
The Kaggle platform provides an excellent way for beginners in data science and machine learning to pick up basic skills. By appropriately leveraging the platform, you get the opportunity to practice a broad range of problems on a variety of datasets, as well as to present and discuss your work with fellow machine learning engineers. This can potentially help grow your professional network. Importantly, the platform allows you to run Python notebooks directly in the cloud, which can significantly remove system setup barriers for a beginner. It also provides a limited amount of free GPU computing per week. This further democratizes access to the tools and methods discussed in this book. Throughout the book, we encourage you to use Kaggle to run the code presented.
Another tool—Google Colab—similarly provides free GPU computing while integrating with the Google Drive. If you had to pick one tool, however, I would recommend Kaggle due to its social nature and the access to datasets, discussions, and competitions—which are all extremely valuable learning resources. In reality, of course, most engineers likely leverage both at some point, to increase their weekly free GPU quota, for instance.
In this appendix, we attempt to provide a brief primer that can help a beginner ease their way into the various features of Kaggle. We divide it into two sections. We first discuss the Kaggle kernel concept for running the notebooks and follow that with a look at competitions, related discussions, and Kaggle blog features.
A.1 Free GPUs with Kaggle kernels
As previously mentioned, you can run Python code directly in the cloud for free using Kaggle. These cloud notebooks are sometimes referred to as Kaggle kernels. At the time of writing this in January 2021, Kaggle provides about 36 weekly GPU hours, which you can enable for any notebooks that you think might need it. We will demonstrate how to get started by walking through a simple scenario a beginner in Python might find useful.
Let’s say you were such a beginner and were interested in learning basic Python syntax with these kernels. A good place to start would be to go to https://www.kaggle.com/kernels and search for “Python tutorial.” The search results for this might look as shown in figure A.1.

Figure A.1 The best place to start learning about Kaggle kernels and launching a relevant notebook to learn something new. Go to https://www.kaggle.com/kernels, and search for the topic you are interested in. In the diagram, we show the result list of such a query for a beginner starting out with Python. Select the best-fitting one to proceed. Or create a new notebook using the New Notebook button.
As can be seen in the figure, searching will return a list of results, and you can select one that best fits your needs. In this case, the beginner might want the tutorial to start with an NLP focus directly, given the content of the book, and might thus select the highlighted tutorial notebook. Clicking it brings up the relevant rendered notebook, with a representative view shown in figure A.2.

Figure A.2 A view of the rendered notebook, with some key actions that can be performed highlighted
Note that the view shown is representative of the first view you will encounter when you click on one of our companion notebook links in the book repository.1 As stated in the figure, the notebook is rendered, which means you can scroll and see representative output for all code even without running it.
To run the code, click the Copy and Edit button to create your own version of the notebook. The resulting notebook will have the same dependencies—Python library versions preinstalled in the Kaggle environment and those used to generate the representative notebook output. Note that if you clicked the New Notebook button in figure A.1 instead of opting to copy an existing notebook, the dependencies will be the latest ones specified by Kaggle. Thus, you may need to modify the original code to get it to work, which makes things harder. To complete the copy and edit, or forking, process, you will be asked for login information. You can either register with your email address or use a social account such as Google to log in directly.
To replicate exactly the Kaggle environment we used for the companion notebooks for this book, we have included requirement files in the companion book repository. Note that these requirement files are only for the purpose of replicating the Kaggle environment on a Kaggle notebook. If you tried to use them on your local machine, depending on local architecture, you might run into additional issues and may need to modify them. We do not support this mode, and if you are pursuing it, use the requirement files only as a guide. Also keep in mind that not every listed requirement will be needed for your local installation.
Clicking Copy and Edit will bring you to the main workspace, which is illustrated in figure A.3. As can be seen in the figure, you can either run the currently selected cell or run all the code in the notebook using buttons on the top left. On the right panel, you can enable or disable your internet connection. Internet connection might be required to download data or install packages. This right panel also houses the option to enable GPU acceleration in the current notebook, which you will need for training neural networks in reasonable time. You will also see the datasets currently attached to the notebook and be able to click on any one of them to be taken to the dataset’s description. Clicking Add Data will open a search query box where you will be able to search for datasets of interest for adding to the current notebook, by keyword. For all of the companion notebooks for this book, necessary data has been attached to the notebook for you already.

Figure A.3 The main workspace when using Kaggle kernels. In the top left corner, buttons for running the notebook. In the top right, options to share, save, restart, and turn off the notebook. The right panel houses options for connecting to the internet (for installing packages or downloading data), enabling/disabling GPU acceleration for the current notebook, and adding data.
On the top right, you can select the Share settings of the notebook—you can make notebooks private to just yourself, share them with other users privately, or make them public to the world, depending on your project needs. All of our companion notebooks are public so that anyone can access them, but you can make your forks of them private. Importantly, also on the top right, selecting Save Version will bring up the dialog box to save your work, as shown in figure A.4.
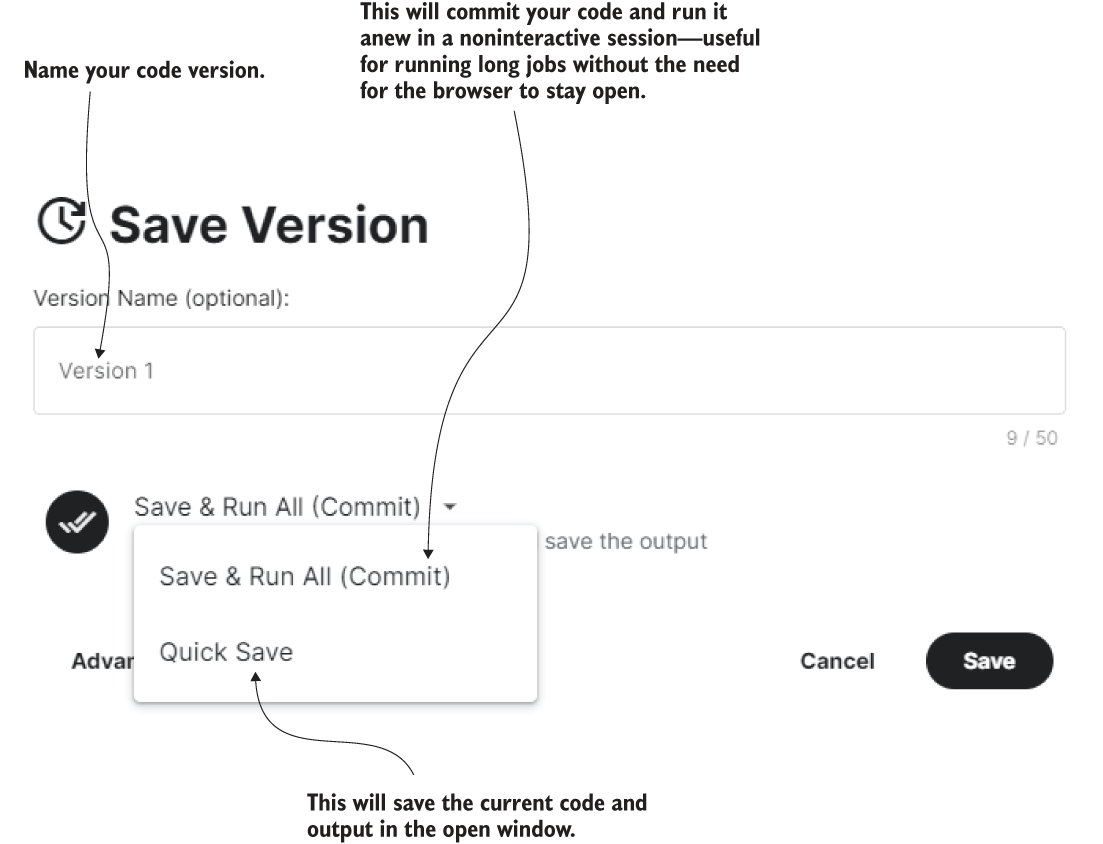
Figure A.4 Save options for notebook. You can either commit the code and have it run noninteractively for inspection later or quick-save the code and current output directly.
As the figure demonstrates, there are two save modes. The Quick Save mode will save the current code and output under the name specified in the version name text blog. In the case that the current output took several hours to generate, this would be the right choice. The Save & Run All option will save the code and run it afresh in a background, noninteractive process. This is particularly useful when running training jobs for long periods, such as for five or six hours. You can close the session and all windows and come back whenever you want to inspect the results. Inspection of the recent runs/saves can typically be carried out at the personalized URL www.kaggle .com/<username>/notebooks, where <username> is your username. For my username azunre, the view of this page is shown in figure A.5.

Figure A.5 Inspection of the recent runs/saves can typically be carried out at the personalized URL www. kaggle.com/<username>/notebooks, where <username> is your username (shown here for my username azunre).
We have thus covered the main features you need to know about to get started with the exercises in this book. There are many other features that we have not covered, and many more continue to get added frequently by Kaggle. Usually, a quick Google search and some persistence and desire to experiment is enough to figure out how to use any such feature.
In the next section, we briefly discuss Kaggle competitions.
A.2 Competitions, discussion, and blog
Leading enterprises facing technical challenges use Kaggle to stimulate research and development into solutions by offering significant cash prizes for top innovations. Let’s inspect the Kaggle competition page by selecting the trophy icon visible on the left panel of any Kaggle page, as shown in figure A.6.

Figure A.6 Go to the competitions page by selecting the trophy icon on the left panel of any Kaggle page. We can see that one competition is offering $100,000 in total prizes—that problem is likely quite valuable to that industry to motivate such an investment!
You can track these competitions to be updated on the most pressing problems in industry, while having access to the underlying data for immediate testing and experimentation. You could browse current and past competitions by topic to find data to test any ideas you might have. All you need to do is attach the dataset to the notebooks introduced in the previous section, change some paths, and likely you should be ready to produce some preliminary insights. Winning the competitions is, of course, great for the monetary reward, if you can do so, but the learning value you will get from experimenting, failing, and trying again is what is truly invaluable. Indeed, in my experience, a solution to a contest problem that may be considered mediocre by leaderboard placement may be the one that leads to a real-world impact, if it easier to deploy and scale in practice, for instance. This is what I personally care about, and so I tend to focus my efforts on working on problems most interesting to me that I know the least about, for the maximum learning value.
Clicking on any competition will bring up a dedicated page where you can browse its description, data, leaderboard, and, importantly, the “discussion” feature shown in figure A.7.

Figure A.7 The discussion feature enables you to engage with other members of the Kaggle community on specific topics of interest to you. Chat and build your network!
As you can probably see in figure A.7, this is a discussion forum relevant to the problem at hand. People post tips and starter notebooks, and ask important questions that might even be answered by competition organizers. If you run into any issues with a particular competition’s data, for example, it is very likely you will find answers to your questions here. Many competitions provide prizes for the most valuable contributions—often measured by upvotes—which incentivizes folks to be quite helpful. Winners often post their solutions, sometimes even as notebooks that you can directly repurpose. You might even strike up a friendship and build a team here for future challenges. Engage with the community, and give back some of what you take from it, and you will likely learn a lot more than you would otherwise. At the end of the day, science is still a social activity, which makes this feature of Kaggle particularly valuable.
Finally, Kaggle runs a blog at https://medium.com/kaggle-blog. Winners of big competitions are often interviewed here for tips they can share with others. Tutorials are frequently posted on various critical topics. Keep up-to-date with this to be sure to catch the latest emerging research trends in data science.
We hope this appendix was a useful exercise and brought you up to speed. Go forth and Kaggle!
1. https:/github.com/azunre/transfer-learning-for-nlp