
PROJECT 6
Hacker Speaker: 1337 Sp34k3r
Are you ready to write a program turns messages into elite hacker speak (1337 sp34k)? You might’ve seen where someone replaces letters with numbers or other letters that resemble the original. A common example is using the number 3 to substitute for the letter E.
To do this, you read a heap about strings, lists, objects, and Python introspection. The code in this project is fairly straightforward, but the ideas that it relies on are quite deep. You’ll also see how crazy powerful Python is to do such amazing stuff with such simplicity. Everything in this project is something you’ll always use in Python!
Waiter, There’s An Object In My String
I thought about calling this section “Brain Explosion,” because it’s so chock-full of information. (My technical editor said she has never witnessed a brain explosion from knowing too much, so I think we’re safe.)
You’re familiar with strings; you ran into your first string literal back in Project 2. Do you remember that you named your Hello World string literal and by naming it you created a variable?
Power up IDLE and do it again right now:
>>> my_message = 'Hello World!'
Look, my editor’s opinions aside (I don’t think she has any medical qualifications), you might want to wrap a bandage around your head before proceeding to the next step. Just in case, you know? When you’ve done that, type this:
>>> dir(my_message)
What is going on here? The built-in dir is one aspect of Python’s Super Introspection Powers! Introspection in computing means that the program can tell you stuff about itself. You can tell from the parentheses that dir is a function. It takes as an optional argument the name of something and provides you with a directory listing of the thing named as its argument. Clear as mud, right?
The dir built-in should’ve printed out something that looks more or less like this:
>>> dir(my_message)
['__add__', '__class__', '__contains__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getslice__', '__gt__', '__hash__', '__init__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_formatter_field_name_split', '_formatter_parser', 'capitalize', 'center', 'count', 'decode', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'index', 'isalnum', 'isalpha', 'isdigit', 'islower', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
These are all names for functions or literals that are associated with your variable my_message. When you typed my_message = 'Hello World!', Python got mad busy. It didn’t just store 'Hello World!' somewhere and make my_message point to it. No, it did a lot more than that:
- It created a prototype data structure.
- It gave that prototype a name (my_message) and assigned 'Hello World!' to that name.
- When it did that, it identified the value as a string. It customized the data structure into one specifically used for string variables.
- It looked up a suite (group) of standard functions and literals that are useful for strings.
- It took that suite and loaded it into the prototype data structure.
Who would’ve thought that Python would get crazy busy just from that simple line of code? The variable my_message is more than just the value 'Hello World!'. Instead, my_message is an object. Object is the word that Python uses for the prototype data structure I talked about. It turns out that everything in Python is an object.
 Every object has a variety of functions and literals. Each of the functions and literals is called an attribute. Attributes that are functions are called methods. If the function is an attribute of a module, then you just call it a function (not a module method).
Every object has a variety of functions and literals. Each of the functions and literals is called an attribute. Attributes that are functions are called methods. If the function is an attribute of a module, then you just call it a function (not a module method).
If you were an object (which you aren’t), you might have attributes like you.height and you.weight. You might have methods like you.go_clean_your_teeth() or you.go_to_bed(), which your parents could call on you. The height and weight attributes hold information about you, while the methods make you do something.
 Don’t forget: Everything in Python is an object.
Don’t forget: Everything in Python is an object.
Dot Your Objects’ Attributes
Knowing that my_message has all these attributes, how do you get them? How do you get to, say, the upper method, which is one of the attributes of my_message by dir? The answer is random. (You already did it with random.randint in Project 3. I snuck it in without telling you.) The object in that case was the module called random. You accessed its function randint by joining them together with a dot.
Using this structure, have a look at the help service for the upper method of your variable my_message:
>>> help(my_message.upper) # spot the dot?
Help on built-in function upper:
upper(…)
S.upper() -> string
Return a copy of the string S converted to uppercase.
This is upper’s docstring. Can you see why Python docstrings are so awesome? All you do is assign a value to a variable. Then you have an object filled with methods — and you don’t need to look in a book or search the Internet to see what they do. The methods themselves tell you what they do.
Try it:
>>> my_message.upper
<built-in method upper of str object at 0x7f3d0803e260>
That’s right, it’s a function. To call it, you need to add parentheses: my_message.upper(). Think of this as a quick and dirty way to tell whether an attribute is a method.
If you know something is a method, add parentheses to call it.
By the way, notice that the printout confirms it’s a method called upper of a str object, and it’s in a specific place in your computer’s memory. Call it:
>>> my_message.upper()
'HELLO WORLD!'
The upper function here creates a new, different literal ('HELLO WORLD!') based on the value in my_message. The value of my_message isn’t changed:
>>> my_message
'Hello World!'
The built-in dir lists a lot of attributes for my_message. Some of those attributes have names that start with double underscores (like this: __getslice). Methods with two underscores are called private methods; the others are called public methods.
When you’re a Python master you can use an object’s private methods to do some funky stuff. (You’ll do a bit with one of them in the address book project.) For now, ignore private methods. Take a few moments to look at the other attributes of my_message and get help on some of its methods.
Reference an attribute of an object by using a dot: object.attribute. object is the name of the object, and attribute is the name of the attribute you want to reference. If the attribute is a method, add parentheses to call the method: object.attribute (<include the method’s arguments, if any, here>).
Meet the List
Did you notice the output of dir(my_message) has those square brackets [] around it? You saw these in the Hello World! project, when you read about range. I told you I’d tell you about the brackets later. It’s later.
Square brackets indicate a list object. Lists are a form of “container” (like a programming bucket) that can store other objects in a specific order. The objects in the list are called elements.
Go Through the Elements of a List
In Project 2 you use the range built-in to create a list and then to iterate (go) through each element in the list. It looks like this:
>>> range(3)
[0, 1, 2]
>>> for i in range(3):
print(i)
0
1
2
The range(3) is the list [0, 1, 2]. The line for i in range(3): is therefore equal to for i in [0, 1, 2]:. It assigns to i the value of each element in the list one at a time. There’s nothing special about the list being a list of numbers; you can use this for i in Y structure for any object (Y in this example) that contains other objects. For example, the dir built-in gives you a list of strings. (You can tell they’re strings because they have single quotes around each of them.)
To print each my_message attribute on a separate line, you can do this:
>>> for i in dir(my_message):
print i
__add__
__class__
__contains__
[…]
It doesn’t actually print […]. That just shows that I’ve left stuff out.
Run the program yourself to get the full output. Your Python-is-mad-crazy-alert should be flashing right now as well. If you have any list at all, you can go through each item in the list by entering just a simple line of code — for element in listname:.
You can store a list just as you can a literal:
>>> string_object_attributes = dir(my_message)
>>> string_object_attributes
['__add__', '__class__', '__contains__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getslice__', '__gt__', '__hash__', '__init__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_formatter_field_name_split', '_formatter_parser', 'capitalize', 'center', 'count', 'decode', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'index', 'isalnum', 'isalpha', 'isdigit', 'islower', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
Since everything in Python is an object — did I mention that? — you can use the dir built-in on this list as well:
>>> dir(string_object_attributes)
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__delslice__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getslice__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__',' '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__setslice__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
I just want you to notice here that these two lists are different. That’s because the first list is the attributes of the my_message object (which is a string) and the second list is the string_object_attributes attributes. The lists are different because the objects are different types. The first is an object of type string (technically, the type is str) and the second is an object of type list. You’ll read about the differences of each type as they’re introduced. For now just carry the super-heavy knowledge that each object has a type.
Create Your Own List
You can either create a list with elements already in it (like buying a bucket filled with candy), or you can create an empty list (like buying an empty bucket). Sometimes you want an empty bucket and sometimes you want one with candy in it. You can add elements to a list (and remove them) later if you want to. If you want to create a list with elements already in it, do this:
- Start with an opening square bracket.
- Put the elements in and separate each one with a comma. Each element can be a literal, a variable, or any other Python object.
- End with a closing square bracket.
For example, if numbers are candy, this list is premade with candy:
>>> new_list = [0, 1, 2]
If you don’t have elements when you create the list, you can still create a list by skipping Step 2! You get an empty list. Do it like this:
>>> new_list2 = []
You can add new elements to the end of a list with the append method. All list objects have an append method:
>>> new_list2.append('element 0')
>>> new_list2
['element 0']
You can mix and match different object types in a list. The list doesn’t care what you put in it. The new_list object has numbers in it, but you can add a string to the end of it:
>>> new_list = [0, 1, 2]
>>> new_list.append("a string")
>>> new_list
[0, 1, 2, 'a string']
append always adds to the end of the list. This example mixes numbers and a string in the same list, but you can put any objects into a list. You can append the list to itself, but don’t go there!
Create a List on Steroids
If you can create the elements in your list from an existing list according to a formula, then Python has a shorthand form for creating it: list comprehension. Actually, any iterator will do, but we’re talking about lists at the moment.
Create a list comprehension like this:
- Open with a square bracket.
- Choose one (or more) dummy variables.
- Write a formula involving the dummy variables.
- Follow the formula with a for statement for each dummy variable.
- Close with a square bracket.
For example, if you want the first ten even numbers (starting at 0), you’d use what’s in Figure 6-1.

Figure 6-1: Create the even numbers from 0 to 18 using a list comprehension.
When it runs into this list comprehension, Python
- Creates an empty list.
- Goes through each element in the list generated by range(10) and stores its value in a dummy variable named x. That is, it runs through the following numbers in this order — 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Remember range starts from 0.
- For each, it applies the formula (in this case, 2*x) to the value in x and appends the result to the list.
- Finishes creating the list when it has gone through all the elements in range(10).
This is an insanely easy and powerful way to create a new list. List comprehension lets you add conditions as well. This means you can filter out a subset of the elements you’re creating. For example, to get all of the even numbers less than 10, you can add a condition at the end of the list comprehension:
>>> [x for x in range(10) if x%2 == 0]
[0, 2, 4, 6, 8]
Here the condition if x%2 == 0 says that the number is even. On the left side is the modulo operator. It gives the remainder left over after dividing the left side by the right side. (The guessing game project covers this.) If you divide even numbers by 2, the remainder is 0. For each of the even numbers, the if condition will be true and x added. For the odd numbers, it’s false and they’re skipped.
Test Whether an Element’s In a List
You can tell, pretty easily, whether an element is in a list. Just use the in keyword:
>>> 0 in [0,1]
True
>>> 5 in [0,1]
False
It’s true that the element 0 is in the list [0,1], but false that the number 5 is in that list. You can reverse the logic by using the not keyword:
>>> 0 not in [0,1]
False
>>> 5 not in [0,1]
True
Planning Your Elite Hacker Speaker
Your 1337 Sp34k3r needs to do this stuff:
- Receive a message from the user. (You can use raw_input for that.)
- Run through each letter in that message and, if it’s a letter that can be substituted in elite speak, make the substitution.
- Construct a new message and print it out.
Set Up Your File
Time to start putting together a skeleton of your program. You can fill in the details a little later.
-
Create a file to store your code. Name the file 1337.py.
Make sure to include the .py ending. Project 4 explains how to create a file if you want a reminder.
-
Write a docstring at the top of the file explaining what the file is supposed to do.
That’s you creating a module docstring.
- Create a constant called TEST_MESSAGE and assign to it a test message string.
-
Create a constant called TEST_SUBSTITUTIONS. Assign to it a test substitution to work with. Make this test substitution a list containing one element: ['e','3'].
Be careful, this is a trick!
This is what I came up with:
""" 1337.py
Given a message, convert it into 1337 sp34k
Brendan Scott
January 2015 """
TEST_MESSAGE = "Hello World!"
TEST_SUBSTITUTIONS = [['e','3']]
Did you remember to include double square brackets for the test substitution list? I was serious when I said ['e','3'] is a single element. To make a list out of it, you have to put square brackets around it: [['e','3']]. Running this program won’t do anything interesting, but you change that in a sec.
Create a function stub
The next step is to create a function stub for the function that will code the message into 1337.
- Use a block comment (a # hash) to mark a Function section.
- Think of a name for the function and create a function stub in your new function section.
-
Think of names for two dummy variables that the function will use.
The function takes a message to code, as well as a list of substitutions to be performed. You’re naming those two variables.
- Add a docstring to explain what the function is doing.
- Use a block comment to mark a testing section in your code.
- In the testing section, add a call to the function using the test variables you created. Assign the return value from this call to a variable.
- Print the variable.
I came up with this:
#### Functions Section
def encode_message(message, substitutions):
"""Take a string message and apply each of the substitutions
provided. Substitutions should be a list, the elements of
substitutions need to be lists of length 2 of the form
(old_string, new_string) """
#### Testing Section
converted_text = encode_message(TEST_MESSAGE, TEST_SUBSTITUTIONS)
print(converted_text)
Run the code
Save the file and run the code: Press F5 or choose Run ⇒ Run Module from the menu. Are there any problems so far? You should get this output in the interactive Shell:
>>> ================================== RESTART ================================
>>>
None
Not much, is it? Because the function encode_message doesn’t use the return keyword, the value assigned to the variable converted_text is None. Makes sense. You’ve established the basic program flow to and from the encode_message function.
You could have had the function return the message it was passed (probably not good because it wouldn’t flag that it was ignoring any substitutions) or returned a debugging message like "Function not implemented yet!" or returned None. I prefer not returning a value at the stub stage. I just find it easier, but it depends a little on the situation.
Make Code Letter Substitutions
The next task is to take encode_message and make it do something: replace letters. To change a string like speak to sp34k, replace the specific letters in the string. It just so happens that strings (objects of the str type) have their own method called replace. Find out what it does by looking at its docstring:
>>> my_message = 'Hello World!'
>>> help(my_message.replace)
Help on built-in function replace:
replace(…)
S.replace(old, new[, count]) -> string
Return a copy of string S with all occurrences of substring
old replaced by new. If the optional argument count is
given, only the first count occurrences are replaced.
Use your existing my_message text as a test message. According to the documentation that you have just printed out in the code readout only two lines previous, in order to use this method you need to have two string variables, one named old, the other named new. These are fed into the method as arguments.
>>> my_message = 'Hello World!'
>>> old = 'e'
>>> new = '3' # remember the quotes
>>> new_string = my_message.replace(old,new)
>>> new_string
'H3llo World!'
A new copy of the string Hello World! was created. Then (actually, while it was being created), the e in Hello was replaced by a 3 (and stored in new_string). The original variable my_message remains unchanged. It’s important that both old and new are strings; however, you don’t need to save them into separate variables. Using bare string literals will still work:
>>> new_string = my_message.replace('e','3')
>>> new_string
'H3llo World!'
Don’t feel like you’re forced to needlessly create variables to fill names in a method’s documentation. That said, I’ve chosen to use old and new because it will make the logic a little easier later.
Replace a Letter
Now fill in the replacement code in the function itself. The function needs to
-
Iterate (go through) each substitution it’s given.
I say each because the function is written to receive a list of substitutions. I know that you’re only testing it with one substitution. When you’re coding, you need to anticipate the general case.
for s in substitutions: -
Unpack each substitution.
You get it as a list of two strings. You need to unpack the list to separate strings to give them to the replace method.
old = s[0]new = s[1] - Use the replace() method of the message variable to apply each of the substitutions.
converted = message.replace(old,new) - Return the encoded message.
return converted
Here’s the code so far:
""" 1337.py
Given a message, convert it into 1337 sp34k
Brendan Scott
January 2015 """
TEST_MESSAGE = "Hello World!"
TEST_SUBSTITUTIONS = [['e','3']]
#### Function Section
def encode_message(message, substitutions):
"""Take a string message and apply each of the substitutions
provided. Substitutions should be a list, the elements of
substitutions need to be lists of length 2 of the form
(old_string, new_string) """
for s in substitutions:
old = s[0]
new = s[1]
converted = message.replace(old,new)
return converted
#### Testing Section
converted_text = encode_message(TEST_MESSAGE, TEST_SUBSTITUTIONS)
print(TEST_MESSAGE)
print(converted_text)
When it runs, you get this:
>>> ================================= RESTART ===============================
>>>
Hello World!
H3llo World!
Everything seems to work fine. However, this code has a logical error. It works with the test substitution you set up, but fails when you try to generalize it. Have a think about what the problem is and how you would solve it. All will be revealed in a moment!
 Errors in program logic are hard to spot. The Python interpreter can’t see them because the code is valid — it just doesn’t do what you want it to do. They come up mainly because you misunderstand how Python is flowing through your program, or because you misunderstand what values your variables are taking.
Errors in program logic are hard to spot. The Python interpreter can’t see them because the code is valid — it just doesn’t do what you want it to do. They come up mainly because you misunderstand how Python is flowing through your program, or because you misunderstand what values your variables are taking.
You’re super familiar with the code you’ve written and people tend to make assumptions about what their code’s actually doing. Explaining your problem in words (talking to your goldfish/pet rock/balloon with a face drawn on it/blank wall/unsuspecting relative) helps break you out of this way of thinking. If you can, go through this book with a coding buddy. You can talk to each other about the issues you find.
Let the User Enter a Message
You know how to get text input from a user. You did it in Project 3:
- Get a text message from the user using raw_input.
- Assign the user’s input to a variable.
- Pass that variable to the encode_message function.
- Print out the message to be encoded.
- Print the output of the call to encode_message.
""" 1337.pyGiven a message, convert it into 1337 sp34kBrendan ScottJanuary 2015 """TEST_MESSAGE = "Hello World!"TEST_SUBSTITUTIONS = [['e','3']]#### Function Sectiondef encode_message(message, substitutions):for s in substitutions:"""Take a string message and apply each of the substitutionsprovided. Substitutions should be a list, the elements ofsubstitutions need to be lists of length 2 of the form(old_string, new_string) """old = s[0]new = s[1]converted = message.replace(old,new)return converted#### Testing Sectionmessage = raw_input("Type the message to be encoded here: ")converted_text = encode_message(message, TEST_SUBSTITUTIONS)print(message)print(converted_text)
Did you remember to change the final print from TEST_MESSAGE to message?
Run the program to make sure it works. Type your own message if you like, but make sure it has at least one e in it, or nothing will happen.
>>> ================================== RESTART ================================
>>>
Type the message to be encoded here: Python is awesome
Python is awesome
Python is aw3som3
Define Letter Substitutions
Changing all the es to 3s won’t cut the mustard with your h4ck3r friends. You need more! More, I tell you! The elite speak substitutions that I suggest are set out here. But this is your project, so freestyle it if you want to.
Letter |
Substitute By |
a |
4 |
e |
3 |
l |
1 |
o |
0 |
t |
7 |
You can code each of these substitutions as a list, with the order in the list having a meaning. For example: ['a','4'] stores the letter to be replaced as the first item (at location 0) and the letter to replace with the second item (at location 1). You can’t write [a,4] because Python will think a is the name of a variable rather than a string.
You could write these substitutions like this:
['a','4'], ['e','3'], ['l','1'], ['o','0'], ['t','7']
Create your substitutions list by putting square brackets around all of this. Here is how you do it with some code that prints out each of the elements:
>>> substitutions = [['a','4'], ['e','3'], ['l','1'], ['o','0'],
['t','7']]
>>> for s in substitutions:
print s
['a', '4']
['e', '3']
['l', '1']
['o', '0']
['t', '7']
I used the trick I mentioned to print out each of the elements in the list named substitutions. Just to recap:
- This list has five elements.
- Each of these elements is itself a list. Each of these lists only has two elements.
- Each of those two elements is a string, and each of those strings has only one character in it.
Why have I asked you to create a list called substitutions when there’s only one substitution? At the moment we’re keeping it simple. The code will be written so that it doesn’t matter how many elements there are. For example, in the for loop for s in substitutions:, the code works the same whether there is one substitution in the list or five.
You write the code with a single substitution for testing. When things work for one substitution, you change the code to deal with multiple substitutions by adding more.
It’s awesome to be filled with inspiration and pound out line after line of code. But unless you’re perfect — and no one is — those lines of code will have errors. The more lines you produce without testing, the harder it is to find the errors. Break your code into parts and prove each part separately. Join two parts together, then test that join.
Apply all the Substitutions
When everything is in order and the code seems to work for a single substitution, you can use all the substitutions set out earlier:
- Add a constant SUBSTITUTIONS and assign to it the substitutions given earlier.
- Pass SUBSTITUTIONS to the encoding function.
-
Delete the test variables.
Or, you can keep them for future testing.
""" 1337.pyGiven a message, convert it into 1337 sp34kBrendan ScottJanuary 2015 """TEST_MESSAGE = "Hello World!"##TEST_SUBSTITUTIONS = [['e','3']]SUBSTITUTIONS = [['a', '4'], ['e', '3'], ['l', '1'], ['o', '0'],['t', '7']]#### Function Sectiondef encode_message(message, substitutions):"""Take a string message and apply each of the substitutionsprovided. Substitutions should be a list, the elements ofsubstitutions need to be lists of length 2 of the form(old_string, new_string) """for s in substitutions:old = s[0]new = s[1]converted = message.replace(old,new)return converted#### Testing Sectionmessage = raw_input("Type the message to be encoded here: ")converted_text = encode_message(message, SUBSTITUTIONS)print(message)print(converted_text)
This sample code is what you use later with the IDLE debugger. Now that that’s done, you can triumphantly run your 1337 speaker:
>>> ================================== RESTART ================================
>>>
Type the message to be encoded here: Python is awesome
Python is awesome
Py7hon is awesome
Oh. That isn’t supposed to happen. The os are supposed to be 0s and the es are supposed to be 3s, and so on. One substitution worked — t->7. The logic error has come back to bite me. How come just one substitution is being applied?
Use print to Debug the Code
Thanks to a woman named Grace Hopper, the process of removing errors from code is known as debugging. Debugging is a skill. The more you do it, the better you’ll get.
Try these strategies to debug this code:
- Include a print statement to output relevant data. What’s relevant will change depending on what’s going on. Start with the data that the program is manipulating when the error occurs and move out from there.
- Add print statements into the code to track what’s going on where. For example, add print("I've just entered function X") or print("Leaving function X") at the start and end of function X. These help you understand the program’s flow.
- Vary the SUBSTITUTIONS constant to see what effect that has on the replacements.
- Be watchful. The place where the error is revealed isn’t always where the error is. Backtrack through how the program got to the point where the error showed itself and look for errors there.
That’s the strategy you use here. Now:
- Include one or more print statements somewhere in the program.
- Make each print statement print either a variable or the location within the program that has been reached — like print("Leaving encode_message").
- Run the program and review the output to see what’s going on.
I came up with this. Look at the comments to see what’s been changed:
""" 1337.py
Given a message, convert it into 1337 sp34k
Brendan Scott
January 2015 """
TEST_MESSAGE = "Hello World!"
##TEST_SUBSTITUTIONS = [['e','3']]
SUBSTITUTIONS = [['a', '4'], ['e', '3'], ['l', '1'], ['o', '0'],
['t', '7']]
#### Function Section
def encode_message(message, substitutions):
"""Take a string message and apply each of the substitutions
provided. Substitutions should be a list, the elements of
substitutions need to be lists of length 2 of the form
(old_string, new_string) """
for s in substitutions:
old = s[0]
new = s[1]
converted = message.replace(old,new)
print("converted text = "+converted) # Added
print("Leaving encode_message") # Added
return converted
#### Testing Section
message = raw_input("Type the message to be encoded here: ")
converted_text = encode_message(message, SUBSTITUTIONS)
print("started with "+message) # Changed
print("Converted to "+converted_text) # Changed
In this code I added two print statements. The first shows the value of the string converted after each replacement. (Check out the indentation levels of the various print statements.) As you know, the indentation level determines whether the statement is inside or outside the code block. The second, which reads print("Leaving encode_message"), shows where the program leaves the encode_message function.
When you run this code, you get this output:
>>> ================================== RESTART ================================
>>>
Type the message to be encoded here: Python is awesome
converted text = Python is 4wesome
converted text = Python is aw3som3
converted text = Python is awesome
converted text = Pyth0n is awes0me
converted text = Py7hon is awesome
Leaving encode_message
started with Python is awesome
Converted to Py7hon is awesome
I guessed earlier that only the last replacement worked because that showed up in the earlier print statements (last two lines in this readout). I was wrong! This printout shows that each replacement is happening correctly — but they keep being made to the original string, so they’re not cumulative. Each substitution is new, rather than being made to the output of the previous substitution.
This is an example of a problem with the programming logic. Rather than working on the string-as-substituted, each substitution operated on the original string, pretty much getting rid of the earlier work.
You can solve this by getting rid of the variable converted in the function encode_message. Instead, you store the replaced text back into the message variable. However, you have to remember to change the print functions that refer to converted to message. You also need to return message, rather than converted. Make these changes and run your code. Yup, you can work those changes out for yourself. Don’t run screaming from the room.
You should get this code:
""" 1337.py
Given a message, convert it into 1337 sp34k
Brendan Scott
January 2015 """
TEST_MESSAGE = "Hello World!"
##TEST_SUBSTITUTIONS = [['e','3']]
SUBSTITUTIONS = [['a','4'], ['e','3'], ['l','1'], ['o','0'], ['t','7']]
#### Function Section
def encode_message(message, substitutions):
"""Take a string message and apply each of the substitutions provided.
Substitutions should be a list, the elements of substitutions need to
be lists of length 2 of the form (old_string, new_string) """
for s in substitutions:
old = s[0]
new = s[1]
message = message.replace(old,new) # Changed
print("converted text = "+message)
print("Leaving encode_message") # Changed
return message # Changed
#### Testing Section
message = raw_input("Type the message to be encoded here: ")
converted_text = encode_message(message, SUBSTITUTIONS)
print("started with "+message)
print("Converted to "+converted_text)
This code should give you this output:
>>> ================================== RESTART ================================
>>>
Type the message to be encoded here: Python is awesome
converted text = Python is 4wesome
converted text = Python is 4w3som3
converted text = Python is 4w3som3
converted text = Pyth0n is 4w3s0m3
converted text = Py7h0n is 4w3s0m3
Leaving encode_message
started with Python is awesome
Converted to Py7h0n is 4w3s0m3
Go back and remove the print statements that you put in for debugging. You can do this either by literally deleting them or by putting a hash (#) in front of them.
Remember, hashes (#) comment out the code that follows on that line.
Debug with IDLE’s Debugger
IDLE has an integrated debugger. It can stop the code at fixed points (called breakpoints) and step through what’s there. The debugger also shows you the values of the variables. A detailed review of the debugger is beyond the scope of this book, but here’s a quick taste. If you like it investigate further!
Mac users: IDLE’s debugger might work properly or it might not. It depends on what Mac you have and what version of Python was loaded on it and, possibly, the phase of the moon. Try Cmd-click instead of right-click. If that doesn’t work, you’ll have to skip this bit.
- Go back to the code at the end of the steps in “Apply All the Substitutions.”
- Open a new file in IDLE and copy this code into it.
- Save the file as idle_debugger.py.
-
On the IDLE Shell window, choose Debug ⇒ Debugger.
This brings up the Debug Control window shown in Figure 6-2.
-
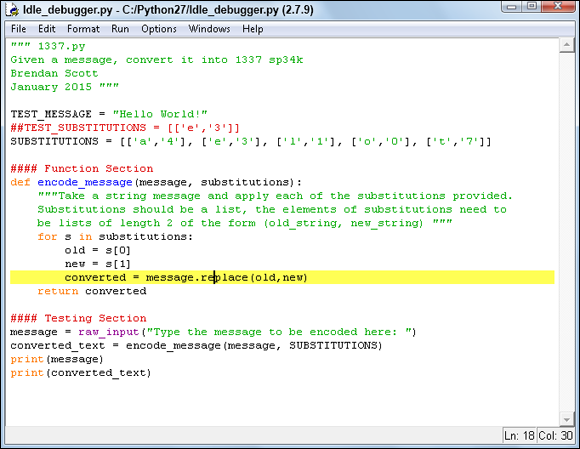
Go to the IDLE Editor window. Right-click line 18 and select Set Breakpoint.
Mac users: Try Cmd-click, knowing that it might not work.
You can see the line number in the bottom-right corner in Figure 6-3. When you set the breakpoint, the line of code where you set it is highlighted in yellow.
-
With the breakpoint set, run the code as your normally would.
Instead of running the whole code, IDLE prepares to start at the start of the file and then gives control to the Debug Control window. The window used to be drab and boring, but now it springs to life! In a boring sort of way. See Figure 6-4.
The Debug Control window tells you:
- That you’re on line 4 of idle_debugger.py.
- That the code you’re about to run ends with: January 2015""". (If the line is short enough, you’ll see all the code on the line.)
- The values of local variables (in the Locals part of the window).
-
Click the Go button in the top-left corner of the Debug Control window.
The raw_input line had asked you for input in the IDLE Shell window. Go tells Python to run the code until it reaches a breakpoint. At the moment it hasn’t reached a breakpoint, but it has hit a raw_input line, and the program needs some text before it can continue.
-
Go to that window and type "Python is awesome" in the prompt. Then press Enter. See Figure 6-5 for what happens.
The Debug Control window has changed a bit now. It now tells you:
- That you’re on line 18, in a function called encode_message().
- The values of all the variables being used within encode_message() in the Locals part of the window. This substitution is ['a','4'], that the value of new is '4', and that the value of old is 'a'.
-
Click the Go button again.
The code runs until it reaches a breakpoint. Because the breakpoint is in a loop, the code stops on the next iteration of the loop. You can see in the Locals section that a new local, called converted, has been added to the list of locals. You can also see that the value of message hasn’t changed.
Pressing the Go button again makes the same thing happen again. The local message doesn’t change. And even though converted changed (the es have been replaced), in the previous pass the a was a 4; now it’s been changed back. By now you’d probably have twigged (which means worked out, where I come from) that you’re not updating the message variable (which you noticed when you used print to print out the values).

Figure 6-2: IDLE’s Debug Control window looks like this.

Figure 6-3: Set a breakpoint from the menu.

Figure 6-4: The Debug Control window springs to life!

Figure 6-5: This is what happens after you press Enter.
Play around with the other buttons to see what they do.
Get rid of breakpoints by right-clicking (Mac users: Try Cmd-click) the line where the breakpoint is and clicking Clear Breakpoint. To turn off the debugger, choose Debug ⇒ Debugger from the IDLE Shell window.
Summary
In this project you read a lot about objects, lists, and debugging techniques. You
- Discovered that everything in Python is an object and that there are different types.
- Read that each object has a unique ID, which records where the object is stored in the computer’s memory.
- Worked with objects that have attributes. Some of those attributes are like variables or literals, and others are like functions. (These attributes are called methods.)
- Referred to an attribute called attribute_name of an object called object_name by using the dot syntax: object_name.attribute_name. Add parentheses and arguments if it’s a method (called method_name): object_name.method_name(argument_name).
- Saw some methods of list objects change the list in place. Watch those: They give you a return value of None.
- Created a new data type — the list — and learned that lists have elements.
- Created a list with a list comprehension and using a conditional.
- Used in to test whether a certain value is an element of a list. To test that it isn’t an element, you used not in. (Both are keywords!)
- Used the replace method of string objects.
- Debugged code using print statements and by using the IDLE debugger.
- Set breakpoints to stop code using the IDLE debugger.
- Inspected the values of local variables as code is running.