
6 Test Management
This chapter describes ways to organize test teams, which qualifications are important, the tasks of a test manager, and which supporting processes must be present for efficient testing.
6.1 Test Organization
6.1.1 Test Teams
Testing activities are necessary during the entire software product life cycle (see chapter 3). They should be well coordinated with the development activities. The easiest solution is to let the developer perform the testing.
However, because there is a tendency to be blind to our own errors, it is much more efficient to let different people perform testing and development and to organize testing as independently as possible from development.
Benefits of independent testing
Independent testing provides the following benefits:
- Independent testers are unbiased and thus find additional and different defects than developers find.
- An independent tester can verify (implicit) assumptions made by developers during specification and implementation of the system.
Possible drawbacks of independent testing
But there may also be drawbacks to independent testing:
- Too much isolation may impair the necessary communication between testers and developers.
- Independent testing may become a bottleneck if there is a lack of necessary resources.
- Developers may lose a sense of responsibility for quality because they may think, “the testers will find the →problems anyway.”
The following models or options for independence are possible:
1. The development team is responsible for testing, but developers test each other’s programs, i.e., a developer tests the program of a colleague.
2. There are testers within the development team; these testers do all the test work for their team.
3. One or more dedicated testing teams exist within the project team (these teams are not responsible for development tasks). Typically, team members from the business or IT department work as independent testers.
4. Independent test specialists are used for specific testing tasks (such as performance test, usability test, security test, or for showing conformance to standards and regulatory rules).
5. A separate organization (testing department, external testing facility, test laboratory) takes over the testing (or important parts of it, such as the system test).
When to choose which model
For each of these models, it is advantageous to have testing consultants available. These consultants can support several projects and can offer methodical assistance in areas such as training, coaching, test automation, etc. Which of the previously mentioned models is appropriate depends on—among other things—the current test level.
Component Testing
Testing should be close to development. Although often used, it is definitely the worst choice to allow developers to test their own programs. Independent testing such as in model 1 is easy to organize and would certainly improve quality. Testing such as in model 2 is useful, if a sufficient number of testers relative to the number of developers can be made available. However, with both testing models, there is the risk that the participating people essentially consider themselves developers and thus will neglect their testing responsibilities.
To prevent this, the following measures are recommended:
Integration Testing
When the same team that developed the components also performs integration and integration testing, this testing can be organized as for component testing (models 1, 2).
If components originating from several teams are integrated, then either a mixed integration team with representatives from the involved development groups or an independent integration team should be responsible. The individual development team may have their own view about their own component and therefore may overlook faults. Depending on the size of the development project and the number of components, models 3, 4, and 5 should be considered here.
System Testing
The final product shall be considered from the point of view of the customer and the end user. Therefore, independence from the development team is crucial. This leaves only models 3, 4, and 5.
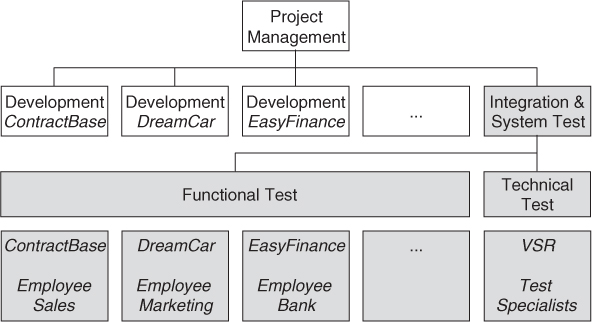
In the VSR project, each development team is responsible for component testing. These teams are organized according to the previously mentioned models 1 and 2. In parallel to these development teams, an independent testing group is established. This testing group is responsible for integration and system testing. Figure 6-1 shows the organization.
Two or three employees from each responsible user department (sales, marketing, etc.) are made available for the functional or business-process-based testing of every subsystem (ContractBase, DreamCar, etc.). These people are familiar with the business processes to be supported by the particular subsystem and know the requirements “their” test object should fulfill from the users’ point of view. They are experienced PC users, but not IT experts. It is their task to support the test specialists in specifying business-related functional test cases and to perform these tests. When the testing activities are started, they have received training in basic testing procedures (test process, specification, execution, and logging).
→Test logging
Additionally, test personnel consists of three to five IT and test specialists, responsible for integration activities, nonfunctional tests, test automation, and support of test tools (“technical test”). A test manager, responsible for test planning and test control, is in charge of the test team. The manager’s tasks also comprise coaching of the test personnel, especially instructing the staff on testing the business requirements.
6.1.2 Tasks and Qualifications
Specialists with knowledge covering the full scope of activities in the test process should be available. The following roles should be assigned, ideally to specifically qualified employees:
Roles and qualification profiles
- Test manager (test leader): Test planning and test control expert(s), possessing knowledge and experience in the fields of software testing, quality management, project management, and personnel management. Typical tasks may include the following:
- Writing and coordinating the test policy for the organization
- Developing the test approach and test plan as described in section 6.2.2
- Representing the testing perspective in the project
- Procuring testing resources
- Selecting and introducing suitable test strategies and methods, introducing or improving testing tools, organizing tools training, deciding about test environment and test automation
- Introducing or optimizing supporting processes (e.g., problem management, configuration management) in order to be able to trace back changes and securing reproducibility of the tests
- Introducing, using, and evaluating metrics defined in the test plan
- Regularly adapting test plans based on test results and test progress
- Identifying suitable metrics for measuring test progress, and evaluating the quality of the testing and the product
- Writing and communicating test reports
- Test designer (test analyst): Expert(s) in test methods and test specification, having knowledge and experience in the fields of software testing, software engineering, and (formal) specification methods. Typical tasks may include the following:
- Reviewing requirements, specifications, and models for testability and in order to design test cases
- Creating test specifications
- Preparing and acquiring test data
- Test automator: Test automation expert(s) with knowledge of testing basics, programming experience, and deep knowledge of the testing tools and script languages. Automates tests as required, making use of the test tools available for the project.
- Test administrator: Expert(s) for installing and operating the test environment (system administrator knowledge). Sets up and supports the test environment (often coordinating with general system administration and network management).
- Tester:1 Expert(s) for executing tests and reporting failures (IT basics, basic knowledge of testing, using the test tools, understanding the test object). Typical tasks are as follows:
- Reviewing test plans and test cases
- Using test tools and test monitoring tools (for example, to measure performance)
- Executing and logging tests, including evaluating and documenting the results and detected deficiencies
Certified Tester
In this context, what does the Certified Tester training offer? The basic Certified Tester training (Foundation Level) qualifies for the “tester” role (without covering the required IT basics). This means that a Certified Tester knows why discipline and structured work are necessary. Under the supervision of a test manager, a Certified Tester can manually execute and document tests. He or she is familiar with basic techniques for test specification and test management. Every software developer should also know these foundations of software testing to be able to adequately execute the testing tasks required by organizational models 1 and 2. Before someone is able to fulfill the role of a test designer or test manager, appropriate experience as a tester should be gathered. The second educational level (Advanced Level) offers training for the tasks of the designer and manager.
Social competence is important
To be successful, in addition to technical and test-specific skills, a tester needs social skills:
- Ability to work in a team, and political and diplomatic aptitude
- Skepticism (willingness to question apparent facts)
- Persistence and poise
- Accuracy and creativity
- Ability to get quickly acquainted with (complex fields of) application
Multidisciplinary team
Especially in system testing, it is often necessary to extend the test team by adding IT specialists, at least temporarily, to perform work for the test team. For example, these might be database administrators, database designers, or network specialists. Professional specialists from the application field of the software system currently being tested or the business are often indispensable. Managing such a multidisciplinary test team can be difficult even for experienced test managers.
Specialized software test service providers
If appropriate resources are not available within the company, test activities can be given to external software testing service providers. This is similar to letting an external software house develop software. Based on their experience and their use of predefined solutions and procedures, these test specialists are able to provide an optimal test for the project. They can also provide missing specialist skills from each of the previously mentioned qualification profiles for the project.
6.2 Planning
Testing should not be the only measure for quality assurance (QA). It should be used in combination with other quality assurance measures. Therefore, an overall plan for quality assurance is needed that should be documented in the quality assurance plan.
6.2.1 Quality Assurance Plan
Guidelines for structuring the quality assurance plan can be found in IEEE standard 730-2002 [IEEE 730-2002]. The following subjects shall be considered (additional sections may be added as required. Some of the material may also appear in other documents).
a. IEEE Standard 730 in its new form from 2013 [IEEE 730-2013] has a new title, Standard for Software Quality Assurance Processes, and does not contain a standard layout for a software quality assurance plan anymore.
During quality assurance planning, the role the tests play as special, analytical measures of quality control is roughly defined. The details are then determined during test planning and documented in the test plan.
6.2.2 Test Plan
A task as extensive as testing requires careful planning. This planning and test preparation starts as early as possible in the software project. The test policy of the organization and the objectives, risks, and constraints of the project as well as the criticality of the product influence the test plan.
Test planning activities
The test manager might participate in the following planning activities:
- Defining the overall approach to and strategy for testing (see section 6.4)
- Deciding about the test environment and test automation
- Defining the test levels and their interaction, and integrating the testing activities with other project activities
- Deciding how to evaluate the test results
- Selecting metrics for monitoring and controlling test work, as well as defining test exit criteria
- Determining how much test documentation shall be prepared and determining templates
- Writing the test plan and deciding on what, who, when, and how much testing
- Estimating test effort and test costs; (re)estimating and (re)planning the testing tasks during later testing work
The results are documented in the test plan. IEEE Standard 829-1998 [IEEE 829] provides a template.
This structure2 works well in practice. The sections listed will be found in real test plans in many projects in the same, or slightly modified, form. The new edition of IEEE 829-2008 [IEEE 829-2008] differentiates between “Master Test Plan” and “Level Test Plan.” The overall test plan (“Master Test Plan”) is required for every project. The different level test plans are optional, depending on the criticality of the product developed. An existing test plan according to IEEE 829-1998 can be changed into the structure of the master test plan in IEEE 829-2008 using mapping or a cross-reference listing. The new standard also has a different approach: There is an explicit requirement for tailoring the test documentation depending on product risks and organizational needs. The standard encourages putting some information from the plans into tools or, if necessary, other plans.
When preparing for an exam using the Foundation syllabus version 2015, IEEE Standard 829-2008, not 1998, should be studied!
Test planning is a continuous activity for the test manager throughout all phases of the development project. The test plan and related plans must be updated regularly, based on feedback from test activities and reacting to changing project risks.
6.2.3 Prioritizing Tests
Even with good planning and control, it is possible that the time and budget for the total test, or for a certain test level, are not sufficient for executing all planned test cases. In this case, it is necessary to select test cases in a suitable way. Even with a reduced number of executable test cases, it must be assured that as many as possible critical faults are found. This means test cases must be prioritized.
Prioritization rule
Test cases should be prioritized so that if any test ends prematurely, the best possible test result at that point of time is achieved.
The most important test cases first
Prioritization also ensures that the most important test cases are executed first. This way important problems can be found early.
The criteria for prioritization, and thus for determining the order of execution of the test cases, are outlined next. Which criteria are used depends on the project, the application area, and the customer requirements.
Criteria for prioritization
The following criteria for prioritization of test cases may be used:
- The usage frequency of a function or the probability of failure in software use. If certain functions of the system are used often and they contain a fault, then the probability of this fault leading to a failure is high. Thus, test cases for this function should have a higher priority than test cases for a less-often-used function.
- Failure risk. Risk is the combination (mathematical product) of severity and failure probability. The severity is the expected damage. Such risks may be, for example, that the business of the customer using the software is impaired, thus leading to financial losses for the customer. Tests that may find failures with a high risk get higher priority than tests that may find failures with low risks (see also section 6.4.3).
- The visibility of a failure for the end user is a further criterion for prioritization of test cases. This is especially important in interactive systems. For example, a user of a city information service will feel unsafe if there are problems in the user interface and will lose confidence in the remaining information output.
- Test cases can be chosen depending on the priority of the requirements. The different functions delivered by a system have different importance for the customer. The customer may be able to accept the loss of some of the functionality if it behaves wrongly. For other parts, this may not be possible.
- Besides the functional requirements, the quality characteristics may have differing importance for the customer. Correct implementation of the important quality characteristics must be tested. Test cases for verifying conformance to required quality characteristics get a high priority.
- Prioritization can also be done from the perspective of development or system architecture. Components that lead to severe consequences when they fail (for example, a crash of the system) should be tested especially intensively.
- Complexity of the individual components and system parts can be used to prioritize test cases. Complex program parts should be tested more intensively because developers probably introduced more faults. However, it may happen that program parts seen as easy contain many faults because development was not done with the necessary care. Therefore, prioritization in this area should be based on experience data from earlier projects run within the organization.
- Failures having a high project risk should be found early. These are failures that require considerable correction work that in turn requires special resources and leads to considerable delays of the project (see section 6.4.3).
In the test plan, the test manager defines adequate priority criteria and priority classes for the project. Every test case in the test plan should get a priority class using these criteria. This helps in deciding which test cases can be left out if resource problems occur.
Where there are many defects, there are probably more
Where many faults were found before, more are present. This phenomenon occurs often in projects. To react appropriately, it must be possible to change test case priority. In the next test cycle (see section 6.5), additional test cases should be executed for such defect-prone test objects.
Without prioritizing test cases, it is not possible to adequately allocate limited test resources. Concentration of resources on high-priority test cases is a MUST.
6.2.4 Test Entry and Exit Criteria
Defining clear test entry and exit criteria is an important part of test planning. They define when testing can be started and stopped (totally or within a test level).
Test start criteria
Here are typical criteria, or checkpoints, that need to be fulfilled before executing the planned tests:
- The test environment is ready.
- The test tools are ready for use in the test environment.
- Test objects are installed in the test environment.
- The necessary test data is available.
These criteria are preconditions for starting test execution. They prevent the test team from wasting time trying to run tests that are not ready.
Exit criteria
Exit criteria are used to make sure test work is not stopped by chance or prematurely. They prevent tests from ending too early, for example, because of time pressure or because of resource shortages. But they also prevent testing from being too extensive. Here are some typical exit criteria and corresponding metrics or indicators:
- Achieved test coverage: Tests run, covered requirements, code coverage, etc.
- Product quality: Defect density, defect severity, failure rate, and reliability of the test object
- Residual risk: Tests not executed, defects not repaired, incomplete coverage of requirements or code, etc.
- Economic constraints: Allowed cost, project risks, release deadlines, and market chances
The test manager defines the project-specific test exit criteria in the test plan. During test execution, these criteria are then regularly measured and evaluated and serve as the basis for decisions by test and project management.
6.3 Cost and Economy Aspects
Testing can be very costly and can constitute a significant cost factor in software development. How much effort is adequate for testing a specific software product? When is the test cost higher than the possible benefit?
To answer these questions, one must understand the potential defect costs due to lack of checking and testing. Then, one has to compare defect costs and testing costs.
6.3.1 Costs of Defects
If testing activities are reduced or cut out completely, there will be more undetected faults and deficiencies in the product. These remain in the product and may lead to the following costs:
Costs due to product deficiencies
- Direct defect costs: Costs that arise for the customer due to failures during operation of the software product (and that the vendor may have to pay for). Examples are costs due to calculation mistakes (data loss, wrong orders, damage of hardware or parts of the technical installation, damage to personnel); costs because of the failure of software-controlled machines, installations, or business processes; and costs due to installation of new versions, which might also require training employees. Very few people think of these costs, but they can be huge. The impact from just the time it takes to install a new version at all customer sites can be enormous.
- Indirect defect costs: Costs or loss of sales for the vendor that occur because the customer is dissatisfied with the product. Some examples include penalties or reduction of payment for failure to meet contractual requirements, increased costs for the customer hotline and support, bad publicity, even legal costs such as loss of license (for example, for safety critical software).
- Costs for defect correction: Costs paid to vendors for fault correction. For example, time needed for failure analysis, correction, retest and regression test, redistribution and reinstallation, new customer and user training, delay of new products due to tying up the developers with maintenance of the existing product, decreasing competitiveness.
It is hard to determine which types of costs will occur in reality, how likely it is, and how expensive it will be, that is, how high the failure cost risk is for a project. This risk depends of course on the kind and size of the software product, the type and business area of the customer, the design of the contract, legal constraints, the type of failures, and the number of installations or end users. There are certainly big differences between software developed specifically for a customer and commercial off-the-shelf products. In case of doubt, all these influencing factors must be evaluated in a project-specific risk analysis.
Finding defects as early as possible lowers the costs
It is crucial to find faults as early as possible after their creation. Defect costs grow rapidly the longer a fault remains in the product (one of the fundamental principles in chapter 2). This is independent of how high the risk of a fault really is.
- A fault that is created very early (e.g., an error in the requirements definition) can, if not detected, produce many subsequent defects during the following development phases (“multiplication” of the original defect).
- The later a fault is detected, the more corrections are necessary. Previous phases of the development (requirements definition, design, and programming) may even have to be partly repeated.
A reasonable assumption is that with every test level, the correction costs for a fault double with respect to the previous level. More information on this can be found in [URL: NIST Report].
If the customer has already installed the software product, there is the additional risk of direct and indirect defect costs. In the case of safety-critical software (control of technical installations, vehicles, aircraft, medical devices, etc.), the potential consequences and costs can be disastrous.
6.3.2 Cost of Testing
The most important action to reduce or limit risk is to plan verification and test activities. But there are plenty of factors that influence the cost3 of such testing activities, and in practice they are difficult to quantify. The following list shows the most important factors that a test manager should take into account when estimating the cost of testing:
- Maturity4 of the development process
- Stability of the organization
- Developer’s error rate
- Change rate for the software
- Time pressure because of unrealistic plans
- Validity, stability, and correctness of plans
- Maturity of the test process, and the discipline in configuration, change, and incident management
- Quality and testability of the software
- Number, severity, and distribution of defects in the software
- Quality, expressiveness, and relevance of the documentation and other information used as test basis
- Size and type of the software and its system environment
- Complexity of the problem domain and the software (e.g., cyclomatic number, see section 4.2.5)
- Test infrastructure
- Availability of testing tools
- Availability of test environment and infrastructure
- Availability of and experience with testing processes, standards, and procedures
- Employee (project member) qualification
- Tester experience and know-how about the field of testing
- Tester experience and know-how about test tools and test environment
- Tester experience and know-how about the test object
- Collaboration between the tester, the developer, management, and customer
- Quality requirements
- Intended test coverage
- Intended reliability or maximum number of remaining defects after testing
- Requirements for security and safety
- Requirements for test documentation5
- Test approach
- The testing objectives (themselves driven by quality requirements) and means to achieve them, such as number and comprehensiveness of test levels (component, integration, system test)
- The chosen test techniques (black box or white box)
- Test schedule (start and execution of the test work in the project or in the software life cycle)
The test manager’s influence
The test manager can directly influence only a few of these factors. The manager’s perspective looks like this:
- Maturity of the software development process
This cannot be influenced in the short run; it is a given and must be accepted as is. Influence in this area can only be exercised in the long run, using a process improvement program.
- Testability of the software
This is very dependent on the maturity of the development process. A well-structured process with reviews leads to better-structured software that is easier to test. This factor can only be influenced in the long run through a process improvement program.
- Test infrastructure
Usually this is a given, but it may be improved during the project in order to save time and cost when it is used.
- Qualification of the project members
This can be changed relatively fast by choosing different test personnel, but training may help in the longer run.
- Quality goals
They are given by customers and other stakeholders and can be changed only slightly (by prioritization).
- Test approach
This can be freely chosen and is the only way a test manager can control and monitor in the short run.
6.3.3 Test Effort Estimation
Before defining a schedule and assigning resources, the test manager must estimate the testing effort to be expected.
General estimation approaches
For small projects, this estimation can be done in one step. For larger projects, separate estimations for each test level and test cycle may be necessary.
In general, two approaches for estimation of test effort are possible:
- Listing all testing tasks; then letting either the task owner or experts who have estimation experience estimate each task
- Estimating the testing effort based on effort data of former or similar projects, or based on typical values (e.g., average number of test cases run per hour)
The effort for every testing task depends on the factors described in the earlier section on testing costs (section 6.3.2). Most of these factors influence each other, and it is nearly impossible to analyze them completely. Even if no testing task is forgotten, task-driven test effort estimation tends to underestimate the testing effort. Estimating based on experience data of similar projects or typical values usually leads to better results.
Rule of thumb
If no data is available, the following rule of thumb can be helpful: testing tasks (including all test levels) in typical business application development costs about 50% of the overall project resources.
6.4 Choosing the Test Strategy and Test Approach
A test strategy or approach defines the project’s testing objectives and the means to achieve them. It therefore determines testing effort and costs. Selecting an appropriate test strategy is one of the most important planning task decisions for a test manager. The goal is to choose a test approach that optimizes the relation between costs of testing and costs of possible defects as well as minimizes the risk (see section 6.4.3).
Cost-benefit relationship
The test costs should, of course, be less than the costs that would be caused by surviving defects and deficiencies in the final product. But, very few software development organizations possess or bother to collect data that enables them to quantify the relation between costs and benefits. This often leads to intuitive rather than rational decisions about how much testing is enough.
6.4.1 Preventative vs. Reactive Approach
The point in time at which testers become involved highly influences the approach. We can distinguish two typical situations:
- Preventive approaches are those in which testers are involved from the beginning: test planning and design start as early as possible. The test manager can really optimize testing and reduce testing costs. Use of the general V-model (see figure 3-1), including design reviews, etc., will contribute a lot to prevent defects. Early test specification and preparation, as well as application of reviews and static analysis, contribute to finding defects early and thus lead to reduced defect density during test execution. When safety-critical software is developed, a preventive approach may be mandatory.
- Reactive approaches are those in which testers are involved (too) late and a preventive approach cannot be chosen: test planning and design starts after the software or system has already been produced. Nevertheless, the test manager must find an appropriate solution even in this case. One very successful strategy in such a situation is called exploratory testing. This is a heuristic approach in which the tester “explores” the test object and test design, test execution, and evaluation occur nearly concurrently (see also section 5.3).
When should testing be started?
Preventative approaches should be chosen whenever possible. Cost analysis clearly shows the following:
- The testing process should start as early as possible in the project.
- Testing should continuously accompany all phases of the project.
6.4.2 Analytical vs. Heuristic Approach
During test planning and test design, the test manager may use different sources of information. Two extreme approaches are possible:
- Analytical approach
Test planning is founded on data and (mathematical) analysis of it. The criteria discussed in section 6.3 will be quantified (at least partially) and their correlation will be modeled. The amount and intensity of testing are then chosen such that individual or multiple parameters (costs, time, coverage, etc.) are optimized.
- Heuristic approach
Test planning is founded on experience of experts (from inside or outside the project) and/or on rules of thumb. Reasons may be that no data is available, mathematical modeling is too complicated, or the necessary know-how is missing.
The approaches used in practice are between these extremes and use (to different degrees) both analytical and heuristic elements:
- Model-based testing uses abstract functional models of the software under test for test case design, to find test exit criteria, and to measure test coverage. An example is state-based testing (see section 5.1.3), where state transition machines are used as models.
- Statistical or stochastic (model-based) testing uses statistical models about fault distribution in the test object, failure rates during use of the software (such as reliability growth models), or the statistical distribution of use cases (such as operational profiles) to develop a test approach. Based on this data, the test effort is allocated and test techniques are chosen.
- Risk-based testing uses information on project and product risks and directs testing to areas with high risk. This is described in more detail in the next section.
- Process- or standard-compliant approaches use rules, recommendations,6 and standards (e.g., the V-model or IEEE 829) as a “cookbook.”
- Reuse-oriented approaches reuse existing test environments and test material. The goal is to set up testing quickly by maximal reuse.
- Checklist-based (methodical) approaches use failure and defect lists from earlier test cycles,7 lists of potential defects or risks,8 or prioritized quality criteria and other less formal methods.
- Expert-oriented approaches use the expertise and “gut feeling” of involved experts (for the technology used or the application domain). Their personal feeling about the technologies used and/or usage domain influences and controls their choice of test approach.
These approaches are seldom used as they are described. Generally, a combination of several approaches is used to develop the testing strategy.
6.4.3 Testing and Risk
Risk = damage × probability
When looking for criteria to select and prioritize testing goals, test methods, and test cases, one of the best criteria is risk.
Risk is defined as the mathematical product of the loss or damage due to failure and the probability (or frequency) of failure resulting in such damage. Damage comprises any consequences or loss due to failure (see section 6.3.1). The probability of occurrence of a product failure depends on the way the software product is used. The software’s operational profile must be considered here. Therefore, detailed estimation of risks is difficult.9 Risk factors to be considered may arise from the project (project risks) as well as from the product to be delivered (product risks).
Project risks
Project risks are risks that threaten the project’s capability to deliver the product:
- Supplier-side risks such as, for example, the risk that a subcontractor fails to deliver or fighting about the contract. Project delays or even legal action may result from these risks.
- An often-underestimated organizational risk is lack of necessary resources (total or partial lack of personnel with the necessary skills; recognizing necessary training but not implementing it), problems of human interaction (e.g., if testers or test results do not get adequate attention), or internal power struggles such as no or insufficient cooperation between different departments.
- Technical problems are another project risk. Wrong, incomplete, fuzzy, or infeasible requirements may lead to project failure. If new technologies, tools, programming languages, or methods are applied without sufficient experience, the expected result—to get better results faster—may easily turn into the opposite. Another technical project risk is that the quality of intermediate results is too low (design documents, program code, or test cases) or that defects have not been detected and corrected. There are even risks for the test itself—for example, if the test environment is not ready or the test data is incomplete.
Product risks
Product risks are risks resulting from problems with the delivered product:
- The delivered product has inadequate functional or nonfunctional quality. Or the quality of the data to be processed is poor (for example, because of faults in previous data migration or conversion).
- The product is not fit for its intended use and is thus unusable.
- The use of the product causes harm to equipment or even endangers human life.
Risk management
The [IEEE 730] and [IEEE 829] standards for quality assurance and test plans demand systematic risk management. This comprises the following actions:
- Regularly identifying what can go wrong (risks)
- Prioritizing identified risks
- Implementing actions to mitigate or fight those risks
An important risk mitigation activity is testing; testing provides information about existing problems and the success or failure of correction. Testing decreases uncertainty about risks, helps to estimate risks, and identifies new risks.
Risk-based Testing
Risk-based testing helps to minimize and fight product risks from the start of the project. Risk-based testing uses information about identified risks for planning, specification, preparation, and execution of the tests. All major elements of the test approach are determined based on risk:
- The test techniques to be used
- The extent of testing
- The priority of test cases
Even other risk-minimizing measures, such as training for inexperienced software developers, are considered as supplements to measures for testing.
Risk-based test prioritization
Risk based prioritization of the tests ensures that risky product parts are tested more intensively and earlier than parts with lower risk. Severe problems (causing much corrective work or serious delays) are found as early as possible. Opposed to this, distributing scarce test resources equally throughout all test objects does not make much sense because this approach will test critical and uncritical product parts with the same intensity. Critical parts are then not adequately tested and test resources are wasted on uncritical parts.
6.5 Managing The Test Work
Every cycle through the testing process (see section 2.2, figure 2-4) usually results in tasks for correction or →changes for the developers. When bugs are corrected or changes are implemented, a new version of the software comes into life, and it must be tested. In every test level, the test process is repeatedly executed.
Test manager tasks
The test manager has to initiate these test cycles, monitor their progress, and control the test work. Depending on the size of the project, a test level may be managed by its own test manager.
6.5.1 Test Cycle Planning
Section 6.2 described the initial test planning (test approach and general work flow). This should be developed early in a project and described in the test plan.
Detailed planning per test cycle
This general plan must be detailed in a detailed plan for the concrete test cycle to be run next, and it must be adapted to the current project situation. The following points should be addressed:
- State of development: The software available at the start of the test cycle may have less or different functionality than originally planned for. The test specification and test cases may need to be adapted.
- Test results: Problems discovered in earlier test cycles might require changed test priorities. Fixed defects require additional confirmation tests (retests), and these must be planned. Additional tests may be necessary because some problems may be difficult or impossible to reproduce or analyze.
- Resources: The plan for the current test cycle must be consistent with the project plan. Attention must be given to personal disposition planning, holiday planning, availability of test environment, and special tools.
Using these preconditions, the test manager estimates effort and duration of the test work and plans in detail which test cases shall be executed by which tester, in which order, and at which points of time. The result of this detailed planning is the plan for the next test cycle or regression test cycle.
6.5.2 Test Cycle Monitoring
To measure and monitor the results of the ongoing tests, objective →test metrics should be used. They are defined in the test plan. Only metrics that are reliably, regularly, and simply measurable10 should be used. These approaches are possible:
Metrics for monitoring the test process
- Fault- and failure-based metrics
Number of encountered faults and number of generated incident reports (per test object) in the particular release. This should also include the problem class and status, and, if possible, a relation to the size of the test object (lines of code), test duration, or other measures (see section 6.6).
- Test-case-based metrics
Number of test cases in a certain state, like specified or planned, →blocked (e.g., because of a fault not being eliminated), number of test cases run (passed or failed).
- Test-object-based metrics
Coverage of code, dialogs, possible installation variants, platforms, etc.
- Cost-based metrics
Test cost until now, cost of the next test cycle in relation to expected benefit (prevented failure cost or reduced project or product risk).
Test status report
The test manager lists the current measurement results in the test reports. After each test cycle, a test status report should show the following information about the status of the test activities:
- Test object(s), test level, test cycle date from ... to ...
- Test progress: tests planned/run/blocked
- Incident status: new/open/corrected
- Risks: new/changed/known
- Outlook: planning of the next test cycle
- Assessment: (subjective) assessment of the maturity of the test object, the possibility for release, or the current confidence
A template for such a report can be found in [IEEE 829].
Test exit criteria
On the one hand, the measured data serves as a means to determine the current situation and to answer the question, How far has the test progressed? On the other hand, the data serves as exit criterion and to answer the question, Can the test be finished and the product be released? The quality requirements to be met (the product’s criticality) and the available test resources (time, personnel, test tools) determine which criteria are appropriate for determining the end of the test. The test exit criteria for the current project are also documented in the test plan. It should be possible to decide about each test exit criterion based on the collected test metrics.
The test cases in the VSR project are divided into the following three priority levels:

Based on this prioritization, the test plan describes the following decision about the test-case-based completion criteria for the VSR-System test:
- All test cases with priority 1 have been executed without failure.
- At least 60% of the test cases with priority 2 have been executed.
Product release
If the defined test exit criteria are met, project management (using advice from the test manager) decides whether the corresponding test object should be released and delivered. For component and integration testing, “delivery” means passing the test object to the next test level. The system test precedes the release of the software for delivery to the customer. Finally, the customer’s acceptance test releases the system for operation in the real application environment.
Release does not mean “bug free.” The product will surely contain some undiscovered faults, as well as some known ones that were rated as “not preventing release” and that therefore were not corrected. The latter faults are recorded in the incident database (also called →defect database or →problem database) and may be corrected later, during software maintenance (see section 3.6.1).
6.5.3 Test Cycle Control
React on deviations from the plan
If testing is delayed with respect to the project and test planning, the test manager must take suitable countermeasures. This is called test (cycle) control. These actions may relate to the test or any other development activity.
It may be necessary to request and deploy additional test resources (personnel, workstations, and tools) in order to compensate for the delay and catch up on the schedule in the remaining cycles.
If additional resources are not available, the test plan must be adapted. Test cases with low priority will be omitted. If test cases are planned in several variants, a further option is to only run them in a single variant (for example, tests are performed on one operating system instead of several). Although these adjustments lead to omission of some interesting tests, the available resources can at least make it possible to execute the high-priority test cases.
Depending on the severity of the faults and problems found, test duration may be extended. This happens because additional test cycles become necessary, because the corrected software must be retested after each correction cycle (see section 3.7.4). This could mean that the product release must be postponed.
Changes to test plan must be communicated clearly
It is important that the test manager documents and communicates every change in the plan because the change in the test plan may increase the release risk (product risk). The test manager is responsible for communicating this risk openly and clearly to the people responsible for the project.
6.6 Incident Management11
To ensure reliable and fast elimination of failures detected by the various test levels, a well-functioning procedure for communicating and managing those incident reports is needed. Incident management starts during test execution or upon test cycle completion by evaluating the test log.
6.6.1 Test Log
Test log analysis
After each test run, or at the latest upon completion of a test cycle, the test logs are evaluated. Real results are compared to the expected results. If the test was automated, the tool will normally do this comparison immediately. Each significant, unexpected event that occurred during testing could be an indication of a test object malfunctioning. Corresponding passages in the test log are analyzed. The testers ascertain whether a deviation from the predicted outcome really has occurred or whether an incorrectly designed test case, incorrect test automation, or incorrect test execution caused the deviation (testers, too, can make mistakes).
Documenting incidents
If the test object caused the problem,12 a defect or incident report is created. This is done for every unexpected behavior or observed deviation from the expected results found in the test log. An observation may be a duplicate of an observation recorded earlier. In this case, it should be checked to see whether the second observation yields additional information, which may make it possible to more easily search for the cause of the problem. Otherwise, to prevent duplication of an incident record, the same incident should not be recorded a second time.
Cause analysis is a developer task
However, the testers do not have to investigate the cause of a recorded incident. This (debugging) is the developers’ responsibility.
6.6.2 Incident Reporting
In general, a central database is established for each project, in which all incidents and failures discovered during testing (and possibly during operation) are registered and managed. All personnel involved in development as well as customers and users can report incidents.13 These reports can refer to problems in the tested (parts of) programs as well as to faults in specifications, user manuals, or other documents.
Incident reporting is also referred to as problem, anomaly, defect, or failure reporting. Not every incident or problem is due to a developer mistake. Incident reporting sounds less like an “accusation.” Incident reporting is not a one-way street because every developer can comment on reports—for example, by requesting comments or clarification from a tester or by rejecting an unjustified report. Should a developer correct a test object, the corrections will also be documented in the incident database. This enables the responsible tester to understand this correction’s implications in order to retest it in the following test cycle.
At any point in time, the incident database enables the test manager and the project manager to get an up-to-date and complete picture of the number and state of problems and about the progress of corrections. For this purpose, the database should offer appropriate possibilities for reporting and analysis.
Standardized reporting format
To allow for smooth communication and to enable statistical analysis of the incident reports, every report must follow a project-wide unique report template. The test manager should define this template and reporting structure in, for example, the test plan.
In addition to the description of the problem, the incident report typically contains information identifying the tested software, test environment, name of the tester, and defect class and prioritization as well as other information that’s important for reproducing and localizing the fault. Table 6-1 shows an example of an incident report template.
A similar, slightly less complex structure can be found in [IEEE 829]. Or a report can include many additional attributes and more detail, as shown in [IEEE 1044].
If the incident database is used in acceptance testing or product support, additional customer data must be collected. The test manager has to develop a template or scheme suitable for the particular project.
Document all information relevant to reproduction and correction
In doing so, it is important to collect all information necessary for reproducing and localizing a potential fault as well as information enabling analysis of product quality and correction progress.
Irrespective of the scheme agreed upon, the following rule must be observed: Each report must be written in such a way that the responsible developer can identify the problem with minimal effort and find its cause as fast as possible. Reproducing problems, localizing the cause of problems, and repairing faults are usually unplanned extra work for developers. Thus, the tester has the task of “selling” the incident report to the developers. In this situation, it is very tempting for developers to ignore or postpone analysis and repair of problems, which are unclearly described or difficult to understand.
Table 6–1
Incident report template

6.6.3 Defect Classification
An important criterion for managing a reported problem is its severity, that is, how far product use is impaired. The degree of severity will certainly be different for 100 open defect reports concerning system crashes in the database than it would be with layout errors in windows. Severity can be classified using the classes given in table 6-2.

The severity of a problem should be assigned from the point of view of the user or future user of the test object. The classifications in table 6-2, however, do not indicate how quickly a particular problem should be corrected. Priority associated with handling the problem (→failure priority) is a different matter and should not be confused with severity! When determining the priority of corrections, additional requirements defined by product or project management (for example, correction complexity), as well as requirements about further test execution (blocked tests), must be taken into account. Therefore, the question of how quickly a fault should be corrected is answered by an additional attribute, fault priority (or rather, correction priority). Table 6-3 presents a possible classification.

Incident analysis for controlling the test process
Analyzing the severity and priority of reported incidents allows the test manager to make statements about product robustness or deliverability. Apart from test status determination and clarification of questions relating to how many faults were found, how many of them are corrected, and how many are still to be corrected, trend analyses are important. This means making predictions based on the analysis of the trend of incoming incident reports over time. In this context, the most important question is whether the volume of product problems still increases or whether the situation seems to improve.
Incident analysis for improving the test process
Data from incident reports can also be used to improve the test process; for example, a comparison of data from several test objects can demonstrate which test objects show an especially small number of faults. This could mean a lack of tests or that the program has been implemented especially carefully.
6.6.4 Incident Status
Test management not only has a responsibility to make sure incidents are collected and documented properly but is additionally responsible (in cooperation with project management) for enabling and supporting rapid fault correction and delivery of improved versions of the test object.
This necessitates continuous monitoring of the defect analysis and correction process. For this purpose the incident status is used. Every incident report (see table 6-1) passes a series of predefined states, covering all steps from original reporting to successful defect resolution. Table 6-4 shows an example for an incident status scheme. Figure 6-2 demonstrates this procedure.
Only the tester may set the state to “Closed”
A crucial fact that is often ignored is that only the tester may set the state to “Closed” and not the developer! And this should happen only after the repeated test (retest) has proven that the problem described in the problem report does not occur anymore. Should new failures occur as side effects after bugs are fixed, these failures should be reported in new incident reports.
Table 6–4
Incident status scheme

Figure 6–2
Incident status model

The scheme described previously can be applied to many projects. However, the model must be tailored to cover existing or necessary decision processes in the project. In the basic model, all decisions lie with one single person. In larger-scale projects, groups make the decisions. The decision processes grow more complex because representatives of many stakeholders must be heard.
Change control board
In many cases, changes to be done by the developers are not really fault corrections, but real (functional) enhancements. Because the distinction between “incident report” and “enhancement request” and the rating as “justified” or “not justified” is often a matter of opinion, an institution accepting or rejecting incident reports and →change requests is needed. This institution, called the change control board, usually consists of representatives from the following stakeholders: product management, project management, test management, and the customer.
6.7 Requirements to Configuration Management
A software system consists of a multitude of individual components that must fit together to ensure the functionality of the system as a whole. In the course of the system’s development, new, corrected, or improved versions or variants of each of these components evolve. Because several developers and testers take part in this process simultaneously, it is far from easy to keep track of the currently valid components and their relationships.
Typical symptoms of insufficient configuration management
If configuration management is not done properly in a project, the following typical symptoms may be observed:
- Developers mutually overwrite each other’s modifications in the source code or other documents because simultaneous access to shared files is not avoided.
- Integration activities are impeded:
- Because it is unclear which code versions of a specific component exist in the development team and which ones are the current versions
- Because it is unclear which versions of several components belong together and can be integrated to a larger subsystem
- Because different versions of compilers and other development tools are used
- Problem analysis, fault correction, and regression tests are complicated:
- Because it is unknown where and why a component’s code was changed with respect to a previous version
- Because it is unknown from which code files a particular integrated subsystem (object code) originates
- Tests and →test evaluation are impeded:
- Because it is unclear which test cases belong to which version of a test object
- Because it is unclear which test cycle of which version of the test object gave which test results
Testing depends on configuration management
Insufficient configuration management thus leads to a number of possible problems disturbing the development and test process. If, for example, it is unclear during a test level whether the examined test objects are the latest version, the tests rapidly lose any significance. A test process cannot be properly executed without reliable configuration management.
Requirements to configuration management
From the perspective of the test, the following requirements should be met:
- Version management
This is the cataloguing, filing, and retrieval of different versions of a →configuration item (for example, version 1.0 and 1.1 of a component consisting of several files). This also includes securing comments on the reason for the particular change.
- Configuration identification
This is the identification and management of all files (configuration objects) in the particular version, which together comprise a subsystem (configuration). The prerequisite for this is version management.
- Incident and change status control
This is the documenting of incident reports and change requests and the possibility to reconstruct their application on the configuration objects.
- Configuration audits
To check the effectiveness of configuration management, it is useful to organize configuration audits. Such an →audit offers the possibility to check whether the configuration management documented all software components, whether configurations can be correctly identified, etc.
To implement configuration management conforming to the requirements mentioned earlier, differing processes and tools should be chosen depending on project characteristics. A configuration management plan must therefore determine a process tailored to the project situation. A standard for configuration management and respective plans can be found in [IEEE 828].
6.8 Relevant Standards
Today, a multitude of standards exist, setting constraints and defining the “state-of-the-art” even for software development. This is especially true for the area of software quality management and software testing, as the standards quoted in this book prove. One of the tasks for a quality manager or test manager is defining, in this context, which standards, rules, or possible legal directives are relevant for the product to be tested (product standards) or for the project (project standards) and to ensure that they are adhered to. Here are some possible sources of standards:
- Company standards
These are company internal directives, procedure, and guidelines (for the supplier, but also possibly set by the customer), such as a quality management handbook, a test plan template, or programming guidelines.
- Best practices
These are not standardized, but professionally accepted methods and procedures representing the state of the art in a particular field of application.
- Quality management standards
These are standards spanning several industrial sectors, specifying minimal process requirements yet not stating specific requirements for process implementation. A well-known example is [ISO 9000], which requires appropriate (intermediate) tests during the production process (also in the special case of the software development process) without indicating when and how these tests are to be performed.
- Standards for particular industrial sectors
These are standards defining for a particular product category or application field the minimum extent to which tests must be performed or documented. An example is standard [RTCA-DO 178] for airborne software products; another example is [EN 50128] for railway signaling applications.
- Software testing standards
These are process or documentation standards, defining independently of the product how software tests should be performed; for example, the standards [BS 7925-2], [IEEE 829], [IEEE 1028], [ISO 29119].
The important and relevant standards for software testing are covered in this book. The test plan according to [IEEE 829-1998] and [IEEE 829-2008] is described in detail in appendix A. Following such standards makes sense, even when compliance is not mandatory. At least when encountering legal disputes, demonstrating that development has been done according to the “state of best industry practice” is helpful. This also includes compliance to standards.
6.9 Summary
- Development activities and testing activities should be independently organized. The clearer this separation, the more effective the testing.
- Depending on the task to be executed within the test process, people with role-specific testing skills are needed. In addition to professional skills, social competence is required.
- The test manager’s tasks comprise the initial strategy and planning of the tests as well as further planning, monitoring, and controlling of the different test cycles.
- In the test plan, the test manager describes and explains the test strategy (test objectives, test approach, tools, etc.). The international standard [IEEE 829] provides a checklist for format and content.
- Faults and deficiencies that are not found by the testing and thus remain in the product can lead to very high costs. The test strategy has to balance testing costs, available resources, and possible defect costs.
- It is important to quickly decide which tests can be left out if lack of test resources occurs. To achieve this, the tests should be prioritized.
- Risk is one of the best criteria for prioritizing. Risk-based testing uses information about identified risks for planning and controlling all steps in the test process. All major elements of the test strategy are determined based on risk.
- Measurable test exit criteria objectively define when testing can be stopped. Without given test exit criteria, testing might stop randomly.
- Incident management and configuration management, together, form the basis for an efficient test process.
- Problem reports must be collected in a project-wide standardized way and followed up through all stages of the incident analysis and fault resolution process.
- Standards contain specifications and recommendations for professional software testing. Following such standards makes sense, even when compliance is not mandatory.