
The World Wide Web has a client-server architecture based on a resource identification scheme (URI), a communication protocol (HTTP) and a document format (HTML), which together allow easy access and exchange of information. The decentralized nature of the Web and its effectiveness in making information accessible have led to fundamental social and cultural change. Every product, from breakfast cereal to cars, has a presence on the Web. Businesses and other institutions have come to regard the Web as an interface, even the primary interface, with their customers. By providing ubiquitous access to information, the Web has reduced barriers erected by geographic and political borders in a profound way.
Electronic hypertext contains links to expanded or related information embedded at relevant points in a document. The links are analogous to footnotes in a traditional paper document, but the electronic nature of these documents allows easier physical access to the links. As early as 1945, Vannevar Bush proposed linked systems for documents on microfiche [18], but electronic hypertext systems did not take hold until the 1960s and 1970s.
In 1980, Tim Berners-Lee wrote a notebook program for CERN called ENQUIRE that had bidirectional links between nodes representing information. In 1989, he proposed a system for browsing the CERN Computer Center’s documentation and help service. Tim Berners-Lee and Robert Cailliau developed a prototype GUI browser-editor for the system in 1990 and coined the name “World Wide Web.” The initial system was released in 1991. At the beginning of 1993 there were 50 known web servers, a number that grew to 500 by the end of 1993 and to 650,000 by 1997. Today, web browsers have become an integral interface to information, and the Internet has millions of web servers.
The World Wide Web is a collection of clients and servers that have agreed to interact and exchange information in a certain format. The client (an application such as a browser) first establishes a connection with a server (an application that accepts connections and responds). Once it has established a connection, the client sends an initial request asking for service. The server responds with the requested information or an error.
As described so far, the World Wide Web is a simple client-server architecture, no different from many others. Its attractiveness lies in the simplicity of the rules for locating resources (URIs), communicating (HTTP) and presenting information (HTML). The next section describes URLs, the most common format for resource location on the Web. Section 19.3 gives an overview of HTTP, the web communication protocol. HTML, the actual format for web pages, is not within the scope of this book. Section 19.4 discusses tunnels, gateways and caching. The chapter project explores various aspects of tunnels, proxies and gateways. Sections 19.5 and 19.6 guide you through the implementation of a tunnel that might be used in a firewall. Section 19.7 describes a driver for testing the programs. Section 19.8 discusses the HTTP parsing needed for the proxy servers. Sections 19.9 and 19.10 describe a proxy server that monitors the traffic generated by the browsers that use it. Sections 19.12 and 19.13 explore the use of gateways for firewalls and load balancing, respectively.
A Uniform Resource Locator (URL) has the form scheme : location. The scheme refers to the method used to access the resource (e.g., HTTP), and the location specifies where the resource resides.
Example 19.1.
The URL http://www.usp.cs.utsa.edu/usp/simple.html specifies that the resource is to be accessed with the HTTP protocol. This particular resource, usp/simple.html, is located on the server www.usp.cs.utsa.edu.
While http is not the only valid URL scheme, it is certainly the most common one. Other schemes include ftp for file transfer, mailto for mail through a browser or other web client, and telnet for remote shell services. The syntax for http URLs is as follows.
http_URL = "http:" "//" host [ ":" port ] [abs_path [ "?" query]]
The optional fields are enclosed in brackets. The host field should be the human-readable name of a host rather than a binary IP address (Section 18.8). The client (often a browser) determines the server location by obtaining the IP address of the specified host. If the URL does not specify a port, the client assumes port 80. The abs_path field refers to a path that is relative to the web root directory of the server. The optional query is not discussed here.
Example 19.2.
The URL http://www.usp.cs.utsa.edu:8080/usp/simple.html specifies that the server for the resource is listening on port 8080 rather than default port 80. The URL’s absolute path is /usp/simple.html.
When a user opens a URL through a browser, the browser parses the server’s host name and makes a TCP connection to that host on the specified port. The browser then sends a request to the server for the resource, as designated by the URL’s absolute path using the HTTP protocol described in the next section.
Example 19.3.
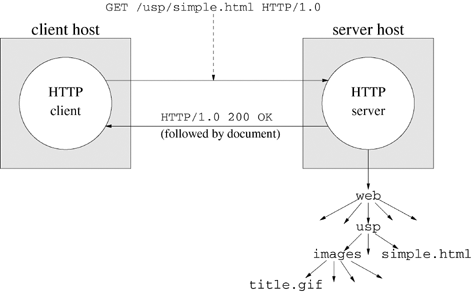
Figure 19.1 shows the location of a typical web server root directory (web) in the host file system. Only the part of the file system below the web directory root is visible and accessible through the web server. If the host name is www.usp.cs.utsa.edu, the image title.gif has the URL http://www.usp.cs.utsa.edu/usp/images/title.gif.

Figure 19.1. The root directory for the web server running on this host is /web. Only the boxed subtree is accessible through the Web.
The specification of a resource location with a URL ties it to a particular server. If the resource moves, web pages that refer to the resource are left with bad links. The Uniform Resource Name (URN) gives more permanence to resource names than does the URL alone. The owner of a resource registers its URN and the location of the resource with a service. If the resource moves, the owner just updates the entry with the registration service. URNs are not in wide use at this time. Both URLs and URNs are examples of Uniform Resource Identifiers (URIs). Uniform Resource Identifiers are formatted strings that identify a resource by name, location or other characteristics.
Clients and web servers have a specific set of rules, or protocol, for exchanging information called Hyper Text Transfer Protocol (HTTP). HTTP is a request-reply protocol that assumes that messages are delivered reliably. For this reason, HTTP communication usually uses TCP, and that is what we assume in this discussion. We also restrict our initial discussion to HTTP 1.0 [53].
Figure 19.2 presents a schematic of a simple HTTP transaction. The client sends a request (e.g., a message that starts with the word GET). The server parses the message and responds with the status and possibly a copy of the requested resource.
HTTP client requests begin with an initial line that specifies the kind of request being made, the location of the resource and the version of HTTP being used. The initial line ends with a carriage return followed by a line feed. In the following, <CRLF> denotes a carriage return followed by a line feed, and <SP> represents a white space character. A white space character is either a blank or tab.
Example 19.4.
The following HTTP 1.0 client request asks a server for the resource /usp/simple.html.
GET <SP> /usp/simple.html <SP> HTTP/1.0 <CRLF> User-Agent:uiciclient <CRLF> <CRLF>
The first or initial line of HTTP client requests has the following format.
Method <SP> Request-URI <SP> HTTP-Version <CRLF>
Method is usually GET, but other client methods include POST and HEAD.
The second line of the request in Example 19.4 is an example of a header line or header field. These lines convey additional information to the server about the request. Header lines are of the following form.
Field-Name:Field-Value <CRLF>
The last line of the request is empty. That is, the last header line just contains a carriage return and a line feed, telling the server that the request is complete. Notice that the HTTP request of Example 19.4 does not explicitly contain a server host name. The request of Example 19.4 might have been generated by a user opening the URL http://www.usp.cs.utsa.edu/usp/simple.html in a browser. The browser parses the URL into a server location www.usp.cs.utsa.edu and a location within that server /usp/simple.html. The browser then opens a TCP connection to port 80 of the server www.usp.cs.utsa.edu and sends the message of Example 19.4.
A web server responds to a client HTTP request by sending a status line, followed by any number of optional header lines, followed by an empty line containing just <CRLF>. The server then may send a resource. The status line has the following format.
HTTP-Version <SP> Status-Code <SP> Reason-Phrase <CRLF>
Table 19.1 summarizes the status codes, which are organized into groups by the first digit.
Table 19.1. Common status codes returned by HTTP servers.
code | category | description |
|---|---|---|
| informational | reserved for future use |
| success | successful request |
| redirection | additional action must be taken (e.g., object has moved) |
| client error | bad syntax or other request error |
| server error | server failed to satisfy apparently valid request |
Example 19.5.
When the request of Example 19.4 is sent to www.usp.cs.utsa.edu, the web server running on port 80 might respond with the following status line.
HTTP/1.0 <SP> 200 <SP> OK <CRLF>
After sending any additional header lines and an empty line to mark the end of the header, the server sends the contents of the requested file.
HTTP presumes reliable transport of messages (in order, error-free), usually achieved by the use of TCP. Figure 19.3 shows the steps for the exchange between client and server, using a TCP connection. The server listens on a well-known port (e.g., 80) for a connection request. The client establishes a connection and sends a GET request. The server responds and closes the connection. HTTP 1.0 allows only a single request on a connection, so the client can detect the end of the sending of the resource by the remote closing of the connection. HTTP 1.1 allows the client to pipeline multiple requests on a single connection, requiring the server to send resource length information as part of the response.

Example 19.6.
How could you use Program 18.5 (client2) on page 629 to access the web server that is running on www.usp.cs.utsa.edu?
Answer:
Start client2 with the following command.
client2 www.usp.cs.utsa.edu 80
Type the HTTP request of Example 19.4 at the keyboard. The third line of the request is just an empty line. The host www.usp.cs.utsa.edu runs a web server that listens on port 80. The server interprets the message as an HTTP request and responds. The server then closes the connection.
Example 19.7.
What message does client2 send to the host when you enter an empty line?
Answer:
The client2 program sends a single byte, the line feed character with ASCII code 10 (the newline character).
Example 19.8.
Why does the web server still respond if you enter only a line feed and not a <CRLF> for the empty line?
Answer:
Although the HTTP specification [53] says that request lines should be terminated by <CRLF>, it also recommends that applications (clients and servers) be tolerant in parsing. Specifically, HTTP parsers should recognize a simple line feed as a line terminator and ignore the leading carriage return. It also recommends that parsers allow any number of space or tab characters between fields. Almost all web servers and browsers follow these guidelines.
Example 19.9.
Run Program 18.5 in the same way as in Exercise 19.6, but enter the following.
GET <SP> /usp/badref.html <SP> HTTP/1.0 <CRLF> <CRLF>
What happens?
Answer:
The server responds with the following initial line.
HTTP/1.1 <SP> 404 <SP> Not <SP> Found <CRLF>
The server response may contain additional header lines before the blank line marking the end of the header. After sending the header, the server closes the connection. Note that the server is using HTTP version 1.1, but it sends a response that can be understood by the client, which is using HTTP version 1.0.
Example 19.10.
Run Program 18.5, using the following command to redirect the client’s standard output to t.out.
client2 www.usp.cs.utsa.edu 80 > t.out
Enter the following at standard input of the client. What will t.out contain?
GET <SP> /usp/images/title.gif <SP> HTTP/1.0 <CRLF> <CRLF>
Answer:
The t.out contains the server response, which consists of an ASCII header followed by a binary file representing an image. You can view the file by first removing the header and then opening the result in your browser. Use the UNIX more command to see how many header lines are there. If the file has 10 lines, use the following command to save the resources.
tail +11 t.out > t.gif
You can then use your web browser to display the result.
To summarize, an HTTP transaction consists of the following components.
An initial line (
GET,HEADorPOSTfor clients and a status line for servers).Zero or more header lines (giving additional information).
A blank line (contains only
<CRLF>).An optional message body. For the server response, the message body is the requested item, which could be binary.
The initial and header lines are tokenized ASCII separated by linear white space (tabs and spaces).
According to HTTP terminology [133], a client is an application that establishes a connection, and a server is an application that accepts connections and responds. A user agent is a client that initiates a request for service. Your browser is both a client and a user agent according to this terminology.
The origin server is the server that has the resource. Figure 19.2 on page 661 shows communication between a client and an origin server. In the current incarnation of the World Wide Web, firewalls, proxy servers and content distribution networks have changed the topology of client-server interaction. Communication between the user agent and the origin server often takes place through one or more intermediaries. This section covers four fundamental building blocks of this more complex topology: tunnels, proxies, caches and gateways.
A tunnel is an intermediary that acts as a blind relay. Tunnels do not parse HTTP, but forward it to the server. Figure 19.4 shows communication between a user agent and an origin server with an intermediate tunnel.

The tunnel of Figure 19.4 accepts an HTTP connection from a client and establishes a connection to the server. In this scenario, the tunnel acts both as a client and as a server according to the HTTP definition, although it is neither a user agent nor an origin server. The tunnel forwards the information from the client to the server. When the server responds, the tunnel forwards the response to the client. The tunnel detects closing of connections by either the client or server and closes the other end. After closing both ends, the tunnel ceases to exist. The tunnel of Figure 19.4 always connects to the web server running on the host www.usp.cs.utsa.edu.
Sometimes a tunnel does not establish its own connections but is created by another entity such as a firewall or gateway after the connections are established. Figure 19.5 illustrates one such situation in which a client connects to www.usp.cs.utsa.edu, a host running outside of a firewall. The firewall software creates a tunnel for the connection to a machine usp.cs.utsa.edu that is behind the firewall. Clients behind the firewall connect directly to usp.cs.utsa.edu, but usp is not visible outside of the firewall. As far as the client is concerned, the content is on the machine www.usp.cs.utsa.edu. The client knows nothing of usp.cs.utsa.edu.

A proxy is an intermediary between clients and servers that makes requests on behalf of its clients. Proxies are addressed by a special form of the GET request and must parse HTTP. Like tunnels, proxies act both as clients and servers. However, a proxy is generally long-lived and often acts as an intermediary for many clients. Figure 19.6 shows an example in which a browser has set its proxy to org.proxy.net. The HTTP client (e.g., a browser) makes a connection to the HTTP proxy (e.g., org.proxy.net) and writes its HTTP request. The HTTP proxy parses the request and makes a separate connection to the HTTP origin server (e.g., www.usp.cs.utsa.edu). When the origin server responds, the HTTP proxy copies the response on the channel connected to the HTTP client.

The GET request of Example 19.4 uses an absolute path to specify the resource location. Clients use an alternative form, the absolute URI, when directing requests to a proxy. The absolute URI contains the full HTTP address of the destination server. In Figure 19.6, the http://www.usp.cs.utsa.edu/usp/simple.html is an absolute URI; /usp/simple.html is an absolute path.
Example 19.11.
This HTTP request contains an absolute URI rather than an absolute path.
GET <SP> http://www.usp.cs.utsa.edu/usp/simple.html <SP> HTTP/1.0 <CRLF> User-Agent:uiciclient <CRLF> <CRLF>
The proxy server parses the GET line and initiates an HTTP request to www.usp.cs.utsa.edu for the resource /usp/simple.html.
When directing a request through a proxy, user agents use the absolute URI form of the GET request and connect to the proxy rather than directly to the origin server. When a server receives a GET request containing an absolute URI, it knows that it should act as a proxy rather than as the origin server. The proxy reconstructs the GET line so that it contains an absolute path, such as the one shown in Example 19.4, and makes the connection to the origin server. Often, the proxy adds additional header lines to the request. The proxy itself can use another proxy, in which case it forwards the original GET to its designated proxy. Most browsers allow a user option of setting a proxy rather than connecting directly to the origin server. Once set up, the browser’s operation with a proxy is transparent to the user, other than a performance improvement or degradation.
A transparent proxy is one that does not modify requests or responses beyond what is needed for proxy identification and authentication. Nontransparent proxies may perform many other types of services on behalf of their clients (e.g., annotation, anonymity filtering, content filtering, censorship, media conversion). Proxies may keep statistics and other information about their clients. Search engines such as Google are proxies of a different sort, caching information about the content of pages along with the URLs. Users access the cached information by keywords or phrases. Clients that use proxies assume that the proxies are correct and trustworthy.
The most important service that proxies perform on behalf of clients is caching. A cache is a local store of response messages. Browsers usually cache recent response messages on disk. When a user opens a URL, the browser checks first to see if the resource can be found on disk and only initiates a network request if it didn’t find the object locally.
Example 19.12.
Examine the current settings and contents of the cache on your browser. Different browsers allow access to this information in different ways. The local cache and proxies are accessible under the Advanced option of the Preferences submenu on the Edit menu in Netscape 6. In Internet Explorer 6, you can access the information from the Internet Options submenu under the Tools menu. The cache is designated under Temporary Internet Files on the General menu. Proxies are designed under LAN Settings on the Connections submenu of Internet Options. Look at the files in the directory that holds your local browser cache. Your browser should offer an option for clearing the local cache. Use the option to clear your local cache, and examine the directory again. What is the effect? Why does the browser keep a local cache and how does the browser use this cache?
Answer:
Clearing the cache should remove the contents of the local cache directory. When the user opens a page in the browser, the browser first checks the local disk for the requested object. If the requested object is in the local cache, the browser can retrieve it locally and avoid a network transfer. Browsers use local caches to speed access and reduce network traffic.
A proxy cache stores resources that it fetches in order to more effectively service future requests for those resources. When the proxy cache receives a request for an object from a client, it first checks its local store of objects. If the object is found in the proxy’s local cache (Figure 19.7), the proxy can retrieve the object locally rather than by transferring it from the origin server.

If the proxy cache does not find an object in its local store (Figure 19.8), it retrieves the object from the origin server and decides whether to save it locally. Some objects contain headers indicating they cannot be cached. The proxy may also decide not to cache an object for other reasons, for example, because the object is too large to cache or because the proxy does not want to remove other, frequently accessed, objects from its cache.

Figure 19.8. When a proxy cannot locate a requested resource locally, it requests the object from the origin server and may elect to add the object to its local cache.
Often, proxy caches are installed at the gateways to local area networks. Clients on the local network direct all their requests through the proxy. The objects in the proxy cache’s local store are responses to requests from many different users. If someone else has already requested the object and the proxy has cached the object, the response to the current request will be much faster.
You are probably wondering what happens if the object has changed since the cache stored the object. In this case, the proxy may return an object that is out-of-date, or stale, a situation that can be mitigated by expiration strategies. Origin servers often provide an expiration time as part of the response header. Proxy caches also use expiration policies to keep old objects from being cached indefinitely. Finally, the proxy (or any client) can execute a conditional GET by including an If-Modified-Since field as a header line. The server only returns objects that have changed since the specified modification date. Otherwise, the server returns a 304 Not Modified response, and the proxy can use the copy from its cache.
While a proxy can be viewed as a client-side intermediary, a gateway is a server-side mechanism. A gateway receives requests as though it is an origin server. A gateway may be located at the boundary router for a local area network or outside a firewall protecting an intranet. Gateways provide a variety of services such as security, translation and load balancing. A gateway might be used as the common interface to a cluster of web servers for an organization or as a front-end portal to a web server that is behind a firewall.
Figure 19.9 shows an example of how a gateway might be configured to provide a common access point to resources inside and outside a firewall. The server www.usp.cs.utsa.edu acts as a gateway for usp.cs.utsa.edu, a server that is behind the firewall. If a GET request accesses a resource in the usp directory, the gateway creates a tunnel to usp.cs.utsa.edu. For other resources, the gateway creates a tunnel to the www.cs.utsa.edu server outside the firewall.
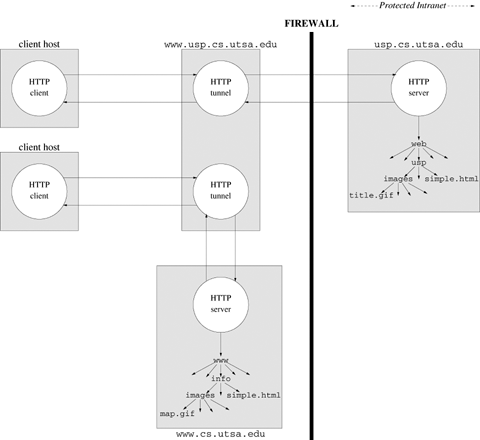
Figure 19.9. The server www.usp.cs.utsa.edu acts as a gateway for servers inside and outside the firewall.
Example 19.13.
How does a gateway differ from a tunnel?
Answer:
A tunnel is a conduit that passes information from one point to another without change. A gateway acts as a front end for a resource, perhaps a cluster of servers.
This chapter explores various aspects of tunnels, proxies and gateways. Sections 19.5 and 19.6 guide you through the implementation of a tunnel that might be used in a firewall. Section 19.7 describes a driver for testing the programs. Section 19.8 discusses the HTTP parsing needed for the proxy servers. Sections 19.9 and 19.10 describe a proxy server that monitors the traffic generated by the browsers that use it. Sections 19.12 and 19.13 explore the use of gateways for firewalls and load balancing, respectively.
This section describes an implementation of a simple pass-through monitor, passmonitor, similar to the tunnel illustrated in Figure 19.4. The passmonitor program takes its listening port number, the destination web server host name and an optional destination web server port number as command-line arguments. If the last argument is omitted, passmonitor assumes that the destination web server uses port 80. The monitor listens at the specified port for TCP connection requests (using the UICI u_accept function). When it accepts a client connection, passmonitor initiates a TCP connection to the destination server (using u_connect) and calls the tunnel function described below. After control returns from tunnel, passmonitor resumes listening for another client connection request.
The tunnel function, which handles one session between a client and the origin server, has the following prototype.
int tunnel(int clientfd, int serverfd);
Here, clientfd is the open file descriptor returned after acceptance of the client’s connection request. The serverfd parameter is an open file descriptor for a TCP connection between the monitor and the destination server. The tunnel function forwards all messages received from clientfd to serverfd, and vice versa. If either the client or the destination server closes a connection (clientfd or serverfd, respectively), tunnel closes its connections and returns the total number of bytes that were forwarded in both directions.
After control returns from tunnel, passmonitor writes status information to standard error, reporting the total number of bytes written for this communication and the time the communication took. The monitor then resumes listening for another client connection request.
To correctly implement passmonitor, you cannot assume that the client and the server strictly alternate responses. The passmonitor program reads from two sources (the client and the server) and must allow for the possibility that either could send next. Use select or poll as in Program 4.13 to monitor the two file descriptors. A simple implementation of tunnel is given in Example 19.14. Be sure to handle all errors returned by library functions. Under what circumstances should passmonitor exit? What other strategies should passmonitor use when errors occur?
Example 19.14.
The tunnel function can easily be implemented in terms of the copy2files function of Program 4.13 on page 111.
int tunnel(int fd1, int fd2) {
int bytescopied;
bytescopied = copy2files(fd1, fd2, fd2, fd1);
close(fd1);
close(fd2);
return bytescopied;
}
Recall that copy2files returns if either side closes a file descriptor.
Example 19.15.
Use Program 18.5 on page 629 to test passmonitor by having it connect to web servers through passmonitor. Why doesn’t passmonitor have to parse the client’s request before forwarding it to the destination server?
Answer:
The passmonitor program uses only the destination server that is passed to it on the command line.
Example 19.16.
Suppose you start passmonitor on machine os1.cs.utsa.edu with the following command.
passmonitor 15000 www.usp.cs.utsa.edu
Start client2 on another machine with the following command.
client2 os1.cs.utsa.edu 15000
If you then enter the following request (on client2), the passmonitor sends the request to port 80 of www.usp.cs.utsa.edu.
GET <SP> /usp/simple.html <SP> HTTP/1.0 <CRLF> User-Agent:uiciclient <CRLF> <CRLF>
How does the reply differ from the one received by having client2 connect directly as in Example 19.4?
Answer:
The replies should be the same in the two cases if passmonitor is correct.
Example 19.17.
Test passmonitor by using a web browser as the client. Start passmonitor as in Exercise 19.16. To access /usp/simple.html, open the URL as follows.
http://os1.cs.utsa.edu:15000/usp/simple.html
Notice that the browser treats the host on which passmonitor is running as the origin server with port number 15000. What happens when you don’t specify a port number in the URL?
Answer:
The browser makes the connection to port 80 of the host running passmonitor.
Example 19.18.
Suppose that you are using a browser and have started passmonitor as in Exercise 19.16. What series of connections are initiated when you open the URL as specified in Exercise 19.17?
Answer:
Your browser makes a connection to port 15000 on os1.cs.utsa.edu and sends a request similar to the one in Example 19.4 on page 660. The passmonitor program receives the request, establishes a connection to port 80 on www.usp.cs.utsa.edu, and forwards the browser’s request. The passmonitor program returns www.usp.cs.utsa.edu’s response to the browser and closes the connections.
A tunnel is a blind relay that ceases to exist when both ends of a connection are closed. The passmonitor program of Section 19.5 is technically not a tunnel because it resumes listening for another connection request after closing its connections to the client and the destination server. It acts as a server for the tunnel function. One limitation of passmonitor is that it handles only one communication at a time.
Modify the passmonitor program of Section 19.5 to fork a child to handle the communication. The child should call the tunnel function and print to standard output a message containing the total number of bytes written. Call the new program tunnelserver.
The parent, which you can base on Program 18.2 on page 623, should clean up zombies by calling waitpid with the WNOHANG option and resume listening for additional requests.
Modify Program 18.3 (client) on page 624 to create a test program for the tunnelserver program and call it servertester. The test program should take four command-line arguments: the tunnel server host name, the tunnel server port number, the number of children to fork and the number of requests each child should make. The parent process forks the specified number of children and then waits for them to exit. Wait for the children by calling wait(NULL) a number of times equal to the number of children created. (See, for example, Example 3.15 on page 73.) Each child executes the testhttp function described below and examines its return value. The testhttp function has the following prototype.
int testhttp(char *host, int port, int numTimes);
The testhttp function executes the following in a loop for numTimes times.
Make a connection to
hostonport(e.g.,u_connect).Write the
REQUESTstring to the connection.REQUESTis a string constant containing the three lines of aGETrequest similar to that of Example 19.4 on page 660. Use aREQUESTstring appropriate for the host you plan to connect to.Read from the connection until the remote end closes the connection or until an error occurs. Keep track of the total number of bytes read from this connection.
Close the connection.
Add the number of bytes to the overall total.
If successful, testhttp returns the total number of bytes read from the network. If unsuccessful, testhttp returns –1 and sets errno.
Begin by writing a simple version of servertester that calls testhttp with numTimes equal to 1 and saves and prints the number of bytes corresponding to one request.
After you have debugged the single request case, modify servertester to fork children after the first call to testhttp. Each child calls testhttp and displays an error message if the number of bytes returned is not numTimes times the number returned by the call made by the original parent process.
Add statements in the main program to read the time before the first fork and after the last child has been waited for. Output the difference in these times. Make sure there is no output to the screen between the two statements that read the time. Use conditional compilation to include or not include the print statements of tunnelserver. The tunnelserver program should not produce any output after its initial startup unless an error occurs.
Start testing servertester by directly accessing a web server. For example, access www.usp.cs.utsa.edu, using the following command to estimate how long it takes to directly access the web server.
servertester www.usp.cs.utsa.edu 80 10 20
Then, do some production runs of tunnelserver and compare the times. You can also run servertester on multiple machines to generate a heavier load.
Example 19.21.
Suppose, as in Exercise 19.19, that tunnelserver was started on port 15002 of host os1.cs.utsa.edu to service the web server www.usp.cs.utsa.edu on port 8080. How would you start servertester to make 20 requests from each of 10 children?
Answer:
servertester os1.cs.utsa.edu 15002 10 20
Example 19.22.
How do you expect the elapsed time for servertester to complete in Exercise 19.21 to compare with that of directly accessing the origin server?
Answer:
If both programs are run under the same conditions, Exercise 19.21 should take longer. The difference in time is an indication of the overhead incurred by going through the tunnel.
In contrast to tunnels, proxies and gateways are party to the HTTP communication and must parse at least the initial line of the client request. This section discusses a parse function that parses the initial request line. The parse function has the following prototype.
int parse(char *inlin, char **commandp, char **serverp,
char **pathp, char **protocolp, char **portp);
The inlin parameter should contain the initial line represented as an array terminated by a line feed. Do not assume in your implementation of parse that inlin is a string, because it may not have a string terminator. The parse function parses inlin in place so that no additional memory needs to be allocated or freed.
The parse function returns 1 if the initial line contains exactly three tokens, or 0 otherwise. On a return of 1, parse sets the last five parameters to strings representing the command, server, path, protocol and port, respectively. These strings should not contain any blanks, tabs, carriage returns or line feeds.
The server and port pointers may be NULL. If an absolute path rather than an absolute URI is given, the server pointer is NULL. If the optional port number is not given, the port pointer is NULL. Allow any number of blanks or tabs at the start of inlin, between tokens, or after the last token. The inlin buffer may have an optional carriage return right before the line feed.
Example 19.23.
Figure 19.10 shows the result of calling parse on a line containing an absolute path form of the URI. The line has two blanks after GET and two blanks after the path. The carriage return and line feed directly follow the protocol. The parse function sets the first blank after GET and the first blank after the path to the null character (i.e., '�'). The parse function also replaces the carriage return by the null character. The NULL value of the *serverp parameter signifies that no host name was present in the initial inlin, and the NULL value of *portp signifies that no port number was specified.

Example 19.24.
Figure 19.11 shows the result of parse for a line that contains an absolute URI distinguished by the leading http:// after GET. Notice that parse moves the host name one character to the left so that it can insert a null character between the host name and the path. There is always room to do this, since the leading http:// is no longer needed.
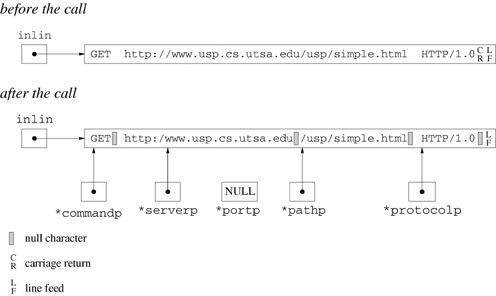
Figure 19.11. The parse function parses the absolute URI form of the initial line by moving the server name to the left.
Implement parse in stages. Start by skipping the leading blanks and tabs, and check that there are exactly three tokens before the first line feed. If inlin does not have exactly three tokens, return 0. Then break these tokens into three strings, setting the command, path and protocol pointers. Consider the second token to be an absolute URI if it starts with http:// and contains at least one additional / character. The server and port pointers should be set to NULL. After successful testing, handle the server pointer. When this is working, check for the port number.
You should write the code to break the input line into strings yourself. Do not use strtok, since it is not thread-safe. Be careful not to assume that the input line is terminated by a string terminator. Do not modify any memory before or after the input line. Test parse by writing a simple driver program. Remember not to assume that the first parameter to parse is a string.
This section describes a modification of the tunnelserver program of Section 19.6 so that it acts like a proxy rather than a tunnel. A proxy must parse the initial request line (unless the proxy happens to be using a proxy, too).
Example 19.25.
When a proxy server receives the following GET line, it knows that it is to act as a proxy because the absolute URI form of the request is given.
GET http://www.usp.cs.utsa.edu/usp/simple.html HTTP/1.0
The proxy knows that the origin server is www.usp.cs.utsa.edu and replaces the initial line with the following initial line.
GET /usp/simple.html HTTP/1.0
The proxy then makes a connection to port 80 of www.usp.cs.utsa.edu.
Make a new directory with a copy of the files for tunnelserver of Section 19.6. Rename tunnelserver to proxyserver. The proxyserver program takes a single command-line argument, the port number at which it listens for requests. The proxyserver program does not need the destination web server as a command-line argument because it parses the initial HTTP request from the client, as in Example 19.25. Write a processproxy function that has the following prototype.
int processproxy(int clientfd);
The clientfd parameter is the file descriptor returned when the server accepts the client’s connection request.
The processproxy function reads in the first line from clientfd and calls parse to parse the initial request. If parse is successful and the line contains an absolute URI (the server pointer is not NULL), processproxy establishes a connection to the destination server. Then processproxy writes to the destination server an initial line containing a command with an absolute path and calls the tunnel function to continue the communication. If the port parameter of parse is not NULL, use the indicated port. Otherwise use port 80.
If successful, processproxy returns the total number of bytes transferred, which is the return value from tunnel plus the length of the initial line read from the client and the corresponding line sent to the server. If unsuccessful, processproxy returns –1 and sets errno.
Assume a maximum line length of 4096 bytes for the initial command from the client so that you need not do dynamic memory allocation. This means that a longer request is considered invalid, but you must not let a long request overflow the buffer. To read the first line from the client, you must read one byte at a time until you get a newline.
If parse returns an error, processproxy should treat the connection request as an error. In this case, processproxy writes the following message on clientfd, closes the connection, and returns –1 with errno set.
HTTP/1.0 <SP> 400 <SP> Bad <SP> Request <CRLF> <CRLF>
The proxyserver program listens for connection requests on the given port, and for each request it forks a child that calls processproxy and prints the number of bytes transferred.
Copy your servertester.c into proxytester.c and modify the request to contain an absolute URI instead of an absolute path. Use proxytester to test proxyserver.
Example 19.26.
How would you test proxyserver through your browser?
Answer:
Set your browser to use proxyserver as its proxy. Suppose that proxyserver is running on machine os1.cs.utsa.edu using port 15000. Set your browser proxy to be os1.cs.utsa.edu on port number 15000. You should be able to use your browser with no noticeable difference.
Make a copy of proxyserver from Section 19.9 and call it proxymonitor. Modify proxymonitor to take an optional command-line argument, pathname, giving the name of a log file. All header traffic and additional information should be dumped to this file in a useful format. Modify processproxy to take an additional parameter, the name of the log file. Do no logging if this additional parameter is NULL. Log the following information.
Client host name and destination host name
Process ID of the process running
processproxyInitial request line from the client to the proxy
Initial request line sent by the proxy to the server
All additional header lines from the client
All additional header lines from the server
The following byte counts
Length of the initial request from the client
Length of the initial request from the proxy
Length of the additional header lines from the client
Length of the additional header lines from the server
Number of additional bytes sent by the server
Number of additional bytes sent by the client
Total number of bytes sent from the client to the proxy
Total number of bytes sent from the proxy to the server
Total number of bytes sent from the server to the proxy
All this information should be stored in a convenient readable format. All header lines should be labeled to indicate their source. Logging must be done atomically so that the log produced by one child running processproxy is not interleaved with another. You can do this by opening the log file with the O_APPEND flag and doing all logging with a single call to write. A simpler way would be to use the atomic logging facility described in Section 4.9. Section D.1 provides the complete code for this facility.
You will not be able to use tunnel for your implementation because sometimes proxymonitor reads lines and sometimes it reads binary content that is not line oriented. After sending the initial request to the host, as in the proxyserver, the client sends line-oriented data that the proxy logs until the client sends a blank line. The client may then send arbitrary data until the connection is closed. The proxymonitor needs to log only the number of bytes of this additional data. Similarly, the server sends line-oriented header information that proxymonitor logs until the server sends a blank line. The server may then send arbitrary data until the connection is closed, but the proxymonitor logs only the number of bytes the server sent for this portion.
Example 19.27.
What is wrong with the following strategy for implementing proxymonitor?
Read the initial header line from the client and send the corresponding line to the server (as in the
proxyserver).Read, log and send client header lines until encountering a blank line.
Read, log and send server header lines until encountering a blank line.
Handle binary data between the client and the server as in
tunnel, keeping track of the number of bytes sent in each direction for logging.
Answer:
This should work for GET and HEAD, but it will fail for POST. For a POST command, the client sends its content before the server sends back a header, so the process blocks while waiting for the server header when in fact it should be reading the client content.
One method of implementing proxymonitor is to keep track of the states of the client and server. Each sends headers until a blank line and then sends content. Use select to determine which descriptor is ready and then process either a header line or content, depending on the state of the source. If proxymonitor encounters a blank header line, it changes the state of the respective client or server from header to content.
Example 19.28.
What happens if several copies of proxymonitor run concurrently using the same log file?
Answer:
As long as the different copies run on different ports, there should not be a problem, provided that logging is atomic. In this case, you might also want to log the port number with each transaction.
Example 19.29.
Why don’t we log the total number of bytes sent from the proxy to the client?
Answer:
This should be the same as the total number of bytes sent from the server to the proxy.
Example 19.30.
The last three numbers logged are the byte totals for a given transaction. How would you keep track of and log the total number of bytes for each of these items for all transactions processed by proxymonitor?
Answer:
This requires some work, since the different transactions are handled by different processes. One possibility is to convert the program to use threads rather than children. The total could then be kept in global variables and updated by each thread. The routines to update these totals would have to be protected by a synchronization construct such as a semaphore or a mutex lock.
To do this without using threads, proxymonitor could create an additional child process to keep track of the totals. This process could communicate with the children by running processproxy with two pipes, one to send the new values to this process and one to receive the new totals from this process. Create the two pipes and this child before doing any other processing. The server processes can store the integers in a structure and output them to the pipe in raw form with a single write operation. You need not worry about byte ordering, since the communication is on the same machine. You still need to worry about synchronization to guarantee that the totals received by the children include the values of the current transaction.
Example 19.31.
Explain the last sentence of the answer to the previous exercise.
Answer:
Suppose we keep track of only one number. The child running processproxy sends the number corresponding to a transaction on one pipe and then reads the new total on the other pipe. Consider the case in which the proxy has just started up and so the current total is 1000. Child A is running a small transaction of 100 bytes, and child B is running a larger transaction of 100,000 bytes. Child A sends 100 on the first pipe and reads the new total on the second pipe. Child B sends 100,000 on the first pipe and reads the new total on the second pipe. If the sending and receiving for each process is not done atomically, The following ordering is possible.
Child A sends 100 on the first pipe.
1100 (the new total) is written to the second pipe.
Child B sends 100,000 on the first pipe.
101,100 (the new total) is written to the second pipe.
Child B reads 1100 from the second pipe.
Child A reads 101,100 from the second pipe.
At this pipe, Child B will have completed a transaction of 100,000 bytes and report that the total so far (including this transaction) is 1100 bytes. To fix this problem, make the writing to the first pipe and the reading from the second pipe be atomic. You can do this by using a POSIX:XSI semaphore set shared by all the child processes.
Proxy caches save resources in local storage so that requests can be satisfied locally. The cache can be in memory or on disk.
Starting with the proxymonitor of Section 19.10, write a program called proxycache that stores all the resources from the remote hosts on disk. Each unique resource must be stored in a unique file. One way to do this is to use sequential file names like cache00001, cache00002, etc., and keep a list containing host name, resource name and filename. Most proxy implementations use some type of hashing or digest mechanism to efficiently represent and search the contents of the cache for a particular resource.
Start by just storing the resources without modifying the communication. If the same resource is requested again, update the stored value rather than create a new entry. Keep track of the number of hits on each resource.
The child processes must coordinate their access to the list of resources, and they must coordinate the generation of unique file names. Consider using threads, shared memory or message passing to implement the coordination.
Once you have the coordination working, implement the code to satisfy requests for cached items locally. Keep track of the total number of bytes transferred from client to proxy, proxy to server, server to proxy and proxy to client. Now the last two of these should be different. Remember that when you are testing with a browser, the browser also does caching, so some requests will not even go to the proxy server. Either turn off the browser’s caching or force a remote access in the browser (usually by holding down the SHIFT key and pressing reload or refresh).
Real proxy caches need to contend with a number of issues.
Real caches are not infinite.
Caches should not store items above a certain size. The optimal size may vary dynamically with cache content.
The cache should have an expiration policy so that resources do not stay in the cache forever.
The cache should respect directives from the server stating that certain items should not be cached.
The cache should check whether an item has been modified before using a local copy.
How many of the above issues can you resolve in your implementation? What else could be added to this list?
A gateway receives requests as though it were the origin server and acts as an intermediary for other servers. This section discusses a server program, gatewayportal, which implements a gateway as shown in Figure 19.9. In this configuration, gatewayportal directs certain requests to a web server that is inside a firewall and directs the remaining requests to a server outside the firewall. The gatewayportal program has three command-line arguments: the port number that it listens on, the default server host name and the default server port number. Start by copying proxyserver.c of Section 19.9 to gatewayportal.c. The gatewayportal program parses the initial line. If the line contains an absolute URI, gatewayportal returns an HTTP error response to the client. If the absolute path of the initial line is for a resource that starts with /usp, then gatewayportal creates a tunnel to www.usp.cs.utsa.edu. The gatewayportal program directs all other requests to the default server through another tunnel.
This section describes a gateway, called gatewaymonitor, used for load balancing. Start with tunnelserver of Section 19.6. The gatewaymonitor program takes two ports as command-line arguments: a listening port for client requests and a listening port for server registration requests. The gatewaymonitor program acts like tunnelserver of Section 19.6 except that instead of directing all requests to a particular server, it maintains a list of servers with identical resources and can direct the request to any of those servers. The gatewaymonitor program keeps track of how many requests it has directed to each of the servers. If a connection request to a particular server fails, gatewaymonitor outputs an error message to standard error, reporting which server failed and providing usage statistics for that server. The gatewaymonitor program removes the failed server from its list and sends the request to another server. If the server list is empty, gatewaymonitor sends an HTTP error message back to the client.
A server can add itself to gatewaymonitor’s list of servers by making a connection request to the server listening port of gatewaymonitor. The server then registers itself by sending its host name and its request listening port number. The gatewaymonitor program monitors the client listening port as before but also monitors the server request listening port. (Use select here.) If a request comes in on the server listening port, gatewaymonitor accepts the connection, reads the port information from the server, adds the host and port number to the server list, and closes the connection. The server should send the port number as a string to avoid byte-ordering problems.
Write a server program called registerserver that registers a server with gatewaymonitor as described above. The registerserver takes three or four command-line arguments. The first two arguments are the host name and server registration port number of the gatewaymonitor. The third parameter is the port number that the registered server will listen on for client requests. The optional fourth command-line argument is the name of a host to register. When called with four command-line arguments, registerserver exits after registering the specified host. The four-argument version of registerserver can be used to register an existing web server. If only three command-line arguments are given, registerserver registers itself and waits for requests.
The registerserver should have a canned HTTP response (with a resource) to send in response to all requests. The host name and process ID should be embedded in the resource so that you can tell how the request to the gateway monitor was serviced. Test your program by using a browser with as many as five servers registering with the gateway. Kill various servers and make sure that gatewaymonitor responds correctly.
This section describes common pitfalls and mistakes that we have observed in student implementations of the servers described in this chapter.
Most timing errors for this type of program result from an incorrect understanding of TCP. Do not assume that an entire request can be read in a single read, even if you provide a large enough buffer. TCP provides an abstraction of a stream of bytes without packet or message boundaries. You have no control over how much will be delivered in a single read operation because the amount depends on how the message was encapsulated into packets and how those packets were delivered through an unreliable channel. Unfortunately, a program that makes this assumption works most of the time when tested on a fast local area network.
Whether writing a tunnel, proxy or gateway, do not assume that a client first sends its entire request and then the server responds. A program that reads from the client until it detects the end of the HTTP request does not follow the specification. Your program should simultaneously monitor the incoming file descriptors for both the client and the origin server. (See Sections 12.1 and 12.2 for approaches to do this.)
According to the specification, passmonitor should measure the time it takes to process each client request. How you approach this depends, to some extent, on your method of handling multiple file descriptors. In any case, do not measure the start time before the accept call because doing so incorporates an indefinite client “think” time. Do not measure the end time right after the fork call if you are using multiple processes, right after pthread_create if you are using multiple threads, or right after select if you are monitoring multiple descriptors in a single thread of execution. Why not?
Be sure that the time values you measure are reasonable. Most time-related library functions return seconds and milliseconds, seconds and microseconds, or seconds and nanoseconds. A common mistake is to confuse the units of the second element. Another common mistake is to subtract the start and end times without allowing for wrap-around. If you come out with a time value in days or months, you know that you made a mistake.
Do not use sleep to “cover up” incorrectly synchronized code. These programs should not need sleep to work correctly, and the presence of a sleep call in the code is a tip-off that something is seriously wrong.
Logging of headers also presents a timing problem. If you write one header line at a time to the log file, it is possible that headers for responses and requests will be interleaved. Accumulate each header in a buffer and write it by using a single write function when your program detects that the header is complete.
Do not connect to the destination web server in the tunnel programs before accepting a client connection. If you type fast enough during testing, you might not detect a problem. However, most web servers disconnect after a fairly short time when no incoming request appears.
If you did not seriously or correctly address how your servers react to errors and when they should exit, your running programs may represent a system threat, particularly if they run with heightened privileges.
A server usually should run until the system reboots, so think about exit strategies. Do not exit from any functions except the main function. In general, other functions should either handle the error or return an error code to the caller. Do not exit if the proxy fails to connect to the destination web server—the problem may be temporary or may just be for that particular server. In general, a client should not be able to cause a server to exit. The server should exit only if there is an unrecoverable error due to lack of resources (memory, descriptors, etc.) that would jeopardize future correct execution. Remember the Mars Pathfinder (see page 483)! For these programs, a server should exit only when it fails to create a socket for listening to client requests. You should think about what actions to take in other situations.
Programs in C continue to execute even when a library function returns an error, possibly causing a fatal and virtually untrackable error later in the execution. To avoid this type of problem, check the return value for every library function that can return an error.
Releasing resources is always important. In servers, it is critical. Close all appropriate file descriptors when the client communication is finished. If a function allocates buffers, be sure to free them somewhere. Check to see that resources are freed on all paths through each function, paying particular attention to what happens when an error occurs.
Decide when a function should output an error message as well as return an error code. Use conditional compilation to leave informational messages in the source without having them appear in the released application. Remember that in the real world those messages have to go somewhere—probably to some unfortunate console log. Write messages to standard error, not to standard output. Usually, standard error is redirected to a console log—where someone might actually read the message. Also, the system does not buffer standard error, so the message appears when the error occurs.
Most significant projects have an accompanying report or auxiliary documentation. Here are some things to think about in producing such a report.
Clean up the spelling and grammar. No one is going to believe that the code is debugged if the report isn’t. Using (and paying attention to) a grammar checker won’t make you a great writer, but it will help you avoid truly awful writing. Be consistent in your style, typeface, numbering scheme and use of bullets. Not only does this attention to detail result in a more visually pleasing report, but it helps readers who may use style as a cue to meaning. Put some thought into the layout and organization of your report. Use section titles and subsection titles to make the organization of the report clear. Use paragraph divisions that are consistent with meaning. If your report contains single-spaced paragraphs that are a third of a page or longer, you probably need more paragraphs or more conciseness. Avoid excessive use of code in the report. Use outlines, pseudocode or block diagrams to convey implementation details. If readers want to see code, they can look at the programs.
Pay attention to the introduction. Be sure that it has enough information for readers to understand the project. However, irrelevant information is sometimes worse than no information at all.
Diagrams are useful and can greatly improve the clarity of the presentation, but a diagram that conveys the wrong idea is worse than no diagram. Ask yourself what information you are trying to convey by the diagram, and distinguish that information with carefully chosen and consistent symbols. For example, don’t use the same style box to represent both a process and a port, or the same type of arrow to represent a connection request and a thread.
Use architectural diagrams to convey overall structure and differences in design. For example, if contrasting the implementations of the tunnel and the proxy, give separate architectural diagrams for each that are clearly distinct. Alternatively, you could give one diagram for both (not two copies of the same diagrams) and emphasize that the two implementations have the same communication structure but differ in other ways.
On your final pass, verify that the report agrees with the implementation. For example, you might describe a resource-naming scheme in the report and then modify it in the program during testing. It is easy to forget to change the documentation to reflect the modifications. Section 22.12 gives some additional discussion about technical reports.
Each of the tunnel and proxy programs should be tested in a controlled environment before being tested with browsers and web servers. Otherwise, you are contending with three linked systems, each with unknown behavior. This configuration is impossible to test in a meaningful way.
A good way to start is to test the tunnel programs with simple copying programs such as Programs 18.1 and 18.3 to be sure that tunnel correctly transfers all of the information. Be sure that ordinary and binary files are correctly transmitted for all versions. Testing that the program transmitted data is not the same as testing to see that it transmitted correctly. Use diff or other utilities to make sure that files were exactly transmitted.
Avoid random test syndrome by organizing the test cases before writing the programs. Think about what factors might affect program behavior—different types of web pages, different types of servers, different network connections, different times of day, etc., and clearly organize the tests.
State clearly in the report what tests were performed, what the results were, and what aspect of the program these tests were designed to exercise. The typical beginner’s approach to test reporting is to write a short paragraph saying the program worked and then append a large log file of test results to the report. A better approach might be to organize the test results into a table with annotations of the outcomes and a column with page numbers in the output so that the reader can actually find the tests.
Always record and state the conditions under which tests or performance experiments were run (machines, times of day, etc.). These factors may not appear to be important at the time, but you usually can’t go back later and reconstruct these details accurately. Include in your report an analysis of what you expected to happen and what actually did happen.
Well-written programs are always easier to debug and modify. If you try to produce clean code from the initial design, you will usually spend less time debugging.
Avoid large or inconsistent indentation—it generally makes complicated code difficult to follow. Also avoid big loops—use functions to reduce complexity. For example, parsing the GET line of an HTTP request should be done in a function and tested separately.
Don’t reinvent the wheel. Use libraries if available. Consolidate common code. For example, in the proxy, call the same function for each direction once the GET line is parsed. Do not assume that a header or other data will never exceed some arbitrary, predetermined size. It is best to include code to resize arrays (by realloc) when necessary. Be careful of memory leaks. Alternatively, you could use a fixed-size buffer and report longer requests as invalid. Be sure your buffer size is large enough. In no circumstance should you write past the end of an array. However, be cognizant of when a badly behaved program (e.g., a client that tries to write an infinitely long HTTP request) might cause trouble and be prepared to take appropriate action.
Always free allocated resources such as buffers, but don’t free them more than once because this can cause later allocations to fail. Good programming practice suggests setting the pointer argument of free to NULL after the call, since the free function ignores NULL pointers. Often, a function will correctly free a buffer or other resource when successful but will miss freeing it when certain error conditions occur.
Do not use numeric values for buffer sizes and other parameters within the program. Use predefined constants for default and initial values so that you know what they mean and only have to modify them in one place. Be careful about when to use a default value and when not to. Mistakes here can be difficult to detect during testing. For example, the absolute URL contains an optional port number. You should not assume port 80 if this optional number is present. Be sure that all command-line arguments meet their specifications.
Parsing the HTTP headers is quite difficult. If you implement robust parsing, you need to assume that lines can end in a carriage return followed by a line feed, by just a line feed, or by just a carriage return. The line feed is the same as the newline character. If you did this parsing inline in the main loop, you probably didn’t test parsing very well—how could you?
Headers in HTTP are in ASCII format, but resources may be in binary format. You will need to switch strategies in the middle of handling input.
You can obtain more information about current developments on the World Wide Web by visiting the web site of the World Wide Web Consortium (W3C) [132], an organization that serves as a forum for development of new standards and protocols for the Web. The Internet Engineering Task Force (IETF) [55] is an open community of researchers, engineers and network operators concerned with the evolution and smooth operation of the Internet. Many important architectural developments and network designs appear in some form as IETF RFCs (Request for Comments). The specifications of HTTP/1.0 [53] and HTTP/1.1 [54] are of particular interest for this project. Both W3C and IETF maintain extensive web sites with much technical documentation. An excellent general reference on networking and the Internet can be found in Computer Networking: A Top-Down Approach Featuring the Internet by Kurose and Ross [68]. Web Protocols and Practice: HTTP/1.1, Networking Protocols, Caching, and Traffic Measurement [66] gives a more technical discussion of web performance and HTTP/1.1. “The state of the art in locally distributed web-server systems,” by Cardellini et al. [21] reviews different architectures for web server clusters.