
Replication
To provide quick and efficient directory services to clients across the enterprise, clients should have the data that they require most frequently within close proximity. For example, to provide the same local directory services to clients in London as those needed locally by clients in Taipei, it is necessary to replicate the directory data between the DCs that provide those services. Understanding replication leads to a site and domain design that replicates efficiently enough to support the enterprise.
Multi-Master Theory
Multi-master means just that; no one master source manages directory data. Unlike Windows NT 4.0, where the Primary DC is that master of the domain database and the Backup DCs cannot write to the directory, Active Directory enables each DC to write to its local copy of the directory. This removes the "single point of failure" limitation of Windows NT because although one DC can fail, the other DCs continue to provide read/write domain services to clients. These changes are then replicated to all the other DCs in the domain.
As shown in Figure 10.4, each DC hosts at least three Active Directory partitions that all replicate. In this model, it is possible, and likely, that at times different DCs will not have the same domain data because changes have occurred and replication has not taken place. This is the nature of a distributed, multi-master directory. This means that reality might be a bit different across the organization at various times because not all the objects in the directory are constant. This theory of loose consistency stipulates that not all DCs in the domain are guaranteed to be a perfect copy of one another at all times and that this is OK. However, the DCs become consistent after all changes have converged upon each DC. Convergence stipulates that despite possible inconsistencies at any given time, the final state of the data in the directory is consistent because each attribute's current value exists somewhere in the directory and will be replicated across the enterprise.
Figure 10.4. A single domain with multi-master DCs.

The Replication Process
The replication process is a complicated one. Reason being that objects, which exist on multiple servers, are assets of an organization and their integrity must be maintained. To maintain this integrity, it is important to assure that as objects change in the directory, the value that survives replication is the value intended to survive.
The replication process establishes and maintains a series of values on each attribute (as well as on the object) that are incremented as changes are made. As a DC receives replicated data, it uses these values to assure the data being replicated to the server is newer than the data contained on the server. The majority of the time changes replicate among the DCs without incident. It is not common for replication conflicts to occur, especially when replication occurs at the attribute level. However, when they do occur, they must be dealt with.
Imagine, for example, an administrator in London changes the value of a user's phone extension to 72164. A few minutes later, an administrator in Los Angeles changes the same phone extension to 71963. Both of these changes need to replicate, but which change is correct? Look at an example that is a bit more complex. Imagine that an application in London makes 10 changes to an attribute in the directory. After which, another application in Los Angeles makes one change to the same attribute in the directory. Which change is most valid? The 10th change made in London or the only change made in Los Angeles? Look which values are maintained during replication and how they are used during conflict resolution to see if we can figure it out.
Replication Partners
First, it is important to understand the relationships between DCs. As you will see in a few pages, the DCs in your Active Directory have a special relationship with at least two (when available) other DCs in thei r site. These other servers are designated as the DCs replication partners. By having more than one replication partner, each DC can receive replicated data from more than one path, providing fault tolerance. On the other hand, by not having each DC replicate with every other DC in the site, replication traffic is mitigated. The replication partner strategy provides a happy medium between fault-tolerance and minimal replication traffic.
Keeping Track
Next, it's important to understand the type of changes made by a DC to the directory and to the values used to keep track of them. There are two types of updates to Active Directory: originating updates and replicated updates. As the name applies, originating updates are changes made to the directory by a user or administrator, whereas replicated updates are changes made to a DC database that have been replicated by another DC in the organization.
If originating updates are made to a DC, a counter on the DC is incremented. This counter, the update sequence number (USN), is what is used by other DCs to determine which updates need to be replicated. Each attribute, object, and server has an individual USN. These USNs are incremented when changes take place to the attribute, object, or server.
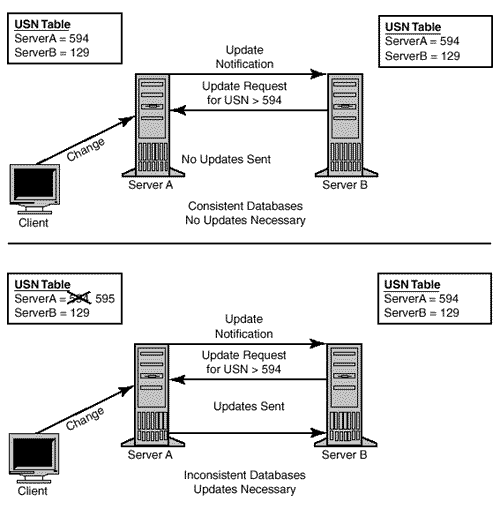
For example, imagine a change is made to the directory on Server A. Server A's USN is incremented to 595, as shown in Figure 10.5. Five minutes later, (default) Server A notifies Server B that updates are available. Server B requests all updates greater than the USN it has for Server A, which is 594. Server A sees that Server B needs the directory update represented by USN 595 and sends Server B that update. Server B receives the replicated update, commits it to the directory, and updates Server A's USN to 595. All is well.
Figure 10.5. The DC replication process.
Exchange 5.5 (and earlier) also uses this directory replication process. The major difference is that Exchange servers in a site do not have directory replication partners. Rather, if a change is made on an Exchange server, that server replicates the change to all other Exchange servers in the site. Because Active Directory uses replication partners to improve performance, it is possible that a DC could receive the same replication data from different DCs. To prevent this, Active Directory has implemented what is called propagation dampening. Propagation dampening is the process of only requesting replication changes that have not been replicated.
To facilitate propagation dampening, each DC maintains an up-to-date vector. The up-to-date vector is a set of USNs that represents the highest originating update for each server. Each DC also maintains a high watermark vector, which is the highest USN for all the objects of a server in the directory.
The best way to understand how t hese values are used in propagation dampening is with the example illustrated in Figure 10.6 and explained in the following steps.
Figure 10.6. Replication propagation dampening.

A change is made to Server A.
Server A sends Server B and Server C a notice that an update has been made, along with Server A's up-to-date vectors.
Server B and Server C independently compare the up-to-date vectors sent by Server A to confirm that they require the update, which they do. They then request the updates from Server A.
Server B and Server C commit the changes to their directories.
Then, they notify their replication partners of the change. In this case, Server B's other replication partner is Server C. Server B sends Server C a notification that a change has been made, along with Server A's up-to-date vectors.
Server C receives this notification and Server B's up-to-date vectors and sees that it has already received the update from Server A. Server C does not request the update from Server B, and the replication propagation is dampened.
Conflict Resolution
If a single attribute is changed on two different DCs and between replication intervals, the directory becomes inconsistent and must determine which value should represent the attribute. Conflict resolution is the process of choosing one of the attribute changes as the value that represents the attribute.
DCs only replicate object properties at the attributes level, not the whole object. Not only does this increase efficiency, but it also helps to minimize conflicts. If the name of an object is changed on one DC and the address of the same object is changed on another DC, no conflict arises because of attribute level replication.
However, to resolve any attribute conflicts that do occur, Active Directory maintains version numbers and timestamps for each attribute as metadata. Unlike USNs, the version numbers and timestamps are not specific to the DC. Rather, these values are specific to the attribute.
When an attribute of an object is first populated with data, the attribute is given a version number of one. All additional originating updates (not replicated updates) increment the attribute's version number.
If a replicated attribute is received from a replication partner and if the replicated attribute's version number is the same as the local attribute's version number, then the attribute with the latest timestamp wins. In the rare case in which the version numbers and the timestamps are the same on the replicated attribute and the local attribute, then the attribute whose database has the highest Globally Unique Identifier (GUID) value wins. This assures that in all cases only one attribute wins.
Therefore, in the example at the beginning of this section, in which two phone extensions where changed on two DCs between replication intervals, the phone extension that was changed last would have the latest timestamp and would represent the phone number attribute for that object. In the more complicated example, in which ten changes were made to an attribute in London after which one change was made to the same attribute in Los Angeles (all happening in between replication intervals) the tenth change made in London would win despite the change occurring earlier than the one change made in Los Angeles. This is because the London change would have the greater version number.
Intra-Site Replication
Intra-site replication is replication between DCs in the same site. One of the aspects of a site that makes up the definition of a site is that all DCs share a high-bandwidth network. Rather than consume additional CPU cycles making network communications more efficient, DCs within the same site communicate freely with one another.
Within a site, DCs do not poll one another to see if changes need to be replicated. Rather, when a change is made on a DC, the DC waits about 300 seconds (or 5 minutes) before sending a change notification to its replication partners in the site. When the replication partners receive this change notification, they pull the change from the DC and update their databases through the replication process previously explained. The originating DC waits 5 minutes because it is probable that additional changes will be made, and it is more efficient to replicate multiple changes at once. Furthermore, if a DC receives no change notifications for six hours, then the DC initiates a replication request with its replication partners.
Now, some types of directory changes need to be replicated immediately. Specifically, changes to Active Directory that concern security, such as password changes, DC role changes, and user account lockouts. These changes will not wait the 5-minute change interval, but rather the change notification will be sent out immediately.
Inter-Site Replication
Because sites themselves are defined as having high bandwidth, the parts of the network that connect sites generally have limited bandwidth. Therefore, more effort goes into conserving network bandwidth between sites. Data is compressed as much as 15 percent before being sent between sites.
Unlike intra-site replication, inter-site replication does not use change notifications to initiate replication. Rather, replication is scheduled. This enables the site design to take into consideration off-peak network hours or an interval that does not constantly consume the entire network bandwidth.
With that said, remember that if a change is made to a DC, the change will be replicated between sites if the sites are in the same domain. Sites do not minimize network traffic, but they help mitigate it through compression and a replication schedule.
Replication Transports
There are two possible transports between Active Directory sites: synchronous RPCs (IP), see Figure 10.7, or asynchronous Simple Mail Transport Protocol (SMTP), see Figure 10.8. Asynchronous SMTP is more efficient and reliable over limited bandwidths and unreliable network connections than synchronous RPCs. Because it is likely that sites will have limited bandwidth, you would think that SMTP would be the best choice for the transport used between sites. However, there is one caveat: SMTP cannot be used to replicate domain partition information between sites.
This means that if a domain is going to contain more than one site, then synchronous RPCs are the only transport available for domain replication traffic between those sites.
Figure 10.7. RPC site link connector between sites within domain.

Figure 10.8. A SMTP site link connector between sites across domains.
If you have two domains, each with their own site, then asynchronous SMTP can be used to replicate the configuration and schema partitions between the two domains/sites.
What does this mean for site design? It means that the limitations of synchronous RPCs make the amount of reliable network bandwidth between physical locations a consideration when designing your domain topology. If you are designing domains to span multiple sites, consider the limitations of RPCs because it is going to be used to replicate the domain partition information between sites.