
Eliminating Duplicate Rows from Output
In some situations, you might want to display only
the unique values or combinations of values in the column(s) listed
in the SELECT clause. You can eliminate duplicate rows from your query
results by using the keyword DISTINCT in the SELECT clause. The DISTINCT
keyword applies to all columns, and only those columns, that are listed
in the SELECT clause. We see how this works in the following example.
Example
Suppose you want to
display a list of the unique flight numbers and destinations of all
international flights that are flown during the month.
The following SELECT
statement in PROC SQL selects the columns FlightNumber and Destination
in the table Sasuser.Internationalflights:
proc sql outobs=12;
select flightnumber, destination
from sasuser.internationalflights;Here is the output.
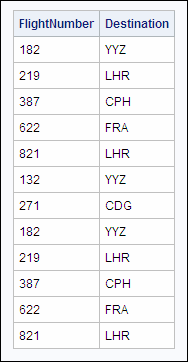
As you can see, there
are several duplicate pairs of values for FlightNumber and Destination
in the first 12 rows alone. For example, flight number 182 to YYZ
appears in rows 1 and 8. The entire table contains many more rows
with duplicate values for each flight number and destination because
each flight has a regular schedule.
To remove rows that
contain duplicate values, add the keyword DISTINCT to the SELECT statement,
following the keyword SELECT, as shown in the following example:
proc sql;
select distinct flightnumber, destination
from sasuser.internationalflights
order by 1;With duplicate values
removed, the output contains many fewer rows, so the OUTOBS= option
has been removed from the PROC SQL statement. Also, to sort the output
by FlightNumber (column 1 in the SELECT clause list), the ORDER BY
clause has been added.
Here is the output from
the modified program.
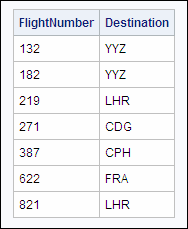
There are no duplicate
rows in the output. There are seven unique FlightNumber-Destination
value pairs in this table.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.