
Chapter 9. Concurrency programming in Scala
- Challenges with concurrent programming
- The actor programming model
- Handling faults in actors
- Composing concurrent programs with Future and Promise
In this chapter I introduce the most exciting feature of Scala: its actor library. Think of an actor as an object that processes a message (your request) and encapsulates state (state is not shared with other actors). The ability to perform an action in response to an incoming message is what makes an object an actor. At the high level, actors are the way you should do OOP. Remember that the actor model encourages no shared state architecture. In this chapter, I explain why that’s an important property to have for any concurrent program.
Future and Promise provide abstractions to perform concurrent operations in a nonblocking fashion. They are a great way to create multiple concurrent and parallel computations and join them to complete your job. This is very similar to how you compose functions, but, in this case, functions are executed concurrently or in parallel. Think of Future as a proxy object that you can create for a result that will be available at some later time. You can use Promise to complete a Future by providing the result. We will explore Promise and Future as this chapter progresses. First let’s understand what I mean by concurrent and parallel programming.
9.1. What is concurrent programming?
Concurrency is when more than one task can start and complete in overlapping time periods. It doesn’t matter whether they’re running at the same instant. You can write concurrent programs on a single CPU (single execution core) machine where only one task can execute at a given point of time. Typically multiple tasks are executed in a time-slice manner, where a scheduler (such as the JVM) will guarantee each process a regular “slice” of operating time. This gives the illusion of parallelism to the users. And the common de facto standard way to implement a multitasking application is to use threads. Figure 9.1 shows how a multitasking application shares a single CPU.
Figure 9.1. A concurrent application running in a single CPU core with two threads

As you can see in figure 9.1, two threads are executing instructions generated by the application in a time-sliced manner. The group of instructions varies in size because you don’t know how much code will be executed before the scheduler decides to take the running thread out and give another thread the opportunity to execute. Remember that other processes running at the same time might need some CPU time—you can see it’s pretty unpredictable. Sometimes schedulers use a priority mechanism to schedule a thread to run when there’s more than one thread in a ready-to-run state.[1] Things become more interesting when you have code that blocks for resources, such as reading data from a socket or reading from the filesystem. In this case, even though the thread has the opportunity to use the CPU, it can’t because it’s waiting for the data, and the CPU is sitting idle. I’ll revisit this topic in section 9.4.
1 Java thread states (download), http://mng.bz/w1VH.
Most people use concurrency and parallel programming interchangeably, but there’s a difference. In parallel programming (figure 9.2), you can literally run multiple tasks at the same time, and it’s possible with multicore processors.
Figure 9.2. A concurrent and parallel application running in a two-CPU core with two threads. Both threads are running at the same time.

A concurrent program sometimes (in the next section I will explain why not always) becomes a parallel program when it’s running in a multicore environment. This sounds great, because all the CPU vendors are moving toward manufacturing CPUs with multiple cores. But it poses a problem for software developers because writing concurrent, parallel applications is hard. Imagine that, while executing the multitasking application in parallel mode (figure 9.2), Thread 1 needs data from Thread 2 before proceeding further, but the data isn’t available. In this case, Thread 1 will wait until it gets the data, and the application is no longer parallel. The more data and state sharing you have among threads, the more difficult it’ll be for the scheduler to run threads in parallel. Throughout this chapter you’ll try to make your concurrent program run in parallel mode as much as you can.
Another term that’s used often with concurrency is distributed computing. The way I define distributed computing is multiple computing nodes (computers, virtual machines) spanned across the network, working together on a given problem. A parallel process could be a distributed process when it’s running on multiple network nodes. You’ll see an example of this in chapter 12 when we deploy actors in remote nodes so they can communicate across the network. But now let’s look at the tools you can use to solve concurrency issues and the challenges associated with it.
9.2. Challenges with concurrent programming
Chapter 1 discusses the current crisis[2] we’re facing with the end of Moore’s law. As a software engineer, I don’t think we have a choice but to support multicore processors. The CPU manufacturers are already moving toward building multicore CPUs.[3] The future will see machines with 16, 32, and 64 cores. And the types of problems we’re solving in enterprise software development are getting bigger and bigger. As the demand for processing power increases, we have to figure out a way to take advantage of these multicore processors—otherwise, our programs will become slower and slower.
2 Herb Sutter, “The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software,” December 2004, CPU trends graph updated August 2009, www.gotw.ca/publications/concurrency-ddj.htm.
3 Multicore CPU trend (graphic), www.gotw.ca/images/CPU.png.
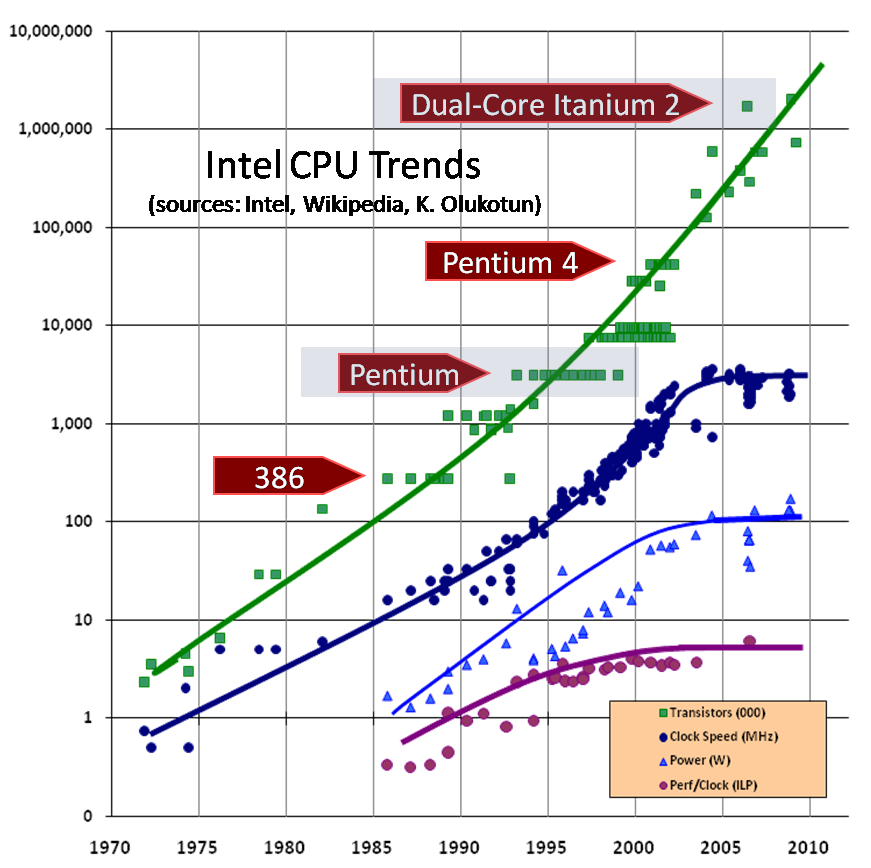{kind=link}
But it’s hard to write a correct and bug-free concurrent program. Here are some reasons why:
- Only a handful of programmers know how to write a correct, concurrent application or program. The correctness of the program is important.
- Debugging multithreaded programs is difficult. The same program that causes deadlock in production might not have any locking issues when debugging locally. Sometimes threading issues show up after years of running in production.
- Threading encourages shared state concurrency, and it’s hard to make programs run in parallel because of locks, semaphores, and dependencies between threads.
Even though multithreading comes up as the main reason why writing concurrent programs is difficult, the main culprit is mutable state. Threading encourages shared-state concurrency. The next section explores the difficulties of shared-state concurrency.
9.2.1. Difficulties of shared-state concurrency with threads
The issue with using threads is it’s a low level of abstraction for concurrency. Threads are too close to hardware and represent the way work is scheduled or executed by the CPU. You need something that can encapsulate threads and give you something that’s easier to program with. Take the example of Scala collections: the Traversable trait defines an abstract method called def foreach[U](f: Elem => U), which other collection library classes and traits implement. Imagine you have to use only foreach to do any sort of manipulation on the collection without using other useful methods like map, fold, filters, and so on. Well, in that case programming in Scala will become a little more difficult. This is exactly what I think about threads: they’re too low-level for programmers. For example, in Java, before the introduction of the java.util.concurrent package, we had only java.lang.Thread and a handful of other classes to implement concurrent applications. After the introduction of the java.util.concurrent package, things improved. The new java.util.concurrent package provides a number of nice utilities and implements popular concurrent design patterns, but it’s still hard to avoid the fact that the main complexity behind using threads comes from using mutable shared data. It’s a design issue that we programmers have to deal with when working with threads. To protect against data corruption and have consistency across many threads, we use locks. Using locks, we control the way the shared data is modified and accessed, but locks introduce problems to the program (see table 9.1).
Table 9.1. Challenges with shared state concurrency
|
Problem |
Description |
|---|---|
| Locks don’t compose | You can’t implement a higher-level, thread-safe behavior by composing smaller thread-safe operations. |
| Using too many or too few locks | You don’t know until you hit a problem. The problem might not show until in production (sometimes after years).[a] Acquiring and releasing locks are expensive operations. |
| Deadlocks and race conditions | This goes to the nondeterministic nature of the threads. It’s almost impossible to make any deterministic reasoning of multithreaded code. You can use design patterns, such as always acquiring locks in a certain order, to avoid deadlocks, but this mechanism adds more responsibility to the developer. |
| Error recovery is hard | This is more of a threading issue than the shared-state issue, but it’s a huge issue nonetheless. There’s no clear mechanism to recover from errors in multithreaded programs. Usually a feedback loop is looking at the stack trace inside a log file. |
a Edward A. Lee, “The Problem with Threads,” Jan. 10, 2006, http://mng.bz/Y4Co.
Last but not least, shared mutable data makes it hard to run programs in parallel, as discussed in section 9.1. The bigger question is: if threads are so hard to use, why are so many programs written using them? Almost all multithreaded programs have bugs, but this hasn’t been a huge problem until recently. As multicore architectures become more popular, these bugs will be more apparent.
Threading should be left to only a few experts; the rest of us need to find a much higher level of abstraction that will hide the complexity of the multithreading and provide an easy-to-use API. Although there will be situations where threading may be your only option, for 99 percent of the cases you should be falling back to other alternatives. This change will come with a price, and the price is that we all have to start learning a new way to write and design concurrent applications. This chapter explores one of these new techniques.
9.2.2. New trends in concurrency
Enough talking about problems with threads and locks—let’s turn our attention to the solutions. Table 9.2 lists the three most popular trends in implementing concurrent applications.
Table 9.2. Three most popular trends in concurrency
|
Description |
|
|---|---|
| Software transactional memory (STM) | STM is a concurrency control mechanism similar to database transactions. Instead of working with tables and rows, STM controls the access to shared memory. An STM transaction executes a piece of code that reads and writes a shared memory. This is typically implemented in a lock-free way and is composable. I talk about STM in chapter 12 in more detail. |
| Dataflow concurrency | The principle behind the dataflow concurrency is to share variables across multiple tasks or threads. These variables can only be assigned a value once in its lifetime. But the values from these variables can be read multiple times, even when the value isn’t assigned to the variable. This gives you programs that are more deterministic, with no race conditions and deterministic deadlocks. Chapter 12 covers dataflow concurrency constructs available in the Akka framework. |
| Message-passing concurrency | This is where you’ll spend most of your time in this chapter. In this concurrency model, components communicate by sending messages. Messages can be sent both synchronously and asynchronously, but asynchronously sending messages to other components is more common. These messages are immutable and are separated from the state of individual components. You don’t have to worry about shared state—in fact, message-passing concurrency encourages shared nothing (SN) architecture. The most successful implementation of message passing concurrency is the actor model, and it became popular after the Erlang programming language demonstrated the success of using the actor model as a concurrency model for building large-scale, distributed, parallel telecom applications. The Scala actor library is another implementation of the message passing concurrency model. |
The remainder of this chapter focuses on message-passing concurrency using Scala actors. Let’s jump right in.
9.3. Implementing message-passing concurrency with actors
In this concurrency model, actors communicate with each other through sending and receiving messages. An actor processes incoming messages and executes the actions associated with it. Typically, these messages are immutable because you shouldn’t share state between them for reasons discussed previously.
There are two main communication abstractions in actor: send and receive. To send a message to an actor, you can use the following expression:
a ! msg
You’re sending the msg message to actor a by invoking the ! method. When you send a message to an actor, it’s an asynchronous operation, and the call immediately returns. The messages are stored in a queue and are processed in first-in, first-out fashion. Think of this queue as a mailbox where messages get stored for an actor. Each actor gets its own mailbox. The receive operation is defined as a set of patterns matching messages to actions:
receive {
case pattern1 =>
...
case pattern =>
}
What differentiates an actor from any other object is the ability to perform actions in response to an incoming message.
The default actor library that ships with Scala, starting with Scala 2.10, is Akka (http://akka.io/) actors. There are many actor libraries but Akka is the most popular and powerful.
Note
Beginning with the Scala 2.10.1 release, the Scala actor library is deprecated and may be removed in a future release. To help with the migration Scala provides an Actor Migration Kit (AMK) and migration guide[4] so old Scala actor code can be easily migrated to the Akka actor library.
4 See “The Scala Actors Migration Guide,” http://docs.scala-lang.org/overviews/core/actors-migration-guide.html.
To create an actor, extend the Actor trait provided by the Akka library and implement the receive method. The following example creates a simple actor that prints a greeting message to the console when it receives a Name message:
import akka.actor.Actor
case class Name(name: String)
class GreetingsActor extends Actor {
def receive = {
case Name(n) => println("Hello " + n)
}
}
The GreetingsActor can only process messages of type Name, and I will cover what will happen when you send messages that don’t match any pattern in a moment. Please note that you don’t necessarily have to create messages from case classes—you can send strings, lists, or whatever you can match using Scala’s pattern matching. For example, to match string type messages, you could do something like the following:
case name: String => println("Hello " + name)
Before sending any messages to the GreetingsActor actor, the actor needs to be instantiated by creating an ActorSystem. Think of an ActorSystem as the manager of one or more actors. (ActorSystem is covered in the next section.) The actor system provides a method called actorOf that takes the configuration object (akka.actor.Props) and, optionally, the name of the actor:

The actor system will create the infrastructure required for the actor to run. When you are done, system.shutdown() shuts down the infrastructure and all its actors. Messages are processed asynchronously so system.shutdown() might stop actors that still have unprocessed messages. Before running the previous snippet, make sure you add the following dependency in your build file:
libraryDependencies += "com.typesafe.akka" %% "akka-actor" % "2.1.0"
The following listing shows the complete code for GreetingsActor.
Listing 9.1. GreetingsActor

If everything works as planned you should see the “Hello Nilanjan” message in the console. Congratulations! You have written your first Scala actors. Now let’s step back to understand why we need an actor system.
9.3.1. What is ActorSystem?
An actor system is a hierarchical group of actors that share a common configuration. It’s also the entry point for creating and looking up actors. Typically a design of an actor-based application resembles the way an organization works in the real world. In an organization the work is divided among departments. Each department may further divide the work until it becomes a size manageable by an employee. Similarly actors form a hierarchy where parent actors spawn child actors to delegate work until it is small enough to be handled by an individual actor.
Note
An ActorSystem is a heavyweight structure that will allocate 1. . .N threads, so create one per logical subsystem of your application. For example, you can have one actor system to handle the backend database, another to handle all the web service calls, and so forth. Actors are very cheap. A given actor consumes only 300 bytes so you can easily create millions of them.
At the top of the hierarchy is the guardian actor, created automatically with each actor system. All other actors created by the given actor system become the child of the guardian actor. In the actor system, each actor has one supervisor (the parent actor) that automatically takes care of the fault handling. So if an actor crashes, its parent will automatically restart that actor (more about this later).
The simplest way to create an actor is to create an ActorSystem and use its actorOf method:
val system = ActorSystem(name = "word-count")
val m: ActorRef = system.actorOf(Props[SomeActor],
name = "someActor")
The preceding snippet creates an ActorSystem named "word-count", and the actorOf method is used to create an actor instance for the SomeActor class. Props is an ActorRef configuration object that’s thread-safe and shareable. Props has a lot of utility methods to create actors.
Note here that when you create an actor in Akka, you never get the direct reference to the actor. Instead you get back a handle to the actor called ActorRef (actor reference). The foremost purpose of ActorRef is to send messages to the actor it represents. It also acts as a protection layer so you can’t access the actor directly and mutate its state. ActorRef is also serializable, so if an actor crashes, as a fault-handling mechanism, you can possibly serialize the ActorRef, send it to another node, and start the actor there. Clients of the actor will not notice. There are different types of actor references. In this chapter we will look into local actor reference (meaning all the actors are running locally in a single JVM); chapter 12 will look into remote actor references (actors running on another remote JVM).
Figure 9.3. Actor system with hierarchy of actors

The second part of the actor system is actor path. An actor path uniquely identifies an actor in the actor system. Because actors are created in a hierarchical structure, they form a similar structure to a filesystem. As a path in a filesystem points to an individual resource, an actor path identifies an actor reference in an actor system. Note that these actors don’t have to be in a single machine—they can be distributed to multiple nodes. Using the methods defined in ActorSystem, you can look up an actor reference of an existing actor in the actor system. The following example uses the system / method to retrieve the actor reference of the WordCountWorker actor:
class WordCountWorker extends Actor { ... }
...
val system = ActorSystem(name = "word-count")
system.actorOf(Props[WordCountWorker], name = "wordCountWorker")
...
val path: ActorPath = system / "WordCountWorker"
val actorRef: ActorRef = system.actorFor(path)
actorRef ! "some message"
The system / method returns the actor path, and the actorFor method returns the actor reference mapped to the given path. If the actorFor fails to find an actor pointed to by the path, it returns a reference to the dead-letter mailbox of the actor system. It’s a synthetic actor where all the undelivered messages are delivered.
You can also create the actor path from scratch and look up actors. See the Akka documentation for more details on the actor path.[5]
5 See “Actor References, Paths, and Addresses,” version 2.1.0, http://doc.akka.io/docs/akka/2.1.0/general/addressing.html.
To shut down all the actors in the actor system, invoke the shutdown method, which gracefully stops all the actors in the system. The parent actor first stops all the child actors and sends all unprocessed messages to the dead-letter mailbox before terminating itself. The last important part of the actor system is message dispatcher. The MessageDispatcher is the engine that makes all the actors work. The next section explains how actors work.
9.3.2. How do Scala actors work?
Every actor system comes with a default MessageDispatcher component. Its responsibility is to send a message to the actor’s mailbox and execute the actor by invoking the receive block. Every MessageDispatcher is backed by a thread pool, which is easily configured using the configuration file (more about this in chapter 12). You can also configure various types of dispatchers for your actor system or specific actors. For this chapter we are going to use the default dispatcher (a.k.a event-based dispatcher). Figure 9.4 shows how sending and receiving messages works inside actors.
Figure 9.4. Showing step by step how a new actor is started and how an already running actor bides its time

Sending a message to an actor is quite simple. To send a message to an actor mailbox the ActorRef first sends the message to the MessageDispatcher associated with the actor (which in most cases is the MessageDispatcher configured for the actor system). The MessageDispatcher immediately queues the message in the mailbox of the actor. The control is immediately returned to the sender of the message. This is exactly how it worked when we sent a message to our greetings actor.
Handling a message is a bit more involved so let’s follow the steps in figure 9.4:
1. When an actor receives a message in its mailbox, MessageDispatcher schedules the actor for execution. Sending and handling messages happens in two different threads. If a free thread is available in the thread pool that thread is selected for execution of the actor. If all the threads are busy, the actor will be executed when threads becomes available.
2. The available thread reads the messages from the mailbox.
3. The receive method of the actor is invoked by passing one message at a time.
The message dispatcher always makes sure that a single thread always executes a given actor. It might not be the same thread all the time but it is always going to be one. This is a huge guarantee to have in the concurrent world because now you can safely use mutable state inside an actor as long as it’s not shared. Now I think we are ready to build an application using actors.
9.3.3. Divide and conquer using actors
In the following example, the challenge is to count the number of words in each file in a given directory and sort them in ascending order. One way of doing it would be to loop through all the files in a given directory in a single thread, count the words in each file, and sort them all together. But that’s sequential. To make it concurrent, we will implement the divide-and-conquer[6] (also called a fork-join) pattern with actors. We will have a set of worker actors handling individual files and a master actor sorting and accumulating the result.
6 Brian Goetz, “Java theory and practice: Stick a fork in it, Part 1,” developerWorks, Nov. 13, 2007, http://mng.bz/aNZn.
The akka.actor.Actor trait defines only one abstract method receive to implement the behavior of the actor. Additionally the Actor trait defines methods that are useful for lifecycle hooks and fault handling. Here is the list of some of the important methods. (Please check the scaladoc for a complete list of methods.)
def unhandled(message: Any): Unit
If a given message doesn’t match any pattern inside the receive method then the unhandled method is called with the akka.actor.UnhandledMessage message. The default behavior of this method is to publish the message to an actor system’s event stream. You can configure the event stream to log these unhandled messages in the log file.
val self: ActorRef
This field holds the actor reference of this actor. You can use self to send a message to itself.
final def sender: ActorRef
This is the ActorRef of the actor that sent the last received message. It is very useful when you want to reply to the sender of the message.
val context: ActorContext
This provides the contextual information for the actor, the current message, and the factory methods to create child actors. The context also provides access to the actor system and lifecycle hooks to monitor other actors.
def supervisorStrategy: SupervisorStrategy
This supervisor strategy defines what will happen when a failure is detected in an actor. You can override to define your own supervisor strategy. We will cover this topic later in this chapter.
def preStart()
This method is called when an actor is started for the first time. This method will be called before any message is handled. This method could be used to initialize any resources the actor needs to function properly.
def preRestart()
Actors might be restarted in case of an exception thrown while handling a message. This method is called on the current instance of the actor. This is a great place to clean up. The default implementation is to stop all the child actors and then invoke the postStop method.
def postStop()
This method is called after the current actor instance is stopped.
def postRestart()
When an actor is restarted, the old instance of an actor is discarded and a fresh new instance of an actor is created using the actorOf method. Then the postRestart is invoked on the fresh instance. The default implementation is to invoke the preStart method.
To solve the word count problem with actors, you’ll create two actor classes: one that will scan the directory for all the files and accumulate results, called WordCountMaster, and another one called WordCountWorker to count words in each file. It’s always a good idea to start thinking about the messages that these actors will use to communicate with each other. First you need a message that will initiate the counting by passing in the directory location and the number of worker actors:
case class StartCounting(docRoot: String, numActors: Int)
The docRoot will specify the location of the files and numActors will create the number of worker actors. The main program will start the counting process by passing this message to the main actor. WordCountMaster and WordCountWorker will communicate with each other via messages. The WordCountMaster needs a message that will send the filename to the worker actor to count, and in return WordCountWorker needs a message that will send the word count information with the filename back to the master actor. Here are those messages:
case class FileToCount(fileName:String) case class WordCount(fileName:String, count: Int)
To understand how these messages are consumed, look at figure 9.5. The figure shows only one worker actor, but the number of worker actors will depend upon the number you send through the StartCounting message.
Figure 9.5. WordCountMaster and WordCountWorker actors are communicating by sending messages. The main program in the figure starts the word count process.

Let’s start with the WordCountWorker actor because it’s the easiest one. This actor processes only FileToCount type messages, and the action associated with the message is to open the file and count all the words in it. Counting words in a file is exactly the same as the threading example you saw previously:
def countWords(fileName:String) = {
val dataFile = new File(fileName)
Source.fromFile(dataFile).getLines.foldRight(0)(_.split(" ").size + _)
}
You’re using scala.io.Source to open the file and count all the words in it—pretty straightforward. Now comes the most interesting part: the receive method. You already know the message you need to handle, but one new thing you have to worry about is sending the reply to the WordCountMaster actor when you’re done counting words for a given file.
The good news is, the Akka actor runtime sends the actor reference of sender implicitly with every message:
def receive {
case FileToCount(fileName:String) =>
val count = countWords(fileName)
sender ! WordCount (fileName, count)
}
In reply you’re sending the WordCount message back to the WordCountMaster actor.
Usually it’s recommended that you don’t perform any blocking operation from actors. When you make a blocking call from an actor you are also blocking a thread. As mentioned earlier, a thread is a limited resource. So if you end up with many of these blocking actors you will soon run out of threads and halt the actor system.
At times you will not have any option other than blocking. In that case the recommended approach is to separate blocking actors from nonblocking actors by assigning different message dispatchers. This provides the flexibility to configure the blocking dispatcher with additional threads, throughput, and so on. An added benefit of this approach is if a part of the system is overloaded with messages (all the threads are busy in a message dispatcher) other parts can still function.
Here’s the complete WordCountWorker class:
class WordCountWorker extends Actor {
def countWords(fileName:String) = {
val dataFile = new File(fileName)
Source.fromFile(dataFile).getLines.foldRight(0)(_.split(" ").size + _)
}
def receive = {
case FileToCount(fileName:String) =>
val count = countWords(fileName)
sender ! WordCount(fileName, count)
}
override def postStop(): Unit = {
println(s"Worker actor is stopped: ${self}")
}
}
In this case the postStop method is overridden to print a message in the console when the actor is stopped. This is not necessary. We will instead use this as a debug message to ensure that the actor is stopped correctly. Currently the WordCountWorker actor responds only to the FileToCount message. When it receives the message, it will count words inside the file and reply to the master actor to sort the response. Any other message will be discarded and handled by the unhandled method as described in the following side note.
If you are familiar with old Scala actors, ActorDSL will look quite similar to Scala actors. This is a new addition to the Akka actor library to help create one-off workers or even try in the REPL. To bring in all the DSL goodies into the scope import:
import akka.actor.ActorDSL._
To create a simple actor use the actor method defined in ActorDSL by passing an instance of the Act trait:
val testActor = actor(new Act {
become {
case "ping" => sender ! "pong"
}
})
The become method adds the message patterns the actor needs to handle. Behind the scene Act extends the Actor trait and become adds the behavior of the receive block. Using this DSL syntax you no longer have to create a class. Here is an example of two actors communicating with each other by sending ping-pong messages:
object ActorDSLExample extends App {
import akka.actor.ActorDSL._
import akka.actor.ActorSystem
implicit val system = ActorSystem("actor-dsl")
val testActor = actor(new Act {
become {
case "ping" => sender ! "pong"
}
})
actor(new Act {
whenStarting { testActor ! "ping"}
become {
case x =>
println(x)
context.system.shutdown()
}
})
}
The actor system is assigned to an implicit value so we don’t have to pass it explicitly to the actor method. The whenStarting is the DSL for a lifecycle hook of the prestart method of the actor.
The WordCountMaster actor will start counting when it receives a StartCounting message. This message will contain the directory name that needs to be processed and the number of worker actors that could be used for the job. To scan the directory, use the list method defined in the java.io.File class that lists all the files in the directory:
private def scanFiles(docRoot: String) =
new File(docRoot).list.map(docRoot + _)
The map method is used to create a list of all the filenames with a complete file path. At this point, don’t worry about subdirectories. To create work actors, we use the numActors value passed to the StartCounting message and create that many actors:
private def createWorkers(numActors: Int) = {
for (i <- 0 until numActors) yield
context.actorOf(Props[WordCountWorker], name = s"worker-${i}")
}
Since the worker actors will be the children of the WordCountMaster, the actor context.actorOf factory method is used.
To begin sorting, we need a method that will loop through all the filenames and send a FileToCount message to these worker actors. Because the number of files to process could be higher than the number of actors available, files are sent to each actor in a round-robin fashion:
private[this] def beginSorting(fileNames: Seq[String],
workers: Seq[ActorRef]) {
fileNames.zipWithIndex.foreach( e => {
workers(e._2 % workers.size) ! FileToCount(e._1)
})
}
The zipWithIndex method pairs each element with its index. Here’s one example:
scala> List("a", "b", "c").zipWithIndex
res2: List[(java.lang.String, Int)] = List((a,0), (b,1), (c,2))
When the WordCountMaster actor receives the StartCounting message it will create the worker actors and scan the files, then send these files to each worker. Here is how the WordCountMaster looks so far:
class WordCountMaster extends Actor {
var fileNames: Seq[String] = Nil
var sortedCount : Seq[(String, Int)] = Nil
def receive = {
case StartCounting(docRoot, numActors) =>
val workers = createWorkers(numActors)
fileNames = scanFiles(docRoot)
beginSorting(fileNames, workers)
}
private def createWorkers(numActors: Int) = {
for (i <- 0 until numActors) yield
context.actorOf(Props[WordCountWorker], name = s"worker-${i}")
}
private def scanFiles(docRoot: String) =
new File(docRoot).list.map(docRoot + _)
private[this] def beginSorting(fileNames: Seq[String],
workers: Seq[ActorRef]) {
fileNames.zipWithIndex.foreach( e => {
workers(e._2 % workers.size) ! FileToCount(e._1)
})
}
}
The fileNames field stores all the files we need to process. We will use this field later on to ensure we have received all the replies. The sortedCount field is used to store the result. An important point to note here is that it is safe to use mutable state inside an actor because the actor system will ensure that no two threads will execute an instance of an actor at the same time. You must make sure you don’t leak the state outside the actor.
Next the WordCountMaster actor needs to handle the WordCount message sent from the WordCountWorker actor. This message will have the filename and the word count. This information is stored in sortedCount and sorted:
case WordCount(fileName, count) =>
sortedCount ::= (fileName, count)
sortedCount = sortedCount.sortWith(_._2 < _._2)
The last step is to determine when all the files are processed. One way to do that is to compare the size of sortedCount with the number of files to determine whether all the responses from the worker actors are received. When that happens we need to print the result in the console and terminate all the actors:
if(sortedCount.size == fileNames.size) {
println("final result " + sortedCount)
finishSorting()
}
We could use context.children to access all the worker actors and stop them like the following:
context.children.foreach(context.stop(_))
The simplest way to shut down an actor system is to use the shutdown method of the actor system. We can access the actor system from context using context.system like the following:
private[this] def finishSorting() {
context.system.shutdown()
}
The following listing shows the complete implementation of WordCountWorker and WordCountMaster actors.
Listing 9.2. WordCount implementation using actors
import akka.actor.Actor
import akka.actor.Props
import akka.actor.ActorRef
import java.io._
import scala.io._
case class FileToCount(fileName:String)
case class WordCount(fileName:String, count: Int)
case class StartCounting(docRoot: String, numActors: Int)
class WordCountWorker extends Actor {
def countWords(fileName:String) = {
val dataFile = new File(fileName)
Source.fromFile(dataFile).getLines.foldRight(0)(_.split(" ").size + _)
}
def receive = {
case FileToCount(fileName:String) =>
val count = countWords(fileName)
sender ! WordCount(fileName, count)
}
override def postStop(): Unit = {
println(s"Worker actor is stopped: ${self}")
}
}
class WordCountMaster extends Actor {
var fileNames: Seq[String] = Nil
var sortedCount : Seq[(String, Int)] = Nil
def receive = {
case StartCounting(docRoot, numActors) =>
val workers = createWorkers(numActors)
fileNames = scanFiles(docRoot)
beginSorting(fileNames, workers)
case WordCount(fileName, count) =>
sortedCount = sortedCount :+ (fileName, count)
sortedCount = sortedCount.sortWith(_._2 < _._2)
if(sortedCount.size == fileNames.size) {
println("final result " + sortedCount)
finishSorting()
}
}
override def postStop(): Unit = {
println(s"Master actor is stopped: ${self}")
}
private def createWorkers(numActors: Int) = {
for (i <- 0 until numActors) yield context.actorOf(Props[WordCount-
Worker], name = s"worker-${i}")
}
private def scanFiles(docRoot: String) =
new File(docRoot).list.map(docRoot + _)
private[this] def beginSorting(fileNames: Seq[String], workers: Seq[Actor-
Ref]) {
fileNames.zipWithIndex.foreach( e => {
workers(e._2 % workers.size) ! FileToCount(e._1)
})
}
private[this] def finishSorting() {
context.system.shutdown()
}
}
WordCountWorker and WordCountMaster are both defined as actors. The communication between them is happening through immutable messages. When the WordCountMaster actor receives the StartCounting message, it creates worker actors based on the number passed in by the message. Once the actors are started, the WordCountMaster actor sends FileToCount messages to all the worker actors in round-robin fashion. When the worker actor is done counting the words inside the file, it sends the WordCount message back to the master actor. If the size of the sortedCount matches the number of files, it kills all the worker actors including the master actor.
The final piece missing from the preceding code is the main actor you saw in figure 9.4. For that, you’re not going to create a new actor but instead create an object with the Main method.
Listing 9.3. Main program to start counting process
import akka.actor.ActorSystem
import akka.actor.Props
object Main {
def main(args: Array[String]) {
val system = ActorSystem("word-count-system")
val m = system.actorOf(Props[WordCountMaster], name="master")
m ! StartCounting("src/main/resources/", 2)
}
}
You’ve learned lots of interesting things about actors in this section. And you learned how to design your applications using actors. Creating self-contained immutable messages and determining the communication between actors are important steps when working with actors. It’s also important to understand that when working with actors, all the communication happens through messages, and only through messages. This brings up a similarity between actors and OOP. When Alan Kay[7] first thought about OOP, his big idea was “message passing.”[8] In fact, working with actors is more object-oriented than you think.
7 Alan Curtis Kay, http://en.wikipedia.org/wiki/Alan_Kay.
8 Alan Kay, “Prototypes vs. classes was: Re: Sun’s HotSpot,” Oct 10, 1998, http://mng.bz/L12u.
What happens if something fails? So many things can go wrong in the concurrent/ parallel programming world. What if we get an IOException while reading the file? Let’s learn how to handle faults in an actor-based application.
9.3.4. Fault tolerance made easy with a supervisor
Akka encourages nondefensive programming in which failure is a valid state in the lifecycle of an application. As a programmer you know you can’t prevent every error, so it’s better to prepare your application for the errors. You can easily do this through fault-tolerance support provided by Akka through the supervisor hierarchy.
Think of this supervisor as an actor that links to supervised actors and restarts them when one dies. The responsibility of a supervisor is to start, stop, and monitor child actors. It’s the same mechanism as linking, but Akka provides better abstractions, called supervision strategies.
Figure 9.6 shows an example of supervisor hierarchy.
Figure 9.6. Supervisor hierarchy in Akka

You aren’t limited to one supervisor. You can have one supervisor linked to another supervisor. That way you can supervise a supervisor in case of a crash. It’s hard to build a fault-tolerant system with one box, so I recommend having your supervisor hierarchy spread across multiple machines. That way, if a node (machine) is down, you can restart an actor in a different box. Always remember to delegate the work so that if a crash occurs, another supervisor can recover. Now let’s look into the fault-tolerant strategies available in Akka.
Supervision Strategies in Akka
Akka comes with two restarting strategies: One-for-One and All-for-One. In the One-for-One strategy (see figure 9.7), if one actor dies, it’s recreated. This is a great strategy if actors are independent in the system. It doesn’t require other actors to function properly.
Figure 9.7. One-for-One restart strategy

If you have multiple actors that participate in one workflow, restarting a single actor might not work. In that case, use the All-for-One restart strategy (see figure 9.8), in which all actors supervised by a supervisor are restarted when one of the actors dies.
Figure 9.8. All-for-One strategy

So how do these look in code? In Akka, by default, each actor has one supervisor, and the parent actor becomes the supervisor for the child actors. When no supervisor strategy is defined, it uses the default strategy (OneForOne), which restarts the failing child actor in case of Exception. The following example configures the WordCountWorker with OneForOneStrategy with retries:
import akka.actor.SupervisorStrategy._
class WordCountWorker extends Actor {
. . .
override val supervisorStrategy = OneForOneStrategy(maxNrOfRetries = 3,
withinTimeRange = 5 seconds) {
case _: Exception => Restart
}
. . .
}
You’re overriding the supervisorStrategy property of the actor with your own fault handler. For example, in the case of java.lang.Exception your pattern will match and give a restart directive to the parent to discard the old instance of the actor and replace it with a new instance. If no pattern matches, the fault is escalated to the parent. Similarly, the following example configures the WordCountMaster actor with AllForOneStrategy:
class WordCountMaster extends Actor {
. . .
override val supervisorStrategy = AllForOneStrategy() {
case _: Exception =>
println("Restarting...")
Restart
}
. . .
}
A working example of a supervisor with the word-count example is in this chapter’s code base. The next section talks about working with mutable data in a concurrent world.
9.4. Composing concurrent programs with Future and Promise
A Future is an object that can hold a value that may become available, as its name suggests, at a later time. It essentially acts as proxy to an actual value that does not yet exist. Usually this value is produced by some computation performed asynchronously. The simplest way to create a Future is to use the apply method:
def someFuture[T]: Future[T] = Future {
someComputation()
}
In this case someFuture will hold the result of the computation and T represents the type of the result. Since the Future is executed asynchronously we need to specify the scala.concurrent.ExecutionContext. ExecutionContext is an abstraction over a thread pool that is responsible for executing all the tasks submitted to it. Here the task is the computation performed by the Future. There are many ways to configure and create ExecutionContext but in this chapter we will use the default global execution context available in the Scala library.
import ExecutionContext.Implicits.global
When the Future has the value it is considered completed. A Future could also be completed with an exception. To do an operation after the Future is completed we can use the onComplete callback method as in following:
someFuture.onComplete {
case Success(result) => println(result)
case Failure(t) => t.printStackTrace
}
Since a Future could be a success or failed state, the onComplete allows you to handle both conditions. (Check the scala.concurrent.Future scaladoc for more details.)
Futures can also be created using Promise. Consider Promise as a writable, single assignment container. You can use Promise to create a Future, which will be completed when Promise is fulfilled with a value:
val promise: Promise[String] = Promise[String]()
val future = promise.future
...
val anotherFuture = Future {
...
promise.success("Done")
doSomethingElse()
}
...
future.onSuccess { case msg => startTheNextStep() }
Here we have created two Futures, one using the future method and the other from Promise. anotherFuture completes the promise by invoking the success method (you can also complete promise with the failure method). Once the promise is completed you cannot invoke success again. If you do, it will throw an exception. And promise will automatically complete the future and the onSuccess callback will be invoked automatically. Please note that callbacks registered with Future will only be executed once the future is completed. The Scala Future and Promise APIs have many useful methods so please check the scaladoc for details.
By now you might be wondering when to use Future and when to use actors. A common use case of Future is to perform some computation concurrently without needing the extra utility of an actor. The most compelling feature of the Scala Future library is it allows us to compose concurrent operations, which is hard to achieve with actors. To see them in action let’s implement the word count problem using Future and Promise.
9.4.1. Divide and conquer with Future
You are going to reimplement the word count problem using Future. First let’s break down the word count problem into small steps so that we can solve them individually. Since Future allows functional composition we should be able to combine small steps to solve our problem. We can find a solution in four steps:
- Scan for all the files in a given directory
- Count words in a given file
- Accumulate and sort the result
- Produce the result
We already know how to scan the files in a given directory but this time we will perform it asynchronously:
private def scanFiles(docRoot: String): Future[Seq[String]] = Future {
new File(docRoot).list.map(docRoot + _)
}
Similarly we can count words for a given file inside a Future. If something goes wrong we can use the recover method to register a fallback:
private def processFile(fileName: String): Future[(String, Int)] =
Future {
val dataFile = new File(fileName)
val wordCount =
Source
.fromFile(dataFile).getLines.foldRight(0)(_.split(" ").size + _)
(fileName, wordCount)
} recover {
case e: java.io.IOException =>
println("Something went wrong " + e)
(fileName, 0)
}
The recover callback will be invoked if IOException is thrown inside the Future. Since each file is processed inside a Future we will end up with a collection of futures like the following:
val futures: Seq[Future[(String, Int)]] = fileNames.map(name => processFile(name))
Now this is a problem. How will we know when all the futures will complete? We cannot possibly register callbacks with each future since each one is independent and can complete at a different time. Rather than Seq[Future[(String, Int)]], we need Future[Seq[(String, Int)]] so we can accumulate the results and sort them. This is exactly what Future.sequence is designed for. It takes collections of futures and reduces them to one Future:
val singleFuture: Future[Seq[(String, Int)]] = Future.sequence(futures)
You can invoke the map method on future to sort the result:
private def processFiles(
fileNames: Seq[String]): Future[Seq[(String, Int)]] = {
val futures: Seq[Future[(String, Int)]] =
fileNames.map(name => processFile(name))
val singleFuture: Future[Seq[(String, Int)]] = Future.sequence(futures)
singleFuture.map(r => r.sortWith(_._2 < _._2))
}
If you haven’t guessed, Future is an example of a monad. It implements map, flatMap, and filter operations, necessary ingredients of functional composition. Now you can compose scanFiles and processFiles to produce the sorted result:
val path = "src/main/resources/"
val futureWithResult: Future[Seq[(String, Int)]] = for {
files <- scanFiles(path)
result <- processFiles(files)
} yield {
result
}
The for-comprehensions here are composing scanFiles and processFiles operations together to produce another future. Note here that each operation is performed asynchronously and we are composing futures in a nonblocking fashion. The for-comprehensions are creating another future that only completes when both the scanFiles and processFiles future complete. It is also acting as the pipe between two operations where the output of the scanFiles is sent to processFiles.
For the last step we can use a Promise that will be fulfilled when futureWithResult completes. Here is the complete implementation of the word count example using Future:
Listing 9.4. Word count example using Future


As you can see it’s very easy to get started with Future and it is very powerful because it allows you to do functional composition. On the other hand, actors allow you to structure your application and provide fault-handling strategies. You don’t have to choose between them. You can have your application broken down into actors and then have actors use futures as building blocks to perform asynchronous operations. In the next section we will see how we can use futures inside actors.
9.4.2. Mixing Future with actors
As you work your way through Akka actors two common patterns will evolve:
- Send a message to an actor and receive a response from it. So far we have only used fire-and-forget using the ! method. But getting a response is also a very common use case (a.k.a ask pattern).
- Reply to sender when some concurrent task (Future) completes (a.k.a pipe pattern).
Let’s take an example to demonstrate these two patterns in action. In the following code snippet we have two actors, parent and the child:
import akka.pattern.{ask, pipe}
implicit val timeout = Timeout(5 seconds)
class GreetingsActor extends Actor {
val messageActor = context.actorOf(Props[GreetingsChildActor])
def receive = {
case name =>
val f: Future[String] = (messageActor ask name).mapTo[String]
f pipeTo sender
}
}
class GreetingsChildActor extends Actor {
def receive = { ...
}
}
GreetingsActor accepts name and sends the message to a child actor to generate a greeting message. In this case we are using the ask method (you can use ? as well) of the ActorRef to send and receive a response. Since messages are processed asynchronously the ask method returns a Future. The mapTo message allows us to transform the message from Future[Any] to Future[String]. The challenge is we don’t know when the message will be ready so that we can send the reply to the sender. The pipeTo pattern solves that problem by hooking up with the Future so that when the future completes it can take the response inside the future and send it to the sender. To see the complete working example please look at the chapter codebase.
9.5. When should you not use actors?
This chapter has highlighted the benefits of actors in building message-oriented concurrent applications. It’s also discussed why shared mutable data is the root cause of most of the concurrency problems, and how actors eliminate that using shared nothing architecture. But what if you have to have a shared state across multiple components?
- Shared state— A classic example is where you want to transfer money from one account to another, and you want to have a consistent view across the application. You need more than actors. You need transaction support. Alternatives like STM would be a great fit for this kind of problem, or you have to build transactions over message passing. (You’ll see an example of this in chapter 12.)
- Cost of asynchronous programming— For many programmers, it’s a paradigm shift to get used to asynchronous programming. It takes time and effort to get comfortable
if you are not used to it. Debugging and testing large message-oriented applications is hard. At times, asynchronous message
passing makes it difficult to track and isolate a problem (knowing the starting point of the message helps). This has nothing
to do with the actor model specifically, but more to do with the inherited complexity of messaging-based applications. Lately
Akka TestKit[9] and Typesafe console[10] are helping to mitigate the testing and debugging issues.
9 “Testing Actor Systems (Scala), TestKit Example,” http://doc.akka.io/docs/akka/2.1.0/scala/testing.html.
10 “Typesafe Console,” http://typesafe.com/products/console.
- Performance— If your application has to have the highest performance, then because actors may add an overhead, you may be better off using a much lower level of abstraction, like threads. But again, for 99.9 percent of applications, I think the performance of actors is good enough.
9.6. Summary
In this chapter you learned about new concurrency trends and the problems with shared-state concurrency. It became clear that if you raise the level of abstraction higher, you can easily build concurrent applications. This chapter focused on message-passing concurrency and how to use actors to implement it.
We also learned about the Future and Promise APIs and how we can use functional composition to construct larger programs by combining small concurrent operations. One of the big challenges with building fault-tolerant applications is handling errors effectively and recovering from them. You learned how the supervisor strategy works to handle errors in actor-based applications. This makes it easy to build long-running applications that can automatically recover from errors and exceptions.
The next chapter focuses on writing automated tests for Scala applications and explores how Scala helps with writing tests and the various tools available to you for testing. It’s not as hard as you may think. It also shows you how to write tests around actors.