user to the callback.
Chaining multiple asynchronous functions with callbacks leads to a lot of nested functions, as we can see in listing 6.14, in which we want to ask the user’s name with a getUserName() function, ask their birthday with a getUser-Birthday() function, ask their email address, and so on. The functions depend on one another because each of them requires some information from the preceding one. (getUser-Birthday() requires the user’s name, for example.) Each function is also asynchronous, as it is potentially long-running, so it takes a callback to provide its result. We use these callbacks to call the next function in the chain.
Listing 6.14. Chaining callbacks
declare function getUserName(
callback: (name: string) => void): void; 1
declare function getUserBirthday(name: string,
callback: (birthday: Date) => void): void; 1
declare function getUserEmail(birthday: Date,
callback: (email: string) => void): void; 1
getUserName((name: string) => {
console.log(`Hi ${name}!`);
getUserBirthday(name, (birthday: Date) => { 2
const today: Date = new Date();
if (birthday.getMonth() == today.getMonth() &&
birthday.getDay() == today.getDay())
console.log('Happy birthday!');
getUserEmail(birthday, (email: string) => { 3
/* ... */
});
})
});
- 1 We won’t provide implementations for these functions—just declarations.
- 2 The callback to getUserName() calls getUserBirthday().
- 3 The callback to getUserBirthday() calls getUserEmail() and so on.
In the callback invoked when getUserName() obtains the name, we call getUserBirthday(), passing it the name. In the callback invoked when getUserBirthday() obtains the birthday, we call getUserEmail() passing in the birthday and so on.
We won’t go over the actual implementation of all the getUser... functions in this example, as they would be similar to the greet()implementation in the preceding section. We’re more concerned here with the overall structure of the calling code. Structuring code this way makes it hard to read, as the more callbacks we chain together, the more nested lambdas inside lambdas we end up with. It turns out that there is a better abstraction for this pattern of asynchronous function calls: promises.
6.4.1. Chaining promises
We start by observing that a function such as getUserName(callback: (name: string) => void) is an asynchronous function that will, at some point in time, determine the user’s name and then hand it over to a callback we provide. In other words, getUserName() “promises” to give back a name string eventually. We also observe that whenever the function has the promised value, we want it to call another function, passing that value as an argument.
Promises and continuations
A promise is a proxy for a value that will be available at a future point in time. Until the code that produces the value runs, other code can use the promise to set up how the value will be processed when it arrives, what to do in case of error, and even to cancel the future execution. A function set up to be called when the result of a promise is available is called a continuation.
The two main ingredients of a promise are a value of some type T that our function “promises” to give us and the ability to specify a function from T to some other type U ((value: T) => U), to be called when the promise is fulfilled and we have our value (a continuation). This is an alternative to supplying the callback directly to a function.
First, let’s update the declarations of our functions in listing 6.15 so that instead of taking a callback argument, they return a Promise. getUserName() will return a Promise-<string>, getUserBirthday() will return a Promise<Date>, and getUser-Email() will return another Promise<string>.
Listing 6.15. Functions returning promises
declare function getUserName(): Promise<string>; declare function getUserBirthday(name: string): Promise<Date>; declare function getUserEmail(birthday: Date): Promise<string>;
JavaScript (and, thus, TypeScript) provides a built-in Promise<T> type that implements this abstraction. In C#, Task<T> implements this, and in Java, CompletableFuture<T> provides similar functionality.
A promise provides a then() method that allows us to pass in our continuation. Each then() function returns another promise, so we can chain then() calls together. This process eliminates the nesting we saw in the callback-based implementation.
Listing 6.16. Chaining promises
getUserName()
.then((name: string) => { 1
console.log(`Hi ${name}!`);
return getUserBirthday(name); 2
})
.then((birthday: Date) => { 3
const today: Date = new Date();
if (birthday.getMonth() == today.getMonth() &&
birthday.getDay() == today.getDay())
console.log('Happy birthday!');
return getUserEmail(birthday);
})
.then((email: string) => { 4
/* ... */
});
- 1 We call then() on the promise returned by getUserName().
- 2 In this continuation, we use the value provided by getUserName().
- 3 Because then() returns another promise, we can call then() on the returned value again . . .
- 4 . . . and again.
As we can see, instead of having a callback within a callback within a callback, continuations are chained together in a pattern that’s easier to follow: we run a function, then() we run another function, and so on.
6.4.2. Creating promises
If we want to use this pattern, we should also look at how we can create a promise. The principle is straightforward, though it relies on higher-order functions—a promise takes as argument a function that takes as argument another function—so it may seem mind-bending at first.
A promise for a value of a certain type, such as Promise<string>, doesn’t really know how to compute that value. It provides a then() method for the continuation chaining we saw before, but it cannot determine what the string is. In the case of getUserName(), the promised string is the name of the user, and in the case of getUserEmail(), the promised string is an email address. How, then, could a generic Promise<string> be able to determine that value? The answer is that it can’t without help. The constructor of a promise takes as an argument a function that actually handles computing the value. For getUserName(), that function would prompt the user for their name and get their reply. The promise can then use this function by calling it directly, queuing it for the event loop, or scheduling its execution on a thread, depending on the implementation, which differs from language to language and library to library.
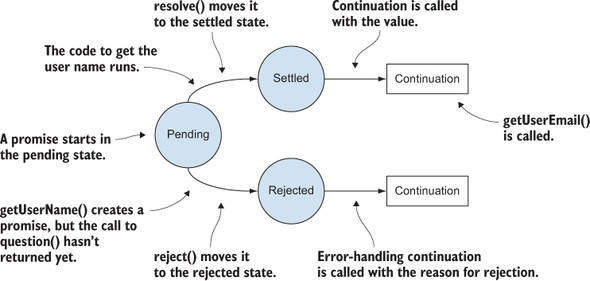
So far, so good. The Promise<string> gets some code that will provide the value. But because that code might run at a later time, we also need a mechanism for that code to tell the promise that the value has arrived. For that task, the promise will pass a function called resolve() to that code. When the value is determined, the code can call resolve() and hand the value back to the promise (figure 6.9).
Figure 6.9. getUserName() enqueues the code to get the username and returns a Promise<string>. The caller of getUserName() can call then() on the promise to hook up the getUserEmail() continuation—code to be run when we have a username. At some later time, the code to get the user name runs and calls resolve() with the username. At this point, the continuation getUserEmail() gets called with the now-available user name.

Let’s look at how we can implement getUserName() in the next listing to return a promise.
Listing 6.17. getUserName() returning a promise
function getUserName(): Promise<string> {
return new Promise<string>(
(resolve: (value: string) => void) => { 1
const readline = require('readline'); 2
const rl = readline.createInterface({ 2
input: process.stdin,
output: process.stdout
});
rl.question("What is your name? ", (name: string) => { 2
rl.close();
resolve(name); 3
});
});
}
- 1 We pass a lambda to the Promise constructor, which expects as argument a resolve() function.
- 2 We use the same code as in greet() to read a string from stdin.
- 3 Finally, when we have a name, we call the provided resolve() function and pass it the name.
getUserName() simply creates and returns a promise. The promise is initialized with a function that takes a resolve argument of type (value: string) => void. This function contains the code to ask the user to provide their name, and when the name is provided, the function calls resolve() to pass the value to the promise.
If we implement long-running functions to return promises, we can chain these asynchronous calls together by using Promise.then() to make our code more readable.
6.4.3. More about promises
There’s more to promises than providing continuations. Let’s see how promises handle errors and a couple more ways to sequence their execution beyond using then().
Handling errors
A promise can be in one of three states: pending, settled, and rejected. Pending means that the promise has been created but not yet resolved (that is, the provided function responsible for providing a value hasn’t called resolve() yet). Settled means that resolve() was called and a value is provided, at which point continuations are called. But what happens if there is an error? When the function responsible for providing a value throws an exception, the promise enters the rejected state.
In fact, the function responsible for providing a value to the promise can take an additional function as an argument, so it can set the promise in the rejected state and provide a reason for that. Instead of providing
(resolve: (value: T) => void) => void
to the constructor, callers can provide a
(resolve: (value: T) => void, reject: (reason: any) => void) => void
The second argument is a function (reason: any) => void, which can provide a reason of any type to the promise and mark it as rejected.
Even without calling reject(), if the function throws an exception, the promise will automatically consider itself to be rejected. Besides the then() function, a promise exposes a catch() function in which we can provide a continuation to be called when the promise is rejected for whatever reason (figure 6.10).
Figure 6.10. A promise starts in the pending state. (getUserName() scheduled the code to prompt the user, but question() hasn’t returned yet.) resolve() transitions it to the settled state and invokes a continuation if one is provided (after the user provided their name). A value is available so the continuation can be called (getUserEmail(), in our case). reject() transitions the promise to the rejected state and invokes an error-handling continuation, if one is provided. A value is not available; a reason for the error is available instead.
Let’s extend our getUserName() function to reject an empty string in the next listing.
Listing 6.18. Rejecting a promise
function getUserName(): Promise<string> {
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
return new Promise<string>(
(resolve: (value: string) => void,
reject: (reason: string) => void) => { 1
rl.question("What is your name? ", (name: string) => {
rl.close();
if (name.length != 0) {
resolve(name);
} else {
reject("Name can't be empty"); 2
}
});
});
}
getUserName()
.then((name: string) => { console.log(`Hi ${name}!`); })
.catch((reason: string) => { console.log(`Error: ${reason}`); }); 3
- 1 We provide the additional reject argument.
- 2 If name.length is 0, we reject the promise.
- 3 The new continuation hooked up with catch() gets called on reject (or if an exception is thrown).
Not only does a promise get rejected, either via a call to reject() or due to an error being thrown, but also all other promises chained to it via then() get rejected. A catch() continuation added at the end of a chain of then() calls will get called if any of the promises in the chain is rejected.
Chaining synchronous functions
There are more ways to chain continuations together than what we’ve covered so far. First, a continuation doesn’t have to return a promise. We don’t always chain asynchronous functions; maybe the continuation is short-running and can be executed synchronously. Let’s take another look at our original example in the following listing, in which all our continuations returned promises.
Listing 6.19. Chaining functions returning promises
getUserName() 1
.then((name: string) => {
console.log(`Hi ${name}!`);
return getUserBirthday(name); 2
})
.then((birthday: Date) => {
const today: Date = new Date();
if (birthday.getMonth() == today.getMonth() &&
birthday.getDay() == today.getDay())
console.log('Happy birthday!');
return getUserEmail(birthday); 3
})
.then((email: string) => {
/* ... */
});
- 1 getUserName() returns a Promise<string>.
- 2 getUserBirthday() returns a Promise<Date>.
- 3 getUserEmail() returns a Promise<string>.
In this case, all our functions need to run asynchronously, as they expect user input. But what if after we get the user’s name, we simply want to splice it inside a string and return that? If our continuation is just return `Hi ${name}!`, it returns a string, not a promise. But that’s OK; the then() function automatically converts it in a Promise-<string> so that it can be further processed by another continuation, as shown in the following code.
Listing 6.20. Chaining functions that don’t return promises
getUserName()
.then((name: string) => {
return `Hi ${name}!`; 1
})
.then((greeting: string) => {
console.log(greeting);
});
This should make sense intuitively: even if our continuation just returns a string, because it is chained to a promise, it can’t execute right away. That fact automatically makes it a promise to be settled when the original promise is settled.
Other ways to compose promises
So far, we’ve looked at then() (and catch()), which chain promises together so that they settle one after the other. There are a couple more ways to schedule the execution of asynchronous functions: via Promise.all() and Promise.race(). These are static methods provided on the Promise class. Promise.all() takes as arguments a set of promises and returns a promise that is settled when all the provided promises are settled. Promise.race() takes a set of promises and returns a promise that is settled when any one of the promises is settled.
We can use Promise.all() when we want to schedule a set of independent asynchronous functions, such as fetching user inbox messages from a database and their profile picture from a CDN, and then passing both values to the UI, as shown in listing 6.21. We don’t want to sequence these fetching functions one after another, because they don’t depend on one another. On the other hand, we do want to gather their results and pass them to another function.
Listing 6.21. Using Promise.all() to sequence execution
class InboxMessage { /* ... */ }
class ProfilePicture { /* ... */ }
declare function getInboxMessages(): Promise<InboxMessage[]>; 1
declare function getProfilePicture(): Promise<ProfilePicture>; 1
declare function renderUI( 2
messages: InboxMessage[], picture: ProfilePicture): void;
Promise.all([getInboxMessages(), getProfilePicture()]) 3
.then((values: [InboxMessage[], ProfilePicture]) => { 4
renderUI(values[0], values[1]); 5
});
- 1 getInboxMessages() and getProfilePicture() are independent asynchronous functions.
- 2 renderUI() needs the result from both functions.
- 3 Promise.all() creates a promise settled when both functions resolve their promises.
- 4 values is a tuple containing both results.
- 5 We pass the values retrieved to renderUI().
A pattern like this would be significantly harder to achieve with callbacks, as there is no mechanism to join them.
Let’s look at an example of using Promise.race() in the next listing. Suppose that the user profile is replicated across two nodes. We try to fetch it from both, and whichever is the fastest wins. In this case, as soon as we get a result from any one of the nodes, we can proceed.
Listing 6.22. Using Promise.race() to sequence execution
class UserProfile { /* ... */ }
declare function getProfile(node: string): Promise<UserProfile>;
declare function renderUI(profile: UserProfile): void;
Promise.race([getProfile("node1"), getProfile("node2")]) 1
.then((profile: UserProfile) => { 2
renderUI(profile);
});
- 1 We call getProfile() once for each of the nodes.
- 2 The argument to the continuation is a single UserProfile in this case—the one that won the race.
This scenario would be more difficult to achieve by using callbacks without promises (figure 6.11).
Figure 6.11. Different ways to combine a promise. Then: Promise 1 settles and hands out Value 1 to Promise 2; Promise 2 settles and hands out Value 2 to Promise 3. All: Promise 1, 2, and 3 settle. When all of them are settled, Promise.all gets all their values and can proceed, settling its own value. Race: One of the promises settles first (in this case, Promise 2). Promise.race gets Value 2 and can proceed, settling its own value.

Promises provide a clean abstraction for running asynchronous functions. They not only make code more readable than using callbacks through the then() and catch() methods, which enable sequencing, but also handle error propagation and joining or racing multiple promises via Promise.all() and Promise.race(). Promise libraries are available in most mainstream programming languages, and they all provide similar functionality, even if the name of the methods is slightly different. (race() is sometimes called any(), for example.)
This is about as far as libraries can go in helping us write clean asynchronous code. Making asynchronous code more readable requires updates to the syntax of the language itself. Much as a yield statement allows us to more easily express a generator function, many languages extended their syntax with async and await to enable us to write asynchronous functions more easily.
6.4.4. async/await
Using promises, we prompted our user for various pieces of information, using continuations to sequence the questions. Let’s take another look at that implementation in the next listing. We’re going to wrap it into a getUserData() function.
Listing 6.23. Chaining promises review
function getUserData(): void {
getUserName()
.then((name: string) => {
console.log(`Hi ${name}!`);
return getUserBirthday(name);
})
.then((birthday: Date) => {
const today: Date = new Date();
if (birthday.getMonth() == today.getMonth() &&
birthday.getDay() == today.getDay())
console.log('Happy birthday!');
return getUserEmail(birthday);
})
.then((email: string) => {
/* ... */
});
}
Notice again that each continuation takes as argument a value of the same type as the type of the promise from the preceding function. async/await allows us to express this better in code. We can draw a parallel with generators and the */yield syntax we discussed in a previous section.
async is a keyword that comes before the keyword function, much as the * appears after the keyword function in generators. In the same way that * can be used only if the function returns an Iterator, async can appear only in a function that returns a Promise, just as *, async does not change the type of the function. function getUserData(): Promise<string> and async function getUserData(): Promise<string> have the same type: () => Promise<string>. The same way that * marks a function as a generator and allows us to call yield inside it, async marks a function as asynchronous and allows us to call await inside it.
We can use await before a function that returns a promise to get the value returned when that promise settles. Instead of writing getUserName().then -((name: string) => { /* ... */ }), we write let name: string = await getUser-Name(). Before walking through how this works, let’s look at how we would write getUserData() with async and await.
Listing 6.24. Using async/await
async function getUserData(): Promise<void> { 1
let name: string = await getUserName(); 2
console.log(`Hi ${name}!`); 3
let birthday: Date = await getUserBirthday(name); 4
const today: Date = new Date();
if (birthday.getMonth() == today.getMonth() &&
birthday.getDay() == today.getDay())
console.log('Happy birthday!');
let email: string = await getUserEmail(birthday); 5
/* ... */
}
- 1 getUserData() must return a Promise because it is marked as async.
- 2 We await getUserName() to settle and give us a name string.
- 3 We can use this name string in this same function.
- 4 We await getUserBirthday() to settle and give us a birthday.
- 5 The same is true for getUserEmail(); we await the settled promise and get the string value.
We immediately see that writing our getUserData() this way makes it even more readable than chaining promises with then(). The compiler generates the same code; there is nothing special under the hood. This technique is simply a nicer way to express a chain of continuations. Instead of putting each continuation in a separate function and connecting them via then(), we can write all the code in a single function, and whenever we call another function that returns a promise, we await its result.
Each await is the equivalent of taking the code after it and placing it in a then() continuation: this reduces the number of lambdas we need to write and makes asynchronous code read just like synchronous code. As for catch(), if there is no value to return, perhaps because we encountered an exception, the exception is thrown from the await call and can be caught with a regular try/catch statement. Simply wrap the await call in a try block to catch the expected errors.
6.4.5. Clean asynchronous code recap
Let’s quickly review the approaches to writing asynchronous code that we covered in this section. We started with callbacks, passing a callback function to an asynchronous function that calls it when its work is done. This approach works, but we’ll usually end up with a lot of nested callbacks within callbacks, which makes code harder to follow. It’s also very difficult to join several independent asynchronous functions if we need the results from all of them to proceed.
Next, we looked at promises. Promises provide an abstraction for writing asynchronous code. They handle scheduling the execution of the code (in languages that rely on threads, they get scheduled on threads) and provide a way for us to provide functions called continuations, which get called when the promise is settled (has a value) or rejected (encountered an error). Promises also provide ways to join and race a set of promises via Promise.all() and Promise.race().
Finally, async/await syntax, now common in most mainstream programming languages, provides an even-cleaner way to write asynchronous code that reads just like regular code. Instead of providing a continuation with then(), we await the result of a promise and continue from there. The underlying code executed by the computer is the same, but the syntax is much nicer to read.
6.4.6. Exercises
Which state does a promise start in?
- Settled
- Rejected
- Pending
- Any
Which of the following chains a continuation to be called when the promise is rejected?
- then()
- catch()
- all()
- race()
Which of the following chains a continuation to be called when a whole set of promises is settled?
- then()
- catch()
- all()
- race()
Summary
- A closure is a lambda that also holds on to a piece of state from its surrounding function.
- We can implement a simpler decorator pattern by using a closure and capturing the decorated function instead of implementing a whole new type.
- We can implement a counter by using a closure that tracks the counter state.
- A generator, written using */yield syntax, is a resumable function.
- Long-running operations should run asynchronously so that they don’t block the rest of the program.
- The two main models for asynchronous execution are threads and event loops.
- A callback is a function passed to an asynchronous function that is invoked when the asynchronous function completes.
- Promises provide a common abstraction for running asynchronous functions and provide continuations as an alternative to callbacks. A promise can be pending, settled (value obtained), or rejected (error encountered).
- Promise.all() and Promise.race() are mechanisms for joining and racing a set of promises.
- async/await is modern syntax for writing promise-based code as though it were synchronous code.
Now that we’ve covered applications of function types in depth, from the basics of passing functions as arguments all the way to generators and asynchronous functions, we’ll move on to the next major topic: subtypes. As we’ll see in chapter 7, there is a lot more to subtypes than inheritance.
Answers to exercises
A simple decorator pattern
A possible implementation returning a function that adds logging to the wrapped factory:
function loggingDecorator(factory: () => Widget): () => Widget { return () => { console.log("Widget created"); return factory(); } }
Implementing a counter
A possible implementation using a closure that captures a and b from the wrapping function:
function fib(): () => number { let a: number = 0; let b: number = 1; return () => { let next: number = a; a = b; b = b + next; return next; } }
A possible implementation using a generator that yields the next number in the sequence:
function *fib2(): IterableIterator<number> { let a: number = 0; let b: number = 1; while (true) { let next: number = a; a = b; b = a + next; yield next; } }
Executing long-running operations asynchronously
d—Both threads and an event loop can be used to implement asynchronous execution.
b—An event loop does not execute code in parallel. It can queue and execute functions asynchronously, but not at the same time.
a—Threads allow parallel execution; multiple threads can run multiple functions at the same time.
Simplifying asynchronous code
c—A promise starts in the pending state.
c—We use catch() to chain a continuation that gets called when a promise is rejected.
c—We use all() to chain a continuation that gets called when all promises are settled.