
The only way a programmer will be able to improve is through practice. Creating programs of different types and using different technologies usually provide a programmer with new insights into software construction. Based on this idea, a Kata is an exercise that defines some requirements or fixed features to be implemented in order to achieve some goals.
The programmer is asked to implement a possible solution and then compare it with others trying to find the best. The key value of this exercise is not getting the fastest implementation but discussing decisions taken while designing the solution. In most cases, all programs created in Kata are dropped at the end.
The Kata exercise in this chapter is about a legacy system. This is a sufficiently simple program to be processed in this chapter but also complex enough to pose some difficulties.
You have been tasked to adopt a system that is already in production, a working piece of software for a book library: the Alexandria project.
The project currently lacks documentation, and the old maintainer is no longer available for discussion. So, should you accept this mission, it is going to be entirely your responsibility, as there is no one else to rely on.
We have been able to recover these specification snippets from the time the original project was written:
- The Alexandria software should be able to store books and lend them to users, who have the power to return them. The user can also query the system for books, by author, book title, status, and ID.
- There is no time frame for returning the books.
- The books can also be censored as this is considered important for business reasons.
- The software should not accept new users.
- The user should be told, at any moment, which is the server's time.
The Alexandria is a backend project written in Java, which communicates information to the frontend using a REST API. For the purpose of this Kata exercise, the persistence has been implemented as an in-memory object, using the Fake test double explained in http://xunitpatterns.com/Fake%20Object.html.
The code is available at https://bitbucket.org/vfarcic/tdd-chapter-08/commits/branch/legacy-code.
Until the point of adding a new feature, the legacy code might not be a disturbance to the programmers' productivity. The codebase is in a state that is worse than desired, but the production systems work without any inconveniences.
Now is the time when the problems start to appear. The Product Owner (PO) wants to add a new feature.
For example, as a library manager, I want to know all the history for a given book so that I can measure which books are more in demand than others.
As the old maintainer of the Alexandria project is no longer available for questions and there is no documentation, the black-box testing is more difficult. Thus, we decide to get to know the software better through investigation and then doing some spikes that will leak internal knowledge to us about the system.
We will later use this knowledge to implement the new feature.
Note
Black-box testing is a method of software testing that examines the functionality of an application without peering into its internal structures or workings. This type of test can be applied to virtually every level of software testing: unit, integration, system, and acceptance. It typically comprises most if not all higher-level testing, but can dominate unit testing as well.
Source: http://en.wikipedia.org/wiki/Black-box_testing.
More information on black-box testing can be found here: http://agile.csc.ncsu.edu/SEMaterials/BlackBox.pdf
When we know the required feature, we will start looking at the Alexandria project:
- 15 files
- maven-based (
pom.xml) - 0 tests
Firstly, we want to confirm is that this project has never been tested, and the lack of a test folder reveals so:
$ find src/test find: src/test: No such file or directory
These are the folder contents for the Java part:
$ cd src/main/java/com/packtpublishing/tddjava/ch08/alexandria/ $ find . . ./Book.java ./Books.java ./BooksEndpoint.java ./BooksRepository.java ./CustomExceptionMapper.java ./MyApplication.java ./States.java ./User.java ./UserRepository.java ./Users.java
The rest:
$ cd src/main $ find resources webapp resources resources/applicationContext.xml webapp webapp/WEB-INF webapp/WEB-INF/web.xml
This seems to be a web project (indicated by the web.xml file), using Spring (indicated by the applicationContext.xml). The dependencies in the pom.xml show the following (fragment):
<dependency> <groupId>org.springframework</groupId> <artifactId>spring-web</artifactId> <version>4.1.4.RELEASE</version> </dependency>
Having Spring is already a good sign, as it can help with the dependency injection, but a quick look showed that the context is not really being used. Maybe something that was used in the past?
In the web.xml file, we can find this fragment:
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
<module-name>alexandria</module-name>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext.xml</param-value>
</context-param>
<servlet>
<servlet-name>SpringApplication</servlet-name>
<servlet-class>org.glassfish.jersey.servlet.ServletContainer</servlet-class>
<init-param>
<param-name>javax.ws.rs.Application</param-name>
<param-value>com.packtpublishing.tddjava.ch08.alexandria.MyApplication</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>In this file:
- The context in
applicationContext.xmlwill be loaded - There is an application file (
com.packtpublishing.tddjava.ch08.alexandria.MyApplication) that will be executed inside a servlet
The MyApplication file is as follows:
public class MyApplication extends ResourceConfig {
public MyApplication() {
register(RequestContextFilter.class);
register(BooksEndpoint.class);
register(JacksonJaxbJsonProvider.class);
register(CustomExceptionMapper.class);
}
}This configures the necessary classes for executing the endpoint BooksEndpoint (fragment):
@Path("books")
@Component
public class BooksEndpoint {
private BooksRepository books = new BooksRepository();
private UserRepository users = new UserRepository();In this last snippet, we can find one of the first indicators that this is a legacy codebase: both dependencies (books and users) are created inside the endpoint and not injected. This makes unit testing more difficult.
We can start by writing down the element that will be used during refactoring; we write the code for the dependency injection in BooksEndpoint.
There are different paradigms of programming (for example, functional, imperative, and object-oriented) and styles (for example, compact, verbose, minimalistic, and too-clever). Therefore, the candidates for refactoring are different from one person to the other.
There is another way, as opposed to subjectively, of finding candidates for refactoring: objectively. Research papers investigating ways of finding these ways include:
Source: http://www.bth.se/fou/cuppsats.nsf/all/2e48c5bc1c234d0ec1257c77003ac842/$file/BTH2014SIVERLAND.pdf
After getting to know the code more, it seems that the most important functional change is to replace the current status (fragment):
@XmlRootElement
public class Book {
private final String title;
private final String author;
private int status; //<- this attribute
private int id;with a collection of them (fragment):
@XmlRootElement
public class Book {
private int[] statuses;
// ...This might seem to work (after changing all access to the field to the array, for example), but this also prompts a functional requirement.
The Alexandria software should be able to store books and lend them to users who have the power to return them. The user can also query the system for books, by author, book title, status, and ID.
The Product Owner (PO) confirms that searching books via status has now changed: now it also allows to search for any previous status.
This change is getting bigger and bigger. Whenever we feel that the time for removing this legacy code has come, we start applying the legacy code algorithm.
We have also detected a primitive obsession and feature envy smell; storing the status as int (primitive obsession) and then actuating on another object's state (feature envy). We will add this to the following to-do list:
- Dependency injection in BooksEndpoint for books
- Change status for statuses
- Remove the primitive obsession for status (optional)
In this case, the whole middle-end works as a standalone, using in-memory persistence. The same algorithm could be used if the persistence was saved into a database, but we would require some extra code to clean and populate the database between test runs.
We'll use DbUnit. More information can be found at http://dbunit.sourceforge.net/.
The first step we've decided to take to ensure the behavior is maintained during the a refactoring is to write end-to-end tests. In other applications that include frontend, this could be using a higher-level tool such as Selenium/Selenide.
In our case, as the frontend is not subject to refactoring, the tool can be lower-level. We have chosen to write HTTP requests for the purpose of end-to-end tests.
These requests should be automatic and testable, and should follow all existing rules for automatic tests or specifications. As we were discovering the real application behavior while writing these tests, we have decided to write a spike in a tool called Postman. (The tool can be found here: https://chrome.google.com/webstore/detail/postman-rest-client/fdmmgilgnpjigdojojpjoooidkmcomcm. The product website is here: https://www.getpostman.com/). This is also possible with a tool called curl (http://curl.haxx.se/).
Note
What is curl?
curl is a command-line tool and library for transferring data with URL syntax, supporting [...] HTTP, HTTPS, [...], HTTP POST, HTTP PUT, [...].
What's curl used for?
curl is used in command lines or scripts to transfer data.
Source: http://curl.haxx.se/.
To do this, we decide to execute the legacy software locally with the following line:
mvn clean jetty:run
This fires up a local jetty server that processes requests. The big benefit is that deployment is done automatically and there is no need to package everything and manually deploy to an application server (for example, JBoss AS, GlassFish, Geronimo, and TomEE). This can greatly speed up the process of making changes and seeing the effects, therefore decreasing the feedback lead time. Later on, we will start the server programmatically from Java code.
We start looking for functionalities. As we discovered earlier that the BooksEndpoint class contains the webservice endpoint definitions, this is a good place to start looking for functionalities. They are listed below:
- Add a new book.
- List all the books.
- Search for books by ID, by author, by title, and by status.
- Prepare this book to be rented.
- Rent this book.
- Censor this book.
- Uncensor the book.
We launch the server manually and start writing requests:
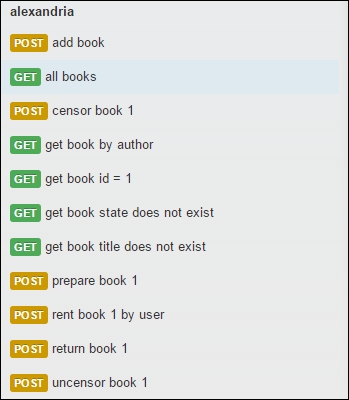
These tests seem good enough for a spike. One thing that we have realized is that each response contains a timestamp, so this makes our automation more difficult:
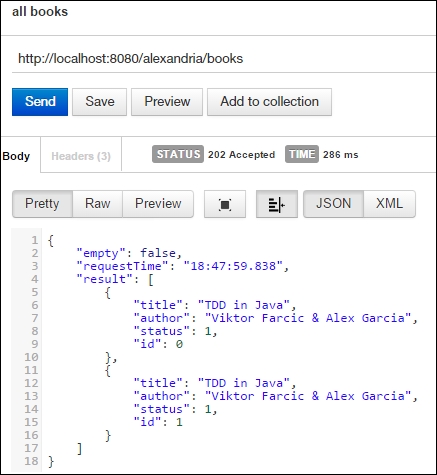
For the tests to have more value, they should be automated and exhaustive. For the moment, they are not, so we consider them spikes. They will be automated in the future.
Note
Each and every single test that we perform is not automated. In this case, the tests from the Postman interface are much faster to write than the automated ones. Also, the experience is far more representative of what production use would be like. The test client (thankfully, in this case) could introduce some problems with the production one, and therefore not return trusted results.
In this particular case, we have found that the Postman tests are a better investment because, even after writing them, we will throw them away. They give a very rapid feedback on the API and results. We also use this tool for prototyping the REST APIs, as its tools are both effective and useful.
The general idea here is: depending on whether you want to save those tests for the future or not, use one tool or another. This also depends on how often you want to execute them, and in which environment.
After writing down all the requests, these are the states that we have found in the application, represented by a state diagram:
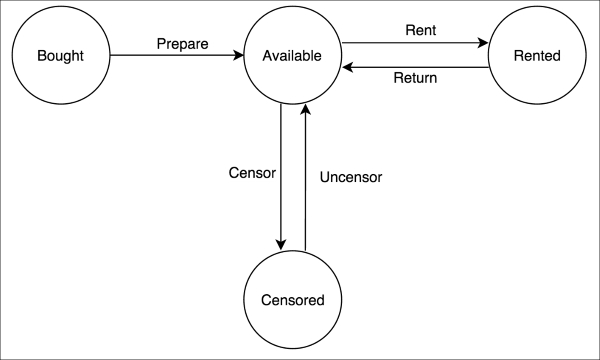
After these tests are ready and we start to understand the application, it is time to automate the tests. After all, if they are not automated, we don't really feel confident enough for refactoring.
We proceed to start the server programmatically. For this, we have decided to use Grizzly (https://grizzly.java.net/), which allows us to start the server using the configuration from Jersey's ResourceConfig (FQCN: org.glassfish.jersey.server.ResourceConfig), as shown on the test BooksEndpointTest (fragment):
The code can be found at https://bitbucket.org/vfarcic/tdd-chapter-08/commits/branch/refactor/inject-dependencies:
public class BooksEndpointTest {
public static final URI FULL_PATH =
URI.create("http://localhost:8080/alexandria");
private HttpServer server;
@Before
public void setUp() throws IOException {
ResourceConfig resourceConfig =
new MyApplication();
server = GrizzlyHttpServerFactory
.createHttpServer(FULL_PATH, resourceConfig);
server.start();
}
@After
public void tearDown(){
server.shutdownNow();
}This prepares a local server in the address http://localhost:8080/alexandria. It will only be available for a short period of time (while the tests run), so if you need to manually access the server, whenever you want to pause the execution, insert a call to the following method:
public void pauseTheServer() throws Exception {
System.in.read();
}When you want to stop the server, stop the execution or hit Enter in the allocated console.
Now we can start the server programmatically, pause it (with the preceding method), and execute the spike again. The results are the same, therefore the refactor is successful.
We add the first automated test to the system:
The code can be found at https://bitbucket.org/vfarcic/tdd-chapter-08/commits/branch/refactor/inject-dependencies:
public class BooksEndpointTest {
public static final String AUTHOR_BOOK_1 =
"Viktor Farcic and Alex Garcia";
public static final String TITLE_BOOK_1 =
"TDD in Java";
private final Map<String, String> TDD_IN_JAVA;
public BooksEndpointTest() {
TDD_IN_JAVA = getBookProperties(TITLE_BOOK_1, AUTHOR_BOOK_1);
}
private Map<String, String> getBookProperties
(String title, String author) {
Map<String, String> bookProperties =
new HashMap<>();
bookProperties.put("title", title);
bookProperties.put("author", author);
return bookProperties;
}
@Test
public void add_one_book() throws IOException {
final Response books1 = addBook(TDD_IN_JAVA);
assertBooksSize(books1, is("1"));
}
private void assertBooksSize(Response response, Matcher<String> matcher) {
response.then().body(matcher);
}
private Response addBook
(Map<String, ?> bookProperties) {
return RestAssured
.given().log().path()
.contentType(ContentType.URLENC)
.parameters(bookProperties)
.post("books");
}For testing purposes, we're using a library called RestAssured (https://code.google.com/p/rest-assured/) that allows for easier testing of REST and JSON.
To complete the automated test suite, we create these tests:
add_one_book().add_a_second_book().get_book_details_by_id().get_several_books_in_a_row().censor_a_book().cannot_retrieve_a_censored_book().
The code is found in https://bitbucket.org/vfarcic/tdd-chapter-08/commits/branch/refactor/inject-dependencies:
Now that we have a suite that ensures that no regression is introduced, we take a look at the following to-do list:
- Dependency injection in BooksEndpoint for books.
- Change status for statuses.
- Remove the primitive obsession for status (optional).
We will apply the already introduced refactoring technique "extract and override call". For this, we create a failing specification, as shown here:
@Test
public void add_one_book() throws IOException {
addBook(TDD_IN_JAVA);
Book tddInJava = new Book(TITLE_BOOK_1,
AUTHOR_BOOK_1,
States.fromValue(1));
verify(booksRepository).add(tddInJava);
}To pass this red specification, also known as a failing specificiation, we will first extract the dependency creation to a protected method in BookRepository class:
@Path("books")
@Component
public class BooksEndpoint {
private BooksRepository books =
getBooksRepository();
[...]
protected BooksRepository
getBooksRepository() {
return new BooksRepository();
}
[...]We copy the MyApplication launcher to this:
public class TestApplication
extends ResourceConfig {
public TestApplication
(BooksEndpoint booksEndpoint) {
register(booksEndpoint);
register(RequestContextFilter.class);
register(JacksonJaxbJsonProvider.class);
register(CustomExceptionMapper.class);
}
public TestApplication() {
this(new BooksEndpoint(
new BooksRepository()));
}
}This allows us to inject any BooksEndpoint. In this case, in the test BooksEndpointInteractionTest, we will override the dependency getter with a mock. In this way, we can check that the necessary calls are being made (fragment from BooksEndpointInteractionTest):
@Test
public void add_one_book() throws IOException {
addBook(TDD_IN_JAVA);
verify(booksRepository)
.add(new Book(TITLE_BOOK_1,
AUTHOR_BOOK_1, 1));
}Run the tests; everything is green. Even though the specifications are successful, we have introduced a piece of design only for test purposes, and the production code is not executing this new launcher TestApplication but is still executing the old MyApplication. To solve this this, we have to unify both launchers into one. This can be solved with the refactor "Parametrize constructor", also explained in Roy Osherove's book "The Art of Unit Testing" (http://artofunittesting.com).
We can unify the launchers accepting a BooksEndpoint dependency: if we don't specify it, it will register the dependency with the real instance of BooksRepository. Otherwise, it will register the received one:
public class MyApplication
extends ResourceConfig {
public MyApplication() {
this(new BooksEndpoint(
new BooksRepository()));
}
public MyApplication
(BooksEndpoint booksEndpoint) {
register(booksEndpoint);
register(RequestContextFilter.class);
register(JacksonJaxbJsonProvider.class);
register(CustomExceptionMapper.class);
}
}In this case, we have opted for 'constructor chaining' to avoid repetition in the constructors.
After doing this refactor, the BooksEndpointInteractionTest class is as follows, in its final state:
public class BooksEndpointInteractionTest {
public static final URI FULL_PATH = URI.
create("http://localhost:8080/alexandria");
private HttpServer server;
private BooksRepository booksRepository;
@Before
public void setUp() throws IOException {
booksRepository = mock(BooksRepository.class);
BooksEndpoint booksEndpoint =
new BooksEndpoint(booksRepository);
ResourceConfig resourceConfig =
new MyApplication(booksEndpoint);
server = GrizzlyHttpServerFactory
.createHttpServer(FULL_PATH, resourceConfig);
server.start();
}The first test passed, so we can mark the dependency injection task as done.
The to-do list:
- Dependency injection in BooksEndpoint for books
- Change status for statuses
- Remove the primitive obsession for status (optional)
Once we have the necessary test environment in place, we can add the new feature.
As a library manager, I want to know all the history for a given book so that I can measure which books are more in demand than others.
We will start with a red specification:
public class BooksSpec {
@Test
public void should_search_for_any_past_state() {
Book book1 = new Book("title", "author", States.AVAILABLE);
book1.censor();
Books books = new Books();
books.add(book1);
String available =
String.valueOf(States.AVAILABLE);
assertThat(
books.filterByState(available).isEmpty(), is(false));
}
}Run all the tests and see the last one fail.
Implement the search on all states (fragment):
public class Book {
private ArrayList<Integer> status;
public Book(String title, String author, int status) {
this.title = title;
this.author = author;
this.status = new ArrayList<>();
this.status.add(status);
}
public int getStatus() {
return status.get(status.size()-1);
}
public void rent() {
status.add(States.RENTED);
}
[...]
public List<Integer> anyState() {
return status;
}
[...]In this fragment, we have omitted the irrelevant parts: things that were not modified or more modifier methods such as rent that have changed the implementation in the same fashion:
public class Books {
public Books filterByState(String state) {
Integer expectedState = Integer.valueOf(state);
return new Books(
new ConcurrentLinkedQueue<>(
books.stream()
.filter(x -> x.anyState()
.contains(expectedState))
.collect(toList())));
}
[...]The outside methods, especially the serialization to JSON, are not affected as the method getStatus still returns an int value.
We run all the tests and everything is green.
The to-do list:
We have decided to also tackle the optional item in our to-do list.
The to-do list:
- Dependency injection in BooksEndpoint for books
- Change status for statuses
- Remove the primitive obsession for status (optional)
Note
The Smell: Primitive Obsession involves using primitive data types to represent domain ideas. For example, we use a string to represent a message, an integer to represent an amount of money, or a Struct/Dictionary/Hash to represent a specific object.
The source is: http://c2.com/cgi/wiki?PrimitiveObsession.
As this is a refactor step (that is, we are not introducing any new behavior into the system), we don't need any new specification. We will proceed and try to always stay green or leave it for as little time as possible.
We have converted the States from a java class with constants:
public class States {
public static final int BOUGHT = 1;
public static final int RENTED = 2;
public static final int AVAILABLE = 3;
public static final int CENSORED = 4;
}to an enum:
enum States {
BOUGHT (1),
RENTED (2),
AVAILABLE (3),
CENSORED (4);
private final int value;
private States(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public static States fromValue(int value) {
for (States states : values()) {
if(states.getValue() == value) {
return states;
}
}
throw new IllegalArgumentException(
"Value '" + value
+ "' could not be found in States");
}
}public class BooksEndpointInteractionTest {
@Test
public void add_one_book() throws IOException {
addBook(TDD_IN_JAVA);
verify(booksRepository).add(
new Book(TITLE_BOOK_1, AUTHOR_BOOK_1,
States.BOUGHT));
}
[...]
public class BooksTest {
@Test
public void should_search_for_any_past_state() {
Book book1 = new Book("title", "author", States.AVAILABLE);
book1.censor();
Books books = new Books();
books.add(book1);
assertThat(books.filterByState(
String.valueOf(
States.AVAILABLE.getValue()))
.isEmpty(), is(false));
}
[...]Adapt the production code. The code snippet is as follows:
@XmlRootElement
public class Books {
public Books filterByState(String state) {
State expected =
States.fromValue(Integer.valueOf(state));
return new Books(
new ConcurrentLinkedQueue<>(
books.stream()
.filter(x -> x.anyState()
.contains(expected))
.collect(toList())));
}
[...]Also the following:
@XmlRootElement
public class Book {
private final String title;
private final String author;
@XmlTransient
private ArrayList<States> status;
private int id;
public Book
(String title, String author, States status) {
this.title = title;
this.author = author;
this.status = new ArrayList<>();
this.status.add(status);
}
public States getStatus() {
return status.get(status.size() - 1);
}
@XmlElement(name = "status")
public int getStatusAsInteger(){
return getStatus().getValue();
}
public List<States> anyState() {
return status;
}
[...]In this case, the serialization has been done using the annotation:
@XmlElement(name = "status")
This converts the result of the method into the field named status.
Also, the field status, now ArrayList<States>, is marked with @XmlTransient so it is not serialized to JSON.
We execute all the tests and they are green, so we can now cross off the optional element in our to-do list:
The to-do list:
- Dependency injection in
BooksEndpointfor books - Change status for statuses
- Remove the primitive obsession for status (optional)